Ghidra: PDB parsing issues
Describe the bug
When trying to parse MSVC C2 (compiler backend) PDBs (x64_arm64 in this case), Ghidra fails.
Expected behavior
PDB parsing not to fail.
Screenshots
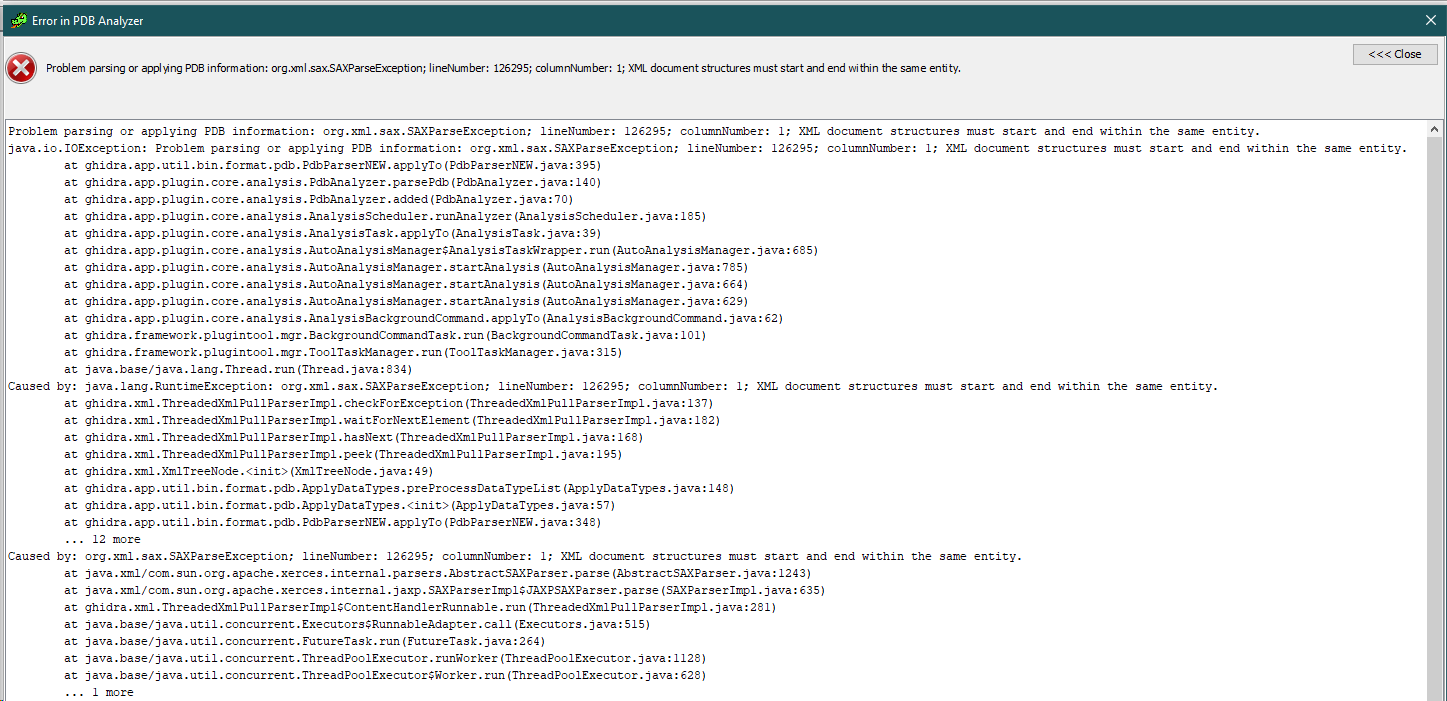
Environment (please complete the following information):
- OS: Windows 10
 woachk
woachk
All 33 comments

On Windows 10 x86-64 (1809) I get the error depicted in the screenshot above
 zznop
on 7 Mar 2019
zznop
on 7 Mar 2019
@zznop register the msdia140 as x64 through regsvr32, and it'll be fixed.
