Keras: model.save and load giving different result
I am trying to save a simple LSTM model for text classification. The input of the model is padded vectorized sentences.
model = Sequential()
model.add(LSTM(40, input_shape=(16, 32)))
model.add(Dense(20))
model.add(Dense(8, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
For saving I'm using the following snippet:
for i in range(50):
from sklearn.cross_validation import train_test_split
data_train, data_test, labels_train, labels_test = train_test_split(feature_set, dummy_y, test_size=0.1, random_state=i)
accuracy = 0.0
try:
with open('/app/accuracy', 'r') as file:
for line in file:
accuracy = float(line)
except Exception:
print("error")
model.fit(data_train, labels_train, nb_epoch=50)
loss, acc = model.evaluate(feature_set, dummy_y)
if acc > accuracy:
model.save_weights("model.h5", overwrite=True)
model.save('my_model.h5', overwrite=True)
print("Saved model to disk.\nAccuracy:")
print(acc)
with open('/app/accuracy', 'w') as file:
file.write('%f' % acc)
But whenever I'm trying to load the same model
from keras.models import load_model
model = load_model('my_model.h5')
I'm getting random accuracy like an untrained model. same result even when trying to load weights separately.
If I set the weights
lstmweights=model.get_weights()
model2.set_weights(lstmweights)
like above. It is working if model and model2 are run under same session (same notebook session). If I serialize lstmweights and try to load it from different place, again I'm getting result like untrained model. It seems saving only the weights are not enough. So why model.save is not working. Any known point?
 dipanjannag
dipanjannag
All 265 comments
I'm having a similar problem, but it has to do with setting stateful=True. If I do that, the prediction from the original model is different from the prediction of the saved and reloaded model.
`# DEPENDENCIES
import numpy as np
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.layers.recurrent import LSTM
TRAINING AND VALIDATION FILES
xTrain = np.random.rand(200,10)
yTrain = np.random.rand(200,1)
xVal = np.random.rand(100,10)
yVal = np.random.rand(100,1)
ADD 3RD DIMENSION TO DATA
xTrain = xTrain.reshape(len(xTrain), 1, xTrain.shape[1])
xVal = xVal.reshape(len(xVal), 1, xVal.shape[1])
CREATE MODEL
model = Sequential()
model.add(LSTM(200, batch_input_shape=(10, 1, xTrain.shape[2])
#, stateful=True # With this line, the reloaded model generates different predictions than the original model
))
model.add(Dense(yTrain.shape[1]))
model.add(Activation("linear"))
model.compile(loss="mean_squared_error", optimizer="rmsprop")
model.fit(xTrain, yTrain,
batch_size=10, nb_epoch=2,
verbose=0,
shuffle='False',
validation_data=(xVal, yVal))
PREDICT RESULTS ON VALIDATION DATA
yFit = model.predict(xVal, batch_size=10, verbose=1)
print()
print(yFit)
SAVE MODEL
model.save('my_model.h5')
del model
RELOAD MODEL
from keras.models import load_model
model = load_model('my_model.h5')
yFit = model.predict(xVal, batch_size=10, verbose=1)
print()
print(yFit)
DO IT AGAIN
del model
model = load_model('my_model.h5')
yFit = model.predict(xVal, batch_size=10, verbose=1)
print()
print(yFit)`
 Panache1
on 7 Feb 2017
Panache1
on 7 Feb 2017
Same problem. Is there sth wrong with the function "save model"?
 fighting41love
on 11 Mar 2017
fighting41love
on 11 Mar 2017
I am having the exact same issue. Does anyone know exactly what the problem is?
 bibhashthakur
on 15 Mar 2017
bibhashthakur
on 15 Mar 2017
Same issue using json format for saving a very simple model. I get different results on my test data before and after save/loading the model.
classifier = train(model, trainSet, devSet)
TEST BEFORE SAVING
test(model, classifier, testSet)
save model to json
model_json = classifier.to_json()
with open('../data/local/SICK-Classifier', "w") as json_file:
json_file.write(model_json)
load model fron json
json_file = open('../data/local/SICK-Classifier', 'r')
loaded_model_json = json_file.read()
json_file.close()
classifier = model_from_json(loaded_model_json)
TEST AFTER SAVING
test(model, classifier, testSet)
 FTAsr
on 4 Apr 2017
FTAsr
on 4 Apr 2017
I crosschecked all these functions - they seem to be working properly.
model.save(), load_model(), model.save_weights() and model.load_weights()
 HarshaVardhanP
on 22 Apr 2017
HarshaVardhanP
on 22 Apr 2017
I ran into a similar issue. After saving my model, the weights were changed and my predictions became random.
For my own case, it came down to how I was mixing vanilla Tensorflow with Keras. It turns out that Keras implicitly runs tf.global_variables_initializer if you don't tell it that you will do so manually. This means that in trying to save my model, it was first re-initializing all of the weights.
The flag to prevent Keras from doing this is _MANUAL_VAR_INIT in the tensorflow backend. You can turn it on like this, before training your model:
from keras.backend import manual_variable_initialization
manual_variable_initialization(True)
Hope this helps!
 kswersky
on 24 Apr 2017
kswersky
on 24 Apr 2017
Hi @kswersky,
Thanks for your answer.
I am using Keras 2.0 with Tensorflow 1.0 setup. I am building model in Keras and using Tensorflow pipeline for training and testing. When you load the keras model, it might reinitialize the weights. I avoided tf.global_variables_initializer() and used load_weights('saved_model.h5'). Then model got the saved weights and I was able to reproduce correct results. I did not have to do the _manual_var_init step. (its a very good answer for just Keras)
May be I confused people who are just using Keras.
HarshaVardhanP
on 24 Apr 2017
Use model.model.save() instead of model.save()
 pras135
on 7 May 2017
pras135
on 7 May 2017
I'm stuck with the same problem. The only solution for now is move to python 2.7 ?
@pras135 , if I do as you suggest I cannot perform model.predict_classes(x), AttributeError: 'Model' object has no attribute 'predict_classes'
 lotempeledGong
on 11 May 2017
lotempeledGong
on 11 May 2017
Same issue here. When I load a saved model my predictions are random.
 kefth
on 11 May 2017
kefth
on 11 May 2017
@lotempeledGong
model_1 = model.model.save('abcd.h5') # save the model as abcd.h5
from keras.models import load_model
model_1 = load_model('abcd.h5') # load the saved model
y_score = model_1.predict_classes(data_to_predict) # supply data_to_predict
Hope it helps.
pras135
on 12 May 2017
@pras135 What you suggested is in the same session, and it does work. Unfortunately I need this to work in separate sessions, and if you do the following:
(in first python session)
model_1 = model.model.save('abcd.h5') # save the model as abcd.h5
(close python session)
(open second python session)
model_1 = load_model('abcd.h5') # load the saved model
y_score = model_1.predict_classes(data_to_predict) # supply data_to_predict
I receive the following error: AttributeError: 'Model' object has no attribute 'predict_classes'
lotempeledGong
on 12 May 2017
@lotempeledGong That should not happen. Check if load_model means same as keras.models.load_model in your context. This should work just fine.
dipanjannag
on 12 May 2017
@deeiip thanks, but this still doesn't work for me. However this is not my main problem here. What I want eventually is to train a model, save it, close the python session and in a new python session load the trained model and obtain the same accuracy. Currently when I try to do this, the loaded model gives random predictions and it is as though it wasn't trained.
By the way, in case this is a versions issue- I'm running with Keras 2.0.4 with Tensorflow 1.1.0 backend on Python 3.5.
lotempeledGong
on 15 May 2017
@lotempeledGong I'm facing exactly the same issue you refer here. However, I'm using Tensorflow 1.1 and TFlearn 0.3 on Windows10 with Python 3.5.2.
 BBarbosa
on 16 May 2017
BBarbosa
on 16 May 2017
@deeiip have you solved this problem? how to?
 chenlihuang
on 26 May 2017
chenlihuang
on 26 May 2017
@kswersky l add the from keras.backend import manual_variable_initialization
manual_variable_initialization(True) but the error came:
tensorflow.python.framework.errors_impl.FailedPreconditionError: Attempting to use uninitialized value Variable
[[Node: Variable/_24 = _Send[T=DT_FLOAT, client_terminated=false, recv_device="/job:localhost/replica:0/task:0/cpu:0", send_device="/job:localhost/replica:0/task:0/gpu:0", send_device_incarnation=1, tensor_name="edge_8_Variable", _device="/job:localhost/replica:0/task:0/gpu:0"](Variable)]]
[[Node: Variable_1/_27 = _Recv[_start_time=0, client_terminated=false, recv_device="/job:localhost/replica:0/task:0/cpu:0", send_device="/job:localhost/replica:0/task:0/gpu:0", send_device_incarnation=1, tensor_name="edge_10_Variable_1", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/cpu:0"]()]]
chenlihuang
on 26 May 2017
@HarshaVardhanP how to avoided tf.global_variables_initializer() before load model?
chenlihuang
on 26 May 2017
@chenlihuang Now, I am using tf.global_variables_initializer(). It will init net variables. And use load_weights() to load the saved weights. This seems easier for me than using load_model().
HarshaVardhanP
on 26 May 2017
@HarshaVardhanP can you give some ideas for me on the keras level . l don't care the backend on TF.
only easy uase keras layers. that's mean how can l solve the problem in this beacuse I didn't touch the TF
.
chenlihuang
on 27 May 2017
EDIT: i've noticed loading my model doesnt give different results so I guess I dont need the workaround.
 Ssica
on 27 May 2017
Ssica
on 27 May 2017
Unfortunately, I've run into the same issue that many others on here seem to have encountered -- I've trained what seems to be an extremely powerful text classifier (based on cross-validation, at least, with a healthy-sized dataset), but upon loading a saved model -- either using load_model or model.load_weights -- my model's performance is now completely worthless when tested in a new session. There's absolutely no way this is the same model that I trained. I've tried every suggestion offered here, but to no avail. Super disheartening to see what appeared to be such good results and have no ability to actually use the classifier in other sessions/settings. I hope this gets addressed soon. (P.S. I'm running with Keras 2.0.4 with Tensorflow 1.1.0 backend on Python 3.5.)
 Atvar
on 30 May 2017
Atvar
on 30 May 2017
@gokceneraslan @fchollet Many of us are facing this issue. Could you please take a look ?
Thanks!
 ChandrahasJR
on 4 Jun 2017
ChandrahasJR
on 4 Jun 2017
I do not see any issue with model serialization using the save_model() and load_model() functions from the latest Tensorflow packaged Keras.
For example:
import tensorflow.contrib.keras as keras
m = train_keras_cnn_model() # Fill in the gaps with your model
model_fn = "test-keras-model-serialization.hdf5"
keras.models.save_model(m, model_fn)
m_load = keras.models.load_model(model_fn)
m_load_weights = m_load.get_weights()
m_weights = m.get_weights()
assert len(m_load_weights) == len(m_weights)
for i in range(len(m_weights)):
assert np.array_equal(m_load_weights[i], m_weights[i])
print("Model weight serialization test passed"
 kevinjos
on 4 Jun 2017
kevinjos
on 4 Jun 2017
Hi @kevinjos
The issue is not with using the saved model in the same session. If i save a model from session 1 and load it in session 2 and use two exactly the same data to perform inference, the results are different.
To be more specific, the inference results from the session in which the model was built is much better compared to results from a different session using the same model.
How is tensorflow packaged keras different from vanilla keras itself ?
ChandrahasJR
on 4 Jun 2017
@Chandrahas1991 When I run a similar code as above with a fresh tf session I get the same results. Have you tried the suggestion offered by @kswersky to set a flag to prevent automatic variable initialization? Could the issue with serialization apply only to LSTM layers? Or more specifically stateful LSTM layers? Have you tried using only the Keras code packaged with TensorFlow?
import tensorflow.contrib.keras as keras
from tensorflow.contrib.keras import backend as K
m = train_keras_cnn_model() # Fill in the gaps with your model
model_fn = "test-keras-model-serialization.hdf5"
m_weights = m.get_weights()
keras.models.save_model(m, model_fn)
K.clear_session()
m_load = keras.models.load_model(model_fn)
m_load_weights = m_load.get_weights()
assert len(m_load_weights) == len(m_weights)
for i in range(len(m_weights)):
assert np.array_equal(m_load_weights[i], m_weights[i])
print("Model weight serialization test passed"
@kevinjos I got this error while working with CNN's and @kswersky's solution did not work for me.
I haven't tried with keras packed in tensorflow. I'll check it out. Thanks for the suggestion!
ChandrahasJR
on 5 Jun 2017
There are already tests in Keras to check if model saving/loading works. Unless you write a short and fully reproducible code (along with the data) and fully describe your working environment (keras/python version, backend), it's difficult to pinpoint the cause of all issues mentioned here.
I've just sent another PR to add more tests about problems described here. @deeiip can you check #7024 and see if it's similar to the code that you use to reproduce this? With my setup, (keras master branch, python 3.6, TF backend) I cannot reproduce any model save/load issues with either mlps or convlstms, even if I restart the session in between.
Some people mentioned reproducibility problems about stateful RNNs. As far as I know, RNN states are not saved via save_model(). Therefore, there must be differences when you compare predictions before and after saving the model, since states are reset. But keep in mind that this report is not about stateful RNNs.
 gokceneraslan
on 18 Jun 2017
gokceneraslan
on 18 Jun 2017
check the input data if is consistent for the same data across multiple executions.
 amadupu
on 21 Jun 2017
amadupu
on 21 Jun 2017
I am having this same problem, but only when I use an embedding layer and keras API. Before closing the session the accuracy after running model.evaluate is >90%, after opening a new session and running a model.evaluate on the exact same data I get ~ 80% accuracy. I have tried saving the model using save,model() and by saving to json and saving and then also loading the weights. Both methods give the same results.
I use the same data with a sequential model without an embedding layer and API model without an embedding layer and both work as expected.
embedding_layer = Embedding(len(word_index) +1, 28, input_length = 28)
sequence_input = Input(shape=(max_seq_len,), dtype='int32')
embedded_sequences = embedding_layer(sequence_input)
x = Conv1D(128, 3, activation='relu')(embedded_sequences)
x = MaxPooling1D(3)(x)
x = Conv1D(128, 2, activation='relu')(x)
x = MaxPooling1D(2)(x)
x = Conv1D(128, 2, activation='relu')(x)
x = MaxPooling1D(2)(x) # global max pooling
x = Flatten()(x)
x = Dense(12, activation='relu')(x)
x = Dropout(0.2)(x)
preds = Dense(46, activation='softmax')(x)
model = Model(sequence_input, preds)
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['acc'])
model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=1, batch_size=300)
I am using anaconda v3.5 and tf r1.1
 Jamesmoly
on 23 Jun 2017
Jamesmoly
on 23 Jun 2017
Any news on that? Similar problem here.
I am training a unet architecture CNN. The training gives good results and the evaluate function works fine loading the model. As I generate new predicitons they are completely random and uncorrelated to the ground truths.. Loading the model or the weights separately does not help.
Keras 2.0.4 with Tensorflow 1.1.0 backend on Python 2.7.
 FrancescoLR
on 27 Jun 2017
FrancescoLR
on 27 Jun 2017
It's difficult to help without a fully reproducible code.
gokceneraslan
on 27 Jun 2017
I ran in to the same issue (and am mixing Keras and Tensorflow) and I am already using manual_variable_initialization(True). I had to add the extra load_weights(..) call to get it to work.
def __init__(self):
self.session = tf.Session()
K.set_session(self.session)
K.manual_variable_initialization(True)
self.model = load_model(FILENAME)
self.model._make_predict_function()
self.session.run(tf.global_variables_initializer())
self.model.load_weights(FILENAME) #### Added this line
self.default_graph = tf.get_default_graph()
self.default_graph.finalize()
 jgustave
on 5 Jul 2017
jgustave
on 5 Jul 2017
For anyone experiencing this, can you check that the weights of the model are exactly the same right after training and after being reloaded? To machine precision.
 Dapid
on 8 Jul 2017
Dapid
on 8 Jul 2017
I have the same issue. In my case if I use Lambda layer then the prediction results after loading are not correct. If I remove the Lambda layer, then the results after loading are the same as training.
EDIT: I checked my code again, and I found the issue is because of using a undefined parameter in my lambda function. After I solved it, the results are consistent.
 ZheweiMedia
on 10 Jul 2017
ZheweiMedia
on 10 Jul 2017
Just switched to a GPU setup, and this issue came up. I haven't tried switching back to CPU only, but will let you know if it seems to be the issue. Additionally #4044 has been happening a lot, although I'm not sure if it's related. Tensorflow is only used to set the device (GPU) for each model.
Python 3.4.3, Keras 2.0.6, TensorFlow 1.2.0, TensorFlow-GPU 1.1.0
UPDATE: It seems to occur when training two models at the same time (i.e. train model1, test model1 with expected accuracy, train model2, test model1 with random predictions). I think this might be an issue with the load_model function, and I'm going to try using the instance method (load the model from json and then load it's weights) to see if the same error occurs.
UPDATE 2: Instance methods didn't solve the issue.
UPDATE 3: I feel kinda silly. My code was the issue. 👎 Sorry for the spam.
 jinksmysteryman
on 13 Jul 2017
jinksmysteryman
on 13 Jul 2017
I'm training a LSTM RNN for description generation using Keras (Tensorflow Backend) with MSCOCO dataset. When training the model it had 92% accuracy with 0.79 loss. Further when the model was training I tested the description generation at each epoch and the model provided very good predictions with a meaningful description when it gives a random word.
However after training I loaded the model using model.load_weights(WEIGHTS) method in Keras and tried to create a description by giving a random word as I've done before. But now model is not providing a meaningful description and it just outputs random words which has no meaning at all.
I checked weight values and they are same too.
My model parameters are:
10 LSTM layers
Learning rate: 0.04
Activation: Softmax
Loss Function: Categorical Cross entropy
Optimizer: rmsprop
My Tesorflow version: 1.2.1
Python: 3.5
Keras Version: 2.0.6
Does anyone have a solution for this ?
 diyathn
on 17 Jul 2017
diyathn
on 17 Jul 2017
What I've tried here is:
md = config_a_model() # a pretty complicated convolutional NN.
md.save('model.h5')
md1 = config_a_model() # same config as above
md1.load_weights('model.h5')
md1.save('another_model.h5')
model.h5 is 176M and another_model.h5 is only 29M.
Python 2.7.6
tensorflow-gpu (1.2.1)
Keras 2.0.6
 rrki
on 1 Aug 2017
rrki
on 1 Aug 2017
Did you try model.save_weights() ?? I am using model.save_weights(), model.load_weights(), model.load_from_json() which are working fine.
HarshaVardhanP
on 1 Aug 2017
@HarshaVardhanP Will try.. What's the difference between save() and save_weights() ?
Also I feel it's a recent issue for me since I upgraded Keras from 2.0.1 => 2.0.6 last weekend.
I didn't have such issue before, as previously the prediction results are much better. Now the prediction results are horrible. That's why I tested above model save->load->save again steps.
rrki
on 1 Aug 2017
@rrki - I had this issue while loading Keras models into Tensorflow. model.save() didn't work for me for some reason. It's supposed to save architecture and weights. So, I saved/loaded architecture and weights separately which seems to be working fine for sometime.
HarshaVardhanP
on 2 Aug 2017
@HarshaVardhanP I've tried save_weights() and also keras.models.save_model()
They are basically all the same. I can't explain why the mode file sizes differ a lot. I tried to print out every layer's summary() and seems the network's architecture is there. But predict() always gives random results...
rrki
on 2 Aug 2017
@rrki we would need a specific example to find what is going wrong there, including a minimal model that reproduces the error, and some data to train it.
Otherwise, can you check if the weights of the model are the same, to machine precision, before and after reloading?
Dapid
on 2 Aug 2017
@Dapid
Thank you for the reply. Correct me if I'm misusing something...
import numpy as np
from keras.callbacks import TensorBoard
from keras.layers import Conv1D, MaxPooling1D
from keras.layers.advanced_activations import PReLU
from keras.layers.core import Dense, Activation, Dropout, Flatten
from keras.layers.normalization import BatchNormalization
from keras.layers.wrappers import TimeDistributed
from keras.legacy.layers import Merge
from keras.models import save_model, load_model, Sequential
def config_model():
pRelu = PReLU()
md1 = Sequential(name='md1')
md2 = Sequential(name='md2')
md1.add(BatchNormalization(axis=1, input_shape=(10, 520)))
md2.add(BatchNormalization(axis=1, input_shape=(10, 520)))
md1.add(Conv1D(512, 1, padding='causal', activation='relu', name='conv1_f1_s1'))
md2.add(Conv1D(512, 3, padding='causal', activation='relu', name='conv1_f3_s1'))
md1.add(TimeDistributed(Dense(512, activation='relu')))
md2.add(TimeDistributed(Dense(512, activation='relu')))
merge_1 = Sequential(name='merge_1')
merge_1.add(Merge([md1, md2], mode='concat'))
merge_1.add(MaxPooling1D(name='mxp_merge'))
merge_1.add(Dropout(0.2))
merge_1.add(Dense(512))
merge_1.add(pRelu)
merge_1.add(Flatten())
md3 = Sequential(name='md3')
md3.add(BatchNormalization(axis=1, input_shape=(10, 520)))
md3.add(Conv1D(512, 1, padding='causal', activation='relu', name='conv1_f1_s1_2'))
md3.add(MaxPooling1D())
md3.add(Dense(256))
md3.add(Flatten())
model = Sequential(name='final_model')
model.add(Merge([merge_1, md3], mode='concat'))
model.add(Dense(2))
model.add(Activation('softmax', name='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam',
metrics=['accuracy'])
return model
if __name__ == '__main__':
X = np.random.rand(2000, 10, 520)
Y = np.random.rand(2000, 2)
model = config_model()
tbCallBack = TensorBoard(
log_dir='tb_logs', histogram_freq=4, write_graph=True,
write_grads=True, write_images=True)
model.fit([X]*3, Y, epochs=10, batch_size=100, callbacks=[tbCallBack])
model.save('model.h5')
model2 = config_model()
model2.load_weights('model.h5')
model2.save('model2.h5')
Result:
-rw-r--r-- 1 root root 3762696 Aug 2 11:57 model2.h5
-rw-r--r-- 1 root root 23983824 Aug 2 11:57 model.h5
rrki
on 2 Aug 2017
@Dapid I tried save_weights() and it looks correct from the model file sizes. (but why?)
