Fluent-bit: Tail DB.Sync lead to multi INPUT stuck
Bug Report
Describe the bug
If config more than one INPUT with DB.Sync(Full) DB file stop update and INPUT stuck when rotate happen, and recover work when log rotate next time.
When stuck happen only one INPUT can be process.
Set all of INPUT DB.Sync to Off is work prefect.
To Reproduce
create 5 INPUT config
[INPUT]
Name tail
Tag a
Path /a.log
DB /a.db
Mem_Buf_Limit 5MB
Path_Key path
DB.Sync Full
Refresh_Interval 5
[INPUT]
Name tail
Tag b
Path /b.log
DB /b.db
Mem_Buf_Limit 5MB
Path_Key path
DB.Sync Full
Refresh_Interval 5
[INPUT]
Name tail
Tag c
Path /c.log
DB /c.db
Mem_Buf_Limit 5MB
Path_Key path
DB.Sync Full
Refresh_Interval 5
....
create 5 instance to write log
logger=logging.getLogger("file")
logger.setLevel(logging.DEBUG)
file_handler=logging.handlers.RotatingFileHandler('/file', mode='a', maxBytes=20*1024*1024, backupCount=2, encoding=None, delay=0)
file_formatter=logging.Formatter(
'{"time":"%(asctime)s", "name": "%(name)s", "level": "%(levelname)s", "message": "%(message)s"}'
, datefmt='%Y-%m-%d %H:%M:%S')
file_handler.setFormatter(file_formatter)
logger.addHandler(file_handler)
rnd = uuid.uuid4()
while True:
logger.debug(rnd)
time.sleep(0.0001)
Expected behavior
Screenshots
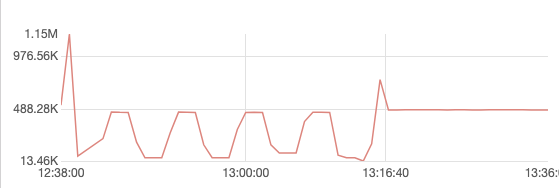
Process Message rate compare DB.Sync Full / Off
Your Environment
- Version used: v1.14.0 @560c4e3
- Server type and version: linux
- Operating System and version: Centos 7.4
 mengskysama
mengskysama
All 9 comments
thanks for reporting the issue and providing a test case.
After some fixes, I am able to write 5 million messages (1 million to a different file) that are rotated on high frequency (250KB limit).
I am still fixing some corner-cases related to inotify(7)... work in process.
 edsiper
on 26 May 2020
edsiper
on 26 May 2020
We're seeing an issue that is sort of like this, but we only have one INPUT stanza. However, we'll see problems when a file gets rotated, and won't see any of the rotated file get sent to our SPLUNK instance until the next file rotation. We aren't setting DB.sync, so I guess we're getting the default of FULL for that?
 Starblade42
on 5 Jun 2020
Starblade42
on 5 Jun 2020
@Starblade42 fixing the db.sync perf issue I found some issues with corner cases on rotated files. The fixes are in place and should be available on the next v1.4.6 (3-4 days)
edsiper
on 5 Jun 2020
Hi @edsiper,
Looking at our logs and taking a deeper dive into the code, I think it all starts with fluentbit missing a rename event.
[Edit: ignore everything below, apparently while watches are created by specifying a path, they are inode based, so the text below doesn't make sense]
[Edit 2: apparently I tried to understand the behavior of 1.4.2 and 1.4.5 by looking at code you had modified just prior. Oops!]
It will keep watching the main file via watch_fd, but fd will point to the renamed file (since the inode stays the same). As long as the main file is being written to, it will receive file change notifications and keep reading the rotated file, allowing that to be read completely.
Based on the Refresh_Interval, the new main file will eventually be discovered and registered, but receive the same watch_fd as the previous file entry. Since it's appended to a list, the inotify events will continue to go to the previously registered file entry, and so this new file still won't get read.
