Forem: Canonical URL should be in <head> instead of <body>
Describe the bug
I was assisting an AWS Hero with drafting their first post for the AWS Heroes DEV Organization and I was and explaining to them they can apply a Canonical URL. The Hero pointed out to me that they think the Canonical URLs should be in the <HEAD> instead of the <BODY> otherwise that would render the Canonical URL ineffective.
According to Google's documentation:
the
rel=canonicallink tag should only appear in the<head>of an HTML document. Additionally, to avoid HTML parsing issues, it’s good to include the rel=canonical as early as possible in the<head>. When we encounter a rel=canonical designation in the<body>, it’s disregarded.
To Reproduce
I do not know how to reproduce.
Screenshots
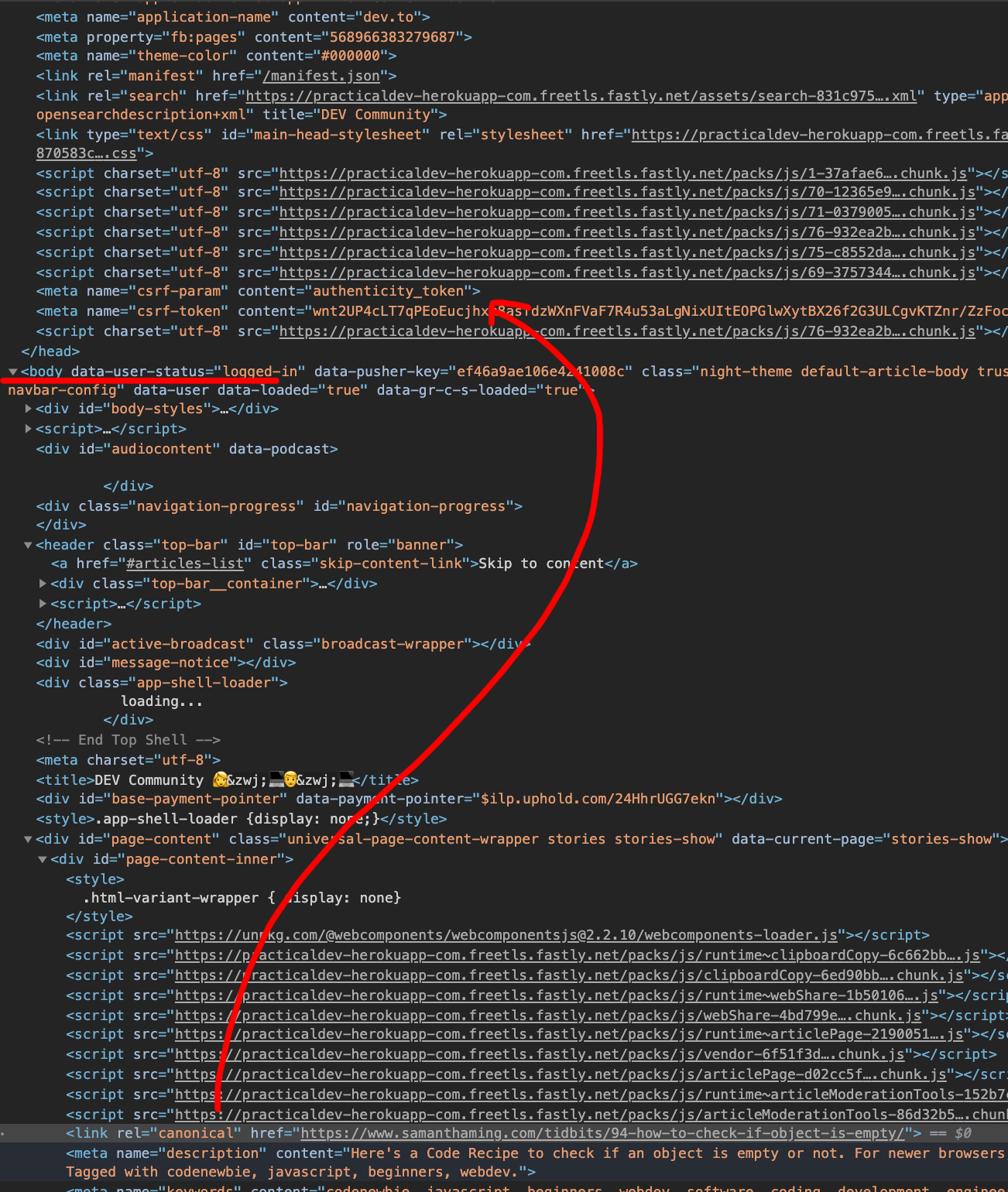
Desktop (please complete the following information):
N/A
Smartphone (please complete the following information):
N/A
Additional context
I thought possibly that it was previously in the <HEAD> and then later moved to <BODY> but it appears it has always been in the <BODY> since the first commit when the project became open-source in the old-repository.
I think I saw @benhalpern in the Gblame so possibly he can provide context here if the tag warrants to be moved.
 omenking
omenking
All 30 comments
In app/views/shell/_top.html.erb the canonical link appeares to be included in this block:
<%= content_for :page_meta do %>
<% if @article.canonical_url.present? %>
<link rel="canonical" href="<%= @article.canonical_url %>"/>
<% else %>
<link rel="canonical" href="https://dev.to<%[email protected]%>"/>
<% end %>
<meta name="description" content="<%[email protected] || "An article from the community" %>">
<meta name="keywords" content="software development,engineering,rails,javascript,ruby">
<meta property="og:type" content="article" />
<meta property="og:url" content="https://dev.to<%[email protected]%>" />
<meta property="og:title" content="<%[email protected] %>" />
<meta property="og:description" content="<%[email protected] || "An article from the community" %>" />
<meta property="og:site_name" content="The Practical Dev" />
<meta name="twitter:site" content="@ThePracticalDev">
<meta name="twitter:creator" content="@<%[email protected]_username %>">
<meta name="twitter:title" content="<%[email protected] %>">
<meta name="twitter:description" content="<%[email protected] || "An article from the community" %>">
<meta name="twitter:card" content="summary_large_image">
<meta property="og:image" content="<%= cloud_social_image(@article) %>" />
<meta name="twitter:image:src" content="<%= cloud_social_image(@article) %>">
<% end %>
So I was checking the yield in the app/views/layouts/application.html.erb as such:
<%= yield(:page_meta) %>
And so I found the yield. It looks like to be it is in the <HEAD>
<head>
<meta charset="utf-8">
<% title = yield(:title) %>
<title><%= title || community_qualified_name.to_s %></title>
<% unless internal_navigation? %>
<meta name="last-updated" content="<%= Time.current %>">
<meta name="user-signed-in" content="<%= user_signed_in? %>">
<% if SiteConfig.payment_pointer.present? %>
<!-- Experimental web monetization payment pointer for micropayments -->
<!-- It lets readers make micropayments to websites they visit. -->
<!-- This is step 1: Get live in production to test for platform-wide payment pointer. -->
<!-- Step 2: Allow authors to set their payment pointer so they can directly monetize their content based on visitors. -->
<!-- Step 3: Enable further functionality based on what we learn from this experimentation and how the ecosystem evolves. -->
<meta name="monetization" content="<%= SiteConfig.payment_pointer %>">
<% end %>
<meta name="environment" content="<%= Rails.env %>">
<%= render "layouts/styles" %>
<style>
.home {
position: relative;
margin: auto;
max-width: 1250px;
}
</style>
<% unless user_signed_in? %>
<%= javascript_packs_with_chunks_tag "Search", defer: true %>
<% end %>
<%= javascript_include_tag "base", defer: true %>
<% if user_signed_in? %>
<%= javascript_packs_with_chunks_tag "Search", "onboardingRedirectCheck", "contentDisplayPolicy", defer: true %>
<% end %>
<%= yield(:page_meta) %>
<meta name="viewport" content="width=device-width, initial-scale=1.0, viewport-fit=cover">
<%= favicon_link_tag SiteConfig.favicon_url %>
<link rel="apple-touch-icon" href="<%= cloudinary(SiteConfig.logo_png, 180, "png") %>">
<link rel="apple-touch-icon" sizes="152x152" href="<%= cloudinary(SiteConfig.logo_png, 152, "png") %>">
<link rel="apple-touch-icon" sizes="180x180" href="<%= cloudinary(SiteConfig.logo_png, 180, "png") %>">
<link rel="apple-touch-icon" sizes="167x167" href="<%= cloudinary(SiteConfig.logo_png, 167, "png") %>">
<link href="<%= cloudinary(SiteConfig.logo_png, 192, "png") %>" rel="icon" sizes="192x192" />
<link href="<%= cloudinary(SiteConfig.logo_png, 128, "png") %>" rel="icon" sizes="128x128" />
<meta name="apple-mobile-web-app-title" content="<%= ApplicationConfig["APP_DOMAIN"] %>">
<meta name="application-name" content="<%= ApplicationConfig["APP_DOMAIN"] %>">
<meta property="fb:pages" content="568966383279687" />
<meta name="theme-color" content="#000000" />
<link rel="manifest" href="/manifest.json" />
<link rel="search" href="<%= asset_path("search.xml") %>" type="application/opensearchdescription+xml" title="<%= community_qualified_name %>" />
<% end %>
</head>
But the live site (DEV.to) shows it rendering in the <BODY>. I am confused 😕
omenking
on 25 Jul 2020
I am going to attempt to run the application locally and see where it renders.
omenking
on 25 Jul 2020
I have no chance of getting this running locally with the new changes, attempting GitPod.
