Dvc: ML experiments and hyperparameters tuning
UPDATE: Skip to https://github.com/iterative/dvc/issues/2799#issuecomment-650464000 for a summary and updated requirements.
Problem
There are a lot of discussions on how to manage ML experiments with DVC. Today's DVC design allows ML experiments through Git-based primitives such as commits and branches. This works nicely for large ML experiments when code writing and testing required. However, this model is too heavy for the hyperparameters tuning stage when the user makes dozens of small, one-line changes in config or code. Users don't want to have dozens of Git-commits or branches.
Requirements
A lightweight abstraction needs to be created in DVC to support hyperparameters-like tiny experiments without Git-commits. Hyperparameters tunning stage can be considered as a separate user activity outside of Git workflow. But the result of this activity still needs to be managed by Git preferably by a single commit.
High-level requirements to the hyperparameters tunning stage:
- Run. Run dozens of experiments without committing any results into Git while keeping track of all the experiments. Each of the experiments includes a small config change or code change (usually, 1-2 lines).
- Compare. A user should be able to compare two experiments: see diffs for code (and probably metrics)
- Visualize. A user should be able to see all the experiments results: metrics that were generated. It might be some table with metrics or a graph. CSV table needs to be supported for custom visualization.
- Propagate. Choose "the best" experiment (not necessarily the highest metrics) and propagate it to the workspace (bring all the config and code changes. Important: without retraining). Then it can be committed to Git. This is the final result of the current hyperparameter tunning stage. After that, the user can continue to work with a project in a regular Git workflow.
- Store. Some (or all) of the experiments might be still useful (in additional to "the best" one). A user should be able to commit them to the Git as well. Preferably in a single commit to keep the Git history clean.
- Clean. Not useful experiments should be removed with all the code and data artifacts that were created. A special subcommand of
dvc gcmight be needed. - [*] Parallel. In some cases, the experiments can be run in parallel which aligns with DVC parallel execution plans: #2212, #755. This might not be implemented now (in the 1st version of this feature) but it is important to support parallel execution by this new lightweight abstraction.
- Group. Iterations of hyperparameters tuning might be not related to each other and need to be managed and visualized separately. Experiments need to be grouped somehow.
What should NOT be covered by this feature?
This feature is NOT about the hyperparameter grid-search. In most cases, hyperparameters tuning is done by users manually using "smart" assumptions and hypotheses about hyperparameter space. Grid-search can be implemented on top of this feature/command using bash for example.
- The ability to run the experiments from
bashmight be also a requirement for this feature request.
Possible implementations
This is an open question but many data scientists create directories for each of the experiments. In some cases, people create directories for a group of experiments and then experiments inside. We can use some of these ideas/practices to better align with users' experience and intuition.
Actions
This is a high-level feature request (epic). The requirements and an initial design need to be discussed and more feature requests need to be created. @iterative/engineering please share your feedback. Is something missing here?
EDITED:
Related issues
2379
https://github.com/iterative/dvc/issues/2532
1018 can be relevant (?)
 dmpetrov
dmpetrov
All 64 comments
I think I almost-but-not-quite understand the aim here. I feel like I'm missing some key concept.
Run dozens of experiments without committing any results into Git while keeping track of all the experiments.
This seems to be almost a contradiction - the most robust way to "keep track" is to commit separately.
Each of the experiments includes a small config change or code change (usually, 1-2 lines).
This could be satisfied by for example by a bash script looping through param choices with @nteract/papermill for notebook users. I think it would be quite hard to try to write a tool to do this in a language/platform agnostic way. It's hard enough with papermill which is pretty niche.
To be all-encompassing we'd have to wind up supporting multiple ways of passing in params: env vars, cli args, sed -r 's/<search>/<repl>/g', and (nightmare) language-specific ways.
see diffs for code (and probably metrics)
Again a papermill-like approach (bash script spawning multiple notebooks and kernels, each with different params, each outputting a dvc metrics-like file) could do this
some table with metrics or a graph. CSV table needs to be supported for custom visualization.
Would need to create a formal metrics specification, or at least be very intelligent about automatically interpreting and visualising whatever the end-users throw at us.
Choose "the best" experiment (not necessarily the highest metrics) and propagate it to the workspace
Not sure how "best" can be automated with "not necessarily the highest metrics"
- Store./6. Clean./7. [*] Parallel.
All could be handled by the bash script.
Experiments need to be grouped somehow.
Probably part of any potential formal metrics spec.
This feature is NOT about the hyperparameter grid-search
and
create directories for each of the experiments [...] directories for a group of experiments
Really seems like end-users writing bash/batch scripts would solve this.
Overall I feel like this has two requirements:
- implement (or create) a formal metrics spec (which we can then use for visualisations etc)
- document/add a tutorial for writing scripts to manage multiple experiments
I'd be against designing (1) from scratch owing to:

Also vaguely related maybe worth considering org-wide project boards (https://github.com/orgs/iterative/projects) for managing epics as well as cross-repo issues (e.g. https://github.com/iterative/dvc.org/pull/765 and https://github.com/iterative/example-versioning/pull/5)
 casperdcl
on 16 Nov 2019
casperdcl
on 16 Nov 2019
@casperdcl good questions but let's start with the major one:
Run dozens of experiments without committing any results into Git while keeping track of all the experiments.
This seems to be almost a contradiction - the most robust way to "keep track" is to commit separately.
Let's imagine you are jumping to a hyperparameter tunning stage. You need to run a few experiments. You don't know in advance how many experiments are needed. Usually, it takes 10-20 but it might easily take 50-100.
Questions:
- What abstraction would you choose? Commits to master? A new branch and commits in the branch? Is it okay for you to have 50 commits in a row?
- You end up having 50 commits. How to get all the results and compare them to find the best result?
- If Git abstractions work and new standards are not needed why a big portion of data scientists (including ex-developers) do not use this and prefer to create 50 dirs instead of 50 commits?
dmpetrov
on 17 Nov 2019
Run dozens of experiments without committing any results into Git while keeping track of all the experiments.
This seems to be almost a contradiction - the most robust way to "keep track" is to commit separately.
Ah I think we were both not using accurate language :) You do indeed want to commit results in some form (metrics for each experiment/summary of metrics/metadata to allow easy reproduction of experiments - which could just be the looping script). You don't necessarily want to commit runs (saved models, generated tweaked source code).
And when I said commit separately I should've just said commit. (Separately implies multiple commits, which isn't necessary unless you want to save each model and its outputs... which may actually still be useful. 1. Run multiple experiments 2. Save each in a separate branch commit 3. Collate metrics and use them to delete most branches. No clear advantage of this over multiple dirs. Maybe if you want to save the 2 best models on two different branches which will then fork?)
I think the rest of my comment dealt with the multi-dir, single-commit approach anyway (which as I understand is what you also intended).
casperdcl
on 17 Nov 2019
Yeah :) Sorry, I put the description in a very abstract form to not to push to any solutions. This abstract form gives a lot of opportunities for different interpretations which is probably the root cause of the misunderstanding. To be clear, I don't see any other solutions besides dirs yet but it would be great if we can consider other options.
I definitely want to give an ability to commit the results (both metrics as well as runs) but not necessarily all the results (ups to a user).
