Kibana: [Maps] Kibana freezes with too many (complex?) polygons
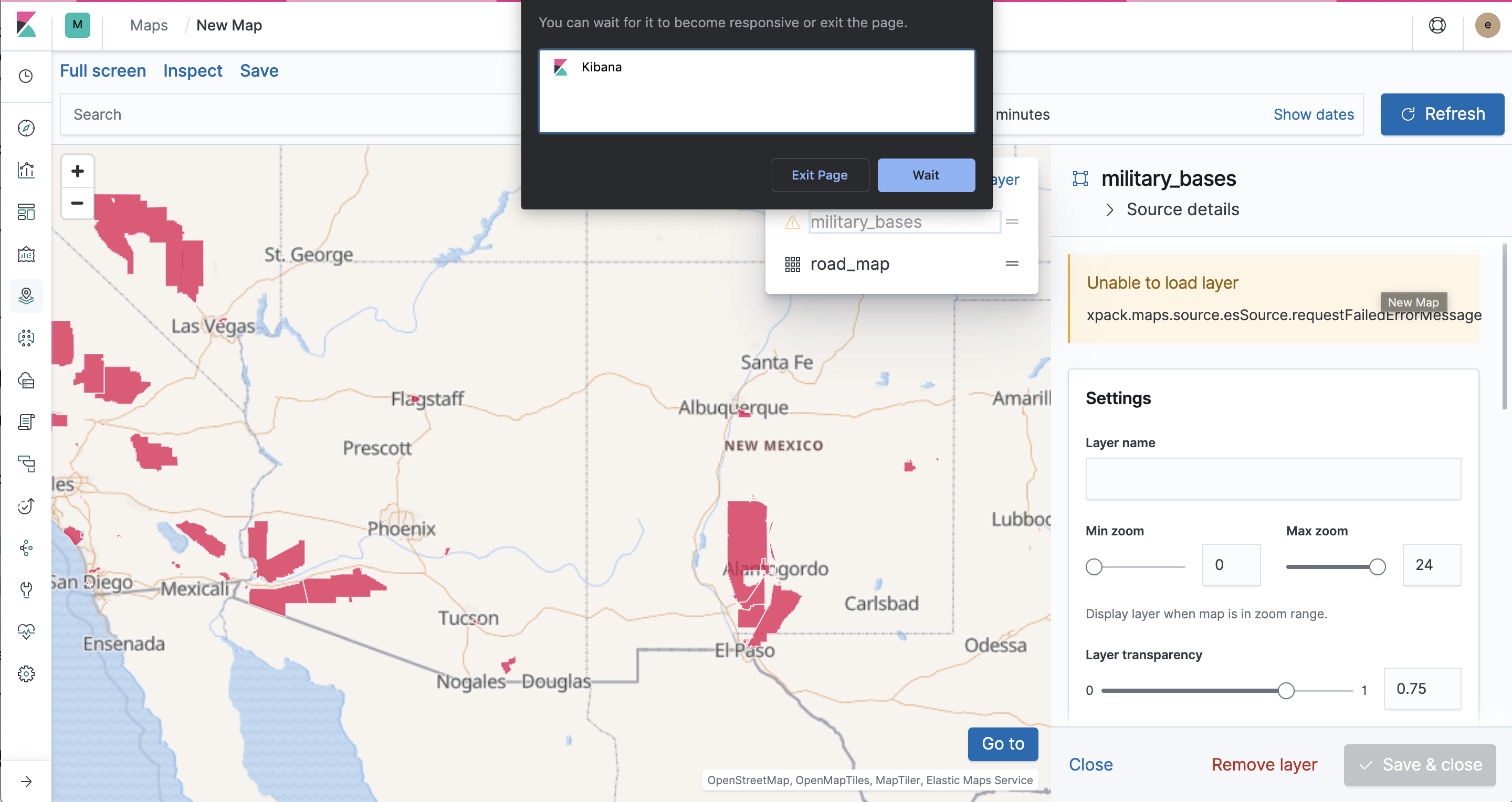
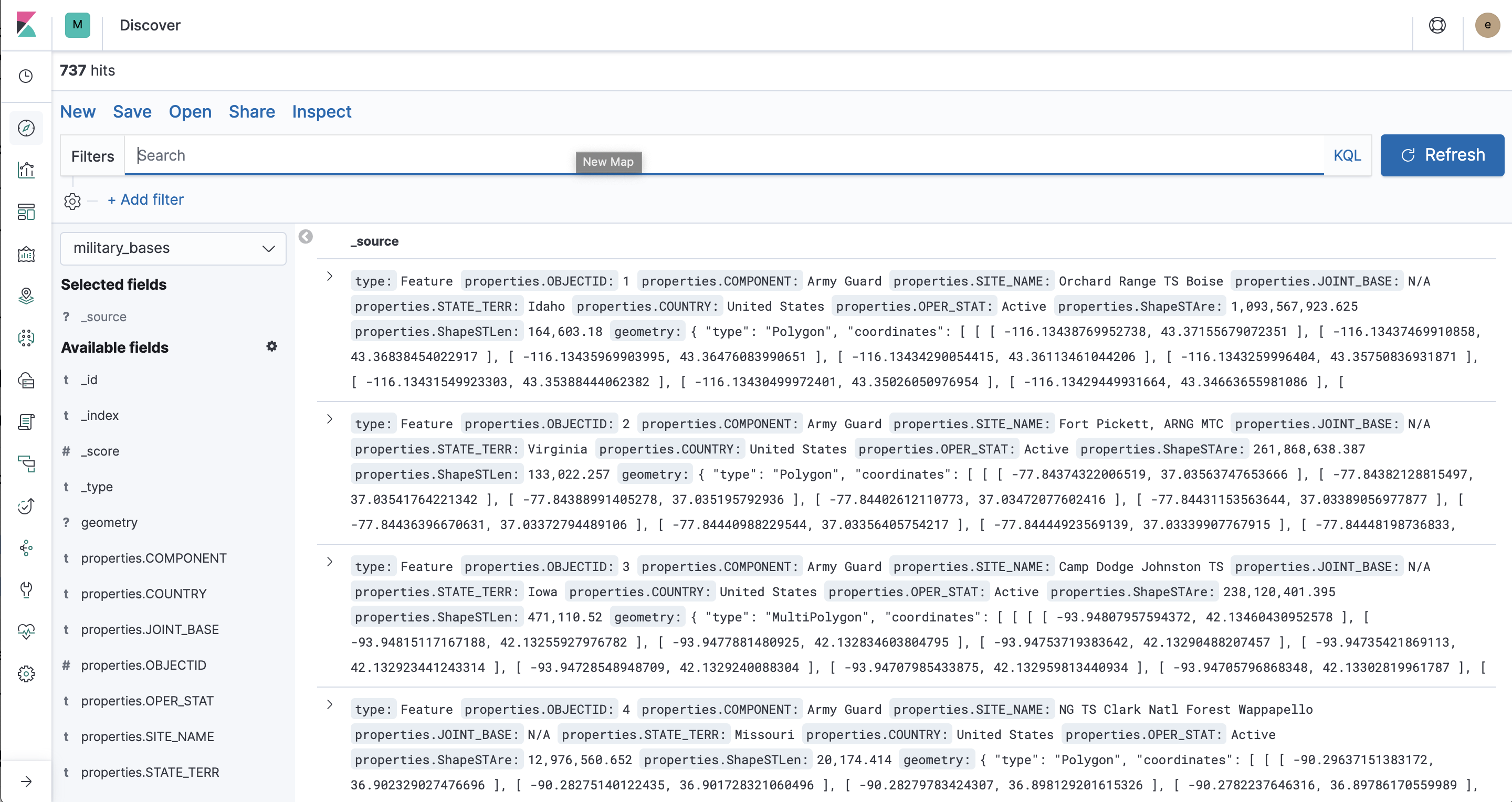
I'm on Kibana 7.0 and am running into some serious lag when I try and visualize 737 polygons on a map. I shared the data set in the maps channel but can repost here if needed. Kibana gets hung up pretty fast. I even switched off the setting to filter dynamically as I move around the map. Still, it freezes. We need to optimize the Maps app for better handling of geo_shape data. A number of our users expect the performance to be similar to other applications. Is there anything we can do here to improve rendering?
