Gatsby: [EPIC] Graphql schema refactor
Who will own this?
_What Area of Responsibility does this fall into? Who will own the work, and who needs to be aware of the work?_
Area of Responsibility:
_Select the Area of Responsibility most impacted by this Epic_
- [ ] Admin
- [ ] Cloud
- [ ] Customer Success
- [ ] Dashboard
- [ ] Developer Relations
- [ ] OSS
- [ ] Learning
- [ ] Marketing
[ ] Sales
| | |
| --------------- | ----- |
| AoR owner | @KyleAMathews |
| Domain owner | TBD |
| Project manager | TBD |
| Tech lead | TBD |
| Contributors | TBD |
Summary
Make graphql schema generation code more maintainable and easier to add new features like allowing user specified types on fields instead of automatic inferring.
How will this impact Gatsby?
Domains
_List the impacted domains here_
Components
_List the impacted Components here_
Goals
_What are the top 3 goals you want to accomplish with this epic? All goals should be specific, measurable, actionable, realistic, and timebound._
3.
How will we know this epic is a success?
_What changes must we see, or what must be created for us to know the project was a success. How will we know when the project is done? How will we measure success?_
User Can Statement
- User can...
Metrics to Measure Success
- We will see an increase /decrease in...
Additional Description
_In a few sentences, describe the current status of the epic, what we know, and what's already been done._
What are the risks to the epic?
_In a few sentences, describe what high-level questions we still need to answer about the project. How could this go wrong? What are the trade-offs? Do we need to close a door to go through this one?_
What questions do we still need to answer, or what resources do we need?
_Is there research to be done? Are there things we don’t know? Are there documents we need access to? Is there contact info we need? Add those questions as bullet points here._
How will we complete the epic?
_What are the steps involved in taking this from idea through to reality?_
How else could we accomplish the same goal?
_Are there other ways to accomplish the goals you listed above? How else could we do the same thing?_
--- This is stub epic - need to convert old description to new format
Main issue im trying to solve is that type inferring will not create fields/types for source data that:
- has conflicting types (sometimes source plugins have no way of knowing what is correct type and can’t type correct themselves),
- has no data for some fields (optional data field/node will not be inferred if that field/node is not used in source of the data and queries will fail because schema doesn’t contain that field)
This is not inferring implementation issue - it’s just this approach simply can’t handle such cases.
My approach to handle that is to allow defining field types by
- using graphql schema definition language (for data that will have static types - i.e.
Filenodes will always have same data structure) - exposing some function for gatsby node api (for data that types are dynamic but we can get information about structure - for example Contentful content model)
Problem:
Current implementation of schema creation looks something like this:

Input/output type creation is not abstracted and implementation has to be duplicated for each source of information.
In my proof of concept ( repository ) I added another source (graphql schema definition language) and just implemented subset of functionality:

As testing ground I used this barebones repository. Things to look for:
- schema definition
- source data with conflicting types (frontmatter in markdown files)
- query using fields with types in schema definition
- summary that compares source data to output data
Implementing it way this way is fine for proof of concept but it’s unmaintainable in long term. So I want to introduce common middleman interface:
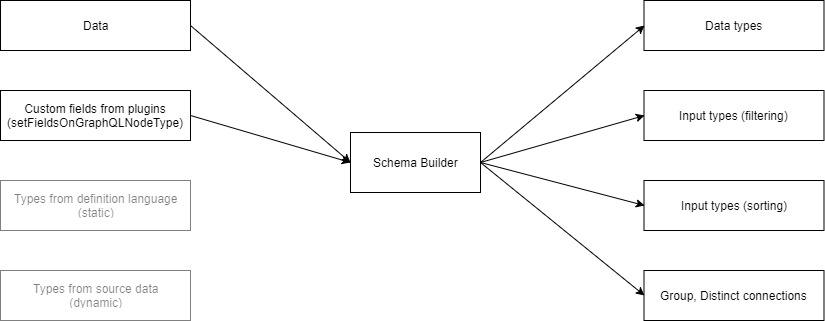
Goals:
- This should be backward compatible
- Make it easy to add new source of field types and/or schema features
- Remove code duplication
- Initial change should only introduce middleman interface and provide feature parity with current implementation to ease review
Questions:
- What are potential features / use cases to take into consideration when designing details of this (not features of schema - it’s how it could be used)? I see 1 potential cases where this might be important (to not need to do big refactor again later):
- Live previews - right now gatsby can’t modify schema when it’s running in
developmode but it can refresh data (builtin refresh for filesystem source +__refreshhook to refresh all source data) - it might be worth looking to be able to refresh schema too?