I guess the problem I'm facing is, I trained a huge model which took one week, but in previous code I did model.save(). Now what should be the right way to load this model from disk?
rrki
on 2 Aug 2017
@rrki your example doesn't work for me:
Using TensorFlow backend.
file.py:22: UserWarning: The `Merge` layer is deprecated and will be removed after 08/2017. Use instead layers from `keras.layers.merge`, e.g. `add`, `concatenate`, etc.
merge_1.add(Merge([md1, md2], mode='concat'))
Traceback (most recent call last):
File "/home/david/.virtualenv/py35/lib/python3.5/site-packages/tensorflow/python/framework/common_shapes.py", line 671, in _call_cpp_shape_fn_impl
input_tensors_as_shapes, status)
File "/usr/lib64/python3.5/contextlib.py", line 66, in __exit__
next(self.gen)
File "/home/david/.virtualenv/py35/lib/python3.5/site-packages/tensorflow/python/framework/errors_impl.py", line 466, in raise_exception_on_not_ok_status
pywrap_tensorflow.TF_GetCode(status))
tensorflow.python.framework.errors_impl.InvalidArgumentError: Dimensions must be equal, but are 5 and 512 for 'dense_3/add' (op: 'Add') with input shapes: [?,5,512], [1,512,1].
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "file.py", line 45, in <module>
model = config_model()
File "file.py", line 25, in config_model
merge_1.add(Dense(512))
File "/home/david/.virtualenv/py35/lib/python3.5/site-packages/keras/models.py", line 469, in add
output_tensor = layer(self.outputs[0])
File "/home/david/.virtualenv/py35/lib/python3.5/site-packages/keras/engine/topology.py", line 596, in __call__
output = self.call(inputs, **kwargs)
File "/home/david/.virtualenv/py35/lib/python3.5/site-packages/keras/layers/core.py", line 840, in call
output = K.bias_add(output, self.bias)
File "/home/david/.virtualenv/py35/lib/python3.5/site-packages/keras/backend/tensorflow_backend.py", line 3479, in bias_add
x += reshape(bias, (1, bias_shape[0], 1))
File "/home/david/.virtualenv/py35/lib/python3.5/site-packages/tensorflow/python/ops/math_ops.py", line 838, in binary_op_wrapper
return func(x, y, name=name)
File "/home/david/.virtualenv/py35/lib/python3.5/site-packages/tensorflow/python/ops/gen_math_ops.py", line 67, in add
result = _op_def_lib.apply_op("Add", x=x, y=y, name=name)
File "/home/david/.virtualenv/py35/lib/python3.5/site-packages/tensorflow/python/framework/op_def_library.py", line 767, in apply_op
op_def=op_def)
File "/home/david/.virtualenv/py35/lib/python3.5/site-packages/tensorflow/python/framework/ops.py", line 2508, in create_op
set_shapes_for_outputs(ret)
File "/home/david/.virtualenv/py35/lib/python3.5/site-packages/tensorflow/python/framework/ops.py", line 1873, in set_shapes_for_outputs
shapes = shape_func(op)
File "/home/david/.virtualenv/py35/lib/python3.5/site-packages/tensorflow/python/framework/ops.py", line 1823, in call_with_requiring
return call_cpp_shape_fn(op, require_shape_fn=True)
File "/home/david/.virtualenv/py35/lib/python3.5/site-packages/tensorflow/python/framework/common_shapes.py", line 610, in call_cpp_shape_fn
debug_python_shape_fn, require_shape_fn)
File "/home/david/.virtualenv/py35/lib/python3.5/site-packages/tensorflow/python/framework/common_shapes.py", line 676, in _call_cpp_shape_fn_impl
raise ValueError(err.message)
ValueError: Dimensions must be equal, but are 5 and 512 for 'dense_3/add' (op: 'Add') with input shapes: [?,5,512], [1,512,1].
@Dapid What's your environment?
I'm using
Python 3.4.3
tensorflow-gpu (1.2.1)
Keras (2.0.6) <- which follows instructions from ISSUE_TEMPLATE
How comes I didn't get any error except for those Merge layer warnings?
rrki
on 3 Aug 2017

visualized via tensorboard...
rrki
on 3 Aug 2017
Ah, now it works, it must have been the image_data_format in the json.
I'll take a look. Thanks for the example.
Dapid
on 4 Aug 2017
Anyone solved the problem?
I found out when I used the statful RNN the code
open('my_model_architecture.json','w').write(json_string)
self.model.save_weights('my_model_weights.h5')
self.model.save('/home/tdk/models/LSTM_3layers_model_weights_2_Callback_%f.h5'%score)
temp = load_model('/home/tdk/models/LSTM_3layers_model_weights_2_Callback_%f.h5'%score)
y_load = temp.predict(self.validation_data[0])
temp2 = model_from_json(open('my_model_architecture.json').read())
temp2.load_weights('my_model_weights.h5')
y_load2 = temp2.predict(self.validation_data[0])
y_show = self.model.predict(self.validation_data[0])
y_show was different from y_load and y_load was same as y_load2.
When I set the statful False. I can get the same y_show and y_load. However, when I open another python, and try to get the prediction, the prediction seems to be random as @lotempeledGong described.
The other code is thatmodel = model_from_json(open('my_model_architecture.json').read())
model.load_weights('my_model_weights.h5')
a = model.predict(test_data)
np.savetxt("test_predict.txt",a)
I don't know how to solve it, anyone has idea? or do I misuse something?
 TingDaoK
on 23 Aug 2017
TingDaoK
on 23 Aug 2017
@rrki sorry, I forgot about this. The difference is the optimizer and gradients. model.save saves both, when you use model.load_weights you ignore the optimizer from the file, and hence it is not saved.
If you have pytables installed you can use the CLI ptdump and pttree to inspect the content of the files.
Dapid
on 23 Aug 2017
In case anyone is still running into this problem, I was dealing with this for a while because I did not realize Python 3.3 and up has non-deterministic hashing between runs (https://stackoverflow.com/questions/27954892/deterministic-hashing-in-python-3). I was doing my own preprocessing through nltk, and then using the native Python hash method to convert words to integers before passing them to my Embedding layer, which ended up being the issue of non-determinism.
 rsmith49
on 31 Aug 2017
rsmith49
on 31 Aug 2017
I'm still with this issue.
It has no difference between load and not load weights.
Both weights are the same.
I just don't know what to do, since I already tried load_model and load_weights
I'm using tf and keras btw...
 jrzmnt
on 4 Sep 2017
jrzmnt
on 4 Sep 2017
Facing exactly the same issue while saving and loading the model itself or the weights of it.
Both resulting in completely different results.
Python: v3.5.3
Tensorflow: v1.3.0
Keras: v2.0.8
 sanosay
on 10 Sep 2017
sanosay
on 10 Sep 2017
Hi all,
I've just finished fighting the battle with this problem and overall not having consistent results while using evaluate_generator (if I execute it multiple times in a row, the results vary). With me the problem was the following -batch_size was not a divisor of number_of_samples! It took me ages to figure this one out -
steps = math.ceil(val_samples/batch_size)
Due to the fact that the batch_size was not a divisor of number_of_samples I assume it took different samples to fill in the last step. Some small errors occured also from using workers variable - using GPU it makes no sense to actually use it. Once I used a real divisor of the val_samples it worked like a charm and reproducible - before and after loading!
 DiplEng
on 13 Sep 2017
DiplEng
on 13 Sep 2017
Unfortunately nothing that I tried helped.
Still face the same issue.
Even on a really simple example like this:
Train
model = Sequential()
model.add(Conv2D(16, (4, 4), padding='same', input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Flatten())
model.add(Dense(2))
model.add(Activation('softmax'))
optimizer = RMSprop()
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
model.fit(x_train,y_train,epochs=10)
print(model.evaluate(x_val, y_val))
model.save('test.h5', overwrite=True)
Output:
[1.0409752264022827, 0.67000000047683717]
Now loading the model back again
Test
```python
from keras.models import load_model
model = load_model('test.h5')
print(model.evaluate(x_val, y_val))
````
Output:
[0.72732420063018799, 0.26000000000000001]
_That's just for demonstration_
- Python: v3.5.3
- Tensorflow-GPU: v1.3.0
- Keras: v2.0.8
Edit:
Just to be sure, I also tried with my training dataset [aka: evaluate the model before and after saving with the same dataset that I used for training.]
Output 1: same session:
{'acc': 0.73999999999999999, 'loss': 0.57565217232704158}
Output 2: load_model / weights:
{'acc': 0.88403865378207269, 'loss': 0.59617107459932062}
sanosay
on 13 Sep 2017
@sanosay Thank you for providing a full example, but I cannot reproduce. Can you provide some data?
from keras.models import load_model, Sequential
from keras.layers import Conv2D, Activation, Flatten, Dense
from keras.optimizers import RMSprop
import numpy as np
x_train = np.random.randn(100, 10, 10, 2)
y_train = np.zeros((100, 2))
y_train[:, np.argmax(np.median(x_train, axis=(1, 2)), axis=1)] = 1.
x_val = np.random.randn(30, 10, 10, 2)
y_val = np.zeros((30, 2))
y_val[:, np.argmax(np.median(x_val, axis=(1, 2)), axis=1)] = 1.
model = Sequential()
model.add(Conv2D(16, (4, 4), padding='same', input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Flatten())
model.add(Dense(2))
model.add(Activation('softmax'))
optimizer = RMSprop()
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
model.fit(x_train,y_train,epochs=10)
print(model.evaluate(x_val, y_val))
model.save('test.h5', overwrite=True)
model = load_model('test.h5')
print(model.evaluate(x_val, y_val))
Gives:
[1.4226549863815308, 0.63333332538604736]
[1.4226549863815308, 0.63333332538604736]
Python: v3.5.4
Tensorflow: v1.3.0
Keras: v2.0.8
I'll test on the GPU.
Dapid
on 14 Sep 2017
@Dapid Unfortunately due to the nature of the dataset [medical] I have no license to upload them anywhere.
Dataset size is: 6002 images and 500 validation images
Images: 64x64x3
I also noticed something really strange [just now]:
Training a different model [same dataset] for different epoch numbers I get :
5 epochs
{'metrics':{'acc': 0.96867710763078974, 'loss': 0.10006937423370672}}
After
{'metrics': {'acc': 0.11596134621792736, 'loss': 0.73292944400320847}}
10 epochs:
Before:
{'metrics': {'acc': 0.98367210929690108, 'loss': 0.045077768838411421}}
After:
{'metrics': {'acc': 0.11596134621792736, 'loss': 1.1414862417133995}}
The accuracy remains the same, while loss is changing.
I tried the same model [and different models] on different machines, and having the same issue.
_Also tried the same with tensorflow and tensorflow-gpu, just in case_
sanosay
on 14 Sep 2017
What do you get with my synthetic data? Is it consistent? I can play with the sizes and number of images to see if I can get it to misbehave.
Dapid
on 14 Sep 2017
@Dapid That is indeed strange, I with your generated dataset [seed to 0] and I can't reproduce it.
I also tried adjusting it to 1001 instead of 100 and 302 instead of 30 [to see if it's affected somehow by batch size etc]. No issue with the results.
I then tried with a different dataset (cifar10) and I get inconsistent results
sanosay
on 14 Sep 2017
Ok, CIFAR is good, I can see if it works funny for me.
Dapid
on 14 Sep 2017
Which model are you using on CIFAR?
from keras.models import load_model, Sequential
from keras.layers import Conv2D, Activation, Flatten, Dense
from keras.optimizers import RMSprop
import numpy as np
from keras.datasets import cifar10
(x_train, y_train), (x_val, y_val) = cifar10.load_data()
model = Sequential()
model.add(Conv2D(16, (4, 4), padding='same', input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Flatten())
model.add(Dense(10))
model.add(Activation('softmax'))
optimizer = RMSprop()
model.compile(loss='sparse_categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
model.fit(x_train,y_train,epochs=10)
print(model.evaluate(x_val, y_val))
model.save('test.h5', overwrite=True)
model = load_model('test.h5')
print(model.evaluate(x_val, y_val))
[14.506285684204101, 0.10000000000000001]
[14.506285684204101, 0.10000000000000001]
I experience the same phenomenon. After saving saving and loading the weights the loss value increases significantly.
Moreover, I don't get consistent behaviour when loading the weights. For the same model weight file, I get dramatically different results every time I load it in a different Keras session. Can it be something linked to numerical precision?
I'm using Keras 2.0.8. Unfortunately I don't know how how to provide a minimal working example.
 darteaga
on 19 Sep 2017
darteaga
on 19 Sep 2017
I'm also having the performance issues when saving and loading a model.
 fmv1992
on 10 Oct 2017
fmv1992
on 10 Oct 2017
I'm facing the same issue, Any idea how to fix this?
 saeedalahmari3
on 15 Nov 2017
saeedalahmari3
on 15 Nov 2017
I'm facing the same problem.
I have an LSTM layer in the model
I verified that the weights are loading properly by comparing them before and after with bcompare. But the output results are different after loading the weights.
Before introducing the LSTM layer my results were reproducible.
 lakshmiprasadvk
on 24 Nov 2017
lakshmiprasadvk
on 24 Nov 2017
I'm having the same issue with the value of the loss function after reloading a model, as described by @darteaga. My model was saved via ModelCheckPoint with both save_best_only and save_weights_only being False. It was then loaded with keras.models.load_model function, which then gave significantly high loss value during the first training epochs.
I'm using python3 and keras 2.0.8. Any suggestion how to fix this would be highly appreciated.
 natuan
on 28 Nov 2017
natuan
on 28 Nov 2017
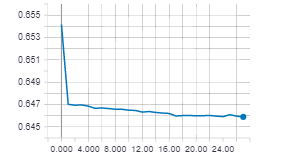
I have the same issue. See attachment. Model was reloaded at epoch 51 as well as few times around 3-5. I do not have a LSTM layer.

 hankbeasley
on 29 Nov 2017
hankbeasley
on 29 Nov 2017
My network is based on xception for transfer learning. From the following thread, the issue might be due to tensorflow with python3: https://github.com/tensorflow/tensorflow/issues/6683
@pickou: "I train and store the model in python2, and restore it using python3, it got terrible result. But when I restore the model using python2, the result is good. Train and store in python3, I got awful result."
natuan
on 29 Nov 2017
I tried python 2.7.12 with tensorflow 1.2, 1.3 and 1.4 (master), Keras 2.1.1, Ubuntu 16.04 LTS and I still have the same issue with unexpected high loss value after reloading the model.
natuan
on 29 Nov 2017
Chiming in. I'm running into the same problem, but it's GPU implementation only from what i've seen. I trained a model on both CPU and GPU. Saved them off. Then tested them in a cross.
Train v Test : Result
CPU v CPU : saved model and loaded model agree
CPU v GPU : saved model and loaded model disagree
GPU v CPU : saved model and loaded model disagree
GPU v GPU : saved model and loaded model disagree
I'm going to attempt the suggestions and see if they resolve the issues
I should be more specific. I train and save the model in one session, then open another session, load the saved model and test on the same data. I can't share the data unfortunately, but the model is a relatively simple sequential FFNN. No recurrence or memory neurons.
 vickorian
on 30 Nov 2017
vickorian
on 30 Nov 2017
I did some more testing to see what was happening. I think this is an issue with jupyter notebook and keras/tensorflow interacting in a manner which is not predicted.
To test, i created and trained identical models in both an external file and in a jupyter notebook. I saved off their predictions, and the model itself using the self.save() method inherent to Keras models. Then in another file/notebook I loaded the test data used in the training file/notebook, loaded the model from their respective training partner, loaded the saved predictions, and then used the loaded model to create an array of predictions based on the test data.
I took the difference of the respective predictions, and found that for the files created in an IDE and run via command line, the results are identical. The difference is zero (to machine tolerance) between the predictions created in the training file and the predictions created by loading the saved model.
For the Jupyter Notebook version though, this isn't true. There is significant difference between the training file predictions and the loaded model predictions.
Interesting note though, is that when you load the model trained and saved via command line and the predictions created via command line in a jupyter notebook and take the difference there, you find it is zero.
Using the model.model.save() method also results in incorrect results in a jupyter notebook.
Using keras.save_weights() generates the exact values found in model.save() in a jupyter notebook.
Using the manual_variable_initialization() method suggested by @kswersky may be a work around, but it seems like a bit of a clever hack for something that should work out of the box. I haven't gotten it to work using just Keras layers though.
vickorian
on 1 Dec 2017
@vickorian,
Thanks for your efforts.
If I understood correctly you connect the error with mixing saving/loading in
different programs (command line and jupyter for example).
If that is the case then my example is a counter example.
My layout was that I trained several models (~100), recorded some statistics
and then saved them. At a later point I wanted to record some more statistics
on them so I loaded them up. The strange thing is that not every re-loaded
model had its scores mixed up just some of them. In any case all this process
was done through an Anaconda Prompt on Windows.
fmv1992
on 1 Dec 2017
No, the problem is with just the notebooks. If you save on a notebook, you'll get bad results
vickorian
on 1 Dec 2017
Hello guys,
I was facing the same issue until I set my ModelCheckpoint to save only weights (save_weights_only=True).
e.g.:
checkpoint = ModelCheckpoint(file_path, monitor='val_acc', verbose=1, save_best_only=True, mode='max', save_weights_only=True)
After this, I tested my best model using a python script through the terminal, and I got a good prediction.
jrzmnt
on 1 Dec 2017
I haven't run the model checkpointing at all. I have been just training model by creating files and running python from command line instead of using Notebooks.
vickorian
on 1 Dec 2017
Having the same issue. Trained a Keras LTSM model, saved the weights. Start a new standalone process reconstructing the model and loading the weights to check evaluation/prediction result, and it gets a different result every time it runs unless I fix numpy random seed.
 chunsheng-chen
on 1 Dec 2017
chunsheng-chen
on 1 Dec 2017
@chunsheng-chen will you try writing a stand-alone file and run it from command line to see if you get different results? Also, when do you fix the random seed? Is it immediately after importing numpy?
vickorian
on 2 Dec 2017
@vickorian,
My issue's methodology was exactly that:
- Ran file from command line.
Fixed the numpy random seed after the imports, as a first statement on the
main()function. E.g.:import numpy as np def main(): np.random.seed(0) # Rest of code if __name__ == '__main__': main()
fmv1992
on 4 Dec 2017
@fmv1992
Interesting. Your models were still getting errors even when run from command line. My test setup is Ubuntu 16.04. I have the samba server set up so I can do further testing for my process on windows without much trouble.
The errors disappear when you set the random seed?
vickorian
on 4 Dec 2017
@vickorian,
They did not go away. I have set both numpy and python random seeds.
Unfortunately I'm developing at work so I feel uncomfortable to post the entire
code here. But the idea is that I have several functions of the type:
def myfunc(shape):
n_lines, n_columns = shape
model = Sequential()
model.add(Dense(
np.random.randint(1000, 2000),
input_dim=n_columns,
activation='sigmoid',
kernel_initializer='glorot_uniform',
bias_initializer='Zeros',
use_bias=True))
model.add(GaussianDropout(0.2))
model.add(Dense(1, activation='sigmoid'))
optimizer = SGD(lr=0.1, momentum=0.6, decay=1e-4, nesterov=True)
model.compile(loss='binary_crossentropy', optimizer=optimizer,
metrics=[auc2])
return model
which get trained in a for loop then saved with:
model.save(model_full_name)
After saving all of them get loaded and then evaluated. So no direct
evaluation after training. All go through the serialization/de-serialization
stage.
The puzzling results are in the attached image. See that many of the models
have a ROC AUC of ~ 0.5 and this is out of the trend of the overall plot. This
image brought me here.

I have tried several workarouds cited here and some place else but none of them
worked.
Also as you can see the loading error does not happen for 100% of the cases
(i.e. some models have reasonable ROC AUCs).
fmv1992
on 5 Dec 2017
@fmv1992
It would be interesting to see the ROC AUC scores when tested before serialization. Is that possible?
vickorian
on 7 Dec 2017
I meet the same problem.
Keras: 2.0.4
Jupyter notebook
Tensorflow-gpu:Version: 1.3.0
Model:
def create_UniLSTMwithAttention(X_vocab_len, X_max_len, y_vocab_len, y_max_len, hidden_size, num_layers, return_probabilities = False):
# create and return the model for unidirectional LSTM encoder decoder
model = Sequential()
model.add(Embedding(X_vocab_len,300, input_length=X_max_len,
weights = [g_word_embedding_matrix],
trainable = False,mask_zero = True))
for _ in range(num_layers):
model.add(LSTM(hidden_size,return_sequences = True))
model.add(AttentionDecoder(hidden_size,y_vocab_len,return_probabilities = return_probabilities))
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
return model
Actions like:
- Model loss =1.2
- save_weights
- create model
- Restart kernel
- Create Model
- load_weights
- Loss = 2.4
 darcula1993
on 11 Dec 2017
darcula1993
on 11 Dec 2017
@vickorian,
I'm trying to revive the code. Will post the results here as soon as I have
them.
