Prework
- [ x ] Read and abide by
drake's code of conduct. - [ x ] Search for duplicates among the existing issues, both open and closed.
- [x] Advanced users: verify that the bottleneck still persists in the current development version (i.e.
remotes::install_github("ropensci/drake")) and mention the SHA-1 hash of the Git commit you install.
Description
As I'm building a drake plan out to include more and more steps, I'm finding that make(plan) and vis_drake_graph() are taking longer to start executing.
Link to Rstudio community post.
Reproducible example
Partial example that seems to at least illustrate the slow down problem:
Code: https://github.com/adamkski/ships/blob/master/drake/plan.R
Rprof: https://github.com/adamkski/ships/blob/master/your_samples.rds
Benchmarks
My drake plan on the other hand has 35 targets and it takes 17 seconds to run the same command. There is a similar delay for targets for make(plan) to start creating targets.
Rprof file:
your_samples.zip
 adamkski
adamkski
All 18 comments
Awesome! With the full Rprof file, I could generate some pprof flame graphs.
As I say below, process_imports() is surprisingly slow. How many custom functions do you have? How many files do you declare with file_in() and friends?
Full workflow:
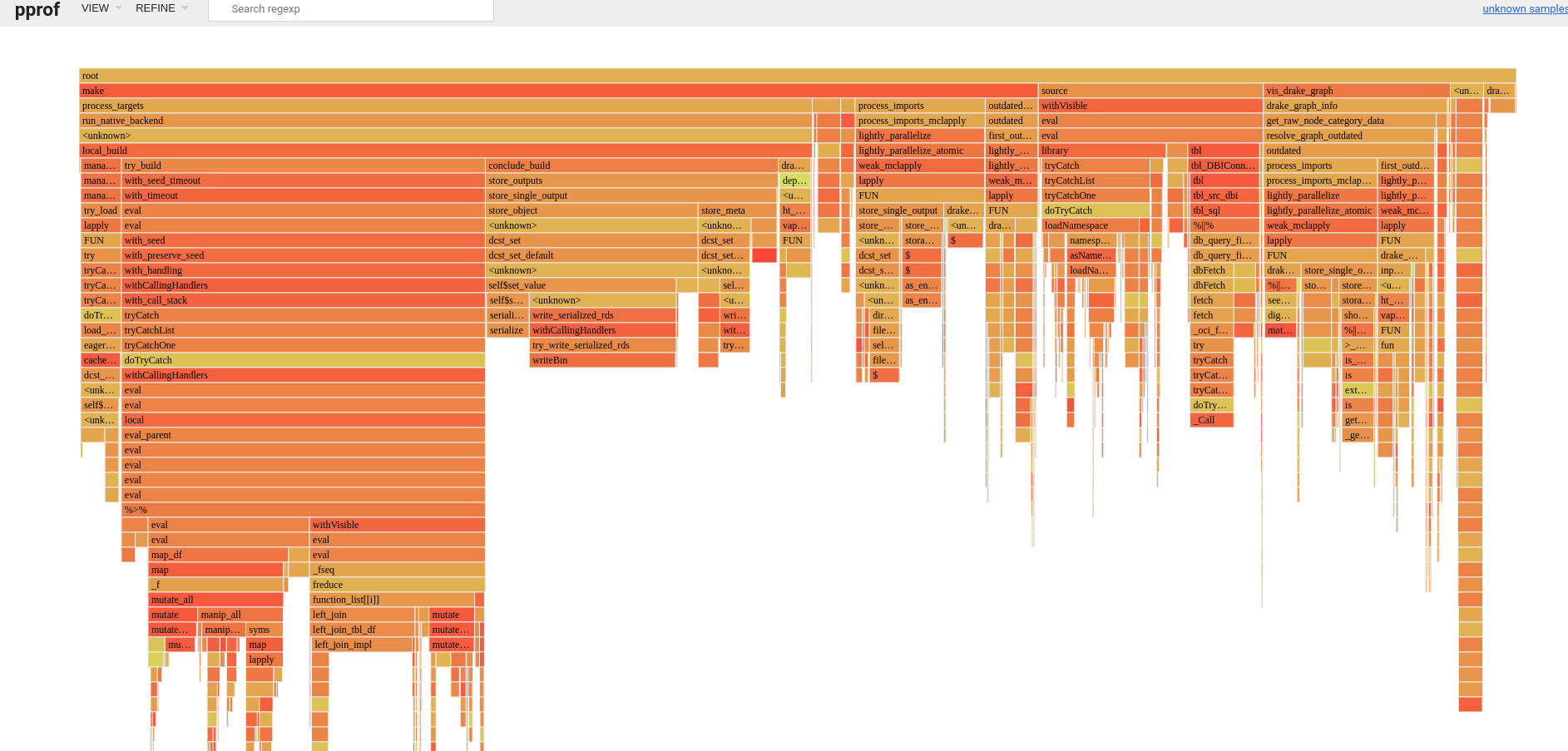
Just make():
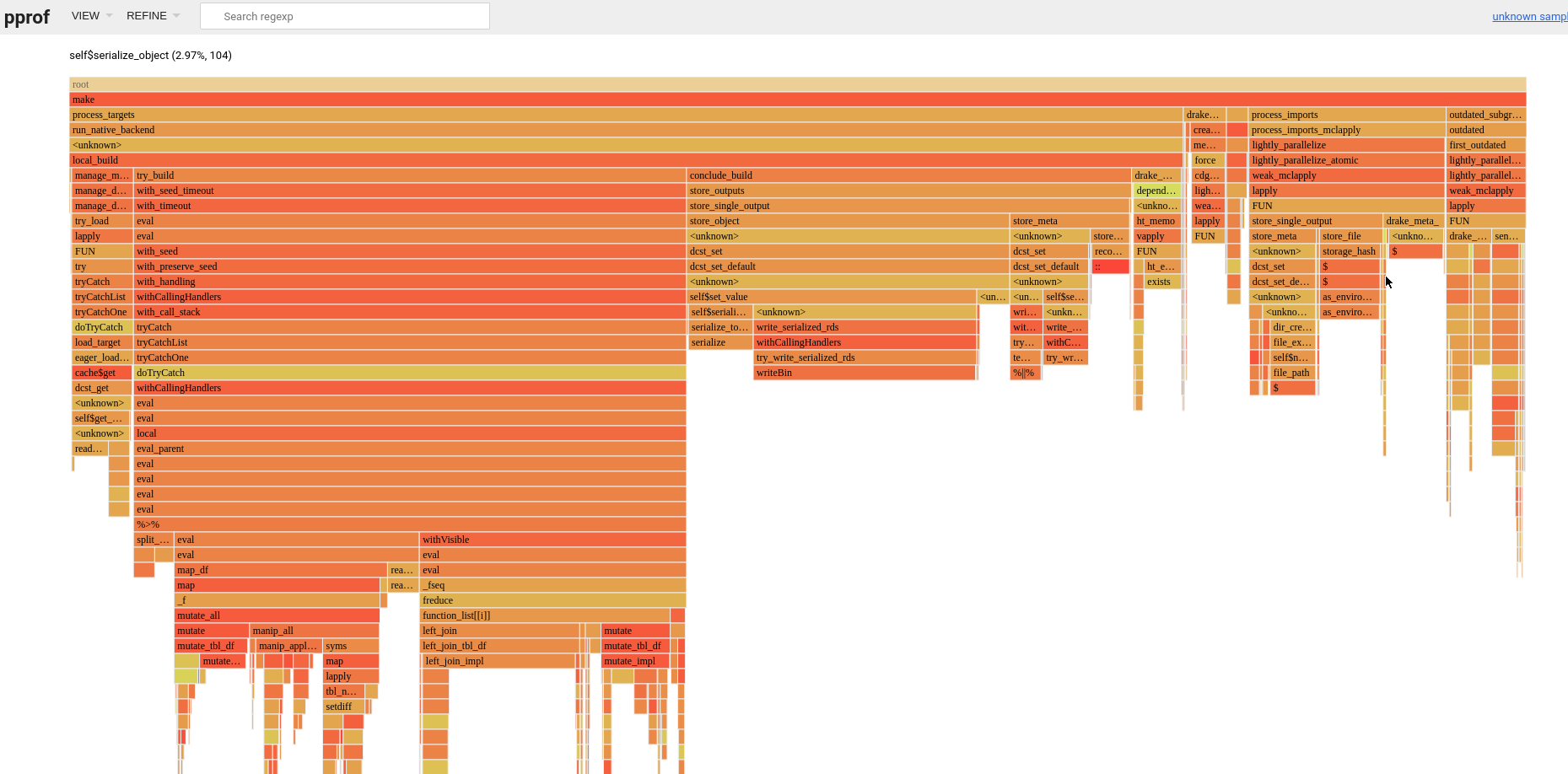
Just vis_drake_graph():

pprof file:
Some things I notice right away:
- About 22% of
