Etcd: Why after space compaction and defrag operator must clear alarms by hand?
subj,
I understood why some node can raise up alarm and stop working, but why whole cluster will be in RO mode, when one node have luck of free space?
Even, okay. I did compaction, did defrag, but why alarm which automatically make cluster RO, not return cluster to RW mode after that?
What kind of half-measures?
 Nefelim4ag
Nefelim4ag
All 6 comments
@Nefelim4ag if your cluster loses quorum it will go into a read-only state, this does require manual interaction. I think the best countermeasure here is to make sure that you have enough members to sustain a node failure. How many nodes are in your cluster when it was healthy?
 hexfusion
on 20 Aug 2018
hexfusion
on 20 Aug 2018
Is it do defrag operator definite time is a good idea?
 piaoyu
on 27 Aug 2018
piaoyu
on 27 Aug 2018
Before and After defarg disk sync
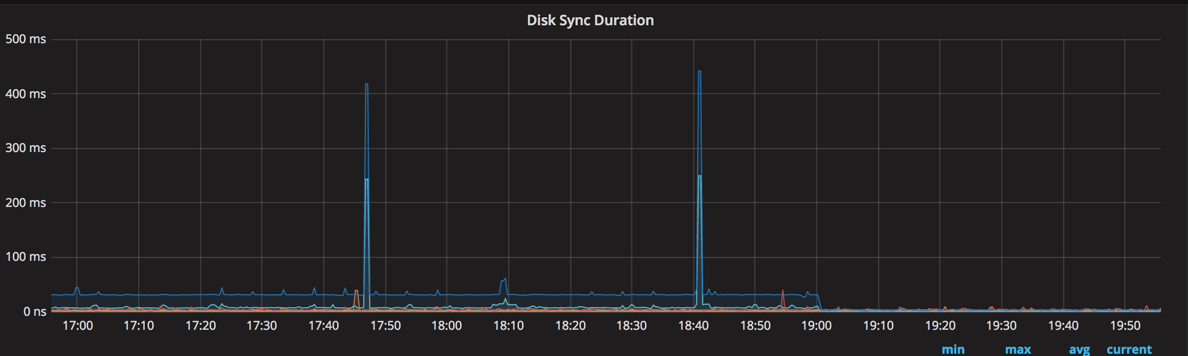
piaoyu
on 27 Aug 2018
@hexfusion, i talk about:
https://github.com/coreos/etcd/blob/61354ff8ede7dde7839e0df987f37cda931fd740/Documentation/op-guide/maintenance.md#space-quota
i.e. cluster not lose quorum, it's enough that one node of 3 get alarm state.
Or i miss something?
Nefelim4ag
on 27 Aug 2018
@Nefelim4ag I am sorry I misunderstood you. You are correct once the cluster hits the NOSPACE alarm it will not recover without a manual call against the Maintenance API to DEACTIVATE.
I see your point that you have only a single node in the cluster that for whatever reason was not compacted/defragged why does this mean the whole cluster gets NOSPACE alarm. I think the main thing here is the code wants to protect the cluster from data corruption. While this is not optimal in your situation the more complex we make this mechanism the greater a chance for a serious problem on the data level. This is how I read it.
I am going to take a deeper look into this though and see what types of options might be possible for at least a self-healing NOSPACE alarm. So, for example, you compact and defrag the node afterwards etcd checks the store for corruption if all nodes pass we force an election. If the election is OK then NOSPACE alarm is disabled because we have a safe and sane store. For CORRUPT alarm I feel this would not be possible for now and a node with corrupt data needs to bring everything to a halt so that engineers can manually verify.
hexfusion
on 28 Aug 2018
Alarm is another apply command in Raft. It's triggered by etcd quota layer and replicated over consensus. Since compact and defrag are requested manually by an operator, alarm deactivation should be done so in an explicit way. etcd does not track defrag effects. Operator should do.
 gyuho
on 7 Sep 2018
gyuho
on 7 Sep 2018
Related issues
 primeroz
·
3Comments
gyuho
·
4Comments
primeroz
·
3Comments
gyuho
·
4Comments
 cheyang
·
3Comments
cheyang
·
3Comments
 kghost
·
4Comments
kghost
·
4Comments
 el10savio
·
4Comments
el10savio
·
4Comments