woachk
on 7 Mar 2019
@woachk You are a saint.
zznop
on 7 Mar 2019
It is documented in /docs/README_PDB.html
@zznop
 jonyluke
on 7 Mar 2019
jonyluke
on 7 Mar 2019
Describe the bug
When trying to parse MSVC C2 (compiler backend) PDBs (x64_arm64 in this case), Ghidra fails.Expected behavior
PDB parsing not to fail.Screenshots
Environment (please complete the following information):
- OS: Windows 10
I am also getting a similar error with a pdb that loads normally with IDA
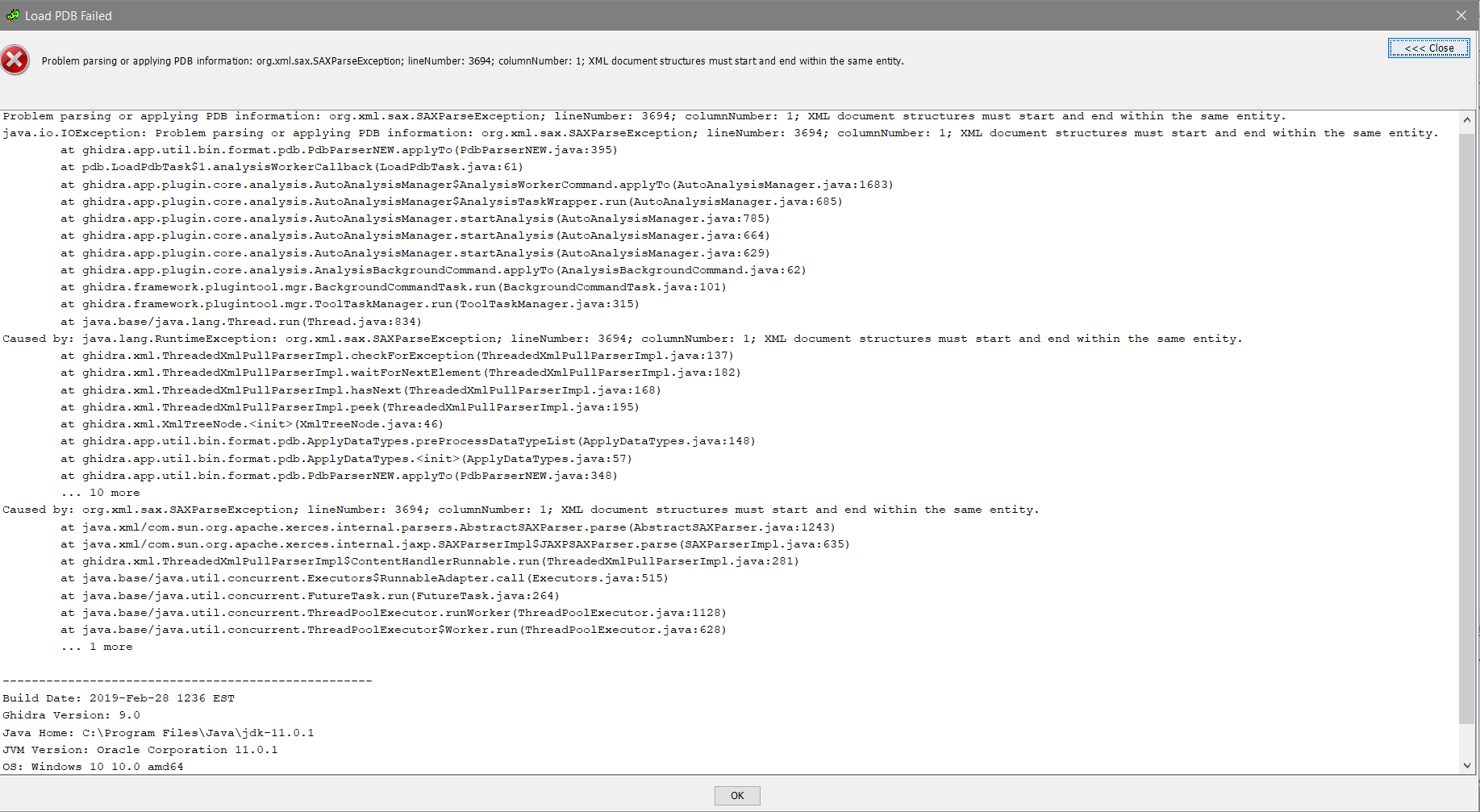
jonyluke
on 7 Mar 2019
@jonyluke This problem is that Ghidra does not support char16_t and char32_t to be present in the PDB file. You have to manually build your pdb.exe.
