Incubator-superset: Google BigQuery Support
Currently sqlalchemy does not support a bigquery dialect. Is there any way that BigQuery sources can be added to Caravel, apart from extending sqlalchemy to support BigQuery?
 rlanda
rlanda
All 76 comments
@rlanda take a look at druid support if you want an example on how this could be done
 xrmx
on 15 Aug 2016
xrmx
on 15 Aug 2016
Someone has any news about that?
 burdiyan
on 21 Feb 2017
burdiyan
on 21 Feb 2017
Yeah we're looking at this as well.
 hunt3r
on 21 Feb 2017
hunt3r
on 21 Feb 2017
Hi guys, any news on this? Thanks.
 maxcorbeau
on 9 Apr 2017
maxcorbeau
on 9 Apr 2017
Take a look at this thread. Some progress has been made on getting sqlalchemy to work with big query, but seems like it's not ready yet.
https://groups.google.com/forum/#!topic/sqlalchemy/-DzCGKFA9h4
There are also these projects:
https://pypi.python.org/pypi/sqlalchemy_bigquery/
https://github.com/cpdean/sqlalchemy-bigquery
hunt3r
on 9 Apr 2017
There's 2 approaches here, either going through SqlAlchemy (which may or may not be possible, depending on how messed up the GSQL dialect is), the thing is we only need for a subset of the dialect to work (no need for DML joins, ...). The other option is to create a brand new Supserset connector for it.
I've done some work to make the connectors interface more extendable recently. It's a matter of of deriving the BaseTable, BaseColumn and BaseMetric models, creating the related ModelViews, and implementing a handful of of methods (ok well a bit more than that...). The most complex one is the query method, where you get a time filter, an array of metrics and columns to group by, a set of filters, whether the query is a time series of now, and somehow have to return a pandas dataframe.
A solid Python programmer familiar with Flask/Django should be able to implement this a matter of days, perhaps a week or two. I'd be open to mentor someone through the process. I'm sure we could host the engineer at Airbnb for a week while working on this task. Who's up for the challenge!?
 mistercrunch
on 10 Apr 2017
mistercrunch
on 10 Apr 2017
I would be open to working on this, if this has not been done. I'm familiar with Python and am using superset at my company internally to display various information from redshift (But would like to move us to BQ)
 joshuacano
on 2 May 2017
joshuacano
on 2 May 2017
@joshuacano I'd be happy helping you out while working on this. I see you are in SF and we love to host at Airbnb so we could host you for coding sessions or for a few days while you crank that out.
I can also help improving and clarifying the connector interface while working on this so that it's more straightforward to add the next connectors.
mistercrunch
on 3 May 2017
Wow it would be real honor to meet you @mistercrunch. I'd love to come over for a few coding sessions. Maybe I can get familiar with the code base over the next few days and ping you on gitter once I have an idea of where to get started. Does that sound good?
joshuacano
on 4 May 2017
@joshwalters @mistercrunch thats great, i tried to tackle this issue on my own, but i believe having a spark connector instead of a bigquery is a much neater solution, since you can connect spark to bigquery and much more, hadoop or elastic search.
 Bamieh
on 4 May 2017
Bamieh
on 4 May 2017
@Bamieh , what do you use to connect spark to big query?
 lilila
on 4 May 2017
lilila
on 4 May 2017
@mistercrunch I've started a bit of work on this, Not sure if you use Gitter, but I Wrote you some questions on there to just point me in the right direction. Thanks!
joshuacano
on 12 May 2017
[copied from gitter to keep the conversation here]
joshuacano @joshuacano May 11 22:10
I was just reviewing adding the connector and it seems like this involves essentially mimicking the behavior in superset/connectors/druid OR superset/connectors/sqla. But adapting it to use BQ. However you had indicated that you would make it a bit easier to add a new connector? Do you have any guidance for me here? Thanks so much again!
mistercrunch
on 13 May 2017
So two main approaches:
- Try to make BQ comply to what it needs to go through the
sqlaroute in Superset. This requires essentially 2 things: - a SqlAlchemy dialect, that's easy-ish assuming that BQ SQL is close enough to ANSI SQL. Note that we only need a subset of the dialect defined, only the query part and the method to fetch metadata (tables, columns, views, ...)