However I think that the problem is pretty much "established" and I fail to see
how those results would help.
And unfortunately this issue is a real show stopper. If you are using Keras for
your homework assignment and training a 5 minute model this is not an issue.
However if you are on an enterprise setting this is a huge deal as the
models will necessarily be serialized to be transferred to a "production
environment" or something. And also the entire project reputation becomes
jeopardized by this behavior.
And please, please don't get me wrong. Keras seems to be a great project.
Indeed it is very unfortunate that this is happening. I want to be as helpful
as possible.
One thing really bothers me though: Why don't use the simple pickle module?
Best,
fmv1992
on 11 Dec 2017
It seems that Keras will not overwrite the existed model file. Tried to use early stopping and save only model after stopping. Make sure your model directory is empty before training. I had similar issue and this solved my problem. Hope it helps.
 ryanzh-cr
on 11 Dec 2017
ryanzh-cr
on 11 Dec 2017
@ryanzh13 Yes I save_weights after training stop and I make sure there is no other file in the directory. The training take 8 hours and I can only pray the instance won't be corrupted.
darcula1993
on 11 Dec 2017
@darcula1993 Have you tried save instead of save_weights? Another thing is to try the code on a smaller dataset and less epochs. Also, you can print out the model.summary() to see if the model parameters are the same before saving and after loading.
ryanzh-cr
on 11 Dec 2017
@ryanzh13 Since there is a custom layer, I didn't. I will give it a try when I finish the training and submit my assignment. I already past the deadline.
darcula1993
on 11 Dec 2017
I'm also having a problem saving my model or my weights. They "save" but when loaded back in the values are clearly garbage. For saving weights I tried reloading them into a replica model architecture and then doing a batch of predictions, results in junk values. I tried saving a full model with model.save() and reloading it and running a prediction gives junk values. The only time my prediction results look valid is while in the same run(session) and when not saving the whole model. If I try to save the whole model then even the same run predictions are junk. So something is happening when saving the model and/or loading the model. My model consists of regular Conv2d, max pooling, and dense layers. I'm guessing something is happening either to the weights or the training config data. I'm still new to all this so I'm not sure but the model consists of three things right: weights, training config, structure? I should also specify that I'm using the model.predict_generator() for my predictions.
Ubuntu 16.04 LTS
Tensorflow v1.4.1
Keras v2.1.2
Python 2.7 (anaconda)
 npocodes
on 15 Dec 2017
npocodes
on 15 Dec 2017
@rsmith49 Thanks for your solution, I faced the same problem when training a text classifier using LSTM. Already got stuck for a long time and I found the problem is the word dict: I didn't enforce the dict to have the same id for one word in different session, the solution is either dump the dict using pickle or sort the words before assigning id to them.
 cjqw
on 24 Dec 2017
cjqw
on 24 Dec 2017
I also had the problem of constant output after loading a model at Keras 2.0.6.
I've upgraded to Keras 2.1.2 and used the preprocess_input and now it works.
Below is the output of the model with and without using the preprocess_input function.
Using preprocess_input at Keras 2.0.6 didn't work for me and I had to upgrade to Keras 2.1.2.
Output:
Without Preprocess:
[[ 0. 1. 0.]]
[[ 0. 1. 0.]]
With Preprocess:
[[ 5.07961657e-24 1.00000000e+00 3.09985791e-28]]
[[ 0.00508418 0.00213011 0.99278569]]
from keras.preprocessing.image import load_img, img_to_array
from keras.applications.imagenet_utils import preprocess_input
import matplotlib.pyplot as plt
from keras.models import Model, load_model
import numpy as np
def readImg(filename):
img = load_img(filename, target_size=(299, 299))
imgArray = img_to_array(img)
imgArrayReshaped = np.expand_dims(imgArray, axis=0)
imgProcessed = preprocess_input(imgArrayReshaped, mode='tf')
return img, imgProcessed
def readImgWithout(filename):
img = load_img(filename, target_size=(299, 299))
imgArray = img_to_array(img)
imgProcessed = np.expand_dims(imgArray, axis=0)
return img, imgProcessed
sidesModel = load_model('C:/Models/Xception.hdf5', compile=False)
img1, arr1 = readImgWithout('c:/Test/image1.jpeg')
img2, arr2 = readImgWithout('c:/Test/image2.jpeg')
prob1 = sidesModel.predict(arr1)
prob2 = sidesModel.predict(arr2)
print('Without Preprocess:')
print(prob1)
print(prob2)
img1, arr1 = readImg('c:/Test/image1.jpeg')
img2, arr2 = readImg('c:/Test/image2.jpeg')
prob1 = sidesModel.predict(arr1)
prob2 = sidesModel.predict(arr2)
print('With Preprocess:')
print(prob1)
print(prob2)
 DawnMe
on 31 Dec 2017
DawnMe
on 31 Dec 2017
I was able to resolve this issue by adapting my preprocessing pipeline.
I tried saving the model, clearing the session, then loading the model, and then calling the prediction function on the training and validation sets from when I trained the model. This gave me the same accuracy.
If I imported exactly the same data, but preprocessed it again (in my case using a Tokenizer for a text classification problem) the accuracy dropped drastically. After some research, I assume this was because the Tokenizer assigns different ids to different tokens unless they are trained on exactly the same dataset. I was able to achieve my training accuracy (~.95) on newly imported data in a new session, provided I used the same Tokenizer to preprocess the text.
This may not be the underlying problem for all above cases, but I suggest checking your preprocessing pipeline carefully and observing if the issue remains.
 ludwigthebull
on 8 Jan 2018
ludwigthebull
on 8 Jan 2018
I'm facing the same issue.
If I recreate the model (ResNext SE from https://github.com/titu1994/keras-squeeze-excite-network) from scratch and use load_weights and then use model.predict everything works as expected. If I use load_model first and then use load_weights on top of that (I have different sets of weights) the model predicts garbage.
I checked that in both cases the weights are the same (through model.get_weights).
I use Keras 2.1.3 and Tensorflow 1.4.0
This works:
K.clear_session()
model=SEResNext(**model_params)
model.compile(Adam(1e-4), 'binary_crossentropy', metrics=[tf.losses.log_loss])
model.load_weights('1694.hdf5')
pred=model.predict(train_set)
print(log_loss(y_true=train_y,y_pred=pred))
This doesn't:
K.clear_session()
model=keras.models.load_model(model_name,custom_objects={'log_loss': tf.losses.log_loss})
model.load_weights('1694.hdf5')
pred=model.predict(train_set)
print(log_loss(y_true=train_y,y_pred=pred))
 sakvaua
on 18 Jan 2018
sakvaua
on 18 Jan 2018
After 2hrs of struggling, I found this inconsistency can be related to K.batch_set_value() not working if multiple python kernels (with tf imported) are running on the same machine, and resolved if all but one are closed.
 shouldsee
on 27 Jan 2018
shouldsee
on 27 Jan 2018
@ludwigthebull I am pickling the tokenizer and loading it to tokenize the text I want to predict, but I'm still getting random predictions. With your pipeline, are you running the model on the same session? If not, can you let us know how are you saving and loading the model?
 dterg
on 30 Jan 2018
dterg
on 30 Jan 2018
@dterg I am not running the model in the same session. I am loading and saving the model as an .h5 file using the standard model.save('model_name') and load_model('model_name') Keras functions. I should add that I am not pickling the Tokenizer but instead rebuilding the tokenizer each time I load data by having a large text file as the common reference for the tokenizer. This is inefficient, but I haven't gotten around to writing a function that pickles the Tokenizer for me (I don't think Keras has this option.) In your case, I would try to see if you can get the same predictions by loading the model in a new session, but instead of pickling the tokenizer, just recreating it in the new session by using a common text file for both the training and the prediction phase. It may be that your issue has to do with the way you are pickling the tokenizer. Hope that helps !
ludwigthebull
on 30 Jan 2018
I'm struggling again on the same problem on a different model. Both models consist on a series of linear convolutional filters (same filter reused many times) followed by non-linear convolutional filters. While training, after each epoch I save weights using the checkpoint callback.
Early in the training process I can load the weights saved to disk and I get reliable and consistent results, but beyond some training saved filter coefficients lead to almost random values of the loss function (as if there had been no training at all). Moreover the loss value is different every time I load the weights in a different Keras session.
I don't know what to do. Most workarounds suggested here rely on having LSTM layers (I don't have any) or data preprocessing (I don't do it). I find the problems while saving both the full model or only the weights.
I have built a few similar models and I haven't found this problem in all models consistently. Hence I don't know how to provide a minimally working example. I would be willing to do any testing to help solving the bug.
It is currently a major issue for me because I rely on Keras for my research and after this bug I have found myself unable to continue working.
I am using Keras 2.1.1 under Python 3.5.2. I have found the problem both with the Tensorflow (1.2.0) and Theano (0.9.0) backends.
darteaga
on 31 Jan 2018
please try first load the model and then the weigths using:
Save code
serialize model to JSON
model_json = model.to_json()
with open("model.json", "w") as json_file:
json_file.write(model_json)
serialize weights to HDF5
model.save_weights("model.h5")
print("Saved model to disk")
Load code
load json and create model
json_file = open('model.json', 'r')
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
load weights into new model
loaded_model.load_weights("model.h5")
print("Loaded model from disk")
reference:
https://machinelearningmastery.com/save-load-keras-deep-learning-models/
 pedroMoya
on 2 Feb 2018
pedroMoya
on 2 Feb 2018
The problem is: If you are using tokenizer (from Keras), because Keras applies an unique index for each word but then if you load the model and use tokenizer applies another index for each word. The solution is save the original word_index and then load to tokenizer with these index.
 alejandrods
on 9 Feb 2018
alejandrods
on 9 Feb 2018
I had the same problem. Turns out, the problem wasn't with my LSTM, but with my pre-trained word vectors. I preprocessed my corpus using FastText, and since it is a non-deterministic model, each run of Skip-Gram gives a different set of word vectors. Since we are dealing with LSTM, I'm pretty sure a lot of folks out there are doing some kind of word2vec. Make sure that your word vectors are the same each time. Hope this helps!
 taninaim
on 23 Feb 2018
taninaim
on 23 Feb 2018
I have the same issue:
I am trying to load a saved model in order to use it for predictions after I restart the kernel. While saving the model seems to work, loading does not seem to work without issues. Heres what I have done:
I have retrained a VGG16 model using Keras:
vgg16_model = keras.applications.vgg16.VGG16()
model = Sequential()
for layer in vgg16_model.layers[:-1]:
model.add(layer)
model.layers.pop()
for layer in model.layers:
layer.trainable = False
model.add(Dense(26, activation='softmax'))
model.summary()
model.compile(Adam(lr=.0000025), loss='categorical_crossentropy', metrics=['accuracy'])
Next I have trained the model:
model.fit_generator(train_batches,validation_data=validation_batches,
epochs=85, verbose=1,callbacks=[tbCallBack,earlystopCallback])
and finally I am saving my model like so:
model.save("model.h5")
Now when I restart the kernel and load the model again using:
from keras.models import load_model
new_model = load_model("model.h5")
While the model does load, I get a warning telling me:
C:\Users...Anaconda2envs\tensorflow-gpu\lib\site-packages\kerasmodels.py:291:
UserWarning: Error in loading the saved optimizer state. As a result,
your model is starting with a freshly initialized optimizer.
warnings.warn('Error in loading the saved optimizer '
Furthermore, when I use the loaded model for predictions, I get wrong values (very different values from the one I trained) and it appears that the model has not been trained at all. However, when I check .get_weights I see that weights have been loaded.
I have also tried to save and load the model via json and weights only like so:
# serialize model to JSON
model_json = model.to_json()
with open("model.json", "w") as json_file:
json_file.write(model_json)
# serialize weights to HDF5
model.save_weights("model_weights.h5")
and loading:
#load json and create model
json_file = open('model.json', 'r')
loaded_model_json = json_file.read()
json_file.close()
load_model = model_from_json(loaded_model_json)
# load weights into new model
load_model.load_weights("model_weights.h5")
While loading the model this way does not throw me an error message, I still get predictions much worse than my previously trained model. In order to ensure that the model loading works I did the following:
I checked the weights of the trained model and the loaded model and they appear to be the same.
Also checking the models summary "model.summary()" displays the same architecture.
So to my understanding, having the same architecture and the same weights should yield the same model i.e. results - but I can't figure out why this is not the case
What baffles me even further is that when I use model.get_weights() and model.set_weights() it works perfectly, e.g.:
#getting weights from the old model
weights = model.get_weights()
# setting weights of the new model
new_model.set_weights(weights)
Hence, my current workaround involves saving the weights in as a numpy (.npy) file and loading it, once I restart my kernel
# saving
the_weights = model.get_weights()
np.save("weights_array", the_weights)
# loading upon restarting the kernel
the_weights = np.load('weights_array.npy')
new_model.set_weights(trained_weights)
Maybe this is helpful for some of you as well!
 aarondt
on 26 Feb 2018
aarondt
on 26 Feb 2018
Hi everyone
I've got exactly the same issue previously. The saved keras model works fine in the same session, but completely random result in other session.
However I finally found that it was this snippet of code that messed up the result.
data = open(filepath, encoding='utf-8').read().lower()
uniq = set(data)
# mapping
ch2idx = {word: idx for idx, word in enumerate(uniq)}
idx2ch = {idx: word for idx, word in enumerate(uniq)}
My model is using RNN to generate human's name, so I created a mapping from character to index.
However, according to this link, the set function will return different result in different console/session since Python 3.3, so even the model remains the same, this wrong mapping rule will map id to the wrong character, and the result seems random.
For those who have the same issue as mine, please check if any other environment variable related to your model is unchanged, or even your model is identical, other related variable will also mess up your prediction result.
 KaitoHH
on 28 Feb 2018
KaitoHH
on 28 Feb 2018
Is there any solution to this issue? I am running across the same issue, I am training a model on AWS. Every epoch takes about an hour to run, and I am not able to save the model. Is there any workaround to it?
I have also tried saving and loading weights, and the model as a json file, none of them seem to work.
Does the numpy workaround work? Sadly, I have to retrain my model and would really love to find a solution to this issue.
 durgasury
on 6 Mar 2018
durgasury
on 6 Mar 2018
I have solved this problem because we have to save the word_index in addition to the model. The reason is because when you use the predict you have to tokenize the sentence also but you have to apply the same index that in the previous word_index.
alejandrods
on 6 Mar 2018
@alejandrods I am working on an image prediction model, so I don't think tokenizing applies here. I have checked for the order of output classes though, and they are the same through different runs.
durgasury
on 7 Mar 2018
Just to make things a little stranger - I'm training an image classifier using Xception with bottleneck features (saving in one session, then testing in another). When I save and load my classifier layers (a separate sequential model) things work well. When I have the classifier layers attached to the base network and only train those layers it also works. However in the latter case if I let any of the base network layers train then the results I get look like the weights have been randomly initialized.
One of the things I tried was to train the classifier layers only then let the last convolutional block train for one epoch at the end before saving - the results looked half way between randomly initialized and the bottleneck results. Training for any longer and it looks almost like a complete re-initialization. This is not a learning rate problem due to the 20% difference in accuracy score between validation accuracy during training and with reloading. It kinda looks like some weights are saving/loading and others are not.
Update:
I've compared the weights for each corresponding layer between the two networks and they are identical. This is the case both before and after calling model.evaluate_generator().
Update:
Well I have managed to get this to work by recompiling the model after every change (trainable flags, loading weights, etc..).
model.compile(optimizer=model.optimizer, loss=model.loss, metrics=model.metrics).
Although I don't think that this fully explains the problem I was seeing as the issue regressed after trying to tidy up the code a bit.
 shinstra
on 7 Mar 2018
shinstra
on 7 Mar 2018
I am also experiencing same problem.
I trained a model on a machine with GPU using CudnnGRU, I saved the model weights. I then rebuilt a model with similar architecture but this time with GRU on machine with just CPU. I loaded the saved weights on to this new model and I see different prediction results.
Sadly, I cannot use the numpy work around as the shape of the weights change from CudnnGru to GRU.
 SatishDivakarla
on 8 Mar 2018
SatishDivakarla
on 8 Mar 2018
I have same issue here.
Loading weight and evaluating model yields poor results.
What is interesting that if I start training again, after one epoch loss goes back to the correct value from previous training:
My setup:
- I'm not using any custom layers.
- Windows 10
- Using GPU
- Keras 2.1.3
- tensorflow-gpu 1.5.0
- python 3.6.4
 Ajk4
on 9 Mar 2018
Ajk4
on 9 Mar 2018
The gotcha I found was that when using a sub-model in a Lambda layer (and nowhere else) the weights corresponding to the sub model were not saved. My hacky solution:
layer = L.Lambda(func_including_model)
layer.trainable_weights = included_model.trainable_weights
layer.non_trainable_weights = included_model.non_trainable_weights
I also needed to add updates for batch norm.
 mharradon
on 23 Mar 2018
mharradon
on 23 Mar 2018
@mharradon that sounds serious, can you report a bug with an example?
Dapid
on 23 Mar 2018
I've opened a new issue with reproducing code: https://github.com/keras-team/keras/issues/9740
mharradon
on 23 Mar 2018
One possible trigger for this that I've found comes from the keras auto layer naming (i.e. if you don't explicitly give a layer a name then you get one that is indexed based on the number of times that layer has been created in that session). If you build your model(s) slightly differently or in a different order between train and test time code then these auto named layers may have a different name to what is stored in the weights file. This of course means that the load weights by name flag will be useless in this case, and also explains why the numpy save/load weights solution works for some people.
The safest way to avoid this case is to save the model architecture as well as the weights - then in the second session create the model directly from that save:
Saving Model
# Architecture
with open("model.json","w") as f:
f.write(model.to_json())
f.close()
# Weights
model.save_weights("model.hdf5")
Loading Model
# Architecture
with open("model.json","r") as f:
json_str = f.read()
f.close()
model = keras.models.model_from_json(json_str)
# Weights
model.load_weights("model.hdf5")
Hopefully this is helpful for some people.
This solution has only fixed one manifestation of this problem in my code. I'll post the solution to the other instance if I manage to work it out.
shinstra
on 28 Mar 2018
I have also found that fine-tuning batch-norm layers can also result in this problem (in Xception at least - haven't tested with the other BN models yet). My stop-gap solution is to freeze the BN layers using the method in #7085 while I get my head around why the BN is not working in my case.
shinstra
on 5 Apr 2018
I think someone said it before, but I'll comment anyway just in case someone has the same situation in the future.
I made a script with multiple calls to fit in order to train a model on multiple smallish files in batches. In order to save the state of the model for each next call to fit, I had to somehow save the model. I realized that saving and loading the model with model.save() and load_model() wasn't working, and I couldn't figure out why.
I tried saving the architecture and weights separately, which didn't work either, and finally decided to change my script in order to be able to train the model progressively without saving the model, but of course at the end of the session I would lose the progress.
Finally, I realized that the problem was just that Keras won't overwrite an existing file, so I would save the first model calling it 'Model.h5py' or whatever, and then load it in each call to fit, starting again from a very low accuracy each time. To solve this, I just made sure that the Model is saved differently each time, adding a counter to my script.
 ja-94
on 19 Apr 2018
ja-94
on 19 Apr 2018
This is unlikely to be the root cause. Because Keras actually does overwrite the old file in normal cases.
dipanjannag
on 20 Apr 2018
@KaitoHH Thank you for the solution. I experienced the issue, spent easily 3 hours. At the end it was caused by the set function returning different order per session.
 enriqueav
on 16 May 2018
enriqueav
on 16 May 2018
I'm having similar issues to the original problem where I am saving model weights, but when I load up the weights again, it's predicting essentially random probabilities. Has there been a fix to this yet? Thanks.
 alexc2684
on 13 Jul 2018
alexc2684
on 13 Jul 2018
@enriqueav Thanks, I had the same problem, my sample list was in different order per session due to python set. Thus my LSTM would have its accuracy reduced to baseline when I loaded the weights.
 devssh
on 14 Jul 2018
devssh
on 14 Jul 2018
I have similar problems. I use the sample code in Keras documentation as following to save and reload model and weights, but the reloaded model get wrong. The model has around 1000 layers, and I think the problem is possibly caused by the mismatch between weights and layers when newmodel.set_weights(weights). Is there any solution to it?
json_string = model.to_json()
weights = model.get_weights()
newmodel = model_from_json(json_string)
newmodel.set_weights(weights)
 hangweiqiang
on 3 Aug 2018
hangweiqiang
on 3 Aug 2018
Hi guys, I got a similar issue with Tensorflow backend for Keras, and the new nightly built version solved the problem. Not sure whether it may help this issue.
 ybsave
on 30 Aug 2018
ybsave
on 30 Aug 2018
I have re-encountered the same bug in a totally different model. The model is https://arxiv.org/abs/1703.09452, basically consisting on a series of 1D convolutional layers with skip connections (the full model is a GAN but for the time being I'm just training the generator). So there are no recurrent layers, no preprocessing, nothing fancy.
One thing that I noticed, both with this model and the previous one, is that with a small amount of training the loss almost doesn't increase after saving and loading, but the more the model is trained the more the loss function increases after saving and loading. Could it be anything related to machine precision?
