Freecodecamp: Machine Learning with Python Projects - HTTP 403 from CDN
Describe your problem and how to reproduce it:
There seem to be issue with loading dataset from the cdn.freecodecamp.org when using get_file() function. The problem occurs only when both these conditions are fulfilled - using that function and when data is supposed to be downloaded from cdn.freecodecamp.org. So this currently applies only to Cat and Dog Image Classifier and Linear Regression Health Costs Calculator notebooks.
There's no issue when dataset is downloaded alternatively - using wget as in Book Recommendation Engine using KNN notebook, or when dataset is not on cdn.freecodecamp.org as in Neural Network SMS Text Classifier.
When replacing downloading get_file() with the wget alternative in the affected notebooks datasets downloads fine.
fcc_cat_dog.ipynb
Downloading data from https://cdn.freecodecamp.org/project-data/cats-and-dogs/cats_and_dogs.zip
---------------------------------------------------------------------------
HTTPError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/utils/data_utils.py in get_file(fname, origin, untar, md5_hash, file_hash, cache_subdir, hash_algorithm, extract, archive_format, cache_dir)
262 try:
--> 263 urlretrieve(origin, fpath, dl_progress)
264 except HTTPError as e:
8 frames
HTTPError: HTTP Error 403: Forbidden
During handling of the above exception, another exception occurred:
Exception Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/utils/data_utils.py in get_file(fname, origin, untar, md5_hash, file_hash, cache_subdir, hash_algorithm, extract, archive_format, cache_dir)
263 urlretrieve(origin, fpath, dl_progress)
264 except HTTPError as e:
--> 265 raise Exception(error_msg.format(origin, e.code, e.msg))
266 except URLError as e:
267 raise Exception(error_msg.format(origin, e.errno, e.reason))
Exception: URL fetch failure on https://cdn.freecodecamp.org/project-data/cats-and-dogs/cats_and_dogs.zip: 403 -- Forbidden
fcc_predict_health_costs_with_regression.ipynb
Downloading data from https://cdn.freecodecamp.org/project-data/health-costs/insurance.csv
---------------------------------------------------------------------------
HTTPError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/utils/data_utils.py in get_file(fname, origin, untar, md5_hash, file_hash, cache_subdir, hash_algorithm, extract, archive_format, cache_dir)
262 try:
--> 263 urlretrieve(origin, fpath, dl_progress)
264 except HTTPError as e:
8 frames
HTTPError: HTTP Error 403: Forbidden
During handling of the above exception, another exception occurred:
Exception Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/utils/data_utils.py in get_file(fname, origin, untar, md5_hash, file_hash, cache_subdir, hash_algorithm, extract, archive_format, cache_dir)
263 urlretrieve(origin, fpath, dl_progress)
264 except HTTPError as e:
--> 265 raise Exception(error_msg.format(origin, e.code, e.msg))
266 except URLError as e:
267 raise Exception(error_msg.format(origin, e.errno, e.reason))
Exception: URL fetch failure on https://cdn.freecodecamp.org/project-data/health-costs/insurance.csv: 403 -- Forbidden
Add a Link to the page with the problem:
https://www.freecodecamp.dev/learn/machine-learning-with-python/machine-learning-with-python-projects/cat-and-dog-image-classifier
https://colab.research.google.com/drive/1UCHiRuBLxo0S3aMuiDXlaP54LsxzrXHz
https://www.freecodecamp.dev/learn/machine-learning-with-python/machine-learning-with-python-projects/linear-regression-health-costs-calculator
https://colab.research.google.com/drive/1o8sTSCMa8Tnmcqhp_2BKKJEaHFoFmRzI?usp=sharing
 gikf
gikf
All 16 comments
As far as I can see, the problem is that get_file does not let you pass any headers and the cdn rejects anything without a User-Agent header. With that in mind, the following code lets you download the file:
import urllib.request
import shutil
URL = 'https://cdn.freecodecamp.org/project-data/cats-and-dogs/cats_and_dogs.zip'
# The cdn requires a user agent
req = urllib.request.Request(URL, headers={'User-Agent' : "Magic Browser"})
# Download the file from `url` and save it locally under `file_name`:
with urllib.request.urlopen(req) as response, open('cats_and_dogs.zip', 'wb') as out_file:
shutil.copyfileobj(response, out_file)
@beaucarnes does that seem reasonable?
 ojeytonwilliams
on 29 Jun 2020
ojeytonwilliams
on 29 Jun 2020
We made some changes to our CDN config. @sanityto Can you verify this is resolved?
 raisedadead
on 30 Jun 2020
raisedadead
on 30 Jun 2020
It works now as expected @raisedadead.
gikf
on 30 Jun 2020
Thanks for confirming. Happy coding.
raisedadead
on 30 Jun 2020
Hey guys, I'm still having this issue. I'm getting a 403 error on the https://www.freecodecamp.dev/learn/machine-learning-with-python/machine-learning-with-python-projects/cat-and-dog-image-classifier.