- a DBAPI interface: DBAPI is a python standard for how database interfaces should look like. connections and cursor objects, and a set of standard methods.
The pyhive project does both these things on top of both Presto and Hive and can be a source or inspiration here.
- The second approach would be to create a new big_query package under
connectors, and create a brand new connector. This approach is a lot more flexible but it's much more code to write and maintain, and only helps Superset (where SQLALchemy/DBApi) helps BigQuery integration in other tools...
This has been discussed here:
https://github.com/GoogleCloudPlatform/google-cloud-python/issues/2434
mistercrunch
on 13 May 2017
So perhaps the interim solution for me is to go down the connector route, and then depending on the discussion in the issue referenced above, it should be fairly trivial to just turn off the bigquery connector section once that is done. However, it does seem like you might prefer option #1 (and it might be a more long term solution), so I'll defer to you on what direction I should head.
joshuacano
on 14 May 2017
I'd go with solution 1 starting by forking that repo and moving it forward to where it needs to be. This would become a largeish PR against that repo.
mistercrunch
on 15 May 2017
BTW Druid added support for SQL and we'll be going down the same route eventually.
mistercrunch
on 15 May 2017
Any updates on this feature?
 vincentwongso
on 5 Jun 2017
vincentwongso
on 5 Jun 2017
@vincentwongso I think this is currently blocked on my PR https://github.com/GoogleCloudPlatform/google-cloud-python/pull/2921
It's got a bit more work required before it can merge. Specifically, query parameters, executemany(), fetchmany(), and fetchall(). Once that db-api module is available, it should be easy to create a module to add SQLAlchemy support and thus Superset support.
 tswast
on 5 Jun 2017
tswast
on 5 Jun 2017
If anyone needs this feature ASAP, you can try the interface that I've implemented to use BigQuery in Superset: https://github.com/mxmzdlv/pybigquery
It is basic, but querying and query generation works fine. There is no support for Record type, so you'll have to flatten your schema using views.
You will also need to include this snippet of code in superset_config.py for Superset's Time Grain to work. I haven't created a PR as I am not sure if it is a complete engine spec.
Some issues that I've encountered while developing the interface:
- Not sure how to reference datasets. For now I've made them part of a table id, so the table name must contain the dataset, e.g.
dataset.table - As I understand, GROUP BY statement in BigQuery must reference expressions by their labels, e.g.:
SELECT TIMESTAMP_TRUNC(TIMESTAMP(ts), DAY) AS __timestamp, COUNT(*) AS count
FROM dataset.table
GROUP BY __timestamp
So I had to use this hack to make it work. Not sure if there is a better way.
 mxmzdlv
on 7 Jun 2017
mxmzdlv
on 7 Jun 2017
thank you @mxmzdlv its working.. but I want to know about Time Grain.. How to activate it?
 alamhanz
on 12 Jun 2017
alamhanz
on 12 Jun 2017
@alamhanz You'll need to create superset_config.py and put this code in it. Make sure that you have wrapt module installed (pip install wrapt) and superset_config.py is in your PYTHONPATH.
Otherwise you can just add BQEngineSpec class from the snippet to superset/superset/db_engine_specs.py module
mxmzdlv
on 12 Jun 2017
Thank you.. It is working when I put the BQEngineSpec Script on superset/superset/db_engine_specs.py
alamhanz
on 12 Jun 2017
But, I can't use SQL LAB.