Looks like it rolling along 🤞
omenking
on 25 Jul 2020
Possibly another issue, Can't seed data.
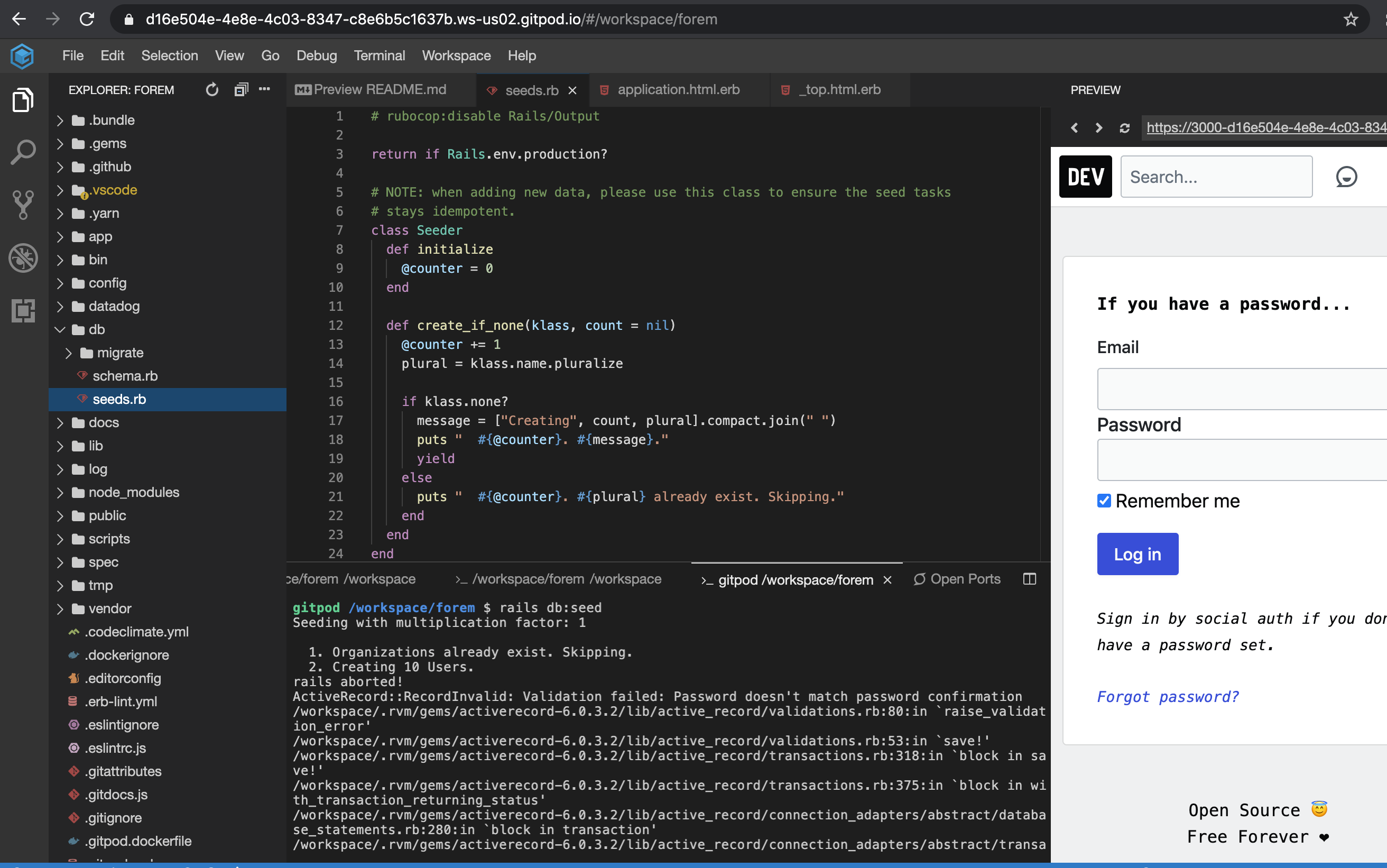
I added in:
password_confirmation: "password"
For the create and now the seeding is working as expected:
user = User.create!(
name: name,
summary: Faker::Lorem.paragraph_by_chars(number: 199, supplemental: false),
profile_image: File.open(Rails.root.join("app/assets/images/#{rand(1..40)}.png")),
website_url: Faker::Internet.url,
twitter_username: Faker::Internet.username(specifier: name),
email_comment_notifications: false,
email_follower_notifications: false,
# Emails limited to 50 characters
email: Faker::Internet.email(name: name, separators: "+", domain: Faker::Internet.domain_word.first(20)),
confirmed_at: Time.current,
password: "password",
password_confirmation: "password"
)
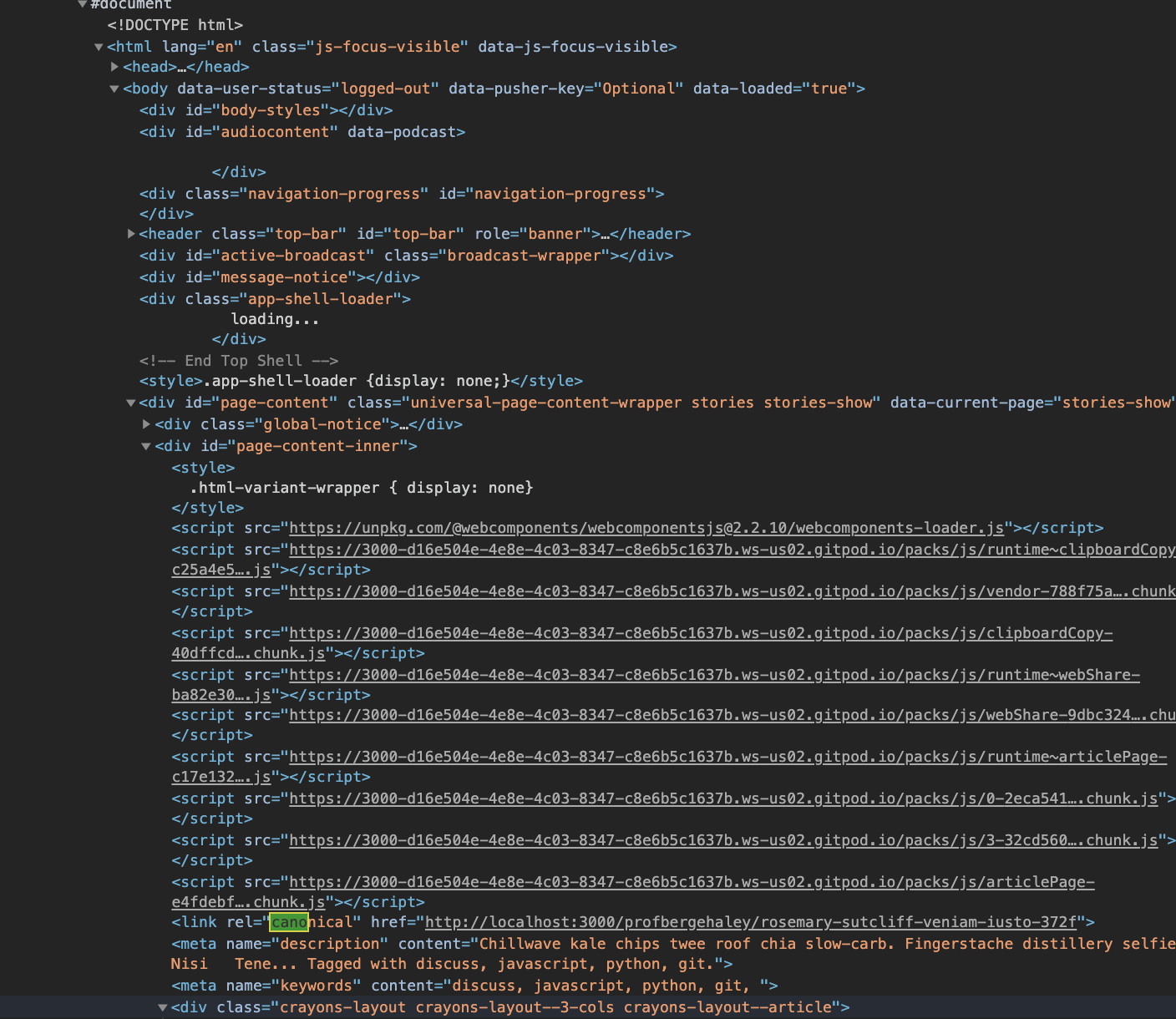
Confirmed that the application in GitPods does render in the <body> instead of <head>.
