Drake: Dynamic subtargets that depend on each other
Prework
- [X] Read and abide by
drake's code of conduct. - [X] Search for duplicates among the existing issues, both open and closed.
Use case
I want to perform an operation on each node of a tree, where the results depend on the results of the child nodes. Of course, this is what drake does in the background anyway, but I have an explicit tree.
In addition, suppose the tree is not known ahead of time, so it needs to be an earlier target in the plan. Here is an example with a known tree using static branching and dark magic:
library(drake)
tree <- list(
c(NA, NA),
c(NA, NA),
c(NA, NA),
c(NA, NA),
c(1L, 2L),
c(3L, 4L),
c(5L, 6L)
)
idx <- seq_along(tree)
# calculate the total number of nodes in the (sub)tree
do_process <- function(node1, node2) sum(1L, node1, node2, na.rm = TRUE)
# gives the target name of the result from a child
# or NA if the child is NA
child <- function(x, i) {
if (is.na(i)) return(NA)
name <- rlang::ensym(x)
name <- paste(rlang::expr_name(name),
rlang::expr_text(rlang::expr(!!i)),
sep = "_")
rlang::sym(name)
}
plan <- drake_plan(
process_tree = target(
do_process(!!child(process_tree, tree[1]),
!!child(process_tree, tree[2])),
transform = map(tree = !!tree,
idx = !!idx,
.id = idx)
)
)
make(plan)
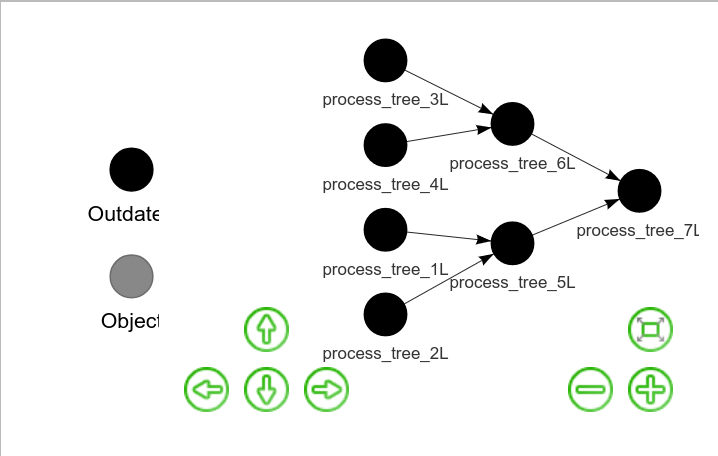
#> target process_tree_3L
#> target process_tree_4L
#> target process_tree_1L
#> target process_tree_2L
#> target process_tree_6L
#> target process_tree_5L
#> target process_tree_7L
readd(process_tree_7L)
#> [1] 7
Created on 2019-11-12 by the reprex package (v0.3.0)
Here is a failing attempt with dynamic branching:
library(drake)
tree <- list(
c(NA, NA),
c(NA, NA),
c(NA, NA),
c(NA, NA),
c(1L, 2L),
c(3L, 4L),
c(5L, 6L)
)
idx <- seq_along(tree)
# calculate the total number of nodes in the (sub)tree
do_process <- function(node1, node2) sum(1L, node1, node2, na.rm = TRUE)
# returns x[[i]] as an expression
child2 <- function(x, i) {
if (is.na(i)) return(NA)
mycall <- match.call()
mycall[[1]] <- `[[`
mycall
}
plan2 <- drake_plan(
process_tree = target(
do_process(!!child2(process_tree, tree[1]),
!!child2(process_tree, tree[2])),
dynamic = map(tree)
)
)
make(plan2)
#> dynamic process_tree
#> subtarget process_tree_008192c9
#> fail process_tree_008192c9
#> Error: Target `process_tree_008192c9` failed. Call `diagnose(process_tree_008192c9)` for details. Error message:
#> object 'process_tree' not found
Created on 2019-11-12 by the reprex package (v0.3.0)
Proposal
Allow a subtarget to refer to other targets in the same dynamic target using indexes, i.e. <target_name>[[i]].
 brendanf
brendanf
All 10 comments
What is your motivation for pursuing trees of (sub-)targets? Does the advice at https://books.ropensci.org/drake/plans.html#how-to-choose-good-targets resonate with your strategy, or would it make more sense to put entire trees within individual targets?