Go to Ghidra\Features\PDB\src, there you find VC solution. Open Ghidra\Features\PDB\src\pdb\cpp\symbol.cpp. Modify BASIC_TYPE_STRINGS array definition. Add something like
L"char16_t",
L"char32_t"
to the array definitions. During building you may have issues with post-build even which want to copy resulting pdb.exe from Ghidra\Features\PDB\build\os\win64 to Ghidra\Features\PDB\os\win64\. You could do that manually. that should fix your issue.
 kant2002
on 10 Mar 2019
kant2002
on 10 Mar 2019
It worked, although, it gave me the following message
Warning: Composite data type generated from PDB has size mismatch. _Bxty: expected 0x10, but was 0x20
Error: failed to resolve typedef: _Cnd_imp_t -> _Cnd_internal_imp_t*
Error: failed to resolve typedef: _Cnd_t -> _Cnd_internal_imp_t*
Error: failed to resolve typedef: _Mtx_imp_t -> _Mtx_internal_imp_t*
Error: failed to resolve typedef: _Mtx_t -> _Mtx_internal_imp_t*
Demangle Symbol> Unable to demangle symbol at 004c7324; name: ??_C@_0L@BLPOFLNJ@owner?5dead?$AA@. Message: Symbol name matches possible default symbol name: s_owner_dead
Demangle Symbol> Unable to demangle symbol at 004cbcd8; name: ??_C@_1PG@GALDDHKE@?$AAc?$AAa?$AAn?$AAn?$AAo?$AAt?$AA?5?$AAs?$AAe?$AAe?$AAk?$AA?5?$AAs?$AAt?$AAr?$AAi?$AAn?$AAg?$AA?5?$AAi?$AAt?$AAe?$AAr?$AAa?$AAt?$AAo?$AAr?$AA?5?$AAb?$AAe?$AAc?$AAa@. Message: Symbol name matches possible default symbol name: u_cannot_seek_string_iterator_beca
Demangle Symbol> Failed to apply mangled symbol at 004d0478; name: ?lowercase@?1???$parse_floating_point_possible_nan_is_ind@_WV?$c_string_character_source@_W@__crt_strtox@@@__crt_strtox@@YA_NAA_WAAV?$c_string_character_source@_W@1@@Z@4QB_WB (ghidra.app.util.demangler.microsoft.MicrosoftDemangler/ghidra.app.util.demangler.DemangledVariable)
It require me to setting up building Ghidra from source code, since I do not see a way to debug it as is. I have somewhat working setup using Maven, but not sure that this is correct way to recommend this, given the fact that NSA want to release tooling using Gradle with which I do not familiar with. If you fine with building using Maven, I could at least provide you a way how to debug issue.
I have a question, how do you run Ghidra? At least which bat file do you use.
kant2002
on 11 Mar 2019
@jonyluke This problem is that Ghidra does not support char16_t and char32_t to be present in the PDB file. You have to manually build your pdb.exe.
Go toGhidra\Features\PDB\src, there you find VC solution. OpenGhidra\Features\PDB\src\pdb\cpp\symbol.cpp. ModifyBASIC_TYPE_STRINGSarray definition. Add something likeL"char16_t", L"char32_t"to the array definitions. During building you _may_ have issues with post-build even which want to copy resulting
pdb.exefromGhidra\Features\PDB\build\os\win64toGhidra\Features\PDB\os\win64\. You could do that manually. that should fix your issue.