Confusing....
omenking
on 25 Jul 2020
I thought also maybe the preact was being rehydrated on top of a server-side render page so it is in the right area but when forcing cache to clear appears to be still in the body. 🤷♂️
omenking
on 25 Jul 2020
Thanks for the detailed writeup @omenking, I'll fix the seeds for now!
 citizen428
on 27 Jul 2020
citizen428
on 27 Jul 2020
@omenking if I'm understanding and if I recall correctly, the canonical URL is rendered here:
https://github.com/forem/forem/blob/0c8af6bd1eaffbd964a7fc865ef35db6e9af91bc/app/views/articles/show.html.erb#L56
And we intentionally put it in the body because it's article-specific and many of our headers, top bars, etc are all cached.
 atsmith813
on 27 Jul 2020
atsmith813
on 27 Jul 2020
An update in my own personal research:
- Google says that it should be in the header
- Some browsers can lift it into the header, I did not observe that but it would not matter since what we care about is what search engines do, and we can never know since that knowledge and technology is proprietary.
Testing some DEV articles at random I get mixed results with search engines. I cannot tell since I think Google and certain engines can personalize your results so I have no sense of truth even when using a Private VPN.
Can we know definitely (without a doubt) that the
canoncial_urlis valid and works as expected by search engines while in the<body>?- If we can not definitely know, can we work to move this into the
<header>?
I want to be able to say to authors who I am onboarding to DEV without a doubt that if they cross-post they will not be competing against their own personal blogs for organic search traffic. I don't have the certainty or SEO expertise to prove it, since I tend to not care about the canoncial_url 😂
omenking
on 27 Jul 2020
Current state of affairs:
@atsmith813 This is gated by a condition on internal_navigation?, the else-branch uses content_for(:page_meta) as I would expect. This method is defined in ApplicationController and made available in views via helper_method:
def internal_navigation?
params[:i] == "i"
end
helper_method :internal_navigation?
I assume this has something to do with our top shell, we may only be swapping out the document body for internal navigation, though I'm not overly familiar with this part of the app.
Should we have canonical links in <body>?
tl;dr: No.
Longer answer: According to the HTML specification section 4.2.4, link tags can appear in the body if they use only keywords that are "body-ok" (source). This list is of keywords is quite limited: dns-prefetch, modulepreload, pingback, preconnect, prefetch, preload, prerender, and stylesheet, see here for more details.
Now we all know that lived reality often trumps standards in web development, but the document linked above by Andrew is quite clear on the matter, Google considers canonical links the body a mistake.
What does this mean?
We should find a better way to swap out the canonical URL in the header during internal navigation. Maybe @benhalpern, @maestromac or @nickytonline want to comment on this.
citizen428
on 30 Jul 2020
Hey! While reading up on canonical recently, I did find out that there are two ways to implement it:
- rel=canonical tag.
- rel=canonical HTTP header.
The rel="canonical" HTTP Headers work with web search and could help resolve this issue by allowing to send it in the response.
 Amorpheuz
on 1 Aug 2020
Amorpheuz
on 1 Aug 2020
To bring some clarity to this conversation.... the canonical tag _is_ in the body. This was discussed here. https://github.com/forem/forem/issues/5156
I think we should add a comment on the page to prevent further confusion.
If you run the page with service workers turned off...
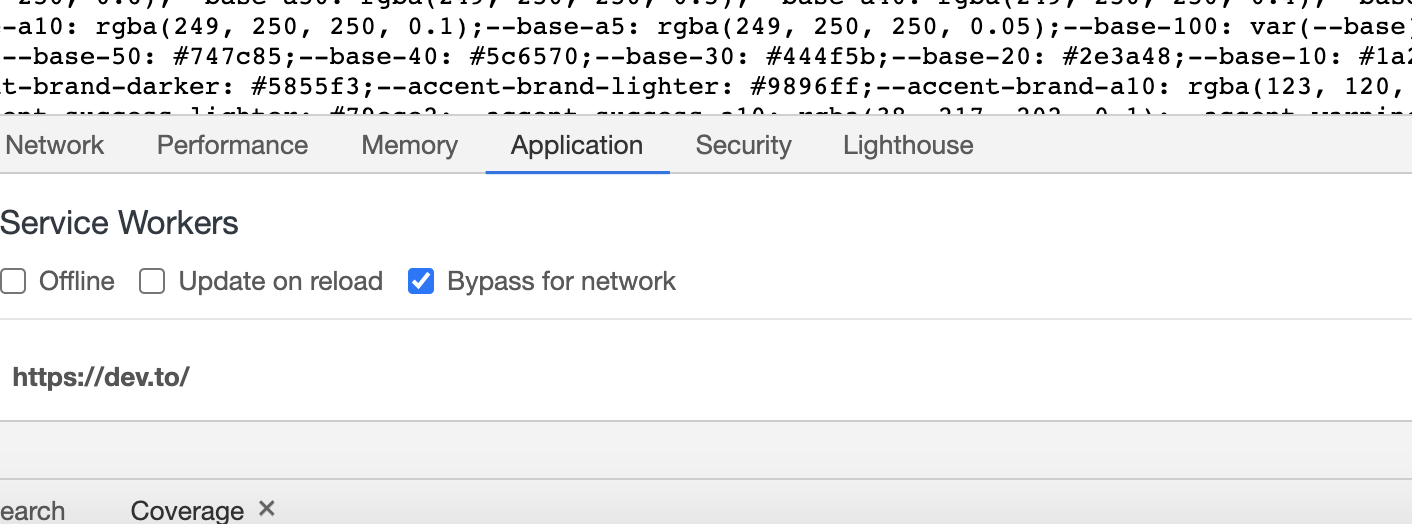
You'll see that the canonical url is in the head, as dictated by <%= content_for :page_meta do %>.