make()is spent storing targets. Judging from your use ofleft_join()andmutate(), I am guessing some of them might be data frames. To store data frame targets faster, you might consider the "fst" format. Details: https://books.ropensci.org/drake/plans.html#special-data-formats-for-targets. .deparseOpts(),is.Date(), andmatch.arg()are surprising sources of overhead inprocess_imports(). I am not sure how much progress we can make there because they are called in external packages, but clever workarounds could lead to quick wins.- We do not need seeds for imports, and eliminating
seed_from_basic_types()could reduce startup times.
 wlandau
on 3 Dec 2019
wlandau
on 3 Dec 2019
@adamkski, I made a couple changes that should decrease the runtime of vis_drake_graph() by about 35% in your use case. There should also be a minor speedup in the initialization time of make(). Care to try the development version?
For slowness due to match.arg() in digest() and .deparseOpts() in deparse(), the solutions are going to be more difficult: drake needs that code, but it is code I do not control.
wlandau
on 4 Dec 2019
Trying to remove the deparse() bottleneck: https://stackoverflow.com/questions/59167441/faster-alternative-to-deparse
wlandau
on 4 Dec 2019
G. Grothendieck has a super promising candidate solution to the slowness in deparse(). Really stoked to try it out.
wlandau
on 4 Dec 2019
Care to try the development version?
With pleasure! I'm using 7.8.0.9000 now.
vis_drake_graph and make are running faster. I haven't designed something like a fair comparison, but in my current state vis_drake_graph runs in 6 seconds now, down from 17. Much better! make has had a noticeable improvement too.
I'll likely be rebuilding some targets this week so I'll try to run the profiler if I notice a slowdown again.
adamkski
on 4 Dec 2019
