需求
egg暴露 graphql 服务
GraphQL使用 Schema 来描述数据,并通过制定和实现 GraphQL 规范定义了支持 Schema 查询的 DSQL (Domain Specific Query Language,领域特定查询语言,由 FACEBOOK 提出。

传统 web 应用通过开发服务给客户端提供接口是很常见的场景。而当需求或数据发生变化时,应用需要修改或者重新创建新的接口。长此以后,会造成服务器代码的不断增长,接口内部逻辑复杂难以维护。而 GraphQL 则通过以下特性解决这个问题:
- 声明式。查询的结果格式由请求方(即客户端)决定而非响应方(即服务器端)决定。你不需要编写很多额外的接口来适配客户端请求
- 可组合。GraphQL 的查询结构可以自由组合来满足需求。
- 强类型。每个 GraphQL 查询必须遵循其设定的类型才会被执行。
也就是说,通过以上的三个特性,当需求发生变化,客户端只需要编写能满足新需求的查询结构,如果服务端能提供的数据满足需求,服务端代码几乎不需要做任何的修改。
这里不会过多介绍 GraphQL 的概念,而会着重于确定如何通过 eggjs 来搭建 GraphQL 查询服务。
技术选型
使用 GraphQL Tools配合 eggjs 完成 GraphQL 服务的搭建。 GraphQL Tools 建立了一种 GraphQL-first 的开发哲学,主要体现在以下三个方面:
- 使用官方的 GraphQL schema 进行编程。 GraphQL Tools 提供工具,让你可以书写标准的 GraphQL schema,并完全支持里面的特性。
- schema 与业务逻辑分离。 GraphQL Tools 建议我们把 GraphQL 逻辑分为四个部分: Schema, Resolvers, Models, 和 Connectors。
- 为很多特殊场景提供标准解决方案。最大限度标准化 GraphQL 应用。
我们也会使用 GraphQL Server 来完成 GraphQL 查询语言 DSQL 的解析。
同时我们会使用 dataloader 来优化数据缓存。
使用 graphql-tag 来书写并解析graphql的schema。
这些我们都会集成到 (egg-graphql)[https://github.com/eggjs/egg-graphql] 插件中。
编写方式
目录结构

跟 controller 平行有个 graphql 目录用来编写 graphql 服务
代码
根据 GraphQL Tools 的建议,我们把 GraphQL 逻辑分为四个部分: Schema, Resolvers, Models, 和 Connectors
schema.graphql用于编写 graphql 的 schemaconnector.js编写 connector 逻辑,主要是跟数据库之间的侨接Resolvers编写对每个 query 的 resolver 逻辑。
> 注意, Resolver 可能会通过app.connector.xxx引用其他 graphql 类型下的connector。Models如果某个 graphql 服务跟orm框架对接,这个 Models 就是定义数据模型的 model
之后应用会加载 graphql 目录下的所有服务,并使用GraphQL Tools 的 makeExecutableSchema进行处理后挂载到app.schema上。
并且将所有服务的connector挂载到app.connector下面。
服务暴露方式
暴露一个路由专门处理 graphql 服务。并针对这个路由封装一个 graphql 的 service,参考 https://github.com/eggjs/egg-graphql/pull/1 的实现。
例子
https://github.com/eggjs/egg-graphql/tree/in/test/fixtures/apps/graphql-app
对 egg 框架的要求
目前没有,可以讨论下是否把这种加载方式集成到egg-loader中。
 jtyjty99999
jtyjty99999
All 52 comments
Good
 linguofeng
on 27 Feb 2017
linguofeng
on 27 Feb 2017
顶,反正我现在是rest api有点多=。=
 luicfer
on 27 Feb 2017
luicfer
on 27 Feb 2017
@fengmk2 @popomore 这个看下?
jtyjty99999
on 27 Feb 2017
加载的时候就按 schema 分好了(其实是 resolver,后面都叫 resolver),具体的 schema 内容 可能还会分模块,所以我觉得不需要太局限,使用者可以将 schema 都放到一个目录中。
然后我们就定义一个目录存放 resolver,还要考虑如何在 resolver 中获取 ctx,需要调用 db。
[graphql-server] 已经支持 koa 了,我们只需要将 schema 定义好给他就好了。
 popomore
on 27 Feb 2017
popomore
on 27 Feb 2017
@popomore 嗯,目前就是使用的graphql-server
jtyjty99999
on 27 Feb 2017
@jtyjty99999 我没看到 connector 的逻辑,resolverMap 就可以直接调用数据库了
popomore
on 27 Feb 2017
还有一些不解,之前对 graphql 的了解不是很多,他是按什么来路由规则的,如何根据请求映射到具体的 schema,有没有调用的例子看看?