"Failed to start remote query on worker. Tell your administrator to verify the availability of the message queue."
this message is pop out after I ran my query.. what should i do?
alamhanz
on 12 Jun 2017
@alamhanz I think this is because your Celery is not configured. Try disabling Allow Run Async in the database settings in superset.
mxmzdlv
on 12 Jun 2017
@mxmzdlv What do you mean by "Celery is not configured"? Then how can I disabling Allow Run Async??
alamhanz
on 14 Jun 2017
@alamhanz check out the installation docs around SQL Lab:
http://superset.apache.org/installation.html#sql-lab
Allow Run Async is a database configuration parameter. Edit the database entry for Big Query and uncheck the box.
mistercrunch
on 27 Jul 2017
@mxmzdlv thanks for writing the engine spec for BigQuery, I'm adding it to the codebase here
https://github.com/apache/incubator-superset/pull/3193
mistercrunch
on 27 Jul 2017
FYI: the DB-API interface for BigQuery is checked in, but not yet released to PyPI.
@mxmzdlv perhaps you could update https://github.com/mxmzdlv/pybigquery to use the official DB-API module when available? Otherwise, I'll investigate what it would take to make an official SQLAlchemy adapter, too.
tswast
on 27 Jul 2017
@tswast I will definitely switch it over to the official DB-API module, thank you.
mxmzdlv
on 30 Jul 2017
I am getting the following error while creating slices in superset.
POST https://www.googleapis.com/bigquery/v2/projects/
Any idea how to resolve this ?
 surya2012
on 8 Aug 2017
surya2012
on 8 Aug 2017
@surya2012 there is currently a problem with autogenerated metrics when you add a new BigQuery datasource – the generated SQL expressions for these metrics contain dataset, e.g. SUM(dataset.table.column). You need to manually remove dataset and just leave a table and a column, e.g. SUM(table.column) and it should be working.
mxmzdlv
on 9 Aug 2017
@mxmzdlv Thank you.. It is working when I removed dataset manually . :)
surya2012
on 9 Aug 2017
Hi, may I ask about the progress of this support?
 teamsoo
on 8 Oct 2017
teamsoo
on 8 Oct 2017
Hi,
What's the latest on this?
 jimanvlad
on 2 Jan 2018
jimanvlad
on 2 Jan 2018
Hi all,
I am trying to connect bigquery to superset using the method specified by @mxmzdlv on Jun 7, 2017. I am receiving an error while connecting. I ran the following code
from sqlalchemy import *
from sqlalchemy.engine import create_engine
from sqlalchemy.schema import *
engine = create_engine('bigquery://my_project_id')
table = Table('Weekly_trial.hour_timeband_mapping', MetaData(bind=engine), autoload=True)
Error I got is as below
sqlalchemy.exc.InterfaceError: (pyodbc.InterfaceError) ('IM002', '[IM002] [Microsoft][ODBC Driver Manager] Data source name not found and no default driver specified (0) (SQLDriverConnect)') (Background on this error at: http://sqlalche.me/e/rvf5)
I ran the above code in command promt in windows 10 in python module.
Please let me know If I am doing anything wrong.
 swamy16
on 26 Apr 2018
swamy16
on 26 Apr 2018
Also I am running these commands from my command promt. I am still unsure of how my superset will be connected to Bigquery. I have not provided any credentials anywhere nor has it been mentioned anywhere. It would be great If anyone can give any clarity on that as well.
swamy16
on 26 Apr 2018
@swamy16 Not sure what's happening, but it seems like it doesn't recognize BigQuery and is trying to use pyodbc db-api instead. I would recommend asking SQLAlchemy community about this.
To run BigQuery in Superset just install pybigquery in the environment with your Superset:
pip install pybigquery --upgrade
Afterwards, create a new Database in Superset (menu Source > Databases) and use the connection string bigquery://your_project_id.
mxmzdlv
on 26 Apr 2018
@mxmzdlv Thanks for your quick response. I tried the method you suggested
pip install pybigquery --upgrade. It didnt work.
