Deeplearning4j: How can I speed up KDTree search on Android?
Deeplearning4j issue
Issue Description
- KDTree instance storing so many vectors works slowly. I did a performance evaluation to show the cost time of
knnmethod on Android 9.0.
- Vector length: 512
List<Pair<Double, INDArray>> pairs = tree.knn(Transforms.unitVec(targetNDArray), QUERY_DIST_THRESHOLD);
- Vector length: 512
Here is the result:
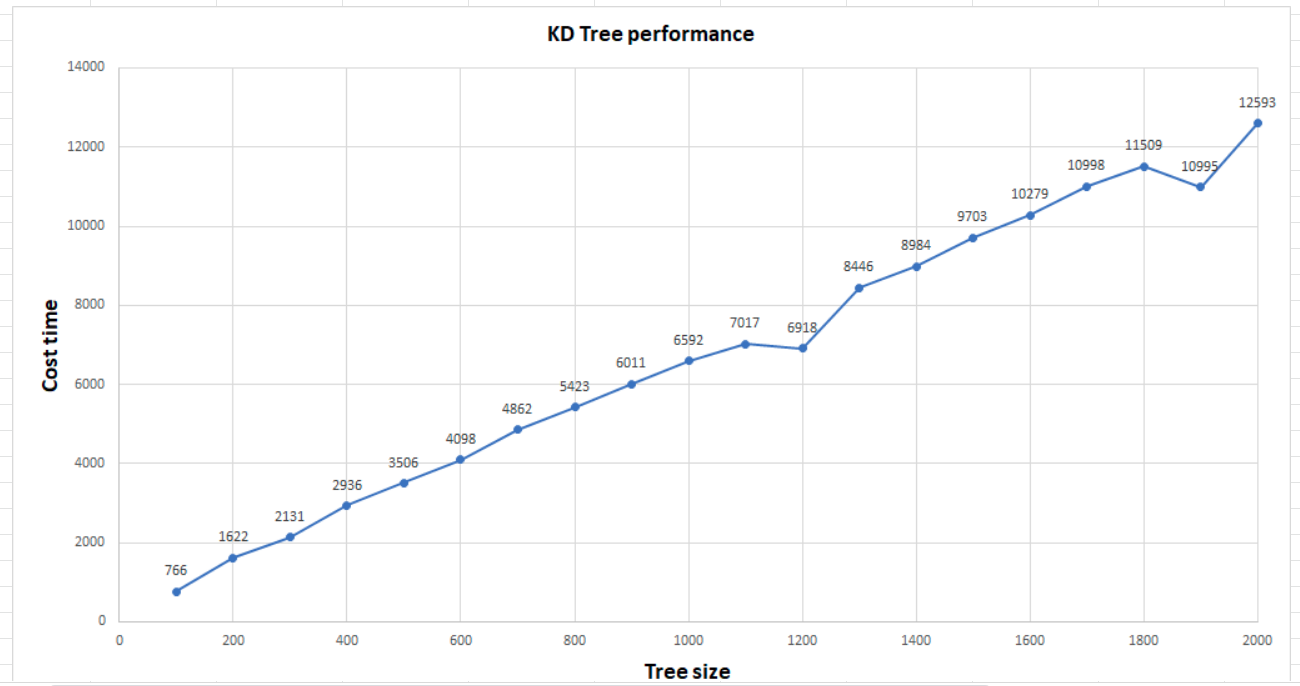
The cost time for 10000 vectors is 61.1 sec
- Is there any way to make the query faster? I need to implement nearest neighbor search and plan to make it real-time with upto 50000 vectors in tree.
Version Information
Please indicate relevant versions, including, if relevant:
- Deeplearning4j version:
1.0.0-beta4 - Platform information (OS, etc):
Android 9.0 (Snapdragon 845) - CUDA version, if used
- NVIDIA driver version, if in use
Additional Information
Where applicable, please also provide:
- Full log or exception stack trace (ideally in a Gist: gist.github.com)
- pom.xml file or similar (also in a Gist)
Contributing
If you'd like to help us fix the issue by contributing some code, but would
like guidance or help in doing so, please mention it!
 mexeniz
mexeniz
All 8 comments
We'll be glad to take a look into it. Will you be able to benchmark snapshots once we have improvements ready?
 raver119
on 17 Oct 2019
raver119
on 17 Oct 2019
Also, are you benchmarking it with random vectors and it looks like you have 512 dimensions so the following probably also applies to your data:
Due to the curse of dimensionality which leads most searches in high dimensional spaces to end up being needlessly fancy brute searches,k-d trees are not suitable for efficiently finding the nearest neighbour in high-dimensional spaces. As a general rule, if the dimensionality is k, the number of points in the data, N, should be N >> 2^k . Otherwise, when k-d trees are used with high-dimensional data, most of the points in the tree will be evaluated and the efficiency is no better than exhaustive search,[11] and, if a good-enough fast answer is required, approximate nearest-neighbour methods should be used instead.
So if you don't have more than 2^512 data points (you don't!), there is no point in using a kd-tree for this case.
If you are using looking for cosine similarity as your distance metric, it is usually a lot faster to save the vectors in a normalized form, and then pick the best matches using a matrix multiplication and iamax
 treo
on 17 Oct 2019
treo
on 17 Oct 2019
@raver119 Sure!
@treo Yes, I am benchmarking with random vectors, but all of them are unit vectors. My distance metric is Euclidean distance.
mexeniz
on 21 Oct 2019
@mexeniz both euclidean distance and cosine similarity produce the same ordering when used on unit vectors. So my suggestion should still work for your use case.
In any case, even after improving our kd-tree performance, you will still see a fancy linear search, as you would need more entries than there are atoms in the universe (about 10^154) before your search would start seeing a speed up from using kd-trees.
A kd-tree is only really effective on low dimensional inputs, and 512 dimensions is anything but low dimensional. See https://en.wikipedia.org/wiki/Curse_of_dimensionality for more information on that.
But I agree, it still shouldn't take 60 seconds to search through a set of just 10000 vectors.
treo
on 21 Oct 2019
On regular laptop CPU it doesn't actually take 60s, so part of this is mobile cpu. We're looking into performance optimizations now.
Can we see your source code, btw?
raver119
on 21 Oct 2019
@raver119 Great to hear that. Please wait for me. I will convert evaluation code on Android for JAVA project soon.
mexeniz
on 25 Oct 2019
@raver119 Here are source codes for evaluation
https://github.com/mexeniz/dl4j-kdtree-android-evaluation
https://github.com/mexeniz/dl4j-kdtree-java-evaluation
mexeniz
on 28 Oct 2019
@raver119 Hi, any update about the optimization?
mexeniz
on 14 Feb 2020
Related issues
 AlexDBlack
·
4Comments
AlexDBlack
·
4Comments
 atuzhykov
·
4Comments
atuzhykov
·
4Comments
 novog
·
4Comments
novog
·
4Comments
 AlexanderSerbul
·
3Comments
AlexDBlack
·
4Comments
AlexanderSerbul
·
3Comments
AlexDBlack
·
4Comments
Most helpful comment
Also, are you benchmarking it with random vectors and it looks like you have 512 dimensions so the following probably also applies to your data:
So if you don't have more than 2^512 data points (you don't!), there is no point in using a kd-tree for this case.
If you are using looking for cosine similarity as your distance metric, it is usually a lot faster to save the vectors in a normalized form, and then pick the best matches using a matrix multiplication and iamax