popomore
on 27 Feb 2017
@popomore 有这么个例子是用这个模式写的 https://github.com/apollographql/GitHunt-API
jtyjty99999
on 27 Feb 2017
这个看了, resolverMap 上从 context 上获取 model,然后 model 调用 connector。
对于我们来说,db 层是另外一套,所以只要 resolverMap 中注入的的方法能获取到 ctx 就可以调用 db 了。
popomore
on 27 Feb 2017
@popomore 那这个意思是说,即使存在connector层,也不能跨组件调用,必须使用ctx直接调用db?(比如文章的connector要查询用户信息,不能走用户的connector,而需要走db.user.find?)
jtyjty99999
on 27 Feb 2017
恩,grapghql 感觉应该是薄薄的一层路由,具体的业务还是应该封装到 service
popomore
on 27 Feb 2017
这个到时估计还要测测性能
popomore
on 27 Feb 2017
到时候把用这个和用restful风格写出来的接口做下对比
jtyjty99999
on 27 Feb 2017
这个看了, resolverMap 上从 context 上获取 model,然后 model 调用 connector。对于我们来说,db 层是另外一套,所以只要 resolverMap 中注入的的方法能获取到 ctx 就可以调用 db 了。
我的理解,connector更多地是service层的角色,主要是利用dataloader来做取数优化,db相关的操作还是放到proxy比较好。
 luckydrq
on 27 Feb 2017
luckydrq
on 27 Feb 2017
附一个基于MySQL等ralational database的dataloader优化实现:https://github.com/luckydrq/rdb-dataloader
luckydrq
on 27 Feb 2017
@luckydrq 我感觉 @popomore 的意思应该是 connector 的角色跟 service 是有一些重复的
jtyjty99999
on 27 Feb 2017
@jtyjty99999 给个例子?正文说完,我还是不知道到底能从 graphql 取到怎样的数据。
 fengmk2
on 27 Feb 2017
fengmk2
on 27 Feb 2017
他的用法还需要客户端,API 应该不需要手写的,不过是应该给下应用代码。
fengmk2 notifications@github.com于2017年2月28日 周二00:09写道:
@jtyjty99999 https://github.com/jtyjty99999 给个例子?正文说完,我还是不知道到底能从
graphql 取到怎样的数据。—
You are receiving this because you were mentioned.Reply to this email directly, view it on GitHub
https://github.com/eggjs/egg/issues/468#issuecomment-282765132, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AAWA1bJwhwoR5kjra1aWpU-0NfeF1P0Nks5rgvVMgaJpZM4MMthY
.
popomore
on 27 Feb 2017
@fengmk2
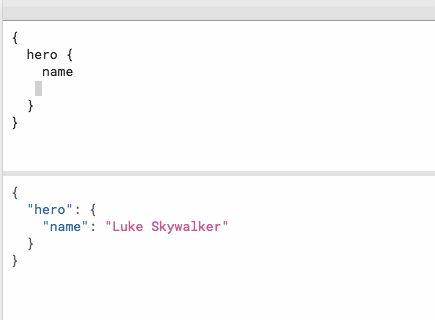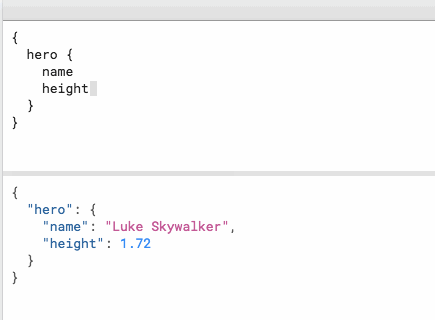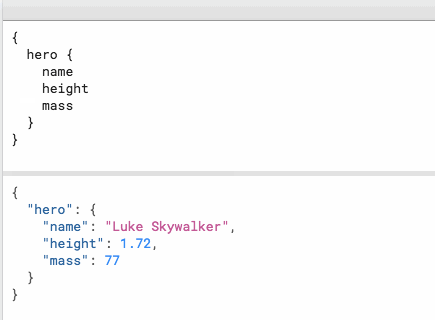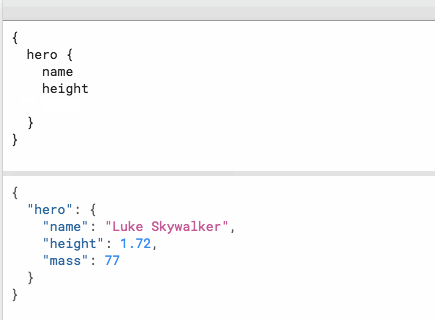
jtyjty99999
on 28 Feb 2017
mark
 mericmo
on 28 Feb 2017
mericmo
on 28 Feb 2017
@mericmo 不要发表 mark 这样的评论,想关注的话,右边 Notifications 有个 subscribe

 atian25
on 28 Feb 2017
atian25
on 28 Feb 2017
可以讲讲GraphQL如何进行鉴权操作~
 okoala
on 28 Feb 2017
okoala
on 28 Feb 2017
还有单元测试这块,graphql-tools 本身提供了一些 mock 方法也需要适配到 egg 的测试体系里吧 ~
okoala
on 28 Feb 2017
业务上正准备用graphql,希望egg对其的集成可以让开发更加方便地使用graphql, 赞, @jtyjty99999
 xiaoji121
on 1 Mar 2017
xiaoji121
on 1 Mar 2017
可以讲讲GraphQL如何进行鉴权操作~
@okoala 对于鉴权的部分,从设计上我们确实希望是有统一的一层做鉴权,但是由于graphQL本身的这种1个field1个resolver的设计,我目前能想到的鉴权代码就是散落在各个resolver里的,不知道你有没有啥最佳实践?