@kant2002 This does not solve the issue ("XML document structure must start and end within the same entity") for Chrome's PDBs (both chrome.exe.pdb and chrome.dll.pdb, Windows 64-bit, latest versions, PDB source is https://chromium-browser-symsrv.commondatastorage.googleapis.com).
 Mitsos101
on 11 Mar 2019
Mitsos101
on 11 Mar 2019
@Mitsos101 chrome_exe.pdb was correctly processed by me using pdb.exe with applied patch. I believe that you do not copy pdb.exe from Ghidra\Features\PDB\build\os\win64 to Ghidra\Features\PDB\os\win64\ after you apply fix.
You could verify that fix working as expected by running
.\Ghidra\Features\PDB\os\win64\pdb.exe chrome_exe.pdb | Out-File chrome_exe.pdb.xml
in the PowerShell. Then you could manually inspect chrome_exe.pdb.xml to ensure that updated version produce valid XML
kant2002
on 11 Mar 2019
@kant2002 My apologies, it was my fault. I had accidentally written L"char16_t" instead of L"char16_t",.
Mitsos101
on 11 Mar 2019
@jonyluke I do not know what happens, but I manage to create some compilation infrastructure here: https://github.com/kant2002/Ghidra . I still do not know how to properly setup debugging for the project, but at least modifications of the faulty components would be fairy trivial.
First warning here: https://github.com/kant2002/Ghidra/blob/master/Ghidra/Features/PDB/src/main/java/ghidra/app/util/bin/format/pdb/PdbUtil.java#L118
Second error here:
https://github.com/kant2002/Ghidra/blob/master/Ghidra/Features/PDB/src/main/java/ghidra/app/util/bin/format/pdb/ApplyTypeDefs.java#L103
Third kind of errors here:
https://github.com/kant2002/Ghidra/blob/master/Ghidra/Features/Base/src/main/java/ghidra/app/cmd/label/DemanglerCmd.java#L119
Last message is from there
https://github.com/kant2002/Ghidra/blob/master/Ghidra/Features/Base/src/main/java/ghidra/app/cmd/label/DemanglerCmd.java#L113
So everybody interesting at least has a place too look into 😄
kant2002
on 12 Mar 2019
For me the problem was fixed (or rather worked around) after adding those 2 char types AND also modifying the code of iterateSymbolTable function, like this:
bool skipGetUndecoratedName =
wcscmp(name, L"_Myptr") == 0 ||
wcscmp(name, L"address") == 0 ||
wcscmp(name, L"allocate") == 0 ||
wcscmp(name, L"at") == 0 ||
wcscmp(name, L"operator[]") == 0 ||
wcscmp(name, L"front") == 0 ||
wcscmp(name, L"back") == 0;
printf("%s", indent(12));
printf("<symbol name=\"%ws\" ", name);
printf("address=\"0x%x\" ", getRVA(pSymbol));
printf("length=\"0x%x\" ", getLength(pSymbol));
printf("tag=\"%ws\" ", getTagAsString(pSymbol));
printf("kind=\"%ws\" ", getKindAsString(pSymbol));
printf("index=\"0x%x\" ", getIndex(pSymbol));
printf("undecorated=\"%ws\" ", skipGetUndecoratedName ? name : getUndecoratedName(pSymbol));
printf("value=\"%ws\" ", getValue(pSymbol));
printf("datatype=\"%ws\" ", getTypeAsString(pSymbol));
printf(" />\n");
Of course this is just a workaround, the real issue is that call to getUndecoratedName function is causing a memory access exception. Perhaps this is caused by using a different version of msdia140.dll. I am working with VS 2015, maybe the developers were using newer VS 2017 and hence those problems.
 mithadis
on 12 Mar 2019
mithadis
on 12 Mar 2019
Hi all,
I have similar issue with PDB.
