Dxvk: Questions about DXVK to get a better understanding
This thread is for various questions about the DXVK code and functions to try to get a better understanding of various issues.
This is mainly done because (for me) it is to try to troubleshoot issues better, and in doing so, I want to learn more about the internal functions of DXVK, and questions of this nature is deemed off-topic to other troubleshooting threads since it is not a direct fix to the issue at hand.
So to kick it off, i will begin by asking a simple question:
@doitsujin
Is the heap.size variable in the following lines https://github.com/doitsujin/dxvk/blob/master/src/dxvk/dxvk_memory.cpp#L414-L417 supposed to be the "current heap" (whatever heap the allocation happens in), the "vram" heap Memory Heap[0] or the system memory heap Memory Heap[1]?
Example: If I have a graphics card with 1GB of vram, and 16GB system ram. Would the above function calculate a smaller chunksize than 128MB?
Observed function: I inserted a couple of lines at https://github.com/doitsujin/dxvk/blob/master/src/dxvk/dxvk_memory.cpp#L418 doing this:
Logger::info(str::format("DxvkMemoryAllocator: HeapSize = ", heap.size / mib, " MiB"));
Logger::info(str::format("DxvkMemoryAllocator: ChunkSize = ", chunkSize / mib, " MiB"));
And constexpr VkDeviceSize mib = 1024 * 1024; at https://github.com/doitsujin/dxvk/blob/master/src/dxvk/dxvk_memory.cpp#L403
What i do see is that ChunkSize changes depending on whether it is a 32-bit or 64-bit app (correct behavior), but the HeapSize remains the same - HeapSize = 11980 MiB regardless of 32/64-bit. Since i have 16GB system ram, 12GB is 3/4 of system ram, and i think i read someplace that this is supposedly correct.
Subquestion to the above observation: Is this function supposed to only consider system ram, and if so - why? And what would happen with my 1GB graphics card when the chunksize is calculated to 128MB since i have an abundance of system ram Heap Memory[1]?
 SveSop
SveSop
All 42 comments
Is the heap.size variable in the following lines https://github.com/doitsujin/dxvk/blob/master/src/dxvk/dxvk_memory.cpp#L414-L417 supposed to be the "current heap" (whatever heap the allocation happens in), the "vram" heap Memory Heap[0] or the system memory heap Memory Heap[1]?
The answer is just several lines above. 🐸
https://github.com/doitsujin/dxvk/blob/master/src/dxvk/dxvk_memory.cpp#L401
It's the heap of the memTypeId passed in to the function.
The chunk size is determined for each memory type using that function here:
https://github.com/doitsujin/dxvk/blob/master/src/dxvk/dxvk_memory.cpp#L170
Hopefully this also answers your subquestion.
What i do see is that ChunkSize changes depending on whether it is a 32-bit or 64-bit app
This is because of https://github.com/doitsujin/dxvk/blob/master/src/dxvk/dxvk_memory.cpp#L409-L412 which is meant to reduce fragmentation on x86 where that would be a much bigger issue due to available address space than on x64.
HeapSize remains the same - HeapSize = 11980 MiB regardless of 32/64-bit
I'm not too sure what the behaviour of allocating > 4096MB on 32 bit of system mem type is meant to be in Vulkan. If it does work, it's probably some magic mapping magic.
 Joshua-Ashton
on 21 Jul 2019
Joshua-Ashton
on 21 Jul 2019
Hmm. What struck me as somewhat odd, is when i launch a 32-bit app, the chunksize of 32MB is reported together with the heapsize of 11980 like this:
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 8192 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 8192 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 32 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 32 MiB
From the log-spew it could seem for a n00b like me, that the 32MiB set (due to 32-bit app) is set when the HeapSize is 11980MiB.
When i add the logging lines as i did i thought they would correspond to eachother?
SveSop
on 21 Jul 2019
I don't understand what you're trying to ask but...
The base ChunkSize on x86 is only 32 with VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT, it is the same as x64 otherwise.
https://github.com/doitsujin/dxvk/blob/master/src/dxvk/dxvk_memory.cpp#L410
Joshua-Ashton
on 21 Jul 2019
Ah.. changing it to VK_MEMORY_HEAP_DEVICE_LOCAL_BIT changes the logs like this:
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 8192 MiB
info: DxvkMemoryAllocator: ChunkSize = 32 MiB
info: DxvkMemoryAllocator: HeapSize = 8192 MiB
info: DxvkMemoryAllocator: ChunkSize = 32 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
Is that a bad thing then? Having 32MiB chunksize for VRAM, and 128MiB chunksize for System ram? Or am i just misunderstanding the whole concept?