...process_imports() is surprisingly slow. How many custom functions do you have? How many files do you declare with
file_in()and friends?
- 35 custom functions (coincidentally the same number as targets right now).
- 5 file_in (example sizes: 499.6 MB, 9.6 MB, 234.3 KB, 86.4 MB, 14 MB)
- 1 file_out
adamkski
on 4 Dec 2019
That explains why process_imports() was showing up prominently in the profiling output. In a lot of use cases I was optimizing for, there was a small-ish collection of functions that got reused over thousands of targets. Still, 35 is quite small, and drake needs to be faster. I think that that slick deparse() workaround should remove the last major bottleneck you are seeing in the way imports are processed. I will let you know when I implement it.
wlandau
on 4 Dec 2019
FYI: #1089 and https://github.com/eddelbuettel/digest/pull/138 are related. You may see speedups if you install development digest. I still need to try and speed up deparsing in drake. I will let you know when things are ready to benchmark again.
wlandau
on 5 Dec 2019
Deparsing should be about 5x faster in f19efcb53aafd9da1fd30f1a1540f4d74c752a25. With development drake and development digest, those bottlenecks should be gone now. If I am wrong, please send me more profiling data and I can continue to diagnose things.
wlandau
on 5 Dec 2019
I've uploaded a code example that appears to have a similar slow down issue as I had before on some data I could get openly. I tried to replicate some patterns I use at work to setup data for SQL queries (though in my example I don't actually query a SQL db). Hope that gives you the flavor of what you were looking for.