What I have tried so far:
- Give a explicit name to the model layers, and load by name (the increase in the loss function seems to be even greater in this case)
- Setting PYTHONHASHSEED=0 as a an environment variable.
darteaga
on 2 Oct 2018
@darteaga do you have batchnorm layers? I found them to be problematic in #10784
Dapid
on 2 Oct 2018
@Dapid No, I don't have batchnorm layers... The only layers I have are:
- Conv2D
- PReLU
- Conv2DTranspose
- Add
- Reshape
- Conv1D
Sequential layers with skip connections.
Thank you very much.
darteaga
on 2 Oct 2018
Is there any known solution or workaround?
I can't publish the exact code or the data, but I'm willing to help in testing / debugging.
This is a stopper bug for me that I have hit twice with two different models. If unresolved, I'll need to switch to a different DL framework.
darteaga
on 3 Oct 2018
Can you check the weights of the original and re-loaded model? They should match exactly.
Dapid
on 3 Oct 2018
@Dapid Good idea. I have done the following test:
- Reloading the weights of the model
- Saving them again with save_weights()
Then I have compared the original and re-loaded model weights in the hdf5 file (with the tool h5diff) and I have found that they are _identical_.
darteaga
on 3 Oct 2018
@darteaga can you check it on the model loaded? It is possible that some weights are being transposed wrongly when reading from the HDF5.
Dapid
on 3 Oct 2018
@Dapid How can I do this test that you propose? If I look at the weights with model.weights I seen tensorflow tensors, and I don't know how to compare them (thank you very much, btw).
darteaga
on 3 Oct 2018
@darteaga
from keras import backend as K
K.batch_get_value(m.weights[0])
@Dapid Thanks. By looking at this, I discovered that in my case the issue this time is related to using multi_gpu_model, and the template and multi-gpu models apparently not sharing the weights. I am still investigating, and I will post the results here when I am done.
darteaga
on 5 Oct 2018
In my case the root cause of the problem was using multi_gpu_model. I have found a bug with cpu_relocation. I have opened another issue: https://github.com/keras-team/keras/issues/11313
darteaga
on 8 Oct 2018
I'll give a detail description below.
keras: 2.2.2
tensorboard: 1.10.0
tensorflow-gpu: 1.10.1
"RNN problem?"
I have the same problem when using a model textcnnbelow to do text classify:(just prove it's not a rnn problem)
All layer is trainable, I saved my model at best f1 score 0. 8719, and load my best model to predict same validate dataset but got different score '0.8636'.
"Your models have the different parameter."
I checked my parameters as @kevinjos said, I saved model parameter and weight below if new best f1 score appear:
self.model.save_weights(save_path)
pickle.dump(self.model.get_weights(), open('./debug_best_weight.pkl', 'wb'))
Then after model.fit ending, I check it:
self.model = load_model(save_path)
m_weight = self.model.get_weights()
m_best_weight = pickle.load(open('./debug_best_weight.pkl', 'rb'))
m_weights = m.get_weights()
assert len(m_best_weight) == len(m_weights)
for i in range(len(m_weights)):
assert np.array_equal(m_best_weight[i], m_weights[i])
print("Model weight serialization test passed")
the output is:
Model weight serialization test passed
Unfortunately, all parameter is the same, but I get different score using the same model, same parameter and same validate dataset. SO
"You use a different function to calculate score"
so maybe you say I have a different function to calculate f1 score. But it's not.
I use custom callback and f1 metric:
self.model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[JZTrainCategory.compile_official_f1_score])
During training, I got best score 0. 8719, And the use the same score function below, it changed:
sess = tf.Session()
with sess.as_default():
score = JZTrainCategory.compile_official_f1_score(K.constant(y_test), K.constant(oof_pred_)).eval()
the score is '0.8636'. see the picture below:
"You write a wrong score function"
my score function can run correctly, even it's wrong, saved model should give me a same wrong result, you can see all my customer callback function and score function JZTrainCategory.compile_official_f1_score.
import tensorflow.keras as keras
from tensorflow.keras import backend as K
import numpy as np
import warnings
import glob
import os
from tensorflow.keras.models import load_model
from tensorflow.keras.models import save_model
import pickle
class JZTrainCategory(keras.callbacks.Callback):
def __init__(self, filepath, nb_epochs=20, nb_snapshots=1, monitor='val_loss', factor=0.1, verbose=1, patience=1,
save_weights_only=False,
mode='auto', period=1):
super(JZTrainCategory, self).__init__()
self.nb_epochs = nb_epochs
self.monitor = monitor
self.verbose = verbose
self.filepath = filepath
self.factor = factor
self.save_weights_only = save_weights_only
self.patience = patience
self.r_patience = 0
self.check = nb_epochs // nb_snapshots
self.monitor_val_list = []
if mode not in ['auto', 'min', 'max']:
warnings.warn('ModelCheckpoint mode %s is unknown, '
'fallback to auto mode.' % (mode),
RuntimeWarning)
mode = 'auto'
if mode == 'min':
self.monitor_op = np.less
self.init_best = np.Inf
elif mode == 'max':
self.monitor_op = np.greater
self.init_best = -np.Inf
else:
if 'acc' in self.monitor or self.monitor.startswith('fmeasure'):
self.monitor_op = np.greater
self.init_best = -np.Inf
else:
self.monitor_op = np.less
self.init_best = np.Inf
@staticmethod
def compile_official_f1_score(y_true, y_pred):
y_true = K.reshape(y_true, (-1, 10))
y_true = K.cast(y_true, 'float32')
y_pred = K.round(y_pred)
tp = K.sum(y_pred * y_true)
fp = K.sum(K.cast(K.greater(y_pred - y_true, 0.), 'float32'))
fn = K.sum(K.cast(K.greater(y_true - y_pred, 0.), 'float32'))
p = tp / (tp + fp)
r = tp / (tp + fn)
f = 2*p*r/(p+r)
return f
def on_batch_begin(self, batch, logs={}):
return
def on_batch_end(self, batch, logs={}):
return
def on_train_end(self, logs={}):
print(self.monitor_val_list)
return
def on_train_begin(self, logs={}):
self.init_lr = K.get_value(self.model.optimizer.lr)
self.best = self.init_best
return
def on_epoch_begin(self, epoch, logs=None):
return
def on_epoch_end(self, epoch, logs=None):
logs = logs or {}
logs['lr'] = K.get_value(self.model.optimizer.lr)
n_recurrent = epoch // self.check
self.save_path = '{}/{}.h5'.format(self.filepath, n_recurrent)
dir_path = '{}'.format(self.filepath)
os.makedirs(dir_path, exist_ok=True)
current = logs.get(self.monitor)
if current is None:
warnings.warn('Can save best model only with %s available, '
'skipping.' % (self.monitor), RuntimeWarning)
else:
if self.monitor_op(current, self.best):
# if better result: save model
if self.verbose > 0:
print('\nEpoch %05d: %s improved from %0.5f to %0.5f,'
' saving model to %s'
% (epoch + 1, self.monitor, self.best,
current, self.save_path))
self.best = current
if self.save_weights_only:
self.model.save_weights(self.save_path)
pickle.dump(self.model.get_weights(), open('./debug_weight.pkl', 'wb'))
else:
# save_model(self.model, self.save_path)
self.model.save(self.save_path)
else:
# if worse resule: reload last best model saved
self.r_patience += 1
if self.verbose > 0:
if self.r_patience == self.patience:
print('\nEpoch %05d: %s did not improve from %0.5f' %
(epoch + 1, self.monitor, self.best))
if self.save_weights_only:
self.model.load_weights(self.save_path)
else:
self.model = load_model(self.save_path, custom_objects={'compile_official_f1_score': JZTrainCategory.compile_official_f1_score})
# set new learning rate
old_lr = K.get_value(self.model.optimizer.lr)
new_lr = old_lr * self.factor
K.set_value(self.model.optimizer.lr, new_lr)
print('\nReload model and decay learningrate from {} to {}\n'.format(old_lr, new_lr))
self.r_patience = 0
if (epoch+1) % self.check == 0:
self.monitor_val_list.append(self.best)
self.best = self.init_best
if (epoch+1) != self.nb_epochs:
K.set_value(self.model.optimizer.lr, self.init_lr)
print('At epoch-{} reset learning rate to mountain-top init lr {}'.format(epoch+1, self.init_lr))
more test
I also test model.load_weights,the results are similar near 0.864 but they are still not equal.
I don't know how to fix the bug, and it makes me very insecurities. Anyhow, it's about 1% point.
Hope someone's help. Thanks in advance. It wastes my lots of time. Oh gosh/
 nlpjoe
on 13 Oct 2018
nlpjoe
on 13 Oct 2018
I was able to work around this problem by using TensorFlow Saver.
Training
import tensorflow as tf
import keras
...
[ code of your model here]
...
model.fit()
saver = tf.train.Saver()
sess = keras.backend.get_session()
saver.save(sess, './keras_model')
model.save('keras_model.hdf5')
Testing
import tensorflow as tf
import keras
model = keras.models.load_model('keras_model.hdf5')
saver = tf.train.Saver()
sess = keras.backend.get_session()
saver.restore(sess, './keras_model')
model.predict(inputs)
...
[the rest of your code here]
With this code, I'm getting same results in training and prediction :)
 cjbayron
on 27 Oct 2018
cjbayron
on 27 Oct 2018
Hi, all.
Someone helped me with a similar issue. For my binary classification task, the issue was the order of class labels. During training it was [1, 0], while in the script I was loading the model it was [0, 1], which of course led to abysmal evaluation results.
 taasmoe
on 30 Oct 2018
taasmoe
on 30 Oct 2018
Namaste folks :)
I seem to have made it work. The issue was the script using the saved model was importing these libraries:
import argparse
import math
import numpy as np
from keras.models import Model
from keras.applications.inception_v3 import InceptionV3
from keras.preprocessing import image
from keras.applications.inception_v3 import preprocess_input, decode_predictions
import cv2
And the script wherein I trained the model imported these:
import numpy as np
import keras
from keras import backend as K
from keras.models import Sequential
from keras.layers import Activation
from keras.layers.core import Dense, Flatten
from keras.optimizers import Adam
from keras.metrics import categorical_crossentropy
from keras.preprocessing.image import ImageDataGenerator
from keras.layers.convolutional import *
from sklearn.metrics import confusion_matrix
from keras import Model
from keras.applications.imagenet_utils import preprocess_input
import cv2
from keras.preprocessing import image
from keras.models import load_model
So importing the same libraries in the script where I wanted to use my trained model worked out.
I dont know if the issue was from loading wrong libraries, but this helped me.
Could be the fact that im importing preprocess_input from InceptionV3 instead of image_utils
 mikkelmedm
on 8 Nov 2018
mikkelmedm
on 8 Nov 2018
Found one Solution, by saving the model with tensorflow checkpoints during training worked for me!!
https://www.tensorflow.org/tutorials/keras/save_and_restore_models
 onuragmaji
on 27 Nov 2018
onuragmaji
on 27 Nov 2018
@onuragmaji Is there any difference with my solution?
cjbayron
on 27 Nov 2018
@cjbayron I tried your solution also but in my case (working on LSTM), it won't work still giving random outputs but with checkpoints, I am getting the same output which I got before saving the model.
onuragmaji
on 28 Nov 2018
Hi, all.
Someone helped me with a similar issue. For my binary classification task, the issue was the order of class labels. During training it was [1, 0], while in the script I was loading the model it was [0, 1], which of course led to abysmal evaluation results.
same issue and solution with seq2seq model I just ran. The order of my token-id mapping would be changed between different python session, which results to wrong predictions.
If you build your token-id lookup dictionary each time, just make sure you have the same order of tokens (maybe sorted your list of tokens or just save it as a file)
 tan800630
on 29 Nov 2018
tan800630
on 29 Nov 2018
Hi all,
My issue with this is solved when I made sure my test data is using the correct embedding matrix to convert to vectors. Previously, my test data used a new embedding matrix (with different index orders) when I loaded the model in a new script. The same as @tan800630.
 jetnew
on 30 Nov 2018
jetnew
on 30 Nov 2018
Guys it's been verified, if this error is happening with you, probably it's coz key-value pair is in different order, or something similar.
 shivam13juna
on 7 Jan 2019
shivam13juna
on 7 Jan 2019
@cjbayron Thanks!! I have solved my problem by using your solution. It works!! My previous problem is that after saving a seq2seq keras model, I get different decoding results every time I restore the model.
 yuewang-cuhk
on 7 Jan 2019
yuewang-cuhk
on 7 Jan 2019
I met this problem too. The symptom is after loading model from last training, everything like weightings became random yet and distorted the training result. Yet, results from the first training was fine.
My solution would be DON'T USE keras.models.load_model() and Model.save().
Instead, use Model.load_weights(filename) and Model.save_weights(filename), where Model is your own model.
 Cynwell
on 9 Jan 2019
Cynwell
on 9 Jan 2019
I am also facing same issue the model working in jupyter .but when i am trying to load the model using flask in spyder that time i am getting random output.
 Somabhadra
on 14 Jan 2019
Somabhadra
on 14 Jan 2019
please help me out from this keras issue.in jupyter the prediction class is 2 but when i am saving and loading for flask its giving wrong output like 6.which is wrong.
Somabhadra
on 14 Jan 2019
I have the same problem. When I save and then load a model inside the same method of a class, I get one result. When I call the same piece of code, from another method of the same (already instantiated) class I get another result.
(TF 1.11, Keras 2.1.6)
 federicovagnoni
on 16 Jan 2019
federicovagnoni
on 16 Jan 2019
We had a similar issue.
In a network with arbitrary number of inputs we used a Lambda layer to select a part of the input. Then we combined them using some other layers to obtain a unique output.
While the training worked properly, without any issue, the serialization did NOT work in the same way.
After training, our model reached a certain accuracy.
We saved it
model.save('model.hdf5')
and then loaded it (we tried both another or the same project)
load_model('model.hdf5')
Unfortunately the accuracy of the loaded model was almost half that of the trained one.
WRONG:
for i in range(inputs_number):
lam = Lambda(lambda x: x[:,i,:], output_shape=(dimension, ))
F_inputs = lam(main_input)
# ...
model = Model(inputs=main_input, outputs=outputs)
model.save('model.hdf5')
The problem is that we defined the lambda function in the Lambda layer using "i" referring to an integer outside the function.
Strangely the model was working and could be fitted.
But in the serialization, all the Lambda layers were identical with the last "i" (i = len(inputs_number) - 1).
So when we loaded it, it was working but using just one input, the last one.
That is why the accuracy dropped to half of the trained model accuracy but not down to the random network accuracy.
CORRECT:
for i in range(inputs_number):
lam = Lambda(lambda x, ind: x[:,ind,:], output_shape=(dimension, ), arguments={'ind': i})
F_inputs = lam(main_input)
# ...
model = Model(inputs=main_input, outputs=outputs)
model.save('model.hdf5')
The correct model uses "i" as an argument of the Lambda layer so that it is in the signature of the function (so its value is fixed)
 Innuendo1975
on 18 Jan 2019
Innuendo1975
on 18 Jan 2019
Thanks! @Innuendo1975 Your method worked for me. The problem was indeed the serialization issue with lambda.
 shenyichen105
on 24 Jan 2019
shenyichen105
on 24 Jan 2019
Made an account just to upvote @Innuendo1975 for helping me avoid deep debugging.
thanks!
 slowhand42
on 31 Jan 2019
slowhand42
on 31 Jan 2019
I have the same problem, please someone help me, I'm using the following code:
import keras
from keras.layers.core import Flatten
from keras.layers.core import Dense
from keras.layers.core import Dropout
from keras.applications.resnet50 import ResNet50
from keras.layers import Input
from keras.models import Model
from keras.regularizers import *
def get_model():
aliases = {}
Input_1 = Input(shape=(3, 200, 200), name='Input_1')
ResNet50_1_model = ResNet50(include_top= False, input_tensor = Input_1)
ResNet50_1 = ResNet50_1_model(Input_1)
aliases['ResNet50_1'] = ResNet50_1_model.name
num_layers = len(ResNet50_1_model.layers)
for i, layer in enumerate(ResNet50_1_model.layers):
if ((i * 100) / (num_layers - 1)) <= (100 - 25):
layer.trainable = False
Flatten_1 = Flatten(name='Flatten_1')(ResNet50_1)
Dense_1 = Dense(name='Dense_1',output_dim= 4096,activation= 'relu' )(Flatten_1)
Dropout_1 = Dropout(name='Dropout_1',p= .7)(Dense_1)
Dense_2 = Dense(name='Dense_2',output_dim= 3,activation= 'softmax' )(Dropout_1)
model = Model([Input_1],[Dense_2])
return aliases, model
model = get_model()
model.compile(loss='binary_crossentropy',optimizer = 'Adadelta',metric = ['accuracy'])
model.fit(...)
When I load my model i got bad predictions. Anyone has solved this problem ?
 cags9607
on 2 Feb 2019
cags9607
on 2 Feb 2019
right now, it's 2019, the problem is still there
 visionandy
on 26 Mar 2019
visionandy
on 26 Mar 2019
The problem is definitely not solved, yet :/
 SaadMTSA
on 11 Apr 2019
SaadMTSA
on 11 Apr 2019
I found that if loss turns to 'nan' the model will not load properly trained,
even though it does seem to function well in the original session.
 dror-g
on 14 Apr 2019
dror-g
on 14 Apr 2019
i also met this problem, and i solved it. i use set in reading data, but i don't sort it, so the label sequence is not the same. sort the set perfectly solve this problem.
 zhang0peter
on 17 Apr 2019
zhang0peter
on 17 Apr 2019
I still have the same issue. Mac OS. Python 3.5, keras 2.2.0, tensor flow 1.12.0. model.load_model and model.save_model always give different result. Same for model.load_weight and model.save_weight. It seems that the model anyway randomly initialize the weight even if the original model is loaded.
Update
One more information. I check both model.h5 and model_weights.h5.
import h5py
a = h5py.File('MODELS/sensorml.h5','r')
print(list(a.values()))
It shows that the h5 file only contain model_weights field, which is different from what is stated in the documentation
You can use model.save(filepath) to save a Keras model into a single HDF5 file which will contain:
- the architecture of the model, allowing to re-create the model
- the weights of the model
- the training configuration (loss, optimizer)
- the state of the optimizer, allowing to resume training exactly where you left off.
What's more. For the model_weights field. The value is exactly the same as the initialized parameter value that I first train the model. It's quite interesting why we are not saving the trained parameter but the untrained one? Anyway it seems that the loaded model is not random but just the untrained one.
Update
Hey guys, I solved the problem. Stupid me. My code was:
model.compile(optimizer=sgd, loss='mae',metrics=[relative_acc])
model.save(model_path)
history=model.fit(x_train_processed,y_train,epochs=50,batch_size=100,validation_split=0.2,shuffle=True)
So I save the model before training process... That's why the parameter is always the initial one. Just need to switch the lines to
model.compile(optimizer=sgd, loss='mae',metrics=[relative_acc])
history=model.fit(x_train_processed,y_train,epochs=50,batch_size=100,validation_split=0.2,shuffle=True)
model.save(model_path)
and the problem solved. It's really stupid. But posting and sharing here in case some one need it.
 corn23
on 26 Apr 2019
corn23
on 26 Apr 2019
I had the same problem while trying to save the nlp classifier keras model with the weights Once I saved and loaded the model I was getting different predictions. Finally I figured out what the problem was. I was using keras tokenizer and whenever I run the tokenizer I was getting different vocab therefore model was giving different predictions.I first dumped the tokenizer as a pickle file and then save the model. Once I recall tokenizer and the model, it just started to work like a charm.
import pickle
saving the tokenizer
with open('tokenizer.pickle', 'wb') as handle:
pickle.dump(tokenizer, handle, protocol=pickle.HIGHEST_PROTOCOL)
serialize model to JSON
model_json_conv = model_conv.to_json()
with open("model_conv.json", "w") as json_file:
json_file.write(model_json_conv)
serialize weights to HDF5
model_conv.save_weights("model_conv.h5")
print("Saved model to disk")
I saved the model with the weights and then load it.
with open('tokenizer.pickle', 'rb') as handle:
tokenizer = pickle.load(handle)
json_file = open('model_conv.json', 'r')
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
load weights into new model
loaded_model.load_weights("model_conv.h5")
 MustafaKadioglu
on 2 May 2019
MustafaKadioglu
on 2 May 2019
I had the same problem while trying to save the nlp classifier keras model with the weights Once I saved and loaded the model I was getting different predictions. Finally I figured out what the problem was. I was using keras tokenizer and whenever I run the tokenizer I was getting different vocab therefore model was giving different predictions.I first dumped the tokenizer as a pickle file and then save the model. Once I recall tokenizer and the model, it just started to work like a charm.
import pickle
saving the tokenizer
with open('tokenizer.pickle', 'wb') as handle:
pickle.dump(tokenizer, handle, protocol=pickle.HIGHEST_PROTOCOL)serialize model to JSON
model_json_conv = model_conv.to_json()
with open("model_conv.json", "w") as json_file:
json_file.write(model_json_conv)serialize weights to HDF5
model_conv.save_weights("model_conv.h5")
print("Saved model to disk")I saved the model with the weights and then load it.
with open('tokenizer.pickle', 'rb') as handle:
tokenizer = pickle.load(handle)json_file = open('model_conv.json', 'r')
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)load weights into new model
loaded_model.load_weights("model_conv.h5")
it is just the case in my situation. Thank you for the solution
 bbbxixixixi
on 5 May 2019
bbbxixixixi
on 5 May 2019
I had exactly the same problem with saving and loading the weights. So on loading the model the accuracy and loss were changed greatly from 68% accuracy to 2 %. In my experiment, I am using Tensorflow as backend with Keras model layers Embedding, LSTM and Dense. My issue got solved by fixing the seed for keras which uses NumPy random generator and since I am using Tensorflow as backend, I also fixed the seed for it.
