Leela-zero: 40x256 training note.
 bjiyxo
bjiyxo
All 305 comments
@gcp @roy7 Can you match 40b in queue?
bjiyxo
on 2 Aug 2018
can you add information of training?
 l1t1
on 2 Aug 2018
l1t1
on 2 Aug 2018
learning rate 0.0001
current round: v152-v155 + elf
released version: 328k.
still going
previous round: v148-v152 + elf
final version: 384k
I forgot the rounds before these two. But I remembered that bjiyxo posted it in some thread.
ps: 328k vs 224k = 76:61, not tested vs elf0, elf1
224k vs elf0 = 86:83
224k vs elf1 = 53:79
all matches with 3200 visits
 bubblesld
on 2 Aug 2018
bubblesld
on 2 Aug 2018
So released version should probably be in between Elf0 and Elf1, which is quite much stronger than LZ160, so nice! Let's wait for the test results anyway, that'll clarify it's Elo
 Friday9i
on 2 Aug 2018
Friday9i
on 2 Aug 2018
Thanks Bjiyxo, can't wait to see this...
 john45678
on 2 Aug 2018
john45678
on 2 Aug 2018
I'm a bit worried by the LR however: isn't it a bit too small? If yes, we risk being stuck in a local minima and it will be hard to improve it by selfplay (without going down quite significantly, which is not allowed by gating). BTW, isn't it the problem we face with current 20b net?
Friday9i
on 2 Aug 2018
@Friday9i if it is much better than current 20b, it will generate much better games. That and with new elf1 games, it will maybe be possible to see improvement and pass gating with a higher LR maybe.
i dont even know if this learning rate is bad at current LZ state.
 herazul
on 2 Aug 2018
herazul
on 2 Aug 2018
@Friday9i I tried 0.0005 learning rate for the same training data, and found that the result is poor (worse than the previous weight).
bubblesld
on 2 Aug 2018
Thx @bubblesld, interesting
Friday9i
on 2 Aug 2018
I could be wrong, but I feel that the poor results from offiicial 20b is due to the high learning rate.
bubblesld
on 2 Aug 2018
I don't remember, what was the learning rate at the end of 15b ? didn't @gcp lowered it at the end ?
Maybe LZ has enough step and is at a point where LR must be reduced to 0.0001, whatever the size of the net being trained.
herazul
on 2 Aug 2018
@bubblesld Is the 40b net2net from a smaller lz network, or did you bootstrap it from a random net?
 NhanHo
on 2 Aug 2018
NhanHo
on 2 Aug 2018
@NhanHo from bjiyxo's 20b. @bjiyxo did the net2net.
bubblesld
on 2 Aug 2018
@NhanHo @bubblesld No, I didn't n2n this time. I trained it from Xavier Initialization.
bjiyxo
on 2 Aug 2018
bjiyxo
on 2 Aug 2018
@bjiyxo How many games were the network trained in total? It seems like my net needs to run through the last 2million games to match the current network strength
NhanHo
on 2 Aug 2018
@NhanHo
How many games were the network trained in total?
40b was trained from the beginning of 10b.
It seems like my net needs to run through the last 2million games to match the current network strength.
Maybe you can post your training schedule, including your window, lr, bs and data.
bjiyxo
on 2 Aug 2018
What is this Xavier Initialization ? It was a clean 40b blank net ?
herazul
on 2 Aug 2018
You can regard Xavier Initialization as clean 40b blank net.
bjiyxo
on 2 Aug 2018
okay thanks for all the informations !
herazul
on 2 Aug 2018
Test matches queued.
 roy7
on 2 Aug 2018
roy7
on 2 Aug 2018
Promising start against Elf1, let's cross fingers!
Friday9i
on 2 Aug 2018
I would not expect 40b to be close to elf1.
bubblesld
on 2 Aug 2018
From your comment above 328 vs 224 vs Elf1 that should be quite close...
Friday9i
on 2 Aug 2018
@Friday9i It is not. From my experience, the best weight in each round is much better than that of the previous round. But the winning rate against elf0 increases very slowly (even worse sometimes).
bubblesld
on 2 Aug 2018
If the 40 block network comes our really strong, why don't we go all out and use it? Mabye even lower the visit amount to 800 and see what happens, I think it would be very interesting to see.
 MartinDevelopment
on 2 Aug 2018
MartinDevelopment
on 2 Aug 2018
If the 40 block network comes our really strong, why don't we go all out and use it
We could. It's "only" half the speed as 256x20. We would skip an optimal 256x20 network then, but we have ELFv1 too, so there's options in that range.
 gcp
on 2 Aug 2018
gcp
on 2 Aug 2018
Looks like the Elf v1 is still much stronger. Sorry it may off-topic here. May I ask that doest it make sense to produce self-play game between two network? (elf v1 vs current best) I am currious that it can know how to win it self from elf v1.
 2ji3150
on 2 Aug 2018
2ji3150
on 2 Aug 2018
Note the file size on 40 block is huge though. Wonder if we eventually need a torrent based solution for that.
roy7
on 2 Aug 2018
@roy7 I don't think a torrent based solution would work since some people might not have access to that since it is blocked for them.
MartinDevelopment
on 2 Aug 2018
Since this net has also been trained with very low learning rates, it is likely that promoting it would encounter the same initial problem as we're having right now: Reinforcement learning with the usual learning rates would likely fail to produce networks which pass gating.
 jkiliani
on 2 Aug 2018
jkiliani
on 2 Aug 2018
@MartinDevelopment "I don't think a torrent based solution would work since some people might not have access to that since it is blocked for them"
A big file can be split into parts and joined with a very simple utility.
 Marcin1960
on 2 Aug 2018
Marcin1960
on 2 Aug 2018
Well, seems like the 40b net is way too good to not use.
herazul
on 2 Aug 2018
@2ji3150 I guess that current match is with 1600v. elf has advantage in low visit due to its sharper values in policy. I believe that 40b can produce at least 1/3 w.r. against elf1 for higher visit.
bubblesld
on 2 Aug 2018
@gcp 40b self play games are very useful to produce any lower block weight, and whatever you want. We do not care half speed for 40b training and current 20b is hopeless and just a aimless lost in elf trap
Most guys in our training group (500 persons] also wish to keep going on 40b and it’s very attractive and we will enjoy this great promotion.
 alphaladder
on 2 Aug 2018
alphaladder
on 2 Aug 2018
Reinforcement learning with the usual learning rates would likely fail to produce networks which pass gating.
We can drop learning rate then. I don't see any other options to progress. The next run for the current 256x20 will be at bs=128 @ 0.0001. (By the way, if you mention learning rate, the number is pointless if you don't include the batch size!)
I didn't manage to train a net competitive with the best 192x15 with larger rates.
current 20b is hopeless
Well, by this kind of reasoning, we don't need to try the 256x40 because it'll be more of the same. (Luckily I don't agree with you)
Note the file size on 40 block is huge though. Wonder if we eventually need a torrent based solution for that.
Data traffic from my webserver was 3.5TB in July. If we go above 5TB, it will be throttled (but not dramatically). I suspect we'll be fine. Most of the traffic seems to come in huge spikes, so that won't be the clients who are downloading new networks day to day, but rather people who are downloading all networks or something. I hope there won't be people running the clients that suddenly get a scare when they see their data traffic stats.
I'd like to see if we can get any movement on the 256x20 before we go to 256x40 though. Let's give it one more cycle at the lower rate at least.
gcp
on 2 Aug 2018
20b progressed.
 1-punchMan
on 2 Aug 2018
1-punchMan
on 2 Aug 2018
Data traffic from my webserver was 3.5TB in July. If we go above 5TB, it will be throttled (but not dramatically).
If you do end up needing some bandwidth, I'd be happy to provide a server with 60TB/month.
 tux3
on 2 Aug 2018
tux3
on 2 Aug 2018
i think experimenting with 20 blocks is fine and above all interesting
after all, elf v1 is 20 blocks but still much stronger than this lz 40 blocks
this just shows how much potential the 20 block has
i think its really interesting to keep waiting for 100-150k games on the 20 block lz to see how it influences new networks strength and direction of play
20b is not stalled or hopeless, its just its in early stage, i think
there seems to be a trend on the 20b, progressively getting stronger and learning things (fixing its own holes ?)
i'm curious to see how things will develop for the 20b network, remembering that elf v1 is 20 blocks but so much stronger
 wonderingabout
on 2 Aug 2018
wonderingabout
on 2 Aug 2018
i think theres no need to upgrade immediately to 40b
40 blocks may be be stronger at the start, but like elf v0 and v1 showed, 20 blocks has the potential to be stronger than current 40 blocks lz
so as long as 20b is not stalling, it may be more efficient to use it as a training point (starting point is lower, but we can expect it to learn faster than 40b if we look at elo gained per week, with equal computing power between 20b and 40b)
also, this will require less ressource to train and less ressource to play matches (which can be useful to play against it on weak computers, smartphones, etc...)
and finally, like i said, i'm curious to see how this 20b experiment will develop, going directly to 40b makes us miss a chance to learn knowledge and experience about bots
if we made some mistake, its a good opportunity to learn from it, no need to rush things
you should also consider that by the time lz 40 blocks catches up to elf v1, elf team can release a 40b elf v2 which will be insanely stronger than the 40b you want to achieve, so again rushing for strength is pointless imo
wonderingabout
on 2 Aug 2018
I think we have to leave this decision to @gcp, there are certainly arguments both for and against going to 40 blocks soon. If a majority of self-play contributors favor upgrading sooner rather than later, we might as well upgrade early this time, but there's no harm in at least waiting out another few training cycles while trying different learning rates.
jkiliani
on 2 Aug 2018
I am no expert on this. I am very interested in seeing how high leelaz can reach with a 40-block network. Also, it is unlikely that we will see leelaz surpass ELFv1 in its strength anytime soon. So the fans' enthusiasm might be dampened at a certain point if we keep training a 20-block network that is far below the strength of ELF.
The only worry I have is that it appears we do not know exactly why we are having problems with the current 20-block networks. It could be the learning rate, the ratio of the ELF games being used, the use of 1601 visits, or something else. I would think that we want to at least have a better idea of the problem before moving onto 40 blocks since it will take double the amount of time to experiment to find the problem if we are stuck again at the 40-block level.
Perhaps, all what we are seeing is the nature of the network when it reaches a certain level of strength. I suspect that if we are stuck in 40 blocks again in the future, we will have to try the Alpha Zero approach of no gating to move a network out of a local minima.
 iteachcs
on 2 Aug 2018
iteachcs
on 2 Aug 2018
Since we're considering going to 40 blocks soon, one possible change that would very likely help in either case would be to up the ELF fraction in game production, from 25% to half or even higher. Regular self-play games at 1600 visits are currently somewhat weaker than 15 block games at 3200 visits, but ELF v1 games are definitely more useful than either. Having more of them sooner may help the 20 block nets to pass gating, and would also be more useful in case we switch to 40 blocks.
jkiliani
on 3 Aug 2018
It's hard to believe the current lack of improvement can largely be attributed to the training process hitting a plateau at the current network size, considering the smaller ELF networks that are significantly stronger than not only the current best 20x256, but also the bootstrapped 40x256 one. The training process is meant to maximize improvement per time unit (which was the motivation behind decreasing the number of visits). In the absence of a legitimate plateau, it simply makes no sense to have a larger and thus slower network generate training games. That has always been the purpose of the current "official" network and the very fact a larger, stronger network could be created from the training games by a separate endeavor in the first place means that no one should somehow feel deprived of anything.
I think the network size of the training process should not be increased until there are no more 192x15 games in the training window, and maybe even that then there should be a full pass through all the typical learning rates (to have a chance of getting out of local maxima), just to make sure this isn't a transitional issue and 20x256 is indeed irredeemable beyond a reasonable doubt. Don't be impatient and worry about a few weeks.
 TFiFiE
on 3 Aug 2018
TFiFiE
on 3 Aug 2018
@TFiFiE What you don't consider is that if a net is WAY better (even if it's a bigger net) than a smaller net, it's better to generate the selfplay game with it, because the net you will train on these way better self play games will be a lot better (even if you want to train a smaller net with these games).
If the 40b net only had something like 60 or 65% WR it would be debattable what's better for the fastest training possible : the 40b net and it's 60% wr ? or two times faster 20b net with slightly worse game quality ? But with an insane 40b net with 85% WR, there is not even a contest.
Doesn't mean it's not interesting to continue with the 20b net to see what can happen and what's wrong with it's training for now and test things and parameters, but for efficiency it's 100% the 40b net.
herazul
on 3 Aug 2018
@herazul
Recall that AlphaZero was trained from scratch. If human games were used, the training would
hit a lower "ceiling". In other words, an AlphaZero trained by human games would have a faster start,
but the final result might be a weaker network, as it might miss some "blind spots".
 MacErlang
on 3 Aug 2018
MacErlang
on 3 Aug 2018
@MacErlang The concern was that the weight is contaminated by the weakness of the human games. Then what is your point comparing to skip 20b-net? In fact, the 40b weight is already contaminated by the weakness of the lower block games since it is trained from those self-games.
bubblesld
on 3 Aug 2018
What's the evidence that human games resulted in a lower ceiling?
 diadorak
on 3 Aug 2018
diadorak
on 3 Aug 2018
@bubblesld You have a good point. I am no expert on this. But, perhaps one implication is that
the 40B network (or any new blocks) should be trained from scratch, despite the poor performance
at the outset. Does this make any sense at all? Since potential moves are generated randomly, a
clean slate might reduce possible sampling bias created by weaker games from a lower block count.
MacErlang
on 3 Aug 2018
It is necessary to conduct experiments and data analysis to find technical details not mentioned in the paper.
l1t1
on 3 Aug 2018
No, I didn't n2n this time. I trained it from Xavier Initialization.
So the problem may be n2n? I dont know much about training, but if the 40b network was trained in absolute different way, it may worth a try to train a new 20b with the same training methods and parameters to find out why the 20b network is so poor now. It may not be just the problem of network size.
 kfc51151271
on 3 Aug 2018
kfc51151271
on 3 Aug 2018
@alphaladder
I think 40 blocks will get the same chance.
But is there any guarantee that the current trap will not occur in 40 blocks? We need more time to test until we find a way to solve this problem.
Efforts to solve this problem at 40 blocks are much more expensive.
ELF shows that the limit of 20 blocks is much higher than we are.
If the problem is solved it is a good thing. If not, go to 40 blocks.
Wait for the results with more patience.
It is not a great help to continue to speak the same opinion of yours.
gcp will choose in the right direction.
