I am struggling with the use of strings as wildcards in drake. In the following example, I want drake to take the iris dataset and generate three subsets, split by Species. However, drake thinks that the levels of Species (i.e., setosa, versicolor and virginica) are objects that are missing.
Session Info
> sessionInfo()
R version 3.2.1 (2015-06-18)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 14.04.5 LTS
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C LC_TIME=en_US.UTF-8
[4] LC_COLLATE=en_US.UTF-8 LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] drake_5.0.0
loaded via a namespace (and not attached):
[1] igraph_1.0.1 Rcpp_0.12.8 knitr_1.12.3 magrittr_1.5 R6_2.2.2
[6] stringr_1.2.0 storr_1.1.2 plyr_1.8.4 globals_0.10.3 tools_3.2.1
[11] visNetwork_2.0.1 parallel_3.2.1 R.oo_1.21.0 withr_2.1.0 htmltools_0.3.5
[16] yaml_2.1.13 digest_0.6.12 rprojroot_1.2 crayon_1.3.1 formatR_1.2.1
[21] htmlwidgets_0.9 R.utils_2.5.0 codetools_0.2-15 testthat_0.11.0 memoise_1.0.0
[26] evaluate_0.8 stringi_1.1.2 future.apply_0.1.0 backports_1.1.1 R.methodsS3_1.7.1
[31] jsonlite_1.5 future_1.6.2 lubridate_1.5.0 listenv_0.6.0
Example
library("drake")
data("iris")
# Get all species. We need them to extract subsets for each of them.
species <- as.character(unique(iris[, "Species"]))
# This function splits the data into subsets for each species.
split_by_species <- function(dat, species_var, species_lvl) {
# dat: dataframe. Iris dataset
# species_var: Character scalar. This variable stores the species information
# species_lvl: character scalar. Subset the data using this species
dat[dat[, species_var] == species_lvl, ]
}
# Create the drake-workplan for a single target and a wild card for the species.
species_plan <- drake::drake_plan(
data = split_by_species(
species_var = "Species",
species_lvl = SPECIES
)
)
# Generate one target for each species.
species_plan <- drake::expand_plan(
plan = species_plan,
values = species
)
# Use a wild card for the species to pass different species to the
# 'split-by-species()' function.
species_plan <- drake::evaluate_plan(
plan = species_plan,
rules = list(SPECIES = species)
)
# Visualize and build the work plan.
config <- drake::drake_config(species_plan)
drake::vis_drake_graph(config)
Is there already a way to quote the values passed to the wildcard variable appropriately?
 mwesthues
mwesthues
All 10 comments
Thanks for asking, @mwesthues. I expected this point to require more explanation. Your minimal working example is excellent!
Solution
Here is some code that does what I think you want. To emphasize the parts I changed, I replaced your comments with my own.
library("drake")
data("iris")
species <- as.character(unique(iris[, "Species"]))
split_by_species <- function(dat, species_var, species_lvl) {
dat[dat[, species_var] == species_lvl, ]
}
species_plan <- drake::drake_plan(
data = split_by_species(
species_var = "Species",
species_lvl = "SPECIES"
),
# Make sure to use double quotes instead of single quotes.
# That way, drake knows that "Species" and "SPECIES"
# are ordinary strings, not the names of file dependencies.
strings_in_dots = "literals"
)
