Dvc: SSH caching doesn't work when cloning an external repository
Bug Report
The usage of SSH remote location for caching doesn't seem to work in all situations. Mainly, when the use case is to use an existing DVC repository and set the caching on a disk accessed through SSH.
When it is set as cache.ssh, it is ignored and it seems normal according to the documentation since the files are not added on an SSH location (the files are already in the DVC repository when it is cloned from an existing repository).
However, when the "local" remote is set, it just crashes at the configuration parsing since it can't find the cache directory. Precise line in repo/__init__.py:
if path_isin(self.cache.local.cache_dir, self.root_dir):
Thus, it is not possible to use a SSH repository as a caching, unless the files have been added through SSH.
Please provide information about your setup
Output of dvc version:
$ dvc --version
0.94.0
 dmidge8
dmidge8
All 10 comments
Hi @dmidge8 ! Cache.ssh is for external outputs scenario https://dvc.org/doc/user-guide/managing-external-data, it is not meant for direct use as a local cache.
 efiop
on 22 Jun 2020
efiop
on 22 Jun 2020
Hi @efiop !
Thank you for your quick reply.
I was under impression, reading the documentation, that it was possible to extend the use case to inputs also coming from a SSH location (through SFTP). As an example, when I read the documentation, I see that it is possible to add data from an ssh location directly to an SSH cache.
# Add data on SSH directly
dvc add ssh://[email protected]:/mydata --external
As far as I understand, setting cache.ssh in such configuration bypass the need to download locally. It is mostly useful when working on the same disk.
But then, what happens is that you want to checkout from an external location (a co-worker needs the same data). Then, the link is gone, the cache location may not be the same and so on. The local config is there to handle the specific reconfiguration.
Right now, I have a setup where I pull from one SSH location and use the "local" cache on the same SSH server (different location to avoid hashes conflict). The data has been added through the regular dvc add. But what I gather is, I have to redefine everything, create a virtual SSH filesystem on every machine with the same goal and then use that location as a cache. And since DVC is agnostic to the type of storage, DVC can't avoid the network copy. Is there a better way? Reading the documentation, I thought so, but I am not that sure anymore...
dmidge8
on 23 Jun 2020
@dmidge8
However, when the "local" remote is set, it just crashes at the configuration parsing since it can't find the cache directory. Precise line in repo/init.py:
could you elaborate on this a little bit?
As far as I understand, setting cache.ssh in such configuration bypass the need to download locally. It is mostly useful when working on the same disk.
yes, that's true. But we before we jump into the details and try to find a workaround, could you please share a bit more details? If you don't download data to any local volume, how do you access it in your scripts/code?
The local config is there to handle the specific reconfiguration.
that's also, correct. You can check this repo for Dask/SSH pipelines with DVC - https://github.com/PeterFogh/dvc_dask_use_case - it's a bit outdated but idea is correct.
Is there a better way? Reading the documentation, I thought so, but I am not that sure anymore...
to be honest, I'm still not sure I got the setup from your description - could share some commands, configs, etc?
 shcheklein
on 25 Jun 2020
shcheklein
on 25 Jun 2020
However, when the "local" remote is set, it just crashes at the configuration parsing since it can't find the cache directory. Precise line in repo/init.py:
could you elaborate on this a little bit?
Yes. I tried to define the local repository with an ssh URL. I assumed it may create its own SFTP connection or go through scp to copy the files. But DVC local cache can't handle remote location URLs (which strikes to me as normal, since there is a dedicated parameter for SSH cache). But the SSH cache is ignored, even if the data is fetched from an SSH remote.
So far, the only workaround I see is to create a fuse.sshfs mount point in the Linux fstab of every machine that needs to fetch the repo (the Windows user would need to figure out a similar way, maybe with putty?), then use the mounted folder location on the machine as the cache location (thus can't be but in the dvc config file) and do the fetch. Of course, it will create a copy of the whole dataset content over the network.
As far as I understand, setting cache.ssh in such configuration bypass the need to download locally. It is mostly useful when working on the same disk.
yes, that's true. But we before we jump into the details and try to find a workaround, could you please share a bit more details? If you don't download data to any local volume, how do you access it in your scripts/code?
I am trying to access them through any kind of link available.
There is a use case I am planning. I can't download the dataset on the user computer (too big). So the first stage of the pipeline would be a filtering/subselection process. Then, the second would be the training. Thus, on the first stage, I only care about pointers on the data. What matters is that I can download them once the filtering is done.
Is there a better way? Reading the documentation, I thought so, but I am not that sure anymore...
to be honest, I'm still not sure I got the setup from your description - could share some commands, configs, etc?
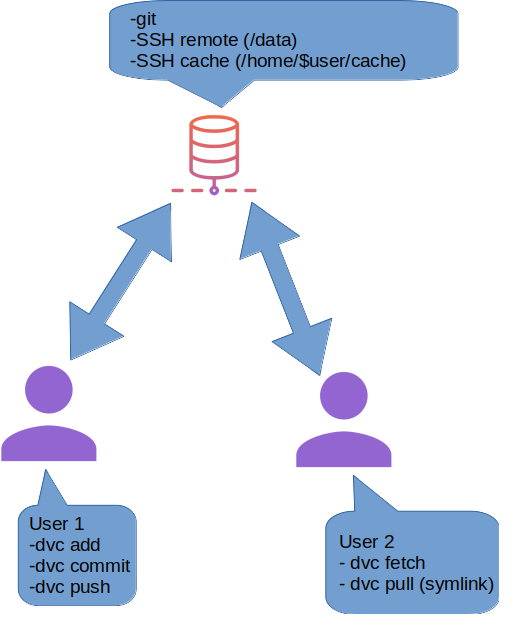
Yes, I did a small picture to explain the workflow a bit, using the DVC icons. Please don't mind my poor graphic skills. Assume that the user 1 is sharing it's data with user 2 through the server.
dmidge8
on 30 Jun 2020
@efiop Arg, I was typing :'(
dmidge8
on 30 Jun 2020
@efiop Thanks! :) What a coincidence though!
dmidge8
on 30 Jun 2020
@dmidge8 Maybe our python API would be useful in your case https://dvc.org/doc/api-reference . It allows you to stream the data directly from remote.
efiop
on 3 Jul 2020
@dmidge8 Were you able to make it work for you?
efiop
on 28 Jul 2020
@efiop Sadly, not yet, but I face another issue that is bothering me (https://github.com/iterative/dvc/issues/4139), and sadly have limited time to work with DVC.
Besides, it is not directly clear to me how I can use the API to do what I want. I would need to dive deeper in it.
dmidge8
on 29 Jul 2020
Closing for now as stale.
efiop
on 7 Sep 2020
Related issues
 tc-ying
·
3Comments
tc-ying
·
3Comments
 ghost
·
3Comments
ghost
·
3Comments
 nik123
·
3Comments
nik123
·
3Comments
 robguinness
·
3Comments
robguinness
·
3Comments
 siddygups
·
3Comments
siddygups
·
3Comments