Then I uninstalled pyodbc using
pip uninstall pyodbc
and again ran the same commands
engine = create_engine('bigquery://My_database')
I got an error showing
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Users\sachitanandp\venv\lib\site-packages\sqlalchemy\engine\__init__.py", line 419, in create_engine
return strategy.create(*args, **kwargs)
File "C:\Users\sachitanandp\venv\lib\site-packages\sqlalchemy\engine\strategies.py", line 80, in create
dbapi = dialect_cls.dbapi(**dbapi_args)
File "C:\Users\sachitanandp\venv\lib\site-packages\sqlalchemy\connectors\pyodbc.py", line 38, in dbapi
return __import__('pyodbc')
ModuleNotFoundError: No module named 'pyodbc'
I dont know if I am doing the right thing.
swamy16
on 26 Apr 2018

I got this error while trying to connect to bigquery.
swamy16
on 26 Apr 2018
Did you do your pip install within your virtual env?
Only other little things I see different then mine is:
URI has trailing slash ..
bigquery://my-production-bigdata/
and for extras I added some debugging..
{
"metadata_params": {},
"engine_params": {"echo":True}
}
 darylerwin
on 26 Apr 2018
darylerwin
on 26 Apr 2018
@darylerwin @mxmzdlv need your help here again.
@darylerwin I did install superset in venv but still getting the error.
So I created a different venv named venv1 and tried installing everything from scratch. (Now I think I installed everything right).
Here while running the following code
engine = create_engine('bigquery://my_project')
I got the following error
google.auth.exceptions.DefaultCredentialsError: Could not automatically determine credentials. Please set GOOGLE_APPLICATION_CREDENTIALS or
explicitly create credential and re-run the application. For more
information, please see
https://developers.google.com/accounts/docs/application-default-credentials.
(Because of the errormessage I said I did something right although I don't know what)
I have the created a service account key and have the json file in my laptop. I think I have to use the file but amd not sure of how to use it(I mean which folder should I keep the file or in which of the scripts within 'venv1\Lib\site-packages\google\auth' folder ('_cloud_sdk', '_default', '_oauth2client', '_service_account_info', 'app_engine', 'credentials', 'environment_vars') should I modify so that it reads my file and authenticates my google account.
Please do help me with this.
swamy16
on 26 Apr 2018
I set this in my box that is running superset via .profile
export GOOGLE_APPLICATION_CREDENTIALS="/home/derwin/my-production-bigdata-key.json"
And that json file should similar in format to:
{
"type": "service_account",
"project_id": "xxxxxata",
"private_key_id": "cxxxxxxxxb8c5d3d7b03203",
"private_key": "-----BEGIN PRIVATE KEY-----\nMIIEvQ
etcetc
}
@swamy16 : @darylerwin is correct. To use default credentials you must set the GOOGLE_APPLICATION_CREDENTIALS environment variable.
As an alternative, I've filed https://github.com/mxmzdlv/pybigquery/issues/14 to allow specifying path to service account key file via the connection string.
Linux or macOS
Replace [PATH] with the file path of the JSON file that contains your service account key.
export GOOGLE_APPLICATION_CREDENTIALS="[PATH]"
For example:
export GOOGLE_APPLICATION_CREDENTIALS="/home/user/Downloads/service-account-file.json"
Windows
Replace [PATH] with the file path of the JSON file that contains your service account key, and [FILE_NAME] with the filename.
With PowerShell:
$env:GOOGLE_APPLICATION_CREDENTIALS="[PATH]"
For example:
$env:GOOGLE_APPLICATION_CREDENTIALS="C:\Users\username\Downloads\[FILE_NAME].json"
With command prompt:
set GOOGLE_APPLICATION_CREDENTIALS=[PATH]
(From https://cloud.google.com/bigquery/docs/reference/libraries)
tswast
on 26 Apr 2018
@darylerwin @tswast sorry for asking more dumb questions.
when I use the following code
set GOOGLE_APPLICATION_CREDENTIALS="Downloads\My_First_Project_79feb5164038.json"
I get the following error
google.auth.exceptions.DefaultCredentialsError: File "Downloads\My_First_Project_79feb5164038.json" was not found.
Somehow the app is throwing this exception.
swamy16
on 26 Apr 2018
@swamy16 This error is a good sign. It means that you are definitely setting the variable so that the code can find it.