Eventually, the new main file will get rotated as well. fluentbit isn't busy at this point anymore since it just had to finish reading a rotated file. It receives the rename event, and unwatches the main file name (I suspect that breaks the watch_fd for the second, blocked entry, too), and watches the rotated file name instead (which will eventually get deleted, allowing this file entry to get removed). The blocked entry has a broken watch_fd, and so never sees any events. I'm wondering whether it will ever get cleaned up, actuallly.
Because of the rename, fluentbit discovers the new main file, and registers it successfully, so things are okay again until another rename is missed.
Quite possible that I got some details wrong since I changed my conclusions probably a dozen times by now, but I'm curious whether this makes sense to you and will be addressed by 1.4.6.
Thank you!
 DennisKehrig
on 5 Jun 2020
DennisKehrig
on 5 Jun 2020
Hi @edsiper, an update from our side. To be clear, I'm not associated with @mengskysama, so this issue may be different, but it sounds very similar.
We have changed the value of /proc/sys/fs/inotify/max_queued_events from 16384 to 131072. It looks like we are losing files less often now under sustained high load. Instead of losing every third file, 2-10 files in a row get forwarded intact.
My understanding is that this queue limit applies across watched files, and so when you receive IN_Q_OVERFLOW, you cannot determine which file the events were lost for ("wd is -1 for this event").
I think the plugin needs to not just log IN_Q_OVERFLOW at debug level, but log it at info level (setting fluent-bit to debug level produced way too much data in our case, but this is an important event to hear about, so a higher level is justified in my opinion), and also act on it.
When an IN_Q_OVERFLOW event is received, the plugin needs to look at each watched file and check:
- Was the file deleted?
- Was it renamed?
- Were there writes to the file?
If any of the above is true, it should act as if it had received a corresponding explicit event.
Otherwise the result is an inconsistent state where at the very least it reads from a renamed file but reports the data as coming from the original file name. For us, the bigger problem seems to be that it also doesn't pick up on the fact that there's a new file that needs to be forwarded.
Thanks for considering the above!
DennisKehrig
on 10 Jun 2020
@DennisKehrig
We just addressed many rotation related issues that were reproducible "sometimes" under specific load scenarios, hopefully our tests are passing after several rounds without problems. So the detection problem is solved and already is part of v1.4.6 release:
https://fluentbit.io/announcements/v1.4.6/
I will take a look at the IN_Q_OVERFLOW issue mentioned. How many files are you monitoring and what's the estimated data rate (lines per second) being written to each file ?
edsiper
on 11 Jun 2020
@DennisKehrig I will close this issue since the conversation switched to a non DB.Sync topic. Can you open a new ticket so we can continue the conversation there ?
Closing this since the main issue is fixed.
edsiper
on 11 Jun 2020
@edsiper thansk!
Testing 1.4.6 in my environment it work well now.
mengskysama
on 12 Jun 2020
@edsiper Thanks for the update! I was able to test 1.4.6 today. The situation is greatly improved! We still see that occasionally, when we would expect the file name to end in .1, it continues to use the original file name, but it doesn't drop the following file anymore, all data is transmitted. That's a fantastic improvement.
Also thanks for adding rotation and inotify logging output at info level, that is very helpful. It shows that fluent-bit does actually see the rotations above. One explanation could be that by the time the file was rotated it had already read all the data in the original file, but given the load that is unlikely.
Not really important for us though, as long as all data makes it, this is great. Thank you!
DennisKehrig
on 15 Jun 2020
Related issues
 rjshrjndrn
·
43Comments
rjshrjndrn
·
43Comments
 hdiass
·
26Comments
hdiass
·
26Comments
 duythinht
·
26Comments
duythinht
·
26Comments
 marckamerbeek
·
34Comments
marckamerbeek
·
34Comments
 fujimotos
·
132Comments
fujimotos
·
132Comments
Most helpful comment
@Starblade42 fixing the db.sync perf issue I found some issues with corner cases on rotated files. The fixes are in place and should be available on the next v1.4.6 (3-4 days)