luckydrq
on 1 Mar 2017
能否把 resolver 映射到 controller 上,resolverMap 变成层级调用,这样就能加中间件了。
popomore
on 1 Mar 2017
@luckydrq 之前跟 @xiaoji121 沟通,鉴权部分按照 graphql 的推荐是可以直接抽出来的,可以通过中间件的方式拦截掉 http://graphql.org/learn/authorization/
jtyjty99999
on 1 Mar 2017
@popomore 有没有伪代码看下什么意思?
jtyjty99999
on 1 Mar 2017
@luckydrq 之前跟 @xiaoji121 沟通,鉴权部分按照 graphql 的推荐是可以直接抽出来的,可以通过中间件的方式拦截掉 http://graphql.org/learn/authorization/
@jtyjty99999 这篇文章看过,它的意思只是把鉴权接口封装一下,但是resolver里面还是得调用的。我的意思是逻辑分层上直接挡在前面,resolver只负责纯粹的取数,这样更clean。不过目前看来只是美好的愿景而已。
luckydrq
on 1 Mar 2017
@luckydrq 文章只是表达抽取鉴权部分的意思,我考虑的实施方式是通过中间件的方式拦在前面
jtyjty99999
on 1 Mar 2017
@jtyjty99999 中间件也很难做到吧,毕竟这个粒度是要细化到field的。
luckydrq
on 1 Mar 2017
如果细化到field是不是graphql的意义就失去了,我觉得可能更多场景是取数前的auth,而不是根据auth限制field吧。这样做还可以结合egg的passport和userrole来做。(话说graphql官方文档貌似就是用中间件拦截的,但只是一个登录用户校验)
还有一种方式就是加载验权代码,然后在resolve中 yield this.app.auth('login') 这样,虽然还需要手动调用,但是这样比较优雅,也可以做你说的细粒度控制了 @luckydrq
jtyjty99999
on 1 Mar 2017
粒度必须是细化到field的,很多业务场景都有这个需求。最简单的,User这个实体,如果是用户本人,是可以看到password这个字段的,用于修改密码等场景。而如果是其他用户(例如有粉丝的角色),那么是不能看到password的。
以上只是举个例子,简单来说,我们定义一个实体,实体里的field一定是和实体相关的,所以都内聚在一起,但是对某些角色(场景)而言,一些field是需要隐去的。
luckydrq
on 1 Mar 2017
@luckydrq 我知道这样的场景,但是这种为什么不是发起方控制要的资源呢,甚至是接收请求验权后,生成查询再调用graphql呢,本来graphql我理解就是“你要什么,我给你什么”,这样你揉杂很多验权逻辑在 resolver里,跟传统开发维护一个接口里面一大堆分支没有区别了
jtyjty99999
on 1 Mar 2017
我理解验权是对“query”的验权,而不是对取数逻辑的验权
jtyjty99999
on 1 Mar 2017
我理解验权是对“query”的验权,而不是对取数逻辑的验权
query你不好做吧,因为请求过来的就是一个query字符串,你还得解析成ast,然后遍历所有字段,过滤出无权限的字段,然后重新构造一个query送到graphql底层,这个光说效率上就不可接受,我看了业界的一些做法,貌似也没有这么干的,能否提供下伪代码?