How about:
if (type.propertyFlags & VK_MEMORY_HEAP_DEVICE_LOCAL_BIT || type.propertyFlags & VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT)
That will produce this:
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 128 MiB
info: DxvkMemoryAllocator: HeapSize = 8192 MiB
info: DxvkMemoryAllocator: ChunkSize = 32 MiB
info: DxvkMemoryAllocator: HeapSize = 8192 MiB
info: DxvkMemoryAllocator: ChunkSize = 32 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 32 MiB
info: DxvkMemoryAllocator: HeapSize = 11980 MiB
info: DxvkMemoryAllocator: ChunkSize = 32 MiB
We only care about a lower chunk size on x32 + HOST_VISIBLE because of the limited address space (given that HOST_VISIBLE is mapped.)
Joshua-Ashton
on 21 Jul 2019
Bacause all allocations are mapped from VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT by using vkMapMemory?
SveSop
on 21 Jul 2019
Yes
Joshua-Ashton
on 21 Jul 2019
So will VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT map from available system memory, but the actual data is placed in vram?
And allocating does by no means actually check for available system memory, it just allocates and either get a VK_SUCCESS if it works, or any of the three - VK_ERROR_OUT_OF_HOST_MEMORY, VK_ERROR_OUT_OF_DEVICE_MEMORY, VK_ERROR_MEMORY_MAP_FAILED if it fails?
SveSop
on 21 Jul 2019
When logging the value of m_memHeaps[i].stats.memoryAllocated (ref https://github.com/doitsujin/dxvk/blob/master/src/dxvk/dxvk_memory.cpp#L241-L242) respectively to their memHeaps (0-1 for my nVidia card), these values are not divisible by 128.
Is this because there is also some buffer amount included here?
Eg. I started Unigine Superposition in 1080p Extreme, and the values were:
m_memHeaps[0].stats.memoryAllocated - 3461
m_memHeaps[1].stats.memoryAllocated - 224
In my untrained mind, this means DXVK has allocated 3461MB from GPU memory (heap 0), and 224 from System memory (heap 1).
3461/128 = 27,039 and 224 / 128 = 1,75. Added together: 3461+224 / 128 = 28,789
Now im getting confused again. I kinda thought allocations happened in chunks of 128MB? (ref. https://github.com/doitsujin/dxvk/blob/master/src/dxvk/dxvk_memory.cpp#L405)? Or are we talking "amount of chunks containing data"?
SveSop
on 25 Jul 2019
@SveSop render targets will use dedicated allocations on Nvidia to increase performance, which will throw the 128MB thing out of the window for some allocations.
 doitsujin
on 25 Jul 2019
doitsujin
on 25 Jul 2019
Ah. Yeah, tossing a nullptr instead of dedAllocPtr at https://github.com/doitsujin/dxvk/blob/master/src/dxvk/dxvk_memory.cpp#L190 creates "divisible by 128" amount of memory allocated.
m_memHeaps[0].stats.memoryAllocated - 3456
m_memHeaps[1].stats.memoryAllocated - 256
One thing i noticed is if i do that, the allocated memory "stays put", ie. it does not vary once you have run a course of eg. Unigine Superposition (all all needed memory is allocated), where as when you use the VK_KHR_dedicated_allocation extension (i guess it is), the memory allocations will increase/decrease throughout the scene more or less continuously.
Is this "dedicated_allocation" extension "doing its own thing" then?
SveSop
on 25 Jul 2019
In my quest to better understand this allocation thing, i added a counter here https://github.com/doitsujin/dxvk/blob/master/src/dxvk/dxvk_memory.cpp#L357 , and a logging line.
Now using the above example of replacing dedAllocPtr with nullptr to force "normal" allocations, the counter counted up to 29 when running Superposition. (3456 + 256 = 3712 / 128 = 29). All good, and corresponds with what i would expect.
Using dedAllocPtr as per default, and adding another counter that counts both when "dedicated" allocations happens, and "regular" allocations, i observed both numbers keep counting. So, is this intended behavior?
I left Superposition running in a loop (Game mode - scene) for a couple of hours, and the counter had passed 1K. I don't know if there is a limit to number of allocations, but it is clear that some sort of clearing happens, cos the memory usage did not increase accordingly to number of allocations (that i counted).
Sorry if i am a bit awkward explaining things tho, but if you wanna look at my attempts to do this counting i can upload it to my git repo so you can take a look at it and maybe explain it better to me? (Tomorrow tho.. if interested)
SveSop
on 25 Jul 2019
About "some sort of clearing":
Allocations of memory are handled within a chunk: A new chunk is basically a single-item freelist declaring the whole chunk as free. If you allocate memory from the chunk, the freelist is broken into two parts and the first item is allocated, the second points to the remaining freelist with a block descriptor at that offset. On subsequent allocations, the allocator will walk the freelist for a fitting block, and then again splits the freelist to allocate one more block. The freelist is a chain of descriptors pointing to the offset of the next free block. Space in-between (jumped by the freelist chain) is thus allocated.