species_plan
## target command
## 1 data split_by_species(species_var = "Species", species_lvl = "SPECIES")
# Here, SPECIES is a wildcard.
# Drake does not care that it appears in quotes.
# It will evaluate the wildcard anyway.
new_plan <- evaluate_plan(
plan = species_plan,
wildcard = "SPECIES",
values = species
)
new_plan
## target command
## 1 data_setosa split_by_species(species_var = "Species", species_lvl = "setosa")
## 2 data_versicolor split_by_species(species_var = "Species", species_lvl = "versicolor")
## 3 data_virginica split_by_species(species_var = "Species", species_lvl = "virginica")
config <- drake_config(new_plan)
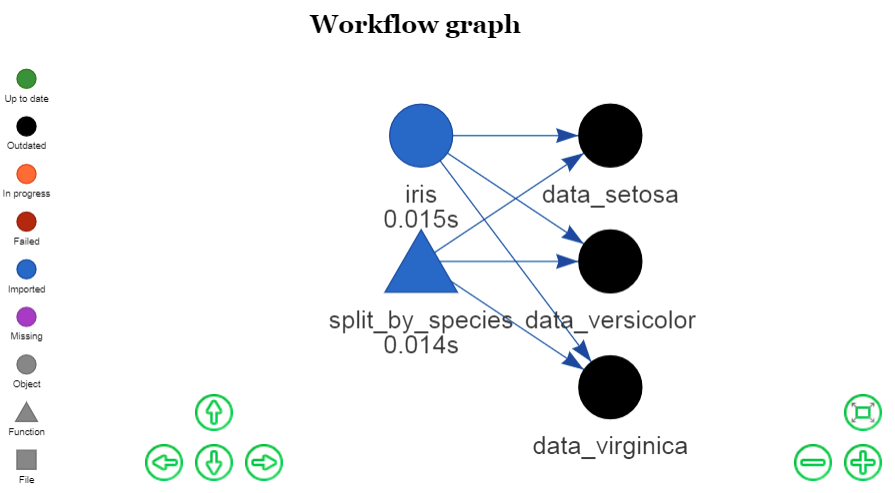
make(new_plan)
## target data_setosa
## target data_versicolor
## target data_virginica
readd(data_setosa)
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## ...
## 50 5.0 3.3 1.4 0.2 setosa
What about undefined symbols?
drakethinks that the levels of Species (i.e., setosa, versicolor and virginica) are objects that are missing.
Drake looks for them, but as long as your commands run without quitting in error, drake does not care if they are missing. Just be sure to avoid name conflicts with actual targets or imports. Otherwise, non-standard evaluation will mangle the dependency network.
Here is some example code that uses Species as a symbol rather than a quoted string. Drake looks for where Species is defined, does not find it, and chooses to not care.
library(drake)
library(tidyverse)
data("iris")
species <- as.character(unique(iris[, "Species"]))
# Non-standard evaluation: Species is a symbol.
# Drake looks for it and cannot find it.
# make() works anyway since there is no target or import
# already named Species.
split_by_species <- function(dat, species_var, species_lvl) {
dplyr::filter(dat, Species == species_lvl)
}
species_plan <- drake::drake_plan(
data = split_by_species(
dat = iris,
# Species is now a symbol.
species_var = Species,
species_lvl = "SPECIES"
),
strings_in_dots = "literals"
) %>% evaluate_plan(
wildcard = "SPECIES",
values = species
)
species_plan
config <- drake_config(species_plan)
vis_drake_graph(config)
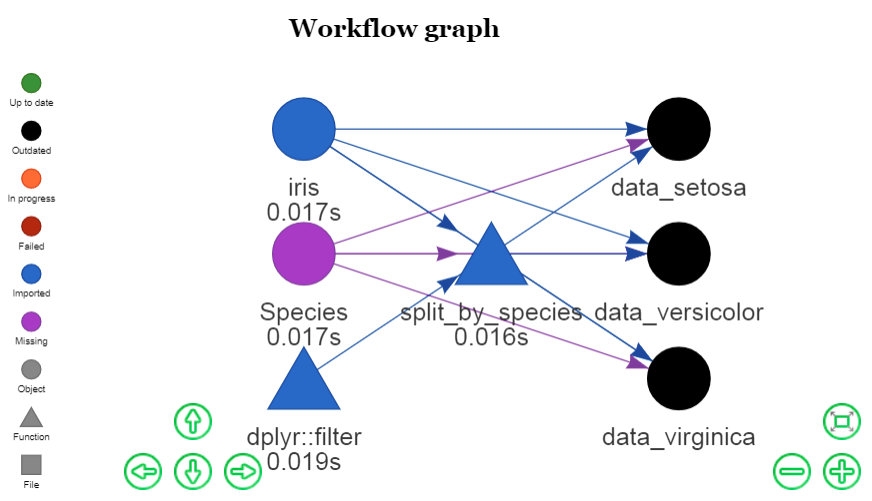
Since we're using non-standard evaluation, Species is not defined as a variable, so its node above is purple. But that's okay. make() gives you the benefit of the doubt.