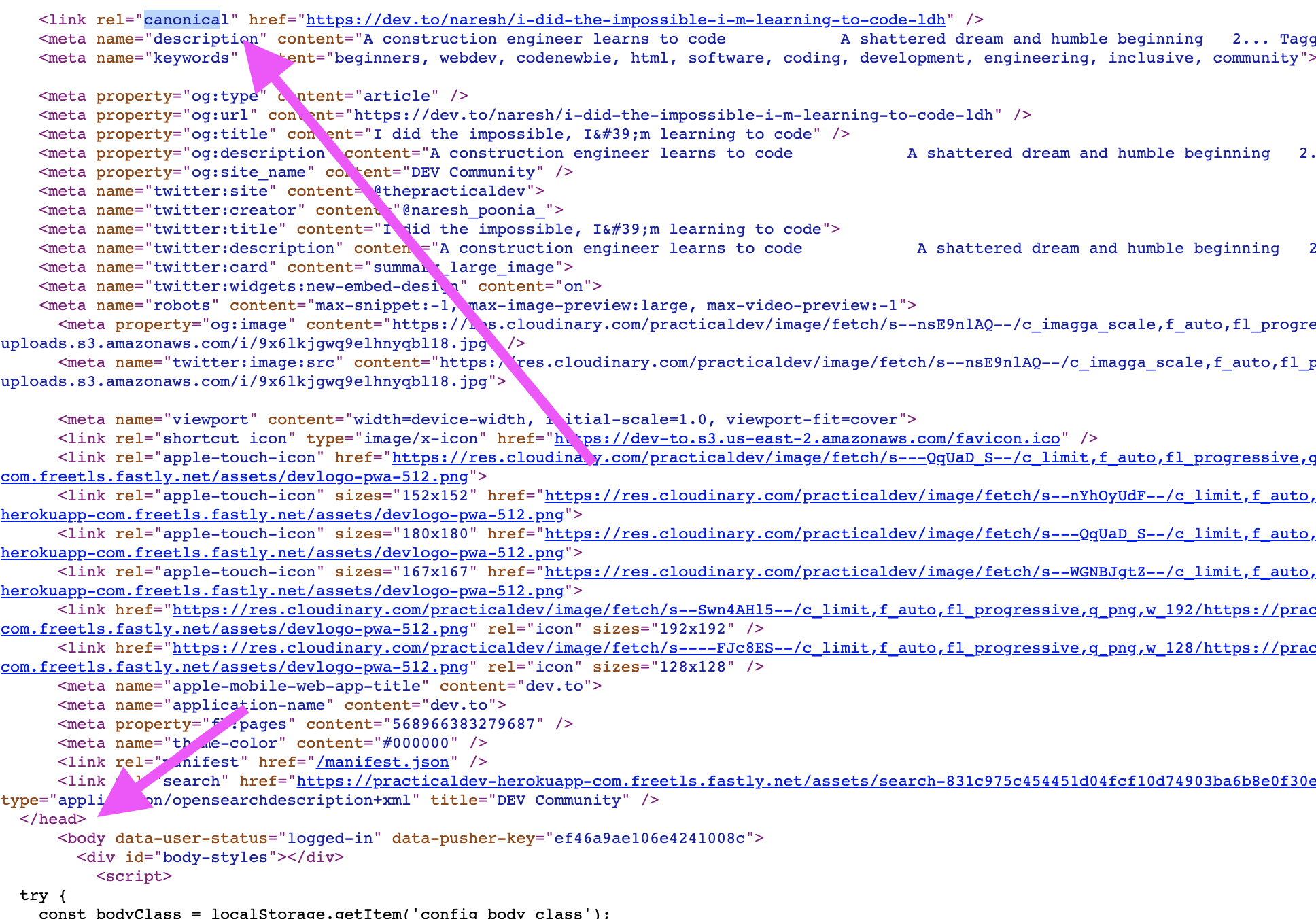
The boolean here is that if service workers are running, we fetch the page as if it were "internal nav" because we already have fetched the "shell" from the local cache. No crawler will request this version of the page, it would only be used after a user has triggered service workers based on prior interactions.
I think the satisfaction of this issue would be to add a clear comment about this in the html.
 benhalpern
on 5 Aug 2020
benhalpern
on 5 Aug 2020
No crawler will request this version of the page, it would only be used after a user has triggered service workers based on prior interactions.
Then who is the tag in the body for? It's a tag for search engines, but according to this description they'll never see it. So I'm wondering if instead of adding a comment explaining all of this, we can just remove it completely for the internal navigation case.
citizen428
on 5 Aug 2020
Just explained in another way here.
The original DEV page renders the meta tag in the header.
DEV uses a service worker to add progressive web app (PWA) features. PWA Service workers offer rich offline experiences, periodic background syncs, push notifications, functionality that would normally require a native application or features eventually coming to the web. Service workers provide the technical foundation that all these features rely on.
DEV has a service worker which you can see gets registered in:
app/assets/javascripts/serviceworkers-companion.js
And this maps to a route that hits the following controller method:
def index
set_surrogate_key_header "serviceworker-js"
render formats: [:js]
end
Which in turn renders app/view/service_worker/index.js.erb
The service work will grab from the cache the header and the footer and replace them on the page.
event.waitUntil(
caches.open(staticCacheName)
.then(cache => cache.addAll([
"/shell_top", // head, top bar, inline styles
"/shell_bottom", // footer
"/async_info/shell_version", // For comparing changes in the shell. Should be incremented with style changes.
"/404.html", // Not found page
"/500.html", // Error page
"/offline.html" //Offline page
]))
);
});
My recommendation would be when the service worker replaces the header it reinserts the canonical_url back into the header. canonical_url are a touchy subject and even though I can make developer assumptions that it's okay replace the header since it would not make sense for the search engine bot to load a service worker and then read the page, there will linger unanswered questions that may not be provable.
omenking
on 5 Aug 2020
I am still uncertain. Google does execute javascript, and my developer's brain says to me I would assume their crawler ignores service objects but does it really?
https://developers.google.com/search/docs/guides/javascript-seo-basics
Here is a fresh article on DEV:
Here is the canonical URL:

https://daily-dev-tips.com/posts/pimp-your-github-profile/
Here's the blog
This is google's result. returns DEV first.
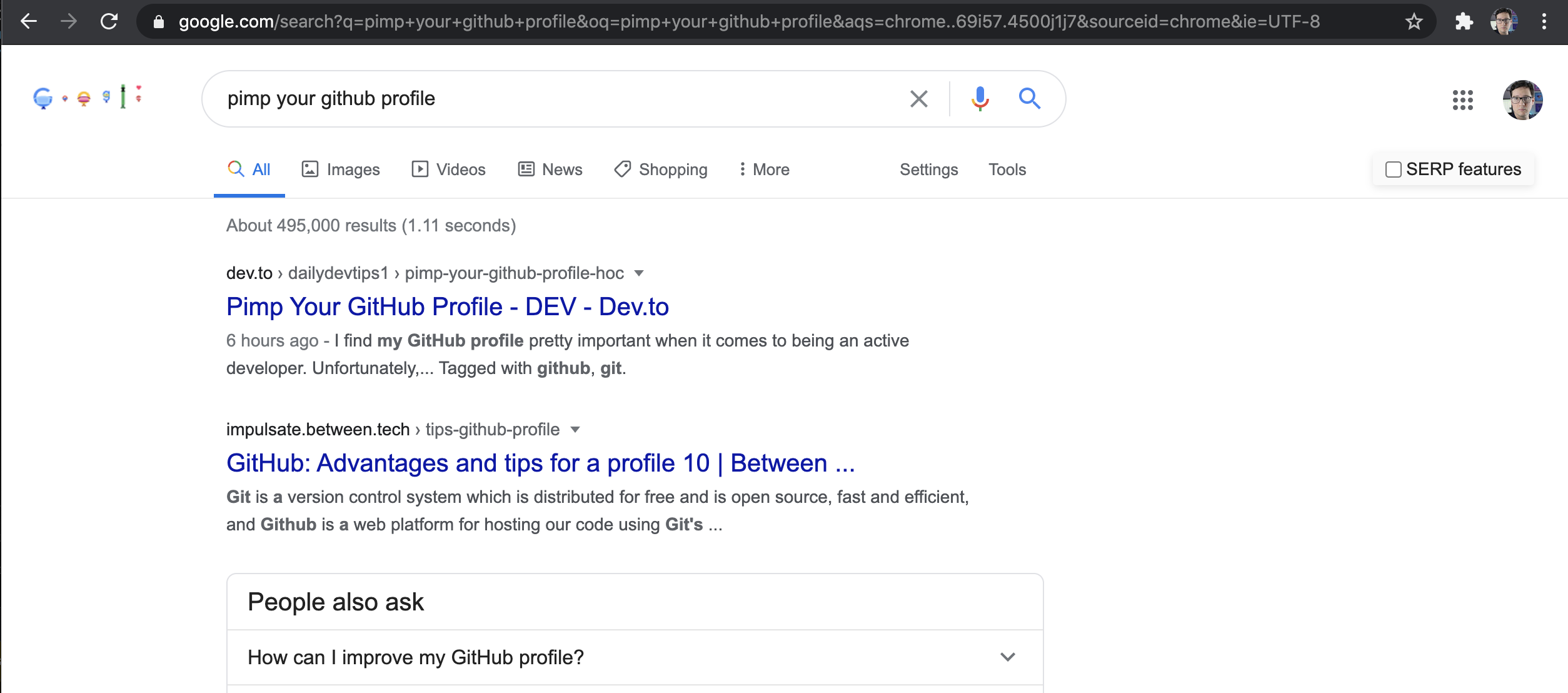
- Did they publish first on DEV and then on their own blog?