Problem parsing or applying PDB information: Data type <anonymous-tag> has _LARGE_INTEGER within it.
java.io.IOException: Problem parsing or applying PDB information: Data type <anonymous-tag> has _LARGE_INTEGER within it.
at ghidra.app.util.bin.format.pdb.PdbParserNEW.applyTo(PdbParserNEW.java:395)
at pdb.LoadPdbTask$1.analysisWorkerCallback(LoadPdbTask.java:61)
at ghidra.app.plugin.core.analysis.AutoAnalysisManager$AnalysisWorkerCommand.applyTo(AutoAnalysisManager.java:1683)
at ghidra.app.plugin.core.analysis.AutoAnalysisManager$AnalysisTaskWrapper.run(AutoAnalysisManager.java:685)
at ghidra.app.plugin.core.analysis.AutoAnalysisManager.startAnalysis(AutoAnalysisManager.java:785)
at ghidra.app.plugin.core.analysis.AutoAnalysisManager.startAnalysis(AutoAnalysisManager.java:664)
at ghidra.app.plugin.core.analysis.AutoAnalysisManager.startAnalysis(AutoAnalysisManager.java:629)
at ghidra.app.plugin.core.analysis.AnalysisBackgroundCommand.applyTo(AnalysisBackgroundCommand.java:62)
at ghidra.framework.plugintool.mgr.BackgroundCommandTask.run(BackgroundCommandTask.java:101)
at ghidra.framework.plugintool.mgr.ToolTaskManager.run(ToolTaskManager.java:315)
at java.base/java.lang.Thread.run(Thread.java:834)
Caused by: java.lang.IllegalArgumentException: Data type <anonymous-tag> has _LARGE_INTEGER within it.
at ghidra.program.model.data.CompositeDataTypeImpl.checkAncestry(CompositeDataTypeImpl.java:86)
at ghidra.program.model.data.UnionDataType.doAdd(UnionDataType.java:133)
at ghidra.program.model.data.UnionDataType.add(UnionDataType.java:122)
at ghidra.program.model.data.CompositeDataTypeImpl.add(CompositeDataTypeImpl.java:142)
at ghidra.app.util.bin.format.pdb.CompositeMember.addUnionMember(CompositeMember.java:587)
at ghidra.app.util.bin.format.pdb.CompositeMember.addMember(CompositeMember.java:736)
at ghidra.app.util.bin.format.pdb.CompositeMember.addMember(CompositeMember.java:424)
at ghidra.app.util.bin.format.pdb.CompositeMember.applyDataTypeMembers(CompositeMember.java:810)
at ghidra.app.util.bin.format.pdb.ApplyDataTypes.buildDataTypes(ApplyDataTypes.java:93)
at ghidra.app.util.bin.format.pdb.PdbParserNEW.completeDefferedTypeParsing(PdbParserNEW.java:281)
at ghidra.app.util.bin.format.pdb.PdbParserNEW.applyTo(PdbParserNEW.java:359)
... 10 more
---------------------------------------------------
Build Date: 2019-Feb-28 1236 EST
Ghidra Version: 9.0
Java Home: C:\Program Files\Java\jdk-11.0.2
JVM Version: Oracle Corporation 11.0.2
OS: Windows 10 10.0 amd64
Workstation: WinDev1806Eval
 hacksysteam
on 13 Mar 2019
hacksysteam
on 13 Mar 2019
@hacksysteam could you run .\Ghidra\Features\PDB\os\win64\pdb.exe XXXX.pdb and look for any _LARGE_INTEGER references? It is not clear what kind of data in the PDB produce this kind of errors
kant2002
on 16 Mar 2019
@kant2002 The issue seems to be still present in latest version of Ghidra.
I have a driver PDB file which has anonymous-tag having LARGE_INTEGER.
The PDB can be found from this link: https://github.com/hacksysteam/HackSysExtremeVulnerableDriver/releases/download/v2.00/HEVD.2.00.zip
hacksysteam
on 4 Jun 2019
@kant2002 Do you have the GUID, age (, and filename) for each of chrome.exe.pdb and chrome.dll.pdb?
