Keras: ModelCheckpoint callback with multi_gpu fails to save the model, throws error after 1st epoch
@fchollet Using Multiple callbacks in multi_gpu scenario throws an error. A single callback works perfectly for multi_gpu case, but multiple causes issue.
Its a kind of continuation of #8649. i followed the solution suggested there.
CODE USED:
cbk = resnet_model.MyCallBack(lr_scheduler, model)
cbk1 = resnet_model.MyCallBack(lr_reducer, model)
cbk2 = resnet_model.MyCallBack(checkpoint, model)
cbk3 = resnet_model.MyCallBack(csv_log, model)
callback = [cbk,cbk1,cbk2,cbk3]
Adding Data Augmentation Provided by Keras Module
datagen = ImageDataGenerator(featurewise_center=False,samplewise_center=False,featurewise_std_normalization=False,
samplewise_std_normalization=False,zca_whitening=False,rotation_range=0,
width_shift_range=0.1,height_shift_range=0.1,horizontal_flip=True,vertical_flip=False)
datagen.fit(x_train)
steps_per_epoch = int(np.ceil(x_train.shape[0] / float(batch_size)))
model_info = parallel_model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size),
steps_per_epoch=steps_per_epoch,
validation_data=(x_test, y_test),
epochs=epochs, verbose=1, workers=4,
callbacks=callback)
CLASS DEFINED:
class MyCallBack(keras.callbacks.Callback):
def __init__(self, callbacks,model):
super().__init__()
self.callback = callbacks
self.model = model
def on_epoch_begin(self,epoch,logs=None):
self.callback.on_epoch_begin(epoch, logs=logs)
def on_epoch_end(self,epoch,logs=None):
self.callback.on_epoch_end(epoch, logs=logs)
def on_batch_end(self, batch, logs=None):
self.callback.on_batch_end(batch, logs=logs)
def on_batch_begin(self, batch, logs=None):
self.callback.on_batch_begin(batch, logs=logs)
def on_train_begin(self, logs=None):
self.callback.set_model(self.model)
self.callback.on_train_begin(logs=logs)
def on_train_end(self, logs=None):
self.callback.on_train_end(logs=logs)
Error Received:
Epoch 1/100
195/196 [============================>.] - ETA: 0s - loss: 2.5631 - acc: 0.4139Epoch 00001: val_acc improved from -inf to 0.42420, saving model
to /home/bansa01/resnet_final/gpu_dir/tmp/saved_models/cifar10_v1_model.001.h5
Traceback (most recent call last):
File "resnet_cifar10.py", line 199, in
callbacks=callback)
File "/usr/local/keras-python3/lib/python3.5/site-packages/keras/legacy/interfaces.py", line 87, in wrapper
return func(args, *kwargs)
File "/usr/local/keras-python3/lib/python3.5/site-packages/keras/engine/training.py", line 2187, in fit_generator
callbacks.on_epoch_end(epoch, epoch_logs)
File "/usr/local/keras-python3/lib/python3.5/site-packages/keras/callbacks.py", line 73, in on_epoch_end
callback.on_epoch_end(epoch, logs)
File "/home/bansa01/resnet_final/gpu_dir/tmp/resnet_model.py", line 181, in on_epoch_end
self.callback.on_epoch_end(epoch, logs=logs)
File "/usr/local/keras-python3/lib/python3.5/site-packages/keras/callbacks.py", line 415, in on_epoch_end
self.model.save(filepath, overwrite=True)
File "/usr/local/keras-python3/lib/python3.5/site-packages/keras/engine/topology.py", line 2556, in save
save_model(self, filepath, overwrite, include_optimizer)
File "/usr/local/keras-python3/lib/python3.5/site-packages/keras/models.py", line 108, in save_model
'config': model.get_config()
File "/usr/local/keras-python3/lib/python3.5/site-packages/keras/engine/topology.py", line 2397, in get_config
return copy.deepcopy(config)
File "/usr/local/keras-python3/lib/python3.5/copy.py", line 155, in deepcopy
y = copier(x, memo)
File "/usr/local/keras-python3/lib/python3.5/copy.py", line 243, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "/usr/local/keras-python3/lib/python3.5/copy.py", line 155, in deepcopy
y = copier(x, memo)
File "/usr/local/keras-python3/lib/python3.5/copy.py", line 218, in _deepcopy_list
y.append(deepcopy(a, memo))
)
File "/usr/local/keras-python3/lib/python3.5/copy.py", line 155, in deepcopy
y = copier(x, memo)
File "/usr/local/keras-python3/lib/python3.5/copy.py", line 243, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "/usr/local/keras-python3/lib/python3.5/copy.py", line 174, in deepcopy
rv = reductor(4)
TypeError: cannot serialize '_io.TextIOWrapper' object
 nbansal90
nbansal90
All 7 comments
Okay, so I gave it a try with the callback function I gave in #8123 and a total of four callbacks, it works for me (on an other model).