- Live previews - right now gatsby can’t modify schema when it’s running in
- How would schema stitching fit into it (merging external remote graphql endpoints with gatsby graphql layer)? Basic schema stitching would not interact with gatsby graphql part (for example we have our gatsby queries
markdownetc and then we have fields from github graphql apirepository- if there’s no connection between them then then this would be out of scope for this RFC), but if we would like to add connection - for example allow linking frontmatter field to github repository then this would need to be thought out ahead of time. I was looking atgraphql-toolsschema stitching and it does have some nice tooling for merging schemas and option to add resolvers between schemas - is this something that was planned to be used for that?
 pieh
pieh
All 64 comments
Thanks a lot for the research @pieh .
Maybe I am completely off road here but couldn't we use schema stitching to add missing fields?
But maybe it could not solve the issue 1 you raise (conflicting types on a field) and it probably is a weaker solution overall on the long run...?
I love your idea about live preview refresh! That would be a super solid feature to add to Gatsby IMHO.
To be honest my main concern is the time such a refactor will take...
 m4rrc0
on 27 Feb 2018
m4rrc0
on 27 Feb 2018
@MarcCoet
Not sure on what level you would want to stitch schema - this is not magic that would make it work automatically :) . There is multiple "side effects" for single field in data - it produces output type, it produces input type for filtering, it produces input type for sorting, it produces input type for grouping. This would still suffer same problems - it would need to be implemented in multiple places.
There is not much distinction between fields with no data and with conflicting types in terms of creating schema currently - gatsby discards fields with have conflicting types (so they become fields with no data at the stage of creating schema) - the distinction is more for website/apps developers - they have data but field is not in schema.
You can use my proof of concept branch (at least for testing things out) - it has all basic features of getting fields - it can resolve local files, linked nodes (both of single and multiple types - unions) and of course inline fields. But to get full feature set I would have to implement this 3 more times in different places (filtering, sorting, grouping).
Or you now can use setFieldsOnGraphQLNodeType function ( https://www.gatsbyjs.org/docs/node-apis/#setFieldsOnGraphQLNodeType ) to add/overwrite "inline" field types (fields that aren't linked to other nodes). Not really super easy to use and can't reference other types that are available in schema.
I totally get your time concern and frustration about this issue - I have this problem too with some of my sites - it's hard to explain your content editors why things suddenly stopped working when they cleared some optional field ( this is why I started working on this! ), but this has to be done right sooner than later, as features that will need to be refactored will pile up.
pieh
on 27 Feb 2018
How would schema stitching fit into it
It wouldn't — the schema stitching process basically takes two entirely separate schemas and lets you query both of them at the same time. Unless people name their types the same as the default Gatsby ones, there'd be no interaction between the two schemas.
 KyleAMathews
on 27 Feb 2018
KyleAMathews
on 27 Feb 2018
Love the direction you're going here! This feels like the right approach and direction for a refactor and will unlock a lot of really nice capabilities!
KyleAMathews
on 27 Feb 2018
About schema stitching - I was researching this a bit earlier and graphql-tools provide way to add resolvers between schemas - https://www.apollographql.com/docs/graphql-tools/schema-stitching.html#adding-resolvers as part of their schema stitching toolkit. So hypothetically we could create custom resolver (or rather user on project level or on plugin level would) that could transform:
repository: "https://github.com/gatsbyjs/gatsby" (<- that's frontmatter) into response from repository query from github graphql api (similar to how we link/map to nodes currently). This doesn't have to land in initial version of schema stitching, but is something worth keeping in mind.
pieh
on 27 Feb 2018
Huh! That'd be amazing! Yeah, there's a ton of possibilities here — you could link to tweets, flickr images, facebook profiles, etc. anything accessible via an API and as long as you have the right source plugin installed, everything would be linked up. That'd be crazy powerful.
KyleAMathews
on 27 Feb 2018
@pieh @KyleAMathews This is something I've got a bit of experience with. When I was at IBM, we needed to keep data sources discrete, but allow them to be combined in queries to avoid complex data processing on the front-end. I ended up creating and open sourcing GrAMPS to address this. (I wrote up a "hello world" example in this post.)
One of the goals of GrAMPS is to allow what I've clumsily dubbed "asynchronous stitching", where a data source can define how it extends another data source _if that data source exists in the schema_. This would allow plugins to build on each other _when possible_, but wouldn't require them to be peerDependencies. From an open/shareable standpoint, this seems like a way to have our cake and eat it, too: we optionally upgrade the GraphQL schema, rather than hard-coding fragile relationships.
The logic behind this wouldn't require GrAMPS to function; it's basically checking the schema for a given type before applying the mergeSchemas call.
I'm not sure how well this fits into the overall goal of this RFC, but I _think_ it could help us implement the "Schema Builder" with more flexibility and extendability.
Happy to help out on this however I can. Let me know if you want me to expand on any of this.
 jlengstorf
on 27 Feb 2018
jlengstorf
on 27 Feb 2018
@jlengstorf Wow, GrAMPS is cool! Not sure if it will fit, but I will definitely read up more on it (either to use it or at least steal some ideas!) I will for sure reach out to you for your insight.
