Kops: Calico cpu request is insufficient on a heavily utilized node causing crashback loop
**1. What kops version are you running? 1.14.0
**2. What Kubernetes version are you running? v1.14.6
3. What cloud provider are you using? AWS
4. What commands did you run? What is the simplest way to reproduce this issue? m4.large node that is 100% utilized
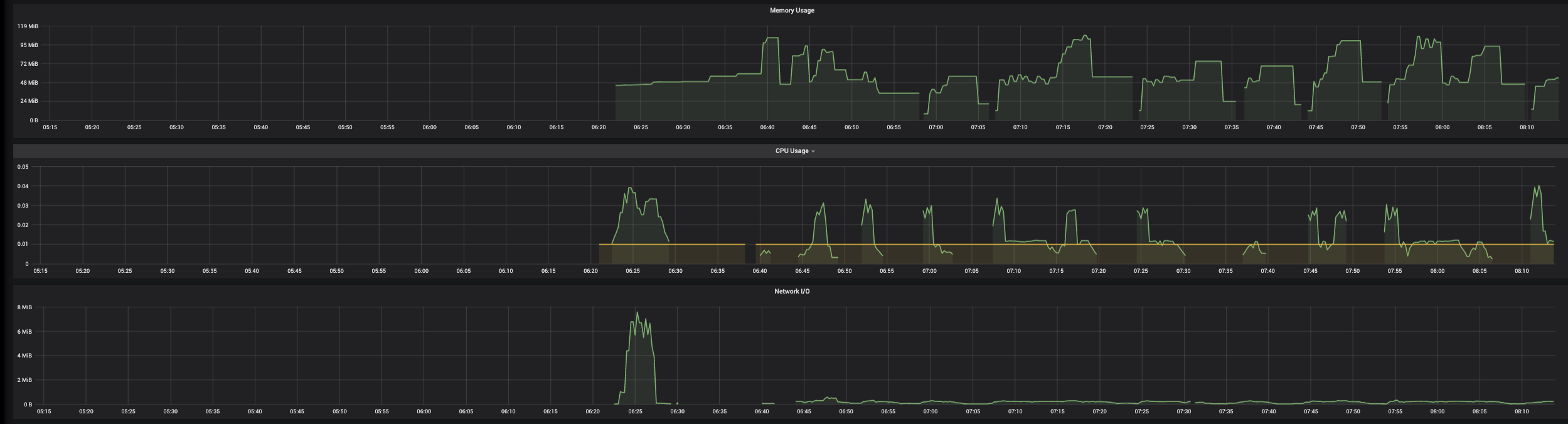
5. What happened after the commands executed? Calico fails liveness probes causing it to go into a crashback loop
6. What did you expect to happen? Calico to keep running
I understand why the calico requests were reduced, but it will likely be helpful to make it configurable so it can be overridden when someone is using a large node type.
Warning Unhealthy 87m (x15 over 96m) kubelet, ip-10-40-11-0.us-west-2.compute.internal Readiness probe failed: calico/node is not ready: felix is not ready: Get http://localhost:9099/readiness: dial tcp [::1]:9099: connect: connection refused
Normal Started 72m (x11 over 112m) kubelet, ip-10-40-11-0.us-west-2.compute.internal Started container calico-node
Warning Unhealthy 57m (x10 over 99m) kubelet, ip-10-40-11-0.us-west-2.compute.internal Readiness probe failed: calico/node is not ready: felix is not ready: readiness probe reporting 503
Warning Unhealthy 27m (x40 over 100m) kubelet, ip-10-40-11-0.us-west-2.compute.internal Liveness probe failed: HTTP probe failed with statuscode: 503
Warning Unhealthy 17m (x59 over 96m) kubelet, ip-10-40-11-0.us-west-2.compute.internal Liveness probe failed: Get http://localhost:9099/liveness: dial tcp 127.0.0.1:9099: connect: connection refused
Warning Unhealthy 12m (x105 over 100m) kubelet, ip-10-40-11-0.us-west-2.compute.internal Liveness probe failed: Get http://localhost:9099/liveness: net/http: request canceled (Client.Timeout exceeded while awaiting headers)
Warning BackOff 7m52s (x166 over 84m) kubelet, ip-10-40-11-0.us-west-2.compute.internal Back-off restarting failed container
Warning Unhealthy 2m52s (x32 over 87m) kubelet, ip-10-40-11-0.us-west-2.compute.internal (combined from similar events): Readiness probe failed: calico/node is not ready: BIRD is not ready: BGP not established with 10.40.5.1942019-11-15 16:10:38.576 [INFO][167] readiness.go 88: Number of node(s) with BGP peering established = 15
 sstarcher
sstarcher
All 12 comments
sstarcher
on 15 Nov 2019
In my humble opinion this should be made configurable.