- Is Google's cache just old and it takes time to propagate?
I just get mixed results so this is where my doubt keeps coming from.
omenking
on 5 Aug 2020
Just to rule out "fresh" or google taking time to cache, here is another one I just pulled at random:
Here it looks like it doesn't have a canonical URL
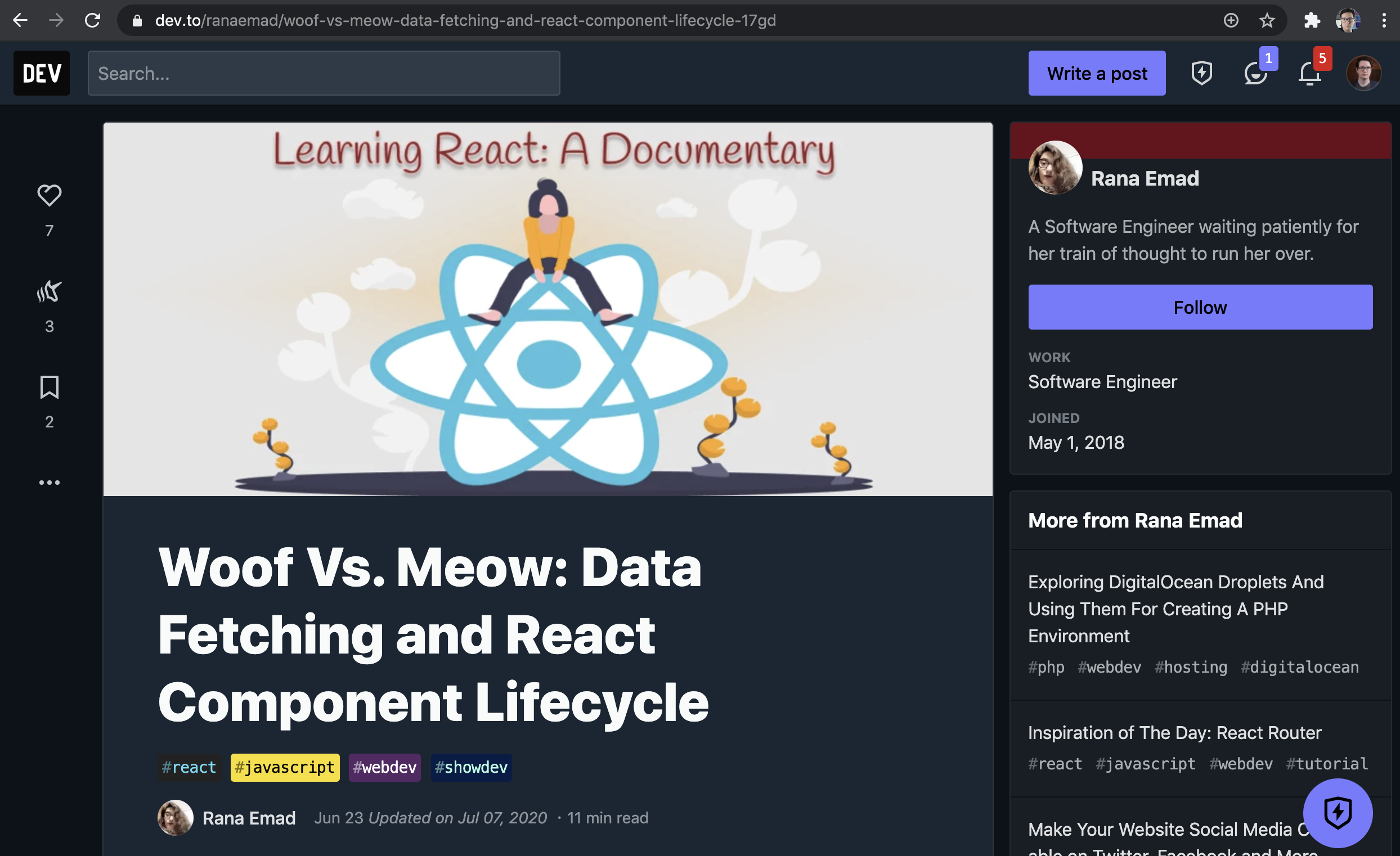
Checking the source code there is a canonical URL
https://blog.ranaemad.com/woof-vs-meow-data-fetching-and-react-component-lifecycle-ckcbpsbvj0002yys155ij60g0
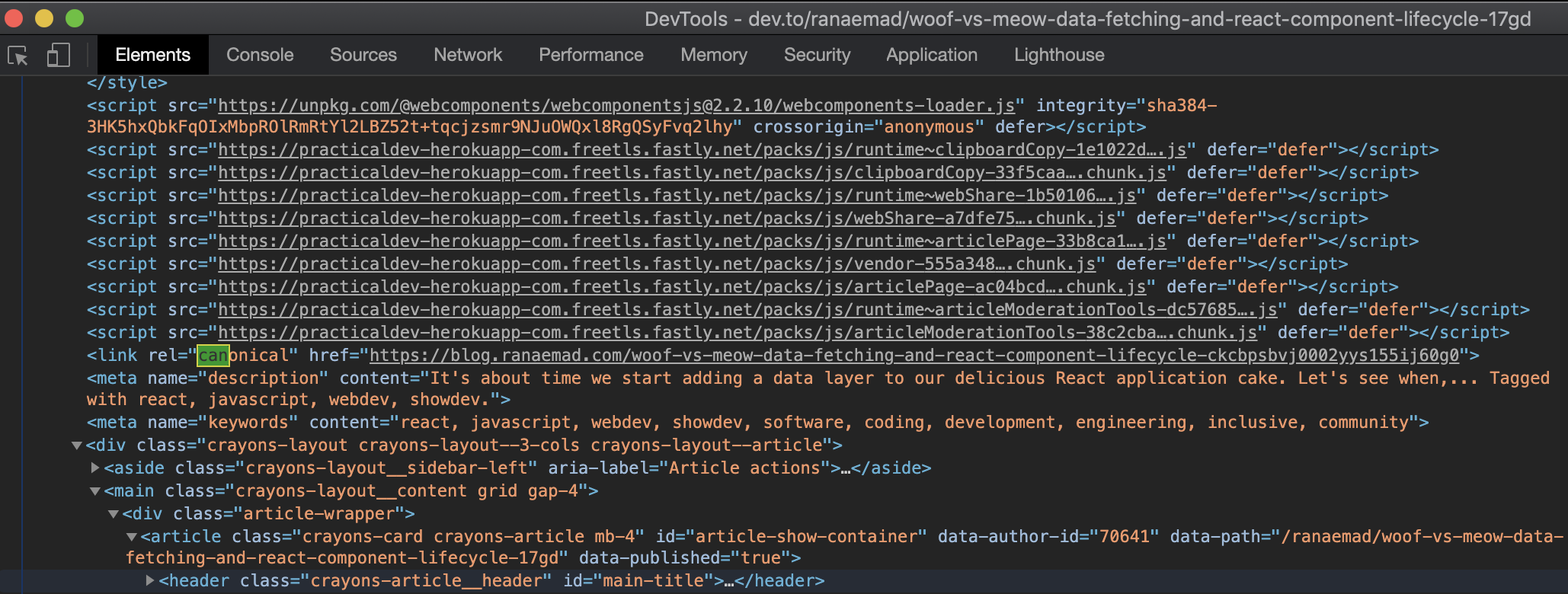