 22nsuk
on 3 Aug 2018
22nsuk
on 3 Aug 2018
@jkiliani I think I read in some of the issues that someone (I think our Chinese contributors) tried to produce networks with varying amounts of ELF generated games and found that even 25% may be too much. That few games spice the training, but perhaps too much makes it stuck in between both optimal ELF as well as LZ plays (and being weaker).
I personally would have probably liked to adopting ELF games altogether (we had a slow progress in the last month anyway, we might have had it the same by not adopting ELF generated games somewhat earlier). I kind of fear that we will be always chasing ELF. As soon as we catch them they release a new, bigger and better network (perhaps not to spite us, just out of coincidence), the end result will be the same: 1,5 publicly available network (ELF and ELF derived LZ) instead of 2 clearly independent.
But in the news we have to trust GCP, I don't even remember if he ever made a clearly wrong choice regarding the project, so let's wait and see, I trust him :-). In 2-3 days we will know if lowering LR helps 20x256. Even if I might prefer going to 40x256 for the bigger final potential it is not that important. Though I do wonder where we got all the new hundreds contributors?
 sheeryjay
on 3 Aug 2018
sheeryjay
on 3 Aug 2018
@sheeryjay
i was wondering about something similar
wouldnt it be better to stop using elf selfplay until 20b catches up to current best 20b network ?
because elf will make our current 20b stronger in a faster way and using stronger plays, but the weaknesses ("holes") in the network architechture will still remain, and these weaknesses may possibly prevent the stronger elf moves from being used in the best conditions
perhaps it is better to let the 20b figure out the "weaknesses" by itself and fix them, and when the new networks generated get back to the same strength as our current best 20b, then introducing elf selfplay may be more effective ?
the way i see it, getting new generated 20b networks's strength back to best 20b may be a prerequired step to scale the 20b development
it is also possible to do both elf + 20b selfplay at the same time, but isnt stopping elf until 20b catches up an interesting idea ?
wonderingabout
on 3 Aug 2018
The only worry I have is that it appears we do not know exactly why we are having problems with the current 20-block networks. It could be the learning rate, the ratio of the ELF games being used, the use of 1601 visits, or something else. I would think that we want to at least have a better idea of the problem before moving onto 40 blocks since it will take double the amount of time to experiment to find the problem if we are stuck again at the 40-block level.
Yes, this is exactly my reasoning as well.
If we can improve the 20 blocks, we can still see what to do. If it improves at 55.01%, well, then switching to the 40 blocks could speed us up. But if the 20 blocks starts promoting every cycle at 66%, then it's a different matter entirely.
gcp
on 3 Aug 2018
@MacErlang
Recall that AlphaZero was trained from scratch. If human games were used, the training would hit a lower "ceiling".
I think we don't know that in fact. Alphago and AlphagoZero have very different training process and architecture, we don't really know what would have happened with an AlphaGo Zero initialised from human pro data if i'm not mistaken.
We don't even know if all Zero bots who are improving are converging toward the same style of play or not.
@GCP will you try to lower next cycle %Elf games in training ? @bjiyxo had succes with 30-40% of elf games if i recall correctly, might be worth a try too.
herazul
on 3 Aug 2018
I suspect the current issue is more likely learning rate, so let's see what that gives first.
I think we don't know that in fact.
We don't. It's unfortunate that the graphs in the DeepMind papers are rather unclear, but I think the suspicion was that Alpha Go Master was actually stronger at 20 blocks than Alpha Go Zero, so they did Alpha Go Zero at 40 blocks to beat them both. But of course, what would have happened with Alpha Go Master at 40 blocks?
gcp
on 3 Aug 2018
Why not for now wait until 20b self-play games are more than half of the window and, then, if we still don't have a promotion, lower the LR gradually until we get one.
 afalturki
on 3 Aug 2018
afalturki
on 3 Aug 2018
The very low scoring (20%-30%) suggests that training with more and new data, even if few, is making the network considerably weaker, which I think is a different situation than nets that are about the same strength (40%-54%).
gcp
on 3 Aug 2018
Two things have changed at the same time, the network and the visits. Wouldn't it be wise to just going back to 3200v? We don't care about game generation slowdown on the short term, what matters is to quickly put the new net on track, no? You may have to play with learning rate for a while.
Once promotions have resumed, visits reduction effect can be considered, against the new baseline.
 Ishinoshita
on 3 Aug 2018
Ishinoshita
on 3 Aug 2018
Yes, this is exactly my reasoning as well.
If we can improve the 20 blocks, we can still see what to do. If it improves at 55.01%, well, then switching to the 40 blocks could speed us up. But if the 20 blocks starts promoting every cycle at 66%, then it's a different matter entirely.
——-/////——
very reasonable.
alphaladder
on 3 Aug 2018
@gcp we set up the random play in the whole training games, thus, is it a problem in the current step?
Too many short games in our current training games.
Previously only in the first 30 steps.
alphaladder
on 3 Aug 2018
The whole game t=1 training worked really well for the 15x192 networks. Why would it suddenly cause problems?
diadorak
on 3 Aug 2018
that is what we are trying to slove...
alphaladder
on 3 Aug 2018
See? 20b is progressing.
1-punchMan
on 3 Aug 2018
yes,if problem could be solved in these 20b tests, then we have more reason to start 40b.
Test any bugs in 20b and start to run 40b weight mixed with some portion of elf games. 20b is just for trouble shooting.
Running 20b with elf is just a copy of elf v2 ,not our LZ. 20b is the field of Dr. Tian’s. 40b belong to lz
alphaladder
on 4 Aug 2018
I can't believe people now appear to be rooting against whatever progress might be happening under 20x256 (if I'm correctly interpreting the thumbs-downs 1-punchMan's comments are getting). :confused:
@alphaladder, you can't have it both ways here à la Morton's fork. The fact is, that if the promotions start coming in again, then we're (ideally) only about 7.5 minimal promotions away from a 20 block that is as least as strong as 1fdfb1c5 under equal visits, let alone under equal time, meaning that a hypothetical parallel training process of 40x256 would likely be overtaken in the medium term.
"_No plateau, no size increase_" seems like a perfectly fine motto to adhere to and being that 20x256 was one of the sizes DeepMind settled on (for who knows what reasons), it deserves some proper treatment by the project that seeks to replicate their work.
TFiFiE
on 4 Aug 2018
20b 7a8a0c1a is stronger than 511034f4 79 : 75 (51.30%)now
l1t1
on 4 Aug 2018
@TFiFiE see gcp review above. I can not get your point since we have other better fast promotion methds for Lz in 40b level. Just to follow elf v1 in this 20b using elf games.
I bet people prefer to train a 40b network if 40 has any opportunity in the queue of training.we should fully make use of elf in 40b , rather simple copy !
alphaladder
on 4 Aug 2018
40b can run on a mobile phone/low-end computer, but it is too slow to use, while 20b can run nicely on those platforms @alphaladder
l1t1
on 4 Aug 2018
@I1T1 You can use 40b games for any weight in any size of block. Do not worry.
Otherwise we should stop in 15b and go home, which is enough for most guys. Just kidding.
In our training group with 500 persons, they have great enthusiasm in 40b training.
alphaladder
on 4 Aug 2018
can you training out a 40b weight which is stronger than 20b elf? @alphaladder
l1t1
on 4 Aug 2018
See? 20b is progressing.
The question is: Is it because of the new learning rate or is it because we have more self-play games now?
 betterworld
on 4 Aug 2018
betterworld
on 4 Aug 2018
I vote for learning rate.
bjiyxo
on 4 Aug 2018
Did @gcp say that he lowered the LR?
afalturki
on 4 Aug 2018
I vote for learning rate,too.
alphaladder
on 4 Aug 2018
can you training out a 40b weight which is stronger than 20b elf?
————
@I1T1. You do not get my point. We have already a very good 40b candidate in the queue. If we could start this 40b scenario, it should easily exceed elf. In most cases, 40b should have much possibility than 20b to beat elf. It is very hard to exceed elf series since Tian is still working on his 20b.
Let us wait for gcp’s decision after recent test in 20x256.
alphaladder
on 4 Aug 2018
@alphaladder
i think someone has to say it directly to you :
just because you have the right to speak doesnt mean you can say whatever nonsense you feel like depending on your mood, its better not to speak if you dont know what you're saying
if you want to ask questions, to learn information, or if you have an opinion, express it in a humble way, being open to be wrong and corrected
all this is adding a lot of work to the contributors, making the work more exhausting and less efficient
of course, i'm saying this to you but i'm the first one trying to apply it to myself
hope this helps...
wonderingabout
on 4 Aug 2018
@wonderingabout
I do not understand what you are focusing on . It looks like that you are interested in initiating a useless “nonsense” or aggressive argue in person
Since it is not associated with this issue any more, please stop @me .Thank you.
alphaladder
on 4 Aug 2018
I'm not sure how relevant for this particular problem at hand, but I have always found the bigger and more complex a net is, the lower the usable learning rate is. Even with non-constant / decaying lr schedules, I saw complex tasks where the net converged but only to a trivial "I don't know" middle result, and only started to do actual work with lower initial lrs.
Net size have more than doubled between and 192x15 and 256x20 (not to mention the increased understanding and complexity one hopes for), so it wouldn't be surprising if rather different lr would be necessary.
EDIT: Likely unrelated to the training problem, but just now I noticed that not just selfplay but even matches are reduced to 1600 visits now. This is very surprising and will certainly affect match results! Since we know that the difference in result scales up with more visits, achieving 55% is significantly harder now than before. Was this change accounted for somehow?
 tapsika
on 4 Aug 2018
tapsika
on 4 Aug 2018
Just adding my 5 cent to the debate. I think chasing after ELF and comparing LZ continuously to that is counter-productive: Facebook has and will always have superior resources, and so long as they pursue the bot, it is quite guaranteed we will be following their tail if we obsess about comparisons, and probably lose our unique way doing that.
I feel that just switching to 40b to "easily have stronger than ELF" network before seeing if we can make 20b work is not the long-term solution. There is even no proof that "easily" is true at all, it might as well be "harder and slower than through 20b" (maybe we encounter same issues as with 20b, or it takes 3 months and we could've gotten there with 20b in 2.5, who knows?). I'm having a gut feeling myself that the "40b is 2x better than 20b" is too intuitive to people and "because AZ had 40b" people think that somehow just having the Bigger Network will boost the results.
Silly analogy: If I had a 500 hp motorbike that goes 100 mph and could not get it to go 200 mph (when that Mark guy next door has a 400 hp bike that goes 250 mph), I would not buy a 1000 hp bike that already goes 150 mph. I would first try to get my 500 hp one to go 300 mph, and THEN buy the bigger one, or build it myself using the learnings.
It's true that the 40b network is currently stronger, and maybe it might be best to train a 20b net but use new ELF and 40b to generate the games. But I think the strength of Leela Zero project is the long-term view, and while it may feel frustrating to wait for several days, even a week or two, and not immediately adopt the currently biggest and meanest, I'd vote for patience and maybe even doing things a bit sub-optimally, if we can get experience that might save us bigger (40b, 50b, 100b, whatever) headaches in the future.
 jokkebk
on 4 Aug 2018
jokkebk
on 4 Aug 2018
I like analogies. :) If you have brains of a fly, a mouse, a dog, a human, a superhuman. There is no much sense to produce the best go playing dog. But you should learn how to teach best the game of go by testing with the smaller sized brains.
My conclusion: Continue with 20b up to the moment, we know, what may go wrong and how to insure that the network improves.
Probably this is the same idea as @jokkebk just voted for.
 Gondolieri
on 4 Aug 2018
Gondolieri
on 4 Aug 2018
@jokkebk
"it might be best to train a 20b net but use new ELF and 40b to generate the games. "
Generating self-games is the part consuming most of resources. Training a weight from self-game is much easier. The debate will be generating 20b or 40b self-games, not training 20b or 40b weight.
bubblesld
on 4 Aug 2018
@jokkebk That's not a good comparison. For one thing, clearly the issue with the bikes is the transmission/gear ratios, and that 500hp bike is getting to 100mph lightning fast and will smoke the neighbor's bike off the line every day of the week.
The big advantage that having more blocks will confer is the bot will be able to better see larger parts of the board, and therefore better avoid the big problems that smaller networks face, such as large, nontrivial ladders or the life and death and semeais of very large groups. Having the extra information will allow bots to either win these large fights, or find nuanced, expert ways to avoid them. And there's also the other potential benefits that come from better pattern recognition and increased capacity, which humans can only speculate about.
It's not that a 40b is twice as good as a 20b; it's that a 40b will learn strategies that a 20b will miss completely, and that fundamental difference can never be overcome, no matter how much you train a 20b or how much search you use, because the 20b is sub-optimally pruning and narrowing the search space based on a relatively smaller sample of information about the state of the game.
Incrementally increasing the size of the network makes for an interesting experiment to see how bootstrapping larger networks from smaller ones (and the training data set produced by the smaller ones) impacts the efficacy of the training process and the quality of the final network, if at all, but there's no proof yet that we're actually gaining a computational time advantage from doing it, as we don't have a control group that we can make comparisons to and use to draw meaningful conclusions about our methods.
We're basically just wandering about in the dark while tinkering with some things here and there and making inferences to refine our training methods, using statistical reasoning and otherwise, that are likely subject to a multitude of systemic biases and in a manner that's very difficult to reproduce. That's not to say that the LZ project doesn't have a lot of value, however, as we're the only group providing a fully open source zero-style dcnn go bot with a large training data set and a tool that is completely reshaping the world of go and leading to better understanding and appreciation for the game.
The point is that where we're at now, there's not much significance in the choice between continuing with a 20b or a 40b, except that there's no actual evidence that going through a 20b first will actually be faster in the long run, and a 40b should, in the long run, produce better results. Even if we know that increasing the number of blocks affects the rate of game generation in polynomial time, and therefore a 20b should generate games twice as fast as a 40b with equal visits, if it becomes necessary to decrease the learning rate and step size of larger networks to get them to continue to converge, or potentially be forced to lower or remove gating to try and escape a local extrema, it could potentially be a wash in the long run. What's the chance of reaching an adverse outcome? We simply don't know.
Again, there's no actual evidence to support either path, so really it just comes down to preference.
 Crazyeight101
on 4 Aug 2018
Crazyeight101
on 4 Aug 2018
@crazyeight01
Thank you for your great review! Very reliable and objective.
alphaladder
on 4 Aug 2018
We're basically just wandering about in the dark while tinkering with some things here and there and making inferences to refine our training methods, using statistical reasoning and otherwise, that are likely subject to a multitude of systemic biases and in a manner that's very difficult to reproduce.
So, then, business as usual when it comes to programming neural networks. :P
 anonymousAwesome
on 5 Aug 2018
anonymousAwesome
on 5 Aug 2018
Before I present my proposal, I would like to show the results of 400 matches between 40b (new round 112k) with 1600 visits and 20b (v160) with 3200 visits.