We can't possibly find a value which works for all types of nodes.
 joekohlsdorf
on 19 Nov 2019
joekohlsdorf
on 19 Nov 2019
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
 fejta-bot
on 17 Feb 2020
fejta-bot
on 17 Feb 2020
Stale issues rot after 30d of inactivity.
Mark the issue as fresh with /remove-lifecycle rotten.
Rotten issues close after an additional 30d of inactivity.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle rotten
fejta-bot
on 18 Mar 2020
Rotten issues close after 30d of inactivity.
Reopen the issue with /reopen.
Mark the issue as fresh with /remove-lifecycle rotten.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/close
fejta-bot
on 17 Apr 2020
@fejta-bot: Closing this issue.
In response to this:
Rotten issues close after 30d of inactivity.
Reopen the issue with/reopen.
Mark the issue as fresh with/remove-lifecycle rotten.Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/close
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
 k8s-ci-robot
on 17 Apr 2020
k8s-ci-robot
on 17 Apr 2020
/reopen
 etwillbefine
on 18 Apr 2020
etwillbefine
on 18 Apr 2020
@etwillbefine: You can't reopen an issue/PR unless you authored it or you are a collaborator.
In response to this:
/reopen
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
k8s-ci-robot
on 18 Apr 2020
Hey there, @rifelpet!
I'd like to take a stab at this issue if possible.
From poking around the code a little bit, what I think of doing is:
- Add a new variable called
CpuRequestsunderCalicoNetworkingSpec(https://github.com/kubernetes/kops/blob/master/pkg/apis/kops/networking.go#L102) andCanalNetworkingSpec(https://github.com/kubernetes/kops/blob/master/pkg/apis/kops/networking.go#L136). - Update the templates for 1.12 and 1.16 in here https://github.com/kubernetes/kops/tree/master/upup/models/cloudup/resources/addons/networking.projectcalico.org and here https://github.com/kubernetes/kops/tree/master/upup/models/cloudup/resources/addons/networking.projectcalico.org.canal so that requests will pull the variable value if it was specified, otherwise default to the current values.
Does that sound good? If so- feel free to assign it to me and I'll get to work on it ASAP.
Thanks!
 MoShitrit
on 24 Apr 2020
MoShitrit
on 24 Apr 2020
Hi @MoShitrit yes feel free to tackle this.
Weave would be a good reference for resource related fields. Feel free to mimic those in CalicoNetworkingSpec and CanalNetworkingSpec. Specifically having the field named CPURequest and of type *resource.Quantity.
Run make apimachinery crds after adding the fields to pkg/apis/kops/networking.go, and reference the fields in the template as you mentioned. You may need to run ./hack/updated-expected.sh to update some manifest hashes used in tests but I'm not positive.
Go ahead and give it a shot and let me know if you run into any issues. Thanks!
 rifelpet
on 24 Apr 2020
rifelpet
on 24 Apr 2020
@rifelpet That's super helpful! Thanks for referring me to that.
Yeah I'd love to give it a try, probably over the weekend.
I'll let you know if I need any help, thanks so much!
MoShitrit
on 24 Apr 2020
/assign
MoShitrit
on 24 Apr 2020
Related issues
 Caskia
·
3Comments
Caskia
·
3Comments
 justinsb
·
4Comments
justinsb
·
4Comments
 joshbranham
·
3Comments
joshbranham
·
3Comments
 georgebuckerfield
·
4Comments
georgebuckerfield
·
4Comments
 chrislovecnm
·
3Comments
chrislovecnm
·
3Comments
Most helpful comment
In my humble opinion this should be made configurable.
We can't possibly find a value which works for all types of nodes.