These are the lines I added at the top of my file where the model is also defined.
from numpy.random import seed
seed(42) #seed fixing for keras
import tensorflow as tf
tf.random.set_seed(42)# tensorflow seed fixing
I hope this helps someone. :)
For more information visit this link- https://machinelearningmastery.com/reproducible-results-neural-networks-keras/
 rishabhsahrawat
on 9 May 2019
rishabhsahrawat
on 9 May 2019
I experienced the same issue with Keras and none of the above methods worked. The main issue was that the trained model wasn't getting saved and instead the initial model was getting saved. To counter that you can use the "ModelCheckpoint" callback from keras.callbacks. It saves the best checkpoint after training.
checkpoint = ModelCheckpoint(filepath="./keras_model/model.hdf5", verbose=1, save_best_only=True)
model.fit(X_train, y_train, validation_data=(X_valid, y_valid), epochs=3, batch_size=batch_size, callbacks=[checkpoint])
This generates a model.hdf5 file in the given directory. Hope this solves your problem.
For more info- https://keras.io/callbacks/
 rrr-coders
on 17 May 2019
rrr-coders
on 17 May 2019
I found a solution that works for me. Still no ideas why it makes a difference though, any clarification on that is appreciated!
I had the following problem:
from tensorflow import keras
from tensorflow.keras import layers
x_train, y_train, x_test, y_test = load_data()
# create your model
model = neural_network_model(inputs)
model.fit(x_train, y_train, batch_size=64, epochs=1)
predictions = model.predict(x_test)
model.save('path_to_my_model.h5')
new_model = keras.models.load_model('path_to_my_model.h5')
new_predictions = new_model.predict(x_test)
print(np.array_equal(predictions, new_predictions))
# I expected it to print TRUE but it came back as FALSE
I verified that the x_test supplied and the weights of the model were exactly the same.
Solution:
What worked for me was moving the activation layer into the dense layer.
I didn't set any seed to a fixed value in my script.
Didn't have to add PYTHONHASHSEED add environment variable
Works in both when you do it in the same session and when running the predict in a new session (tried it on the same machine)
Works both on CPU and GPU (Windows machine)
def neural_network_model(input_dims, layer0, layer1, layer2, lb):
"""
This function specifies the deep learning model architecture
Returns model object
"""
seed = random.randint(0, 50)
init = he_normal(seed=seed)
bias_init= Constant(value=0.0)
kernel_reg = regularizers.l2(lb)
model = Sequential()
model.add(Dense(layer0, input_dim=input_dims, activation="relu", # added activation here
kernel_initializer=init, bias_initializer=bias_init,
kernel_regularizer = kernel_reg))
# model.add(ReLU()) -> Remove this and add to Dense layers
model.add(Dropout(0.4))
model.add(Dense(layer1, kernel_initializer=init, activation="relu", # added activation here
bias_initializer=bias_init, kernel_regularizer =kernel_reg))
# model.add(ReLU()) -> Remove this and add to Dense layers
model.add(Dropout(0.4))
model.add(Dense(layer2, kernel_initializer=init, activation="relu", # added activation here
bias_initializer=bias_init, kernel_regularizer =kernel_reg))
# model.add(ReLU()) -> Remove this and add to Dense layers
model.add(Dropout(0.4))
model.add(Dense(1, activation='linear', kernel_initializer=init,
bias_initializer=bias_init))
optimizer = Adam(lr=0.0002, beta_1=0.5)
model.compile(optimizer=optimizer,
loss='mean_absolute_error')
print(model.summary())
return model
Hope this will help some of you!
 Ramaekers
on 22 May 2019
Ramaekers
on 22 May 2019
I found a solution that works for me. Still no ideas why it makes a difference though, any clarification on that is appreciated!
I had the following problem:
from tensorflow import keras from tensorflow.keras import layers x_train, y_train, x_test, y_test = load_data() # create your model model = neural_network_model(inputs) model.fit(x_train, y_train, batch_size=64, epochs=1) predictions = model.predict(x_test) model.save('path_to_my_model.h5') new_model = keras.models.load_model('path_to_my_model.h5') new_predictions = new_model.predict(x_test) print(np.array_equal(predictions, new_predictions)) # I expected it to print TRUE but it came back as FALSEI verified that the x_test supplied and the weights of the model were exactly the same.
Solution:
What worked for me was moving the activation layer into the dense layer.
I didn't set any seed to a fixed value in my script.
Didn't have to add PYTHONHASHSEED add environment variable
Works in both when you do it in the same session and when running the predict in a new session (tried it on the same machine)
Works both on CPU and GPU (Windows machine)def neural_network_model(input_dims, layer0, layer1, layer2, lb): """ This function specifies the deep learning model architecture Returns model object """ seed = random.randint(0, 50) init = he_normal(seed=seed) bias_init= Constant(value=0.0) kernel_reg = regularizers.l2(lb) model = Sequential() model.add(Dense(layer0, input_dim=input_dims, activation="relu", # added activation here kernel_initializer=init, bias_initializer=bias_init, kernel_regularizer = kernel_reg)) # model.add(ReLU()) -> Remove this and add to Dense layers model.add(Dropout(0.4)) model.add(Dense(layer1, kernel_initializer=init, activation="relu", # added activation here bias_initializer=bias_init, kernel_regularizer =kernel_reg)) # model.add(ReLU()) -> Remove this and add to Dense layers model.add(Dropout(0.4)) model.add(Dense(layer2, kernel_initializer=init, activation="relu", # added activation here bias_initializer=bias_init, kernel_regularizer =kernel_reg)) # model.add(ReLU()) -> Remove this and add to Dense layers model.add(Dropout(0.4)) model.add(Dense(1, activation='linear', kernel_initializer=init, bias_initializer=bias_init)) optimizer = Adam(lr=0.0002, beta_1=0.5) model.compile(optimizer=optimizer, loss='mean_absolute_error') print(model.summary()) return modelHope this will help some of you!
I already had the activation layer defined how you showed but still it did not work for me.
rishabhsahrawat
on 22 May 2019
I am having this issue in a simple VGG19 model application. I'm trying my best to find the reason why this happens and I came down to the following. I can't reproduce exactly the problem I face because it's a private dataset I can't share here, so I tried to re-create the situation using minimal code and CIFAR10. I can't get the problem to happen with this dataset, so the situation is very confusing. What I know so far is:
1 - On my original problem, using model.save_weights() and model.load_weights() causes the buggy behavior. After loading my predictions are all 1.0 and accuracy goes to 0.50. Using model.save() and load_model() works perfectly for some reason, however.
2 - On the original problem, I've been using model.load_weights() and load_model() and then using model.get_weights() after loading, and I can confirm that in both cases the weights are identical after loading, even though in one case the accuracy is horrible and the other one it's normal. It's as if load_model() is loading something else besides the weights that is fixing the problem. Does anyone know what it can be?
3 - Trying to recreate the situation using CIFAR10 has not worked so far. No matter what I do (adding custom metrics / several callbacks / etc), the model save and load works perfectly regardless of the method I use to save or load (whether through checkpoints/model.save_weights/model.save). I can't get the issue to happen on this mock code I'll post below.
If someone can use these two codes below to make the issue happen in a controlled fashion that'd be great. Hopefully we get one step closer to solving this very serious reproducibility issue.
Code for session 1 (Training VGG19 on Cifar10 and saving weights only / whole model / checkpoints):
import keras
from keras.applications.vgg19 import VGG19
from keras.datasets import cifar10
from keras.layers import Dense
from keras.models import Model, Input
from keras.callbacks import ModelCheckpoint,EarlyStopping,TensorBoard,CSVLogger,ReduceLROnPlateau,LearningRateScheduler
from keras.optimizers import SGD
import tensorflow as tf
from keras import backend as K
batch_size = 128
num_classes = 10
epochs = 10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
input_tensor = Input((32, 32, 3))
base_model = VGG19(include_top=False, pooling='avg', input_tensor=input_tensor, weights = 'imagenet')
x = base_model(input_tensor)
out = Dense(10, activation="softmax")(x)
model = Model(input_tensor, out)
#####################################################################
###############################TESTING###############################
def auc(y_true, y_pred):
auc = tf.metrics.auc(y_true, y_pred)[1]
K.get_session().run(tf.local_variables_initializer())
return auc
best_model_weights = 'model_checkpoints.h5'
checkpoint = ModelCheckpoint(
best_model_weights,
monitor = 'acc',
save_best_only = True,
mode='max',
verbose=1,
save_weights_only=False,
period = 1)
earlyStop = EarlyStopping(
monitor = 'acc',
min_delta=0.01,
patience = 5,
verbose = 1,
mode = 'max')
tensorBoard = TensorBoard(
log_dir = './logs',
histogram_freq=0,
batch_size=batch_size,
write_graph=True,
write_grads=True,
write_images=False)
#learnrate = LearningRateSchedule(lambda x: 1. / (1. + x))
reduce = ReduceLROnPlateau(monitor='acc',
factor=0.5,
patience=3,
verbose=1,
mode='max'
)
csvlogger = CSVLogger(filename='training_csv.log',
separator=',',
append=False)
callbacks = [checkpoint, tensorBoard, csvlogger, reduce]
#####################################################################
model.compile(optimizer=SGD(lr=1e-4, momentum=0.99), loss=keras.losses.categorical_crossentropy, metrics=['accuracy', auc])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
callbacks=callbacks)
score = model.evaluate(x_test, y_test, verbose=0)
print('Model test_acc:', score[1])
model.save('model_whole.h5')
model.save_weights('model_weightsonly.h5')
Code for session 2 (Loading the previously saved weights to a new session and performing predictions/evals):
import keras
from keras.applications.vgg19 import VGG19
from keras.datasets import cifar10
from keras.layers import Dense
from keras.models import Model, Input
from keras.models import load_model
import tensorflow as tf
from keras import backend as K
from keras.optimizers import SGD
def auc(y_true, y_pred):
auc = tf.metrics.auc(y_true, y_pred)[1]
K.get_session().run(tf.local_variables_initializer())
return auc
batch_size = 128
num_classes = 10
epochs = 10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model1 = load_model('../input/model_whole.h5', custom_objects={'auc': auc})
score = model1.evaluate(x_test, y_test, verbose=0)
print('Model load whole test_acc:', score[1])
input_tensor = Input((32, 32, 3))
base_model = VGG19(include_top=False, pooling='avg', input_tensor=input_tensor, weights = None)
x = base_model(input_tensor)
out = Dense(10, activation="softmax")(x)
model2 = Model(input_tensor, out)
model2.compile(optimizer=SGD(lr=1e-4, momentum=0.99), loss=keras.losses.categorical_crossentropy, metrics=['accuracy', auc])
model2.load_weights('../input/model_weightsonly.h5')
score = model2.evaluate(x_test, y_test, verbose=0)
print('Model load weights only test_acc:', score[1])
input_tensor = Input((32, 32, 3))
base_model = VGG19(include_top=False, pooling='avg', input_tensor=input_tensor, weights = None)
x = base_model(input_tensor)
out = Dense(10, activation="softmax")(x)
model3 = Model(input_tensor, out)
model3.load_weights('../input/model_checkpoints.h5')
model3.compile(optimizer=SGD(lr=1e-4, momentum=0.99), loss=keras.losses.categorical_crossentropy, metrics=['accuracy', auc])
score = model3.evaluate(x_test, y_test, verbose=0)
print('Model load checkpoint test_acc:', score[1])
Ideally to reproduce the issue you'd get the print-outs from sessions 1 and 2 to say different values. On my last test I got
Session 1:
Model test_acc: 0.8434 (just an example, I didn't use seeds so you'll get something random around 0.8)
Session 2:
Model load whole test_acc: 0.8434
Model load weights only test_acc: 0.8434
Model load checkpoint test_acc: 0.8434
Cheers
 palatos
on 24 May 2019
palatos
on 24 May 2019
I am documenting my findings below since what I have encountered has not been mentioned in the above 2.5-year long thread.
I actually have issues with loading weights, which prompted me switching to save and load_model.
Model inference by loading weights performed as expected in
Keras 2.1.2, Tensorflow 1.9.0
but performance drops (the prediction output is not random, but just really bad) in
Keras 2.2.2, Tensorflow 1.9.0
Once model is saved in 2.1.2, it was loaded in Keras 2.2.2 ( which was the desired production environment), performance was not as expected, until setting k.set_image_data_format('channels_last'), despite model is trained using data_format : channels_first!
I think this issue is only occurring for models with batchnorm layers, however, i have also tried storing the architecture in Json, setting trainable to False for all batchnorm layers and loading the weights to do inference, the inference results was not as expected. Note that you can set the axis in batchnorm, but there is a bug when you set axis=1 and then loading the weights from that trained in Keras 2.1.2 (i think it is related to #10648 ). Another issue that I found is to remember to cast your array to float prior doing any normalization. That was one gotcha before this gotcha...
The amount of time spent on troubleshooting this issue probably took much much longer time than to just setup the model to serve via Tensorflow Serving. :) Good luck!
 pangyuteng
on 30 May 2019
pangyuteng
on 30 May 2019
I faced similar issue.its related to tokenizer.you have to save the tokenizer in pickle format and then you can use it for different session.so the same result you can get it.
Somabhadra
on 7 Jun 2019
I met the same problem and finally, I found the problem is caused by the process of encoding the data instead of initiating weight.
When I searched for the solution, an article mentioned that most of the users use set() i.e word_set to create word_to_index or index_to_word dict, the order of poping value is different if in a different session.
If we encode our data at the begin of a session, we use the different representation of data to predict.
So if you meet the problem, you may need to check whether the data used to predict is in the same representation.
 Royeqiu
on 26 Jun 2019
Royeqiu
on 26 Jun 2019
I had an issue with my model outputting incorrect values after I had loaded it with keras load_model. More specifically and interestingly it was outputting one index of the softmax output as 1 and all others 0 (obviously), with this occuring for the same index for most observations.
I overcame this issue by doing all session and variable initialisation before loading the model.
For example... I altered
from tensorflow.keras.backend import set_session
model=load_model(model_path)
sess = tf.Session()
set_session(sess)
sess.run(tf.global_variables_initializer())
to
from tensorflow.keras.backend import set_session
sess = tf.Session()
set_session(sess)
sess.run(tf.global_variables_initializer())
model=load_model(model_path)
and the model worked perfectly.
I'm not 100% sure why this is the case but it appeared to have something to do with some variables in a batch_normalization layer I was using.
Hopefully this will help others
 CarlSouthall
on 26 Jun 2019
CarlSouthall
on 26 Jun 2019
@ Somabhadra That is it for me. Thanks!
I notice they are adding the tokenizer text layers, those would solve this problem cleanly.
 LanceNorskog
on 9 Jul 2019
LanceNorskog
on 9 Jul 2019
The following code worked for me --
generator.compile(loss='mse', optimizer=opt, metrics=[perceptual_distance])
model = load_model("../input/srresnet-epoch-120/pretrain/model00000120.h5", custom_objects={'perceptual_distance': perceptual_distance})
weights = model.get_weights()
generator.set_weights(weights)
 khushal1996
on 10 Jul 2019
khushal1996
on 10 Jul 2019
Hi guys,
Has anybody been able to successfully resolve the issue?
I have almost tried everything mentioned in the comments above and haven't been able to rectify the same problem as most people here. I am using keras for deep reinforcement learning to solve the mountain car problem.
During my training session I use my learnt model to predict the next action the car should do but when I save the same model and reload it using model_save and model_load respectively, my model prediction is no where near what it was during training. In fact, it gives the same output values for any given input.
 ZainBashir
on 23 Jul 2019
ZainBashir
on 23 Jul 2019
Same problem with MobileNet in utils
 JunzheJosephZhu
on 25 Jul 2019
JunzheJosephZhu
on 25 Jul 2019
Really wanted to say thanks to @Innuendo1975 answer above (Jan 18, 2019) !! It was exactly the problem I had, and his answer solved it.
Might be a bit of an edge case, as we are splitting our input to the model (rather than just defining a model on an input of the size of the split), so we can run the splits through the same model and then concat the outputs at the end. But it is our case, and that answer is correct!
 tlekang
on 6 Aug 2019
tlekang
on 6 Aug 2019
Just posting here in case someone else has this issue. I wasted three days debugging this. Using tensorflow 2.0 beta1
My model was a sequence generator with several stateful GRUs and an embedding later. Also a sizeable vocabulary.
FIRST: if you are using ‘set()’ to get your vocabulary, and then mapping from words(or characters) to integers, these dictionaries will be different every time you run your session. Run it once then write the dictionary to JSON. In each new instance of your model load your dictionaries from these JSONs
SECOND- using model.save() and models.load_model() worked fine when my h5 file was “small” but when it was over 1GB I still had the issues above. Solution was to save model architecture to JSON and save the weights to H5. When these are loaded separately problem solved! Looks like sufficiently large models (in this context) can’t save all the weights + architecture to a single H5
 brandonbell11
on 8 Aug 2019
brandonbell11
on 8 Aug 2019
I can not make the trained model work in the new session. The model has LSTM layers and gives great results in the same session, however when I load the model, the weights and layers are populated, but the predictions are complete garbage.
 pycckuu
on 10 Aug 2019
pycckuu
on 10 Aug 2019
Guys, are you using python version 3.5? After 4 days of battling with keras/tf, updating to python 3.6.6 solved the problem for me.
pycckuu
on 13 Aug 2019
@pycckuu did u need to change only in new session or need to train with that python version?
 allanbatista
on 14 Aug 2019
allanbatista
on 14 Aug 2019
I trained; the previously trained models didn't work. I also use Keras from TensorFlow. Although, this didn't help in python 3.5 I also tried everything using python 2.7. Also, different ways of saving in keras and tensorfolow directly, e.g., saving and resroring tf sessions with saver = tf.train.Saver(), using saved models with tf.saved_model.save(), loading architectures, weights and compiling, tried to use theano as backend etc. Nothing worked. Now I use python 3.6.9 and keras from tf and regular load/save from tf.keras.models.
pycckuu
on 14 Aug 2019
Which TF and keras versions do you use on python 3.6.6?
 maxima120
on 14 Aug 2019
maxima120
on 14 Aug 2019
Keras: 2.2.4-tf, Tensorflow: 1.14.0. Keras from TF, i.e, from tensorflow import keras. In TF 1.13 it also works. I also used conda environment and installed everything from there. Maybe there is an issue with pre-compiled packages. This is my pip freeze: https://gist.github.com/pycckuu/54e944bf4435453940c68dacbc874d93
pycckuu
on 14 Aug 2019
I investigate a little more. and I discovery that I have that issue when I load the model on machine only with CPU. When I load same model on GPU, I got same results.
I train with TF 1.14 and python 3.5 on Google Cloud AI-Platform with Nvidia V100.
allanbatista
on 14 Aug 2019
I trained the model in gcloud as well. When I load it locally with CPU and python 3.5, I have random predictions.
pycckuu
on 14 Aug 2019
I also had a problem of different accuracy of the model after saving and loading model in different session. Given the lot of issues in github about this, I was in a echo chamber that it had to be keras. I tried an online simple example with a different dataset where they saved and loaded the model and it worked. So I slowly converted my model to the simple model, to find out wat was causing the issue. I still had the issue when my model was the same as the online example. At the end I thought, than it has to be the dataset.
And indeed the problem was in the way I loaded the dataset. I was doing the following:
file_path = "data/common_voice_all.csv"
df = pd.read_csv(file_path)
target_variables = {"age_categorical", "age_numerical", "gender", "accent"}
columns_feature_vector = list(set(df.columns) - target_variables)
feature_vector = df[columns_feature_vector].values
I was using set over the columns, and this changes the order of the columns everytime.
Was a stupid error, kept me going for 2 weeks 🤣 .
 ajayaadhikari
on 15 Aug 2019
ajayaadhikari
on 15 Aug 2019
I tried the solution mentione by @CarlSouthall and it worked !!!
Initialize the session and variables before loading the model and that fixed my problem.
from tensorflow.keras.backend import set_session
model=load_model(model_path)
sess = tf.Session()
set_session(sess)
sess.run(tf.global_variables_initializer())
to
from tensorflow.keras.backend import set_session
sess = tf.Session()
set_session(sess)
sess.run(tf.global_variables_initializer())
model=load_model(model_path)
 tr-ips-bahubali
on 20 Aug 2019
tr-ips-bahubali
on 20 Aug 2019
I struggled with the same issue for some time now and finally found the solution for a small CNN. It was actually a beginner's mistake on my side, but since the issue is quite common and does not seem to be reproducible by the authors I wanted to share the result.
The issue was that the model was originally trained on a normalized dataset while it was reloaded and evaluated by an unnormalized version of the dataset.
Make sure to feed exactly the same input data.
 philopee
on 23 Aug 2019
philopee
on 23 Aug 2019
I encounter the same problems. Finally, I find the reason are due to a bug in my code. I use set() to store a collections of layer names and concatenate those layers when building model. Since the set() order are non-determined, each time the concatenation order are different.
 robotwanggit
on 3 Sep 2019
robotwanggit
on 3 Sep 2019
Hi guys,
Has anybody been able to successfully resolve the issue?
I have almost tried everything mentioned in the comments above and haven't been able to rectify the same problem as most people here. I am using keras for deep reinforcement learning to solve the mountain car problem.During my training session I use my learnt model to predict the next action the car should do but when I save the same model and reload it using model_save and model_load respectively, my model prediction is no where near what it was during training. In fact, it gives the same output values for any given input.