40b (1600v) vs 20b (3200v) = 231 : 169
The running time for 40b with 1600v is a little longer than 20b with 3200v, but very close. That means, we can generate self-games with better quality from 40b than from 20b for the same period of time.
Now, I would like to propose the next version of LZ to generate 20b self-games as default, but people with high-end machines can add some parameter to generate 40b self-games instead. This will be a win-win. The total amount of self-games will stay about the same.
For the 20b training, there are some better quality games. And remember that the weight of 40b in some sense is much closer to that of 20b than elf to 20b, which may produce greater help. The bottom is: there is no harm to the 20b training.
For the 40b training, the part of better quality games stays the same. And the most important thing is that the self-play games generated by itself can correct some mistakes learned in the previous round of training. From the experience of 20b training by bjiyxo, the weights of 20b once had a serious ladder problem that the weights of 15b did not have. The weight of 20b does not know that it has such a problem because no its self-play game for training.
In summary:
- Let the clients select the type of self-games they want to generate.
- The total amount of training games will be about the same by this approach.
- It is good for both 20b and 40b trainings.
What do you think?
bubblesld
on 5 Aug 2018
@gcp problem is solved in 20b,thus, could you please let us know any possibility to run 40b ? Thanks.
alphaladder
on 5 Aug 2018
@bubblesld Great plan!
We could simply run 50% LZ-20B (1600visits), 25% LZ-40B(800 visits), and 25% elf-v1 (1600visits).
Then we might be able to improve both the 20B and 40B networks faster.
diadorak
on 5 Aug 2018
I am a strong bot supporter. But if you match 40b & 20b in normal match setting ( 30min, 1min byo-yomi), 40b really can't compete with 20b weight because 20b get as twice the playouts as 40b. 40B is only good when you have 500K or 1M+ playouts/min ( at least you should have 2 or more 1080Ti). It only benefits to very few people who has extraordinary ambition on FoxGo server. And I like to point out here, 500 persons in QQ group is just nothing, most people there only take and not give, and manipulated by few persons. @alphaladder is keeping blablabla and try to influence the direction of LZ project. why should the Leela Zero project to satisfy your need or ambition?
 jamesho8743
on 5 Aug 2018
jamesho8743
on 5 Aug 2018
@jamesho8743
Did you test what you wrote? 40b is not as good as 20b in normal match setting?
My tested results show 231:169 when 20b gets twice visits. Furthermore, from my experience, it will favor 40b more if both visits are doubled.
bubblesld
on 5 Aug 2018
I only have 1070 card, in my test, 40B lost more often than 20B because the playouts is poor and in any case, 20B always has the "double" playouts than 40B. 231:169 please describe your time settings and setup. As far as I know even Octopus can win ELF with more playouts. To most people, I think one 1080Ti is top gear setup, and 30min/1min is very standard and universal.
jamesho8743
on 5 Aug 2018
And as your 231:169, it's only 57.75% winrate. What is the advantage of 40B? Let alone the majority of people who has mediocre card.
jamesho8743
on 5 Aug 2018
@jamesho8743
@bubblesld said its 40b (1600v) vs 20b (3200v).
So it's 57.5% win rate in 400 games at time-parity independent of hardware.
diadorak
on 5 Aug 2018
The 40b is not my personal ambition. It is our final goal for lz program.And most guys will support 40b.
I do not think you really learn our training group in QQ. In fact, we produce at least thousands of self play games per day but in your eye it is nothing. Are you kidding? How many self play games do you make daily? 30? @jamesho8843
I just consult gcp on the possibility based on his previous response, which is not judged by your preference of 40bphobia.
At last, kindly reminder is that your blablabla supported by your noble graphic card could not make the direction of lz. Thanks.
alphaladder
on 5 Aug 2018
@jamesho8743 What is the sample size of your tests ?
 remdu
on 5 Aug 2018
remdu
on 5 Aug 2018
in my test, 40B lost more often than 20B
The strength of the current 40B network is not so important. It will only be the starting point for more training on 40 blocks. The theory is that after a couple of weeks / months, a 20B network cannot become as strong as a 40B network.
betterworld
on 5 Aug 2018
@betterworld
Yes. The debate is just to find the efficient way to our final goal of az 40b.
We could learn a lot from the fall and rise of 20b training, which is also benefit for potential 40b block.
alphaladder
on 5 Aug 2018
@bubblesld I like your idea. But I think there is one potential risk. According to your training scheme, for either 20b or 40 b network, the training data is partly self-played and partly supervised (by the other network and elf). Both networks might be like students taught by three different teachers that often contradict one another. By trying to reach a compromise among conflicting teachings, the students might end up worse, not better.
 ashinpan
on 6 Aug 2018
ashinpan
on 6 Aug 2018
No, I didn't n2n this time. I trained it from Xavier Initialization.
@bjiyxo Could Xavier Initialization for 40b and net2net for 20b have made a difference in their performance? 40b seems to be doing a lot better than expected with similar training data.
 estonte
on 6 Aug 2018
estonte
on 6 Aug 2018
@estonte
I have no idea. It's hard to compare after millions of steps.
bjiyxo
on 6 Aug 2018
good~
 wonsiks
on 7 Aug 2018
wonsiks
on 7 Aug 2018
@bjiyxo did you also try Xavier Initialization for the 20b networks, as it apparently worked very well for the 40b net?
Friday9i
on 7 Aug 2018
@Friday9i No. It will need ~2 weeks to train a 20b on 2x1080Ti if you use a similar schedule from my 40b.
bjiyxo
on 8 Aug 2018
Didn't know it was so long..., I understand you didn't! Thx for the answer
Friday9i
on 8 Aug 2018
Sorry, I match 40b vs 20b by accident and if 40b wins it will promote. So if @gcp or @roy7 is not here, I will match 20b vs 5b to get a quick fix.
bjiyxo
on 9 Aug 2018
mistake happen, i'm sure roy can correct it =)
Well played on the training anyway, seems like the new 40b is very strong ! Did you start using elf v1 games in the training ?
herazul
on 9 Aug 2018
Fixed by roy7
bjiyxo
on 9 Aug 2018
40b-157-360k (e2be4815) trains to 157, the last 15b. It didn't train neither elf-v1 (d13c4099) nor 20b yet.
bjiyxo
on 9 Aug 2018
Okay thank you.
I'm quite hyped to see the results when the training includes some 20b games and elf v1 games !
herazul
on 9 Aug 2018
Because the 40b-157-360k was trained to the last 15b, so before we get into 20b, it shall be a good reference there. After this 40b, I will test 40b when 20b is ~5 promotion.
bjiyxo
on 9 Aug 2018
@bjiyxo
The new 40b look so good!
How about 30b? Do you have the intrest about 30b? Maybe it is a good trade-off for the strengh and speed.
2ji3150
on 9 Aug 2018
My original idea was that 20b was used for training, and 40b was used for competition, and now I don't have enough machine to train another network. I'm training another 20x256 from scratch, but I am not sure if it works.
bjiyxo
on 9 Aug 2018
I see, Thanks!
Looks like elf v1 is still stronger than 40b. And it is much much stronger than our 20x256 network.
That't very strange that our 20x256 network still progresses slow.
Does it worth to train a 20x256 network based on elf v1 and see whether its strengh is near elf v1 or not ? If it isn't that should be some problem on our training . And if it is much stronger than we can know there is still some potential. And it can be the new teacher or we can just mix the network with our 20x256.
2ji3150
on 9 Aug 2018
The slow progress of 20x256 is not strange, because its potential is relatively limited, probably less than 1000 Elo (selfplay)... A net improves fast in the beginning, then slowly when it's close to the asymptot: we are close to the asymptot, so it is slow. And we are close because we trained very well the 15b net and because the difference of potential between 15b and 20b is not huge (we know it from Elf v0 and v1)
That's why I think we should switch to 40b, because it has for sure much more potential, so we should enter a new cycle of frequent promotions and improvements, which is nice and motivating for everyone.
Friday9i
on 10 Aug 2018
Our 20b is nowhere near as strong as ELF though, so there should be plenty of room for improvement.
roy7
on 10 Aug 2018
Only 400 Elo difference, which in selfplay is less than 1000 selfplay Elo: this is "relatively close to the asymptot", and it will take quite a lot of time to go there (several months probably).
I find it much more exciting and motivating to switch to 40b, where the potential is probably 2000 or 3000 selfplay Elo points: we would get frequent improvements and fast LZ would be an ultra super human bot :-)
Friday9i
on 10 Aug 2018
on intuition, i see things kinda like it, but i don't know if th'at remotly true :
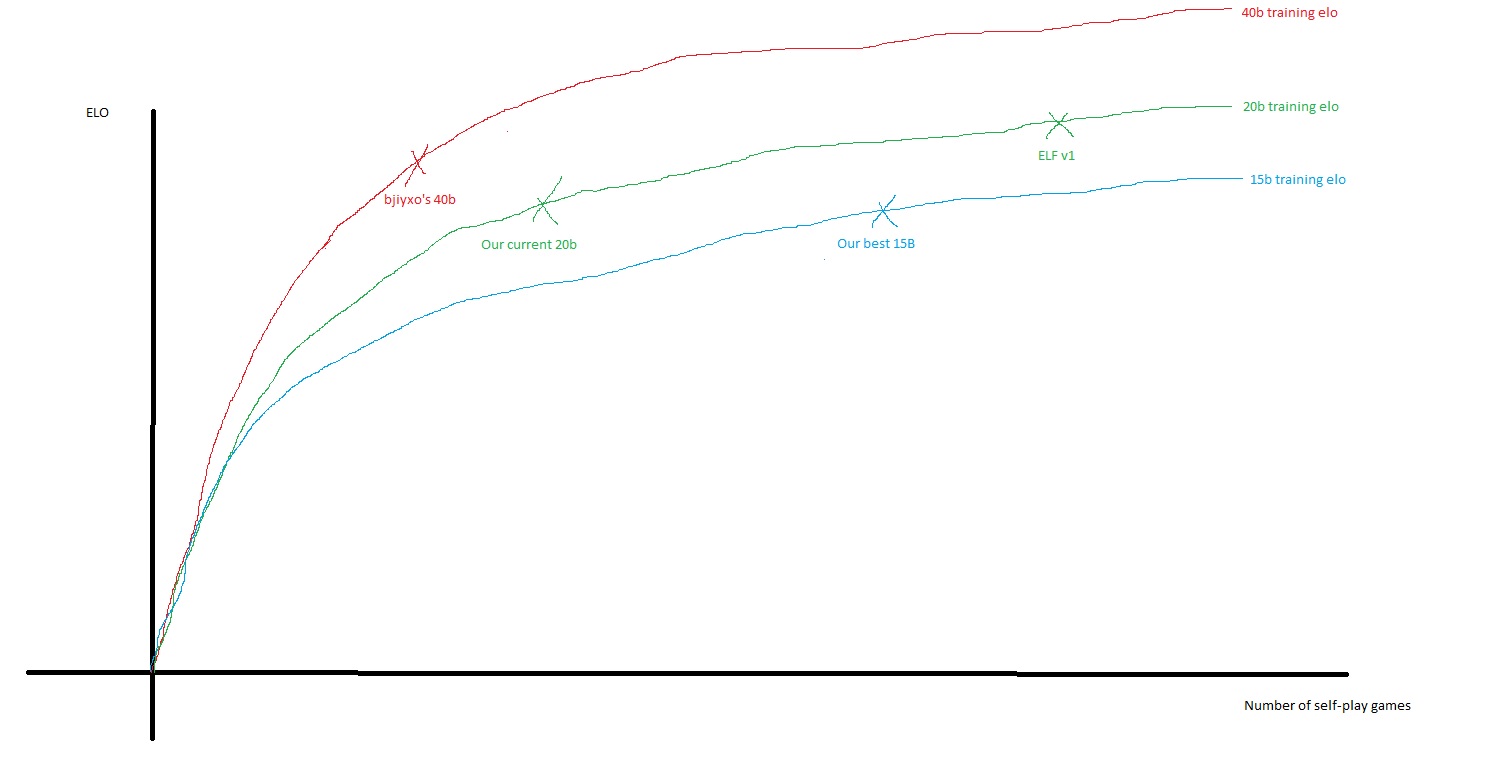
But yeah if bjiyxo's 40b is already at elf v1 elo, a very well trained network, i think the 20b will take a very very long time to cath up, furthermore if it's true that elf v1 is realmly close to 20b skill ceiling. (and it may be, because opengo said it took them a LOT of additional steps to get 65% wr against their v0 net)
herazul
on 10 Aug 2018
The test match had a winning rate around 52% at first 220 matches. It was close to my personal test. I have 40b win 96 out of 200. I do not know what happened to the last 180 games.
At the moment I thought that the w.r. will be close to 48%, I would like to suggest to keep training 20b but replacing elf self-games with 40b self-games. I believe that the 40b weight is closer to the 20b one so that 20b is easier to learn from 40b than elf. Now that elf1 is still better than 40b from the official test. Maybe we should wait a little longer.
bubblesld
on 10 Aug 2018
Small update of our pretrained model for ELF OpenGo. This is v0 after finetuning with approximately 250000 additional minibatches (learning rate 1e-4).
Elf v1 is said use 250000 mini batches for fineturing and it is 67% stronger than elf v0 by our test. Does it means 250000 games? If it does, how elf can grow so fast by just 250000 games.
2ji3150
on 10 Aug 2018
Elf v1 is said use 250000 mini batches
Are we talking about mini-batch size or number of mini-batches per epoch? The first one (increasing the batch size) is a known solution to keep learning rate high and speed up fine-tuning. Although 250k samples would be a really high mini-batch size.....
Ishinoshita
on 10 Aug 2018
It looks like the 40b is very close to the best ELF now.
I said before I don't think we need to max out 20b as there's already ELF in that size that people can use (or just any other size!). So it makes a lot of sense to jump to 40b. The gain in Elo is much higher than the x2 speed loss.
I am catching up on uploading data now. I assume it will give an updated 40b another boost. By the time that network is up I think we can queue it for promotion?
gcp
on 10 Aug 2018
Elf v1 is said use 250000 mini batches for fineturing and it is 67% stronger than elf v0 by our test. Does it means 250000 games? If it does, how elf can grow so fast by just 250000 games.
No it's not only 250k selfplay games (or i didn't understand something). I just asked them on their github, maybe we will have an answer.
@gcp in the next @bjiyxo 40b net, there will be 20b games and some elf v1 games, it could be interesting to match it versus previous 40b iteration to see if it didn't cause problem to the training before promoting.
herazul
on 10 Aug 2018
@gcp also i have several questions when you promote 40b :
- what LR do you plan to use ? same as 20b or will you try a little higher LR at first ?