Clearing up memory does the reverse action: It converts allocated memory back into a freelist descriptor, and after this it joins adjacent freelist descriptors to shorten the freelist chain while increasing a the free block size described by it. This joining will allow the allocator to more easily find a fitting block when it searches for some next time.
But there's one difference: While an allocation can create a newly allocated chunk, DXVK would never free chunks that contain just one freelist item spanning the whole chunk (aka "nothing allocated from the chunk"). Thus it will never give up a chunk once it has been allocated for a specific heap type.
So, a chunk is just hosting a list of memory allocations within its designated physical memory block, and the chunk itself is never freed (aka given back to the device/system). A code comment actually says that: "This is not thread-safe but chunks are never freed anyways", or: DXVK cannot and even doesn't try. It's like creating and appending to a file on disk: You allocate "memory" from disk space but even when you write into that file a text "the next 64MB are free" it just says that without freeing space on disk, tho it tells you (aka "DXVK") that this 64MB block can be newly allocated to some other operation. Just when you quit your application, you would also delete that whole file and actually free disk space. In that example, such a file is a chunk, and whatever you write into that file is an allocation or free. The system (aka driver/GPU) doesn't care how or why you do that, it even isn't aware of the structure contained.
In that term, allocated and freed memory is calculated from the freelist but that's a complete different picture from what is really allocated from the VRAM as chunks: That counter will ever only go up (and such memory is no longer available to other processes) while the DXVK-internal allocator may vary in actual usage of chunk space. Or in other words: Once DXVK has allocated memory, it will never be given back to the system/device. It can just be freed to be re-purposed within DXVK.
With this observation, your counters only indicate allocation but don't decrease on free. And even if they did, it will never have any proportional relation to native memory allocated from system/device (aka chunks).
It would be interesting if you counted the "active" allocation (thus decrease your counter upon free, or alternatively count frees also, and check the difference between both, or even count chunk allocations vs. internal allocations from a chunk freelist) and see if it still raises on multiple loops of the render scene. If yes, there may be some leak which should be fixed (tho, allocated chunks won't decrease, see above).
Also, by counting just allocations but not frees, your counter has no value in talking about "limit of total allocations":
A. There is not really a limit because we are limited only by the amount of freelist/allocated items you could fit into a chunk, and by the amount of chunks you could fit into the device/system memory. There's no direct handle associated with such allocations which could be limited by the driver or system. Tho, walking long freelist chains will have an impact on allocation performance (which would be an issue of internal fragmentation because DXVK is designed to keep internal fragmentation low).
B. If you allocated one full chunk size you're limited to one allocation within this chunk. The next allocation has to allocate a new chunk unless you freed memory from that first chunk before doing so. Again, a direct driver handle is probably only associated with the chunk itself but not the allocated blocks within said chunk.
C. Your counter can technically only ever increase currently and thus limits cannot be defined. It is more or less pointless if you don't compare it to something like a free counter or decrease it upon frees.
 kakra
on 26 Jul 2019
kakra
on 26 Jul 2019
BTW: As an exercise you could implement a fragmentation indicator. Memory fragmentation in terms of DXVK is only indicated by how spread out amounts of free memory within a chunk are. Allocated memory blocks itself never fragment, they are always contiguous. A fragmentation counter should be proportional to how much free memory is split in relation to the total free memory. Thus, if a chunk has 64MB of free memory but that's split into two parts of 32MB free space each, it would be 50% free space fragmented (because 100-100/x with x=2 is 50, non-weighted for ease of implementation). I'm not sure, tho, if such a value would tell us anything about stability performance of DXVK wrt memory allocations.
kakra
on 26 Jul 2019
@kakra
Thank you for the explanation. This is more or less what i kinda thought would be the case. The thing that threw me off a bit, is the difference between "counting allocations" (the way i clumsily do) when things are allocated using the VK_KHR_dedicated_allocation extension (the default behavior) vs "forcing" it disabled by tossing a nullptr at the line i describe above.
In the latter experiment (NOT using VK_KHR_dedicated_allocation afaik), the counter NEVER goes up during the scene once it has run its course, and thus in line with "never freeing a chunk". This is absolutely how i understand it, and what you describe - logic is safe. How come the counter keeps on counting when that extension is used? Sure, as you point out, i should have a logical de-counting for whatever function frees this, and the number would possibly go up/down accordingly... But why the difference?
I guess my "counting logic" is flawed there... It should be no difference right?
SveSop
on 26 Jul 2019
@SveSop I currently have no idea but I will soon be back into taking care of my own wine-proton branch, and maybe then I could check this in more depth.