Here is the original blog post:
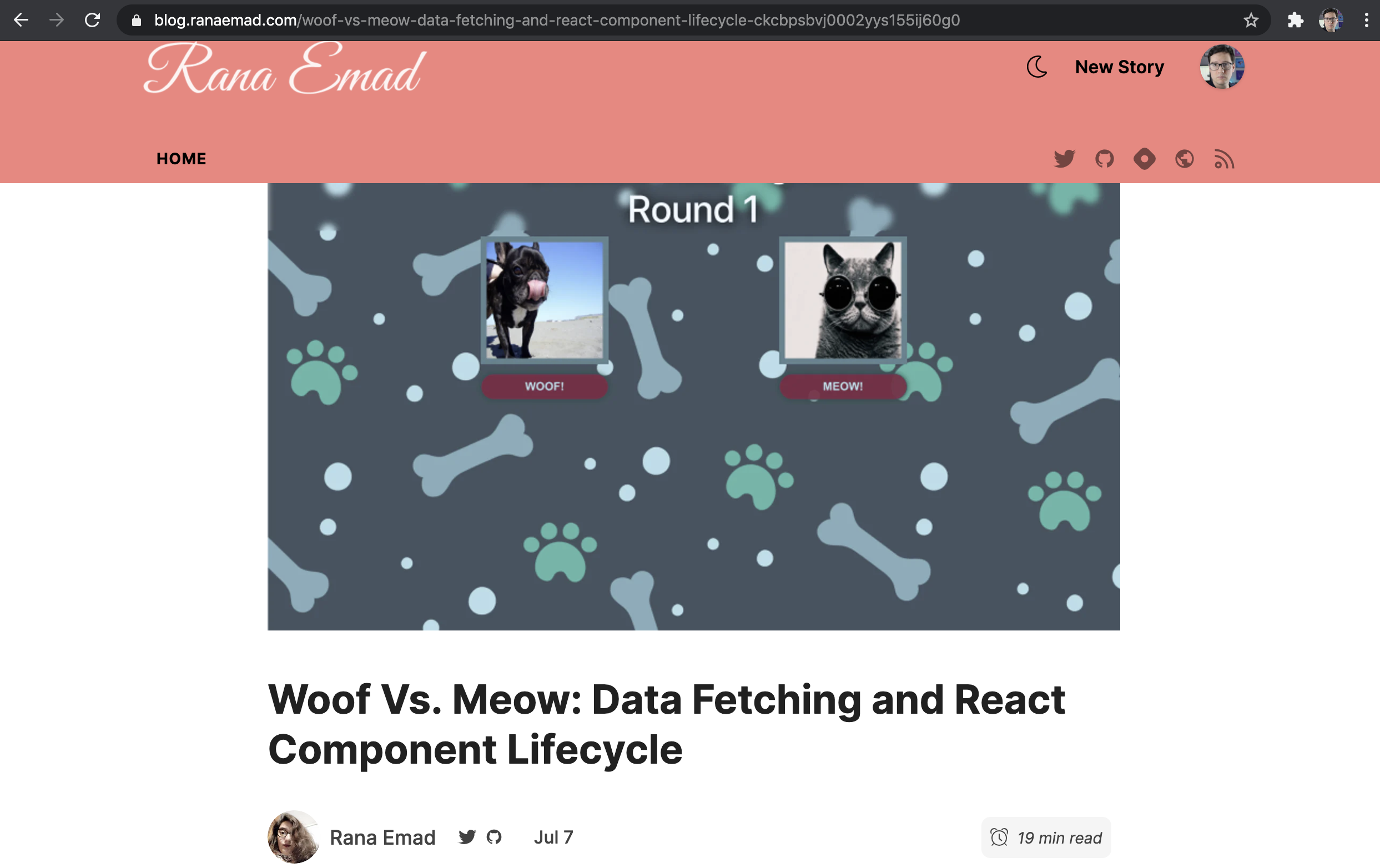
Here are my google results:
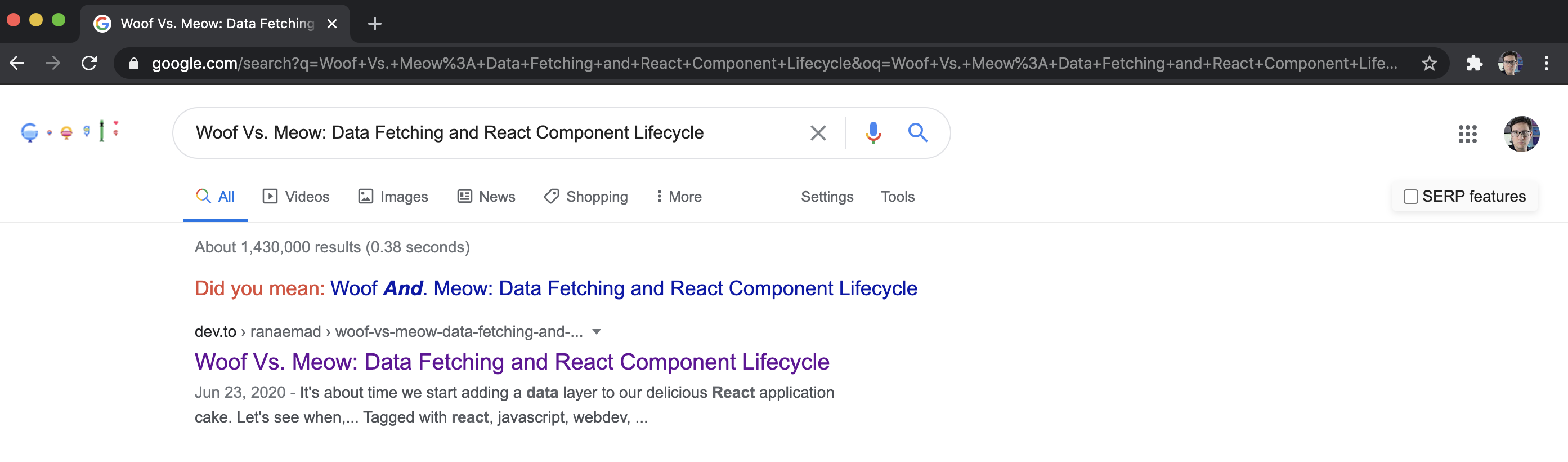
Is it because they updated their article? Is google holding on to an old cached file? Is DEV canonical URL ineffective? I just can't tell.
omenking
on 5 Aug 2020
Here is something I know I published first on Hashnode.
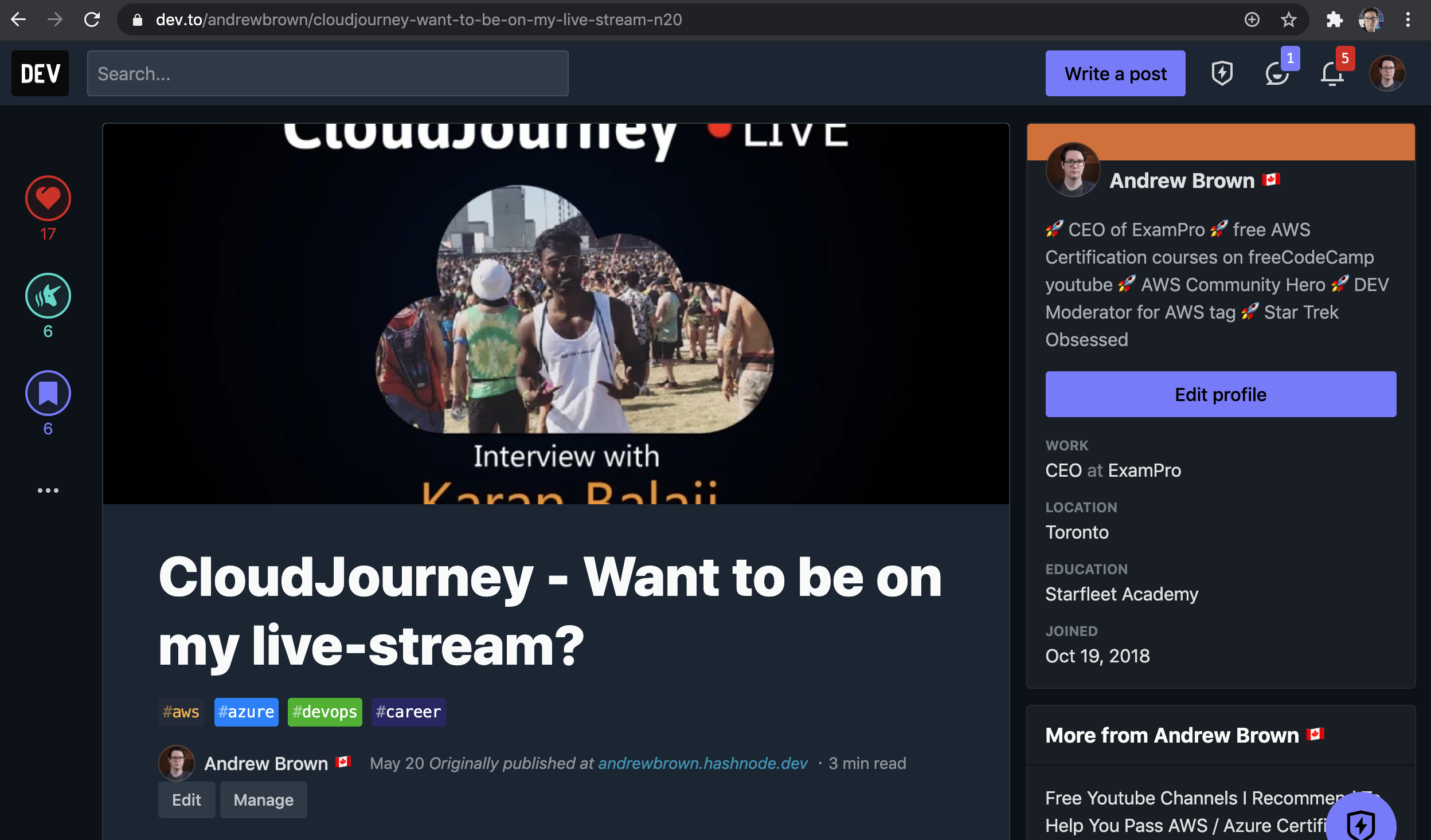
So here is both. I thought the canonical URL made it so only that the original source shows up, so why do both show-up and why is DEV first?