I think the rest of my comment dealt with the multi-dir, single-commit approach anyway (which as I understand is what you also intended).
👍
dmpetrov
on 17 Nov 2019
Preferably in a single commit to keep the Git history clean.
Doesn't sound like clean to me. It would be a very messy commit and if that experiments involve code changes it would be way easier to have a commit for each, this way you can git checkout it.
Additionally, if we have a git commit for each experiment we want to save then it would be very easy to save associated artifacts too.
Not useful experiments should be removed with all the code and data artifacts that were created
We might simply dvc run --no-commit, and no need to gc anything in the end.
Parallel. ... which aligns with DVC parallel execution plans:
Not necessarily, if we make a dir copy for each experiment, than that would be a different dvc repo, and we won't need any parallel processing for single repo.
 Suor
on 18 Nov 2019
Suor
on 18 Nov 2019
What worries me the most is the weight of the project. If we decide to go with dir approach, we need to either make a repo copy for each experiment or somehow link/use dvc controlled artifacts from original repo. I think that copy is fine for first version, but later we need to come up with something that would not duplicate our artifacts. That would probably align with parallel execution plans too.
 pared
on 18 Nov 2019
pared
on 18 Nov 2019
About the whole dir copy thing... The bash loop + papermill workflow I gave as an example (granted only works for python notebooks) would create one dir per test, and said dir would only contain a notebook with one different parameter cell, as well as potentially some outputs. All notebooks would use (i.e. import) the same code and data from the root directory. And all you'd need to commit is the bash loop script & the metrics files from the output directories in order to reproduce/track what happened. May need random.seed(1337) or similar to reproduce identically but you get the idea.
My main concern is this all seems very language-, code layout-, and OS-specific and best left to the user to figure out. I think it would be helpful if we gave a concrete example of how dvc could assist in a workflow (e.g. this dummy C++ program training on this MNIST data on linux with a bash script subbing in (or passing in via CLI params) these 10 different params for 10 output dirs, running 2 jobs at a time, outputting metrics.csv, etc...)
I feel like trying to create an app to automate this process in generic scenarios is a bit like trying to create an app to help people use a computer. Sounds more like a manual/course than a product.
casperdcl
on 18 Nov 2019
Preferably in a single commit to keep the Git history clean.
Doesn't sound like clean to me. It would be a very messy commit and if that experiments involve code changes it would be way easier to have a commit for each, this way you can
git checkoutit.Additionally, if we have a git commit for each experiment we want to save then it would be very easy to save associated artifacts too.
@Suor you are right, but ideally, it should be a user's choice - some folks are very against 50 commits and it would be great to provide some options to avoid this (if we can :) ).
In the dir-per-experiment paradigm, all the experiments might be easily saved in a single commit with all the artifacts (changed files and outputs) since they are separated. What do you think about this approach?
ADDED:
We might simply
dvc run --no-commit, and no need to gc anything in the end.
Yeap. An additional, experiment specific option might be helpful like dvc repro --exp tune_lr
Parallel. ... which aligns with DVC parallel execution plans:
Not necessarily, if we make a dir copy for each experiment, than that would be a different dvc repo, and we won't need any parallel processing for single repo.
First, it looks like we have a bit different opinions regarding implementation. I assume that we copy all the artifacts in an experiment dir which gives us an ability to commit experiments (one by one or in a bulk). While you assume that we clone a repo to a dir. We can discuss the pros and cons of these methods. I won't be surprised if we find more options.
Thus, it depends on implementation. If it is a separate repo as a dir then we cannot commit it in the main repo. In this case, you are right in the above - separate commits above will be required.
If we run in a separate dir with no cloning (just copying and instantiating data artifacts) then we parallel running support might require.
dmpetrov
on 19 Nov 2019
we need to either make a repo copy for each experiment or somehow link/use dvc controlled artifacts
@pared you are right. I don't think we can afford to make a copy of data artifacts. So, there is only one option - the most complicated one, unfortunately.
dmpetrov
on 19 Nov 2019
My main concern is this all seems very language-, code layout-, and OS-specific and best left to the user to figure out.
Exactly. Notebook is kind of a specific language. I'd suggest building a language-agnostic version first based on config files or code file changes - copy all code in a dir, instantiate all the data files and run an experiment. Later we can introduce something more language/Notebook specific.
I think it would be helpful if we gave a concrete example of how
dvccould assist in a workflow
Totally! We definitely need an example. This issue was created to initiate the discussion and collect the initial set of requirements. But the development process of MVP should be example-driven.
I feel like trying to create an app to automate this process in generic scenarios is a bit like trying to create an app to help people use a computer. Sounds more like a manual/course than a product.
I see this as an attempt to help users use one of the "best practices" - save all the experiments (in dirs :) ) and compare the results.
dmpetrov
on 19 Nov 2019
What about trying to automatically generate a Git submodule for experiments? 1. Somehow mark code or data files as "under experimentation". 2. Watch those files and make a commit every time they're written (similar to IPython Notebook checkpoints) 3. Tell DVC to stop watching this experiment.
And do we have any ideas on what the interface would look like? Another command, a separate tool, a UI?
a big portion of data scientists (including ex-developers)... prefer to create 50 dirs instead of 50 commits
If this is the case. Perhaps a file linking system or UI that shows the user a growing set of virtual dirs simultaneously, one per experiment. Either based in the single-commit, multiple dir strategy, the git submodule, or something else.
 jorgeorpinel
on 19 Nov 2019
jorgeorpinel
on 19 Nov 2019
@dmpetrov Do you think that we could restrict (at least in the beginning) experiments feature to systems where linking is possible? That would eliminate the risk of experiment throttling disk space. Also in such case implementation does not seem too hard. We would just need to create a repo with default *-link cache type and point cache to the master project cache.
pared
on 19 Nov 2019
What about trying to automatically generate a Git submodule for experiments?
@jorgeorpinel Might be I didn't get the idea but Git-submodule means a separate repo. So, we end up having 50 Git repositories instead of 50 commits. It looks like an even more havier approach that we currently have.
And do we have any ideas on what the interface would look like? Another command, a separate tool, a UI?
Initially, the command line one. I see that as part or repro. Line vi config.yaml && dvc repro --exp tune_lr - will create a dir with changed files and new outputs.
dmpetrov
on 20 Nov 2019
No, just one submodule with a single copy of the source code, and 50 commits in it. Although now that I think about it, it's similar to just making a branch, and the latter is probably easier...
jorgeorpinel
on 20 Nov 2019
@pared No restriction is needed. We should use link-type that was specified by the user. My point is - we cannot create a copy if the user prefers reflinks. Also, I don't think we need to create any repo. Experiments should work in an existing repo.
dmpetrov
on 20 Nov 2019
@dmpetrov I agree that experiments should work in existing repo. What I have in mind by "creating the new repo" was that I imagined, that we will store each experiment as a current repo "copy" in some special directory, like .dvc/exp/tune_lr_v1 and so on. Are we on the same page here? Or do you imagine it differently?
pared
on 20 Nov 2019
@pared yes, it is very likely we will need to store a copy of the current repo. It might be directly in project root dir tune_lr_v1/.
dmpetrov
on 21 Nov 2019
By the way, I have not seen anyone mentioning MLflow. I haven't tried it myself yet, but the description promises to manage the ML lifecycle, including experimentation and reproducibility. How did they solved this issue? Any chance to just integrate/build on top of that or some other similar tool? Or an API for integrating third-party ML lifecycle tools?
 alexvoronov
on 21 Nov 2019
alexvoronov
on 21 Nov 2019
In the dir-per-experiment paradigm, all the experiments might be easily saved in a single commit with all the artifacts (changed files and outputs) since they are separated. What do you think about this approach?
