Dataverse: MakeDataCount counts all relationships as citations
As written, I think the MakeDataCountApi citation counting will also report the "unique-resolutions-machine" and similar relationships between a dataset and the report sent in to register its views and downloads. Those events have the same structure and the code only checks subj-id and obj-id and doesn't filter on "source-id" or "relation-type-id".
The example URL in the code (curl https://api.datacite.org/events?doi=10.7910/dvn/hqzoob&source=crossref) shows the type of view/download events that I think will get picked up.
I have not confirmed this specifically, but instead noted that this code does pick up the is-part-of relationships between files and a dataset that we've added for QDR ( #2778 is related) and those are reported as citations. That lead me to inspect the code and, unless I missed something, I think it will count the reported views/downloads as well.
Minimally, I think it should filter those out, but there's a potentially larger question of whether all of the relationships DataCite will report should count as citations. That may be a MakeDataCount question rather than for Dataverse alone. (My guess is that there are few systems that give DOIs to datasets and files as Dataverse can, and few if any of those actually reporting the ispartof/haspart relationship to DataCite as we've started to do in QDR and as is planned in #2778).
 qqmyers
qqmyers
All 11 comments
FWIW: https://support.datacite.org/v1.1/docs/eventdata-query-api-guide#section-filtering-events-links-by-type says the following should excluded:
HasVersion
IsVersionOf
IsNewVersionOf
IsPreviousVersionOf
IsIdenticalTo
HasPart
IsPartOf
They recommend retrieving all relationships and filtering on the client side. (In their api, you can get events for just one type, but not for all types except the above, so there's no easy way to exclude 1000 ispartof relationships. :-( ), which means paging probably has to be managed even if there aren't many 'real' citations.
qqmyers
on 12 Sep 2019
@qqmyers I appreciate the legwork on this. Out of curiosity, have you tried hitting the DataCite API directly (outside of Dataverse, I mean) to try to figure out how many dataset citations QDR (or TDL) or any installation has accumulated? Someday I'd love to get a count of all citations for all datasets hosted in an installation of Dataverse. 😄
 pdurbin
on 12 Sep 2019
pdurbin
on 12 Sep 2019
@qqmyers, I see that the recent PR to get a better count of citations uses a whitelist with the relation types "cites", "references" and their inverses. I'm curious why just those four. From what I can tell, for QDR's datasets the Event Data database has 3 "references" relation and 55 "is-supplement-to" relations, like this EventData record. Should the whitelist include "is-supplement-to" and its inverse?
 jggautier
on 18 Nov 2019
jggautier
on 18 Nov 2019
@jggautier - probably. I wasn't sure which relationships would be considered citation versus 'structural' across the community so I thought I'd start with the obvious ones (and make sure people thought a whitelist was a good approach). If there's community agreement, I can add others as needed (or others can - the PR is editable). If not, it may be that the whitelist has to be configurable. We'll probably be discussing this at QDR later today (if @adam3smith doesn't chime in here first).
FWIW: what that PR does already is get rid of the 2000+ is-part-of/has-part relationships between files and datasets that QDR is reporting, which then gives us a reasonable number of citations to start looking at GUI/display issues, etc.)