According to http://www.asawicki.info/articles/VK_KHR_dedicated_allocation.php5 this extension allows the driver to manage the allocation on its own to apply more optimizations than what's usually available to the developer. So that makes a direct binding between a chunk containing a single dedicated allocation, and this in turn can probably be freed. For the lifetime of a scene this may trigger freeing the chunk at some point because the render engine indicates it's no longer in use. Because it's a dedicated allocation, it will also free the chunk. But that's just my uneducated guess. It would explain your observations, tho.
In contrast, a non-dedicated allocation will stay in the chunk buffer - and no further allocation will be triggered again.
kakra
on 26 Jul 2019
While browsing links around that unofficial manual, I've found the following comment in https://github.com/GPUOpen-LibrariesAndSDKs/VulkanMemoryAllocator/blob/188a365ed48e03e0a09b636464d4c16a00e14899/src/vk_mem_alloc.h#L411-L421:
- When operating system is Windows 7 or 8.x (Windows 10 is not affected because it uses WDDM2),
device is discrete AMD GPU,
and memory type is the special 256 MiB pool of `DEVICE_LOCAL + HOST_VISIBLE` memory
(selected when you use #VMA_MEMORY_USAGE_CPU_TO_GPU),
then whenever a memory block allocated from this memory type stays mapped
for the time of any call to `vkQueueSubmit()` or `vkQueuePresentKHR()`, this
block is migrated by WDDM to system RAM, which degrades performance. It doesn't
matter if that particular memory block is actually used by the command buffer
being submitted.
So in Windows there actually seems to exist a function that may intentionally migrate data to system memory. It imposes a performance penalty, tho. But it may be part of the solution why allocations may fail in DXVK due to different memory usage behavior.
kakra
on 26 Jul 2019
Allocations generally don't fail in DXVK, unless you're unlucky enough to be affected by #1100 which apparently doesn't have anything to do with memory utilization.
AMD drivers on Linux use TTM, which works in a similar fashion to the memory management in WDDM1 (except the part where mapping causes VRAM allocations to be migrated to sysmem). You can basically allocate all the memory you want and over-subscribe heaps, and let the kernel figure things out. DXVK does this and in general it works rather well.
doitsujin
on 26 Jul 2019
@kakra
Interesting!
nVidia does not have this "256MB special memory" i think tho, but there are some differences to what memory types have the HOST_VISIBLE flag on AMD vs. nVidia. nVidia does not have a type with DEVICE_LOCAL + HOST_VISIBLE flag according to what i can figure out from vulkaninfo.
Ill work on implementing a subtraction to my counter when things are freed, and i have made some adjustments to this that made number of allocations more sensible (in the 26-30 range atleast).
I wonder if it is possible to figure out what the extension uses for chunk size, as this kinda seems its on a fluid basis (that might make sense for optimization purposes i guess). This in turn might explain why it will be freed frequently? Ie. Not enough free chunk space requires a new allocation to fit a block vs. the default (now) 128MB, the difference being that the extension calls for freeing the chunk perhaps?
SveSop
on 26 Jul 2019
@doitsujin Thanks for jumping in. You wrote:
Allocations generally don't fail in DXVK, unless you're unlucky enough to be affected by #1100 which apparently doesn't have anything to do with memory utilization.
From all my observations I previously did on the issue, I can only see that it has to do with sysmem allocations and how the kernel or driver could handle finding mappable memory regions. Except for slow-downs resulting from allocating too much memory, VRAM seems to be mostly fine despite being almost completely filled while the allocation failed for sysmem.
AMD drivers on Linux use TTM, which works in a similar fashion to the memory management in WDDM1 (except the part where mapping causes VRAM allocations to be migrated to sysmem). You can basically allocate all the memory you want and over-subscribe heaps, and let the kernel figure things out. DXVK does this and in general it works rather well.
There has once been a switch to enable or disable over-subscription. Was this the same as "DXVK does this" now? It seemed to solve the apparent problem but was considered a wrong solution - or even actually the cause to expect memory allocations to fail if enabled.
As far as I found by a quick search, TTM is a kernel thing, and it's a translation table manager, so it probably provides something like the CPU page tables to the GPU to work against memory fragmentation problems. Obviously, NVIDIA doesn't use it, as they also refused to adopt GEM.
kakra
on 26 Jul 2019
There has once been a switch to enable or disable over-subscription. Was this the same as "DXVK does this" now?
Yes, sort of. Before, DXVK would keep track of the amount of memory allocated from each heap and fall back to a sysmem heap if the device-local heap was full, even if the driver didn't care. Now it only falls back to sysmem heaps if allocating from a VRAM heap fails in the driver (which never happens on AMD systems).
