Esmvaltool: Implement perfect model test for ClimWIP
Description
A basic version of ClimWIP was recently implemented in ESMValTool via #1648. We would like to add some functionality to this diagnostic. In particular, we would like to add a perfect model test.
@lukasbrunner can you please edit this issue and elaborate on what the perfect model test should do?
Would you be able to help out?
We might be able to make some time for this during the upcoming workshop (#1866), but it depends on whether we want to prioritize this feature, so any insights into this would be helpful.
 Peter9192
Peter9192
All 11 comments
Perfect model test: the idea
(to keep it conceptually simple I will only talk about performance weighting here)
A core part of the model weighting is the transition from model-observation distances to model weights. Theoretical background can, e.g., be found in Knutti at al. 2017, in particular we use formula (1) described there:
https://github.com/ESMValGroup/ESMValTool/blob/5f0d04a2b165dc2a216206691f56a2ccfc6bd66b/esmvaltool/diag_scripts/weighting/climwip.py#L401
The sigma parameter adjusts at what point models get strongly down-weighted for their (bad) performance. We want this parameter to reflect our confidence in the weighting. If it is very large all models will receive equal weighting:
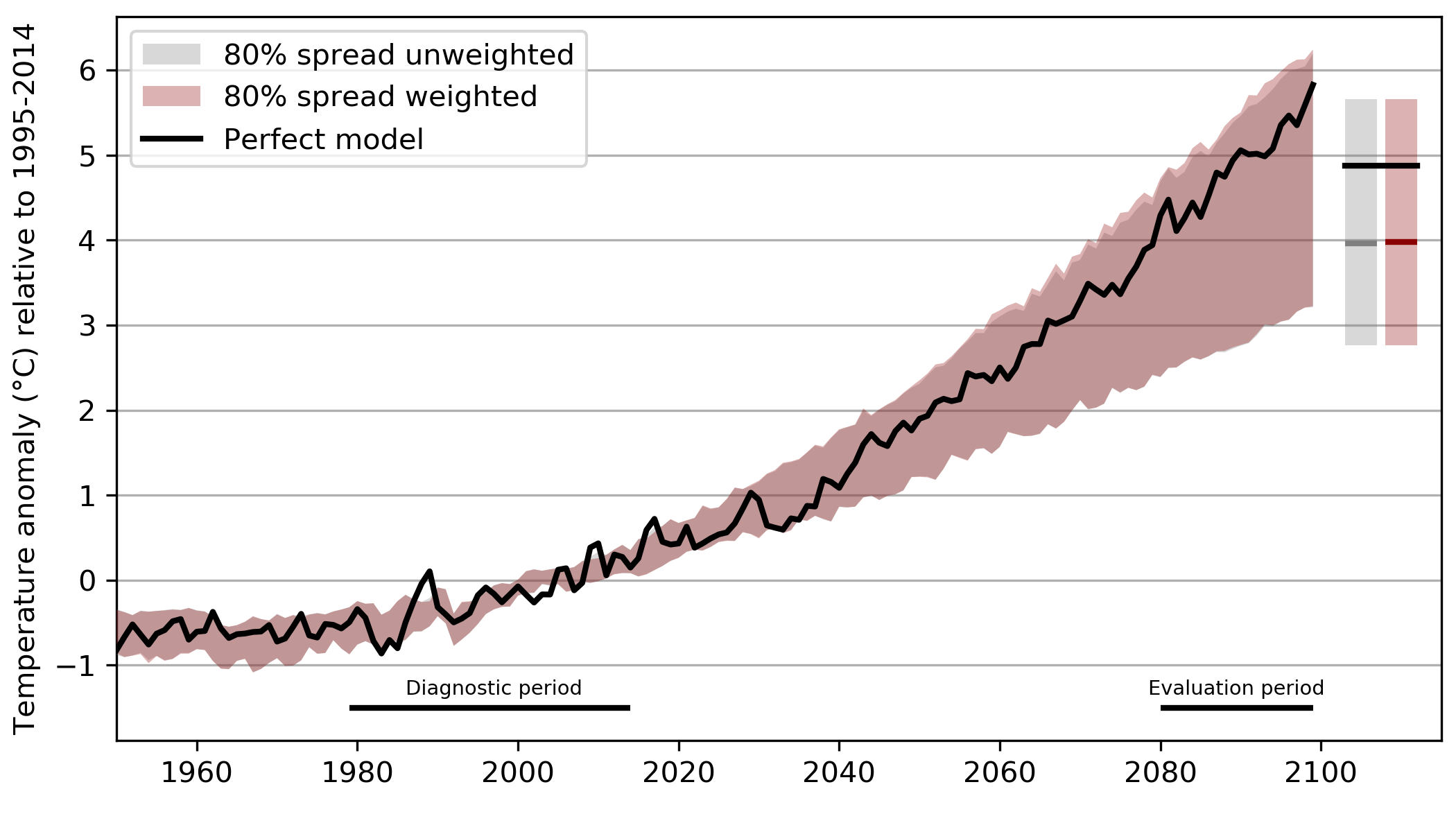
if it is very small a few models will get all the weight and the weighting has the risk of being overconfident:
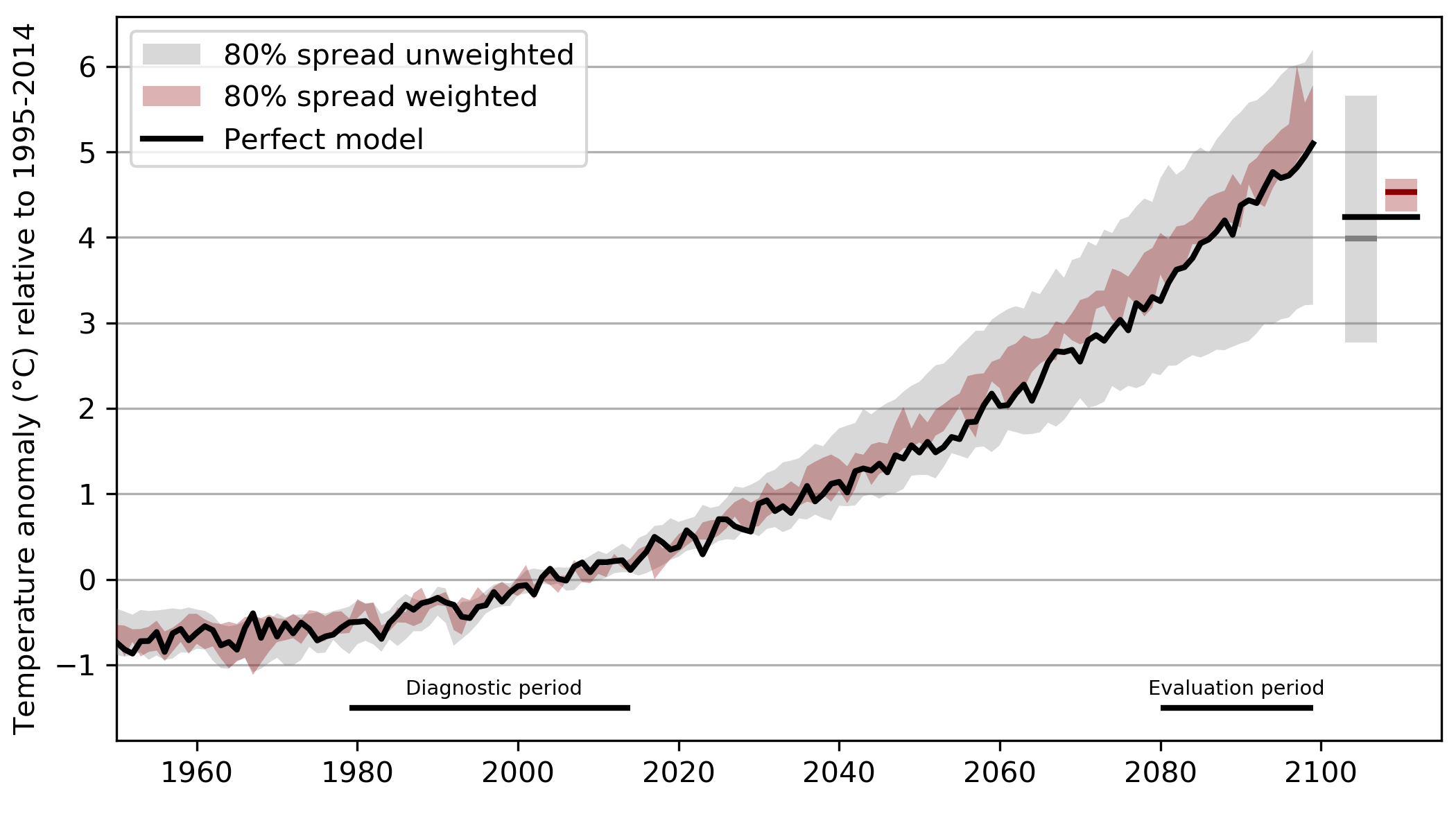
We consider the weighting to be overconfident if the spread in the future (evaluation period) is too narrow and does not reflect the actual probability. However, since we do not have observations in the future this can not be evaluated using real observations. Therefore a perfect model test is needed (note that this has been used under different names: imperfect model test, pseudo-observation test, leave-one-out test) to calibrate the sigma value to a reasonable value.
