Hi,
in v0.9.0-beta, the symbol Å is not rendered correctly.
Thank you for the repair!
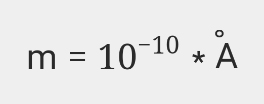
 DominikRocek
DominikRocek
All 10 comments
Which font did you use? On the demo site entering
m=10^{-10} \cdot \text{Å}
works perfectly fine:
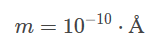
As well as
m=10^{-10}\cdot \text{\r{A}}
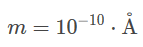
KaTeX does not support the commands \aa or \AA, though.
So I assume it is a problem with the font you are using?
 librilex
on 16 Jan 2018
librilex
on 16 Jan 2018
@librilex I believe the demo site is not on 0.9.0-beta yet, which is why \text{Å} is rendering differently from \text{\r A} in your examples. (It shouldn't, and doesn't on master.)
@DominikRocek Å is currently supported in text mode, but not math mode, because the \r accent is supported in text mode but not math mode. Are you wrapping it in \text?
Developers: Should we consider making Å, and other false Latin-1 characters that we added for backward compatibility, cause a warning in math mode, given that they render incorrectly?
 edemaine
on 16 Jan 2018
edemaine
on 16 Jan 2018
Below I show a test from 0.9.0-beta. It appears that KaTeX does currently support \text{Å} and \text{å}. It just does a poor rendering of both. The math-mode rendering looks good.

Of all the Latin-1 characters added by PR #796, we've regressed only for characters æ, ø, and Ø. I can't get them to render in math mode
 ronkok
on 16 Jan 2018
ronkok
on 16 Jan 2018
Hi,
thank you for the answers. I used textsf{Å}.
When I use: text{Å} .. Result is:

When I use: textsf{Å} .. Result is:

When I use: Å .. Result is:

When I use: mathsf{Å} .. Result is:

My problem solved mathsf{Å}. I use a KaTeX on Android.
DominikRocek
on 16 Jan 2018
I think https://github.com/KaTeX/katex-fonts/pull/5 might fix the issues with the accents as it makes all accents non-combining include the accent for \r which is listed in https://github.com/KaTeX/katex-fonts/pull/5/files#diff-39cb684094d84b58582045c86bd72f75 as "ring above".
 kevinbarabash
on 17 Jan 2018
kevinbarabash
on 17 Jan 2018
Issue #1086 looks like it was a duplicate of this one, but also demonstrated that there are issues with the ring accent over lowercase u (in Czech) and the dot over an uppercase I in Turkish. (Note that those characters are not in the Latin-1 charset, but I just landed a PR the other day to add support for Latin Extended A and B.)
I'm pretty sure that that the LaTeX source code I was using was using the single unicode codepoints, not combining forms to get these diacritics. But the parser is pulling them apart and rendering them as accented forms, which surprises me.
If Kevin is right that this is just a font issue, we could presumably work the Turkish and Czech issues by defining the css class 'latin-fallback' which should be defined on any text{} mode characters in the Latin Extended A and B blocks.
Would it be simpler to to modify the parser so that (in text mode, at least) it doesn't break single accented characters apart into their combining forms?
 davidflanagan
on 24 Jan 2018
davidflanagan
on 24 Jan 2018
This is the HTML I get both text{r A} and text{Å}
<span class="mord text">
<span class="mord accent">
<span class="vlist-t">
<span class="vlist-r">
<span class="vlist" style="height: 0.94677em;">
<span class="" style="top: -3em;">
<span class="pstrut" style="height: 3em;"></span>
<span class="mord">A</span>
</span>
<span class="" style="top: -3.25233em;">
<span class="pstrut" style="height: 3em;"></span>
<span class="accent-body" style="left: -0.375em;">˚</span>
</span></span></span></span></span></span>
So when I use Å in the input, it doesn't just get decomposed into an A and a Unicode combining form, it gets decomposed into an A and a manually positioned ring glyph. In this case, if the -0.375em had been about -0.25em instead we might not have noticed the issue.
Ah ha! I see now that unicodeSymbols.js decomposes all latin accented forms, so that Å really does end up parsing just like r A.
If I comment out this line:
"\u00c5": "\u0041\u030a", // Å = \r{A}
Then I get a parse error for text{Å} because it is not a recognized codepoint.
But since I've just added Latin Extended A and B, I bet that this trick will work for characters in those blocks:
text{ů} displays with the ring too far to the left, but if I comment out unicodeSymbols.js:125 then it displays as a single font glyph and the ring is in the right place. (This only makes it display correctly in text mode, however, and prevents it from displaying in math mode)
I don't know much about unicodeSymbols.js, or how KaTeX uses fonts, but I'd propose that we assume that in text mode all the characters we want are going to be supported directly by the font. I think I'd try to fix this by:
1) modify unicodeScripts() to extend the definition of the Latin script to include all of Latin-1 and not just the extensions. So that Å, for example, is a supported codepoint.
2) Modify Parser.js:1036 so that it only does the unicodeSymbols substitutions in math mode and not in text mode.
3) I was going to say that the third step was to make Å look right in math mode by figuring out why was causing the ring to be mis-positioned. But it turns out that math mode Å has a special case in symbols.js so it doesn't get decomposed in math mode. So I guess just fixing these accented forms in text mode may be all that is needed. (The Czech u with the ring and Turkish I with the dot don't work in math mode, so there is nothing to fix there.)
davidflanagan
on 24 Jan 2018
I'd propose that we assume that in text mode all the characters we want are going to be supported directly by the font
This would result in the fonts being much larger than they are now. Also, I'm not familiar enough with our font pipeline to combine base and accent glyphs into new glyphs. Updating existing accent glyphs from combining to non-combining and using JS to center was the original plan to deal with accent positioning issues. This is how the accents that are positioned correctly work. The only reason why the ring doesn't work is that for some reason we're shifting it left by -125 units when the font is generate. This is equivalent to -0.125em which which would cause the 0.375em position to be correct.
kevinbarabash
on 24 Jan 2018
I was assuming that text{} environments just inherited whatever font was used outside of KaTeX, and that we could assume they had support for all the necessary glyphs. But if KaTeX renders text mode with its own fonts (and I understand that there are probably good typographical reasons for doing that) then either the fonts have to get big or we have to manually handle the accents. So I retract my proposal above.
davidflanagan
on 24 Jan 2018
This was fixed with #1094 except for the position of accent characters in \textit{}. I've opened a separate issue, #1099, to track this.
kevinbarabash
on 29 Jan 2018
Related issues
 HughGrovesArup
·
4Comments
HughGrovesArup
·
4Comments
 hagenw
·
3Comments
hagenw
·
3Comments
 janosh
·
4Comments
janosh
·
4Comments
 OisinMoran
·
4Comments
OisinMoran
·
4Comments
 jason-s
·
3Comments
jason-s
·
3Comments