This allows VK_EXT_memory_priority to work somewhat efficiently, since the kernel will control dynamically which allocations are resident in VRAM and which aren't.
doitsujin
on 26 Jul 2019
What does the note
// This call is technically not thread-safe, but it
// doesn't need to be since we don't free chunks
mean found here: https://github.com/doitsujin/dxvk/blob/master/src/dxvk/dxvk_memory.cpp#L68-L72 , in reference to the function here https://github.com/doitsujin/dxvk/blob/master/src/dxvk/dxvk_memory.cpp#L391-L397
Is it "not thread safe" because it calls DxvkMemoryAllocator::freeDeviceMemory directly, but the DxvkMemoryAllocator::free is "thread safe" because of the mutex?
SveSop
on 26 Jul 2019
@SveSop If you'd free a chunk you must ensure that no other thread is currently trying to allocate or free memory within it. Not sure if Vulkan itself puts further constraints.
kakra
on 26 Jul 2019
We never free chunks until the Vulkan device itself gets destroyed, and that's being done one one thread, so it being thread-safe literally doesn't matter.
doitsujin
on 26 Jul 2019
@kakra
I was just wondering about the
... since we don't free chunks
As it seems that putting my "counting down allocationcounter" logic i am fiddling with needs to be put in the DxvkMemoryAllocator::freeDeviceMemory function, or else the counter just keeps counting up. So, does this indicate that something is actually freeing chunks? (Also ref. the fluidity of the allocated memory on the HUD indicate something is being freed). This does not happen if you do not use the dedicated allocation extension tho, cos then the allocations is allocated and thats it.
SveSop
on 26 Jul 2019
So that comment isn't technically correct? ;-) We free chunks but only at device tear-down time when thread-safety no longer matters...
kakra
on 26 Jul 2019
@SveSop Well, I'm sure DXVK actually sometimes frees device memory but it doesn't free chunks. I.e. I think dedicated allocations may be such an occasion.
kakra
on 26 Jul 2019
Oh.. I kinda was under the impression that a "chunk" lived in the "device memory", and thus you logically cannot free "device memory" without freeing a "chunk" first?
Sorry if i am totally off here tho..
Eg.
Device memory:
<-------------------------------------------------------------------->
<-----------> <--------> <----------------------->
Chunk chunk chunk
Or no?
SveSop
on 26 Jul 2019
My current understanding is: Yes, a chunk is allocated from device memory (or some other heap) but in sizes of chunks. Vulkan is a bit complicated here: You need to allocate objects and also allocate memory, then bind both together, as far as I understood. A chunk is bound to some device memory block, within it DXVK allocates memory. A dedicated allocation is a block of device memory directly bound to some object. From view of the system both are the same: It's allocated from device memory. If you free a chunk you free device memory.
I think your ASCII art allows for some misinterpretation: Device memory is not just some static amount of VRAM, it can be allocated from. Basically you're allocating a "chunk" of device memory. But the difference is the role in which you're going to use it: As a chunk managed in more detail by DXVK itself, or as directly serving some dedicated memory request for Vulkan operations.
The allocations within a chunk are really just only managed by DXVK itself. The driver doesn't care: Free device memory associated with the chunk - everything's fine. It just invalidates whatever handles DXVK held within that chunk. If you'd want to cleanly tear it down: Yes, free your allocations within the chunk first, then free the chunk itself and thus get back unused device memory. But if the game is stopped anyways, DXVK can just free the chunks without bothering what's inside. That's probably also what "is technically not thread-safe" means, and why "we don't free chunks" [...while the application is running].
kakra
on 26 Jul 2019
If you free a chunk you free device memory.
@doitsujin said:
We never free chunks until the Vulkan device itself gets destroyed
So, that cannot be i guess.
I think your ASCII art allows for some misinterpretation: Device memory is not just some static amount of VRAM, it can be allocated from. Basically you're allocating a chunk of device memory. But the difference is the role in which you're going to use it: As a chunk managed in more detail by DXVK itself, or as directly serving some dedicated memory request for Vulkan operations.
Yeah. It was incredibly simple, and since i dont really grasp the whole concept myself, i am simple...
Device memory <-> heap memory and so on... "Device memory" is a broad description, and not correct... but what i MEANT was that you cannot "free device memory without freeing chunks" (freeing any type of chunk = create any type of free memory), and that is more or less what you said above - ie. "when you free chunks you free device memory". (Disregarding the meaning of "device" memory)
However, if chunks are NEVER freed while the game is running, how does this explain for the variable "allocated memory" on the HUD + my feeble experiments with counting down chunks from the DxvkMemoryAllocator::freeDeviceMemory function? Or should i use the DxvkMemoryAllocator::freeChunkMemory function instead? (oh.. wait.. chunks are never freed?).
Maybe the driver does whatever the f.. it wants when that extension is allowing it, and the HUD just outputs whatever memory is allocated (ref. the driver), and there is no control over the allocations or what the driver does with it?