# Use extra verbosity to report potentially missing items.
make(species_plan, verbose = 3)
## check 3 items: dplyr::filter, iris, Species
## import dplyr::filter
## import iris
## import Species # Drake processes Species
## missing Species # and moves on.
## check 1 item: split_by_species
## import split_by_species
## check 3 items: data_setosa, data_versicolor, data_virginica
## target data_setosa
## target data_versicolor
## target data_virginica
readd(data_setosa)
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## ...
## 50 5.0 3.3 1.4 0.2 setosa
A note on quoting
For anyone else reading this thread, drake cares about how you quote variables. Single-quoted strings are for file names (dependencies and/or targets), and double-quoted strings are for ordinary string literals. To be safe, drake_plan() single_quotes all the strings in whatever you pass to ..., unless you set the strings_in_dots argument to "literals". For finer control, use the list argument of drake_plan().
drake_plan(
list = c(
dataset = "readxl::read_excel(path = 'my_file.xlsx', sheet = \"second_sheet\")"
)
)
## target command
## 1 dataset readxl::read_excel(path = 'my_file.xlsx', sheet = "second_sheet")
 wlandau
on 29 Jan 2018
wlandau
on 29 Jan 2018
I just improved the drake_plan() examples (?drake_plan). I think this issue is now addressed. Please let me know if you have more questions.
wlandau
on 29 Jan 2018
That is exactly what I needed! Thank you so much for your patience and great example! Looking forward to building my workflows with drake.
mwesthues
on 29 Jan 2018
While the code works as is, I believe there are two issues in the "symbol" version of the code. In particular,
split_by_species <- function(dat, species_var, species_lvl) {
dplyr::filter(iris, Species == species_lvl)
}
The "iris" ref should be to "dat", and the "Species" should really be a en-quoted version of species_var.
should really be something like:
split_by_species <- function(dat, species_var, species_lvl) {
dplyr::filter(dat, !!enquo(species_var) == species_lvl)
}
 jw5
on 22 May 2018
jw5
on 22 May 2018
Thanks, @jw5! Works great. I updated the thread.
wlandau
on 23 May 2018
Hoping I'm not missing something here, but is there any guidance for how to do this if you're using a rules list? for example, my input rules look something like:
list (
year__ = c(2000, 2001),
disease__ = c("TB", "FLU")
)
And I want to use disease__ as both a wildcard to name targets as well as a string input to a function, so something like:
data_TB_2000 = subset_data(df, year = 2000, disease = "TB")
Any guidance would be greatly appreciated!
 jzelner
on 18 Jul 2018
jzelner
on 18 Jul 2018
@jzelner, is this the kind of plan you want?