I thought of those dirs as copies of a git/dvc repo. So if you commit it's state, probably to a branch, to a separate commit you might access all the artifacts easily. It will work with gc seamlessly and so on. A copy dvc repo also retains all the functionality, you may cd into it and explore it. You can diff it to original with any dir diff tool, like meld. This are supposed to share cache and use some light-weight links.
Do you suggest a copy of everything in a subdir, but still being the same git/dvc repo? And then committing the whole structure. Not sure how this will work, but I haven't thought about that much.
And, yes if that is the same repo you most probably need parallelized runs.
The thing is with subdirs in a single repo, we can't refer to different versions of an artifact by changing rev, we will also need to change path. And those paths won't be consistent between revs. This might be an issue or not.
Also, how do you mainline some experiment then? Do we need som specific dvc command for that?
If we run in a separate dir with no cloning (just copying and instantiating data artifacts) then we parallel running support might require.
Checking out artifacts is an issue both implementations have. We can simply checkout artifacts for a new copy if we use fast links. But if we use copy we might want to make some lightweight links to already checked out copies in the original dir. This could be ignored or at least wait for a while though.
We have @slow_link_guard to at least keep people informed about that.
What about trying to automatically generate a Git submodule for experiments?
I don't see any advantage of a git submodule over a simple clone. Why should we complicate this?
Initially, the command line one. I see that as part or repro. Line vi config.yaml && dvc repro --exp tune_lr - will create a dir with changed files and new outputs.
I see that a basic building block is creating a dir copy (a clone or just a copy) and checking out artifacts there. Maybe cd there. Then a user may do whatever he/she wants inside:
dvc exp tune_some_thing
dvc repro some_stage.dvc
cd ../..
cd exp/tune_some_thing
# later
vim ...
dvc repro some_stage.dvc
Or maybe it's ok to bundle it from the start, like @dmitry envisions. Not sure --exp under repro or a separate command is better:
dvc experiment <experiment-name> some_stage.dvc
# or
dvc exp <experiment-name> some_stage.dvc
# or even
dvc try <experiment-name> some_stage.dvc
We will need commands to manage all these, probably. If these are just dirs then we can commit everything as is, which is a plus. But we will still need something to diff, compare metrics, mainline an experiment.
Since these are just dirs (and clones are mostly dirs too) we get some of these for free, which I like a lot:
meld . exp/tune_some_thing # compare dirs
rm -rf exp/tune_some_thing # discard experiment
cp -r exp/tune_some_thing . # mainline, not sure this one is correct
Regarding the MLFlow, idea - it looks like an augmented conda env.yml file which supports tracking input CLI params and you need to use their python API for logging outputs/results/metrics.
They do have a nice web UI for visualising said logs, though.
casperdcl
on 21 Nov 2019
I don't see any advantage of a git submodule over a simple clone.
The thing is that if you clone a Git repo inside a Git repo and add it, Git just ignores the inner repo's contents. I think it stages a dummy empty file with the name of the embedded repos' dir. So we may be forced to use submodules, depending on the specific needs. Here's Git's output when you clone a repo inside a repo and stage it:
warning: adding embedded git repository: {INNER_REPO}
hint: You've added another git repository inside your current repository.
hint: Clones of the outer repository will not contain the contents of
hint: the embedded repository and will not know how to obtain it.
hint: If you meant to add a submodule, use:
hint:
hint: git submodule add <url> {INNER_REPO}
hint:
hint: If you added this path by mistake, you can remove it from the
hint: index with:
hint:
hint: git rm --cached {INNER_REPO}
hint:
hint: See "git help submodule" for more information.
I thought of those dirs as copies of a git/dvc repo.
@Suor it looks like we are on the same page with that.
Do you suggest a copy of everything in a subdir, but still being the same git/dvc repo? And then committing the whole structure. Not sure how this will work, but I haven't thought about that much.
And, yes if that is the same repo you most probably need parallelized runs.
Right. Yes, I think we should consider this subdir-in-the-same-repo option. This allows a user to commit many subdirs in a single commit or just remove subdirs using a regular rm -rf tune_lr_v1/.
The thing is with subdirs in a single repo, we can't refer to different versions of an artifact by changing
rev, we will also need to changepath. And those paths won't be consistent between revs. This might be an issue or not.
If you copy a whole structure and change paths in dvc-files it should not be an issue except the cases when a whole path was used like /Users/dmitry/src/myproj/file.txt. I don't think we should care about this case.
Also, how do you mainline some experiment then? Do we need som specific dvc command for that?
🤷♂️ The option I like the most so far: dvc repro --exp tune_lr_v1. A separate command is fine: dvc exp tune_lr_v1
We can simply checkout artifacts for a new copy if we use fast links. But if we use copy we might want to make some lightweight links to already checked out copies in the original dir.
I don't think we need to invent something new here. We should use the same data file liking strategy as specified in a repo. From the file management point of view, the experiment subdirs play the same role as branches and commits and should use the same strategy.
Or maybe it's ok to bundle it from the start, like @dmitry envisions. Not sure
--expunderreproor a separate command is better:
Yeah. I'd prefer to create and execute an experiment as a single, simple command. No matter if it is repro or a dedicated one.
Since these are just dirs (and clones are mostly dirs too) we get some of these for free, which I like a lot:
meld . exp/tune_some_thing # compare dirs rm -rf exp/tune_some_thing # discard experiment cp -r exp/tune_some_thing . # mainline, not sure this one is correct
Exactly! We will get a lot of stuff for free. More than that - it should align well with data scientists' intuition of creating dirs for experiments.
The last command (cp -r ext/...) won't work, unfortunately - we might need a new command dvc exp propagate exp/tune_some_thing (to the current dir by default)
dmpetrov
on 22 Nov 2019
Any chance to just integrate/build on top of that or some other similar tool? Or an API for integrating third-party ML lifecycle tools?
@alexvoronov the integration itself is a good idea. Unfortunately, DVC experiments cannot be built on top of MlFlow because MlFlow has a different purpose and focuses on metrics visualization. But the visualization part can be nicely implemented on top of existing solutions. There are a few more MlFlow analogs: Weights & Biases, comet ml and others. It would be great to create a unified integration with these tools.
@casperdcl brought a good point about conda env.yml. It might be another integration.
We should definitely keep the UI and visualization in mind but I would not start with that.
dmpetrov
on 22 Nov 2019
Yeah. I'd prefer to create and execute an experiment as a single, simple command. No matter if it is repro or a dedicated one.
@dmpetrov how would this work? What I have in mind is:
- doing some changes in my repo, not necessarily committing them
- running
dvc repro --exp tune_lr train_model.dvc dvctakes care of creating an experiment directory and moving all the stuff there, also running
What I don't like about incorporating experiments into repro is that it assumes that we want to run the experiment. Will it always be the case?