The basic idea is not use real observations but instead remove one model from the ensemble in turn. The performance is now calculated as the other models distance to this "perfect model". Future this case the effect of the weighting can be evaluated against the "truth" (i.e., the perfect model) in the future.

 lukasbrunner
on 10 Nov 2020
lukasbrunner
on 10 Nov 2020
Perfect model test: practical considerations
Apart from the theory presented in my comment above, the details of the perfect model test can take different forms and I think it would be good to keep it flexible, possibly allowing different ways of estimating sigma.
What we do in the current implementation: the sigma is chosen in a way that the perfect model falls within the weighted 80% range for 80% of the cases (c.f. first to figures in the comment above). This could be the first try, but I'm also not committed to this and open for other suggestions.
Open questions/issus:
- [ ] Should the perfect model test be used for both sigmas (@ruthlorenz I think we need to discuss this again)
- [ ] Should the sigmas be calculated on the fly within the climwip recipe or separately (maybe relevant: the calculation is quite expensive and I expect in most cases sigmas will still be set)?
- [ ] We need another test recipe (maybe the one @ruthlorenz is currently working on #1850) because the perfect model test needs at least ~20 models to work
- [ ] we probably need #1849 for this but I can work on this in the next couple of days
- [ ] other points?
lukasbrunner
on 10 Nov 2020
Would you be able to help out?
We might be able to make some time for this during the upcoming workshop (#1866), but it depends on whether we want to prioritize this feature, so any insights into this would be helpful.
@Peter9192 I'm happy to discuss this and for any help. Maybe we can talk a couple of minutes tomorrow.
lukasbrunner
on 10 Nov 2020
* Should the sigmas be calculated on the fly within the climwip recipe or separately (maybe relevant: the calculation is quite expensive and I expect in most cases sigmas will still be set)
I envision we can make it a separate diagnostic script (perhaps calling some shared functions?). In the recipe we can make it a separate diagnostic section, and use that as an ancestor for the weighting diagnostic. You can then easily skip that step (or not). Note that it's possible to run like esmvaltool run .... --diagnostics climwip/calibrate_sigmas to specify individual tasks that should be run. The only questions is whether we want to pass on the values between the diagnostics (automated) or specify them manually.
note that this has been used under different names: imperfect model test, pseudo-observation test, leave-one-out test
Shall we call it 'calibrate_sigmas' in the recipe?
Peter9192
on 10 Nov 2020
Hey @Peter9192 !
We had a really fruitful discussion about the theoretical backgrounds of the performance and independence shape parameter (sigma) calibration today. Now I'm trying to come up with how to best structure the code. There I could really use your help from a software engineering perspective. Here is the starting position:
the calculation of independence_sigma and performance_sigma is independent from each other BUT the independence_sigma calculation needs to come first as the performance_sigma calculation (depending on the use preference) needs the independence_sigma
the independence_sigma calculation needs the overall_independence variable as input, this means one of two things:
- if we calculate it in a separate diagnostic we will need to repeat most of the calculation done in the current main script
- if we calculate it in the main script we could reuse the variable calculated there
the performance_sigma calculation needs the performance_contributions variable AND the independence_sigma (or probably even better the independence_weights) variable as input. Again two points:
- IF we calculate the independence_sigma in the main script we need to do the same for the performance_sigma (as it needs its output)
- otherwise we could calculate it in a third (separate) diagnostic script
I can see the reason for doing each of them in a separate diagnostic as I assume having it independent from the main script is cleaner. But in terms of code performance and potential code duplication calling two functions from the main script seems preferable to me. What do you think?