SveSop
on 27 Jul 2019
Quick couple of follow-ups here:
- Am i right in assuming chunk memory allocated with a pointer in
dedAllocInfois to be considered as using the extension to do "dedicated allocation"? Or can there be a pointer here (other than null) regardless? - Counting allocations WITH a pointer in
dedAllocInfoas "dedicated allocation", i notice that there is a difference in the amount of such allocations between "games/apps". Is this something that happens when the type of resource is "right" (ie. contains a useful kind of data), or is this controlled by DXVK in another way? (Some games seems to use this more than others). - If the answer to question #1 is "yes", and #2 is "the resource determines the usage", could this explain why SOME games seems more prone to allocation errors than others?
SveSop
on 29 Jul 2019
@SveSop With the explanation here https://github.com/doitsujin/dxvk/issues/1100#issuecomment-519833964, maybe you want to add histogram statistics for memory allocations in DXVK? (aka count of allocations for different allocation sizes like 1k, 2k, 4k, 8k, 16k, 32k, 64k, ... you get the idea)
But this is interesting mostly only for allocations using sysmem...
kakra
on 9 Aug 2019
@kakra
I will look into that and see if it creates a difference. Just fyi this is what my default values are (Ubuntu 18.04 w/custom built 5.2 kernel i make myself here: https://github.com/SveSop/kernel_cybmod)
/sys/kernel/mm/transparent_hugepage/shmem_enabled
always within_size advise [never] deny force
/sys/kernel/mm/transparent_hugepage/enabled
always [madvise] never
/sys/kernel/mm/transparent_hugepage/defrag
always defer defer+madvise [madvise] never
/sys/kernel/mm/transparent_hugepage/khugepaged/max_ptes_none
511
I managed to frag the custom functions i was fiddling with, but i might be able to come up with the counter again.. but what i did was not really reliable, cos i do not have a perfect way to count down (freed allocations), as i have not figured out how to verify that whatever allocation is freed is dedicated or non-dedicated... Other than me setting a flag when something is allocated, and assuming the next allocation freed is of the same type. The "free" function does not use the property flags, or "priority" flags, so i currently do not know what is freed. It does mostly seem "sane", as the results did not get out of hand, but exiting an app should (i think) result in the counter going down to 0, but i tend to end up with a + result, and thus probably not correct.
But have not had too much experimentation lately due to actually playing a game hehe.
SveSop
on 9 Aug 2019
@kakra
I will look into that and see if it creates a difference. Just fyi this is what my default values are (Ubuntu 18.04 w/custom built 5.2 kernel i make myself here: https://github.com/SveSop/kernel_cybmod)/sys/kernel/mm/transparent_hugepage/shmem_enabled always within_size advise [never] deny force /sys/kernel/mm/transparent_hugepage/enabled always [madvise] never /sys/kernel/mm/transparent_hugepage/defrag always defer defer+madvise [madvise] never /sys/kernel/mm/transparent_hugepage/khugepaged/max_ptes_none 511 ^^^
That particular value is the kernel default (and much too high in my opinion because it inflates all allocations below 2M (even 4k allocations) to a full 2M huge page, even if the application never intents to put any more data into it. I had a lot of problems due to this. But since you're using enabled=madvise, it shouldn't be a problem: In that case huge pages are only allocated when an application explicitly asks for them, and then it's likely that it will fill 2M pages with actual data more or less completely.
But have not had too much experimentation lately due to actually playing a game hehe.
I totally agree with you that extensive testing is very much needed and valuable :-D
kakra
on 9 Aug 2019
I must admit i am kinda sick of this *hit at times, and from the general low traffic on the memoryallocation thread, i guess i am not the only one that kinda puts up with random crashes, or contemplates buying a AMD card, as this is clearly the better option (until i buy that, and ends up with just another bit of random bugs switching between 3 driver branches constantly?!)
Nevertheless, i will ask stuff from time to time when i wanna bother with this i guess.
Testing i have done above indicate TO ME the following:
vk_khr_dedicated_allocationusage disregards whatever chunksize and uses some magic "driver size".- The dedicated allocations are constantly being allocated and freed throughout the scene.
Since there is no easy answer to be had if this is what is supposed to happen, i just wonder if this is also happening with AMD?
Test: Start Unigine Superposition benchmark in "game" mode, preferably with the "8K Optimized" preset, but any preset as high as you can will do. Watch the "Allocated" amount. Turn around and do stuff in the room. Does the allocated amount go up/down depending on what angle you look at stuff? (Higher "jumps" at higher presets, so its easier to see).
If you look at my screenshot here, just by moving the camera back and forth a wee bit, the allocation will jump a whopping 382MB. And not just go up, but it will be freed once i turn back..
I just wonder if this is actually how it is supposed to be on AMD aswell?