What if I want to prepare a few experiment "drafts" by editing my repo, and then, at the end of the day, just dvc experiment run tune_lr tune_lr_v1 tune_lr_v2, go home and get back to finished tasks?
I think the experiment should be a separate command that has three main steps:
- create a directory with an experiment
- run the experiment(s)
- choose experiment(s) which you would like to preserve
First two could be joined into one with some flag like dvc experiment --run tune_lr
I want to get back to creating the experiment directory:
@pared yes, it is very likely we will need to store a copy of the current repo. It might be directly in project root dir tune_lr_v1/.
I think it should not be in the project root dir.
- In the case of several dozens of experiments, root dir will look terribly
- removing unwanted experiments will be hell if someone uses "creative" naming
If experiments will be in dedicated directory (.experiments, .dvc/exp or whatever):
- easy to
.gitand.dvcignore - finished with experimenting? no problem just
rm -rf .experiments
pared
on 28 Nov 2019
@pared first of all let me make the disclaimer that I have not followed this discussion very carefully and I am not sure that I understand all the ideas presented here. So, it is quite possible that I don't know what I am talking about.
What if I want to prepare a few experiment "drafts" by editing my repo, and then, at the end of the day, just
dvc experiment run tune_lr tune_lr_v1 tune_lr_v2, go home and get back to finished tasks?
I think the experiment should be a separate command that has three main steps:
- create a directory with an experiment
- run the experiment(s)
- choose experiment(s) which you would like to preserve
Using a command like dvc experiment ... seems interesting to me.
@pared is it possible to show with a simple bash script or with a simple example what the command dvc experiment create ... is supposed to do? Or is it possible to explain how we could do this manually without using dvc experiment?
If experiments will be in dedicated directory (
.experiments,.dvc/expor whatever)
If these experiments are going to be managed transparently (meaning that the users only use dvc experiment ... to manage them, don't touch them manually), then it seems a good idea to use something like .dvc/experiments/.
 dashohoxha
on 29 Nov 2019
dashohoxha
on 29 Nov 2019
@dashohoxha
I will try to explain first, if it will not be enough, I can try to prepare some draft:
- The user makes some changes inside repo to adjust repo state to his experiment (eg change fully connected model code to CNN in some image recognition project, change number of layers, change learning rate adjustment algorithm), they will probably not be committed to the current branch, but it's up to further discussion.
The user runs
dvc experiment create {ename}, dvc copies current repo state to.dvc/experiment/{ename}, and links artifacts properlyThe user can run the experiment with another command.
There is a set of commands allowing to manage experiments (choose "the winner" and move it to the current repo, choose few "winners" and [for example] make branch from each one).
So in few words experiment create would be advanced cp . .dvc/experiment/{ename}.
What do you think about that?
pared
on 29 Nov 2019
So in few words
experiment createwould be advancedcp . .dvc/experiment/{ename}.
So, basically you want to clone all the data and DVC-files to an experiment directory, which can use the same cache (.dvc/cache/) as the main project. With a deduplicating/reflink filesystem this should work.
It is not clear whether you modify the pipeline (or the parameters) of an experiment before you create it or after you create it, and how you are going to do it.
[By the way, rsync might be a better option than cp in this case, but this is not relevant to the discussion.]
dashohoxha
on 29 Nov 2019
It is not clear whether you modify the pipeline (or the parameters) of an experiment before you create it or after you create it, and how you are going to do it.
I believe that user should be able to fix something after it is created, but I think that main use case should be focused on modifying before experiment creation. In other case, we would be just copying and making user to manually enter particular dir, which does not sound too welcoming.
I think that flow like edit -> create experiment -> git reset -> edit .... would be better, especially in use cases when one develops in IDE or notebook
pared
on 29 Nov 2019
I think that main use case should be focused on modifying before experiment creation
But how would you track these changes (so that you can reproduce the experiment, if needed). By committing them to Git?
dashohoxha
on 29 Nov 2019
I think that we don't want to commit them in any way until the user decides so. They are stored in their own experiment repos, and when the user is satisfied with their performance, just dvc experiment pick {ename}. Only then it would be committed to the main repo.
pared
on 30 Nov 2019
I think that we don't want to commit them in any way until the user decides so. They are stored in their own experiment repos, and when the user is satisfied with their performance, just
dvc experiment pick {ename}. Only then it would be committed to the main repo.
Seems reasonable to me.
However, instead of dvc experiment create {ename} I would prefer dvc clone {src_exp} {dst_exp} where {src_exp} is the directory of the source experiment and {dst_exp} is the directory of the destination. This would also cover the case when we want to base an experiment on another one (modify an existing experiment to create another one).
It would basically be like rsync, but some paths maybe need to be fixed on the DVC-files, configuration files, etc.
Deleting an experiment may be as easy as rm -rf {exp_dir}.
dashohoxha
on 1 Dec 2019
- doing some changes in my repo, not necessarily committing them
- running
dvc repro --exp tune_lr train_model.dvcdvctakes care of creating an experiment directory and moving all the stuff there, also running
Yes. That's what I have in my mind.
What I don't like about incorporating experiments into
reprois that it assumes that we want to run the experiment. Will it always be the case?
Sure. It might be a different command if we have a good reason.
What if I want to prepare a few experiment "drafts" by editing my repo, and then, at the end of the day, just
dvc experiment run tune_lr tune_lr_v1 tune_lr_v2, go home and get back to finished tasks?
It seems like a different scenario - auto-hyper param tunning or a grid-search with a custom grid. We should keep these scenarios in mind but the primary use case for this issue is:
- make a small change
- push a button
- get a result in a dir
- propagate the result to master if needed.
And you are absolutely right! It might be beneficial to give an option of separating an experiment creation and experiment run. It might be dvc exp --dry-run or something similar. This should help us in future scenarios.
@pared yes, it is very likely we will need to store a copy of the current repo. It might be directly in project root dir tune_lr_v1/.
I think it should not be in the project root dir.
- In the case of several dozens of experiments, root dir will look terribly
- removing unwanted experiments will be hell if someone uses "creative" naming
Right. Users should be able to "hide" them into some dir. Like exp/tune_lr_v1.
I probably didn't communicate that properly. What I meant is - we should not limit users from custom directories (even a project root) and shouldn't limit by a single dir like .dvc/exp/ without a good reason.
If experiments will be in dedicated directory (
.experiments,.dvc/expor whatever):
- easy to
.gitand.dvcignore
Should be the experiment ignored? I'd expect to have at least some of them in my Git history.
- finished with experimenting? no problem just
rm -rf .experiments
The same if you store experiments in a project root.
dmpetrov
on 2 Dec 2019
If we don't say where people should put their experiments then experiments need to be referenced by their path for all uses:
- listing experiments with some metric
- reintegrating an experiment
If we don't put them to standard location like <repo-root>/experiments/<exp-name> then people might:
cd some-topic
dvc repro thing.dvc --exp try_this
# ... hack ...
dvc repro thing.dvc --exp exp/t1
# ... hack ...
dvc repro thing.dvc --exp exp/t2
# ... hack hack ...
dvc repro thing.dvc --exp exp/new-approach
# list experiments
ls exp try_this # kind of manual
# list metrics, some repetition
dvc metric show exp/*/some-topic/metric.json try_this/some-topic/metric.json
# list diffs
... ???