Example document from the data set below:
{
"_index": "military_bases",
"_type": "_doc",
"_id": "6hHNVWoBV_Efqma1WGbW",
"_version": 1,
"_score": 0,
"_source": {
"type": "Feature",
"properties": {
"OBJECTID": 1,
"COMPONENT": "Army Guard",
"SITE_NAME": "Orchard Range TS Boise",
"JOINT_BASE": "N/A",
"STATE_TERR": "Idaho",
"COUNTRY": "United States",
"OPER_STAT": "Active",
"ShapeSTAre": 1093567923.625,
"ShapeSTLen": 164603.17968159242
},
"geometry": {
"type": "Polygon",
"coordinates": [
[
[
-116.13438769952738,
43.37155679072351
],
[
-116.13437469910858,
43.36838454022917
],
["many, many, many, many, many more points"],
[
-116.13964939984442,
43.371566590285596
],
[
-116.13438769952738,
43.37155679072351
]
]
]
}
}
}
Removed a number of points to reduce scrolling for the issue ^^
 alexfrancoeur
alexfrancoeur
All 7 comments
Pinging @elastic/kibana-gis
 elasticmachine
on 25 Apr 2019
elasticmachine
on 25 Apr 2019
@thomasneirynck do you think there is anything we can do to improve this experience in the next release?
alexfrancoeur
on 2 May 2019
One thing is that the locations contain 14 decimal places. Anything after 6 is meaningless and provides no value on a map. Would it make sense to update geo_shape and geo_point field types to automatically truncate numbers to 6 decimal places?
This would save bandwidth when requesting the data from elasticsearch and memory in the client as well
 nreese
on 2 May 2019
nreese
on 2 May 2019
The main issue here is the excessive amount the Kibana maps app spends on decoding the geojson response coming from Elasticsearch.
For that reference file in particular, running on my platform (ubuntu/chrome) , the breakdown is roughly:
- 5-10s: waiting on response from Elasticsearch for the entire collection of documents (this is the raw response from the _msearch request, already filtered through the lower-level response handling in Kibana)
- 90-120s: converting the ES response to geojson. _this is the place where the hang-ups happen_
- 3-4s: setting the source on the mapbox-gl context
The reason for the enormous decoding time is mainly: https://github.com/thomasneirynck/kibana/blob/ee0664a184fa32b44b05f7b205a58a7b46fa1900/x-pack/plugins/maps/public/elasticsearch_geo_utils.js#L139
This creates a copy of each individual coordinate. This is not necessary. The implementation could just copy a reference to the original coordinate-array, as the coordinate arrays of geojson and es-responses are equivalent (too bad we cannot use the es-response as-is, since the capitalization of the geometry-types is slightly different in ES).
In general, the decoding of ES responses in Kibana (and by extension the Maps-app) are crufty in terms of mem-usage and allocation. A lot of code creates deep callstacks (e.g. the deep-clone). The many functional constructs (foreach, map, reduce, ...) and temporary object allocations of these programming techniques add up. This is especially the case when using these constructs in tight loops (e.g. unrolling many coordinate-arrays for many features). That type of code not only slows down execution, but its main impact is that it unnecessarily strains the garbage collector, creating noticeable pauses and hickups in the end-user experience. In excessive cases, it causes the browser to freeze.
Apart from the core issue (inefficient decoding of the ES-reponse), there are fringe issues that make working with such a large file difficult in the Maps-app.
- using extent-based filtering. this rerequests the data for pannig&zooming. This is a _suboptimal_ strategy for such a file. This setting should be switched off.
- setting the tooltips immediately triggers a re-request of the data. this is a _suboptimal_ strategy for such a file
- modifying style changes rebinds the data with the mapbox-gl context. this is a _suboptimal_ strategy for such a file (and all files for that matter). This should be fixed by https://github.com/elastic/kibana/issues/34396
I think we should pick up the low hanging fruit first.