Code: https://github.com/adamkski/ships/blob/master/drake/plan.R
Rprof: https://github.com/adamkski/ships/blob/master/your_samples.rds
P.S. I haven't tried "fst" format yet.
adamkski
on 9 Dec 2019
Awesome, thanks for uploading the example! It could help with other use cases going forward.
Did you mean to say drake is still slow for this example when you run it? How slow are we talking in terms of elapsed runtime? I looked at your profiling data, and there do not seem to be any quick wins left.
library(proffer) # https://github.com:wlandau/proffer
download.file(
"https://raw.githubusercontent.com/adamkski/ships/master/your_samples.rds",
"your_samples.rds"
)
px <- serve_rprof("your_samples.rds")
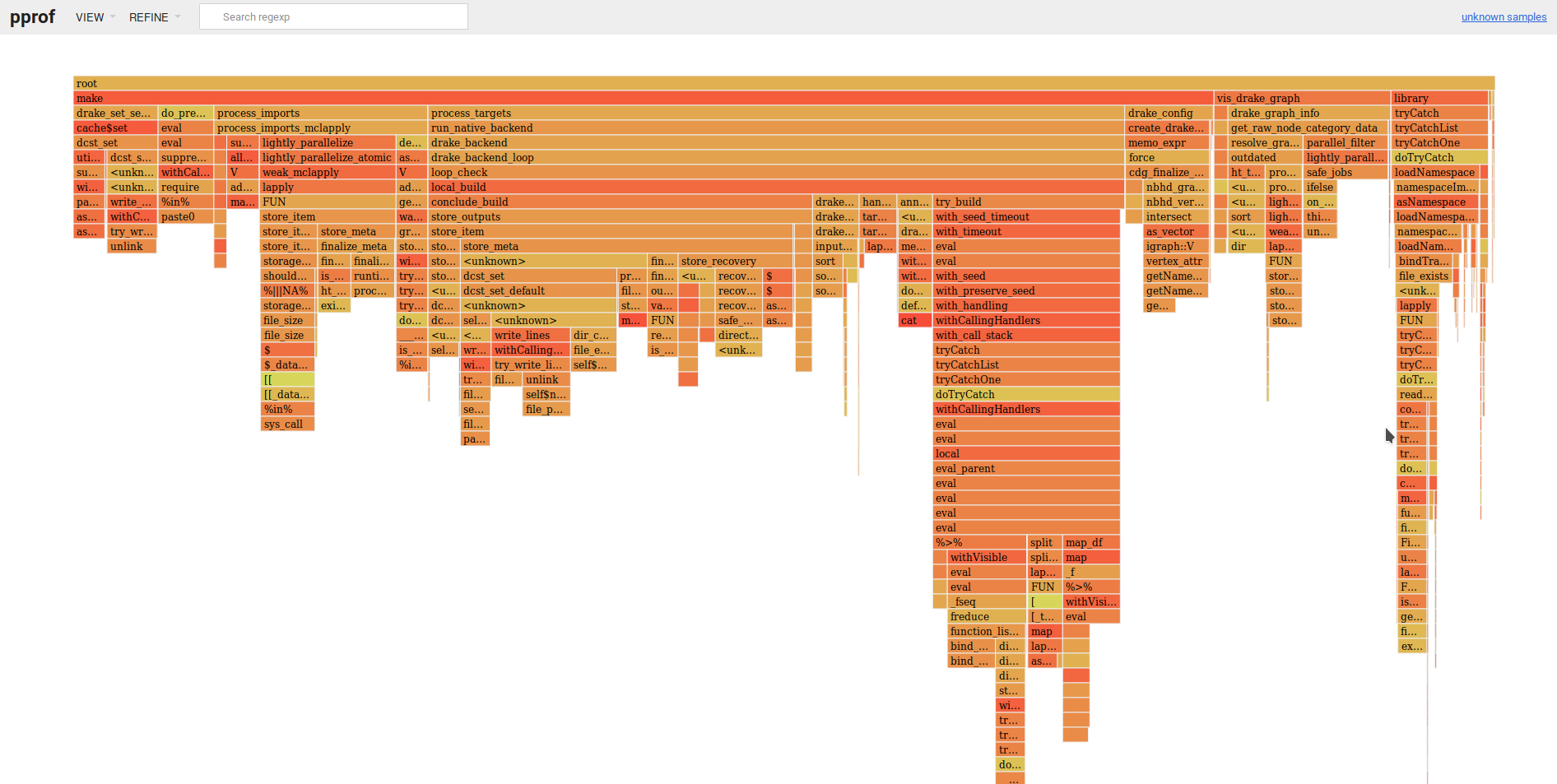
To get drake to run faster, there are a bunch of little features you can disable if they are not necessary for your use case. Example: https://github.com/wlandau/drake-examples/blob/8447e2b7412a69fc67465bb8729c5b6f713481f7/overhead/R/functions.R#L5-L10. In development drake, you can also shut off build times with log_build_times = FALSE in make().
