The idea is that, for a given query, to build a bell curve.
The X-axis would be the metric value (time) and Y-axis is relative frequency (or reversed if that makes more sense).
I'm not looking for a perfect bell curve, but two queries on the same filter (one for percentiles and one with a range aggregation based on the histogram) could do it nicely.
 pickypg
pickypg
All 7 comments
This would be a really powerful feature! I'd love to be able to see what my response time distribution would be.
It would be even better if you could overlay multiple queries (so compare the performance distribution curve of one data center vs another for example)
 jc-ns
on 21 Jan 2015
jc-ns
on 21 Jan 2015
How would this be different to using a bar chart with time-based ranges on the X-Axis and 'count of documents' on the Y-Axis?
 AlexIoannides
on 21 Jan 2015
AlexIoannides
on 21 Jan 2015
It would always be a bell curve, but the x axis scale would vary with what the percentiles were.
Also, this is not for count, but for the evaluation of a metric.
jc-ns
on 12 Feb 2015
The "Bell Curve" AKA probability density function differs from a Count aggregate over Histogram buckets, because the Y axis shows relative frequencies instead of absolute counts, e.g.:
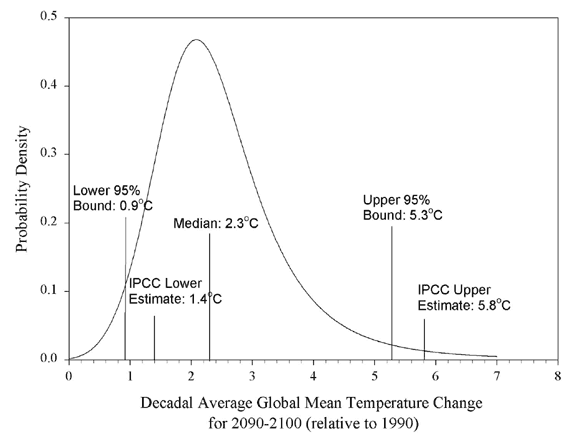 .
.
This is very useful if you need to compare distributions via Split Lines, but the absolute counts are orders of magnitude different, so one series squashes the other:

The log scale often is not enough.
 dagguh
on 21 May 2015
dagguh
on 21 May 2015
For a summary of statistical properties of the data, we could also consider the boxplot alternative. It shows similar metrics, but makes less explicit of an assumption that the data is normally distributed. If you'd agree, I would close this one in favor of https://github.com/elastic/kibana/issues/4157 then.
 thomasneirynck
on 2 Jan 2017
thomasneirynck
on 2 Jan 2017
@thomasneirynck the box plot would be really helpful but really all that is needed to to divide each bucket by the total values seen in the whole chart. This would just make the Y axis a percentile of the total instead of a raw count.
 camerondavison
on 26 Jan 2017
camerondavison
on 26 Jan 2017
Is this related to the Cumulative Distribution function? https://github.com/elastic/kibana/issues/3905
 wylieconlon
on 15 Jan 2020
wylieconlon
on 15 Jan 2020
Related issues
 ctindel
·
3Comments
ctindel
·
3Comments
 timroes
·
3Comments
timroes
·
3Comments
 socialmineruser1
·
3Comments
socialmineruser1
·
3Comments
 snide
·
3Comments
snide
·
3Comments
 Ginja
·
3Comments
Ginja
·
3Comments
Most helpful comment
@thomasneirynck the box plot would be really helpful but really all that is needed to to divide each bucket by the total values seen in the whole chart. This would just make the Y axis a percentile of the total instead of a raw count.