I'd like to keep this RFC to not focus on implementation details (too much 😄). I want this to serve as requirements gathering place so we could later design APIs that could be extended if needed (to not over-engineer initial refactor) but not changed (wishful thinking 😄). I think we could expose same internal APIs to plugins but to do that they need to be well designed and not be subject to breaking changes in near future.
pieh
on 28 Feb 2018
Hi. Has there been any update on this issue? Just wondering. I really wanna use Contentful + graphql ... but this issue makes it very hard to do so :(
 i8ramin
on 16 May 2018
i8ramin
on 16 May 2018
Just reading into this concept. I wrote a custom source plugin where a field from my JSON API can be null. These fields don't end up in my schema as I would expect. Are there any updates on this?
@pieh Awesome work! Keep it up 😊
 niklasravnsborg
on 30 Jul 2018
niklasravnsborg
on 30 Jul 2018
@i8ramin -- it's definitely in our backlog!
@pieh -- I've renamed this issue for clarity
 calcsam
on 12 Aug 2018
calcsam
on 12 Aug 2018
Was talking to @sgrove today with @calcsam and he had a really interesting idea which could apply here. Basically it was how to estimate when you've sufficiently inferred a graphql type from data. He said you could assign a "novelty" score to each type you're inferring i.e. how novel do you expect each new item to be. You evaluate sample data item by item. Each time you "learn" something new e.g. a new field, the expected novelty score goes up. Whenever an item matches the existing inferred type, the expected novelty score drops. After evaluating enough new items and not learning anything new, you can quit.
This could speed up processing large data sets as we could pull out random samples and often times (especially on data that has representative data for each field on every object) we could stop the inference process quite a bit sooner than we do now.
KyleAMathews
on 8 Sep 2018
@sgrove mentioned this lib too https://github.com/cristianoc/REInfer
KyleAMathews
on 29 Sep 2018
I have re-created Gatsby's schema builder, mainly to better understand what's going on there, and in the process changed a couple of things that maybe someone here might find useful:
- added a new node API
addTypeDefsthat allows to register new GraphQL types in SDL. Top nodes should implement the Node interface. Example:
// gatsby-node.js
exports.addTypeDefs = ({ addTypeDefs }) => {
const typeDefs = `
type Frontmatter {
title: String!
date: Date
published: Boolean
}
type MarkdownRemark implements Node {
frontmatter: Frontmatter
html: String
htmlAst: JSON
}
`
addTypeDefs(typeDefs)
}
Plugins can take type definitions from gatsby-config.js:
// gatsby-config.js
plugins: [
{ resolve: 'gatsby-transformer-foo', options: { typeDefs: `type Foo { bar: Boolean }` } }
]
// plugin gatsby-node.js
exports.addTypeDefs = ({ addTypeDefs }, { typeDefs }) => addTypeDefs(typeDefs)
- added a
@linkdirective that allows linking a field value to a node. Example:
const typeDefs = `
type Frontmatter = {
title: String!
image: File @link(by: "relativePath")
authors: [AuthorsYaml] @link(by: "name")
}
type MarkdownRemark implements Node {
frontmatter: Frontmatter
}
type AuthorsYaml implements Node {
name: String!
email: String
posts: [MarkdownRemark] @link(by: "frontmatter.authors.name")
}
`
- linked fields (as well as
parentandchildren) should be queryable, i.e.
allMarkdownRemark(
filter: {
frontmatter: {
image: {
extension: { eq: "png" }
size: { gte: 10000 }
}
authors: {
name: { in: ["Jane Doe", "John Doe"] }
}
}
) {
html
}
- also changed the relay-style pagination, but that's not really important
In case you want to have a look, the stuff is here:
https://github.com/stefanprobst/gatsby/tree/rfc-schema-refactor
If you want to play with the code, make sure to yarn add graphql-compose, and to not have conflicting graphql packages (you'll get an Error: InputTypeComposer accept only GraphQLInputObjectType in constructor).
Please note: I did this for fun so it's not intended as a PR, there's stuff missing, there are no tests, it needs more memory, and there surely are bugs, but it would be great to get some feedback.
 stefanprobst
on 28 Nov 2018
stefanprobst
on 28 Nov 2018
@stefanprobst Omg! On the functional side this is exactly what I'm imagining Gatsbys query layer to be in the future and what I was missing when I used custom data sources and CMSs with unpredictable data schema.