luckydrq
on 1 Mar 2017
目前我对graphql的理解,它不是银弹,架构上也是有不完美的地方。但是它的优势是明确的:
- 统一领域模型,屏蔽底层取数方式。
- 要什么给什么,通过图来实现灵活的数据存取,去除REST这种
endpoint-to-endpoint的局限性。
我一开始选择它其实还是第2个原因,REST太他妈蛋疼了。
luckydrq
on 1 Mar 2017
@luckydrq 说实话,业界很多我感觉那都是demo, graphql跟后端服务是一起部署的,结果前端代码就直接请求到graphql了。。
真正的场景应该是数据独立通过graphql提供服务,然后业务层验证权限。
这样前端发起 getUserInfo 接口 => 业务层校验,发现是本人 = >
业务层构造query
{user{id password}} =》 到graphql 数据服务器,返回数据
前端发起 getUserInfo 接口 => 业务层校验,发现不是本人 = >
业务层构造query
{user{id}} =》 到graphql 数据服务器,返回数据
graphql他只管暴露数据,对query做校验即可。
jtyjty99999
on 1 Mar 2017
@luckydrq 你说的这些优点,我觉得只有把graphql作为纯粹的取数服务才能体现出来,比如你就把它当作一个corona
jtyjty99999
on 1 Mar 2017
真正的场景应该是数据独立通过graphql提供服务,然后业务层验证权限。
@jtyjty99999 还是一个之前的问题,鉴权细化到field你的代码就确实不好做了。
业务层构造query
可以看看relay, relay就是前端直接发schema query的,一直以来被称为graphql的最佳伴侣,在React Native开发中广泛应用,relay就是把schema和组件放在前端的。
luckydrq
on 1 Mar 2017
不能说relay前端直接发schema query就一定是正确做法吧,我反而觉得那纯粹是为了graphql而graphql,把接口伪装成那种schema了,最佳伴侣这个我也不同意,不能因为用的人多就说是对的。。这里不能发内网链接,我觉得内网有个叫 Postgraphql 的东西,还有一个叫“内容平台”的东西正是我想说的东西
jtyjty99999
on 1 Mar 2017
嗯,讨论先到这,我会继续探索。
luckydrq
on 1 Mar 2017
@luckydrq 感谢讨论
jtyjty99999
on 1 Mar 2017
以这个为例 http://dev.apollodata.com/tools/graphql-tools/connectors.html
原来是这样的 resolverMap
const resolverMap = {
Query: {
gitHubRepository(root, args, context) {
return rp({ uri: `https://api.github.com/repos/${args.name}` });
}
}
}
我们将 resolverMap 转化成一个 router 的形式
app.graghql.resolve('Query.gitHubRepository', mw, 'query.gitHubRepository');
query 为 controller app/controller/query.js
module.exports = app => {
return class Query extends app.Controller {
* gitHubRepository() {
return yield this.ctx.curl('https://api.github.com/repos/${query.name}')
}
}
}
这样使用方式和 http 没什么区别。
popomore
on 1 Mar 2017
cc @shaoshuai0102 这个感觉和 bff 有点类似
popomore
on 1 Mar 2017
@popomore 这样写需要额外把query从resolve里拆出来,额外维护一个resolveQueryRouter?本来这个map就比较轻量了,就是一个type和query的对应而已
jtyjty99999
on 1 Mar 2017
但是对于使用者来说都是有学习成本的吧,如果先熟悉 egg,那 controller 和 router 就有一致性了。
如果不讨论这个,其实就没必要在 egg 官方讨论了,直接用中间件的方式集成就可以了。
popomore
on 1 Mar 2017
@popomore 是在讨论这个啊,你可以考虑下,本来 app/graphql 下面只需要维护他自己的逻辑,现在他还要把resolve的方法拆出来放到controller ,跟他自己的业务逻辑揉在一起了,我们之前的意思是他这块逻辑可以独立的,甚至可以维护成一个包比如 npm/githubGraphql,然后下载下来,app/graphql中require进来,就可以作为他自己graphql服务的一部分了
jtyjty99999
on 1 Mar 2017
有点像网关系统,对 graphql 不是很了解,loader 的机制不用集成的 egg 里,可以参考内部的网关插件来做。
 shaoshuai0102
on 1 Mar 2017
shaoshuai0102
on 1 Mar 2017
@jtyjty99999 这个不能这么说,graphql 也是业务逻辑,可能他提供给页面的只有一套 graphql 接口,在 controller 实现觉得没什么问题。
而且所有的具体业务应该封装在 service 里,不管用 rest 还是 grapghql 只是路由进来调用对应的 service,底层业务应该不会有太多的改动。
popomore
on 1 Mar 2017
@popomore ok,那我清楚了,这个插件只负责管理schema,resolver的映射以及暴露graphql服务,对graphql查询和结果的返回。 resolver获取数据的逻辑还是走controller和service
jtyjty99999
on 1 Mar 2017
已经发布 [email protected]
jtyjty99999
on 7 Sep 2017
Related issues
 bupafengyu
·
3Comments
bupafengyu
·
3Comments
 Webjiacheng
·
3Comments
Webjiacheng
·
3Comments
 Azard
·
3Comments
Azard
·
3Comments
 lvgg3271
·
3Comments
lvgg3271
·
3Comments
 Seovos
·
3Comments
Seovos
·
3Comments
Most helpful comment
@mericmo 不要发表 mark 这样的评论,想关注的话,右边 Notifications 有个 subscribe