# reintegrate
dvc integrate exp/new-approach # better command name?
Note that we need to use full path to metric.json, which might be surprising to the user. We can't copy only the part of the repo because something outside some-topic might be referenced.
Overall exp as a dir referenced as a dir works ok though.
Suor
on 12 Dec 2019
Interesting. I kind of wanna help out, but the current way DVC works is just too far from my own mental model, so my ideas would probably require very serious changes that most contributors are probably not willing to buy into. I will try to describe it anyways, and then you can take it or leave it :)
As I see it there is two underlaying questions: One is about parameterised pipelines, and the other is about doing fast iterations locally. Lets take them in that order:
Parameterised pipelines: At the very core, I think DVC fails at distinguishing between "raw data" and "produced data". A raw dataset is a constant immutable thing. You might want to change it at some point, and this is why you need data versioning in the first place. This aligns the "Data is immutable" here https://drivendata.github.io/cookiecutter-data-science/#data-is-immutable and the definition os constants here https://www.brandonsmith.ninja/blog/three-types-of-data). And this is where DVC shines! However, a dataset or a model or any other artifact the was _produced_ by raw data, code, and parameters are just deterministic products (in a broad understanding of "deterministic"). Produced data should not by manually committed since it is a direct consequence of other stuff that is already committed. Instead, it should just be computed and cached using hashes. If you can switch to this way of viewing an experiment, then the solution to the problem is straight forward: Just add parameters to the dependency graph.
Local development: Everything that dmpetrov describes is what I would call "local development", so this should also not be tracked. We should still be able to benefit from the cached upstream "produced data" though. At some point when the developer is ready for an actual code change (to be committed, shared and reviewed by peers), he/she commits these changes. To a branch. Branches are the perfect fit for experiments in my point of view. If the experiment is successful it should be merged back into master at some point.
 elgehelge
on 21 Feb 2020
elgehelge
on 21 Feb 2020
@elgehelge though you should bear in mind that you may indeed want to commit produced data if you view it as useful artefacts that are time-consuming to "deterministically" re-generate (e.g. a trained machine learning model, a binary package, a picture to display on a webpage). I think DVC does indeed distinguish between "produced data" (artefacts, outputs) and "raw data" (immutable, inputs) if you look at pipelines (or e.g. the arguments of dvc run which distinguish between outs and deps).
casperdcl
on 21 Feb 2020
I'm looking for ways to tune hyperparameters too. I have a pipeline that first does some pre-processing then trains a model at the end. One of the pre-processing steps requires a threshold to be set, and so I want to be able to try many different values to see how the final trained model is affected. There are thousands of thresholds I may want to try.
A parameterized pipeline (@elgehelge) sounds like exactly what I'm looking for. I envision something like this: dvc repro train_model.dvc -my_threshold 123. But I'm not sure what I'd expect DVC to do with the file paths, since they are not dynamic.
One hack I'm considering, in the meantime, is to put my parameter values (thresholds) into a text file and add it as a dependency (to the stage that uses it). Then I would do a repro, change the value in the text file, and repeat. As for the output files, I would copy the files I want to keep into a unique directory (not under DVC control) before running repro again. The procedure would look something like this (and of course I'd write a script to automate it):
- set parameter value in
my_threshold.txt(e.g.threshold = 10) - run
dvc repro train_model.dvc - (dvc would detect that one of the pre-processing stage's dependency has changed and would rerun it along with the stages that follow; it would know not to rerun any stages prior that don't depend on the parameter)
- run
mv output/trained_model_and_metrics_etc.zip tuning_experiment/0001/ - set _new_ parameter value in
my_threshold.txt(e.g.threshold = 20) - run
dvc repro train_model.dvc - run
mv output/trained_model_and_metrics_etc.zip tuning_experiment/0002/ - and repeat...
Once done, I'd write a script to grab all the files in tuning_experiment and plot the thresholds vs performance metrics.
While I think this solution will work for me, it feels wrong because I'm throwing away the ability for DVC to track the models and metrics. I'm essentially using DVC as a caching mechanism and nothing more. Lastly, at the end of the day, the final output I'm most interested in is the plot of thresholds vs performance metrics, not any of the pipeline's outputs themselves.
(p.s. I just started using DVC recently, and I really like it so far. I hope my use case will help with the discussion and move this feature forward!)
 skylogic004
on 21 Feb 2020
skylogic004
on 21 Feb 2020
@elgehelge thank you for sharing your mental model! I really appreciate it. Your thoughts correlate with our much more than you might think. You just need to accept that not everything is implemented yet and in some directions we still have open questions.
Parameterised pipelines: We understand the pipeline parametrization problem #1462. We even had discussions about extracting results of runs in a separate run/build cache #1234 (note, the description contains "deterministic" as you suggested). Unfortunately, we didn't have time to move to this direction yet. In the last year, we were busy making DVC stable, by optimization of the existed "dataset management" scenarios and another "dataset" scenarios like dvc import/get. Today pipeline parametrization could be done through some workarounds: config file as a dependency (see @skylogic004) or making a pipeline more lightweight by extracting dataset (and then dvc import) with modification of the lightweight pipeline. As far as I understand you (and @skylogic004 from GH), you suggest a simplified version of #1462 - that looks like a very good option - I'll create an issue.
Local development: You are absolutely correct that this issue is mostly about local experimentation experience. It aims to simplify experimentation experience and solve "1000-branches" problem in the hyperparameters tuning case. However, we de-prioritized this issue in favor to CI/CD direction which we are working on right now (this project is outside of core-dvc and not opened yet but you might find some related issues in core-dvc #2995, #2998, #2994). In CI/CD these experimentation problems (including 1000-branches problem) could be solved in a higher abstraction level without introducing additional concepts to DVC - pretty much as you described.
To me, it looks like we don't have any disagreements in the DVC roadmap. We just need to implement all the stuff we have in our plans - "The film is ready. It remains only to shoot it" (Rene Clair) 😄
dmpetrov
on 22 Feb 2020
@skylogic004 thank you for your replay. I responded to @elgehelge above re most of your questions but I'd like to mention that...
While I think this solution will work for me, it feels wrong because I'm throwing away the ability for DVC to track the models and metrics. I'm essentially using DVC as a caching mechanism and nothing more.
... you are right - DVC support might be very helpful in that stage. And we should come up with a solution.
Lastly, at the end of the day, the final output I'm most interested in is the plot of thresholds vs performance metrics, not any of the pipeline's outputs themselves.
This is very good inside. Thank you for pointing to this!
dmpetrov
on 22 Feb 2020
For the record: another discussion on discord https://discordapp.com/channels/485586884165107732/563406153334128681/707272131834150933
 efiop
on 5 May 2020
efiop
on 5 May 2020
Wow this one is long! Should we try to summarize what's left into a separate issue? (and close this one as done) Perhaps an epic with pending stuff from here and a list of related issues such as #3633 or #4069 (which I just opened).
jorgeorpinel
on 19 Jun 2020
The run-caches #1234 was released in DVC 1.0. It opens a new opportunity for implementing the ML experiments on top of it instead of creating directories per experiment (see 1st post in the issue).
In fact, the runs that are stored in the run-cache are already experiments - the user can get the experiment results (generated ML models and metrics) without retraining. The output "experiments" results are already there, we just need to extend it by the inputs and proper API/commands.