Dynamic branching itself is not designed to have interdependent sub-targets, and it would take considerable refactoring to achieve such a feature. The use case you bring up does not seem common enough to justify the effort.
Dynamic sub-targets are indexed by their dependency hashes instead of integer vectors. There are two reasons for this:
- It makes it faster and easier to check which sub-targets are up to date.
- Integer indices are too brittle. Say we have sub_targets
x_1andx_2that depend on the vectorc("a", "b"), e.g.drake_plan(v = c("a", "b"), x = target(v, dynamic = map(v))). What if we insert an element in the middle ofv? With integer indices, we need to (re)build bothx_2andx_3! But becausedrakeuses dependency hashes for names, we only re-build the sub-target corresponding to"x".
library(drake)
plan <- drake_plan(
v = c("a", "b"),
x = target(v, dynamic = map(v))
)
make(plan)
#> target v
#> dynamic x
#> subtarget x_89ca58a1
#> subtarget x_38e75e51
plan <- drake_plan(
v = c("a", "x", "b"), # Insert x in the middle.
x = target(v, dynamic = map(v))
)
make(plan) # Only build one sub-target.
#> target v
#> dynamic x
#> subtarget x_e5004511
unlist(readd(x)) # We have 3 total sub-targets
#> [1] "a" "x" "b"
Created on 2019-11-12 by the reprex package (v0.3.0)
If you really need a tree of targets, I think partial workarounds are possible. Below, I use pairwise summation to compute 1 + 2 + ... + 8. Dynamic branching sums the pairs at each stage. Static branching could probably serve to map over multiple stages if you know the graph order in advance.
library(drake)
get_by <- function(nodes) {
rep(seq_len(length(nodes) / 2), each = 2)
}
sum_list <- function(x) {
sum(unlist(x))
}
plan <- drake_plan(
nodes4 = seq_len(8),
by4 = get_by(nodes4),
nodes3 = target(sum_list(nodes4), dynamic = combine(nodes4, .by = by4)),
by3 = get_by(nodes3),
nodes2 = target(sum_list(nodes3), dynamic = combine(nodes3, .by = by3)),
by2 = get_by(nodes2),
nodes1 = target(sum_list(nodes2), dynamic = combine(nodes2, .by = by2))
)
make(plan)
#> target nodes4
#> target by4
#> dynamic nodes3
#> subtarget nodes3_b42579e8
#> subtarget nodes3_9634c2d5
#> subtarget nodes3_af40d12c
#> subtarget nodes3_edc0b254
#> target by3
#> dynamic nodes2
#> subtarget nodes2_4b058ca2
#> subtarget nodes2_2eae3de7
#> target by2
#> dynamic nodes1
#> subtarget nodes1_652e4d37
unlist(readd(nodes4))
#> [1] 1 2 3 4 5 6 7 8
unlist(readd(nodes3))
#> [1] 3 7 11 15
unlist(readd(nodes2))
#> [1] 10 26
unlist(readd(nodes1))
#> [1] 36
sum(seq_len(8))
#> [1] 36
Created on 2019-11-12 by the reprex package (v0.3.0)
 wlandau
on 12 Nov 2019
wlandau
on 12 Nov 2019
My tree is a phylogenetic tree, and the operation on each node is a potentially costly sequence alignment. I don't know the tree ahead of time, but I'd like to do the alignments in parallel where possible.
Are dynamic targets allowed to have file_in() and file_out()?
brendanf
on 12 Nov 2019
My tree is a phylogenetic tree, and the operation on each node is a potentially costly sequence alignment. I don't know the tree ahead of time, but I'd like to do the alignments in parallel where possible.
How costly exactly? How many nodes do you have, and how many trees?
Are dynamic targets allowed to have file_in() and file_out()?