Hi guys,
So I finally managed to find the issue but I do not have an explanation for it. I shifted from using RMSprop to Adam as my optimizer and now my algorithm works fine both before and after saving. RMSprop was the optimizer that the authors of the paper I was trying to replicate had used.
ZainBashir
on 3 Sep 2019
Well after wasting a week on a this issue similar to many here, I can confirm that the advice of @rsmith49 and @cjqw worked for me as I was not using the same vocab token between different sessions which is why it seemed as if the model was behaving differently.
 omagdy
on 5 Sep 2019
omagdy
on 5 Sep 2019
Hi guys,
Has anybody been able to successfully resolve the issue?
I have almost tried everything mentioned in the comments above and haven't been able to rectify the same problem as most people here. I am using keras for deep reinforcement learning to solve the mountain car problem.
During my training session I use my learnt model to predict the next action the car should do but when I save the same model and reload it using model_save and model_load respectively, my model prediction is no where near what it was during training. In fact, it gives the same output values for any given input.Hi guys,
So I finally managed to find the issue but I do not have an explanation for it. I shifted from using RMSprop to Adam as my optimizer and now my algorithm works fine both before and after saving. RMSprop was the optimizer that the authors of the paper I was trying to replicate had used.
I checked and with Python 3.6.9 both optimizers work.
pycckuu
on 6 Sep 2019
Hi guys,
Has anybody been able to successfully resolve the issue?
I have almost tried everything mentioned in the comments above and haven't been able to rectify the same problem as most people here. I am using keras for deep reinforcement learning to solve the mountain car problem.
During my training session I use my learnt model to predict the next action the car should do but when I save the same model and reload it using model_save and model_load respectively, my model prediction is no where near what it was during training. In fact, it gives the same output values for any given input.Hi guys,
So I finally managed to find the issue but I do not have an explanation for it. I shifted from using RMSprop to Adam as my optimizer and now my algorithm works fine both before and after saving. RMSprop was the optimizer that the authors of the paper I was trying to replicate had used.I checked and with Python 3.6.9 both optimizers work.
Both should work fine but I guess the problem is very specific to my algorithm.For my algorithm I do not have any train or test data with labels. I train my algorithm with data generated online and as soon as I get a data sample I run it through my network to update the weights and at the same time while my network is being trained I am also using it to make predictions so that new data can be generated. So I assume this problem with optimizers is very specific to the way I am training my network.
Thanks
ZainBashir
on 6 Sep 2019
Hello!
We are a open source enthusiast group from India and we would like to solve the issue. Please provide us with some leads which you may have developed to find the solution.
We hope to come up with a solution soon!
 ayushjain209
on 6 Sep 2019
ayushjain209
on 6 Sep 2019
I recently had a similar experience with changing from RMSProp to Adam. I resurrected Keras code from three years ago and RMSProp no longer functioned, while Adam did. It is possible that the RMSProp implementation is no longer an exact replica of the standard algorithm.
LanceNorskog
on 7 Sep 2019
I recently had a similar experience with changing from RMSProp to Adam. I resurrected Keras code from three years ago and RMSProp no longer functioned, while Adam did. It is possible that the RMSProp implementation is no longer an exact replica of the standard algorithm.
You also had problems saving and loading the model using RMSprop? Maybe you are right that they've changed the implementation.
ZainBashir
on 8 Sep 2019
I am getting the same issue but I am saving the model using ModelCheckpoint. However, loading this model gives a poor solution. Any clues as to how we solve this issue within the Callbacks?
 kmair
on 26 Nov 2019
kmair
on 26 Nov 2019
I had this problem where I was getting different losses between when I saved the model and when I loaded it. It seems it was to do with the way I was compiling. When I trained my model I used:
from keras import losses
model.compile(loss=losses.binary_crossentropy,
optimizer=keras.optimizers.RMSprop(),
metrics=metrics.binary_accuracy])
but when loading my model I was using:
model.compile(loss='binary_crossentropy',
optimizer='RMSprop',
metrics=['binary_accuracy'])
I don't know why this was causing differences but only when I reverted it back to calling the keras.losses version (v1) did it work.
 liampearson
on 10 Dec 2019
liampearson
on 10 Dec 2019
So just some further information, I think this is related to using keras with GPU enabled, as the same code running on a laptop was just fine. I couldn't figure it out but I did find a workaround, using a ModelCheckpoint to save after every epoch using callbacks
from keras.callbacks import ModelCheckpoint
fpath = os.path.join("model", fname+ ".hdf5")
checkpointer = ModelCheckpoint(filepath=fpath,
monitor='val_loss',
save_best_only=True,
verbose=1)
history = model.fit(x_train, y_train,
epochs=epochs,
batch_size=batch_size,
validation_data=(x_test, y_test),
callbacks=[checkpointer],
verbose=2)
then just load it like normal
fpath = os.path.join("model", fname + ".hdf5")
model.load_weights(fpath)
(I was using Sequential model, with Adam optimizer and sparse_categorical_crossentropy loss)
Original code:
https://github.com/markadivalerio/audio-classifier-project/blob/master/audio-classifier-project.ipynb
 markadivalerio
on 11 Dec 2019
markadivalerio
on 11 Dec 2019
I have spent 3 hours reading through this post and found a solution to this problem (at least in my case):
- do backend.clear_session()
- tf.random.set_seed(0) and np.random.seed(0) of any seed number
- run create_lstm_model()
- load_weights(saved_weight.hdf5)
- model.predict()
Even models.load_model('my_model.h5') and then load_weights(saved_weight.hdf5) would not work!
And try to keep the python thread number to only 1, other concurrent python process may (or may not) potentially affect the result.
 gawain-git-code
on 15 Jan 2020
gawain-git-code
on 15 Jan 2020
Any solutions? This thread has been open for a long time. I faced same issue with ConvNet model (no LSTM) in Kaggle. Trained the model, then downloaded and used it in another kernel and result was poor. I see many people suggesting to use this:
"from keras.backend import manual_variable_initialization manual_variable_initialization(True)",
and that model.save initializes weights before saving. Shouldn't it be fixed first? Whole point of saving a model is to save the trained weights.
 nayash
on 24 Jan 2020
nayash
on 24 Jan 2020
Experiencing the same issue as well for my ConvNet model. Got 90% accuracy when the model was saved. When I loaded the saved model weights, got an accuracy of 59%.
p.s. Using the same random_state when I load the test data through the train_test_split function of scikit-learn module.
Here is the pseudo-code:
model = .... # model definition
model.compile(optimizer=adam, loss='binary_crossentropy', metrics=['acc'])
model.load_weights('best_cnn_model.h5')
And, here are my callbacks:
callbacks = [
EarlyStopping(
monitor='loss',
patience=20,
mode='min',
verbose=1
),
ModelCheckpoint(
filepath='best_cnn_model.h5',
monitor='loss',
save_best_only=True,
mode='min',
verbose=1
)
]
 talhakabakus
on 1 Feb 2020
talhakabakus
on 1 Feb 2020
@talhakabakus Do you use a separate validation set, or split? If so, you want to monitor 'val_loss' instead of 'loss' in EarlyStopping and ModelCheckpoint.
Also, with EarlyStopping add restore_best_weights=True . This makes the model object retain the best version after model.fit(). It is not relevant when you load the weights after.
LanceNorskog
on 5 Feb 2020
Hey @LanceNorskog
Thank you for your interest. Yes, I construct both of my training & validation sets through splitting the data. I was monitoring loss as I have posted the script above. When I changed the monitoring criteria to val_loss, the validation accuracy was decreased by 1%. And, the situation is still same, the test accuracy was dramatically decreased (to 40%) when I restored the saved model after adding the restore_best_weights=Trueparameter to the EarlyStopping callback.
talhakabakus
on 5 Feb 2020
I have a similar issue when I save weights of a sequential model with dense layers that are built and optimized via Keras API of TensorFlow 2.0. I have started to suspect that the saved tensors have different decimal accuracy or maybe they are getting rounded to zero in some cases.
 k1moradi
on 17 Feb 2020
k1moradi
on 17 Feb 2020
Do not add any layers with training weights to the Lambda layer
I saved the model separately as structure and weights.Because some layers are more complex, I used Lambda Layer to build the model, and I got the problem. loss ,accuracy and f1 are all random.
I checked the saved weights (tensor) with the notepad ,and found that none of the layers in Lambda save weights. cry
 yiyehu
on 6 Mar 2020
yiyehu
on 6 Mar 2020
I have the same issue,and I found that the keras(<2.3) don't support the reuse of the layer definited by yourself.eg : you difine layer 1,then you difine layer 2,and use layer 1 in the layer2.You would find that you can successfully train and valid, but when you reload the model the model's output is random.To solve this issue, you can overwrite the Class Layer`s reuse function,and then inherit it .
 L-hongbin
on 9 Mar 2020
L-hongbin
on 9 Mar 2020
This is how I solved my problem with random predictions
My problem:
I ran multiple U-Net trainings on an EC2 instance and ran tensorflow.keras.callbacks.ModelCheckpoint to store the checkpoints. The final model were then stored to s3 via a MLflow Tracking server (hosted on EC2). When downloading the model from s3 and loading it in a new session locally on my computer (using tensorflow.keras.models.load_model), the predictions came out all random and bad.
Solution:
I thought the complete model including the weights were stored in the file saved_model.pb, but I then found out that it also need the folder variables where the actual checkpoints are. Because I had run multiple local test training runs, I already had an old variable folder with the checkpoints from older runs. So when I loaded the downloaded saved_model.pb, I loaded the old checkpoints.
 maxvfischer
on 9 Mar 2020
maxvfischer
on 9 Mar 2020
I have spent 3 hours reading through this post and found a solution to this problem (at least in my case):
- do backend.clear_session()
- tf.random.set_seed(0) and np.random.seed(0) of any seed number
- run create_lstm_model()
- load_weights(saved_weight.hdf5)
- model.predict()
Even models.load_model('my_model.h5') and then load_weights(saved_weight.hdf5) would not work!
And try to keep the python thread number to only 1, other concurrent python process may (or may not) potentially affect the result.
Could you please explain a little bit more. Specifically, what did you do with concurrency? Could you please share the commands you ran or the settings you used.
k1moradi
on 14 Mar 2020
So just some further information, I think this is related to using keras with GPU enabled, as the same code running on a laptop was just fine. I couldn't figure it out but I did find a workaround, using a ModelCheckpoint to save after every epoch using callbacks
from keras.callbacks import ModelCheckpoint fpath = os.path.join("model", fname+ ".hdf5") checkpointer = ModelCheckpoint(filepath=fpath, monitor='val_loss', save_best_only=True, verbose=1) history = model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size, validation_data=(x_test, y_test), callbacks=[checkpointer], verbose=2)then just load it like normal
fpath = os.path.join("model", fname + ".hdf5") model.load_weights(fpath)(I was using Sequential model, with Adam optimizer and sparse_categorical_crossentropy loss)
Original code:
https://github.com/markadivalerio/audio-classifier-project/blob/master/audio-classifier-project.ipynb
No, the problem is not GPU related only. It is not even platform-specific. I could reproduce it in Windows and Linux using GPU, and CPU, MKL or Eigen.
k1moradi
on 14 Mar 2020
I have a similar issue when I save weights of a sequential model with dense layers that are built and optimized via Keras API of TensorFlow 2.0. I have started to suspect that the saved tensors have different decimal accuracy or maybe they are getting rounded to zero in some cases.
have you found any solution? I have the same problem training a reinforcement learning agent.
 PSXBRosa
on 22 Mar 2020
PSXBRosa
on 22 Mar 2020
have you found any solution? I have the same problem training a reinforcement learning agent.
Not yet. I tried TF 2.0, 2.1, Linux, Windows, CPU-Eigen version, CPU-MKL version, GPU version on anaconda, setting the NumPy and Keras random seed to zero, and disabling initializer altogether without any luck. However, I have noticed loading the weights, the convergence chance increases. I wished developers actively working on this issue.
k1moradi
on 22 Mar 2020
Hi guys! I'm facing the same issue.
 NikhilKothari
on 22 Mar 2020
NikhilKothari
on 22 Mar 2020
Hi,
I make a small report on the issue concerning the saving and loading of the keras model+weights for a re-use in other circumtances. Please visit this link for similar issues.
I am using keras functional API (v. 2.3.1) for developing a model aiming at predicting values of three different parameters that are then compared with the true ones. The version of Tenforflow is 2.1. I use model.save(file_path) function in '.h5' extension where both the model's architecture and weights are simultanously saved.Fisrt of all my loaded model was displaying various weights but not that much, the differencies were quite smalls. This happened because once the model reloaded, I was retraining it before plotting the training losses, errors, predictions, etc. A surprising thing I observed is that the training losses plotted from the retraning process of the saved model was not varying too much. As I was changing the data, the features were simillar. However, when I just reload and perform predictions without retraining, I obtain the same results with the same data. if I change the data, I do obtain different prediction errors simply because the data are not the same, but only the model and weights are preserved during the saving stage.Therefore the lesson I learnt from this is that, when we reload the model which has already been pre-trained, we do not have to train it again. We just need to directly perform predictions on new and unknown data!
 D-Wolf1
on 25 Mar 2020
D-Wolf1
on 25 Mar 2020
However, when I just reload and perform predictions without retraining, I obtain the same results with the same data.
We do exactly as you say but we get different results. I am doing regression not classification. How about you? Do you compile yourself, use Anaconda or sth else?
k1moradi
on 25 Mar 2020
How do you generate the vocabulary? As mentioned above, if you used a dictionary, it will have a different ordering each time, so you are predicting to a randomized word set.
You need to save the dictionary and reload it. There is a project (preprocessing) to create Layer objects to include the dictionary in the saved model.
Lance
On Wednesday, March 25, 2020, 04:51:50 PM PDT, vrvlive notifications@github.com wrote:
I am facing the same issue. Huge variation in accuracy after loading the model from .h5 file.
Accuracy
I am using
Tensorflow Version - 2.1.0 (GPU)
Keras Version - 2.2.4-tf
with a simple model given below.
model = tf.keras.models.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(6, activation='softmax')
])
Not sure whether the model state saving and loading is the issue here as it is discussed in the following thread. I have observed that the accuracy remains the same if the model is trained in the same session, even if the same model is reloaded after saving to a file. But accuracy changes if we load and test on the same data without re training.
https://stackoverflow.com/questions/42551628/on-loading-the-saved-keras-sequential-model-my-test-data-gives-low-accuracy-in
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub, or unsubscribe.
LanceNorskog
on 26 Mar 2020
Thanks Lance, for the reply. Quickly realized the issue and that was the reason the post was deleted. It was the dictionary.
 vrvlive
on 26 Mar 2020
vrvlive
on 26 Mar 2020
However, when I just reload and perform predictions without retraining, I obtain the same results with the same data.
We do exactly as you say but we get different results. I am doing regression not classification. How about you? Do you compile yourself, use Anaconda or sth else?
I am doing regression as well. I compile the model by myself before training. Do no longer compile once the model loaded. I directly apply it to the 'predict' fucntion. The training of the model on the same data gives me the identical outcomes. Where do you include the syntax or command line for saving your model with weights? I include it after the 'model.fit() command line in my code. I do not know if it matters enough but checking may help.
D-Wolf1
on 26 Mar 2020
However, when I just reload and perform predictions without retraining, I obtain the same results with the same data.
We do exactly as you say but we get different results. I am doing regression not classification. How about you? Do you compile yourself, use Anaconda or sth else?
I am doing regression as well. I compile the model by myself before training. Do no longer compile once the model loaded. I directly apply it to the 'predict' fucntion. The training of the model on the same data gives me the identical outcomes. Where do you include the syntax or command line for saving your model with weights? I include it after the 'model.fit() command line in my code. I do not know if it matters enough but checking may help.
I am using jupyter in the anaconda repository.
D-Wolf1
on 26 Mar 2020
I had the same problem, I was using data generator to feed the data into the model and I made it shuffled (shuffle =True ), so when I made predict It predicts correctly but storing the output shuffled as the same way it gets from the generator, so I just changed it from True to False and everything runs smoothly
you can make sure you have my problem if you make model.evaluate() and you get the same accuracy value of training
this is my data generator
valid_it = valid_datagen.flow_from_directory(directory=".path",batch_size=64, shuffle=False,
target_size=(img_rows, img_cols))
this the prediction part
from sklearn.metrics import classification_report, confusion_matrix
y=model.predict(x=valid_it, verbose=1, steps=valid_it.samples//valid_it.batch_size+1,workers=128)
y_pred = np.argmax(y, axis=1)
print('Confusion Matrix')
print(confusion_matrix(valid_it.classes, y_pred))
print('Classification Report')
target_names = ['ND', 'D']
print(classification_report(valid_it.classes, y_pred, target_names=target_names))
hope it helps you
I also found some details about an error in batch normalization layer when you make transfer learning , it might be your problem
 zeyad3ezzat
on 26 Mar 2020
zeyad3ezzat
on 26 Mar 2020
I recall there is a project to make a Layer that encodes the dictionary, which will cause the dictionary to be stored with the model. That would fix this problem permanently.
On Wednesday, March 25, 2020, 06:35:06 PM PDT, vrvlive notifications@github.com wrote:
Thanks Lance, for the reply. Quickly realized the issue and that was the reason the post was deleted. It was the dictionary.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub, or unsubscribe.
LanceNorskog
on 26 Mar 2020
I was using data generator to feed the data into the model and I made it shuffled (shuffle =True ).
I am not using a data generator since my whole dataset fits into memory. I tried to train and test with the whole dataset so that shuffling does not change the results. If it helps to debug, I might be able to share a simplified version of code and data.
k1moradi
on 26 Mar 2020
I am still facing the same issue.
I suspect it is because of lamda layers
 Walid-Ahmed
on 1 Apr 2020
Walid-Ahmed
on 1 Apr 2020
I solved my problem
It was because improper creation of lamda layers in a loop
Walid-Ahmed
on 5 Apr 2020
I solved my problem
It was because of improper creation of lamda layers in a loop
It was a problem with your code or a bug in Keras API? Could you please explain a little bit more about what you did?
k1moradi
on 7 Apr 2020
@k1moradi
The solution is to use arguments option in Lambda layer such that the corresponding argument can be passed correctly to seperatly defined function.
def funName(x, i, j):
....................
Lambda(funName, arguments={'i':b, 'j':e})(x)
Walid-Ahmed
on 7 Apr 2020
Sorry, but I do not understand. I am just loading network weights from a .h5 file. You mean I should change all of my custom build functions this way?
k1moradi
on 12 Apr 2020
@k1moradi
You need to edit the code you use to define model to create lamda layer in proper way and then retrain
Walid-Ahmed
on 14 Apr 2020
Hello @Walid-Ahmed
I am having this problem of different acc afterload (on same exact data).
I am using lots of lambda for example to divide dimensions (creata a path for each index of one dimension ):
varsVec=[]
for x in range(0,inputs.shape[4]):
var=Lambda(lambda element : element[:,:,:,:,x])(inputs)
How do I correct this? Can you help me in identifying what is wrong in my lambda implementation?
Complete code in this thread :
https://github.com/keras-team/keras/issues/13907
and this link :
https://drive.google.com/file/d/1QNj_KuiTmxpFoZhl9fIOD9WNZbMF6IZm/view?usp=sharing
Thanks in advance !
 rjpg
on 15 Apr 2020
rjpg
on 15 Apr 2020
Ok @Walid-Ahmed,
I get it problem solved :
def split(element,x):
return element[:,:,:,:,x]
...
for x in range(0,inputs.shape[4]):
var=Lambda(split,arguments={'x':x})(inputs)
...
Load and save working with equal accuracy !
rjpg
on 15 Apr 2020
In my case, I've saved an Image classification CNN using TF2.1 (tf.keras.save()) and loading the model (tf.keras.models.load_model()) I wasn't able to evaluate it again (model.evaluate) Reason was model not compiled. Which is completely weird...
Solution: What works for me is like mentioned by @FTAsr, I've executed model.evaluate BEFORE saving the model, now after reloading it model.evaluate works perfectly!
Btw, I didn't called evaluate at the begening because I'm validating my model at the same as the training process with model.fit(..., validation_data=(X_test, y_test), ...)
 hzitoun
on 23 Apr 2020
hzitoun
on 23 Apr 2020
@Walid-Ahmed I have tried what u said and it doesn't solve my problem :(
i get this error :
/usr/local/lib/python3.6/dist-packages/keras/engine/network.py:888: UserWarning: Layer lstm_2 was passed non-serializable keyword arguments: {'initial_state': [
'. They will not be included '
 HoudaKilani
on 28 Apr 2020
HoudaKilani
on 28 Apr 2020
I had the same issues as many of you guys. I found my solution! I was forgetting to compile the model. Try loading it as usual and then compile it as you normally would before training any model.
ex.
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
Try it!
 JoseGuzmanZamora
on 3 May 2020
JoseGuzmanZamora
on 3 May 2020
same issue here, I have also checked the weights of the saved model but it seems like if they don't change, really don't know what to do!
I'm using tensorflow 2.1.0 and keras 2.3.1, also doesn't work with tensorflow 2.0.0 and 2.2.0.
Nothing works, also downgrading keras.
Note that there is the same problem while saving with model.save(), saving with pickle and with model.save_weights().
