Lightgbm: [performance] Single row predictions speedup.
Hello,
Context
I know you're looking for ways to improve performance throughout the codebase.
I'm working on a production scenario with LightGBM for real-time prediction systems where throughtput and latency are both important.
Due to those and other constraints, since I receive individual events which must be scored as quickly as possible, I'm using the method LGBM_BoosterPredictForMatSingleRow for it states in the documentation that it partly reuses internal structures to speed up computation.
Change proposal
I looked at the code to see if there were any easy wins we could pull off and saw that for every single prediction we create a new Config object from scratch. This object has roughly 200 members, and also must parse the configuration string into the different properties.
I split that LGBM_BoosterPredictForMatSingleRow call into a "configuration/init" call that creates the config and a "scoring" call that uses that config. With some small twraks I got in a very basic case almost 2x the throughtput. This requires adding 2 functions to the C API (without touching existing code at all):
LGBM_BoosterPredictForMatSingleRowFastInit(creates the config before scoring lots of events)LGBM_BoosterPredictForMatSingleRowFast(score using the pre-build config - as we're not changing parameters)
Check here the call graph for the current (non-patched code) with a binary classifier test with 1 thread, 7 features and 100 trees (extremely simple model):
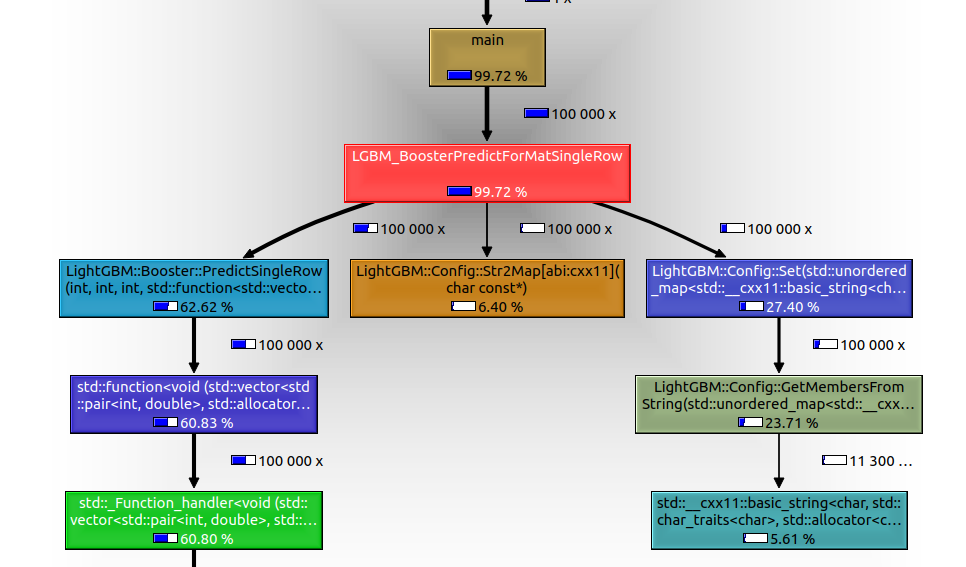
Roughly 1/3 of the time (27.40% + 6.40%) is spent recreating the same Config over and over.
Notice only the left branch is doing "meaningful" work when you mantain the config properties - i.e. score lots of events with the same configuration.
In that implementation I was speaking of that cost no longer exists.
You can find a prototype code in here: https://github.com/AlbertoEAF/LightGBM/blob/ft-af-PULSEDEV-30690-optimize-single-row-predict-fast/src/c_api.cpp.
Can we add those 2 functions to the C API?
This is just the prototype and I could work a bit more on it to further improve it.
 AlbertoEAF
AlbertoEAF
All 4 comments
@AlbertoEAF that looks very promising! I could definitely reuse that in mmlspark's version as well to improve performance.
 imatiach-msft
on 23 Mar 2020
imatiach-msft
on 23 Mar 2020
Also ping @eisber as the original author and this method is only used in SWIG wrapper which in turn is used by MMLSpark.
 StrikerRUS
on 23 Mar 2020
StrikerRUS
on 23 Mar 2020
@AlbertoEAF good catch! Contribution is very welcome.
 guolinke
on 23 Mar 2020
guolinke
on 23 Mar 2020
Closed via #2992.
StrikerRUS
on 15 Jul 2020
Related issues
 mayer79
·
3Comments
mayer79
·
3Comments
 BuGTEa
·
3Comments
BuGTEa
·
3Comments
 tbenthompson
·
3Comments
tbenthompson
·
3Comments
 zanemarkson
·
3Comments
zanemarkson
·
3Comments
 chivee
·
3Comments
chivee
·
3Comments
Most helpful comment
@AlbertoEAF that looks very promising! I could definitely reuse that in mmlspark's version as well to improve performance.