First, let's establish the terminology:
- Persistent experiment\run - an experiment that is based on Git commit.
- Ephemeral experiment\run - an experiment that is based on run-cache and is not committed to Git.
Run might be a good shortcut term for experiment.
The missing functionality in run-cache or a requirements for experiments commands (those are the rephrased initial requirements):
- Navigation: what experiments/runs were executed (for a given commit/persistent experiment)?
- Experiment diff: See the metrics and params difference for all ephemeral experiments (for a given commit).
- Checkout experiment: Get an experiment with all the hyperparams, code and data to the workspace.
- Parallel execution of experiments.
- Execute with hyper params set - as we discussed we can change hyper params and execute it.
- (Optional) Delete/GC an experiments.
- (Optional) Delete/GC all ephemeral experiments (for a given persistent experiment).
Open questions:
- Can an ephemeral experiment be based on another ephemeral experiment, or only on persistent one.
- yes, especially if we decide to support circular dependency for data (reusing weights/ML models, "model surgery").
- A separate set of experiment commands or embed into the existing one?
- to the existing one when it is possible (like reusing
dvc checkout), ok if not (likedvc exp diff). Otherwise, it might create too much complexity for users.
- to the existing one when it is possible (like reusing
- To store experiments (for diff and checkout), should we store only params, params and
dvc.yaml, data (dvc files), or all including source code (at least changed code)?
- probably everything. but we need to come up with a good structure to store the diffs.
- How to address the experiments?
- we need to have something like checksums. probably in a different format to distinguish them from Git commits. Like
e-cf5e7f4
- we need to have something like checksums. probably in a different format to distinguish them from Git commits. Like
- Do we need human-names for experiments?
- probably not. some users will create dozens or thousands of experiments in a single hour.
Proposed commands/API (corresponded to the requirements from above):
dvc exp list/show [checksum]- shows a table with the experiments. Probably with metrics.dvc exp diff [checksum [checksum]]- metics, hyperparams (might be dataset versions) diff. Similar todvc metrics/plots diffdvc checkout e-checksum- checkout an experiment, a persistent or ephemeral one.dvc repro --paralleldvc repro --params lr=0.04,process.threshold=0.93dvc exp gc e-checksum- e-checksum is id of an ephemeral experiment.dvc exp gc --all checksum- checksum is id of a persistent experiment.
@iterative/engineering, @elgehelge, @alexvoronov, @casperdcl, @skylogic004 please share your thoughts on experiments.
PS: Some ideas on implementation in run-cache side (a bit outdated):
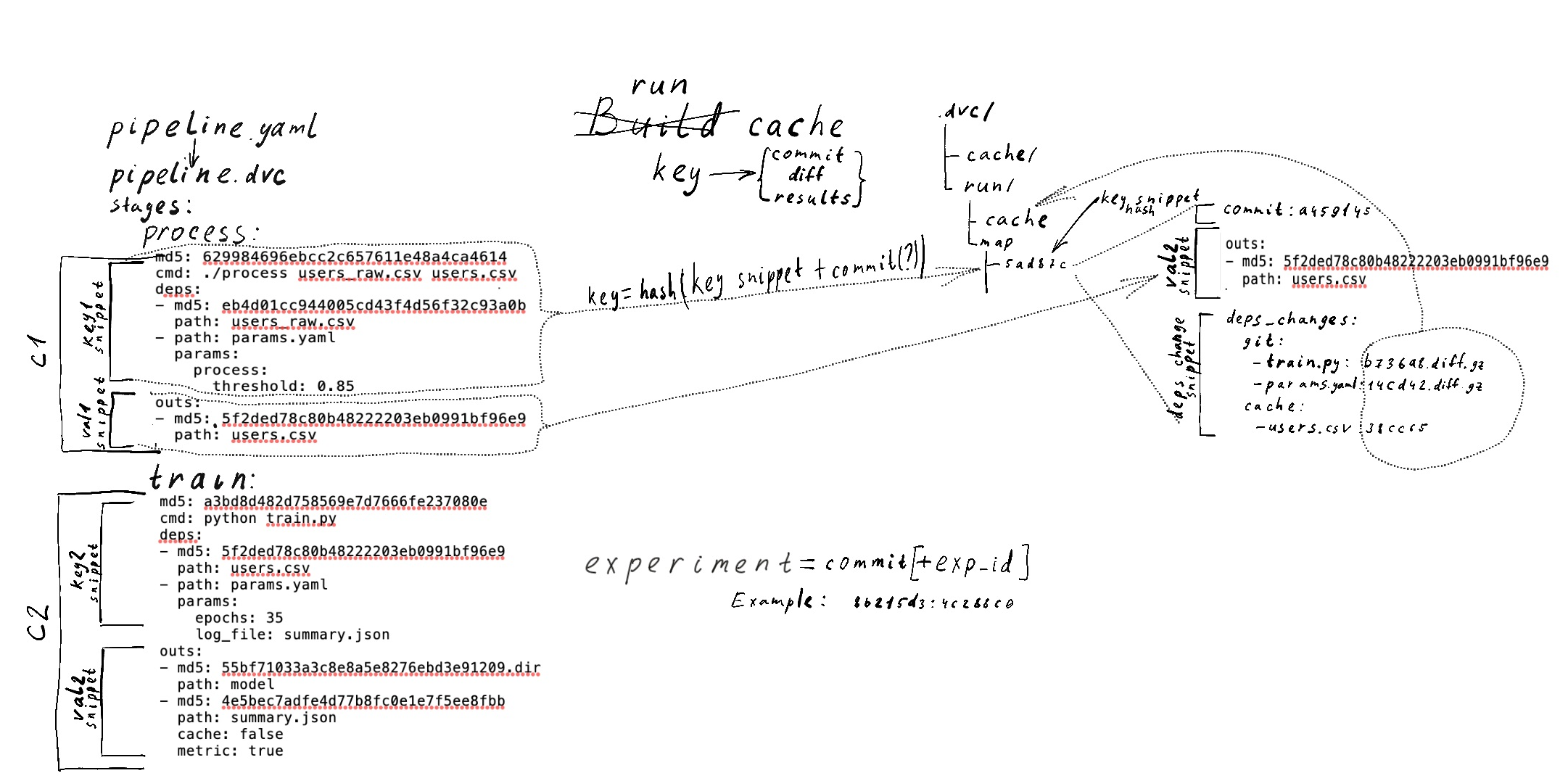
dmpetrov
on 27 Jun 2020
Parallel execution of experiments.
Since DVC doesn't have an execution engine what would DVC's role be in this?
 elleobrien
on 27 Jun 2020
elleobrien
on 27 Jun 2020
Since DVC doesn't have an execution engine what would DVC's role be in this?
Good question. To make it clear - there are no plans to go to the data engineering/AirFlow world.
We need very simple executors -just execute by default as we do now. Additionally, we can implement more runers:
- Local. For some stages, it is ok to run in parallel in a single machine.
- CI/CD.
- Just remote through some (terraform) script.