Same problem when i use tensorflow.keras
The same using theano backend
Did somebody understand if it is a keras or a tensorflow problem?
hoping this will help somebody to solve these are the variables into the two models
`
!-- this is the trained model (before saving)
{'name': 'sequential_1', 'trainable': True, 'dtype': 'float32', '_is_compiled': True, '_expects_training_arg': False, '_initial_weights': None, 'supports_masking': False, 'optimizer':
!-- this is the saved model
{'name': 'sequential_1', 'trainable': True, 'dtype': 'float32', '_is_compiled': True, '_expects_training_arg': False, '_initial_weights': None, 'supports_masking': False, 'optimizer':
comparing the above outputs (please do that to confirm what i think) you can see that the names of the layers changes ( "_1" is added at the end of the name).
 Giuppox
on 8 May 2020
Giuppox
on 8 May 2020
Could it be because of precision loss when saving the weights? This can be probably tested if the weights are saved in .npz format instead of .h5
 bjamali
on 29 May 2020
bjamali
on 29 May 2020
Maybe not everybody is dump that I.
But me probleme was that I have rescale it one time and one other time not.
Please check that before, it cost me a lot of time.
 TillFetzer
on 3 Jun 2020
TillFetzer
on 3 Jun 2020
Does you model contain a Upsampling2D layer AND did you specify interpolation?
# Example
x = UpSampling2D(2, interpolation="bilinear")(x)
It seems the setting 'interpolation' is NOT saved with the model. Therefore, when loading the model, UpSampling2D layers get the default 'nearest' interpolation when loading. Because the model was trained with 'bilinear' interpolation it will not perform as well when given 'nearest' interpolation after loading.
In tensorflow 1.14.0 this seems to be the case. It seems fixed in tensorflow 1.15.0.
WORKAROUND 1
- Create the model with the original code
- Now load the save weights from either the .h5 of .hdf5 file using model.load_weights(...)
WORKAROUND 2
- In the model JSON file, add "interpolation": "bilinear" to the config of UpSampling2D layers.
- Now load, this works, even in tensorflow 1.14.0
WORKAROUND 3
- After loading the model, look in model.layers and for each UpSampling2D layer, change the interpolation
I also noticed that the .h5 file is smaller (8MB) than the .hdf5 file (25MB) but the contents seems similar, probably compression. I proved this by getting original model performance after loading either. Also comparing the loaded weights and precision (float32) was equal.
Lastly, took me 4 hours. I found this issue by having the good and bad model simultaneously loaded in a Jupyter notebook. Then, I let both models predict a single sample and compared the output after each layer until a difference occurred. In my case after layer 35 which was the first Upsampling2D layer.
layer_no = 34
inf_good = Model(inputs=model_good.input, outputs=[model_good.layers[layer_no].output])
inf_bad = Model(inputs=model_bad.input, outputs=[model_bad.layers[layer_no].output])
pred_sample = 2
plt.imshow(np.squeeze(X[pred_sample]))
p_good = inf_good.predict(X[pred_sample:pred_sample+1])
p_bad = inf_bad.predict(X[pred_sample:pred_sample+1])
(p_good == p_bad).all()
Hope this helps
 udevnl
on 4 Jun 2020
udevnl
on 4 Jun 2020
Here a piece of code that will tell you if you have problem:
# Determine if the model has any UpSampling2D layers that use interpolation other than 'nearest'
model_at_risk = False
for l in model.layers:
if 'UpSampling2D' in str(l):
if l.interpolation != 'nearest':
model_at_risk = True
break
# Check if interpolation settings are saved in the model JSON
model_json = model.to_json()
if 'interpolation' in model_json:
print("OK (interpolation settings are saved)")
else:
if model_at_risk:
print("ERROR, interpolation settings are lost and will get default values on load.")
else:
print("OK, your model has no UpSampling2D layers that use non-default interpolation.")
after wasting so much time reading this thread to no real end, i fixed the cause of this issue for my code.
The cause was that i used a word index when tokenizing the training data, but a much reduced word index when tokeninzing the prediction data.
What you need to do is to store the tokenizer when training, then load it when predicting.
here are some snippets you might find useful:
save the tokenizer when training:
tokenizer_json = tokenizer.to_json()
with open(model_name+'_tokenizer.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(tokenizer_json, ensure_ascii=False))
then load same tokenizer when using the model:
with open(model_name+'_tokenizer.json') as f:
data = json.load(f)
tokenizer = tokenizer_from_json(data)
Turns out to be a logic issue, not a bug
Hope this helps someone!
 Max-Lumnar
on 11 Jun 2020
Max-Lumnar
on 11 Jun 2020
Yes! Keras is now adding tokenizers as Layers, so that model.save() will save and restore the tokenizer state to avoid this problem.
On Thursday, June 11, 2020, 02:40:53 AM PDT, Max Lumnar notifications@github.com wrote:
after wasting so much time reading this thread to no real end, i fixed the cause of this issue for my code.
The cause was that i used a word index when tokenizing the training data, but a much reduced word index when tokeninzing the prediction data.
What you need to do is to store the tokenizer when training, then load it when predicting.
here are some snippets you might find useful:
save the tokenizer when training:
tokenizer_json = tokenizer.to_json() with open(model_name+'_tokenizer.json', 'w', encoding='utf-8') as f: f.write(json.dumps(tokenizer_json, ensure_ascii=False))
then load same tokenizer when using the model:
with open(model_name+'_tokenizer.json') as f: data = json.load(f) tokenizer = tokenizer_from_json(data)
Turns out to be a logic issue, not a bug
Hope this helps someone!
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub, or unsubscribe.
LanceNorskog
on 12 Jun 2020
I have the same problem and I haven't figured out the problems of model.save and load. I find another way to save and load the model and it works for me. To save the model, we can save the architecture and the weights separately and load them separately.
save the architecture to a file
with open('path', 'w') as f:
f.write(model.to_json())
save the weights
model.save_weights('path')
load
with open('path', 'w') as f:
model = tf.keras.models.model_from_json('path')
model.load_weights('path')
compile the model
model.compile(...)
 nbe000
on 12 Jun 2020
nbe000
on 12 Jun 2020
I'm training a LSTM RNN for description generation using Keras (Tensorflow Backend) with MSCOCO dataset. When training the model it had 92% accuracy with 0.79 loss. Further when the model was training I tested the description generation at each epoch and the model provided very good predictions with a meaningful description when it gives a random word.
However after training I loaded the model using model.load_weights(WEIGHTS) method in Keras and tried to create a description by giving a random word as I've done before. But now model is not providing a meaningful description and it just outputs random words which has no meaning at all.
I checked weight values and they are same too.
My model parameters are:
10 LSTM layers
Learning rate: 0.04
Activation: Softmax
Loss Function: Categorical Cross entropy
Optimizer: rmspropMy Tesorflow version: 1.2.1
Python: 3.5
Keras Version: 2.0.6Does anyone have a solution for this ?
Have you solved the problem? If so, can you share how you solved it?
 qiong-sportsbet
on 18 Jun 2020
qiong-sportsbet
on 18 Jun 2020
@qiong-sportsbet are you saving and reloading the dictionary? The mapping from words to numbers used in the output?
Python dictionaries are created in random order.
LanceNorskog
on 19 Jun 2020
I was able to work around this problem by using TensorFlow Saver.
Training
import tensorflow as tf
import keras
...
[ code of your model here]
...
model.fit()
saver = tf.train.Saver()
sess = keras.backend.get_session()
saver.save(sess, './keras_model')model.save('keras_model.hdf5')
Testingimport tensorflow as tf
import kerasmodel = keras.models.load_model('keras_model.hdf5')
saver = tf.train.Saver()
sess = keras.backend.get_session()
saver.restore(sess, './keras_model')model.predict(inputs)
...
[the rest of your code here]
With this code, I'm getting same results in training and prediction :)
This solution is no more working as Saver() not running on TensorFlow 2
 maisonhai3
on 1 Jul 2020
maisonhai3
on 1 Jul 2020
I had the same problem, I was using data generator to feed the data into the model and I made it shuffled (shuffle =True ), so when I made predict It predicts correctly but storing the output shuffled as the same way it gets from the generator, so I just changed it from True to False and everything runs smoothly
you can make sure you have my problem if you make model.evaluate() and you get the same accuracy value of training
this is my data generatorvalid_it = valid_datagen.flow_from_directory(directory=".path",batch_size=64, shuffle=False, target_size=(img_rows, img_cols))this the prediction part
from sklearn.metrics import classification_report, confusion_matrix y=model.predict(x=valid_it, verbose=1, steps=valid_it.samples//valid_it.batch_size+1,workers=128) y_pred = np.argmax(y, axis=1) print('Confusion Matrix') print(confusion_matrix(valid_it.classes, y_pred)) print('Classification Report') target_names = ['ND', 'D'] print(classification_report(valid_it.classes, y_pred, target_names=target_names))hope it helps you
I also found some details about an error in batch normalization layer when you make transfer learning , it might be your problem
YESSSSS!!! You did it!! Somehow the shuffle=True messes the predictions up. The model predicts correctly but giving predictions in shuffling, which mismatch the test set's ground truth.
In the flow_from_directory of test set, change shuffle=True -> False will address the problem.
Here is my reproduce:
Data: 360 Fruit.
train = ImageDataGenerator.flow_from_directory(shuffle=True)
test = ImageDataGenerator.flow_from_directory(shuffle=True)
Here the problem happened. Let's take a look at:
test.classes OR test.labels
You will see the ground truth is ascending, from 0 0 .. 121.. 131. It did NOT show any trace of shuffle=True.
But while we run the predictions:
y_pred = model.predict(test)
y_pred = np.argmax(y_pred)
Then,
print(y_pred)
y_pred is shuffled, not ascending at all. Then,
print(classification(test.labels, y_pred) will be almost zero for every class.
Again, setting shuffle=False in test solves this issue.
maisonhai3
on 1 Jul 2020
The only way to test this accurately is to do the prediction in a separate
file independent from the training part.
In my case the issue was the wrong vocabulary, and you can't say it works
till you tested within a different file from scratch
On Wed, Jul 1, 2020, 19:05 Mai_Hai notifications@github.com wrote:
I had the same problem, I was using data generator to feed the data into
the model and I made it shuffled (shuffle =True ), so when I made predict
It predicts correctly but storing the output shuffled as the same way it
gets from the generator, so I just changed it from True to False and
everything runs smoothly
you can make sure you have my problem if you make model.evaluate() and you
get the same accuracy value of training
this is my data generatorvalid_it = valid_datagen.flow_from_directory(directory=".path",batch_size=64, shuffle=False,
target_size=(img_rows, img_cols))this the prediction part
from sklearn.metrics import classification_report, confusion_matrix
y=model.predict(x=valid_it, verbose=1, steps=valid_it.samples//valid_it.batch_size+1,workers=128)y_pred = np.argmax(y, axis=1)
print('Confusion Matrix')
print(confusion_matrix(valid_it.classes, y_pred))
print('Classification Report')
target_names = ['ND', 'D']
print(classification_report(valid_it.classes, y_pred, target_names=target_names))hope it helps you
I also found some details about an error in batch normalization layer when
you make transfer learning , it might be your problemYESSSSS!!! You did it!! Somehow the shuffle=True messes the predictions
up. The model predicts correctly but giving predictions in shuffling, which
mismatch the test set's ground truth.In the flow_from_directory of test set, change shuffle=True -> False will
address the problem.Here is my reproduce:
Data: 360 Fruit.
train = ImageDataGenerator.flow_from_directory(shuffle=True)
test = ImageDataGenerator.flow_from_directory(shuffle=True)Here the problem happened. Let's take a look at:
test.classes OR test.labels
You will see the ground truth is ascending, from 0 0 .. 121.. 131. It did
NOT show any trace of shuffle=True.But while we run the predictions:
y_pred = model.predict(test)
y_pred = np.argmax(y_pred)Then,
print(y_pred)
y_pred is shuffled, not ascending at all. Then,
print(classification(test.labels, y_pred) will be almost zero for every
class.Again, setting shuffle=False in test solves this issue.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/keras-team/keras/issues/4875#issuecomment-652508523,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AEZQNFG7JPRGPUON5JDEV3DRZNNFLANCNFSM4C3AFSNQ
.
Max-Lumnar
on 2 Jul 2020
Has anyone solved this problem?
 SuperSupeng
on 30 Jul 2020
SuperSupeng
on 30 Jul 2020
I also face precision loss (about 5 percent) and I think it is because the ''saved model'' saves weights with a lower precision than the ''fit'' function have calculated. I do not know how to solve this.
It shows itself when I multiply two weights together and multiply the result again to a variable. ( i mean lots of math operations on a single variable)
 alirezaghader
on 8 Aug 2020
alirezaghader
on 8 Aug 2020
May be it helps somebody, but in my case the error was in my code while generating indexes for words:
index_word = dict(zip(range(len(all_words)), all_words))
changed to
index_word = dict(zip(range(len(all_words)), sorted(all_words)))
index_word dictionary was not the same on every run
 amurgit
on 20 Aug 2020
amurgit
on 20 Aug 2020
Is this issue fixed? I have tried different ways like setting random seed,PYTHONHASHSEED, manual_variable_initialization(True) but still facing the issue. Please help
 chinnuviswan
on 8 Sep 2020
chinnuviswan
on 8 Sep 2020
When I load the model in different session its behaving like an untrained new model otherwise if evaluated from same session gives proper accuracy.
chinnuviswan
on 8 Sep 2020
I got the same issue when using Custom Layer.
Same session always works, but once I open another session and load model & weight, the result is random.
I don't know if someone is getting the same issue with me as following:
- At the beginning, I trained with epochs=100, it works, I saved and loaded ( same session), still work
- I loaded model and weight in another session, result is random. Let name this model is model1
I trained model1 again with epochs=5 (5 is just enough), it works again, I saved model to model_saved_2 - I load model_saved_2, result is random again, I train epochs=5, it works again
then again and again => This never end.
It seems, the loaded model was trained but lost something.
I have compared model & weight, before save & after load are the same.
I tried many ways but keep failing, anyone can help ?
 MichaelCash
on 8 Sep 2020
MichaelCash
on 8 Sep 2020
I got the same issue when use or not use Custom Layer.
 allen20200111
on 18 Sep 2020
allen20200111
on 18 Sep 2020
I found the solution to this via stack overflow finally. Its coming from the line in which a set was being converted to list. As a set is always unordered and are loaded randomly. So while converting them to a list each time different randomness is created. so instead of loading list(set(s)) you need to do sorted(list(set(s))). This solved my issue and i am able to reproduce the model behavior in every session. Besides this I also tried setting random seeds. Hope this helps
chinnuviswan
on 20 Sep 2020
I found the solution to this via stack overflow finally. Its coming from the line in which a set was being converted to list. As a set is always unordered and are loaded randomly. So while converting them to a list each time different randomness is created. so instead of loading list(set(s)) you need to do sorted(list(set(s))). This solved my issue and i am able to reproduce the model behavior in every session. Besides this I also tried setting random seeds. Hope this helps
My model had a similar issue with set function as well. Using a sorted list, the problem is partially mitigated, but still reloading the model I see a few percent drops in model accuracy.
k1moradi
on 20 Sep 2020
I am trying to save a simple LSTM model for text classification. The input of the model is padded vectorized sentences.
model = Sequential() model.add(LSTM(40, input_shape=(16, 32))) model.add(Dense(20)) model.add(Dense(8, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])For saving I'm using the following snippet:
for i in range(50): from sklearn.cross_validation import train_test_split data_train, data_test, labels_train, labels_test = train_test_split(feature_set, dummy_y, test_size=0.1, random_state=i) accuracy = 0.0 try: with open('/app/accuracy', 'r') as file: for line in file: accuracy = float(line) except Exception: print("error") model.fit(data_train, labels_train, nb_epoch=50) loss, acc = model.evaluate(feature_set, dummy_y) if acc > accuracy: model.save_weights("model.h5", overwrite=True) model.save('my_model.h5', overwrite=True) print("Saved model to disk.\nAccuracy:") print(acc) with open('/app/accuracy', 'w') as file: file.write('%f' % acc)But whenever I'm trying to load the same model
from keras.models import load_model model = load_model('my_model.h5')I'm getting random accuracy like an untrained model. same result even when trying to load weights separately.
If I set the weightslstmweights=model.get_weights() model2.set_weights(lstmweights)like above. It is working if
modelandmodel2are run under same session (same notebook session). If I serializelstmweightsand try to load it from different place, again I'm getting result like untrained model. It seems saving only the weights are not enough. So why model.save is not working. Any known point?
Hi, I had the same exact issue.
Looking on some of StackOverflow's posts i found out it has something to do with an ENV variable called PYTHONHASHSEED.
You need to set it to a fixed number otherwise everytime that python wants to hash smth it is totally different.
 LBartolini
on 28 Sep 2020
LBartolini
on 28 Sep 2020
I am trying to save a simple LSTM model for text classification. The input of the model is padded vectorized sentences.
model = Sequential() model.add(LSTM(40, input_shape=(16, 32))) model.add(Dense(20)) model.add(Dense(8, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])For saving I'm using the following snippet:
for i in range(50): from sklearn.cross_validation import train_test_split data_train, data_test, labels_train, labels_test = train_test_split(feature_set, dummy_y, test_size=0.1, random_state=i) accuracy = 0.0 try: with open('/app/accuracy', 'r') as file: for line in file: accuracy = float(line) except Exception: print("error") model.fit(data_train, labels_train, nb_epoch=50) loss, acc = model.evaluate(feature_set, dummy_y) if acc > accuracy: model.save_weights("model.h5", overwrite=True) model.save('my_model.h5', overwrite=True) print("Saved model to disk.\nAccuracy:") print(acc) with open('/app/accuracy', 'w') as file: file.write('%f' % acc)But whenever I'm trying to load the same model
from keras.models import load_model model = load_model('my_model.h5')I'm getting random accuracy like an untrained model. same result even when trying to load weights separately.
If I set the weightslstmweights=model.get_weights() model2.set_weights(lstmweights)like above. It is working if
modelandmodel2are run under same session (same notebook session). If I serializelstmweightsand try to load it from different place, again I'm getting result like untrained model. It seems saving only the weights are not enough. So why model.save is not working. Any known point?
Hi, try to set env variable PYTHONHASHSEED to a fixed number, it fixed my problem.
LBartolini
on 28 Sep 2020
I have a similar problem.
I trained a CNN that had proper accuracy on test set and I saved it in h5 format. I can load the model in another session, the architecture is correct, the weights are correct. However, the loaded model performs poorly in terms of accuracy on test set.
The weird thing is that the loss on test set is same for both original model and loaded model, just the accuracy drops significantly (around 90%).
SOLVED
Edit: I learned that the problem was because of the BatchNormalization layers in my network. In this link,
https://keras.io/api/layers/normalization_layers/batch_normalization/
You can see the following sentence:
"Importantly, batch normalization works differently during training and during inference."
If you read the whole part, it says that to use learned batch statistics for inference, set training=False and use the model as follows,
output = model(input, training = False)
instead of model.evaluate().
When I compare the output of network with the labels manually, I observe the trained behavior.
However, I cannot get the same result with model.evaluate()
 atalay1
on 30 Sep 2020
atalay1
on 30 Sep 2020
I have the same problem and I haven't figured out the problems of model.save and load. I find another way to save and load the model and it works for me. To save the model, we can save the architecture and the weights separately and load them separately.
save the architecture to a file
with open('path', 'w') as f:
f.write(model.to_json())save the weights
model.save_weights('path')
load
with open('path', 'w') as f:
model = tf.keras.models.model_from_json('path')
model.load_weights('path')compile the model
model.compile(...)
Thank. you,
I did like so:
best_model.save('./best_model')
best_model.save_weights('./best_model_w')
best_model.evaluate(test_images, test_labels)
_loss: 0.5851 - accuracy: 0.7930_
_and then_
loaded_model = keras.models.load_model('./best_model')
loaded_model.load_weights('./best_model_w')
loaded_model.compile(
optimizer = 'adam',
loss = keras.losses.SparseCategoricalCrossentropy(),
metrics = ['accuracy']
)`
loaded_model.evaluate(test_images, test_labels)
_loss: 0.5851 - accuracy: 0.7930_
 Ildar5
on 2 Oct 2020
Ildar5
on 2 Oct 2020
This is happening to me either. I don't have any Batchnormalization layer. I have the latest version of Tensorflow 2.3.1
 hamidkhb
on 7 Oct 2020
hamidkhb
on 7 Oct 2020
As on 20th Oct 2020.
if anyone is still looking around, using python 3.610.
Stacked GRU model with masking layer
Model.save and load_model not working for keras 2.3.1 and tensor flow 2.2.0
using model.to_json and models.model_from_json also doesn't work.
The loaded model has definitely something missing and gives way lesser accuracy as the saved model in a different session/spyder consoles.
upgrade the packages to keras 2.4.3 and tensorflow 2.3.0. together.
 akbaramed
on 20 Oct 2020
akbaramed
on 20 Oct 2020
As on 20th Oct 2020.
if anyone is still looking around, using python 3.610.
Stacked GRU model with masking layer
Model.save and load_model not working for keras 2.3.1 and tensor flow 2.2.0
using model.to_json and models.model_from_json also doesn't work.
The loaded model has definitely something missing and gives way lesser accuracy as the saved model in a different session/spyder consoles.
upgrade the packages to keras 2.4.3 and tensorflow 2.3.0. together.
thanks, I will try.
Ildar5
on 22 Oct 2020
As a fresh machine-learning student I'm facing this issue as well. Thanks to that issue, there is nothing left to read in Keras' documentation, I've learned a lot so far cuz of this issue:)
I've already checked out: #13 #4904 #11335
@gokceneraslan could you check my codes below?