Looking forward to see this evolving. Can't comment on the technical side. ☺️
niklasravnsborg
on 28 Nov 2018
@stefanprobst this is fantastic! There's a lot going on there so feedback might be slow.
graphql-compose seems like nice abstraction to work with generation of graphql schema (which seems to fit nicely in the "schema builder" block in diagram I did few months back). I will definitely look into that.
https://github.com/gatsbyjs/gatsby/compare/master...stefanprobst:rfc-schema-refactor#diff-fdb188c5894dbabd62f2b8e65d1fa7b6R17 this part is tricky ;) I think deep-merge would be pretty important to be able to fully do partial SDL. If I understand your code correctly, we wouldn't infer any additional fields for Frontmatter type - it would contain "just" fields from SDL, right?
it needs more memory
Do you know where this is coming from?
pieh
on 29 Nov 2018
@stefanprobst This is awesome! :+1:
One comment - instead/in addition to the link directive, I'd also allow passing resolvers. I'd provide functions that can retrieve arbitrary nodes within those resolvers. This allows more flexible schema logic and allow escape hatches. I'd allow resolvers both in addTypeDefs and in options of plugins.
 freiksenet
on 29 Nov 2018
freiksenet
on 29 Nov 2018
Thanks for the feedback!
Most of it is really just rewriting stuff with native map/filter/reduce which I can't expect anyone to review, so I think the two interesting things are:
- using
graphql-composefor schema building, which has worked really well (and it has a very responsive maintainer upstream). The approach was explicit-schema-first, i.e. while currently we start with type inference, we here start with type definitions and add fields from type inference and fromsetFieldsOnGraphQLNodeTypeto it. @pieh I agree we should deepmerge the inferred fields (yes, right now we just delete any top level props from the example value when they are already on the type). I can look into this on the weekend. - the link directive. Since AFAIK there is no standard for custom directives, we use
graphql-tools'sSchemaDirectiveVisitorhere. The directive is actually quite simple: we know the desired return type from the field definition and just construct query args from the field value (which is a scalar, or array of scalars) and the prop we want to link by. - "needs more memory": TBH I'm not even sure if that's actually still the case, will do some profiling.
- @freiksenet What I like about the link directive is that, from a user perspective, SDL is quite easy to read and write. But I agree that providing a way to add custom resolvers would be great to have, I'll think about how to best approach this. Do you have any specific usecases in mind?
stefanprobst
on 29 Nov 2018
@freiksenet What I like about the link directive is that, from a user perspective, SDL is quite easy to read and write. But I agree that providing a way to add custom resolvers would be great to have, I'll think about how to best approach this. Do you have any specific usecases in mind?
So mainly I feel that approach to the features should be programmatic API first and then declarative API on top. This is because declarative API is usually a solution for one common use case for the sake of brevity. However, there always should be a low-level escape hatch (with which you implement the declarative API). The use cases is any more complex relation logic than just using another field as id. It could especially be important when working with 3rd party APIs, for instance.
Practically I feel that there also should be a possibility to replicate logic we have in inferred types with hand-written resolvers, so we should provide low-level hooks to do that. (Eg all resolver utilities can be passed via context or info object).
using graphql-compose for schema building, which has worked really well (and it has a very responsive maintainer upstream). The approach was explicit-schema-first, i.e. while currently we start with type inference, we here start with type definitions and add fields from type inference and from setFieldsOnGraphQLNodeType to it. @pieh I agree we should deepmerge the inferred fields (yes, right now we just delete any top level props from the example value when they are already on the type). I can look into this on the weekend.
I agree with schema first approach. I think they way it should work is:
- If there is no type definition provided, use current infer-from-data
- If type definitions are provided, depending on a typedef provided:
2.1 if it's an extend, merge with inferred definitions
2.2 if it's a definition - replace the inferred with that one
freiksenet
on 29 Nov 2018
Maybe as a first step we could simply expose graphql-compose's schemaComposer to setFieldsOnGraphQLNodeTypes, which would give access to all registered types and their corresponding findOne and findMany resolvers.
stefanprobst
on 29 Nov 2018
So we definetely shouldn't expose graphql-compose APIs directly to Gatsby users, because this way we lose control over those APIs. We can expose a wrapped function to get resolvers, though.
freiksenet
on 29 Nov 2018
On externalizing schemas, my recent thinking is that each new field should always be added. So when a user adds a new markdown frontmatter field, we add it. But if the user _removes_ that field, we leave the field in the schema. We only ask the user what it wants to do when there's a field conflict (when we should show the user how the field is used — we can be smart and say, it looks like all current usages of this field align with the new field type and say "you should probably upgrade the field".
KyleAMathews
on 1 Jan 2019
Quick update on where I'm at with this:
- it is now possible to merge inferred types with explicit type definitions
- now correctly merges in third-party schemas. I had trouble getting this to work with graphql-tools, so I'm using a much simplified approach
- added
addResolversAPI. I'd still love some input what to expose to resolvercontexthere. Personally I'm not sure any more if we even have to pass on anything extra: we already haveinfo.schema, so you can query withinfo.schema.getQueryType().getFields().allMarkdownRemark.resolve()
Apart from that some questions (more to follow):
- do we want to keep
SitePluginin the schema? What would be a usecase for it? - do we want to infer strings as File type, even when
gatsby-source-filesystemis not present to handle File types? - in File type: what should
relativePathbe relative to. I have found it confusing that it is relative to sourceInstance, so I've changed this to be interpreted as relative to the page or StaticQuery.
stefanprobst
on 2 Jan 2019
Also: much better at type reuse. In a default starter, from 592 types to 96.
stefanprobst
on 2 Jan 2019
Also: much better at type reuse. In a default starter, from 592 types to 96.