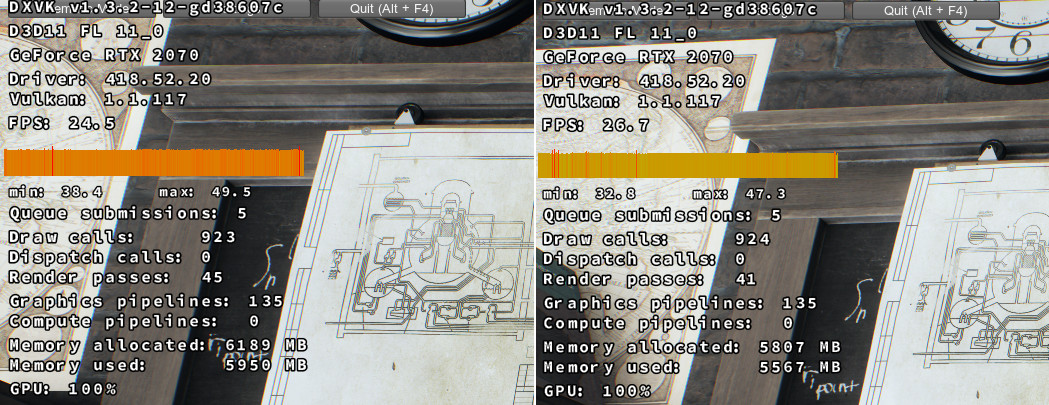
SveSop
on 22 Aug 2019
Since there is no easy answer to be had if this is what is supposed to happen, i just wonder if this is also happening with AMD?
No, because AMD hardware doesn't require dedicated allocations for best performance.
You can disable this in the code, but expect a 10-20% performance hit.
doitsujin
on 22 Aug 2019
May i then suggest that it may be a problem with how nVidia driver handles this requirement, or the way DXVK utilizes this?
I kinda lived with the notion that allocating/freeing chunks also came with a performance cost, and from all we know it MAY be that this constant allocation/freeing causes some weirdness when thinking about the memory allocation problem.
The XID errors that the driver spew now (with the PID responsible) seem to indicate a randomness of what causes the error. I have had multiple XID errors pointing to things from Firefox to whatever else (but so far not wine or wine related processes). So, lets say something happens in the background that requires some sort of VRAM memory allocation at the same time the driver allocates/frees vulkan vram (constantly!) that COULD mean both fragmentation and other problems.
Far fetched? Or a viable theory? Ill keep testing some differences and see if i can figure out WHY dedicated allocations are freed. I dunno if it NEEDS to, cos the documentation is rather spares (from what i have found). I have found i guess why and how to use it, but not what it really needs to do... I mean, why would a dedicated allocation need to be freed when regular allocations do not (atleast not in a constant manner like it does now)? nVidia do not recommending using every allocation as dedicated, and it does not, but i don't know why, or how to prevent that if the driver kinda flags a lot of resources/buffers as "need dedicated allocation".
https://devblogs.nvidia.com/vulkan-dos-donts/
Don’t put every resource into a Dedicated Allocation.
SveSop
on 23 Aug 2019
DXVK let's the driver decide whether to put something into a dedicated allocation or not.
 K0bin
on 23 Aug 2019
K0bin
on 23 Aug 2019
DXVK let's the driver decide whether to put something into a dedicated allocation or not.
Supposedly so yes... But that kinda leaves two questions: Why would a nVidia dev blog indicate one to NOT put every resource into a Dedicated Allocation, if it is purely up to the driver, and secondly: why does DXVK free the dedicated chunk?
The second question is kinda moot, cos if it not freed it is still continuously allocated by DXVK and will eventually fill everything... I'm just not entirely sure that is the correct method. If it is the driver doing something weird or otherwise.
@doitsujin
No, because AMD hardware doesn't require dedicated allocations for best performance.
Does this mean that the same expansion used with a AMD driver and the DXVK functions will NOT cause a dedicated allocation? Is that because the "require dedication" flag set by the driver rarely/never happen with AMD (or VkMemoryDedicatedRequirementsKHR-prefersDedicatedAllocation is not set by AMD driver for that matter?)
Why would the extension indicate that it is something that you need to decide... if it is the driver deciding?
http://twvideo01.ubm-us.net/o1/vault/gdc2018/presentations/Sawicki_Adam_Memory%20management%20in%20Vulkan.pdf
Dedicated allocation
●Some resources may benefit from having their own, dedicated memory block instead of region suballocatedfrom a bigger block.Driver may use additional optimizations.●Use for:
●Render targets, depth-stencil, UAV
●Very large buffers and images (dozens of MiB)
●Large allocations that may need to be resized (freed and reallocated) at run-time.
Maybe DXVK lets the driver decide too much? :)
SveSop
on 23 Aug 2019
DXVK uses dedicated allocations if the driver thinks that doing so is beneficial for performance. It trusts the driver to actually implement this in a reasonable way and e.g. not set the hint for small buffers and regular textures. What is wrong with this approach?