PS: I should have probably mentioned that the parallel run is an optional requirement but a very powerful case tho.
dmpetrov
on 27 Jun 2020
let's establish the terminology
- prefer saved/committed/tracked rather than "persistent"
- prefer unsaved/uncommitted/untracked/cached rather than "ephemeral"
(Optional) Delete/GC all ephemeral experiments (for a given persistent experiment)
- seems like a necessity to me; otherwise can easily run out of disk space
Anyway I don't understand how a user will define (i.e. create) experiments. Is it simply issuing multiple dvc run commands without committing between them? If so,
- how would you define multiple experiments without running them with the intention of subsequently doing
dvc repro --parallel? Presumably need to introducedvc run --dry-with-cache? - how would you delete one experiment?
Also I'd like to see experiment params lists to quickly define (i.e. create) multiple experiments: something like dvc repro --exp-params lr=[0.04,0.08,0.16] --params process.threshold=0.93 --parallel
Also in addition to --parallel I'd like to see --sequential (i.e. run all experiments but not in parallel since my GPU's memory can't handle it)
casperdcl
on 27 Jun 2020
Is it simply issuing multiple
dvc runcommands without committing between them? If so,
Yes.
- how would you define multiple experiments without running them with the intention of subsequently doing
Just run one by one:
$ vi train.py
$ dvc repro
...
Experiment e-28479b0
$ vi train.py
$ dvc repro
...
Experiment e-186f997
$ dvc exp list
e-28479b0
e-186f997
$ dvc checkout e-28479b0
$ git add train.py dvc.lock
$ git commit -m 'Dropout increase'
- how would you delete one experiment?
$ dvc exp gc e-186f997 # Or even `dvc gc e-186f997`
Also I'd like to see experiment params lists to quickly define (i.e. create) multiple experiments
Grid search could be a great next step. Not in the first iteration.
dmpetrov
on 28 Jun 2020
Run might be a good shortcut term for experiment.
I suggest sticking to the term run since this aligns with other tools like KubeFlow and MLFlow
KubeFlow run: "A run is a single execution of a pipeline."
KubeFlow experiment: "An experiment is a workspace where you can try different configurations of your pipelines. You can use experiments to organize your runs into logical groups"
MLFlow run: "MLflow Tracking is organized around the concept of runs, which are executions of some piece of data science code."
MLFlow experiment: "Finally, runs can optionally be organized into experiments, which group together runs for a specific task."
elgehelge
on 29 Jun 2020
probably not. some users will create dozens or thousands of experiments in a single hour.
Then we will need a proper way to navigate between experiments. I guess some command that would let user choose "the best N runs" could be useful.
The problem will definitely be plots: they cannot be as easily compared as metrics.
pared
on 30 Jun 2020
I guess some command that would let user choose "the best N runs" could be useful.
The problem will definitely beplots: they cannot be as easily compared as metrics.
The same problem with metrics - usually it is not easy to find "the best", you always looking for a compromise. dvc exp show should display the experiment and metrics to help with a decision.
dmpetrov
on 30 Jun 2020
- how would you define multiple experiments without running them with the intention of subsequently doing
Just run one by one
No, I just realised the feature I was asking for maybe already exists: dvc run --no-exec && dvc commit (assuming that this will save to the experiment cache such that a subsequent dvc repro --paralel will indeed run all experiments).
I'm still very confused about how experiments are defined. dvc run or vi train.py && dvc repro?
- if it's only
dvc run, this is wrong.dvc runboth creates an experiment and runs it. AFAIK it's actuallydvc run --no-exec && dvc commitwhich just creates an experiment as requested. - if it's only
vi train.py && dvc repro, then I'd request addingdvc repro --no-execto add to therun-cachewith the intention of running later.
Both seem pretty clunky interfaces to the extent that I'd genuinely prefer not to use either and instead continue to write my own marginally less painful bash scripts.
From an implementation standpoint unfortunately maybe they're required before implementing grid search (which I would use).
casperdcl
on 30 Jun 2020
Run might be a good shortcut term for experiment.
Agree, in the context of dvc run (we are keeping that command name right?) "Experiment" . For example let me rephrase some of the req's using this rule:
- Navigation: what runs were executed for a given commit?
- Run diff: Compare metrics and params among runs (for a given commit)
- Checkout experiment: Get an experiment with all the hyperparams, code and data to the workspace.
Do you mean a run here? I.e. non-committed to Git
6/7. (Optional) Delete/GC
I think this is very important. Caching all those intermediate results can result in many multiples of sotrage requirement for people. I would even make the run-cache pushing optional (require an explicit option e.g. dvc push --run-cache (may already be the case?).
A separate set of experiment commands or embed into the existing one?
What about overloading dvc run for this? That is, if we also introduce dvc stage as a helper to define stages in dvc.yaml
How to address the experiments?
How about dvc exp list (and diff) listing all the experiments and assign them a 1-based index (1,2,3) ? Their "full path" could be a combo of the Git commit SHA + index e.g. cf5e7f4+1. I'm not sure checksums are needed if there's no altering the run history (not reinventing Git).
jorgeorpinel
on 1 Jul 2020
Do you mean a run here? I.e. non-committed to Git
Yes
What about overloading
dvc runfor this? That is, if we also introducedvc stageas a helper to define stages in dvc.yaml
🤔 Interesting idea. My concern - it might take time to transfer from run to stages. This might block the experiments a lot.
Their "pull path" could be a combo of the Git commit SHA + index e.g.
cf5e7f4-1.
Good idea. We should consider it.
dmpetrov
on 2 Jul 2020
No, I just realised the feature I was asking for maybe already exists:
dvc run --no-exec && dvc commit(assuming that this will save to the experiment cache such that a subsequentdvc repro --paralelwill indeed run all experiments).
@casperdcl I have a feeling that we have a different understanding of the workflow. First of all, I'd forget about --parallel for now because this is a technical detail. With the new experiments, we are working in a regular workflow, but it gives us an ability to return back to not-committed runs.
The experiments are about all the runs - dvc run as well as dvc repro.
dmpetrov
on 2 Jul 2020
Setting aside the issues of command usage and experiment execution, I'm wondering if we would be able to build on top of git stash for this?
When I think about the idea of an "ephemeral commit" it sounds to me like it's the same idea as a stash commit. Using stash would give us actual commit objects we can refer to and diff without actually polluting the git repo with 1000 branches or 1000 formal commits - we can also avoid polluting the user's stash reflog by using git stash create and keeping track of our "experiment stash" ourselves if needed.
- this lets us leverage existing git functionality to handle storing param/metrics/code diffs for an experiment instead of having to do it ourselves
- this resolves the issue of how to name/identify experiments (at least internally) since experiments all have git SHAs
- if the user wants to re-run an experiment or start with an experiment as base but modify more parameters, it's just a
git stash applyoperation for us (and repro as needed) to restore the experiment state - restoring repo to some state before experiments were run is just a git checkout and/or git reset
So essentially, the workflow would be something like:
- user edits code/params, and runs some dvc command that defines the current (dirty) repo state as an experiment
- we run the experiment (
dvc repro) to generate the experiment output - we
git stashthe state of the repo which gives us an ephemeral/stash commit containing the code/params/metrics/etc changes without formally committing anything to the git repo
- we run the experiment (
- user repeats this w/more experiments until some desired result is reached
- we provide
dvc exp list/show/diff(or similar) commands - showing and diffing experiments would work the same way as existing metrics/params diff/show functionality (internally all we are doing now is referencing stash commits rather than formal branches/commits)
- for listing experiments we just need to iterate over our stashed commits
- we provide
- user runs some dvc command to "commit" a specific experiment
- we just need to
git stash apply <experiment_commit>on top of the original repo state, then commit the result - we can then drop/delete the remaining (unneeded) experiment stash commits and gc the data outputs from those commits (alternatively we have separate commands for cleaning up stashed experiments)
- we just need to
again, this doesn't address considerations about running experiments outside the dvc repro or in parallel, it's just my thoughts on one potential way that the internals on the diff/list/show side could work
 pmrowla
on 2 Jul 2020
pmrowla
on 2 Jul 2020
I'd be concerned about using git-stash as people who already use the stash will get confused if DVC has quietly put a dozen commits on it. At that stage we may as well have DVC quietly create multiple branches/commits.