The code I used is the following one :
class MyCallBack(keras.callbacks.Callback):
def __init__(self, callbacks,model):
super().__init__()
self.callback = callbacks
self.model = model
def on_epoch_begin(self,epoch,logs=None):
self.callback.on_epoch_begin(epoch, logs=logs)
def on_epoch_end(self,epoch,logs=None):
self.callback.on_epoch_end(epoch, logs=logs)
def on_batch_end(self, batch, logs=None):
self.callback.on_batch_end(batch, logs=logs)
def on_batch_begin(self, batch, logs=None):
self.callback.on_batch_begin(batch, logs=logs)
def on_train_begin(self, logs=None):
self.callback.set_model(self.model)
self.callback.on_train_begin(logs=logs)
def on_train_end(self, logs=None):
self.callback.on_train_end(logs=logs)
lr_scheduler = keras.callbacks.LearningRateScheduler(schedule)
reduce_lr = keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=5, min_lr=0.001)
csv_logger = keras.callbacks.CSVLogger('training.log')
checkpointer = CustomModelCheckpoint(gpu_model, '/tmp/weights.hdf5')
cbk = MyCallBack(lr_scheduler, model)
cbk1 = MyCallBack(reduce_lr, model)
cbk2 = MyCallBack(checkpointer, model)
cbk3 = MyCallBack(csv_logger, model)
callbacks = [cbk,cbk1,cbk2,cbk3]
Do you have more details on the functions you used for the callbacks ? From what I see when searching your error on google, this might be a problem of variable naming (twice the same name).
Also do you know if it bugs only with some groups of callbacks ? Like [cbk,cbk1] could be working but [cbk,cbk2] not, and so on with different groups. It could help to see if the problem is related to a pair/group of callbacks or more global.
And what is this "resnet_model." ? Just a module you defined yourself with the class in it or something else ?
 D3lt4lph4
on 28 Dec 2017
D3lt4lph4
on 28 Dec 2017
@D3lt4lph4 I think I have narrowed down the issue! It is failing for a particular callback, and that is for : checkpoint = ModelCheckpoint(filepath=filepath, monitor='val_acc',verbose=1,
save_best_only=True)
Now If you use fit_generator, and in to that, if you pass ModelCheckpoint callback, It will fail after the first epoch. I removed ModelCheckpoint callback and its working fine with other multiple callbacks! So there seems to be an issue while using ModelCheckpoint callback.
So Seems like, I had the same issue as one discussed in the earlier thread, regarding not able to save model :) .
So do we have any solution for it .. As per what I see https://github.com/rmkemker/main/blob/master/machine_learning/model_checkpoint_parallel.py, this seems to have worked for few guys.. but I am not sure why? Any comments..
nbansal90
on 29 Dec 2017
@nbansal90 I've looked into the code at the url you gave, maybe I am being completely oblivious to something but it looks like it saves only the x layer.