I do not have the chrome.exe and chrome.dll files to check, and unfortunately cannot take it upon myself to "agree" to License information to download the files.
In ghidra project manager, you can right-click->About... on the executables to find information about the PDB that goes with the executable. I _might_ be able to download the PDBs from the symbol server you specified if you tell me everything about each PDB from the About... dialog box.
 ghizard
on 18 Jun 2019
ghizard
on 18 Jun 2019
I have to resurrect my understanding of this project. and how to build it. I'm pretty sure that
- PDB: add char16_t/char32_t types to BASIC_TYPE_STRINGS is one thing (has #685)
- and parsing of complex lambda from chrome is another thing entirely (more complex).
First one is easy to reproduce with simple CMake setup, I could create small win32 app, to show you the issue. and you could build code yourself.
For second one issue it will take more time for me to properly setup build from official source code, and not from my attempts to build Ghidra.
Could you clarify that you do not confuse these two? First one has PR, second one does not have one and require discussion.
kant2002
on 18 Jun 2019
I could be wrong, but I do not believe we have a VS2019 license (though someone might have ordered it... and in case you are not aware, licensing is tougher on our organization than on individuals). Not having VS2019 would also impact #699. Regardless of what work someone does on VS2019-related issues, we would usually need to either confirm builds or find other ways around issues. I was hoping to find some VS2019 PDBs from trusted sources based on various tickets like this one.
I realize that these are separate issues, and I have an immediate third issue as well...
I realize that char16_t/char32_t is a very simple PR/fix, but would like to confirm it. I could easily do it if I had VS2019 or PDBs containing these basic types. (I thought it was implied/stated that these were new with 2019.)
I looked at the the code where the anonymous-tag (from chrome) was triggering the issue, and it seems we probably haven’t done the right thing to break up a cyclic dependency (my impression). That is why I wanted to try to download these specific PDBs.
Lastly, I’m trying to test java-based PDB processing and would like to test against VS2019 PDBs. I had older VS tool chains and scraped them of PDBs, but didn’t get as much variety as I had hoped, but certainly want to test against the newest tool chain outputs. The java-based code might be constructed in a way to already handle the chrome lambda issue, and I’d like to know either way.
I hope this helps.
ghizard
on 19 Jun 2019
@ghizard, see #182. The XML file generated by chrome.exe.pdb has been uploaded there.
Mitsos101
on 19 Jun 2019
@ghizard I'm on my side may propose to you setup small GitHub repository which will build small application using AppVeyor or AzureDevOps using VS2019 and upload build files to some public infrastructure owned by CI service. If you don't care who build PDB, I just could create small app with PDB char16_t/char32_t and give that file to you
kant2002
on 19 Jun 2019
@kant2002 I appreciate your willingness to help, though I'm swayed against any binaries (and possibly PDBs) that don't come from a trusted source.
Someone recently explained to me that we might have leeway to pull the free VS2019 since we are now open source. I'll have to investigate the license terms with regard to that. I have other avenues to investigate as well.
@Mitsos101 Similar issue with any attached files. I believe I have some options... I'll get back.
ghizard
on 19 Jun 2019
Update: I was able to get chrome.exe, associated chrome.exe.pdb, and duplicate the problem.
ghizard
on 20 Jun 2019
chrome lambda issue is that the '/' character is also a delimiter in the CategoryPath (seems someone mentioned this before). (Likely issue in CategoryDB as well.) Need to discuss a fix here. Possible short-term is to somehow escape the delimiter character, but probably needs better solution without delimiters, such as list.
Name coming from pdb.xml:
BindState<`lambda at ../../base/threading/thread_task_runner_handle.cc:52:9&apos
As going into CategoryPath:
BindState<`lambdaat../../base/threading/thread_task_runner_handle.cc:52:9',std
In my opinion, would be good to setup some tests which will test different kind of names which could appear in the PDB, and test that. Or maybe generate fake PDBs with desired properties to test. Otherwise it would be rather complex to account for all cases how different compilers could escape names. I'm all for have simple solution which will magically account for all cases, but I suspect it would be hard to catch all at once, and tests could help with that.