You need to specify the full path when you are setting the variable. On Windows this includes the Disk Name: C:\Users\[YOUR_USER_NAME]\Downloads\[FILE_NAME].json. The path could be anywhere, not just the downloads folder. On Linux or macOS the full path starts with a slash: /home/user/Downloads/service-account-file.json.
tswast
on 26 Apr 2018
@tswast
Initially I tried the same. It is still giving me the error.
Attaching a snapshot of the same,
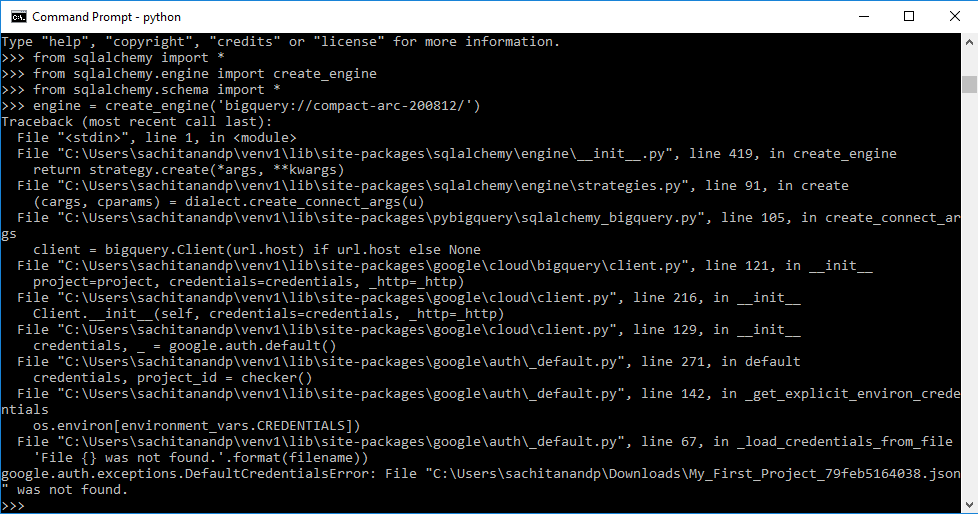
I think I am missing something.
swamy16
on 26 Apr 2018
That's odd. That means Python cannot load the file at that path for some reason. Are you sure the path is correct? Could you run DIR C:\Users\sachitandandp\Downloads\ and check that the file is present?
tswast
on 26 Apr 2018
yea.. Give the whole path..
On Thu, Apr 26, 2018, 5:04 PM Tim Swast notifications@github.com wrote:
That's odd. That means Python cannot load the file at that path for some
reason. Are you sure the path is correct? Could you run DIR
C:\Users\sachitandandp\Downloads\ and check that the file is present?—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/apache/incubator-superset/issues/945#issuecomment-384788427,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AX24-dIxoRXUK_aBXK_nxbXOkcqY9GTsks5tsjZhgaJpZM4JkTQB
.
darylerwin
on 26 Apr 2018
I double checked. The path is correct.
and as for running the command
DIR C:\Users\sachitandandp\Downloads\
I get the following error
The system cannot find the path specified.
I dont know why I am getting this error.
swamy16
on 26 Apr 2018
Also When I try connecting using UI I get the following error.