Looks like all the originals:
self.model.save_weights(filepath, overwrite=True)
else:
self.model.save(filepath, overwrite=True)
have been replaced with:
self.model.layers[-(num_outputs+1)].save_weights(filepath, overwrite=True)
else:
self.model.layers[-(num_outputs+1)].save(filepath, overwrite=True)
And I don't understand the "len(self.model.outputs)" at the beginning of the on_epoch_end() function. model.layers output the list of your model layers but num_outputs = len(self.model.outputs) returns the number of output ? (Not even sure since model.outputs gives me a list.)
It kinda looks like one of the answers in #8253 but either I am missing something and it saves the whole model or it only works for a one layer model.
D3lt4lph4
on 29 Dec 2017
@D3lt4lph4 It looks like They are looking to save weights for a particular Layer. Btw I think I got the gist of it. Thanks Indeed !
nbansal90
on 30 Dec 2017
I'm running into this as well, using the keras.callbacks.ModelCheckpoint callback:
Traceback (most recent call last):
File "./learn.py", line 602, in <module>
main(arguments)
File "./learn.py", line 532, in main
verbose=0)
File "/home/steven/.local/lib/python3.5/site-packages/keras/engine/training.py", line 1669, in fit
validation_steps=validation_steps)
File "/home/steven/.local/lib/python3.5/site-packages/keras/engine/training.py", line 1226, in _fit_loop
callbacks.on_epoch_end(epoch, epoch_logs)
File "/home/steven/.local/lib/python3.5/site-packages/keras/callbacks.py", line 76, in on_epoch_end
callback.on_epoch_end(epoch, logs)
File "/home/steven/.local/lib/python3.5/site-packages/keras/callbacks.py", line 418, in on_epoch_end
self.model.save(filepath, overwrite=True)
File "/home/steven/.local/lib/python3.5/site-packages/keras/engine/topology.py", line 2573, in save
save_model(self, filepath, overwrite, include_optimizer)
File "/home/steven/.local/lib/python3.5/site-packages/keras/models.py", line 111, in save_model
'config': model.get_config()
File "/home/steven/.local/lib/python3.5/site-packages/keras/engine/topology.py", line 2414, in get_config
return copy.deepcopy(config)
File "/usr/lib/python3.5/copy.py", line 155, in deepcopy
y = copier(x, memo)
File "/usr/lib/python3.5/copy.py", line 243, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "/usr/lib/python3.5/copy.py", line 155, in deepcopy
y = copier(x, memo)
File "/usr/lib/python3.5/copy.py", line 218, in _deepcopy_list
y.append(deepcopy(a, memo))
File "/usr/lib/python3.5/copy.py", line 155, in deepcopy
y = copier(x, memo)
File "/usr/lib/python3.5/copy.py", line 243, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "/usr/lib/python3.5/copy.py", line 155, in deepcopy
y = copier(x, memo)
File "/usr/lib/python3.5/copy.py", line 243, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "/usr/lib/python3.5/copy.py", line 155, in deepcopy
y = copier(x, memo)
File "/usr/lib/python3.5/copy.py", line 223, in _deepcopy_tuple
y = [deepcopy(a, memo) for a in x]
File "/usr/lib/python3.5/copy.py", line 223, in <listcomp>
y = [deepcopy(a, memo) for a in x]
File "/usr/lib/python3.5/copy.py", line 155, in deepcopy
y = copier(x, memo)
File "/usr/lib/python3.5/copy.py", line 223, in _deepcopy_tuple
y = [deepcopy(a, memo) for a in x]
File "/usr/lib/python3.5/copy.py", line 223, in <listcomp>
y = [deepcopy(a, memo) for a in x]
File "/usr/lib/python3.5/copy.py", line 182, in deepcopy
y = _reconstruct(x, rv, 1, memo)
File "/usr/lib/python3.5/copy.py", line 297, in _reconstruct
state = deepcopy(state, memo)
File "/usr/lib/python3.5/copy.py", line 155, in deepcopy
y = copier(x, memo)
File "/usr/lib/python3.5/copy.py", line 243, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "/usr/lib/python3.5/copy.py", line 182, in deepcopy
y = _reconstruct(x, rv, 1, memo)
File "/usr/lib/python3.5/copy.py", line 306, in _reconstruct
y.__dict__.update(state)
AttributeError: 'NoneType' object has no attribute 'update'
I dug into this with PyCharm to figure out what it was trying (and failing) to deepcopy. It turns out it was trying to deepcopy the whole tensorflow module. And modules can't be deepcopy'd (the error message gets updated in Python 3.6 to catch this and report it in a less confusing way).