Here is my setup:
- Python 3.8.6
- Keras 2.4.3
- TensorFlow 2.3.1
- Windows10 and using PowerShell
I created a simple LSTM based hand-written number detection with MNIST dataset. You can see the code below lstm_mnist.py:
import logging
logging.getLogger("tensorflow").setLevel(logging.ERROR)
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, LSTM
from tensorflow import keras
from datetime import datetime
mnist = tf.keras.datasets.mnist
(X_train, Y_train),(X_test, Y_test) = mnist.load_data()
X_train = X_train / 255.0
X_test = X_test / 255.0
Tx = X_train.shape[2]
vocab_size = X_train.shape[1]
class_count = 10
Y_train_oh = np.zeros((Y_train.shape[0], class_count))
for i in range(len(Y_train)):
Y_train_oh[i,Y_train[i]] = 1
Y_test_oh = np.zeros((Y_test.shape[0], class_count))
for i in range(len(Y_test)):
Y_test_oh[i, Y_test[i]] = 1
print('Y_train_oh.shape = ', Y_train_oh.shape)
print('Y_test_oh.shape = ', Y_test_oh.shape)
model_lstm = Sequential()
model_lstm.add(LSTM(32, input_shape=(Tx, vocab_size), activation='tanh', return_sequences=False, stateful=False, name="LSTM_input"))
model_lstm.add(Dropout(0.2))
model_lstm.add(Dense(class_count, activation='softmax', name="LSTM_Dense_Out"))
opt_sgd = tf.keras.optimizers.SGD(lr=1e-3, decay=1e-5, momentum=0.9, name="SGD")
loss_cce = tf.keras.losses.CategoricalCrossentropy(from_logits=False, label_smoothing=0.0, reduction="auto")
metric2 = tf.keras.metrics.CategoricalAccuracy()
model_lstm.compile(loss=loss_cce,
optimizer=opt_sgd,
#metrics=['binary_accuracy'])
metrics=metric2)
log_dir = "logs/fit/" + "LSTM_DNN_1_EPOCH10_" + datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
model_checkpoint_cb = tf.keras.callbacks.ModelCheckpoint(
filepath='./model_outputs/lstm_model_checkpoint',
save_weights_only=True,
monitor='val_accuracy',
mode='max',
save_best_only=True)
history = model_lstm.fit(x=X_train, y=Y_train_oh,
epochs=10, batch_size = 32,
validation_data=(X_test, Y_test_oh),
callbacks=[tensorboard_callback, model_checkpoint_cb],
shuffle=True)
print('Model History Out: ', history.history)
score = model_lstm.evaluate(x=X_test, y=Y_test_oh, verbose=0, return_dict=True)
print(score)
preds = model_lstm.predict(X_test[0:20,:,:])
pred_numbers = np.argmax(preds, axis=1)
print('Y_test = ', Y_test[0:20])
print('pred_numbers = ', pred_numbers)
model_lstm.save('model_outputs/LSTM_DNN_1_MNIST',
overwrite=True,
save_format='tf',
include_optimizer=True,)
model_lstm.save_weights('model_outputs/LSTM_DNN_1_MNIST_WEIGHTS.h5', overwrite=True)
High accuracy is achieved after training as seen below: 0.9487
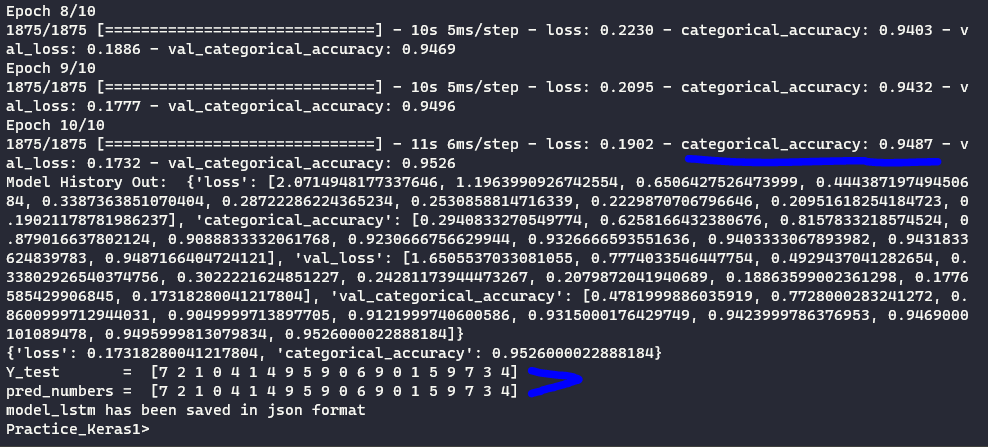
To use my saved-model later, I've created a second python file: lstm_mnist_accuracy.py
import logging
logging.getLogger("tensorflow").setLevel(logging.ERROR)
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, LSTM
from tensorflow import keras
from matplotlib import pyplot as plt
# Keras'in resimleri kullanilacak
mnist = tf.keras.datasets.mnist
(X_train, Y_train),(X_test, Y_test) = mnist.load_data()
# 0 - 9 rakamlari
Tx = X_train.shape[2]
vocab_size = X_train.shape[1]
class_count = 10
#X_train_rs = X_train.reshape(X_train.shape[0], X_train.shape[1]*X_train.shape[2])
#X_test_rs = X_test.reshape(X_test.shape[0], X_test.shape[1]*X_test.shape[2])
print('X_train.shape = ' + str(X_train.shape))
print('Y_train.shape = ' + str(Y_train.shape))
Y_train_oh = np.zeros((Y_train.shape[0], class_count))
for i in range(len(Y_train)):
Y_train_oh[i,Y_train[i]] = 1;
Y_test_oh = np.zeros((Y_test.shape[0], class_count))
for i in range(len(Y_test)):
Y_test_oh[i,Y_test[i]] = 1;
model_lstm = keras.models.load_model('model_outputs/LSTM_DNN_1_MNIST')
#model_lstm.load_weights('model_outputs/LSTM_DNN_1_MNIST_WEIGHTS')
model_lstm.summary()
score = model_lstm.evaluate(X_test, Y_test_oh, verbose=0)
print('Evaulate.score = ', score)
'''
indx_pred = int(input('Prediction index: '))
print('Y_test = ', Y_test[indx_pred])
preds = model_lstm.predict(X_test[indx_pred:(indx_pred+1),:,:])
pred_number = np.argmax(preds)
print('LSTM Based Model Prediction: ', pred_number)
print('LSTM Based Model Possibilities: ')
print(preds)
'''
result_trues = np.zeros((class_count,1))
result_falses = np.zeros((class_count,1))
score = 0.0
score_range = 1000
for i in range(score_range):
#pred = model_lstm.predict(X_test[i:(i+1), :, :])
#print(X_test[i:(i+1),:,:])
pred = model_lstm.predict(X_test[i:(i+1),:,:])
pred_number = np.argmax(pred)
true_val = Y_test[i]
if pred_number == true_val:
result_trues[Y_test[i]] = result_trues[Y_test[i]] + 1
score = score + 1.0
else:
result_falses[Y_test[i]] = result_falses[Y_test[i]] + 1
if (i % 100) == 0:
print('Loading: ', i)
print(result_trues)
print(result_falses)
print('Score = ', score/score_range)
Accuracy after loading model is around 0.15
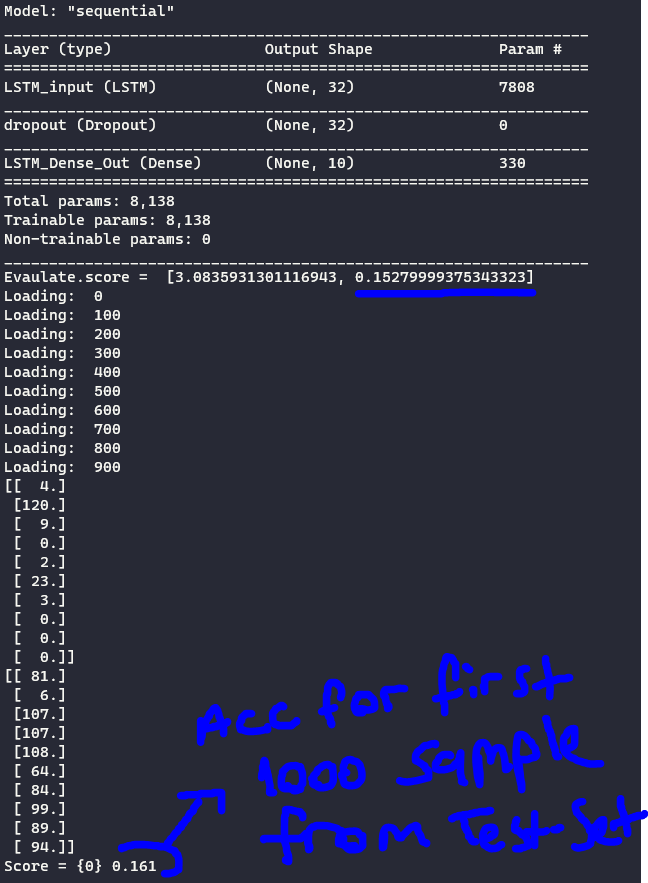
Spent too much time on it, need some tips to solve that issue:)
 namcho
on 29 Oct 2020
namcho
on 29 Oct 2020
You have to load the weights as well , un comment the line
model_lstm.load_weights('model_outputs/LSTM_DNN_1_MNIST_WEIGHTS.h5')
On Fri, Oct 30, 2020, 5:22 AM Nazım YILDIZ notifications@github.com wrote:
As a fresh machine-learning student I'm facing this issue as well. Thanks
to that issue, there is nothing left to read in Keras' documentation, I've
learned a lot so far cuz of this issue:)
I've already checked out: #13
https://github.com/keras-team/keras/pull/13 #4904
https://github.com/keras-team/keras/issues/4904 #11335
https://github.com/keras-team/keras/issues/11335Here is my setup:
- Python 3.8.6
- Keras 2.4.3
- TensorFlow 2.3.1
- Windows10 and using PowerShell
I've created a simple LSTM based hand-written number detection with MNIST
dataset. You can see the code below lstm_mnist.py:import logging
logging.getLogger("tensorflow").setLevel(logging.ERROR)
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, LSTM
from tensorflow import keras
from datetime import datetimemnist = tf.keras.datasets.mnist
(X_train, Y_train),(X_test, Y_test) = mnist.load_data()X_train = X_train / 255.0
X_test = X_test / 255.0Tx = X_train.shape[2]
vocab_size = X_train.shape[1]
class_count = 10Y_train_oh = np.zeros((Y_train.shape[0], class_count))
for i in range(len(Y_train)):
Y_train_oh[i,Y_train[i]] = 1Y_test_oh = np.zeros((Y_test.shape[0], class_count))
for i in range(len(Y_test)):
Y_test_oh[i, Y_test[i]] = 1print('Y_train_oh.shape = ', Y_train_oh.shape)
print('Y_test_oh.shape = ', Y_test_oh.shape)model_lstm = Sequential()
model_lstm.add(LSTM(32, input_shape=(Tx, vocab_size), activation='tanh', return_sequences=False, stateful=False, name="LSTM_input"))
model_lstm.add(Dropout(0.2))model_lstm.add(Dense(class_count, activation='softmax', name="LSTM_Dense_Out"))
opt_sgd = tf.keras.optimizers.SGD(lr=1e-3, decay=1e-5, momentum=0.9, name="SGD")
loss_cce = tf.keras.losses.CategoricalCrossentropy(from_logits=False, label_smoothing=0.0, reduction="auto")
metric2 = tf.keras.metrics.CategoricalAccuracy()model_lstm.compile(loss=loss_cce,
optimizer=opt_sgd,
#metrics=['binary_accuracy'])
metrics=metric2)log_dir = "logs/fit/" + "LSTM_DNN_1_EPOCH10_" + datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)model_checkpoint_cb = tf.keras.callbacks.ModelCheckpoint(
filepath='./model_outputs/lstm_model_checkpoint',
save_weights_only=True,
monitor='val_accuracy',
mode='max',
save_best_only=True)history = model_lstm.fit(x=X_train, y=Y_train_oh,
epochs=10, batch_size = 32,
validation_data=(X_test, Y_test_oh),
callbacks=[tensorboard_callback, model_checkpoint_cb],
shuffle=True)print('Model History Out: ', history.history)
score = model_lstm.evaluate(x=X_test, y=Y_test_oh, verbose=0, return_dict=True)
print(score)preds = model_lstm.predict(X_test[0:20,:,:])
pred_numbers = np.argmax(preds, axis=1)
print('Y_test = ', Y_test[0:20])
print('pred_numbers = ', pred_numbers)model_lstm.save('model_outputs/LSTM_DNN_1_MNIST',
overwrite=True,
save_format='tf',
include_optimizer=True,)
model_lstm.save_weights('model_outputs/LSTM_DNN_1_MNIST_WEIGHTS.h5', overwrite=True)High accuracy is achieved after training as seen below: 0.9487
[image: image]
https://user-images.githubusercontent.com/2217597/97633115-9f70cc00-1a44-11eb-967e-7908d60d1efa.pngTo use my saved-model later, I've created a second python file:
lstm_mnist_accuracy.pyimport logging
logging.getLogger("tensorflow").setLevel(logging.ERROR)
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, LSTM
from tensorflow import keras
from matplotlib import pyplot as pltKeras'in resimleri kullanilacak
mnist = tf.keras.datasets.mnist
(X_train, Y_train),(X_test, Y_test) = mnist.load_data()0 - 9 rakamlari
Tx = X_train.shape[2]
vocab_size = X_train.shape[1]
class_count = 10X_train_rs = X_train.reshape(X_train.shape[0], X_train.shape[1]*X_train.shape[2])
X_test_rs = X_test.reshape(X_test.shape[0], X_test.shape[1]*X_test.shape[2])
print('X_train.shape = ' + str(X_train.shape))
print('Y_train.shape = ' + str(Y_train.shape))Y_train_oh = np.zeros((Y_train.shape[0], class_count))
for i in range(len(Y_train)):
Y_train_oh[i,Y_train[i]] = 1;Y_test_oh = np.zeros((Y_test.shape[0], class_count))
for i in range(len(Y_test)):
Y_test_oh[i,Y_test[i]] = 1;model_lstm = keras.models.load_model('model_outputs/LSTM_DNN_1_MNIST')
model_lstm.load_weights('model_outputs/LSTM_DNN_1_MNIST_WEIGHTS')
model_lstm.summary()
score = model_lstm.evaluate(X_test, Y_test_oh, verbose=0)
print('Evaulate.score = ', score)
'''
indx_pred = int(input('Prediction index: '))
print('Y_test = ', Y_test[indx_pred])preds = model_lstm.predict(X_test[indx_pred:(indx_pred+1),:,:])
pred_number = np.argmax(preds)
print('LSTM Based Model Prediction: ', pred_number)
print('LSTM Based Model Possibilities: ')
print(preds)
'''
result_trues = np.zeros((class_count,1))
result_falses = np.zeros((class_count,1))
score = 0.0score_range = 1000
for i in range(score_range):
#pred = model_lstm.predict(X_test[i:(i+1), :, :])
#print(X_test[i:(i+1),:,:])
pred = model_lstm.predict(X_test[i:(i+1),:,:])
pred_number = np.argmax(pred)
true_val = Y_test[i]
if pred_number == true_val:
result_trues[Y_test[i]] = result_trues[Y_test[i]] + 1
score = score + 1.0
else:
result_falses[Y_test[i]] = result_falses[Y_test[i]] + 1if (i % 100) == 0:
print('Loading: ', i)print(result_trues)
print(result_falses)
print('Score = ', score/score_range)Accuracy after loading model is around 0.15
[image: image]
https://user-images.githubusercontent.com/2217597/97633726-9cc2a680-1a45-11eb-903b-b5cc47c0c0f7.pngSpent too much time on it, need some tips to solve that issue:)
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/keras-team/keras/issues/4875#issuecomment-719030257,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AIC7SYTRT5PL5J4J73KKQQTSNHMKVANCNFSM4C3AFSNQ
.
akbaramed
on 30 Oct 2020
@akbaramed Thanks for advice but I tryed it as well, saved the weights and model in my training python file then loaded both files in other python file, it didn't work. Result was as seen above:(
I've read about hidden state value issue but I think this is not the case...
Actually, I'm not using stateful option so in every batch operation while training hidden values(memory cell and activation state tensors) are getting zero. After training is completed in every begining of the new prediction hidden values should have be zero as aspected.
So in my opinion should be a bug while saving LSTM layers in keras or tensorflow backend.
namcho
on 30 Oct 2020
Its a long shot.
Try using pythonasseed with osenviron
Tensorflow.random.seed and numpy.seed in your train file and same seeds in
your validation file.
On Sat, Oct 31, 2020, 2:32 AM Nazım YILDIZ notifications@github.com wrote:
@akbaramed https://github.com/akbaramed Thanks for advice but I tryed
it as well, saved the weights and model in my training python file then
loaded both files in other python file, it didn't work. Result was as seen
above:(I've read about hidden state value issue but I think this is not the
case...
Actually, I'm not using stateful option so in every batch operation while
training hidden values(memory cell and activation state tensors) are
getting zero. After training is completed in every begining of the new
prediction hidden values should have be zero as aspected.So in my opinion should be a bug in saving LSTM layers in keras or
tensorflow backend.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/keras-team/keras/issues/4875#issuecomment-719725584,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AIC7SYSJWSD2S2QMF7IVNL3SNMBDFANCNFSM4C3AFSNQ
.
akbaramed
on 31 Oct 2020
UPDATE: I did not apply normalization in the second python file that's why I was getting wrong results.
Hi again,
I've tried a couple of things about PYTHONHASHSEEDing and added a piece of code below in both python-files. It did not work.
import os
import sys
hashseed = os.getenv('PYTHONHASHSEED')
if not hashseed:
os.environ['PYTHONHASHSEED'] = '0'
os.execv(sys.executable, [sys.executable] + sys.argv)
I did some debugging and realized that the weights of the after training tensor is not the same as the loaded one.
Weights right after training: Weights were printed with model_lstm.get_weights()
Weights after loading the trained model: Weights were printed with model_lstm.get_weights()
As you can see LSTM layer's weights are completely different.
Basically saving the model and its weights then loading them, I can't see any relation between "hash-seeding" and loading things from a file.
Here is my model: lstm_training.py
# Layer'lari ust uste dizmek icin Sequential modeli kullanalim
model_lstm = Sequential()
model_lstm.add(LSTM(32, input_shape=(Tx, vocab_size), activation='tanh', return_sequences=False, stateful=False, name="LSTM_input"))
model_lstm.add(Dropout(0.2))
model_lstm.add(Dense(128, activation='tanh', name='LSTM_Dense_1'))
model_lstm.add(Dropout(0.1))
# Output layer: 0, 1, ... 9 rakamlarinin softmax ile tespit edildigi layer
model_lstm.add(Dense(class_count, activation='softmax', name="LSTM_Dense_Out"))
bla bla bla...
model_lstm.save('model_outputs/LSTM_DNN_2_MNIST',
overwrite=True,
save_format='tf',
include_optimizer=True,)
model_lstm.save_weights('model_outputs/LSTM_DNN_2_MNIST_WEIGHTS.h5', overwrite=True)
model_lstm.pop()
model_lstm.pop()
model_lstm.pop()
model_lstm.pop()
# After poping we have LSTM layer's weights
print('Weights: ')
print(model_lstm.get_weights())
The second python file is loading the trained model: lstm_loading.py
model_lstm = keras.models.load_model('model_outputs/LSTM_DNN_2_MNIST')
model_lstm.load_weights('model_outputs/LSTM_DNN_2_MNIST_WEIGHTS.h5')
model_lstm.pop()
model_lstm.pop()
model_lstm.pop()
model_lstm.pop()
print('WEIGHTS: ')
print(model_lstm.get_weights())
model_lstm.summary()
@kswersky could you guide me to solve this issue, I'm really stuck on that:(
You can use complete python codes below if you like to debug:
https://github.com/keras-team/keras/issues/4875#issuecomment-719030257
namcho
on 31 Oct 2020
Hi
Have you tried to save the model with include_optimizer=False?
...
model_export_path = 'model.h5'
model.save(filepath=model_export_path, include_optimizer=False)
restored_model = keras.models.load_model(model_export_path)
restore_model.compile(metrics=['accuracy'])
...
I hope this helps :pray:
 ICapalija
on 5 Nov 2020
ICapalija
on 5 Nov 2020
Hi
Have you tried to save the model withinclude_optimizer=False?... model_export_path = 'model.h5' model.save(filepath=model_export_path, include_optimizer=False) restored_model = keras.models.load_model(model_export_path) restore_model.compile(metrics=['accuracy']) ...I hope this helps 🙏
Hi,
Thanks for your suggestion. I haven't tried include_optimizer option but I solved the issue with following steps:
- Uninstalled current tensorflow and keras packages
- Installed tensorflow from nightly build
- With the same code, weights difference has gone
One more extra note: I wasn't applying the normalization in the second python file. This is also important:)
Hope those comments would be helpful for others who struggle with kind of issue.
namcho
on 9 Nov 2020
It worked for me when, after loading the saved model, I compiled it using the same parameters that I used to compile the original one.
 Talendar
on 19 Nov 2020
Talendar
on 19 Nov 2020
Related issues
 braingineer
·
3Comments
braingineer
·
3Comments
 rantsandruse
·
3Comments
rantsandruse
·
3Comments
 anjishnu
·
3Comments
anjishnu
·
3Comments
 oweingrod
·
3Comments
oweingrod
·
3Comments
 amityaffliction
·
3Comments
amityaffliction
·
3Comments
Most helpful comment
I am having the exact same issue. Does anyone know exactly what the problem is?