Yup, we create way too much input types currently - for each string we create separate type with eq, ne, regex etc operator fields
That's one easy win we can fix to make schema more readable
pieh
on 2 Jan 2019
@stefanprobst We should default to keeping old functionality, the schema refactor should be 100% backwards compatible, so we should keep the types like SitePlugin that are currently in the schema.
added addResolvers API. I'd still love some input what to expose to resolver context here. Personally I'm not sure any more if we even have to pass on anything extra: we already have info.schema, so you can query with info.schema.getQueryType().getFields().allMarkdownRemark.resolve()
What I meant is that we should expose gatsby's "model layer", which is the resolvers we use ourselves to do things. That would be the way for people to reuse Gatsby functionality when they are rewriting Gatsby types.
freiksenet
on 4 Jan 2019
100% backwards compatible
Oh, I didn't realize, I thought of this more as a v3.0 thing, so there would be an opportunity to change some things. It's easy enough to change back to current behavior -- I just modified the two things that confused me when I started out with Gatsby, namely what relativePath referred to, and that query results were by default wrapped in a pagination object (edges/nodes). I made the allTypeName endpoints return results directly, and added a pageTypeName field that returns { items, count, pageInfo }
What I meant is that we should expose gatsby's "model layer", which is the resolvers we use ourselves to do things.
Hmm, what you get with info.schema.getQueryType().getFields().allMarkdownRemark.resolve is exactly what is being used internally (namely findMany('MarkdownRemark'). Maybe I'm still misunderstanding?
stefanprobst
on 4 Jan 2019
Excellent work, @stefanprobst - I've been battling for a month trying to find a good way to declare fields and schema types without finding this issue. This looks like a dream come true.
What's the plan going forward - do you have a specific roadmap you're working towards? Is there anything other contributors could do to help?
 rexxars
on 6 Jan 2019
rexxars
on 6 Jan 2019
@rexxars Thanks! I think there are two issues for this to move forward.
First, API: there hasn't been a whole lot of discussion if the proposed API makes sense and covers all usecases? To summarize:
addTypeDefsto register type definitions. Inferred types are merged in when possible, while explicit definitions trump inferred ones.addResolversto add custom field resolvers.@linkdirective to declare foreign-key fields. This would replace the___NODEconvention and mappings ingatsby-config.- keep
setFieldsOnGraphQLNodeType, but allow adding nested fields.
Second, implementation: all of the above should work, but there are other changes mixed in - some of which might be useful (like query operators for Dates), others are just my personal preference (like gettings rid of edges, or requiring query args to always be on a filter field). I'm motivated enough to bring this into a more mergeable state, but I don't know what the planning is in Gatsby HQ.
stefanprobst
on 6 Jan 2019
I don't work at Gatsby HQ and have not been involved in Gatsby for long, so I can't comment on whether it covers _all_ usecases, but it certainly addresses all the issues I've been battling with (see #10856).
Couple of questions:
- Does it handle unions? Both in fields, lists and as the target for foreign key fields?
- If you specify a
Datefield, does it get the date formatting arguments one would get through inferring? This is one of the issues I've run into with any approach I've tried so far - inferring gets you the formatting arguments, explicitly defining the field misses them
As for the changes you've introduced, I wholeheartedly agree on them being a good change, but I don't have the background on why they are not modeled this way currently. I think the edges approach is a Relay-inspired thing, but I'm not sure if it serves any specific purpose within the Gatsby ecosystem - I don't think anyone is using Gatsby with Relay afterall.
rexxars
on 6 Jan 2019
Excellent questions!
Does it handle unions?
Unions are currently not supported at all (but Interfaces are). This has to do with a limitation in graphql-compose, which is the library used for schema construction. I'll take a look how much it would take to add this.
If you specify a
Datefield, does it get the date formatting arguments one would get through inferring?
The way date formatting is implemented is sort of the other way around, namely with a @dateformat directive, which lets you define field defaults, that can be overridden in the selection set:
type Foo {
date: Date @dateformat(defaultFormat: "yyyy/MM/dd", defaultLocale: "en-GB")
}
and
query {
foo {
date(locale: "en-US")
}
}
One advantage is that when constructing the InputObjectType from the ObjectType, the field still has the correct Date type, which is only converted to String type when the directive is processed. This is why you get Date query operators like $gt, $lt, and not the String operators.
What's missing is to add the field args to the inferred Date fields - I'll look into this next week.
stefanprobst
on 6 Jan 2019
100% backwards compatible
Oh, I didn't realize, I thought of this more as a v3.0 thing, so there would be an opportunity to change some things. It's easy enough to change back to current behavior.