The config it tries to deepcopy looks like this:
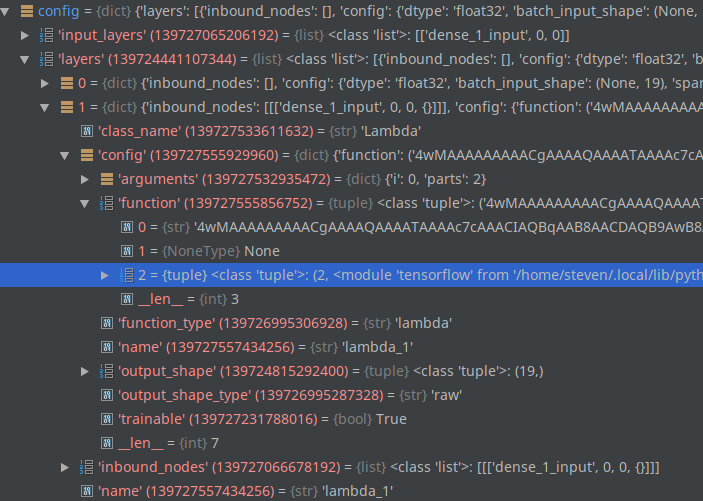
Note how the 2nd index of the tuple function contains the tensorflow module. This appears to come from keras.utils.training_utils.multi_gpu_model, which defines a function called get_slice which directly references functions in the tensorflow module. Deep copying the keras.layers.core.Lambda that uses get_slice as its function will fail because of this.
Is there any way to define the get_slice function that would be serializable?
 tycho
on 7 Feb 2018
tycho
on 7 Feb 2018
Maybe something like this? Seems to work locally at least.
diff --git a/keras/layers/__init__.py b/keras/layers/__init__.py
index 00494f1..6d9c574 100644
--- a/keras/layers/__init__.py
+++ b/keras/layers/__init__.py
@@ -1,6 +1,7 @@
from __future__ import absolute_import
from ..utils.generic_utils import deserialize_keras_object
+from ..utils.training_utils import DeviceSlice
from ..engine import Layer
from ..engine import Input
from ..engine import InputLayer
diff --git a/keras/utils/__init__.py b/keras/utils/__init__.py
index 4c1a1c8..76693f7 100644
--- a/keras/utils/__init__.py
+++ b/keras/utils/__init__.py
@@ -22,4 +22,5 @@ from .layer_utils import print_summary
from .vis_utils import plot_model
from .np_utils import to_categorical
from .np_utils import normalize
+from .training_utils import DeviceSlice
from .training_utils import multi_gpu_model
diff --git a/keras/utils/training_utils.py b/keras/utils/training_utils.py
index 48d4524..d6de833 100644
--- a/keras/utils/training_utils.py
+++ b/keras/utils/training_utils.py
@@ -4,9 +4,8 @@ from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
-from ..layers.merge import concatenate
from .. import backend as K
-from ..layers.core import Lambda
+from ..engine.topology import Layer
from ..engine.training import Model
@@ -19,6 +18,35 @@ def _normalize_device_name(name):
return name
+class DeviceSlice(Layer):
+ def __init__(self, index, total_devices, **kwargs):
+ self.index = index
+ self.total_devices = total_devices
+ super(DeviceSlice, self).__init__(**kwargs)
+
+ def call(self, inputs):
+ shape = K.tf.shape(inputs)
+ batch_size = shape[:1]
+ input_shape = shape[1:]
+ step = batch_size // self.total_devices
+ if self.index == self.total_devices - 1:
+ size = batch_size - step * self.index
+ else:
+ size = step
+ size = K.tf.concat([size, input_shape], axis=0)
+ stride = K.tf.concat([step, input_shape * 0], axis=0)
+ start = stride * self.index
+ return K.tf.slice(inputs, start, size)
+
+ def compute_output_shape(self, input_shape):
+ return input_shape
+
+ def get_config(self):
+ config = {'index': self.index, 'total_devices': self.total_devices}
+ base_config = super(DeviceSlice, self).get_config()
+ return dict(list(base_config.items()) + list(config.items()))
+
+
def multi_gpu_model(model, gpus=None):
"""Replicates a model on different GPUs.