Current problem for me is wide range of CPP names how they could be encoded in PDB. so instead of think upfront how differenet compilers will mangle names, I would like to capture all cases in tests and fix all regressions which appear during development.
Other open question for me, when I look at that was what's idea behind CategoryPath and whole categorization problem. What would happens if name of template will have another fully qualified name like std::vector<std::vector<int>> . Current parser too dump for this. and seeing that non cpp entities could appear in the name of the object raise awareness on the complexity of the problem at hand.
kant2002
on 20 Jun 2019
A little more than a year ago, I had written up detailed requirements and pseudo-tests for a more detailed namespace parser. We took a short cut at the time however to do a more simplistic namespace parser (but better than what we had), and this simplistic solutions should work for the nesting you have shown. The simplistic parser counts matching sets of certain characters such as <, (, {, [, but doesn't do the work of the more detailed requirements, which watches for these and other characters that occur in unmatched locations, such as operator<.
As I mentioned above, once parsed, we can get away from illegal character issue (delimiter character) by using a list instead of a delimited string.
See SymbolPathParser for the simplistic parser.
ghizard
on 20 Jun 2019
SymbolPathParser and specifically SymbolPathParserTest is seems to be what I want. When I look at the PDBParserNew I found small issue with tests for PDB parsing (see #706). Also I play with creation of test for PDBParserNew (that likely was silly excercise captured in #708) and discover
- that
getCategoryandstripNamespacemethod always go hand in hand with each other. That maybe moved into single method which createCategoryPathinstance where Name (result of stripNamespace) would return type name, and Parent would return result of getCategory call. In a sense that would mean that type positioned in the hierarchy in single call. - Other option is to have construct
SymbolPathinstance instead of two callsgetCategoryandstripNamespacewhich will clearly indicate thatSymbolPathwould be used underneath. - Another note is
addPdbRootparameter togetCategoryis always has valuetrue. It seems to be that it is not used. At least not anywhere in the released code. Maybe it would be practical remove that parameter altogether?
This leads me to questions: What's the difference between SymbolPath and CategoryPath. Both seems to be related to symbols hierarchy.
All of that seems to be nit-picking, so feel no sorry for scrapping #708 if there is no value in that work.
kant2002
on 20 Jun 2019
SymbolPath deals with namespaces of symbols CategoryPath deals with how we store things such as in the Data Type Manager, which may or may not be broken down as namespaces are broken down. Different concepts that shouldn't be mixed.
I'm not sure that #708 will be helpful. I'm just trying to fix enough of the current PDB processing to make it happy until replaced; if we find an issue, we can write a test that reflects the issue, but I'm not desiring to do more than that right now. Time spent on old PDB means less time on new PDB.
Symbol namespaces need parsed. As mentioned earlier, I have a list of pseudo-requirements/tests that I've written up already for the SymbolPath. They are not here on github, however, and the list was quite involved. The current SymbolPathParser was a quick fix to catch most generic cases.
Ghidra symbols can only contain certain characters, so we have to substitute _ghidra invalid_ characters with other characters, such as the underscore.
For the CategoryPath, we just need to decide how we want to handle the '/' character that also serves as a delimiter. I mentioned possibilities above, but need to have discussions with people who are not currently available.
ghizard
on 21 Jun 2019
There were a number of problems reported here in Issue #94. If we can refrain from adding any other problems to this issue, and instead report them as new issues, it will be helpful.
Some of these problems have already been fixed; at least two remain. Following represents my take on problems/status:
@woachk saw XML parsing issue when the output of pdb.exe was being parsed. @jonyluke seemed to have the same problem. At this time, it might be hard to reproduce what caused the problem. There was either a bad character in the XML, or I think more likely, the pdb.exe had crashed without completing the writing of the XML file. If you have more information about this issue, I'd like to know about it. But, I am hopeful that work taking place in PR #674 will fix most of the issues of crashing, though there could still be an issue with the call to undname.