What can I do?
 pasDamola
on 6 Oct 2020
pasDamola
on 6 Oct 2020
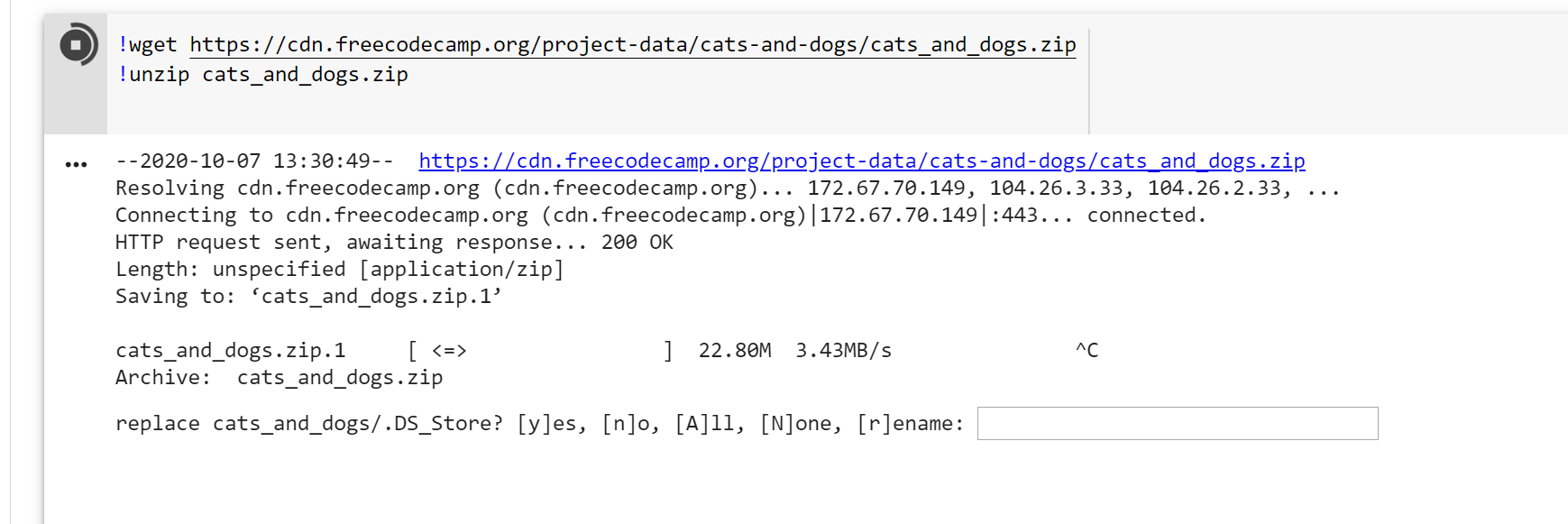
I had to apply a workaround
To download the data, I used;
!wget https://cdn.freecodecamp.org/project-data/cats-and-dogs/cats_and_dogs.zip
Then to unzip it;
!unzip cats_and_dogs.zip
pasDamola
on 7 Oct 2020
Thanks for reporting this @pasDamola, it seems to be the exactly the same problem as before. @raisedadead did we change the CDN config?
I had to apply a workaround
I was going to suggest a variant of the code I applied above, but that workaround is neat. Thanks for sharing.
ojeytonwilliams
on 7 Oct 2020
Thank you @ojeytonwilliams
pasDamola
on 7 Oct 2020
The URL in the comment is from the staging instance, please confirm you are on not on the staging site.
raisedadead
on 7 Oct 2020
It's happening in production, too. Both .dev and .org link to https://colab.research.google.com/drive/1UCHiRuBLxo0S3aMuiDXlaP54LsxzrXHz#scrollTo=jaF8r6aOl48C and it has the issue.
ojeytonwilliams
on 7 Oct 2020
Thanks for confirming, can we get some error logs and steps to reproduce for reproduction. Is it exactly the same as the OP?
raisedadead
on 7 Oct 2020
FYI here is the HEADERS config for CDN:
https://github.com/freeCodeCamp/cdn/blob/b40b5ee60c7c05145c45b87b10c2cbc9b5bd6547/build/_headers#L1-L6
raisedadead
on 7 Oct 2020
OK - as mentioned in https://github.com/freeCodeCamp/freeCodeCamp/issues/39099#issuecomment-704749247 wget works so it could be issue with the get_file and we could use https://github.com/freeCodeCamp/freeCodeCamp/issues/39099#issuecomment-651261679 if its still valid.
I am no Python expert, so I will let someone else recommend a fix.
That said, the CDN config seems to be valid.
raisedadead
on 7 Oct 2020
Thanks for that workaround @pasDamola. It seems like the Book Recommendation project boilerplate was already updated to use !wget and !unzip like you suggested. Now it's just the Cat and Dog Image Classifier boilerplate repo that needs to be updated.
Rather than maintain separate GitHub boilerplate repos and a Jupyter notebooks on Drive, we can spin off projects directly from the GH repos using a link like this: https://colab.research.google.com/github/freeCodeCamp/boilerplate-book-recommendation-engine/blob/master/fcc_book_recommendation_knn.ipynb
I'll go ahead and create PRs towards the Cat and Dog Image Classifier boilerplate repo and /learn.
 scissorsneedfoodtoo
on 11 Nov 2020
scissorsneedfoodtoo
on 11 Nov 2020
@scissorsneedfoodtoo I notice the following boilerplates still use get_file method. Do these need to be updated also?
 RandellDawson
on 11 Nov 2020
RandellDawson
on 11 Nov 2020
@RandellDawson, thanks for catching that.
The Predict Health Cost Regression project definitely needs to be changed since it's trying to get the file from the CDN repo.
The SMS Text Classification should be fine for now because it's grabbing the files from GitHub directly. But it wouldn't hurt to update the boilerplate so it uses !wget, though.
I'll make a couple of quick PRs and tag you in them.
scissorsneedfoodtoo
on 13 Nov 2020
Related issues
 SaintPeter
·
3Comments
SaintPeter
·
3Comments
 ROWn1ne
·
3Comments
ROWn1ne
·
3Comments
 robwelan
·
3Comments
robwelan
·
3Comments
 jurijuri
·
3Comments
jurijuri
·
3Comments
 trashtalka3000
·
3Comments
trashtalka3000
·
3Comments