@@ -137,20 +165,6 @@ def multi_gpu_model(model, gpus=None):
target_devices,
available_devices))
- def get_slice(data, i, parts):
- shape = tf.shape(data)
- batch_size = shape[:1]
- input_shape = shape[1:]
- step = batch_size // parts
- if i == num_gpus - 1:
- size = batch_size - step * i
- else:
- size = step
- size = tf.concat([size, input_shape], axis=0)
- stride = tf.concat([step, input_shape * 0], axis=0)
- start = stride * i
- return tf.slice(data, start, size)
-
all_outputs = []
for i in range(len(model.outputs)):
all_outputs.append([])
@@ -164,10 +178,7 @@ def multi_gpu_model(model, gpus=None):
# Retrieve a slice of the input.
for x in model.inputs:
input_shape = tuple(x.get_shape().as_list())[1:]
- slice_i = Lambda(get_slice,
- output_shape=input_shape,
- arguments={'i': i,
- 'parts': num_gpus})(x)
+ slice_i = DeviceSlice(i, num_gpus)(x)
inputs.append(slice_i)
# Apply model on slice
@@ -180,6 +191,8 @@ def multi_gpu_model(model, gpus=None):
for o in range(len(outputs)):
all_outputs[o].append(outputs[o])
+ from ..layers.merge import concatenate
+
# Merge outputs on CPU.
with tf.device('/cpu:0'):
merged = []
https://github.com/keras-team/keras/issues/8649
provide a way to checkpoint.And it works for me!
`
original_model = ...
parallel_model = multi_gpu_model(original_model, gpus=n)
class MyCbk(keras.callbacks.Callback):
def __init__(self, model):
self.model_to_save = model
def on_epoch_end(self, epoch, logs=None):
self.model_to_save.save('model_at_epoch_%d.h5' % epoch)
cbk = MyCbk(original_model)
parallel_model.fit(..., callbacks=[cbk])
`
by fchollet
 ethir
on 11 Apr 2018
ethir
on 11 Apr 2018
Related issues
 vinayakumarr
·
3Comments
vinayakumarr
·
3Comments
 NancyZxll
·
3Comments
NancyZxll
·
3Comments
 oweingrod
·
3Comments
oweingrod
·
3Comments
 farizrahman4u
·
3Comments
farizrahman4u
·
3Comments
 nryant
·
3Comments
nryant
·
3Comments
Most helpful comment
https://github.com/keras-team/keras/issues/8649
provide a way to checkpoint.And it works for me!
`
original_model = ...
parallel_model = multi_gpu_model(original_model, gpus=n)
class MyCbk(keras.callbacks.Callback):
cbk = MyCbk(original_model)
parallel_model.fit(..., callbacks=[cbk])
`
by fchollet