Excuse me if I'm being blunt, but I haven't seen a single constructive suggestion on how to improve DXVK's behaviour so far, only questions that you wouldn't have to ask if you actually understood any of the code and the corresponding bits of the Vulkan specification.
I can add an option to disable dedicated allocations altogether, but we really have no business overriding the driver's decision to use dedicated allocations when we do.
doitsujin
on 23 Aug 2019
Well, to be equally blunt, i would have called the thread "Suggestions to improve DXVK", and NOT "Questions about DXVK to get a better understanding" if that was the purpose of the thread.
I can't help reading stuff (like i linked above, both from nVidia AND AMD vulkan dev's) indicating that "dedicated allocation" should not be used as a "all" function, whether the driver thinks its the best approach or not. I am sorry for question your better judgement in that matter.
Lets just close the thread, and conclude that nVidia is shit, and AMD rules everything, cos SURELY nothing else could be the problem!
SveSop
on 23 Aug 2019
Asking questions does not contribute.
SveSop
on 23 Aug 2019
Related issues
 EnigmaRaptor
·
5Comments
EnigmaRaptor
·
5Comments
 artivision
·
4Comments
artivision
·
4Comments
 jekstrand
·
5Comments
jekstrand
·
5Comments
 knuxyl
·
5Comments
knuxyl
·
5Comments
 yusdacra
·
4Comments
yusdacra
·
4Comments
Most helpful comment
About "some sort of clearing":
Allocations of memory are handled within a chunk: A new chunk is basically a single-item freelist declaring the whole chunk as free. If you allocate memory from the chunk, the freelist is broken into two parts and the first item is allocated, the second points to the remaining freelist with a block descriptor at that offset. On subsequent allocations, the allocator will walk the freelist for a fitting block, and then again splits the freelist to allocate one more block. The freelist is a chain of descriptors pointing to the offset of the next free block. Space in-between (jumped by the freelist chain) is thus allocated.
Clearing up memory does the reverse action: It converts allocated memory back into a freelist descriptor, and after this it joins adjacent freelist descriptors to shorten the freelist chain while increasing a the free block size described by it. This joining will allow the allocator to more easily find a fitting block when it searches for some next time.
But there's one difference: While an allocation can create a newly allocated chunk, DXVK would never free chunks that contain just one freelist item spanning the whole chunk (aka "nothing allocated from the chunk"). Thus it will never give up a chunk once it has been allocated for a specific heap type.
So, a chunk is just hosting a list of memory allocations within its designated physical memory block, and the chunk itself is never freed (aka given back to the device/system). A code comment actually says that: "This is not thread-safe but chunks are never freed anyways", or: DXVK cannot and even doesn't try. It's like creating and appending to a file on disk: You allocate "memory" from disk space but even when you write into that file a text "the next 64MB are free" it just says that without freeing space on disk, tho it tells you (aka "DXVK") that this 64MB block can be newly allocated to some other operation. Just when you quit your application, you would also delete that whole file and actually free disk space. In that example, such a file is a chunk, and whatever you write into that file is an allocation or free. The system (aka driver/GPU) doesn't care how or why you do that, it even isn't aware of the structure contained.
In that term, allocated and freed memory is calculated from the freelist but that's a complete different picture from what is really allocated from the VRAM as chunks: That counter will ever only go up (and such memory is no longer available to other processes) while the DXVK-internal allocator may vary in actual usage of chunk space. Or in other words: Once DXVK has allocated memory, it will never be given back to the system/device. It can just be freed to be re-purposed within DXVK.
With this observation, your counters only indicate allocation but don't decrease on free. And even if they did, it will never have any proportional relation to native memory allocated from system/device (aka chunks).
It would be interesting if you counted the "active" allocation (thus decrease your counter upon free, or alternatively count frees also, and check the difference between both, or even count chunk allocations vs. internal allocations from a chunk freelist) and see if it still raises on multiple loops of the render scene. If yes, there may be some leak which should be fixed (tho, allocated chunks won't decrease, see above).
Also, by counting just allocations but not frees, your counter has no value in talking about "limit of total allocations":
A. There is not really a limit because we are limited only by the amount of freelist/allocated items you could fit into a chunk, and by the amount of chunks you could fit into the device/system memory. There's no direct handle associated with such allocations which could be limited by the driver or system. Tho, walking long freelist chains will have an impact on allocation performance (which would be an issue of internal fragmentation because DXVK is designed to keep internal fragmentation low).
B. If you allocated one full chunk size you're limited to one allocation within this chunk. The next allocation has to allocate a new chunk unless you freed memory from that first chunk before doing so. Again, a direct driver handle is probably only associated with the chunk itself but not the allocated blocks within said chunk.
C. Your counter can technically only ever increase currently and thus limits cannot be defined. It is more or less pointless if you don't compare it to something like a free counter or decrease it upon frees.