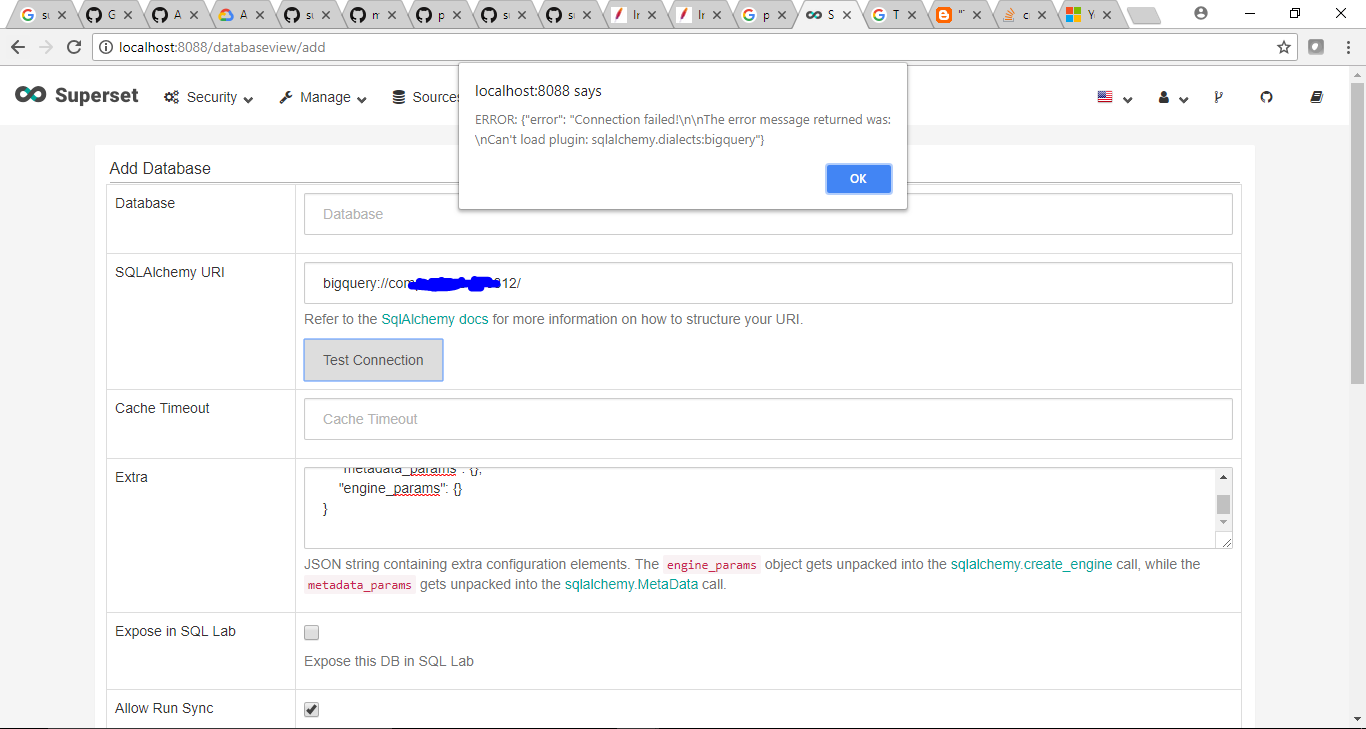
swamy16
on 26 Apr 2018
Where exactly is your .json file located ? Open it in file explorer to get the right path.
The above error means you havent installed the package in the virtualenv.
. ./venv1/bin/activate (or however you activate in windows)
'# Try to install this again .. be sure you are in your virtual env
pip install pybigquery
darylerwin
on 27 Apr 2018
I'm not sure if that may be related, but Superset is not officially supported on Windows. We don't run tests or any sort of build against Windows.
mistercrunch
on 27 Apr 2018
@mistercrunch but the project is dockerized so you can run it inside docker on windows.
Bamieh
on 27 Apr 2018
Good to hear. Which Docker are you referencing? FYI the core team doesn't maintain, test or distribute docker images.
mistercrunch
on 27 Apr 2018
@mistercrunch I host my own DockerFile for superset, also there are community contributed images (like the one mentioned in the README). Superset does not require anything special to run inside a docker so any setup should be more than enough.
Bamieh
on 29 Apr 2018
@tswast @darylerwin @mistercrunch @mxmzdlv @Bamieh
Thanks to you guys (your guidance) I was finally able to connect my superset to bigquery in windows.
For some reason I was not able to set env variable through command promt or windows power shell.
I did it manually through mycomputer/properties/settings/environment variables.
I had to restart superset to make it work though.
@Bamieh Idid not try using docker for running this. I have only heard about docker. Have never practically used it or worked with it. It would be great if you could point me to some resources on it so that I can learn the same.