- will you keep 384k and 512k net ?
- still 1601 visits ?
herazul
on 10 Aug 2018
Probably go one step back with the learning rate, i.e. 0.0001 @ bs=128. But I doubt it will work.
I don't think I'll keep >256k, a net did promote but several of the other steps were already >54% so I think that was just a bit random. Most importantly, I don't see a sign the score gradually increases with more steps.
We'll stay on 1600 visits for now. It's probably a little low now but a) we know this is efficient as long as we can pass the promotion bar b) I suspect this is the kind of thing that matters more if you are trying to max out a size and 40b shouldn't be there for a long time?
gcp
on 10 Aug 2018
Yeah ok makes sense.
For the LR if it don't work no big deal, at worst you will have some cool github issue ! :p ( " THIS IS INTOLERABLE §§§!!! NO PROMOTION FOR A WEEK !!!§§ WE DEMAND THE KING'S HEAD !!§§§§§§§ " )
herazul
on 10 Aug 2018
Thx for these precisions.
However I don't understand your last point "40b shouldn't be there for a long time", could you clarify please?
Friday9i
on 10 Aug 2018
@Friday9i i think he just mean that 40b is far from it's skill ceiling, we should have a lot of progression before we start approaching it. So no hurry to optimize training strength, we can go for training speed in the mean time.
herazul
on 10 Aug 2018
Indeed @herazul, that's the point, thx
(I was wondering if he spoke about a step further, eg 60b, but it didn't really make sense :-)
Friday9i
on 10 Aug 2018
From my experience of 40b training, learning rate of 0.005 did not work well (i.e. become weaker). But things may be different with 40b self-games.
bubblesld
on 11 Aug 2018
Now that the server issue has been resolved. Should a 40B network be queued for promotion match?
diadorak
on 16 Aug 2018
@diadorak I imagine they'll probably do it after bjiyxo's 40b catches up to the full training data set and produces good results. The 162 version showed only marginal improvement over the 157 version, so it probably needs additional steps or some other adjustments first.
Crazyeight101
on 16 Aug 2018
@bjiyxo @bubblesld Just curious. Are the 40b-162 networks trained with ELF v1 games as well?
diadorak
on 16 Aug 2018
@diadorak
Yes, all 40b-162 was trained with ELF v1. 40b-162 was trained with 15b 137k games, 20b ~250k games, elf v0 ~210k games and elf v1 ~80k games.
bjiyxo
on 17 Aug 2018
it looks new games' contribution are small, and new 20b still much weaker than elf, then increase elf v1 games proportion ,since elf team says they played 2.5M games
l1t1
on 17 Aug 2018
This might be a good time to give 40b a try if the server is ready to handle 40b networks with the help from the colab trainers' effort of diverting network traffic. While 20b is making steady progress, it is concerning that the win rate of 9c56ae62, the current best 20b network, is actually worse than d351f06e, the best 15b network, when matched against ELF open go v0.
If 40b is to be used, 66ba9e7a appears to be a good network that can provide an immediate elo boost. e2be4815 can also be a good candidate for consideration.
iteachcs
on 17 Aug 2018
@iteachcs: " it is concerning that the win rate of 9c56ae62, the current best 20b network, is actually worse than d351f06e, the best 15b network"
If so, perhaps 224x20 is the way to go? (d13c4 is
224x20)
Marcin1960
on 17 Aug 2018
@Marcin1960
224x20 is certainly a good choice if network strength is the only consideration. However, we already have Dr. Tian's team working on ELF Open Go networks. It is very likely that Dr. Tian will release new networks in the future when progress is made for Open Go. Therefore, there is not much point in competing with Dr. Tian by further advancing Open Go networks in the Leela Zero project. On other hand, the 40b network has Leela's own identity while providing a sizable ELO boost at the same time.
iteachcs
on 17 Aug 2018
@iteachcs "224x20 is certainly a good choice if network strength is the only consideration."
Hmm, isn't the network strength the main consideration?
"the 40b network has Leela's own identity"
What I meant, that it is possible to have 224x20 net with Leela's own identity.
Marcin1960
on 17 Aug 2018
a new 40b weight need about 10 days to trainning by bjiyxo, 20b promoted 5 weights(163-166) in those days. it's hard to choose.
l1t1
on 17 Aug 2018
@Marcin1960
I understand and respect your point. My main worry of using 224x20 is about competing with Dr. Tian, which does not seem to be very productive considering Dr. Tian is still working on the same network. Leelaz's identity is also important to me personally--although I provided no contribution to the code base, I have been running training games since last November.
iteachcs
on 17 Aug 2018
@iteachcs " My main worry of using 224x20 is about competing with Dr. Tian"
Than perhaps to try 224x21 would be OK? Unless you think it would be too close? I wonder why Dr. Tian picked 224x20? Could it be some sweet spot based on empirical data?
Marcin1960
on 17 Aug 2018
@Marcin1960
It is very possible that the choice of block and feature numbers are based on empirical evaluation. Your suggestion of 224x21 networks could be stronger than 224x20 ones but there is no empirical data to support it. In addition, we do not have a good existing 224x21 network to start with and the performance improvement of 224x21 might be too small to make a difference.
My guess is that people's suggestions of 256x20 or 256x40 networks were mostly based on Google's agz studies. It is reasonable to believe that Google must have empirically evaluted and decided that the 256x40 network size is the most useful in producing strong networks since it is the final product that they presented in the agz paper.
iteachcs
on 17 Aug 2018
when matched against ELF v0, d351f06e used 3200v and 9c56ae62 used 1600v, so it's not fair to say the 20b network is actually worse. In fact, the winrate is improved compared to the previous match between 20b and ELF (79.50% to 73.93%). Of course, big gaps are always frustrating, especially as the slope of the 20b progress curve doesn't look good, compare to the 15b one.
kfc51151271
on 17 Aug 2018
@kfc51151271
Thank you for pointing out the difference in visit numbers. The only remaining argument I could offer would be that the visit number of ELF v0 was also reduced to v1600 so it might still be possible that d351f06e was stronger than 9c56ae62.
Either way, 20b is clearly making progress so the only question is whether we want to embrace 40b now, for the ELO increase, or stay with 20b and run its course. I think I have said enough and should leave it to the more knowledgeable to decide.
iteachcs
on 17 Aug 2018
@iteachcs "Your suggestion of 224x21 networks could be stronger than 224x20 ones but there is no empirical data to support it. "
You missed my point. You expressed concern that "using 224x20 is about competing with Dr. Tian".
If this is not the case, than let 224x20 be the net. Certainly there are VERY strong "empirical data to support it".
Marcin1960
on 17 Aug 2018
In case you missed it, I posted my test result 12 days ago in this thread
40b (1600v) vs 20b (3200v) = 231 : 169
20b was v160.
bubblesld
on 17 Aug 2018
when matched against ELF v0, d351f06e used 3200v and 9c56ae62 used 1600v, so it's not fair to say the 20b network is actually worse.
Exactly because of this, losing to 73.93% at 1600 visits is worse result than 72.46% at 3200 visits. As I wrote in the other thread, lowering match visits pulls results towards 50%, and at higher visits ELF would win more.
tapsika
on 17 Aug 2018
a new 40b weight need about 10 days to trainning by bjiyxo, 20b promoted 5 weights(163-166) in those days. it's hard to choose.
@l1t1 I do not think that it is a fair comparison.
I am helping the 40b training with 1080ti x4. In each cycle, we have at least 400k self-games. With 240 batch size, it is about 64k steps each day. For 360k, it is about 5 days. Usually we would not go beyond 500k steps.
We tried to find the best one in each cycle, and test it. I do believe that we will have some passed 55% if we test t for each 32k (to be analyzed later). For the cycle up to v162, the 360k one has 69:45 against the previous 40b. The winning rate is above 60% and the p-value that it is not better is 0.0154 (which is rate than winning 220 out of 400). We tried to have it tested. But then there was server issue.
When the server issue is gone, we found that 416k is even stronger (37:16 aginst the previous, with p-value at 0.0027). We have 416k tested first. failed. We then try the 256k one. Failed again. I can not believe the results. But, well.... it happens, and everything is possible with probabilities...
Back to statistical theory, the chance of a weight with 51% w.r. to win 220 or more out 400 is about 6%. That means, in average, we can have a weight with 51% passed in 17 trials. From my personal testing, I believe that the weight in this cycle is at least slightly better than the previous, so I believe that I can have one passed if we test the weight as often as the 20b. However, I do not think that promotion is the most important thing. The real improvement is more important.
BTW, we are now going to the next cycle with a few more elf1 and v163-5. From my test, 16k one is 28:22 to the previous one. I would say that it has some probability to pass. Well, we are not going to have it tested until we find a much stronger one.
bubblesld
on 17 Aug 2018
Omg,training lz in 20x224? thus we do bacame the cheap copy of elf.
alphaladder
on 17 Aug 2018
@alphaladder "Omg,training lz in 20x224? thus we do became the cheap copy of elf."
What I meant is that elf size might be advantageous for some peculiar reason. Maybe shape of the net matters?
Marcin1960
on 17 Aug 2018
@alphaladder
close your free colab if its what you want..
just because some colab is contributing doesnt mean you can blackmail with it
everyone is free of will, this includes the colab choice to support leela zero, as well as leela zero project's choice to stay at 20b or go to 30/40/50/100 blocks..
wonderingabout
on 18 Aug 2018
@alphaladder please go away
 PhilipFRipper
on 18 Aug 2018
PhilipFRipper
on 18 Aug 2018
@alphaladder
i was just pointing out how flawed your reasoning is (your comment about "the free colab that is contributing a lot might not be here anymore if you dont move to 40b soon" , (something like that) , you seem to have deleted this comment by now)
i personally dont care how slow a thing is, it was like that before the colab and other people were here btw, but i cant stand people who think like you, that just because they help, people will bow down their heads and beg for help.. dont look down on people, people are proud about their work and care about the how, and btw again, history showed countless times that people with such attitude often suffered horrible deaths by the people they hurt, begging for their lives and promising to give a huge quantity of money if they spare and protect them..
to go back to the point, i think leela zero project welcomes you and is thankful to you if you want to help and contribute on your own free will, but if you think you deserve everything just because you contribute, thats really a disgusting view... it reminds me of those rich men (or women) who think they can do whatever they want to people(insult, hurt, humiliate, harass, dirty one's pride, etc..) just because they have money...
please, let's think in a human and caring way
wonderingabout
on 18 Aug 2018
I appreciated your technical explanation and my opinion to gcp &roy7 is based on the opinions of many Chinese users who have at least hundreds of colab accouts while can not express their worrying on future training in english on this github. All of them are not rich and need the help of free but unreliable help of colab gpu, which is the main reason why we prefer 40b .You can not bear it but I fully understand.
Blackmail, nonsense,go away... Those are the words that you guys like to use. How about the next phrase you preferred? So I am very happy you guys are not Gcp otherwise .....Thus, I really have nothing to say. Do not @our humble colab trainers,thanks.
alphaladder
on 19 Aug 2018
This isn't an opinion sharing forum. It's mainly for coders to discuss the code. People who contribute machine time aren't really a part of this conversation. Myself included. I hate posting here because I don't belong, but I do every few months when a really arrogant person comes and annoys everyone all day long. Back to my silence now.
PhilipFRipper
on 19 Aug 2018
@alphaladder "All of them are not rich and need the help of free but unreliable help of colab gpu, which is the main reason why we prefer 40b ."
Tell me friend. What personal computer would you recommend for people to buy, to handle 40b nets and quite possibly larger nets?
Marcin1960
on 19 Aug 2018
@alphaladder
i understand you, but if you want to speak in the name of all your chinese friends that dont speak english, then first of all you should have a more diplomatic, open minded, and understanding attitude
i believe most of chinese users, just like all users, are mostly reasonable people, so you dont do them a service by forcing your opinion and being impatient..
then, about their "worrying on the future of training", leela zero project is already considering moving to 40 blocks at some point, and they train and test networks for that, but there no immediate need or reason to move immediately to 40 blocks, also, there are some disadvantages to that, including losing low power users (and other applications like smartphone apps for example, it may be good to max out every block size)
also, everyone worries, not only chinese people, so there is no point to mention that chinese people, specifically, worry, everyone here is on the same boat and should think of all users as one single community sharing the same goals, amibitions, and worries
so, can you tell them that there is a plan and to be patient like everyone else for now, and see with an interesting eye the daily improvements made by leela zero project on whatever blocks ? rather than being desperate to reach alphago level (which is going to take many years at least on this project)
also, if they dont like the direction of the project no one is forcing anyone to do anything, and no one has debts to anyone, i want to stress this point again, it is important to understand. this is includes all users, all contributors, and even project owners, that are not forced or commited to their project forever, its only as long as they want to continue it, dont forget
personally, i'm wondering about moving to 30 blocks rather, which may be faster and still have some potential for strength improvement (when 20b starts to stall), but its just my opinion and i express it patiently without trying to force it, and if this is not accepted, i will respect the decision
hope all this helped
wonderingabout
on 19 Aug 2018
" rather than being desperate to reach alphago level (which is going to take many years at least on this project)"
That is why I like an idea of two main branches.
One for those with powerful machines or access to special resources, who love competition and tournaments, based on 40b nets and larger.
Second branch for those who are interested in clever algorithms and artificial intelligence.
De facto it is already is taking place:
Marcin1960
on 19 Aug 2018
RTX 2080 and RTX 2080 Ti will be announce tomorrow, they will be good at training
l1t1
on 19 Aug 2018
I am still puzzled at the official 40b test result. In the current cycle, we have training data with v158-v164 + elf1 + some elf0 (3500-4294). Learning rate 0.0001, batch size 240. Training with 1080ti x4.