@kant2002 provided a fix (also in his his private repo) regarding char16_t and char32_t additions for BASIC_TYPE_STRINGS, suggesting to @jonyluke that this was their particular issue. I can attest that this was a real problem that caused crashes. @marpie submitted this fix in PR #685 and it has been merged into master.
@zznop had a problem running pdb.exe. @woachk provided an answer, referencing the solution that is also documented in README_PDB.html that states that msdia140 must be registered.
@Mitsos101 reported an issue with processing chrome.exe.pdb and chrome.dll.pdb for 64-bit Windows. The problem is with the '/' character in the lambdas and how it impacts CategoryPath internal to Ghidra. I've spoken with folks here, and the proper fix will take a bit of work as there are many files to change, but should be done.
I'll continue to help get PR #674 through review and merge and I'll try to take on the CategoryPath fix. @kant2002, there will likely be future work toward bringing CategoryPath and SymbolPath closer; my work on CategoryPath should help that in the future, but will not be addressed at this time.
ghizard
on 28 Jun 2019
CategoryPath change has been made to allow for forward slashes, but still need to make change to PDB analyzer to make use of the change (to affect chrome.exe.pdb). Holding off on PDB change until ghidra1 is done touching specific files.
ghizard
on 16 Jul 2019
GT-2975 (PR #674) has been merged, and should hopefully deal with certain crashes that were seen to truncate pdb.xml files.
GT-2974 merger (coming after Bitfields merger) is intended to make the PDB Analyzer use the new CategoryPath (GT-2961) forward-slash capability.
After GT-2974 is merged, going to close this and #182, as the issues specified in these seem to have been tackled.
PDB Issues that one will likely still see include:
- Fallout from the new Bitfields capability--causing PDB analysis to fail where it was not failing prior to the Bitfield capability merger; we are trying to tackle these issues as we find them.
- Long-running issue of 2000 character limit on symbols. The chrome.exe.pdb has some symbols that are longer than this limit. I've tried to raise concern about this issue again; there is resistance to just upping the limit, as some what to investigate the impact of chaining database buffers and related issues.
ghizard
on 18 Jul 2019
Could character limit 2000 would be some advanced configuration parameter, which can be left to advanced users? Maybe with big banners THERE BE DRAGONS around that setting? Also is there any separate public issue which track discussion about that topic?
kant2002
on 18 Jul 2019
There is not a public issue tracking the 2000 character topic. I'll keep advocating for the priority of this issue internally. It is not a safety issue for the user, but for the Ghidra database, I believe. If we could up the limit for advanced users, then we would up it for all users.
Good news is that we do not often see symbols larger than 2000. There was only a handful in the chrome pdb... I think I saw sizes of 2271 and 3021. I think a limit between 4000 and 4100 is achievable without too much internal pain, and I've seen a handful over 4000 and less than 4100 when I was doing demangling work, which were mangled symbols... When demangled, they are much larger, but typically can be broken down into constituent components at that time.
ghizard
on 18 Jul 2019
Related issues
 loudinthecloud
·
3Comments
loudinthecloud
·
3Comments
 astrelsky
·
3Comments
astrelsky
·
3Comments
 toor-de-force
·
3Comments
toor-de-force
·
3Comments
 pd0wm
·
3Comments
pd0wm
·
3Comments
 Merculous
·
3Comments
Merculous
·
3Comments
Most helpful comment
@jonyluke This problem is that Ghidra does not support char16_t and char32_t to be present in the PDB file. You have to manually build your pdb.exe.
Go to
Ghidra\Features\PDB\src, there you find VC solution. OpenGhidra\Features\PDB\src\pdb\cpp\symbol.cpp. ModifyBASIC_TYPE_STRINGSarray definition. Add something liketo the array definitions. During building you may have issues with post-build even which want to copy resulting
pdb.exefromGhidra\Features\PDB\build\os\win64toGhidra\Features\PDB\os\win64\. You could do that manually. that should fix your issue.