For the most part this is because we are likely far away from 3.0 and if this is implemented in backward compatible way, we can roll it out during ^2.0. I'm not against potential changes in the future or even behind feature flags (i.e. shallow_connection_type or whatever), but those would need to be discussed and researched - single person preference is a bit anecdotical and is not enough to justify breaking change.
pieh
on 6 Jan 2019
@stefanprobst We definitely do want to fix the issues with Gatsby schema. I'm currently responsible for this issue at Gatsby and I'm very interested in helping more with that. Maybe we should sync up on that more? We can chat eg in Discord (Gatsby Discord https://discord.gg/jUFVxtB) or we can set up a voice/video call.
Hmm, what you get with info.schema.getQueryType().getFields().allMarkdownRemark.resolve is exactly what is being used internally (namely findMany('MarkdownRemark'). Maybe I'm still misunderstanding?
So resolve functions depend on resolver type signature (parent, args, context, info). That means that resolvers that do the same thing, but get the data from different parts wouldn't be reusable. Eg there can be two resolvers that basically get same node by id, but one gets it from parent and other gets it from args. My idea is that we'll expose Gatsby "model layer", that will have the functions to eg operate on nodes. Those will be both used inside Gatsby resolvers and available for users in their custom resolvers. Plugins would be able to add more functions to model layer, so users can write custom resolvers with their functionality, eg for remark transformations. This is a pretty typical way to do it eg in GraphQL servers.
freiksenet
on 9 Jan 2019
@freiksenet Excellent, let's chat early next week! Monday? I'm in GMT+1 timezone.
there can be two resolvers that basically get same node by id, but one gets it from parent and other gets it from args
Ah, I get your point now. However: how consequential is this with how things work in Gatsby (at least currently)? Node resolvers always query with args, and don't use parent, no? In any case, I have now put link, findMany, findOne and findById on context.resolvers.
Plugins would be able to add more functions to model layer
Interesting!
stefanprobst
on 10 Jan 2019
@stefanprobst Most of Gatsby is having a company gathering at Barcelona next week, so I'm afraid I won't have much time :( I'm available tomorrow or then any day after next week. I'm in GMT+2, so timing shouldn't be a problem. Could you select a good time for you in my calendly? https://calendly.com/freiksenet/60min
freiksenet
on 10 Jan 2019
@freiksenet Tomorrow won't work for me unfortunately, I have scheduled tue 22th in your calendar. Thanks!
stefanprobst
on 10 Jan 2019
@stefanprobst can you make a PR, mark it as WIP and tick "allow maintainers to edit"? Would make it much easier to work together on this.
freiksenet
on 11 Jan 2019
Done. #10995
stefanprobst
on 11 Jan 2019
Quick Update:
I added an optional from argument to the @link directive. This makes it easier to do stuff like this:
type AuthorJson implements Node {
name: String!
email: String!
posts: [BlogJson] @link(by: "authors.email", from: "email")
}
type BlogJson implements Node {
title: String!
authors: [AuthorJson] @link(by: "email")
text: String
}
Also, the addResolvers API works better with third-party schemas: it is possible to wrap resolvers on a field on a type from a third-party schema to do some post-processing, or add a new field to third-party types, which allows to add processing which changes the return type. This also accepts a projection prop to automatically include sibling fields in the selection set.
addResolvers({
GraphCMS_BlogPost: {
post: async (source, args, context, info) => {
const remark = require(`remark`)
const html = require(`remark-html`)
const result = await info.resolver(source, args, context, info)
return remark()
.use(html)
.process(result)
},
},
GraphCMS_Asset: {
imageFile: {
type: `File`,
// Projection fields will be included in the selection set.
projection: { url: true, fileName: true },
resolve: async (source, args, context, info) => {
const { fileName: name, url } = source;
const ext = `.` + fileName.match(/[^.]*$/)
const node = await createRemoteFileNode({
url,
store,
cache,
createNode,
createNodeId,
ext,
name,
});
// This will give you a `childImageSharp` field for free
return node
},
},
},
})
Snippets are taken from the using-type-definitions example in the branch.
stefanprobst
on 25 Jan 2019
Issues, before this branch could become something more official:
- Use
momentin@dateformatdirective instead ofdate-fns - Tracing annotations
- No
descriptionfields - More tests with built schema. Test coverage overall is pretty good, but more tests with the executable schema are needed. Also adapt and add back the tests from current master, which should give much more confidence. I'm working on this.