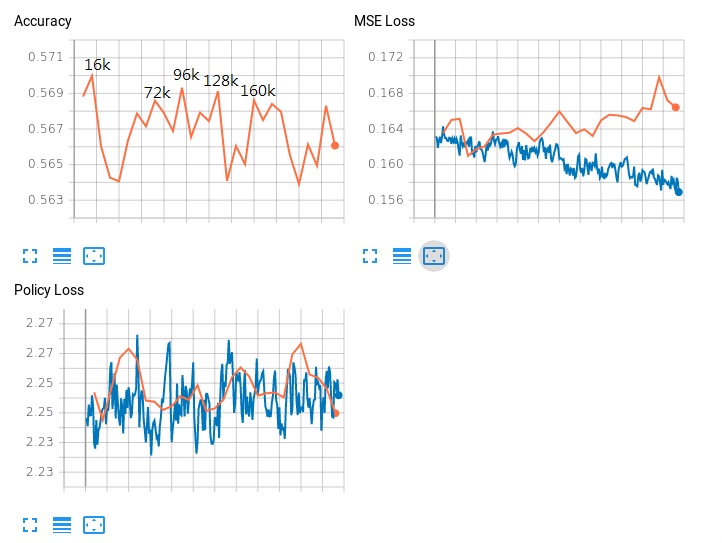
We tested the peaks from the figure above (from our experience, a good weight is usually generated from the peak of accuracy). With 1600v against the previous 40b:
16k 57:49 0.5377
72k 107:77 0.5815
96k 54:49 0.5243
128k 61:57 0.5169
160k 63:49 0.5625
We have 72k tested in the official website. The result is 176:174 (0.5029). I do not know how to explain that all what we tested are more than 51.6%, and it turned out that the best one we picked has only 50.23% in the official test. We wonder whether the resign rate is the difference. We set it as 18 in our tests. What is the number for the official tests? In our tests, we never see a game end with non-resignation.
Then I want to say that people may think that the training of 40b seems stalled. But it may not be the case. The training data are self-games from 20b and elf. 40b training is trying to learned from them. The improvement will be probably on increasing the chance to beat 20b and elf. There is no self-game of 40b, so that it will not learn how to beat itself.
I ran 400 test matches against elf1 with the result 203:197. I am also running test matches against v167 with current result being 54:7. Since my results are often very different from official results, can we have test matches of 40b against elf1 and 20b to check the progress of 40b?
updated result vs v167
59:11
stopped at
117:26
(to test other peak)
bubblesld
on 20 Aug 2018
@gcp @roy7
Do you think that we can have test matches against elf1 and 20b as I suggested above? Thanks.
bubblesld
on 20 Aug 2018
Thank you very much for the great data in details, which is the real thing that we should focus on.
I think one reason is that all your tests are performed in 1080ti gpu while the lz official tests are also involved in 980 or 1050 gpu?
Similarly, in the cpu only machine , the performance of zen 7 is better than the that of 15b 157. As we know that 15b 157 is far strong than zen7.
Just a reference. Anyway, direct match between elf1 and new 40b is very reasonable.
alphaladder
on 20 Aug 2018
@alphaladder
GPU should be irrelevant since visits are specified, not time.
@bubblesld
The resignation threshold is set at 5% in the official test. Here are the settings:
Leela Zero options: -p 0 -v 1600 -r 5 -m 0 -t 1 -d --noponder -s 4508320485158256009 -g -q -w networks/e2be4815f74d5293db054a706ecbed3c9586e110ecbf4917ee58942bd1c836a3
diadorak
on 20 Aug 2018
@bubblesld Either it's bad luck to get less winrate vs what you tested, or it is the resignation threshold. As you tested several nets, bad luck is very unlikely: hence, it must be the resignation threshold...
I saw several games where a net had a winrate below 18% and then won, so this 18% threshold is probably too high: you should probably test with 5% as in the official test.
Friday9i
on 20 Aug 2018
@bubblesld I think you are getting way to many false positive resigns. But that doesn't explain all of the extreme difference. Therefor we need to know a few things. What version/commit of LZ are you using? What are the exact settings you are using? What hardware are you using?
MartinDevelopment
on 20 Aug 2018
I am using the latest LZ with command like
gogui-twogtp -black "~/leelaz -g --noponder -t 12 -q -v 1600 -r 18 -w ~/40b_157_360k.gz --gpu 1 --gpu 2 --gpu 3" -white "~/leelaz -g --noponder -t 12 -q -v 1600 -r 18 -w ~/40b_165_256k.gz --gpu 1 --gpu 2 --gpu 3" -games 400 -sgffile 40b_157_360k_165_256k -size 19 -komi 7.5 -alternate -auto&
It is using -v 1600, so it should not matter to what hardware I am using. Anyway, the machine is with ubuntu and 1080ti x8. I am using 4 gpu for training.
I do feel that the setting on the w.r. is the difference. I think that "-r 5" will lead the result closer to 0.5, since there will be some mistakes that should not happen for higher visit after the w.r. is below 18%.
bubblesld
on 20 Aug 2018
I vaguely remember that "-t 12" could introduce more noise too. Maybe just use "-t 1" like the official tests?
diadorak
on 20 Aug 2018
And "-r 18" would hurt ELF much more than LZ's networks since ELF's win rates vary more quickly. It might resign prematurely in many winnable games.
diadorak
on 20 Aug 2018
@diadorak For sure indeed, high threshold favors LZ vs ELF, good point.
In the same way, it may favor old 40B vs newer 40b if the new ones are a bit more "stable" and get a sharper vision of winrates: that would also result in an optimistic result with high 18% resgin threshold, and lower result with lower resign threshold.
All in all, I think you should do your tests with -r 5
Friday9i
on 20 Aug 2018
@bjiyxo congrats, the a3047139 network seems like a beast. 75-85% winrate against best 20x256, that might mean even a time parity based victory.
If gcp is ready to switch over to 40x256, this seems like a good candidate. Though I guess he will want the binary weight format merged before that so a few more days are to be expected?
sheeryjay
on 20 Aug 2018
@bubblesld it seems a304 is a monster against LZ168, now above 87% winrate and it scored 39 wins in a row, just totally amazing!
Maybe new iterations of 40b learned to better play against ELFv1 and 20b-LZ, but not so much against itself (40b), which would explain it did not improve significantly (vs e2be)? If that is the case, it's even more promising to switch to 40b selfplay, as it would probably improves even faster ;-).
Anyway, a test against ELFv1 seems useful.
Friday9i
on 20 Aug 2018
Though I guess he will want the binary weight format merged before that so a few more days are to be expected?
That's not a consideration at all for a lot of reasons. (See format discussion, but also the need to stabilize the current code so we can actually make a release and get clients to update...)
I'll start a test of the quantized version of this 40b.
gcp
on 20 Aug 2018
The only real concern is the possibility that we lost some clients that are out of RAM for 40b. But I think a) on master it's less of an issue b) on next we just had some fixes c) those are going to be slow clients.
gcp
on 20 Aug 2018
This isn't an opinion sharing forum. It's mainly for coders to discuss the code. People who contribute machine time aren't really a part of this conversation. Myself included.
I wouldn't say that. If your feedback is: the 40b seems 10 times slower on my machine because my GPU runs out of memory, this is important to know :-)
I'm also very interested in what the people who actually play go think. I sometimes wonder how many there are here :-) All the ones I talked to care about komi and getting sensible analysis in lopsided situations (still hoping for a series of small pull requests from alreadydone there at some point).
It is true that there are so many opinions shared here (you know what I said about opinions vs data) that it's been long impossible to follow all, or maybe even most of it, and my priority in time is to unblock the people who are trying to develop the code, i.e. putting the reviews out.
Given that 20b is now progressing normally, 20b vs 40b is a bit of judgement how fast the 20b progresses vs how much stronger the 40b is. The latest 40b looks very good, and we have addressed some of the issues that would've made it problematic.
The quantized test is running now. If it's good, I'll switch to 40b (and the server will output quantized nets). (I am traveling next week so I'd rather do it sooner rather than later)
gcp
on 20 Aug 2018
One argument for sticking to 20b for a while is to test whether our net is definitely stuck in some local optima. If 256x20 fails to eventually catch up to both Elves, this would confirm a sub-optimal configuration of weights, due to the inability of current learning rates to reorganise the net sufficiently. Right now, 256x20 is improving at a good rate, I'm very curious where this will take us.
jkiliani
on 20 Aug 2018
Quantized 40b seems to work well (around 50% after 70 games), we may advance soon to 40b ;-)).
@gcp On another subject, it seems almost 50% of the time spent by clients are on endgame moves for no resign games: these moves are necessary to avoid score errors, but is there any need to spend so much time on them? Note: as they are quite "random", there's almost no tree reuse and 1600 visits leads to almost 1600 playouts, hence no resign games are extremely long. A low number of visits may be enough for that job... Naphthalin suggested on discord a simple approach: to halve visits each time the 2 players passes non-consecutively. What do you think of that? That would for sure help the transition to 40b ;-)
Friday9i
on 20 Aug 2018
@friday9i. The 0 resignation strategy should greatly improve the endgame technique of lz,especially for some special shape we called blind point in the endgame. Another benefit is what we called “”no slack”. Those are the opinions of professional players, just for your reference. :) Thanks. It looks Dr.Tian prefered it in elf training.
alphaladder
on 20 Aug 2018
Note the dynamic komi branch already reduces slack moves. Leela will just continue to crush you after already winning.
roy7
on 20 Aug 2018
@alphaladder I know, and I'm not suggesting to suppress it!! I just suggest to lower visits for the no-resign moves after both players passed (non-consecutively), which is a clear sign we entered the "no-resign endgame" and time spent on moves just appears wasted: 100 or 200 visits should be more than enough to fill the empty spaces ;-)
Friday9i
on 20 Aug 2018
Are there any plans yet for challenging Haylee again, or another professional, with one of the 40b nets and the dynamic komi branch?
jkiliani
on 20 Aug 2018
@Friday9i
Yes.very agree on your idea.
alphaladder
on 20 Aug 2018
I planned to invite her to new handicap games once dynamic komi got merged into /next.
roy7
on 20 Aug 2018
Sorry for always pushing on the same line (don't want to annoy or harass anyone) or if I fail to understand something:
@Friday9i commented:
@gcp On another subject, it seems almost 50% of the time spent by clients are on endgame moves for no resign games: these moves are necessary to avoid score errors, but is there any need to spend so much time on them?
Training data have not meta-data relative to the resign threshold used to genrate them. Thus they cannot and are not used to verify the resign threshold validity ('avoid score errors'). Only offline generated data are used to verify -r threshold validity (false positive rate).
Note: as they are quite "random", there's almost no tree reuse and 1600 visits leads to almost 1600 playouts, hence no resign games are extremely long.
They are quite random because the mcts makes the visits distribution very flat under extreme win rate values AND because t=1 is used. Games become weird way before the first one-side pass. And while moving to 800v or 400v once resign theshold is hit, doing so while still using t=1 would likely keep the games quite random. They should 'look' normal and should follow 'sound' trajectories by switching to t=0 (or a low value) once the resign threshold is hit. Most of the training data would still be quite flat but at least the games would no more be more or less random, providing meaningfull positions to learn from.
Although it's true that learning from late end game positions is important (endgame move account fir 1/3 to 1/2 of the total moves and playing good endgame is often decisive), I don't see that -r0 games should help much to discover new things in that area of the game, due to the issue of completely out of balance values flattening the search.
Moving to t=0 once resign threshold hit means relying on Dirichlet noise only to discover usefull things, i.e. less exploration. But still better than learning from random moves. Just MHO.
Whereas turning of temperature once bestscore hit resign threshold is still 'zero' approach, I believe it is: we are just paliating a deficiency of the search algorithm, nothing soecific to the game of go.
Ishinoshita
on 20 Aug 2018
@gcp
I'm also very interested in what the people who actually play go think. I sometimes wonder how many there are here :-)
If you want to get a lot of opinions from go players, I would suggest you start a thread on reddit (baduk or cbaduk) and ask what they would like to see in Leela Zero.
betterworld
on 20 Aug 2018
@bjiyxo @bubblesld
Looks like you have another 40b candidate network. Is it quantized? It seems we are gonna use quantized networks from now on.
diadorak
on 21 Aug 2018
@diodorak I check 4caca2a8 and 8993cd24, and both of them are ~90 MB. If gcp start to use quantized networks, then I will quantize it, too.
bjiyxo
on 21 Aug 2018
Are we gonna queue 530a or its quantized version for promotion match?
It might be stronger than elf v1 at visit parity!
diadorak
on 21 Aug 2018
530a or b072 which one is better
l1t1
on 21 Aug 2018
Thus they cannot and are not used to verify the resign threshold validity ('avoid score errors')
They are not used to verify our threshold, but they allow the net to discover situations where "oops this wasn't 100% winning after all", due, for example, score or counting errors in the net, or moves incorrectly pruned by the policy (for which purpose the flat distribution isn't necessarily hurting).
If you'd play LZ against a stronger net, you'd have a reasonable amount of games where both think they are 100%. You need to play out some of those games.
And again, our resign threshold is what it is BECAUSE WE KNOW this (completely incorrect scores) happen in a fair percentage of the games (as you pointed out, measured offline), and making it even lower leads to a quickly increasing amount of games where this happens and the program REINFORCES this wrong knowledge instead of discovering the error by not resigning.
gcp
on 21 Aug 2018
@gcp thanks for these precisions. Any opinion regarding the idea to lower visits each time both nets passes non-consecutively? Currently, no-resign games represent almost 50% of the time spent by clients (mostly to fill the board "not so intelligently" ;-). I know we need it, but 50% of the time is a lot!
Friday9i
on 21 Aug 2018
@gcp: To be clear, because I'm afraid there is misunderstanding here : I'm by no way suggesting any change to the resign threshold value. Or to the way it's fixed. Nor suggesting that game reversal or no incorrect score evaluation doesn't happen past the resign threshold.
Anyway, I'll stop asking questions on the ins and outs of no-resign games and randomness, because I'm more and more convinced I must be badly missing some important point on the training process, since I feel I understand your answers for themselves but not how they fit my questions/remarks. What amounts to say I don't truly understand your answers. So better not annoy you any longer and better dig by myself in the papers/code and let the important concepts sink. With more time maybe, everything may fall into place one day ;-) Thank you anyway for your replies and for your patience with newbies like me.
Ishinoshita
on 21 Aug 2018
FYI, 40b-99b6 leads 48-32 on my PC against ELFv1 with 500 visits: 60%, nice achievement!
I did not test 1600 visits as it is very slow... Hard to assess, but it may be even better for 40b at 1600 visits: that would be interesting to test it on the server :-).
Edit: tonight I'll get 200 games, it will be better statistically speaking. I also uses -m 10 for both bots in order to ensure some variability in the games.
Friday9i
on 22 Aug 2018
need 400 games, ref http://zero.sjeng.org/match-games/5b7b67d9cc3dde4a3e75ec80 0.66 at 100 games
l1t1
on 22 Aug 2018
@Ishinoshita I'm not saying what you said was wrong (it seems to have been a correction of a previous post) . If I understand correctly, you're suggesting the program speeds up (uses less visits) once the resign threshold is reached, and perhaps drops randomness. It may very well be that that is fine but it's untested complication I'm not interested in.
Generally speaking, as long as the resign threshold is fine (i.e. there's still a number of scoring errors "below"), the effort of the no-resign games is far from wasted. They will generate a huge error signal during training for all involved positions.
gcp
on 22 Aug 2018
@l1t1 Yeah, 400 games are better of course, but it takes a lot of time. If you want to make 200 of them, that'll do 400 with the 200 I do ; -).
