Fmriprep: Masking with multiecho sequences can be too aggressive
After running fmriprep-unstable on some multiecho sequences, I noticed that there is some aggressive masking going on. This is most likely a tedana issue (see https://github.com/ME-ICA/tedana/issues/600), but I'm posting it here as well because it makes fMRIPrep kind of unusable for these sequences (which were tested out to recover ATL/OFC).
Using tedana 0.8.0 (from pip) results in more reasonable masking
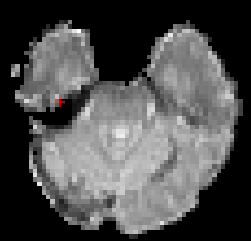
while using 0.9.0a1 (as in fmriprep-unstable), chunks of ATL and OFC are cut out
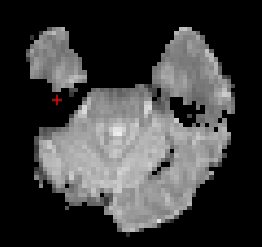
 mvdoc
mvdoc
All 9 comments
Just to point out that this is being discussed in https://github.com/ME-ICA/tedana/issues/617
mvdoc
on 20 Oct 2020
To be clear, is this the BOLD output or the BOLD reference? For single-echo data, we provide unmasked BOLD series + a BOLD mask.
From the perspective of consistency, I think I would prefer to have three outputs:
*_desc-preproc_bold.nii.gz- unmasked*_desc-brain_mask.nii.gz- mask of voxels in brain*_desc-tedana_mask.nii.gz- (or some other desc) mask of "good" data
I will post this over on the other thread, and hopefully not make a fool of myself.
 effigies
on 21 Oct 2020
effigies
on 21 Oct 2020
I need to double check whether the images I posted refer to the boldref or the bold data (I'll double check later today). I'm positive the problem affected the bold data files too, because the aggressive masking was evident both in the report and when I was computing tSNR.
mvdoc
on 21 Oct 2020
Now that I think about it, we still want as unmasked a reference image as we can get, anyway. Degradation of the reference may harm coregistration.
effigies
on 21 Oct 2020
To confirm, both the boldref and the bold are masked. This is what they look like for one of the ME3 sequences that I used.
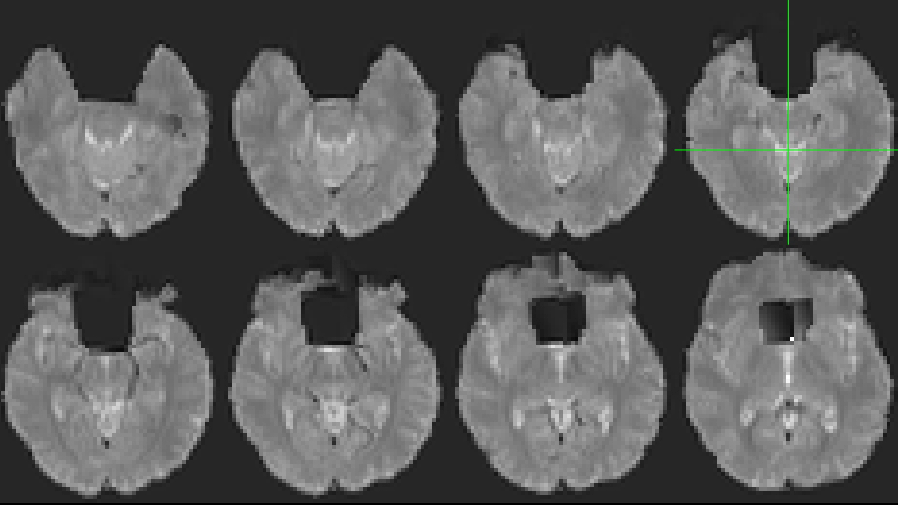
mvdoc
on 22 Oct 2020
While the lion's share of the issue is definitely on tedana's end (see ME-ICA/tedana#617), I've opened #2348, which proposes an idea of @emdupre's that may help.
 tsalo
on 16 Dec 2020
tsalo
on 16 Dec 2020
I'm curious about how the new masking utility I've put together in SDCFlows proper (sdcflows.utils.epimanip.epi_mask()) would work with these images.
could you give it a quick check @tsalo @mvdoc ?
 oesteban
on 17 Dec 2020
oesteban
on 17 Dec 2020
Thanks! I've only run a quick check with one of nilearn's fetchable datasets, and it looks like epi_mask is more liberal than nilearn's compute_epi_mask. Would the idea be to use epi_mask instead of the BET+Automask approach in init_skullstrip_bold_wf?
tsalo
on 17 Dec 2020
Thanks! I've only run a quick check with one of
nilearn's fetchable datasets, and it looks likeepi_maskis more liberal thannilearn'scompute_epi_mask. Would the idea be to useepi_maskinstead of the BET+Automask approach ininit_skullstrip_bold_wf?
Yes, I'm testing it with EPI and b=0 DWIs (EPI) and pretty happy so far (esp. for the speed/accuracy balance). The mask can be made tighter reducing (or removing) a final binary dilation step.
oesteban
on 17 Dec 2020
Related issues
 jawaltz
·
4Comments
oesteban
·
4Comments
jawaltz
·
4Comments
oesteban
·
4Comments
 ptubiolo37
·
4Comments
ptubiolo37
·
4Comments
 asqwerty666
·
3Comments
asqwerty666
·
3Comments
 jandrushko
·
4Comments
jandrushko
·
4Comments