Now I can see tables and get their count and other things. Please refer below image for the same.

But when I am trying to run the same query from sql lab I am not able to generate any result. It just keeps on running and timesout. The same is happening If I try to query from the default 'main' DB that gets installed for visualising World Bank Data and other dashboards. I get the following error
Module 'signal has no attribute 'SILGRAM'
and the query keeps on running for ever.

Currently I am creating dashboards using a manual process (Upload csv).
Please help me resolve this error.
Also is there a way to share the dashboard made on superset to others who dont have superset (even python) installed on them. Can I share it privately within the organisation I work in?
swamy16
on 1 May 2018
@swamy16 seems to be an issue with calling signal(signal.SIGALRM) — SIGALRM is not available on Windows. https://github.com/apache/incubator-superset/blob/d533ce09676921ec2f72e1032bbca0d2a37f65b6/superset/utils.py#L508
I think the easiest way to handle this would be to run Superset in a Docker / Vagrant or just install Virtualbox with Linux on it and run Superset from there?
mxmzdlv
on 1 May 2018
@mxmzdlv thanks for the help. I shall try installing superset in virtualbox.
also is it possible to share the dashboards I create on superset with others in my organisation who don't have superset or python installed?
swamy16
on 1 May 2018
@swamy16 is that a typo in the alarm and perhaps related to this windows signal python issue?
https://github.com/Unity-Technologies/ml-agents/issues/7
Basically it is timing out? Is the dataset too big?
darylerwin
on 1 May 2018
@darylerwin @mistercrunch
sorry it is a typo from my end. The actual error is SIGALRM as mentioned by @mxmzdlv
Module 'signal has no attribute 'SIGALRM'
The table are small (max size in GB's that too <30GB) as of now. But they can become big(can be as large as in TB's) in future. How big a dataset can Superset handle?
Basically I am able to add tables to superset and am able to visualize them in dashboards (Be it tables from bigquery, or the default main db "world bank dataset" ) but I am not able to query them (even the main db tables from superset sql lab)

As you can see the highlighted part in the above image "tsukuyomi" is a dataset in my bigquery and "2017_agency_mapping" is a table. I am able to create a slice view using tables from my bigquery.

As you can see in the above image I am querying from the main db of the default world bank. But it is not able to query the same in sql labs sql editor.
@mxmzdlv mentioned that this is happening due to SIGALRM not working in windows.
But technically shudn't this error also happen when I am creating a slice. Since it is effectively running the same query.
Please let em know if there is a way to solve this error in windows.
I tried replicate what ASPePeX mentioned in the link you have given Unity-Technologies/ml-agents#7
But I am not able to locate the file in my computer.
/python/unityagents/environment.py
I am also not sure if this is the right approach
swamy16
on 2 May 2018
I wouldn't recommend running on Windows since Superset isn't tested against it. You will hit problems like this one. Even if you'd fix this issue there could be regressions in the future since no one uses Windows to run Superset in production.
mistercrunch
on 2 May 2018
Just to make sure...one can now use BigQuery via SQLAlchemy in Superset?
Not seeing any updates in the documentation: https://github.com/apache/incubator-superset yet
 dirkbosman
on 24 May 2018
dirkbosman
on 24 May 2018
Yes .. it just hasnt made it to the published page yet...
BigQuery pip install pybigquery bigquery://
On Thu, May 24, 2018 at 9:03 AM DJB notifications@github.com wrote:
Just to make sure...one can now use BigQuery via SQLAlchemy in Superset?
Not seeing any updates in the documentation:
https://github.com/apache/incubator-superset yet—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/apache/incubator-superset/issues/945#issuecomment-391706440,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AX24-eY8U3oVYJqnTvRCMgM1FmNdZ6mvks5t1q-tgaJpZM4JkTQB
.