Dynamic sub-targets can share a common file_in(), but that's all. They cannot have their own unique file_in() / file_out() files.
wlandau
on 12 Nov 2019
How costly exactly? How many nodes do you have, and how many trees?
The time to do an alignment scales roughly as the product of the child sizes; 11 is only a few seconds. 500500 is around 12 hours. I'm potentially working on cases up to a few thousand nodes. There's only one tree, but it is the product of other computations taking many hours.
Incidentally, because the code that does each alignment is single-threaded, this case is very difficult to appropriately schedule on a cluster. At the early stages there are hundreds of fast jobs that can be run in parallel, but towards the end there is a long time where it can only use one core.
I have something working now using Snakemake, so I'll manage if drake can't do this. I'd prefer drake because most of the rest of the code is in R, and because I'm having trouble with files accidentally getting touched and triggering rebuilds (because Snakemake goes by modification time, not contents).
brendanf
on 12 Nov 2019
What specifically is fixed and what is unknown about the tree at the beginning? How much do we know about the nodes and edges ahead of time? How do parent nodes get defined as you work up from the leaves? Dynamic branching fundamentally assumes conditional independence among sub-targets, so the original feature in this issue is not likely to get implemented, but there may be something else we can do. I am also curious how you achieve this in Snakemake.
wlandau
on 13 Nov 2019
At the beginning of the workflow, I do not even know the number of nodes in the tree. I do know that is is strictly dichotomous (all non-terminal nodes have exactly two children), but it is not balanced (i.e., different terminal nodes are at different distances from the root).
By the time I get to the alignment target, then the content of the tips of the tree has already been calculated, as has the topology of the tree. The alignment target then needs to map a function over the tree of the form result = f(result[child1], result[child2]). So, the dependencies between the dynamic subtargets are known when the dynamic target is started, but not at the beginning of the plan.
In Snakemake, I can mark the step which generates the tree as a checkpoint, which triggers a rebuild of the dependency graph after it is run. Then the rule which runs the alignment uses a function to calculate its inputs.
This could also be achieved in GNU make by putting the alignment steps in an included makefile, and writing a rule to produce the included makefile, which depends on the tree output.
An analogy in drake would be to have one plan which calculates the tree, and then after the first plan is executed, generate a second plan for the alignment targets using the tree calculated in the first plan, and use bind_rows to combine the plans before running again. I ought to be able to try that without any changes to drake itself.
brendanf
on 13 Nov 2019
Thank you @brendanf, those details are extremely helpful! In drake, it sounds like you can have two sequential plans, each with its own cache. See the discussion at #1015, particularly from https://github.com/ropensci/drake/issues/1015#issuecomment-536144899 onwards.
NB I did consider checkpointing in drake, but it seemed rigid and messy at the time, and you can accomplish the same thing by chaining plans and caches together in a single script. There is nothing wrong with calling make() multiple times.
wlandau
on 13 Nov 2019
I'm curious if/why it's necessary to keep the plans separate with different caches. What will go wrong if I run make on the first plan, do some extra code to generate the second plan based on the results from the first plan, rbind the plans together, and then make the whole thing?
The reason I would do this is if there are a lot of targets from the first plan which I will need in the second plan, so that I wouldn't have to manually import them all in the second plan.
brendanf
on 15 Nov 2019
I'm curious if/why it's necessary to keep the plans separate with different caches. What will go wrong if I run make on the first plan, do some extra code to generate the second plan based on the results from the first plan, rbind the plans together, and then make the whole thing?
Yeah, that's a much better idea for your use case!
It works because every target in the second plan is strictly downstream of every target in the first plan and none of the target names conflict between plans. That was not the case in #1015.
wlandau
on 15 Nov 2019
You might be interested in #1178.
wlandau
on 22 Feb 2020
Related issues
wlandau
·
8Comments
 billdenney
·
9Comments
billdenney
·
9Comments
 htlin
·
4Comments
wlandau
·
4Comments
htlin
·
4Comments
wlandau
·
4Comments
 wlandau-lilly
·
7Comments
wlandau-lilly
·
7Comments