And statistically speaking, 200 is already good, with a 1 sigma variance of ~3.5 points.
Note: on a single computer, there is less variance than for distributed matches. Indeed, for distributed matches, short games arrive on average before long games: when win rates for short vs long games are significantly different, the win rate can evolve a lot more than expected (when games are played one after the other and arrive in the same order, which is the case on a single computer).
Friday9i
on 22 Aug 2018
For 40b vs elf1, I have some personal test results:
with -v 1600 -t12 -r 18 gpu x3
66ba9e7a (54:46)
960fe0e8 (62:72)
c72877cd (40:69)
a3047139 (203:197)
with -v 1600 -t1 -r 5 gpu x1
530af2dc (229:237)
99b64745 (63:97)
I believe that elf1 is still stronger than 40b, while 40b learned some tricks to beat elf1 in the early stage of games. 530af2dc should have a good chance to get 45+% vs elf1 (which means not statistically weaker). That is why I hope to have a test match for 530af2dc vs elf1.
==================
update: forgot to paste the one a3047139
bubblesld
on 22 Aug 2018
Nice!
Contrasting results, I'll update with 200 games tonight, and I'll probably launch some games of 99b6 against Elfv1 with 1600 visits (and -r 5 instead of the -r 2 that I used for the 500 visits match)
Friday9i
on 22 Aug 2018
@bubblesld
530a looks really promising. Maybe we should just promote it :)
with -v 1600 -t1 -r 5 gpu x1, 530af2dc (229:237)
diadorak
on 22 Aug 2018
Can we let 40b and 20b generate self-play games simultaneously and train them in parallel?
One downside is that too many matches are needed. But, we could use AZ style no-gating method for the 40B networks and continue to use the 55%-gating method for the 20B networks. And from time to time we do a match between the 40B and the 20B networks to see if they are converging in strength.
diadorak
on 22 Aug 2018
Can we let 40b and 20b generate self-play games simultaneously and train them in parallel?
We can train them in parallel regardless, this has been happening for weeks.
Why would we self-play them both, what would be the point? We want the most time/strength efficient network for self-play I think, and it looks like that is 40 blocks right now. We are switching soon.
But, we could (...overly complicated proposal follows)
No.
gcp
on 22 Aug 2018
Updated results of 40b-99b64745 vs ELFv1 after 200 games with -v 500 (and -r 2 -t 2 -m 10): 40b won easily with a 64.5% winrate (3.4 point of standard deviation), ie 129 vs 71!
Quite impressive, but also a bit surprising compared to @bubblesld test "99b64745 (63:97)", where it was clearly beaten @1600 visits.
I'm wondering about a possible explanation for the difference: I used -m 10, but it may generate not so good moves for both, but Elf plays badly if too much behind? Or simply the difference in visits, but such a big difference just between 500 and 1600 visits is surprising.
Anyway, 40b is good, waiting so much for the transition :-)
Friday9i
on 22 Aug 2018
99b64745(bjiyxo 40b-167-72k quantized) was trained by v158-v167 + elf-v1.
68a8e58e(bjiyxo 40b-167a-72k quantized) was trained by v158-v167 + elf-v1 + 60k elf-v0.
We retrain 40x256 with slightly different data because we test 99b64745 vs elf-v1 =63:97. We will keep on observation and decide which one to continue training.
bjiyxo
on 23 Aug 2018
it seems that so far no 40b network can extract enough strength from all 20b games to be stronger than the 40b trained on 15b games e2be4815 (40b-157-360k), even after including all these new elf v1 games
after all, there are 400k games of 20b bewteen lz 157 and lz 167
is everything going all right with the 20b and 40b training ?
we may be missing something to understand
also, how about a 30b training ?
it would be faster to run than 40b while stronger than 20b
wonderingabout
on 23 Aug 2018
p.s : you also said @bjiyxo at https://github.com/gcp/leela-zero/issues/1681#issuecomment-411767448
that 40b-157 didnt train on any elf v1 game, and we have arround 200k elf v1 games now
it may be interesting to try to train a net based on lz 157 games, with no 20 b games, and including these 200k elf v1 games, to see how it influences the strength of 40b
wonderingabout
on 23 Aug 2018
@wonderingabout even though 40b is slower than 20b it still is much stronger. On my PC with 40b network I get like 1k playouts playing 20sec/move, with 20b network I get 2.5k playouts/move. On my tests (not big, 10 games) 40b won 9 out of 10.
It'll always be like this - how about 25b training? it would be faster to run than 30b while stronger than 20b... ;)
 nukee86
on 23 Aug 2018
nukee86
on 23 Aug 2018
@nukee86
i'm starting to wonder if the 400k games of 20b are not dragging down the strength of the 40b network, and that we dont see it because of the strength contribution of the 200k elf v1 games
this is why i'm interested to test a 40b-157-elfv1 network, that does not include any 20b game
it may also be a good opportunity to train a 30b network instead of a 40b one
remember that time when no good 20b network was able to be stronger than lz157, we still dont know the cause yet, and it may be the same one
another test can be to train a 40b-167 network without any elf v1 game, and compare it to 40b-157 (which didnt train with any elf v1 game too)
if lz 20b is indeed stronger than 15b, its 400k games should contribute to increase 40b strength, even without elf v1 games
if 40b is not stronger or even weaker, then there may be a problem, and if thats the case, the soone rit is fixed the less consequences
edit : 400k, not 900k, my bad
wonderingabout
on 23 Aug 2018
@wonderingabout
There is only less than 400k 40b available. (You have your number from Training #, which is incorrect)
40b was improving because elf1 was much stronger. e2be4815 is only a little weaker than elf1. It is not easy to improve from elf1 and 20b. However, it is improving for vs 20b or elf1 (from my tests).
bubblesld
on 23 Aug 2018
@bubblesld
my bad, i was quite hasty, it seemed to me that 20b was here for some time, so i didnt check the number of games of each 20b network, just quickly made the difference as you explained
about elf v1 vs 40b, the official 400 games tests we had were :
1) 2018-08-02 16:08 : 40b-155 vs elf v1 : 27% winrate (or 73% winrate for elf v1 at 100 games)
2) 2018-08-09 14:43 : 40b-157 vs elf v1 : 58% winrate for elf v1 at 400 games
since that time, no 40b played again against elf v1, but most of 40b networks played against 40b-157 which played against elf v1, and none of these 40b networks could be significantly stronger than 40b-157
with this data, and no 400 games test at hand, i assumed that no 40b network after 40b-157 has significantly improved against elf v1
data with less than 400 games is not reliable, see how 40b-167 had 57-58% winrate at 200 games, to end at 52-53% winrate (which means winrate from games 200 to 400 was close to 50%):
https://zero.sjeng.org/match-games/5b7c48b3cc3dde4a3e78de3b
and again, i want to highlight that 40b-157 doesnt have any elf v1 games (which is stronger) in its training like @bjiyxo said in https://github.com/gcp/leela-zero/issues/1681#issuecomment-411767448 , while all the following 40b networks included elf v1 games in their training
this is why i suggested, to try to find explanations for all this data :
1) to try to train a 40b-157 network that includes elf v1 games, unlike 40b-157-e2be4815, and also and no lz 20b games, and see how it compares to e2be, to 40b-167, or to elfv1
2) to try to train a 40b-167 network without elfv1 data, and compare it to 40b-167-currentone, or to 40b-157-e2be4815 (who doesnt have elf v1 games in its training too)
3) to test a match between elf v1 and latest 40b-167, to see if the elo difference is accurate, and if yes, that would mean the last 400k 20b games did not bring any strength improvement over 40b-157, which makes me wonder if all is all right in the training of the 20b networks. after all, no 20b network was able to be stronger than 15b ones, no matter how many times it was tried, which is a question without answer currently
wonderingabout
on 23 Aug 2018
@wonderingabout
I did paste some of my personal tests vs elf1 one day ago. Please check the reply earlier.
I do hope to see some official test matches against elf1.
bubblesld
on 23 Aug 2018
@bubblesld
i didnt see your tests, thank you for mentionning these
for the first part, the resignation limit is really high (18%), as compared to 5% in official games
it is possible that winrate was inflated or underestimated because 18% games are not totally lostfor the second part, your test with network 40b-167-530 shows a 51% winrate for elf v1 at 460 games , as compared to 58% winrate for elf v1 at 400 games against 40b-157, which seems like a significant improvement
network 40b-167-99b64's worse performance against elf v1 could be explained by an inflated strength estimation of 40b-167-99b64 against 40b-157, due to to the first 200 games having a too high winrate (58% at 200 games, as i explained earlier)
another explanation may be that 40b-157's strength is overestimated, because at the first 200 games elf v1's winrate was only 51% :
https://zero.sjeng.org/match-games/5b6c44e88ee6801594e2c718
then at 400 games it rose to 58%
if 40b-157's strength is indeed overestimated (real winrate of elf v1 might be arround 63%), its easier to assume that 40b progressively improved from 63% to 51%, due to the contribution of both elfv1 games and 20b games
this seems to make sense, but i'm still curious about how a 40b-157-elfv1 network would perform as compared to 40b-167-530, because 40b-167-530 benefited from the strength of elf v1 games in its training unlike 40b-157
its still possible that these elf v1 games can have a bigger impact on 40b-157-elfv1, because after all 7% (from the data we have : 58% to 51% winrate for elfv1 against 40b157 and 167) winrate against elf v1 after 400k 20b games and 200k elf v1 games is really not that much, i remember that between lz 152-153 and lz 157, arround 3-4% of winrate was gained against elf v0, without the help of any additional elf v0 games
wonderingabout
on 23 Aug 2018
Keep in mind that 20b and Elfv1 games are at 1600 visits, while 15b games were at 3200 visits!
So the level of play is not higher than before : 20b@1600 has a strength more or less comparable to 15b@3200, and Elfv1@1600 has a strength more or less comparable to Elfv0@3200.
Hence, it is not really a surprise that we get limited improvement of 40b from recent games of comparable strength. Once we get 40b selfplay, that should hopefully improve faster : -)
Friday9i
on 23 Aug 2018
@Friday9i
I have the similar opinion on the quality of elf game due to low visits. Therefore, I am running elf0 (3200v) vs elf1 (1600v). Currently, 17:11. I will update the result later.
update: stopped at 31:29
bubblesld
on 23 Aug 2018
@Friday9i
what you're saying makes sense
but that doesnt explain why we were not able to make a 20b network stronger than lz 157, no matter how much times we tried, the visits for these matches were capped at 3200 not 1600, but 20b's winrate was 40% at best
just like 20b networks failed to be stronger than 15b, i'm wondering if 40b-20b networks are not failing to be stronger than 40b-157 (that doesnt have any elf v1 game), without the contribution of elf v1@1600 games (but only of the lz 20b@1600 games), and wouldnt 40b-157 make better benefit from elf v1@1600 games (without 20b@1600 games)
are we not missing to understand something ?
wonderingabout
on 23 Aug 2018
Regarding the limited improvement of 20b, I think it is just a question of time and context. 15b was extremely well trained: hard to know but without help from Elfv0 games, we may have needed around 1 year of selfplay training to get to the level of LZ157...
And now 1) going down to 1600 visits, the level of selfplay is not really better 2) the additional potential of 20b is quite limited vs 15b. Hence we are de facto already relatively close to the max potential of 20b: it seems reasonable to think it will take several months for 20b to get significantly better than current level through selfplay... And that may explain we didn't succed to get 20b significantly better than 15b.
All-in-all, the coming move to 40b seems perfectly reasonable: it has much more potential, so it should improve quite rapidly through selfplay ;-), with or without help from Elf.
And for those willing a top 15b or 20b net, it should be easy to get one by training it from excellent 40b selfplay games in a few months time! It will very probably give 20b nets much better than LZ169 (not so well trained yet) and we will see if we can get significantly better than the top 15b net, LZ157 (doubtful, as it is already very well trained).
JMHO
Friday9i
on 23 Aug 2018
I think 20b is getting a bad rap. The progress graph has been steadily going up since we moved to 20b. The first 20b network(s) were weaker since we had to downgrade a bit to find a reasonably strong 20b to force the upgrade with. But we've add 11 promotions since then and had a 54% failure today. There's no way tell how far 20b can go and we'll likely never know since we're going to move to 40b very soon anyway. :)
I think 40b will start to learn better once it's eventually using only its own games and stops using ELF games which may provide conflicting training targets to the 20b self-play.
roy7
on 23 Aug 2018
Just like 15b was able to be very well trained partially with the help of elfv0 (but it still made significant improvements in the latest networks without the help of elf), and just like elfv1 which is a 20b network is able to be stronger than our current best 40b network, i think we can say that the additionnal potential of 20b is actually still very high, unlike what you're saying
what you mean though is how fast can lz 20b catch up to elf v1 level on 20b size, and is it efficient, but no one knows the answer
your point about being able to come back training our 20b network with very strong 40b data is an interesting one, though i am not sure if many people would willignly go back when they are chasing top levels, but its always a possibility
if i'm following your reasoning about well trained nets, you mean that just like 15b lz 157 was very well trained and close to maxed out and can compete against young 20b networks, similarly, elf v1 is a very well trained 20b network close to maxed out and can compete against young 40b networks ?
so, your point is when training a bigger size network, the more maxed out a net is (lz 157 for 15b, elf v1 for 20b), the more the weakest network size has chances to be stronger ? because the highest network size cant generalize and store all the lower networks detailed strength precisions, but with a lot more training this higher network size could get stronger by a more global policy ?
this explanation is plausible from a time point, because we progressively saw 20b nets being weaker and weaker against 15b nets, the first one starting to decrease was lz 20b v17 with 57% winrate as compared to 61% winrate for previous version
finally, i would like to suggest moving to 30b size, which may be faster to run and stronger than 20b, as an intermediate step
and again, i think maxing the 20b strength may have many needs, especially for weaker computers, which are not few ! but i also understand people's rush to reach higher levels
however, the higher level a bot is, the less meaningful and useful it is for us humans, like someone said in another post
thanks for your explanation, i think it makes sense now
wonderingabout
on 23 Aug 2018
We can train them in parallel regardless, this has been happening for weeks.
my two cents: such a training would _not_ be redundant with elf because of the randomcnt parameter.
 Glrr
on 23 Aug 2018
Glrr
on 23 Aug 2018
@wonderingabout
FYI, I tested 7141e697(the latested 20x256) and d351f06e(final 15x192) with -t1 -v1600 -r 5 and 20b:15b=111:89.