lukasbrunner
on 19 Nov 2020
I'm not sure if it makes sense to put this here but I started writing some skeleton pseudo code to see if everything works out like we thought. I'm putting this here in case it is helpful. (it became way too long ':) )
def calibrate_independence_sigma(overall_independence: 'xr.DataArray', force: bool = False,
**kwargs : dict) -> float:
"""
Parameters
----------
overall_independence : array_like, shape (N, N)
force : bool, optional
If force is False (default) this function will raise an error if the
independence_contributions are selected such that that no clear
separateion between dependent and independent models is possible. Set
to True (not recommendet) to scip this check.
Returns
-------
independence_sigma : float
"""
# do stuff
return independence_sigma
def remove_related_models(overall_performance, overall_independence, subset_size=20):
"""
Remove (set to nan?) the models closest related to the perfect model for each perfect model
so that there are the subset_size most independent models remaining
Alternatively: remove random models to test sensitivity
"""
# do stuff
return overall_performance_subset
def evaluate_future(weights_sigma, target, metric):
"""
For each perfect_model and each sigma compare the weighted mean to the 'truth'
# NOTE: for each perfect model at least one model (the perfect model itself) but
potentially more models (see remove_related_models) should have weight nan,
this needs to be ignored (probably happens automaticall but just to keep in mind)
"""
if metric == 'TEST_METRIC_1':
return TEST_METRIC_1 # optimal sigma
if metric == 'TEST_METRIC_2':
return TEST_METRIC_2
# ...
def calibrate_performance_sigma(
models: dict, performance_contributions: list, variable_group_target: str
overall_independence: 'xr.DataArray', independence_sigma: float,
metric: str,
use_independence_weighting: bool = True **kwargs: dict):
# --- this is equivalent to climwip.py but with perfect models as reference instead of obs ---
for variable_group in performance_contributions:
logger.info('Reading model data for %s', variable_group)
datasets_model = models[variable_group]
model_data, model_data_files = read_model_data(datasets_model)
# NOTE: it would probably be good to vectorize this
for perfect_model in models:
performance = calculate_performance(model_data, perfect_model)
performances[variable_group][perfect_model] = performance
overall_performance = compute_overall_mean(performance, performance_contributions) # (N, N) matrix
if cfg['combine_ensemble_members']:
# this combines both dimensions -> I think this is what we want!!
overall_performance, groups_performance = combine_ensemble_members(
overall_performance)
# --- from here it is not equivalent to climwip.py any more ---
# NOTE: what do we do here if 'combine_ensemble_members' is False?
overall_performance = remove_related_models(overall_performance, overall_independence)
# NOTE: it would probably be good to vectorize this
for performance_sigma in performance_sigma_list: # we can probably hardcode this list?
for perfect_model in models:
if use_independence_weighting:
weights_sigma = calculate_weights(
overall_performance.sel(perfect_model=perfect_model),
overall_independence,
performance_sigma, independence_sigma) # (N, N) matrix
else:
weights_sigma = calculate_weights(
overall_performance.sel(perfect_model=perfect_model),
None, performance_sigma, None) # (N, N) matrix
target = models[variable_group_target]
if cfg['combine_ensemble_members']:
target = models[variable_group_target]
model_data, model_data_files = read_model_data(datasets_model)
performance_sigma = evaluate_future(weights_sigma, target, metric)
return performance_sigma
def calibrate_sigmas(
overall_independence: 'xr.DataArray', force_independence: bool = False,
models: dict, performance_contributions: list, variable_group_target: str,
use_independence_weighting: bool = True,
**kwargs: dict):
independence_sigma = calibrate_independence_sigma(overall_independence, force_independence)
performance_sigma = calibrate_performance_sigma(
models, performance_contributions, variable_group_target, overall_independence,
independence_sigma, metric, use_independence_weighting=True, **kwargs)
# potental cross checks, sanity tests, perfect model skill calculation
But in terms of code performance and potential code duplication calling two functions from the main script seems preferable to me. What do you think?