--
Daryl Erwin | Big Data Developer
M. +1 519.748.7953 | BBM PIN. 5D5F0375
E. [email protected] | *W. *bbm.com
Follow us on: Facebook https://www.facebook.com/bbm/ | Twitter
https://twitter.com/BBM | Instagram
https://www.instagram.com/discoverbbm/ | LinkedIn
https://www.linkedin.com/company/discoverbbm | YouTube
https://www.youtube.com/bbm | Vidio https://www.vidio.com/@bbm
BBM used under license by Creative Media Works Pte Ltd *(Co. Regn. No.
201609444E)*
This e-mail is intended only for named addressee(s) and may contain
confidential and/or privileged information. If you are not the named
addressee or have received this e-mail in error, please notify the sender
immediately. The unauthourised disclosure, use or reproduction of this
email's content is prohibited. Unless expressly agreed, no reliance on this
email may be made.
darylerwin
on 24 May 2018
Great! Thanks for the quick reply :) If I can add my 2 cents. Would be great to see an example of how to do the complete set-up in steps and perhaps an example covering the querying of a public BQ Dataset: https://cloud.google.com/bigquery/public-data/ It would help to explain the difference between running query in Standard SQL vs Legacy SQL.
dirkbosman
on 24 May 2018
@darylerwin @dirkjohannesbosman I just updated the docs @ http://superset.apache.org/installation.html#database-dependencies
mistercrunch
on 25 May 2018
@dirkjohannesbosman
as mentioned by @darylerwin and @mistercrunch it is easy to use bigquery via sqlalchemy. You will have to use standard sql though for querying stuff which is quite different from legacy sql.
Let me know if you face any issues in connecting to bigquery.
swamy16
on 25 May 2018
Great, thanks guys for the reply and the docs update 👍
dirkbosman
on 26 May 2018
How do you add BigQuery tables in the Sources -> Tables view? With standard SQL the string is usually project.dataset.table, and I tried to input them in multiple ways in the Schema and Table Name fields. The error I get is either
Table [myproject.mydataset.mytable] could not be found, please double check your database connection, schema, and table name
or
Table [mydataset.mytable] could not be found, please double check your database connection, schema, and table name
My BQ connection works and I can make queries in SQL Lab. I'm using pybigquery.
 amodig
on 30 May 2018
amodig
on 30 May 2018
Hi @amodig Not sure I understood your question correctly.
You might be entering it the wrong way.
In Superset when you click on ad new table
Databases: Select the name you gave to your bigquery connector
Schema: you need to select the name of the dataset in your bigquery (Each of your projects can contain multiple datasets)
Table name: Select the name of the table present in your dataset
Let me know if this helps.
swamy16
on 30 May 2018
@mistercrunch I dont want to be salty but can you lock this thread since it has been closed and resolved, any issues related to this can be opened as new issues.
Bamieh
on 30 May 2018
@swamy16 Ah, NVM, I noticed a GCP Service Account permission issue with SQL Lab. The connection credentials didn't have enough permission to query BQ. I put the dataset name into the Schema field and it worked, thanks!
amodig
on 30 May 2018
What is the status of this issue? Is somebody using Superset with BigQuery in production?
- Is the connector based on pybigquery?
- Is the missing record-type a big issue?
I'm evaluating Superset for my next project...
 bzhr
on 13 Jul 2018
bzhr
on 13 Jul 2018
@Bamieh I don't think it's possible to lock a Github issue. @bzhr the state is closed since it's been resolved, this thread shows that people have succeeded in using Superset against BQ
mistercrunch
on 15 Jul 2018
@mistercrunch There is a button under participants to lock conversation, but i believe it needs certain privilages
here is an example from a repo i own:

Bamieh
on 16 Jul 2018
Oh good, I had not discovered that feature.
mistercrunch
on 16 Jul 2018
Related issues
 sashank
·
3Comments
sashank
·
3Comments
 shyam2794
·
3Comments
shyam2794
·
3Comments
 dinhhuydh
·
3Comments
dinhhuydh
·
3Comments
 deity-bram
·
3Comments
deity-bram
·
3Comments
 tmccartan
·
3Comments
tmccartan
·
3Comments
Most helpful comment
Hi,
What's the latest on this?