_Rewrite the ES-hits -> geojson, taking care of two things_:
- high priority: do not deep clone the geometry
- mid priority: streamline the implementation details to not use so many functional constructs in tight loops. Instead, use more vanilla programming constructs (simple for-loops, don't create many short-lived helper-objects, ...) so the app is not spamming the heap, causing hickups and lag during GC.
In addition:
- modify some of the UX-patterns to avoid having users fat-finger unncessary data-requests
- for tooltips, require some sort of
applybutton so the app avoids frivolous re-queries. - the maps-app already has some recent improvements to the auto-detection of extent-based filtering, so imho that has been working well to alleviate some of these concerns. But maybe we can be a little more aggressive here (? e.g. never apply for large files ?). It would be difficult to determine exactly when/where to apply extent-based filtering, but at least users should be well-informed when to turn this on/off.
- for tooltips, require some sort of
For truly massive files, we need a different paradigm altogether. I think then, we should start looking at things like line-simplification (based on scale), vector tiling, ... That would be a stack-wide effort, but I think these approaches would not be required for a file of this scope which is in the order of thousands of features, thousands of points. The maps-app should be able to handle these types of files with conventional tools/technologies.
 thomasneirynck
on 3 May 2019
thomasneirynck
on 3 May 2019
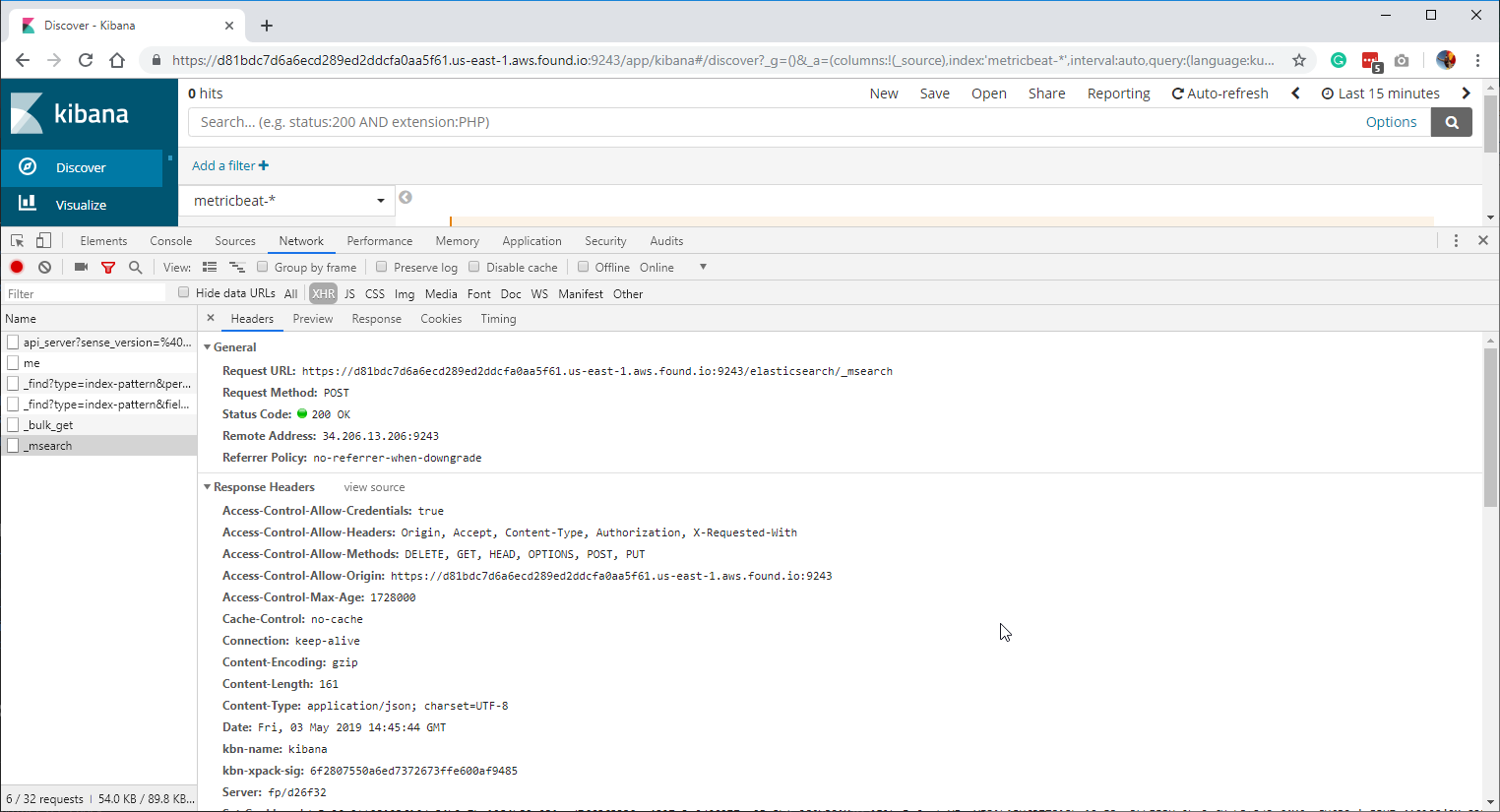
What about compressing the _msearch response from Kibana to the browser? That would greatly reduce the amount of data transferred from the server to the browser and save some time on the request side.
nreese
on 3 May 2019
We should already be gzipping the response from Kibana to the browser. Check for the Content-Encoding: gzip response header.
 tylersmalley
on 3 May 2019
tylersmalley
on 3 May 2019
After talking to @nreese, for next steps we will do:
- improve ES-response decoding (outlined here https://github.com/elastic/kibana/issues/35618#issuecomment-488853990)
- lazily load tooltip contents so the maps-app doesn't need to refetch all the data when the tooltip-configuration changes (https://github.com/elastic/kibana/issues/36032)
thomasneirynck
on 3 May 2019
Related issues
 celesteking
·
3Comments
celesteking
·
3Comments
 Ginja