Another thing I notice is that drake spends around 3-4% runtime getting the sizes of all your files. Internally, drake uses file size and modification time stamp to decide whether a file is worth re-hashing. Ultimately, avoiding the hash should save time.
One little opportunity for a speedup in vis_drake_graph() is to pre-compute whether we are on Windows. And maybe we do not even need that call to parallel_filter() in drake_graph_info(). I will investigate.
wlandau
on 10 Dec 2019
Just attacked the slowdown due to safe_jobs() in https://github.com/ropensci/drake/commit/827cd8f73ccdf8dbabb58b12af85bd01407a06f4 and daf204fc7fa0bc4ea7547e9747c57581f02c9afa. Should speed up vis_drake_graph() by up to 2x (but maybe not by that much) according to that profiling data.
wlandau
on 10 Dec 2019
Did you mean to say
drakeis still slow for this example when you run it? How slow are we talking in terms of elapsed runtime?
It's at 4.86 seconds just now. That's still much better than before. I was just posting the code example for the record. And so I can at least try to have a reprex ☺️ .
adamkski
on 10 Dec 2019
The speed improvement is good news! Thank you for posting the example. I have a suspicion it will come in handy later on.
wlandau
on 11 Dec 2019
Unfortunately, the time for a vis_drake_graph() on my last run has mushroomed to 60 seconds.
I have two more Rprof files that could be useful (I just used an arbitrary name "project emerald"). It's using the code from my original post, plus additional targets to bring it to 57. What's remarkable is that the first run calls to vis_drake_graph() and make() were very fast, while the second run experienced significant slow downs.
P.S. I'll try to add a pseudo-reprex to my ships example when I get the chance.
P.P.S.
there are a bunch of little features you can disable if they are not necessary for your use case. Example: https://github.com/wlandau/drake-examples/blob/8447e2b7412a69fc67465bb8729c5b6f713481f7/overhead/R/functions.R#L5-L10.
This had a speed boost the first time I set the options, but once I ran it a second time it seemed to also slow down again. Haven't tried turning off logging build times because that's pretty useful! ;)
adamkski
on 18 Dec 2019
Just so I know, what commit hash of drake are you using?
packageDescription("drake")$GithubSHA1
From the results you sent, it looks like the second run was the fast one. vis_drake_graph() ran as fast as library().