I think I agree. We can start with writing everything in the main script. If we strive to make the code as modular as possible, we can also easily refactor it into separate diagnostics later. One idea in this respect is that we can also add a function to easily load the intermediate files.
With respect to the implementation, I was thinking of a slightly different approach. I'm curious to hear your thoughts on this.
for performance_sigma in performance_sigma_list: # we can probably hardcode this list?
This hard-coded brute-force approach is probably easiest to implement indeed, but I wonder if we can somehow be a bit smarter about this. E.g. could we use something like scipy minimize? Also compare with scipy brute force.
This is just a very quick top-of-my-head idea of what that could look like:
def performance_score(sigma, ...):
"""Return the result of 'evaluate_future' for a single sigma."""
weights = calculate_weights(sigma, ...) # for perfect_model in models ?
score = evaluate_future(weights, ...)
return score
sigma_performance = scipy.minimize(performance_score, x0=0.5)
What is not clear to me from your code snippet is how you go from one weight per perfect model to an overall evaluation of a certain sigma value.
Peter9192
on 20 Nov 2020
Yes I've played around with minimize before and also with some gradient descent ideas to be smarter about this but nothing came out of it at the time. I can definitely have a look at this. I would start with the surrounding functionality next week and keep the actual skill calculation until the end.
About our last point: yes I had not included that in the pseudo code yet. The idea was that the evaluate_future function would call those and allow easy implementation of additional skill scores. We decided on two that we want to try (basically: optimizing mean skill and optimizing confidence - i.e., uncertainty ranges). This is where the usage of scipy.minimize might make things more complicated...
lukasbrunner
on 21 Nov 2020
Okay I see. I like the idea of being able to optimize either, or both. If you want to balance both criteria, you will have to think about how to that anyway, right? But once you know that, you might as well use scipy to do it, e.g. something like this.
Personally I feel that thinking about it in this way helps to make the code more modular. Perhaps as a compromise we can implement the hardcoded 'brute force' method as a function?
def optimize_brute(...):
"""Try multiple sigmas and return the best result."""
sigmas = [...]
best_score = 1000 # just a random high number
best_sigma = sigmas[0]
for sigma in sigmas:
mean_score = ...
uncertainty_score = ....
combined_score = ....
if combined_score < best_score:
best_score = combined_score
best_sigma = sigma
return best_sigma
The idea was that the
evaluate_futurefunction would call those and allow easy implementation of additional skill scores
It would be very useful to know what those will look like, because then we will know what exactly we need to pass to the optimization functions. And hence to evaluate the code structure.
Peter9192
on 23 Nov 2020
I can see either the scipy or the manual brute force working! Thanks a lot for your input @Peter9192!! I think the performance sigma calibration is by far the more complex part of the two, so I guess it makes sense to try and get this to run during the workshop. (fingers crossed) @ruthlorenz and i will discuss this tomorrow and get going :)
One thing I was wondering about: it might make sense to implement the really heavy lifting (basically the double loop over the perfect models and the sigmas) in cython? I don't have any experience with it but is seems that this could be a case where the performance increase could be pay off?
lukasbrunner
on 23 Nov 2020
I don't have experience with cython either. I'd say let's start with normal python, see if we can use scipy for managing the optimization (outer loop), and go from there in making it more efficient. I'm not entirely sure, but the inner loop doesn't seem to be too complex, so maybe we could just try to implement it efficiently in numpy or scipy? Something along the lines of the distance matrix for the independence?
Peter9192
on 23 Nov 2020
Related issues
 jvegasbsc
·
4Comments
lukasbrunner
·
4Comments
jvegasbsc
·
4Comments
lukasbrunner
·
4Comments
 bjlittle
·
5Comments
bjlittle
·
5Comments
 nielsdrost
·
3Comments
nielsdrost
·
3Comments
 BenMGeo
·
5Comments
BenMGeo
·
5Comments