·
3Comments
Ginja
·
3Comments
 spalger
·
3Comments
spalger
·
3Comments
 timmolter
·
3Comments
timmolter
·
3Comments
 timroes
·
3Comments
timroes
·
3Comments
Most helpful comment
The main issue here is the excessive amount the Kibana maps app spends on decoding the geojson response coming from Elasticsearch.
For that reference file in particular, running on my platform (ubuntu/chrome) , the breakdown is roughly:
The reason for the enormous decoding time is mainly: https://github.com/thomasneirynck/kibana/blob/ee0664a184fa32b44b05f7b205a58a7b46fa1900/x-pack/plugins/maps/public/elasticsearch_geo_utils.js#L139
This creates a copy of each individual coordinate. This is not necessary. The implementation could just copy a reference to the original coordinate-array, as the coordinate arrays of geojson and es-responses are equivalent (too bad we cannot use the es-response as-is, since the capitalization of the geometry-types is slightly different in ES).
In general, the decoding of ES responses in Kibana (and by extension the Maps-app) are crufty in terms of mem-usage and allocation. A lot of code creates deep callstacks (e.g. the deep-clone). The many functional constructs (foreach, map, reduce, ...) and temporary object allocations of these programming techniques add up. This is especially the case when using these constructs in tight loops (e.g. unrolling many coordinate-arrays for many features). That type of code not only slows down execution, but its main impact is that it unnecessarily strains the garbage collector, creating noticeable pauses and hickups in the end-user experience. In excessive cases, it causes the browser to freeze.
Apart from the core issue (inefficient decoding of the ES-reponse), there are fringe issues that make working with such a large file difficult in the Maps-app.
I think we should pick up the low hanging fruit first.
_Rewrite the ES-hits -> geojson, taking care of two things_:
In addition:
applybutton so the app avoids frivolous re-queries.For truly massive files, we need a different paradigm altogether. I think then, we should start looking at things like line-simplification (based on scale), vector tiling, ... That would be a stack-wide effort, but I think these approaches would not be required for a file of this scope which is in the order of thousands of features, thousands of points. The maps-app should be able to handle these types of files with conventional tools/technologies.