library(drake)
pkgconfig::set_config("drake::strings_in_dots" = "literals")
plan <- evaluate_plan(
drake_plan(
data = subset_data(df, year = year__, disease = "disease__")
),
rules = list (
year__ = c(2000, 2001),
disease__ = c("TB", "FLU")
)
)
plan
#> # A tibble: 4 x 2
#> target command
#> * <chr> <chr>
#> 1 data_2000_TB "subset_data(df, year = 2000, disease = \"TB\")"
#> 2 data_2000_FLU "subset_data(df, year = 2000, disease = \"FLU\")"
#> 3 data_2001_TB "subset_data(df, year = 2001, disease = \"TB\")"
#> 4 data_2001_FLU "subset_data(df, year = 2001, disease = \"FLU\")"
config <- drake_config(plan)
vis_drake_graph(config)
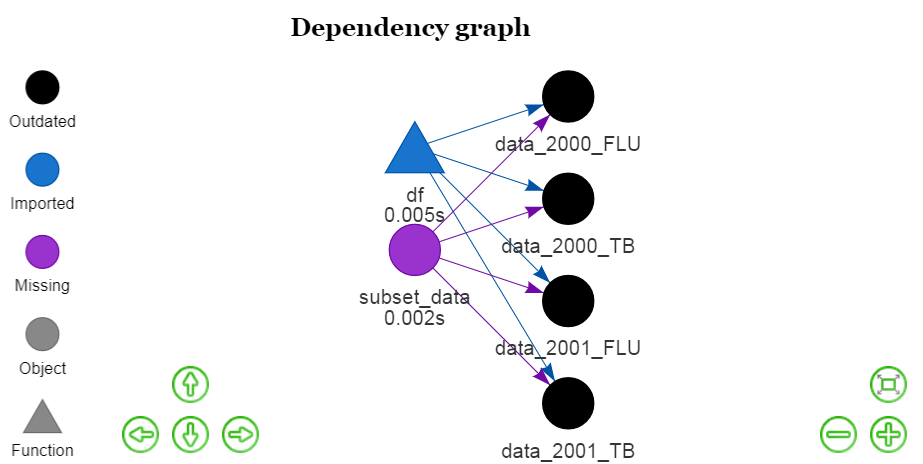
You may find it helpful to look at the new chapter of the manual on plans, particularly the section on generating large plans.
wlandau
on 18 Jul 2018
Yep! Thanks Will! I didn't realize you could quote the wildcard like that.
On Wed, Jul 18, 2018 at 2:18 PM Will Landau notifications@github.com
wrote:
@jzelner https://github.com/jzelner, is this the kind of plan you want?
library(drake)pkgconfig::set_config("drake::strings_in_dots" = "literals")plan <- evaluate_plan(
drake_plan(
data = subset_data(df, year = year__, disease = "disease__")
),
rules = list (
year__ = c(2000, 2001),
disease__ = c("TB", "FLU")
)
)plan#> # A tibble: 4 x 2#> target command #> *#> 1 data_2000_TB "subset_data(df, year = 2000, disease = \"TB\")" #> 2 data_2000_FLU "subset_data(df, year = 2000, disease = \"FLU\")"#> 3 data_2001_TB "subset_data(df, year = 2001, disease = \"TB\")" #> 4 data_2001_FLU "subset_data(df, year = 2001, disease = \"FLU\")"config <- drake_config(plan)
vis_drake_graph(config)[image: capture]
https://user-images.githubusercontent.com/1580860/42899874-555df1ba-8a95-11e8-8cfb-1c885951d4e6.PNGYou may find it helpful to look at the new chapter of the manual on plans
https://ropenscilabs.github.io/drake-manual/plans.html, particularly
the section on generating large plans
https://ropenscilabs.github.io/drake-manual/plans.html#generating-large-workflow-plans
.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/ropensci/drake/issues/199#issuecomment-406026716, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AAIUg5fxQ8Z5jIck-QnZXKWKYycvzTKJks5uH3v9gaJpZM4RwTlC
.
jzelner
on 18 Jul 2018
Update: development drake now has a much friendlier (experimental) API. It is much better than wildcards. Details: https://ropenscilabs.github.io/drake-manual/plans.html#create-large-plans-the-easy-way
wlandau
on 26 Jan 2019
This looks great; look forward to giving it a whirl!
On Sat, Jan 26, 2019 at 12:55 Will Landau notifications@github.com wrote:
Update: development drake now has a much friendlier (experimental) API. It
is much better than wildcards. Details:
https://ropenscilabs.github.io/drake-manual/plans.html#create-large-plans-the-easy-way—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/ropensci/drake/issues/199#issuecomment-457851305, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AAIUgzHzhqtJLOuRTeq3iULg6Pp6EXAZks5vHJZ3gaJpZM4RwTlC
.
jzelner
on 27 Jan 2019
Related issues
wlandau
·
8Comments
 maelle
·
8Comments
maelle
·
8Comments
 djbirke
·
3Comments
djbirke
·
3Comments
 pat-s
·
5Comments
wlandau
·
8Comments
pat-s
·
5Comments
wlandau
·
8Comments