- Rebase on current master. One issue that will need to be solved here is wiring this up with the
lokijschanges that have happened in master since. Should also adjust how we collectlazy-fields, which only needs to happen once. - Respect
internal.ignoreTypeon nodes - adjust sort order for
null, and only respect sort order for the first field to be compatible with current master - naming of
GraphQLUniontypes. When fields link to nodes with the ___NODE field name convention, we infer a union type if the linked nodes are of various types. Currently, the name of those types includes the field name and includes a number suffix because we create a new type on schema update. AFAICS this is problematic because the key is not unique, and it prevents reusing union types. This needs discussion, but it would be better to name theGraphQLUnionTypeafter the types it combines, and reuse those. - There might still be a difference in how a mix of dates and strings is handled in type inference - needs checking.
- The
pageInfoobject onedgesnow includes more thanhasNextPage, decide if we want this. - Decide if custom Unions and Interfaces that are defined in SDL should get their own fields on the root Query type.
- Decide what the expectation is for union types in the input filter.
graphql-composecurrently omits unions when converting to InputObjectTypes, because unions don't necessarily have fields in common. - Node 6 compatibility (
Object.entriesandObject.valuesall over the place) - Behavior of the
elemMatchquery operator. Currently querying arrays of objects can only be done with elemMatch, while in the branch it is an additional operator. This made sense to me because it allows specifying different kinds of query criteria like in the following example:
const query = {
$and: [
{
bar: {
// This is an additional check that *one* of the array objects must pass
foo: { $nin: [1, 2] },
$elemMatch: {
// This would be an additional check for the *same* object that passes
// the other elemMatch criteria
// foo: { $nin: [1, 2] },
bar: { $eq: 1 },
baz: { $eq: 3 },
},
},
},
],
};
const nodes = [
{
foo: 'Foo',
bar: [{ foo: 1, bar: 1, baz: 3 }, { foo: 1, bar: 2, baz: 4 }],
},
{
foo: 'Bar',
bar: [{ foo: 1, bar: 1, baz: 3 }, { foo: 3, bar: 2, baz: 4 }],
},
];
const { default: sift } = require('sift');
console.log(sift(query, nodes));
@stefanprobst btw, instead of projection as an object, we should include a GraphQL fragment.
freiksenet
on 28 Jan 2019
@freiksenet Interesting!! I did projection as an object mainly because it connects nicely with what graphql-compose's Resolver class provides for free.
stefanprobst
on 28 Jan 2019
@stefanprobst right, that makes sense. We can keep it as is for now. Fragment is more flexible cause one can include eg nested fields. I'm borrowing it from here
freiksenet
on 28 Jan 2019
@freiksenet I'm all for allowing fragments to extend the selection set! Nested fields should work with the projection object as well though, e.g. projection: { foo: true, nested: { foo: true } }.
stefanprobst
on 28 Jan 2019
@stefanprobst Hey, why do you have this line in the code?
const updateSchema = async () => {
const tc = addInferredType(`SitePage`)
// this line
delete tc.gqType._gqcInputTypeComposer
addResolvers(tc)
addTypeToRootQuery(tc)
return schemaComposer.buildSchema({ directives })
}
@freiksenet Sorry should have put a comment there. graphql-compose can save a reference to a corresponding InputTypeComposer on this property of the TypeComposer. When updating SitePage we want to create a new InputObjectType, this seemed to be the simplest way without having to mess with the local cache in getFilterInput. Deleting the property should produce a new InputTypeComposer for SitePage when calling getITC() here.
stefanprobst
on 28 Jan 2019
Shouldn't addInferredType produce a new type composer anyway?
freiksenet
on 28 Jan 2019
In type inference, if a TypeComposer already exists, we use it. This is done not mainly because of schema updating, but a TypeComposer can be created when parsing SDL in the step before. One consequence for schema updating is that we re-use a TypeComposer that has the previously produced InputTypeComposer on an internal property. There certainly are more elegant ways to invalidate or reuse this input type - since we want to get rid of schema updating at some point anyway I didn't put much effort into that though.
stefanprobst
on 28 Jan 2019
@stefanprobst got it.
I can't find date type anywhere in code, how is it added to the composer?
freiksenet
on 29 Jan 2019
Right, never mind, it's build in GraphQL Compose.
freiksenet
on 29 Jan 2019
@freiksenet Sorry it took a bit longer - there is now a branch with everything squashed, merged with master, and with the original tests added at https://github.com/stefanprobst/gatsby/tree/schema-refactor-v2
stefanprobst
on 30 Jan 2019
@stefanprobs Thank you! That's very helpful.
freiksenet
on 30 Jan 2019
@stefanprobst I do'nt quite understand this code:
// TODO: Maybe use graphql-compose Resolver, which
// would provides the projected fields out of the box.
const addProjectedFields = fields =>
Object.entries(fields).reduce((acc, [fieldName, fieldConfig]) => {
const { resolve } = fieldConfig
acc[fieldName] = {
...fieldConfig,
resolve: (source, args, context, info) => {
// TODO: We don't need the whole selection set,
// just the `projected` fields on children.
const { getProjectionFromAST } = require(`graphql-compose`)
const projection = getProjectionFromAST(info)
const { selectionSet } = info.fieldNodes[0]
extendSelectionSet(selectionSet, projection)
return resolve(source, args, context, info)
},
}
return acc
}, {})
You are getting projection from AST then merging that same projection back into selection set. Why?
freiksenet
on 30 Jan 2019
Some status update, pinging @ChristopherBiscardi who is blocked on the changes.