I'm not sure why you said 20b is weaker than 15b in same visit.
bjiyxo
on 24 Aug 2018
@bjiyxo i never said that, in fact i said that a close to maxed out 20b network like elf v1 can even compete with young 40b networks, so why couldnt it against 15b ?
what i said is that it seems when a network of X size (ex:15b for lz 157, 20b for elf v0/v1) is close to maxed out, it seems a larger but younger (at the bottom of its curve of life and potential) X+n network trained on this smaller network data (ex: 15b->20b, 20b->40b) cant extract the precise small strength refinements from the smaller network, and therefore cant be stronger than a maxed out network of smaller size
this is what we experimented when trying to train a 20b network stronger than latest 15b networks, especially stronger than lz157 (at best 40% winrate against 15b), and also what we are experimenting currently when training a 40b network to be stronger than maxed out 20b elf v1
the explanation i came up with, to explain this, is that a larger network needs to train its own global policy to grow to full potential, and cant store the "small" and detailed information of smaller size networks
this seems to make sense and would explain why we struggled so much to find a 20b to succeed to 15b at the end of 15b's life (maxing out), while at first there were many 20b stronger than 15b ones (like 20b v15, 20b v17 for example), and eventually 20b has potential to be much stronger than 15b because it is larger, just like elf v1 is so much stronger (20b too)
its just a theory though, but it makes what we experimented make sense all together
wonderingabout
on 24 Aug 2018
cant extract the precise small strength refinements from the smaller network, and therefore cant be stronger than a maxed out network of smaller size
That doesn't seem to be the case in previous network size changes. There were rapid promotions even though most of the training data was from the smaller networks.
 Mardak
on 24 Aug 2018
Mardak
on 24 Aug 2018
That doesn't seem to be the case in previous network size changes. There were rapid promotions even though most of the training data was from the smaller networks.
Which you cannot expect now with matches at 1600 visits. This takes off some % from the observed results, so the effective promotion threshold was slighty raised in 3200 terms.
tapsika
on 24 Aug 2018
This is a bit off-topic: after a little over 3 weeks of experience with @bjiyxo 's 40x256, I've begun to form the vague notion that this network size is still quite far away from approaching the full potential of a go bot, and still will be even at saturation. I'm pretty sure we're currently limited from moving much higher than this due to currently available hardware, though, huh?
Still, I'm starting to get the feeling that a larger network might actually be able to surpass AGZ rather trivially.
Incidentally, I haven't been able to beat the 40b even once yet.
Crazyeight101
on 24 Aug 2018
You may well be right, I thought about it too (with amazement): a well trained 60x384 net could probably crush AG&AZ!!!
And to go even further, in coming years, we'll probably get:
- alternative network architectures (eg global pooling) with better / much better efficiency at equivalent speed. Maybe through Deepmind work on dynamically adjusted network architectures?
- tensor calculation natively intergated in GPUs, with 10s to 100s times more power than today!
- MCTS replaced by much more efficient MCTSnets
- ...
All-in-all, I'm inclined to think that current top bots (eg AZ) on top hardware may be beaten in 5 years by a simple laptop, and possibly even by a smartphone...
Friday9i
on 24 Aug 2018
okay...so we got the result , right?
b75 is better than elf.
shall we start 40b now?
 fame872toe857
on 24 Aug 2018
fame872toe857
on 24 Aug 2018
@bjiyxo congrats on 40b beating ELF-v1!
john45678
on 24 Aug 2018
@Mardak
previous networks were not maxed out as much as 15b and 20b elf v1 are
i remember that someone trained a 128x10 (or x6 ?) block and made it far stronger than where leela zero stopped for this network size
i was talking about maxed out networks at X size
again, its just a theory though, and 40b was able to finally be stronger than 20b elf v1
however, i think comparing 20b to 40b is like comparing 20b to 10 blocks, or 15b to 6 blocks
there are not one but many "class" differences between these, so its possible that the raw power of a larger net made up for most of the strength, and not the lower sized nets games
40b should be compared to a maxed out 30b or something to follow my explanation, and since 40b struggles to be stronger than maxed out 20b, i highly doubt it would be possible to train a young 40b network to be stronger than a 30b maxed out one
to make a parallel, its like asking a 9d player to learn from 10k games, he cant, but a 10k player can learn at least partly from 9d games, even though he wont be 9d, his strength can increase faster and further
so, all in all, it may indeed be the time to move to a larger size if you want faster improvements and performance, but if you like to experiment and are curious like me, you can rather max out every block size (20b then 30b then 40b), for utility, because 20b is doing fine recently
wonderingabout
on 24 Aug 2018
@wonderingabout What is your test result between 40b and 30b? When we discuss the issue, we hope to see the data instead of "maybe." In fact, this is almost no help.
 theleapfaith
on 25 Aug 2018
theleapfaith
on 25 Aug 2018
@theleapfaith
in fact, i didnt train a 30b network, so unfortunately i cant provide data
but this may give ideas to other people
wonderingabout
on 25 Aug 2018
@wonderingabout We actually don't object to moving to other networks. If a network proves that it is powerful enough, we would love to switch to it. Now 40b proves its power, so we tend to 40b. You can train a 30b, and if it is strong, there will be a lot of people supporting you.
theleapfaith
on 25 Aug 2018
@theleapfaith i understand, but the training of 40b networks is already quite advanced, and most important reason, to train a 30b network on my current rig (r5 2400g) would take several weeks at least, but some people reading my idea may want to try it in my stead
wonderingabout
on 25 Aug 2018
We should use data to persuade others rather than wishful thinking without any real work.
alphaladder
on 25 Aug 2018
@alphaladder
i was not trying to persuade though, just suggesting ideas that i think are interesting to be tested
again, some people who read ideas can find them interesting and they may have more power to try them
giving feedback is as important as pushing forward
wonderingabout
on 25 Aug 2018
In this cycle, we have v163-169 + elf1 as training data. Furthermore, we experimented with the modified loss function (policy loss x5). The reason to do this is that we found that the optimization process usually reduces mse, but not policy.
In our small sample size test, the weight 88k (158c107e) has about 60% against e2be4815. However, it becomes weaker against elf1. We found that the winning rate vs elf1 is now only 34/93 when playing white. The biggest difference is that It loses the ability to beat elf1 early when playing white. We then found that now 40b will play star point 星位 (ˋ4,4) instead of komoku 小目 (4,3) in its 2nd move (4th overall). We hope that it will learn back some trick for opening after more training.
We are testing it in official website. Let's see if it is the case as we observed.
bubblesld
on 1 Sep 2018
all in all, the best way to compare leela zero 40b's strength over the time and see if it actually improves, is certainly not to see its winrate improvements against elf v1 as compared to previous 40b results, but rather to have a common 40b network play against the new 40b ones, which is so far e2be4815 (40b-157)
wonderingabout
on 1 Sep 2018
Currently, training games are not better than the ones used for e2be (because 20b and Elfv1 @1600 visits are about as strong as 15b and Elfv0 @3200 visits), hence it's not really a surprise that new 40b nets are not significantly stronger than e2be.
On the opposite, when we'll switch to 40b selfplay games, these games will be stronger than current 20b selfplay games, so we should get frequent 40b improvements ; -).
And to replace a % of stronger training games from Elfv1, we could begin with 10% of Elfv1@3200 visits (or maybe 6400 visits), then when 40b is stronger, we could make 10% of selfplay games (with -r 5 only) with 40b @3200 or 6400 visits.
BTW, any news regarding when we switch to 40b?
Friday9i
on 1 Sep 2018
@Friday9i
they discussed it in #1733 , @roy7 said this https://github.com/gcp/leela-zero/issues/1733#issuecomment-417729119
also, about the elf v1 talk, i understand your point, but it is clear that due to its sharp and highly volatile winrate, elf v1 is not a reliable tool to estimate 40b network strength and improvements, as i said earlier
and as you said, comparing it to e2be, actually little progress has been made in the 40b training, the best 40b network being only 53% stronger than e2be at 400 games
however, as we also said earlier, training leela zero 20b has a utility (low computers, high handi, etc...) and a scientific interest (learning more about the development of a network at X size e.g:20b, the effect of elfv1 and why not 40b games on strength (after all we used 20b elf games for 15b training), the max capacity and strength, etc...)
wonderingabout
on 1 Sep 2018
@wondering Yeah thanks, I saw the "once gcp is back", but when is it ; -)?
And I'm not suggesting to go back to e2be, the new ones are probably a bit better, and it's useful to train 20b, no doubt (but I think migrating to 40b is more efficient, even if we want a top 20b: in a few months, we will be in a position to train a top 20b from 40b selfplay games ; -)
Friday9i
on 1 Sep 2018
@Friday9i
yes, neither do i, i also think the new 40b are slighlty better than e2be (40b-157), but as compared to e2be, little improvements have been made in the 40b training, it is just what i meant
about training a top 20b from strong 40b games, it looks interesting and may indeed be much faster (just like 20b elf helped a lot our 15b leela zero), but will people who chase after alphago and max strength as fast as possible, really be willing to go back from 40b to 20b ?
wonderingabout
on 1 Sep 2018

Both of them showed they were 10.05M. Is there any problem here? @roy7 @gcp
bjiyxo
on 9 Sep 2018
I remember those condition occurs at 20b weights training, gcp should also remember it
https://github.com/gcp/leela-zero/issues/1742#issuecomment-414151092
l1t1
on 9 Sep 2018
No that is correct. The number of games is the same for about 5 different networks that are tested at different training steps, and then new games are used for future training which increments that number.
roy7
on 9 Sep 2018
there are already 5 weights between 7e4ce468 and 84edc0e @roy7
l1t1
on 9 Sep 2018
Oh I see the point now. The next set didn't increase the count, @gcp.
roy7
on 9 Sep 2018
will you setup a test match of lz175 vs elfv1?
l1t1
on 10 Sep 2018
This seems to happen rather regularly now, does this mean that no new games were sampled or just that the number of games reported to the web interface is wrong?
jkiliani
on 10 Sep 2018
@l1t1 I think a test match vs elfv1 after 5 promotion of 40b will be better.
bjiyxo
on 10 Sep 2018
@bjiyxo 40b has much more resources than elfv1 in match games, so the comparison isn't really fair.
MartinDevelopment
on 10 Sep 2018
I don't think fairness is the point, but rather to test if future 40b nets can conclusively leave ELF behind at equal nodes, now that they're approximately even.
jkiliani
on 10 Sep 2018
If anyone would like to explore this deeper or compare the search results/priors vs our old strongest 15b network, here's a ladder the 40b misplayed.
https://online-go.com/game/14339777
kuba from discord looked into it:
the ladder issue seems to be the same in both nets.
Both 15b and current 40b don't see the escape by white for a very long time.
they both find it after roughly the same time
but 40b needs fewer visits
https://gyazo.com/780a77d9638b77a5b701ca890bb9e9a7
jiu from discord tried it the Leela version (https://github.com/Ttl/leela-zero/tree/liberty_planes_se2) that does ladders:
With ladder input planes it finds the escaping move instantly as expected:
O16 -> 757 (V: 73.09%) (N: 38.95%) PV: O16 R14 N16 N17 M16 M17 P14 Q14 O15 P13 Q15 R15 O13 P12 Q13 S13
R15 -> 39 (V: 45.80%) (N: 50.11%) PV: R15 O16 R14 F4 N6 L5 L6 K6
N6 -> 3 (V: 44.51%) (N: 5.07%) PV: N6 R14 O16
roy7
on 10 Sep 2018
@l1t1 and who is interested,
From my small sample test, with -t 1 -v 1600 -r 5, v175 leads elf1 64 to 61. I would say that they are still of the same strength.
--
update: v175 won 84:75 over elf1 (I am running other tests now)
bubblesld
on 10 Sep 2018
For the weight 40b-174-96k, it is trained up to v172 for first 80k, then 16k more with adding roughtly 30-40k 40b self-play release yesterday.
One biggest difference is that we experiented with different lost function. Original lost is policy + mse x4 +reg, the current weight is trained with lost = policy x4 +mse x4 +reg. We found that the policy loss is usually not reduced by training, therefore, we are trying to experient with a loss more focusing on policy.
In my personal test on my machine, the new 40b has 91:55 over v175. Let's see how it goes in the official test.
bubblesld
on 12 Sep 2018
174 96k seems very strong as so far, the suitable parameter is very diffcult to find
l1t1
on 12 Sep 2018
Yes, 40b-174-96k is promoted.
bjiyxo
on 12 Sep 2018
the first seven games are lucky or not? http://zero.sjeng.org/match-games/5b98a1d8516d4d37737da13e
l1t1
on 12 Sep 2018
the games after promote is for compute elo?
dabff367 VS b0a601d9
135 : 80
l1t1
on 12 Sep 2018
Congratulations on training such a strong net! This confirms that #1480 is successful for Leela Zero as well, presumably by improving the quality of the value head as it did for the short experiment in Leela Chess.
jkiliani
on 12 Sep 2018
Problem is GCP's net will maybe have a hard time passing gating against this one.
herazul
on 12 Sep 2018
What would be interesting is training the elf net with this, it would give interesting results !
herazul
on 12 Sep 2018
@bubblesld Great job! Can you train a 15x192 network using the new loss function to see if it's significantly stronger than LZ 157? The performance hike of LZ176 could be because there is plenty of room for improvement for 40b. It seems gcp's 128k network in this batch is even stronger.
diadorak
on 12 Sep 2018
@diadorak I planned to train on 20b after the training of 40b being on track. I can try 15b as well.
The motivation for a different LOSS function is from the situation present in the following figure
The left one is by LZ-40b, and the right one is by elf1. While the picked one is the same, the estimated winning rates are very different. This actually happens very often. Then how should the algorithm learning from games by 40b and elf1 if the goal is to minimize mse?
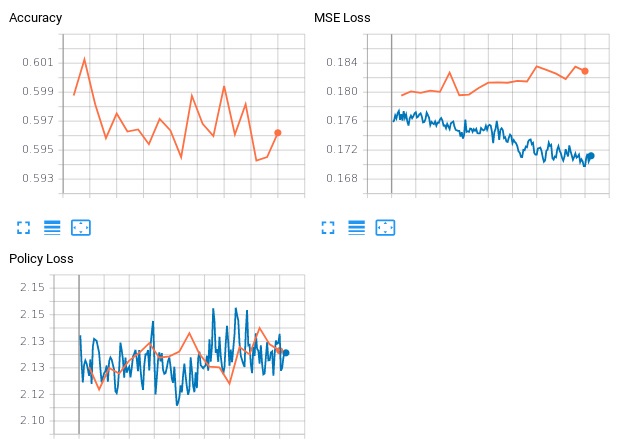
The figure above is a typical one from training with the default setting. You can see that the train mse is reduced, but not the policy. I guess that the original idea is trying to minimize mse while keeping policy loss in control. This is ok if only traing from self-games generated by some similar weights. However, in our situation, since the estimated winning rates are too different, it may be better to reduce policy loss while keeping mse in control.
bubblesld
on 13 Sep 2018
Good example why I'm eager to move to all 40b data and no longer use ELF data. It's always worried me a bit that we're trying to learn from conflicting training data.
roy7
on 13 Sep 2018
@bubblesld The MSE only depends on the game result, and on the winrate output of the LZ network you are training; it doesn't depend on the winrate output of the ELF network (but that affected tree search for sure; if the winrates of different moves are too different the visit counts will be very focused on the chosen move, but that rather affects policy training).
