Kops: SSL handshake time issue on AWS with kops 1.6.1 and weave
We installed a new cluster on AWS using kops 1.6.1 and weave (and last stable kubernetes/ingress-nginx).
Everything seemed to work. However, when checking the overall response times of everything running on the cluster, we noticed something was wrong.
One good example is our simple HealthCheck that gets monitored by AWS. We found that the SSL handshake time was constantly jumpy at a very high level.
We also reproduced this behavior with a simple timed curl. Results varied between 1000 and 6000ms only for the handshake.
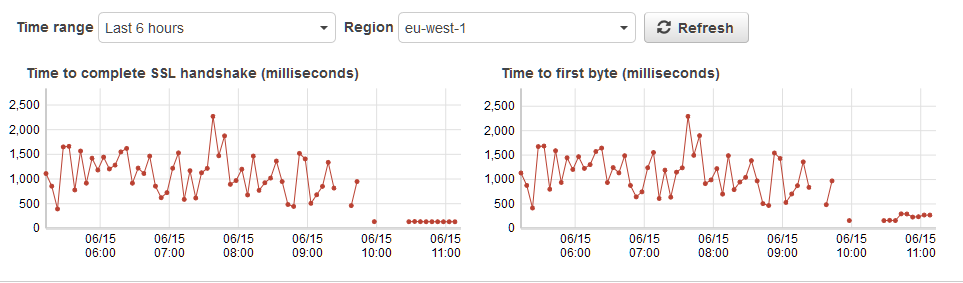
We then removed the cluster and built a new one with Kops 1.6.0 (everything else stayed the same). The timings are now back to normal. (the later dots in the image)
Our assumption is, that something went wrong on the changes to 1.6.1. There was the releasenote-line:
Make Weave MTU configurable and configure jumbo frame support for new clusters on AWS (thanks @jordanjennings)
Maybe it is related? Maybe a default-config that needs to be changed?
We would appreciate someone looking into this.
 DocValerian
DocValerian
All 4 comments
@DocValerian Can you provide more info on this HealthCheck that you've configured?
Also, could you try using kops 1.6.1 and removing the Weave mtu settings it puts by default to try to isolate the issue to that change? After running kops create cluster do kops edit cluster and change:
networking:
weave:
mtu: 8912
to
networking:
weave: {}
Then do the kops update cluster --yes to create everything as normal.
 jordanjennings
on 15 Jun 2017
jordanjennings
on 15 Jun 2017
Hi @jordanjennings,
thank you for the quick reply. I tried the edit and deployed the cluster.
The result is unchanged. (Yellow line is our productive kops1.6.0 build, red line the kops1.6.1 one with mtu removed)
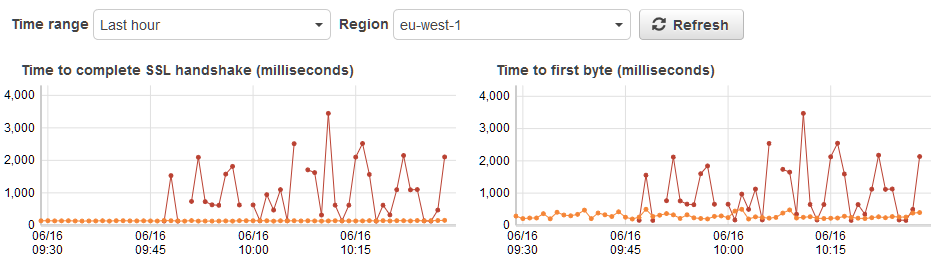
HOWEVER, when i looked at the weave-npc logfile, i noticed (on kops1.6.1 build) it is spamming warnings like:
WARN: 2017/06/16 07:48:10.697876 TCP connection from <AWS-ELB>:47143 to <NGINX-ingress>:80 blocked by Weave NPC.
WARN: 2017/06/16 07:48:10.697894 TCP connection from <AWS-ELB>:47153 to <NGINX-ingress>:80 blocked by Weave NPC.
This looks like something that could make requests take a while before actually reaching any service.
DocValerian
on 16 Jun 2017
@DocValerian OK, glad to know the MTU wasn't screwing things up at least :)
One additional thing to try: update the weave DaemonSet and change the version of both weave containers to 1.9.8. I think after updating you'll have to delete the weave pods, and then restart all nodes just to recycle everything. There were some issues with Weave NPC in 1.9.7, which were fixed in 1.9.8 (which just came out yesterday).
I'm testing out the upgrade to 1.9.8 right now and will be sending a pull request to get that integrated here once I'm done (probably in a couple hours).
jordanjennings
on 16 Jun 2017
Hi @jordanjennings,
great job, we just deployed with 1.6.2 and the issues are resolved.
Handshake timings are back to normal.
...closed
DocValerian
on 21 Jun 2017
Related issues
 justinsb
·
4Comments
justinsb
·
4Comments
 lnformer
·
3Comments
lnformer
·
3Comments
 austinmoore-
·
5Comments
austinmoore-
·
5Comments
 mikejoh
·
3Comments
mikejoh
·
3Comments
 RXminuS
·
5Comments
RXminuS
·
5Comments