- I'm porting the code by going file-through-file.
- I'm being conservative and I'm removing changes that would result in minor breaking changes.
- I'm moving from a dependency on global schemaComposer state and instead passing schemaComposer to functions.
- Same goes for "db", that I pass as "nodeStorage", both to schema generation and to graphql context to be used in resolvers.
- I've made addTypeDefs and addResolvers to be actions, instead of new api runs.
My one week prediction is probably overly optimistic, but I hope to get something running until the end of the week. Let's see how it goes.
freiksenet
on 30 Jan 2019
Also I feel I'd make a similar thing that was done with lokijs and put the new schema thing under a flag. Without the flag, the two new apis won't work, but otherwise it should (hopefully) work identically. I feel many changes that @stefanprobst did to the APIs/internal logic are very good, but I want to first release something that's fully compatible before possibly adding those for 3.0.
freiksenet
on 30 Jan 2019
@freiksenet Thanks for the update! Sounds like a great plan!
You are getting projection from AST then merging that same projection back into selection set. Why?
This is what's happening:
We use the getProjectionFromAST utility from graphql-compose (that's also used internally in its Resolver class) to get all fields in the selection set plus all fields defined in projection properties. This is returned as an object.
We then use this object (that represents all the fields that need to be in the selection set) and extend the selection set accordingly.
As the TODO comment is trying to convey, this is not the most straightforward way: there is no need to use the getProjectionFromAST utility - we should just collect all the projection props ourselves and use those to extend the selection set - I hope to find some time next weekend to improve on this.
stefanprobst
on 30 Jan 2019
Also for info: except for a few tests that didn't make sense anymore (I left a comment there) all the old tests are ported and passing - except (i) sorting null values, and (ii) we infer a mix of date objects and strings as string, not as invalid.
stefanprobst
on 30 Jan 2019
Hiya!
This issue has gone quiet. Spooky quiet. 👻
We get a lot of issues, so we currently close issues after 30 days of inactivity. It’s been at least 20 days since the last update here.
If we missed this issue or if you want to keep it open, please reply here. You can also add the label "not stale" to keep this issue open!
Thanks for being a part of the Gatsby community! 💪💜
![gatsbot[bot] picture](https://avatars2.githubusercontent.com/in/12849?v=4&s=40) gatsbot[bot]
on 20 Feb 2019
gatsbot[bot]
on 20 Feb 2019
Everyone: We have an alpha version of our new Schema Customization API ready, and we'd love your feedback! For more info check out this blogpost.
stefanprobst
on 5 Mar 2019
This is released now in 2.2.x.
freiksenet
on 22 Mar 2019
Im running into an issue when using the new schema customisation with gatsby-source-contentful.
Defining a type where one of the fields points to a reference array always returns null
Ie:
type ContentfulPage implements Node {
editorTitle: String
title: String
slug: String
sections: [ContentfulSection] // im always null
}
 sami616
on 22 Mar 2019
sami616
on 22 Mar 2019
@sami616 Could you file a bug report for this, and if possible include a test repo to reproduce the error? That would be very helpful, thank you!
stefanprobst
on 22 Mar 2019
@stefanprobst will try to file a bug report today - thanks!
sami616
on 23 Mar 2019
@stefanprobst #12787 👍🏻
sami616
on 23 Mar 2019
Related issues
 jimfilippou
·
3Comments
jimfilippou
·
3Comments
 rossPatton
·
3Comments
rossPatton
·
3Comments
 brandonmp
·
3Comments
brandonmp
·
3Comments
 3CordGuy
·
3Comments
3CordGuy
·
3Comments
 hobochild
·
3Comments
hobochild
·
3Comments
Most helpful comment
I have re-created Gatsby's schema builder, mainly to better understand what's going on there, and in the process changed a couple of things that maybe someone here might find useful:
addTypeDefsthat allows to register new GraphQL types in SDL. Top nodes should implement the Node interface. Example:Plugins can take type definitions from
gatsby-config.js:@linkdirective that allows linking a field value to a node. Example:parentandchildren) should be queryable, i.e.In case you want to have a look, the stuff is here:
https://github.com/stefanprobst/gatsby/tree/rfc-schema-refactor
If you want to play with the code, make sure to
yarn add graphql-compose, and to not have conflictinggraphqlpackages (you'll get anError: InputTypeComposer accept only GraphQLInputObjectType in constructor).Please note: I did this for fun so it's not intended as a PR, there's stuff missing, there are no tests, it needs more memory, and there surely are bugs, but it would be great to get some feedback.