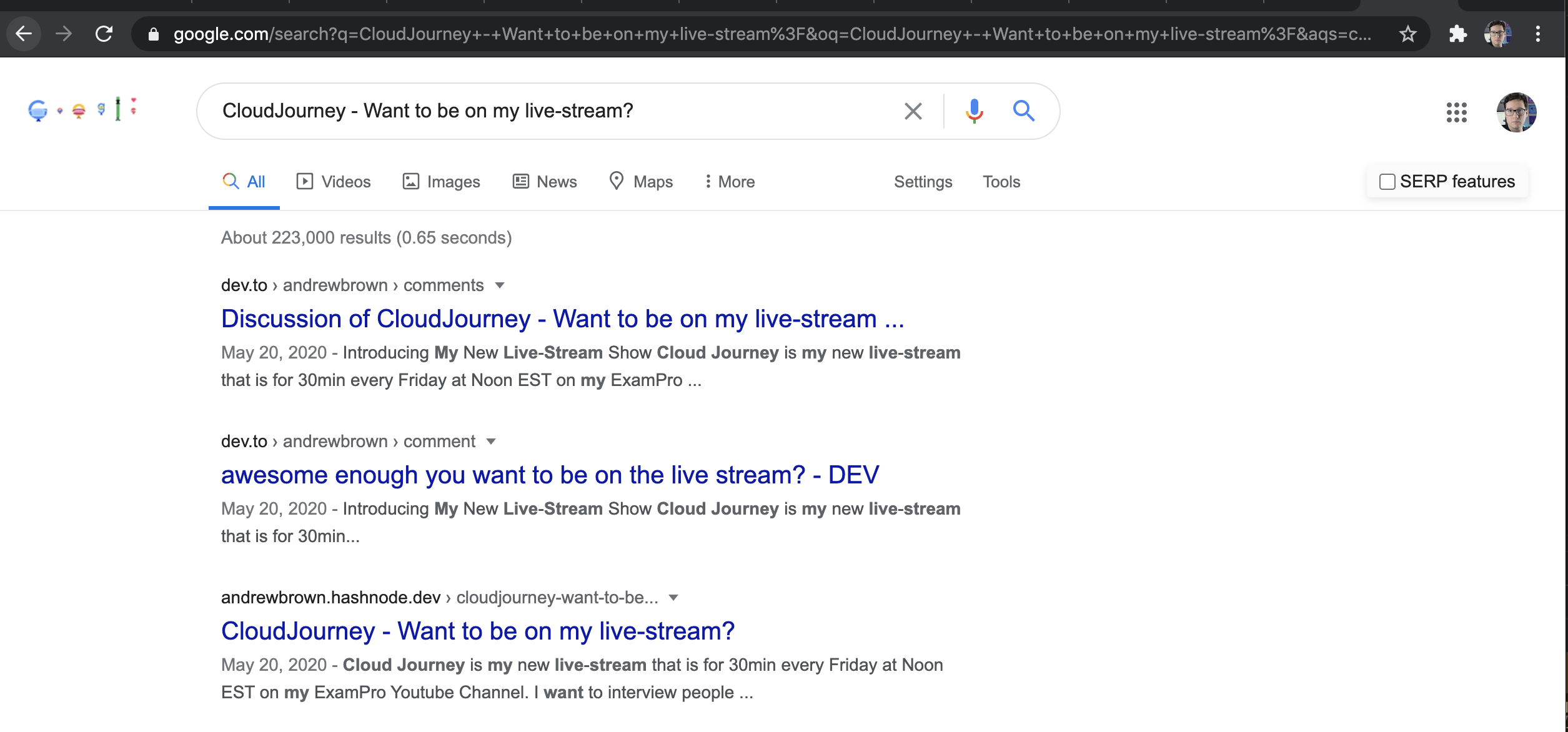
My developer instinct would be to stop caching the header, flush these pages and do a sanity check to ensure that it's not interfering with the canonical URL and see if these pages have any changes in ranking.
Updated : Here is the DEV comments page, so I suppose this example is exactly the same as prior or how I thought when describing it. So now here's a question which Im sure opens up a can of worms, should comments pages like this point to the canonical URL to the original article?
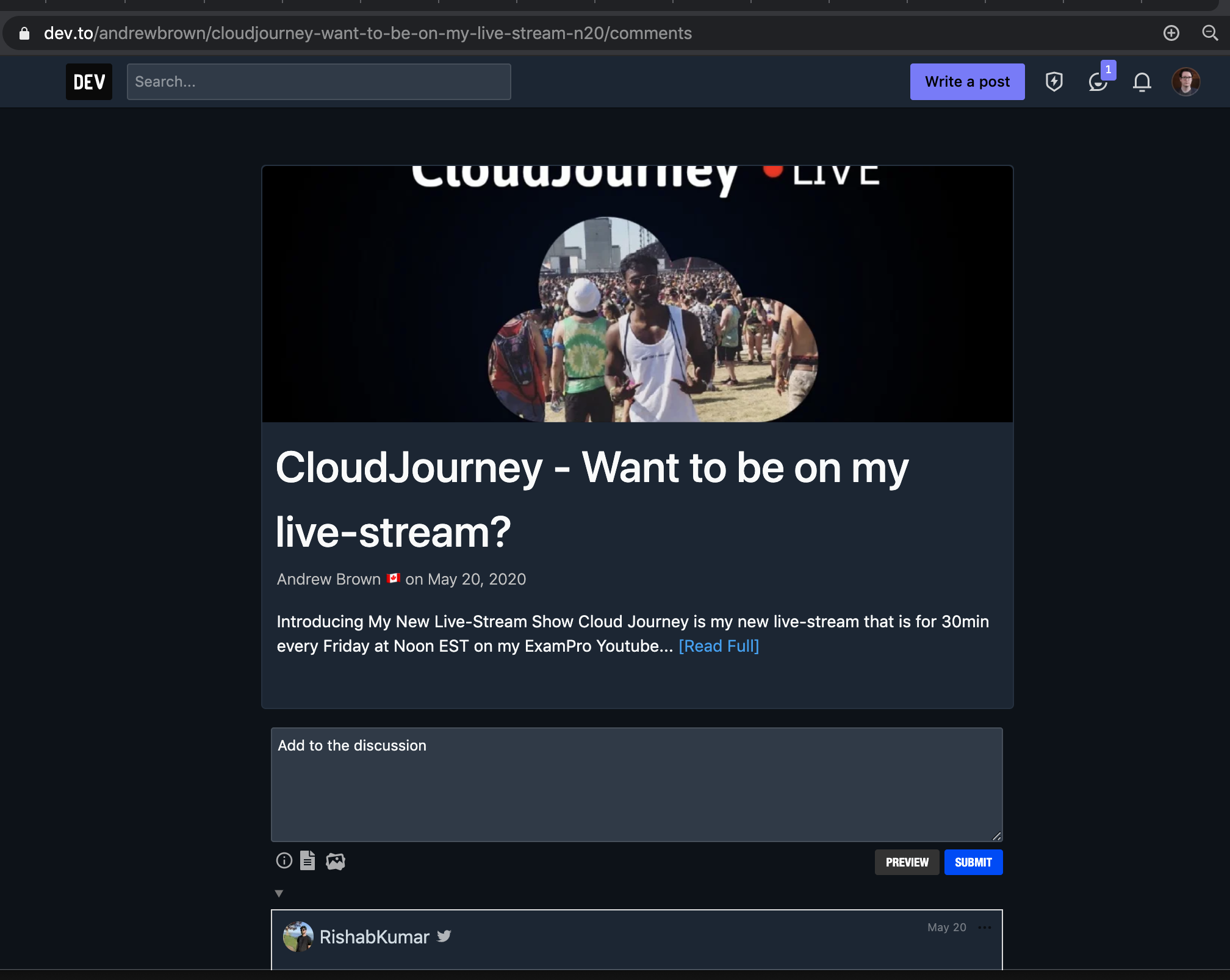
This is hard because people are authoring comments, and its their content, but its competing with the original article, and in this specific example its show part of the article, but the comments are competing with the article...