Curious that LZ thinks black is losing while ELF thinks it's very likely winning, but keep in mind that ELF's 50-50 training strategy has the effect of inflating black's winrate.
 alreadydone
on 13 Sep 2018
alreadydone
on 13 Sep 2018
there are 3 bjiyxo weights in all 4 promoted, can the offical training use the formula of bjiyxo?
l1t1
on 16 Sep 2018
Are these nets trained with the same data ? Or do they use more 40b selfplay games ?
Glrr
on 16 Sep 2018
Our nets is slightly behind the official net in terms of data.
bjiyxo
on 16 Sep 2018
@roy7 Based on the match data of 40b, shall we stop the match in 32k-96k ?
alphaladder
on 16 Sep 2018
32k-96k networks have promoted in the past.
roy7
on 16 Sep 2018
@bjiyxo 5 promoted, can you test 178 vs elfv1
l1t1
on 20 Sep 2018
Test added.
bjiyxo
on 20 Sep 2018
178 is stronger at short games but still weaker at long games.
very similar as http://zero.sjeng.org/match-games/5b8e45bc1be45d7cad858929
l1t1
on 20 Sep 2018
ea2132804b5684c1e662bd91b9f16111 | 58d1222a | B+4.5 | 349 | 12.6 minutes
-- | -- | -- | -- | --
l1t1
on 20 Sep 2018
I still feel like "stronger at short games but still weaker at long games" is kinda misleading. I'd say ELF is quicker to resign when losing (since the win rates are much more extreme than Leela). If you take many of those short games and reverse the players, Leela would keep playing longer since her win rate might only be say 20% instead of ELF's 5%.
roy7
on 20 Sep 2018
CloudyGo generated an updated eval graph for us.
roy7
on 20 Sep 2018
@roy7 I believe that it is not only due to early resignation. From my limited experience to replay game by lizzie, I do feel that 40b is stronger than elf1 in the early stage of games, but weaker in the later stage. If I have time later (or if someone one has time to do it), I will replay those 40b-lost games by lizzie with elf1, and record the first move that elf1 thinks the w.r. is smaller than 5%. Then, that will be a fair comparison whether 40b has a higher w.r. in short game.
bubblesld
on 20 Sep 2018
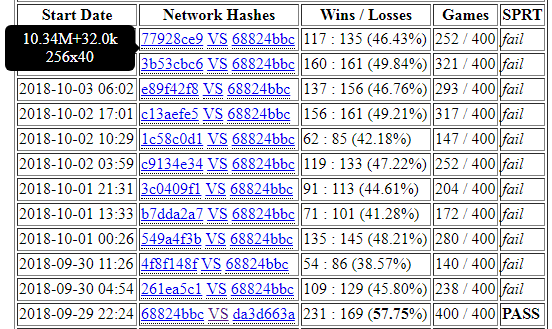
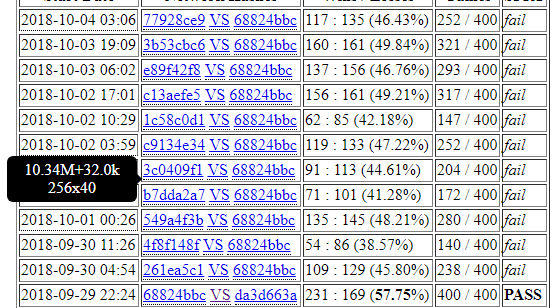
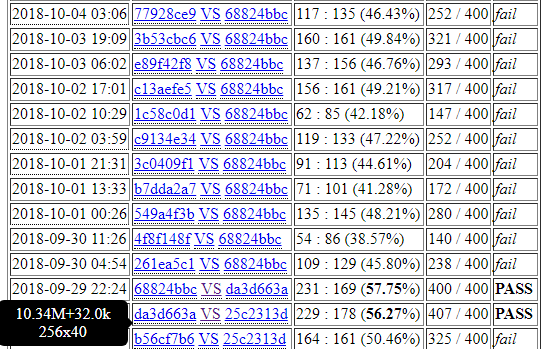
Straight 3 rounds 10.34M. Are you experimenting with new parameters? @gcp
bjiyxo
on 4 Oct 2018
The internet connection to the training server was having issues so it couldn't download newer games.
roy7
on 8 Oct 2018
The latest 40b remains policy x4, and is trained by 400k 40x256 games and 250k elf-v1 games. The learning rate is 0.0001.
We tested 100 games on our own computer vs 68d7c8fc(v182) with v1600 and the result is 59:41.
bjiyxo
on 20 Oct 2018
it seems that training with mix of elf and lz is useful
but lz 183 is stronger than elfv1 now,
l1t1
on 20 Oct 2018
then, should we put back all elf v1 games in the next 40b training cycle @gcp ?
what if networks suddenly get stronger after we do that
it's also interesting to note that as compared to the test of :
2018-09-20 05:40 | 58d1222a VS d13c4099 | 182 : 180 (50.28%) | 362 / 400 | fail
-- | -- | -- | -- | --
VS
2018-10-20 05:30 | a53cd929 VS d13c4099 | 227 : 175 (56.47%) | 402 / 400 | PASS
-- | -- | -- | -- | --
it's day and night ! @bjiyxo
in just one month !
this month seemed to show small improvements (little promotions), but it seems actually like leela zero learnt a lot since last month
wonderingabout
on 20 Oct 2018
Wait, is it possible that the Elf games actually held the network back, then? What if you trained a full network on just 40x256 games then had it play against Elf?
anonymousAwesome
on 21 Oct 2018
@anonymousAwesome
i'd say it's more like a debt/a drug
ELFv1 allowed leela zero to improve faster than it should have naturally, which may mean many things, among which possibly an inbalanced growth
so leela zero would need to grow on all the other areas it lacked to be globally at the higher level ELFv1 made it go to
and it seems if @bjiyxo 's guess is correct, it may just mean that leela zero still needs ELF v1 games in its training
wonderingabout
on 21 Oct 2018
so leela zero would need to grow on all the other areas it lacked to be globally at the higher level ELFv1 made it go to
There is zero evidence that this is the case.
The only things we know for certain:
1) The last time a bjiyxo-trained network fought Elfv1 it had a roughly 50% winrate.
2) LZ grew stronger afterwards.
3) A net trained by bjiyxo with more recent LZ games plus Elf games won with a winrate of roughly 56%.
That's it. That's all we know. If bjiyxo trained a net only on LZ games, we don't know if the winrate vs Elfv1 would have been better or worse than the outcome we got.
and it seems if @bjiyxo 's guess is correct
As far as I can tell, Bjiyxo didn't make any guesses. He just did the training and posted the results.
anonymousAwesome
on 22 Oct 2018
FYI: we tried two different settings in the previous cycle (when the self-play games only updated to v181, no v182), one is all 40b, and the other is 250k elf1 + 400k 40b. The all 40b one is weaker. Therefore, we tried the setting with elf1 first in this cycle (with v182 self-play), and the 64k one (now v183) seems pretty good.
bubblesld
on 22 Oct 2018
Without elf games, fc9 will be also promoted.Anyway, we need another 500k games after the original 58d.
alphaladder
on 22 Oct 2018
@bjiyxo : did you try to train 40b nets without Elf games, and if yes, when? Thanks a lot
Friday9i
on 12 Nov 2018
We tried it a month ago, but it looked worse than the one with ELF games. We're going to train without ELF games again now.
bjiyxo
on 12 Nov 2018
Thanks a lot for your answer @bjiyxo.
Just to be sure, was it already with 40b ("a month ago" was around LZ182) or still with 20b?
And congrats once again for the nice nets you managed to train, I'm now waiting so much for the next ones without Elf ;-)!
Friday9i
on 12 Nov 2018
An importance may be slowly reducing the number of ELF games that are included instead of all or none. It may be too much of a change at once for the network to adapt to two different play styles, so slowly going from 2 nets to only LZ self play may help improve the strength. This hypothesis is supported by the fact we saw a sharp rise in ELO in LZ when some ELF games were withdrawn recently.
 jillybob
on 13 Nov 2018
jillybob
on 13 Nov 2018
Thanks @bjiyxo, and I also noticed the earlier post from @bubblesld 3 weeks ago: you tried a 40b net trained without ELF games, and it wasn't successful at the time ;-(.
It seems we can draw 2 possible conclusions from that test: 1) the absence of ELF games was a problem at the time, or 2) you were unlucky with the single net trained without ELF.
Unless you trained several and they were all bad?
New question: was the last "@bjiyxo net" 5c650ef2 trained with or without ELF?
And btw, are the 10.86M nets already trained without ELF, or are they still trained with ~25% of ELF games?
Thanks a lot
Friday9i
on 14 Nov 2018
It seems we can draw 2 possible conclusions from that test: 1) the absence of ELF games was a problem at the time, or 2) you were unlucky with the single net trained without ELF.
Unless you trained several and they were all bad?
We had trained two networks simultaneously, one with ELF and one without ELF for several weeks.
All nets without ELF seemed bad at that time.
New question: was the last "@bjiyxo net" 5c650ef2 trained with or without ELF?
5c650ef2 was trained without ELF.
And btw, are the 10.86M nets already trained without ELF, or are they still trained with ~25% of ELF
games?
I'm not sure how many percentage are there in 10.86M. @gcp may answer it.
bjiyxo
on 14 Nov 2018
Nice, thx!
So we get a net trained without Elf games, 5c65, which is as strong as the strongest one trained with Elf: very encouraging. Congrats to you!
Friday9i
on 14 Nov 2018
LZ195 is a killer, wonderful job @bjiyxo !!!
It seems to be better than Elfv1 on time parity, that's an amazing achievement (if confirmed by more tests)
Friday9i
on 14 Dec 2018
if it includes elf games, then it is more likely to perform better against elf : probably a confusing factor
i dont doubt that this new network is stronger, but the current numbers are probably misleading
wonderingabout
on 14 Dec 2018
Fwiw, I tested LZ192/3 on time parity with high visits (500k-ish) against elfv1. They were better than elfv1, though the games were horribly tense (the winrates fluctuated a lot). I guess at that point, it converges to be equivalent to same visits counts.
 nerai
on 16 Dec 2018
nerai
on 16 Dec 2018
@neral "I guess at that point, it converges to be equivalent to same visits counts."
Could you clarify, what you mean?
Marcin1960
on 16 Dec 2018
@Marcin1960 That was just a side remark, nothing of importance, but I'll explain my thoughts.
First of all, in a match of 40b LZ vs 20b ELF, the ELF net is of worse quality but has a speed advantage, so in an equivalent time match, the result is not obvious. On the other hand, with equal visits, 40b clearly has an advantage. This fact has been established recently.
Given that, my understanding is that at some point, reading more nodes quickly becomes worth relatively less than reading the right nodes slowly. In other words, at some point it will take more than linearly more reading to overcome poorer net quality. So effectively, the speed advantage is gone, and the match result behavior becomes more similar to what could be observed with equal visits instead of equal time (i.e. 40b advantage).
This was also tested in #1914, though it seems less clear in this particular setup.
nerai
on 16 Dec 2018
With the latest 8b28 net, i can report a much higher probability of wins for petgo3 vs golois (which uses elf).
That lz is stronger than elf we know allready that... But now not only with time parity, but also with slower hardware (Here GTX1060 vs GTX1980 as far as i know ...).
http://kgs.gosquares.net/index.rhtml.en?id=petgo3&id2=golois&ty=2018&tm=10
 petgo3
on 16 Dec 2018
petgo3
on 16 Dec 2018
@petgo3 Do you have some insight on Golois ? His author has not put on KGS bot profile as many details as for previous Golois6. Now just says "Golois in Elf framework", which sounds to me more like "Elf (program) with Golois's weights" than the contrary. Like "LZ with Elf weights"....
Ishinoshita
on 16 Dec 2018
@Ishinoshita "more like "Elf (program) with Golois's weights" than the contrary. Like "LZ with Elf weights"...."
You don't mean ""Golois's (program) with Elf weights"?
Marcin1960
on 16 Dec 2018
You can ask thc on kgs. He is the owner and dev of golois.
petgo3
on 16 Dec 2018
@petgo3 I let him a message on KGS a while ago but did not get an answer. Hence my question to you, as you both may have chatted as owners of the two strongest most regular bots on KGS.
@Marcin1960 "Golois in Elf framework". Framework sounds more like 'engine', 'program', etc... than 'weights'. Hence my doubt and question.
Ishinoshita
on 16 Dec 2018
@Ishinoshita : Well I had some conversation with thc. He owns also account elf and this runs with GTX1080. But I have no further insight to golois, but i tend to agreee, that elf is the engine (or some parts) and may be there are some golois weights. The pure golois version before were able to handle handicap, the actual is not, but this also gives no sigificant hints about the actual configuation.
petgo3
on 16 Dec 2018
@Ishinoshita @petgo3 In my experience virtually all moves of Golois can be predicted using the ELF weights (but not LZ weights, old or new) and similar hardware and time. It also corresponds very well regarding its internal time management (when to play forced moves vs when to think about selecting from many options). I would be very surprised if it did not use ELF or very similar weights. But of course it would be best to ask him specifically... :)
nerai
on 17 Dec 2018
I did a test with v195 (1600v) vs ELFv1 (3200v). From small sample size of 50, v195 only won 15 of them.
bubblesld
on 17 Dec 2018
Related issues
l1t1
·
3Comments
 StanTraykov
·
4Comments
StanTraykov
·
4Comments
 Ttl
·
4Comments
Ttl
·
4Comments
 jslechasseur
·
4Comments
l1t1
·
4Comments
jslechasseur
·
4Comments
l1t1
·
4Comments
Most helpful comment
It looks like the 40b is very close to the best ELF now.
I said before I don't think we need to max out 20b as there's already ELF in that size that people can use (or just any other size!). So it makes a lot of sense to jump to 40b. The gain in Elo is much higher than the x2 speed loss.
I am catching up on uploading data now. I assume it will give an updated 40b another boost. By the time that network is up I think we can queue it for promotion?