There are ways of course to git-commit things in such a way that they don't show up on any branch or stash list, but are also not fully detached/headless. That perhaps could be an option.
casperdcl
on 2 Jul 2020
I'd be concerned about using
git-stashas people who already use the stash will get confused if DVC has quietly put a dozen commits on it. At that stage we may as well have DVC quietly create multiple branches/commits.
yeah, my understanding of git is that this concern is why git stash create exists - it lets 3rd party scripts (in this case dvc) create standalone stash commits that don't affect the regular user stash list/reflog
pmrowla
on 2 Jul 2020
build on top of
git stash
@pmrowla I really like this idea. I don't know in advance if it can cover all our needs but this solution looks very elegant :) Let's investigate!
A question that I have for now: how to move the experiments between machines (to CI/CD for example)? I'd appreciate it if you could explain the sharing part.
dmpetrov
on 2 Jul 2020
What about overloading dvc run for this? That is, if we also introduce dvc stage as a helper to define stages
My concern - it might take time to transfer from run to stages
@dmpetrov I'm not sure I get this concern. I understand it is the intention to separate stage definition from running them anyway no?
My concern would be that we'd probably need subcommands for dvc run in this case e.g. dvc run list, dvc run diff, dvc run exe (execute), which would be a big non-backward compatible change.
build on top of git stash for this?
Great thinking @pmrowla! But I don't think we can literally piggy back on Git stashed because they only store diffs (like any commit) and have to be reapplied to the current HEAD, which often has merge conflicts. However it should be possible for you to try your workflow manually now (or almost) and you'll know how realistic the approach is 🙂
The idea of replicating something similar in terms of the UI is definitely good though, for familiarity. But I would avoid calling it "stash" at all because it would increase our Git vs DVC confusion.
jorgeorpinel
on 2 Jul 2020
My concern would be that we'd probably need subcommands for
dvc runin this case e.g.dvc run list,dvc run diff,dvc run exe(execute), which would be a big non-backward compatible change.
@jorgeorpinel Exactly, it leads to the breaking change (right after 1.0 release). So, we can potentially introduce dvc stage but we won't be able to change dvc run in the next few months.
dmpetrov
on 2 Jul 2020
But I don't think we can literally piggy back on Git stashed because they only store diffs (like any commit) and have to be reapplied to the current HEAD, which often has merge conflicts.
Stash commits don't actually have to be reapplied to the current HEAD, so I think the dealing with potential merge issues is something we could work around. Just as an example, you can use git stash branch to make a new branch containing the stash commit, and the branch will start at the original commit from which you made the stash entry and not the current HEAD. From the git docs: "This is useful if the branch on which you ran git stash push has changed enough that git stash apply fails due to conflicts." And since we can work directly with the git index if we want, we aren't limited strictly to existing git stash subcommand behavior when it comes to how/where we apply a stash commit.
My main point was just that git does have existing internal functionality that (in my opinion) is analogous to "ephemeral commits" so it would make sense for us to take advantage of that if possible
pmrowla
on 3 Jul 2020
The idea is definitely worth trying out before implementing from scratch! 2 more doubts I have about this git stash strategy, though:
Each run is based on the previous one, I believe. They're sequential, like intermediate auto-commits. Can stashed changes be based on previous stashes? I think not 🙁
So run-cache would be disabled for --no-scm projects?
P/s
like intermediate auto-commits
What about implementing a full Git subrepo in between each commit internally (each commit being a run)? Sounds overkill but hey, 🧠 🌩️
jorgeorpinel
on 3 Jul 2020
- So run-cache would be disabled for --no-scm projects?
Is --no-scm actually something we need to support with regard to experiment runs? Given that other commands for doing diffs/comparison in DVC require git, it seems like having the same requirement for comparing experiments is reasonable?
pmrowla
on 3 Jul 2020
- Each run is based on the previous one, I believe. They're sequential, like intermediate auto-commits. Can stashed changes be based on previous stashes? I think not 🙁
Regarding this question, if a user has some experiment tree/history based on some existing commit like
<master @ 123abc>
+- exp1-1
+- exp2-1 -> exp2-2 -> exp2-3
+- exp3-1
(where experiments 1-1, 2-1, 3-1 are modifications of commit 123abc and experiments 2-2 and 2-3 depend on prior runs)
If the user decides at the end that they want to formally "commit" exp2-3
- Do we need to save the full experiment history? (so master would end up with separate commits for
exp2,exp2-2,exp2-3following commit123abc) - Or do we only care about having a single commit for the final results of
exp2-3? (so master would just have a single commit with the results ofexp2-3following commit123abc)
pmrowla
on 3 Jul 2020
Is --no-scm actually something we need to support with regard to experiment runs?
Idk, but I think it's supported with the current way run cache works.
if a user has some experiment tree/history...
Actually, I think we're overcomplicating this part, @pmrowla. Should we define what a run is technically? Are they actually nodes in a graph (commits)? I think not: they're unique combinations of cmd, params, deps, and out. So I guess they're not ordered in any way, just loosely connected to the last commit at the time they were run.
In fact maybe this signature could be the run checksum (instead of an index like I suggested before): basically an md5 of the hypotetical stage entry in dvc.lock. Full path = <commit sha>+<stage md5> cc @dmpetrov
This also means that my concern about git stash entries not being sequential isn't a problem to use that implementation approach 👍
Do we need to save the full experiment history?
Why delete it? It relates to something I suggested in https://github.com/iterative/dvc/issues/2799#issuecomment-652182872 though:
_Caching all those intermediate results can result in many multiples of storage requirements. I would even make the run-cache pushing optional (require an explicit option e.g. dvc push --run-cache_
jorgeorpinel
on 3 Jul 2020
Closed since experiments functionality has been implemented internally (but not released/finalized). At this point, it will be more useful for specific experiments related issues to be handled in their own tickets.
pmrowla
on 20 Oct 2020
Related issues
 siddygups
·
3Comments
dmpetrov
·
3Comments
siddygups
·
3Comments
dmpetrov
·
3Comments
 shcheklein
·
3Comments
shcheklein
·
3Comments
 TezRomacH
·
3Comments
TezRomacH
·
3Comments
 nik123
·
3Comments
nik123
·
3Comments
Most helpful comment
yeah, my understanding of git is that this concern is why
git stash createexists - it lets 3rd party scripts (in this case dvc) create standalone stash commits that don't affect the regular user stash list/reflog