omenking
on 5 Aug 2020
https://dev.to/yujiri8/how-can-i-tell-if-my-canonical-urls-are-working-4l6p
So I'm just not sure if this is normal behaviour or something we can figure out but at least I'm not the only one confused on the matter
omenking
on 5 Aug 2020
Okay so this is interesting
https://support.google.com/webmasters/answer/139066?hl=en
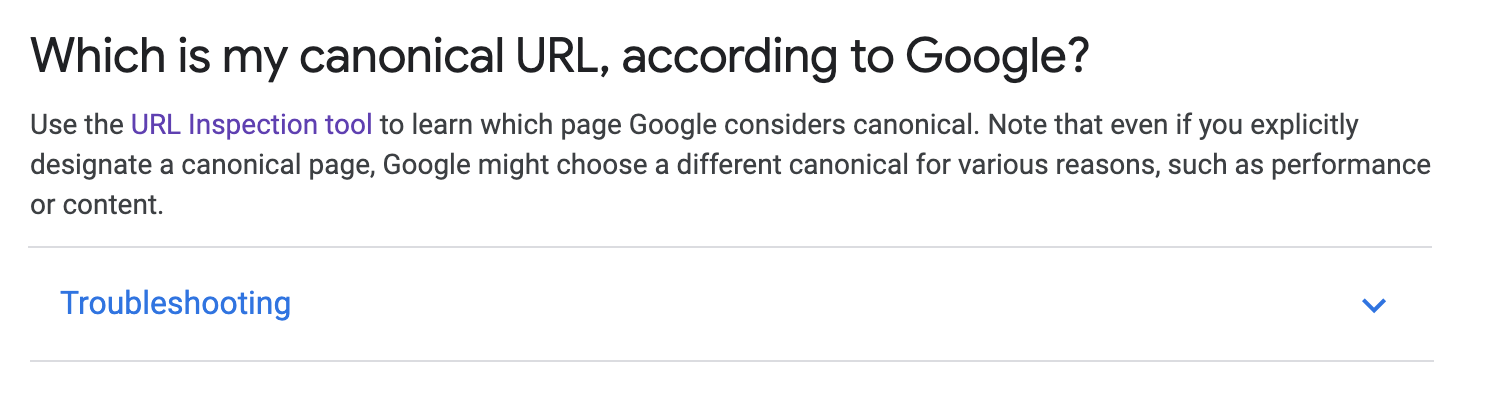
That tool I think can only be used on domains that you have managed in your webmaster tools. So I can't check the DEV or original URLs. I'd have to setup an experiment
Look at me learning so much about canonical URLs 😂
Note that even if you explicitly designate a canonical page, Google might choose a different canonical for various reasons, such as performance or content.
omenking
on 5 Aug 2020
I'm not entirely sure if this is the same issue, but it feels like it may be related, so I thought it made sense to raise here.
A DEV user wrote in wondering why the canonical URL on their post here - https://dev.to/sematext/a-step-by-step-guide-to-java-garbage-collection-tuning-2m1g is referencing itself as the canonical URL (i.e. the canonical points to https://dev.to/sematext/a-step-by-step-guide-to-java-garbage-collection-tuning-2m1g.

Other context:
The user was hoping to update their post and change the canonical URL to point to https://sematext.com/blog/java-garbage-collection-tuning/ but were hitting an error message saying canonical_url: has already been taken. ~I plan to write up another issue about this occurrence and what we can do to avoid false alarms like this. I'll come back and post a link to that issue shortly (here's a related link I want to keep handy in the meantime - https://github.com/forem/forem/issues/3363)~
Here's are 2 related issues:
 michael-tharrington
on 12 Aug 2020
michael-tharrington
on 12 Aug 2020
@michael-tharrington
It is recommended practice that when you create a blog article online that you create a self-referencing canonical URL. This prevents bad-parties from trying to set a canonical URL as the truth source in order to compete with your traffic.
Since this user first created their article on DEV, it makes sense that DEV would create a self-referencing canonical URL.
Why they can't update it is uncertain. I never experienced this when I retroactively updated an article.
I would say we would have to rule out of that person as maybe a duplicate article with the canonical URL set.
omenking
on 12 Aug 2020
Thanks @omenking — that is super helpful! Glad to know that the self-referencing canonical is standard practice.
Also I made a separate feature request to hopefully address the issue they faced when trying to update the canonical. Until that issue is fixed, I've advised them on how to get around the warning.
michael-tharrington
on 12 Aug 2020
Since this user first created their article on DEV, it makes sense that DEV would create a self-referencing canonical URL.
But that is not true. The original article at https://sematext.com/blog/java-garbage-collection-tuning/ was created first.
 otisg
on 12 Aug 2020
otisg
on 12 Aug 2020
@otisg my apologies, I should rephrase to say maybe you published the article first without setting the canonical url.
Lets keep future replies in this post https://github.com/forem/forem/issues/9759
omenking
on 12 Aug 2020
@benhalpern I'd love to see this fix. It's stopping many people from cross-posting on Dev.to.
 ahmadawais
on 10 Oct 2020
ahmadawais
on 10 Oct 2020
Hello, what is the status of this issue?
@benhalpern, @maestromac or @nickytonline
 catalinpit
on 9 Nov 2020
catalinpit
on 9 Nov 2020
Joining this party, I would appreciate the fix. 🙏
Canonical URLs are super important for SEO and we can't compromise it.
If I can help in any way let me know.
 idoshamun
on 23 Nov 2020
idoshamun
on 23 Nov 2020
As mentioned earlier, we are using canonical URLs correctly, and Google has been letting us know that.
Here is the canonical URL inspection for this URL: https://dev.to/100daysofcloud/use-vscode-debugger-when-working-with-aws-cdk-28b7
benhalpern
on 23 Nov 2020
Thanks @benhalpern for addressing this issue :)
idoshamun
on 23 Nov 2020
Yep, I am satisfied with that screenshot.
I believe we were never able to check ourselves so it did require someone on DEV's side to check what Google said it was resolving to
There's still the issue of /comments having their own URL with DEV and competing with the original article, though my gut is that a minor issue.
omenking
on 23 Nov 2020
Related issues
benhalpern
·
3Comments
 Gherciu
·
3Comments
Gherciu
·
3Comments
 miku86
·
3Comments
miku86
·
3Comments
 nickytonline
·
3Comments
nickytonline
·
3Comments
 szabgab
·
3Comments
szabgab
·
3Comments
Most helpful comment
To bring some clarity to this conversation.... the canonical tag _is_ in the body. This was discussed here. https://github.com/forem/forem/issues/5156
I think we should add a comment on the page to prevent further confusion.
If you run the page with service workers turned off...
You'll see that the canonical url is in the head, as dictated by
<%= content_for :page_meta do %>.The boolean here is that if service workers are running, we fetch the page as if it were "internal nav" because we already have fetched the "shell" from the local cache. No crawler will request this version of the page, it would only be used after a user has triggered service workers based on prior interactions.
I think the satisfaction of this issue would be to add a clear comment about this in the html.