library(proffer)
serve_rprof("2nd-run.rds")
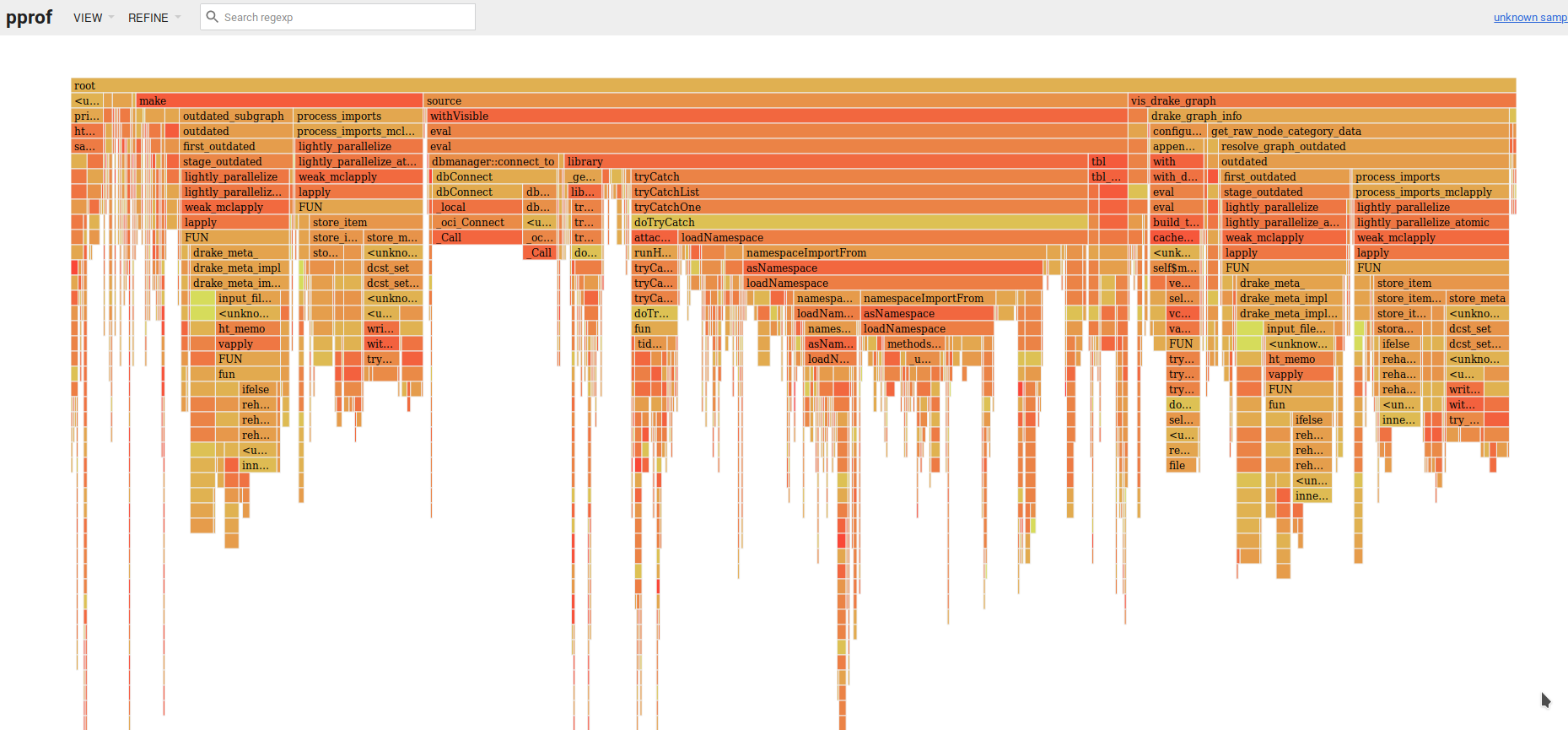
The first one seems to spend the vast majority of time actually running the commands in the plan (especially Sys.sleep()) which is a good thing.
serve_rprof("1st-run.rds")

Did you mean to mean to send me a different set of files?
Alternatively, now that proffer is available, please feel free to send me screenshots of flame graphs etc. directly.
Also, vis_drake_graph() with from_scratch = FALSE is likely to be slowest right after a make() because that is when it takes longest to confirm that all the targets are up to date.
wlandau
on 18 Dec 2019
Thanks I'll check that package out!
Those were the files I meant to send... and it looks like it's sped back up. Feels magical sometimes. Anyways maybe I'll wait for a longer term pattern to emerge, if it does. Thanks for the reply.
adamkski
on 18 Dec 2019
Those were the files I meant to send... and it looks like it's sped back up. Feels magical sometimes.
Glad it took care of itself.
Anyways maybe I'll wait for a longer term pattern to emerge, if it does. Thanks for the reply.
No worries, I would rather have false alarms than miss bottlenecks. These things can be elusive.
wlandau
on 19 Dec 2019
Related issues
 maelle
·
8Comments
maelle
·
8Comments
 rsangole
·
3Comments
wlandau
·
8Comments
rsangole
·
3Comments
wlandau
·
8Comments
 billdenney
·
9Comments
billdenney
·
9Comments
 bart1
·
7Comments
bart1
·
7Comments