qqmyers
on 18 Nov 2019
Yeah, this is a super-tricky quesiton. Here was DataCite's original thinking on this
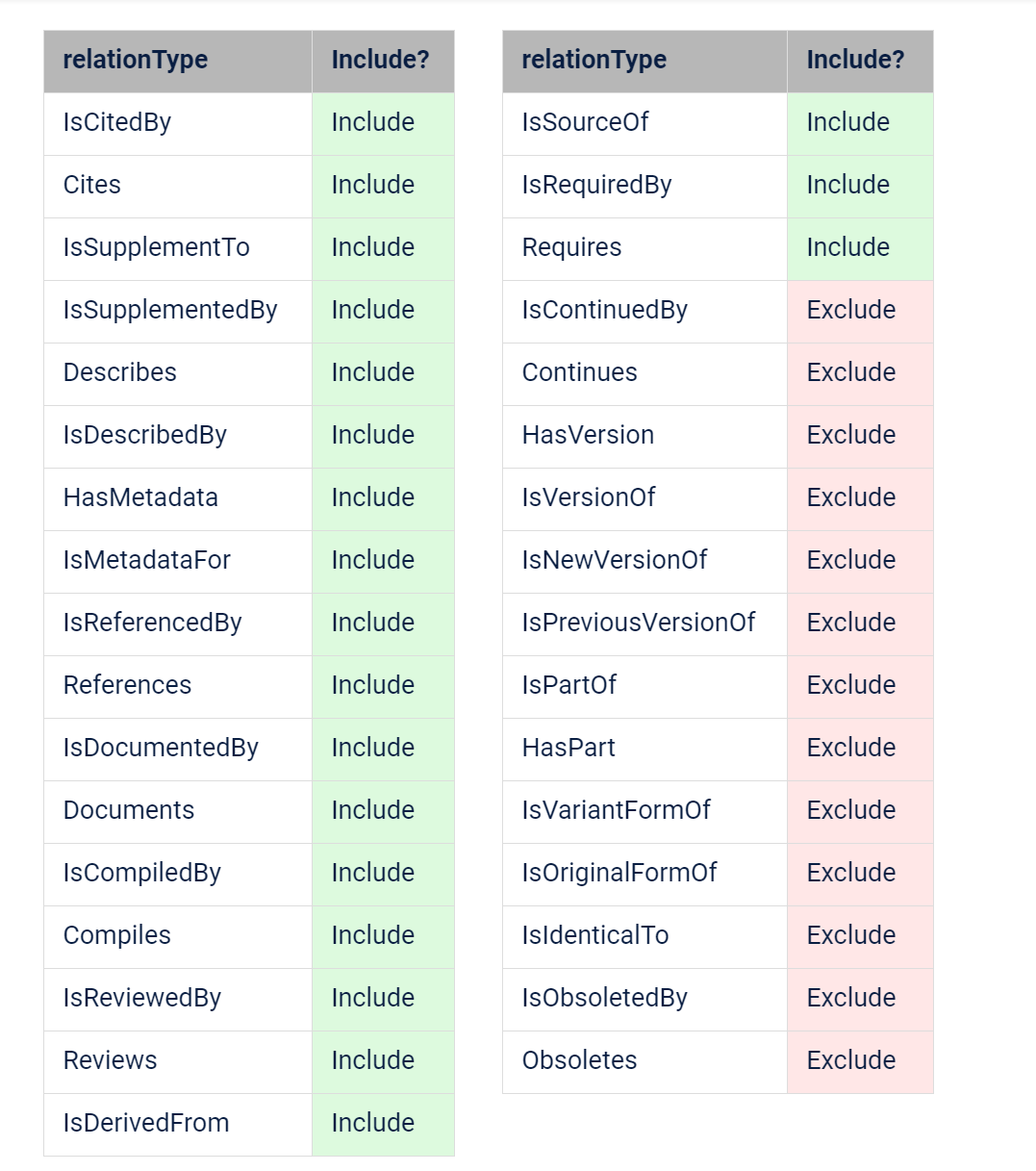
(with duplicates removed) for their own counts. Discussions in the steering group indicated that that was likely still too broad. One particular challenge they face is that clients implement the relationships very inconsistently. E.g. ICPSR uses "isDocumentedBy" for their (very substantial) catalog of data citations. (Don't ask me why).
I think @jggautier is definitely right that isSupplementTo should be included.
On the other hand, I would _exclude_ outgoing cites and references -- e.g. if a dataset cites 100 articles (not completely implausible e.g. for historic data) that shouldn't be reflected. Similarly, incoming isCitedBy and isReferencedBy shouldn't be included.
Can we make that sort of distinction in the data?
 adam3smith
on 18 Nov 2019
adam3smith
on 18 Nov 2019
A couple thoughts:
The event record includes the ids for the subject and object as well as the relationship name, so one can definitely filter on the direction of the relationship. There's also a 'source-id' that could be used as a filter - the is-part/has-part relationships between datasets and files are from 'datacite-related' (versus 'datacite-crossref', 'crossref', etc.). So one could potentially distinguish between a file being metadata-for a dataset and a dataset being metadata-for a paper (or vice versa) - the latter meant as an example where one might consider a relationship to be a citation if the subject/object are really independent.
I don't know if MDC addresses it, but one could also split citations of this dataset from things this dataset cites and display both.
qqmyers
on 18 Nov 2019
@dlowenberg do you have any guidance here or some examples of how other repositories have implemented this? Thank you!
 djbrooke
on 20 Nov 2019
djbrooke
on 20 Nov 2019
For some reason it won't let me tag other people but if you can loop in Martin Fenner or Kristian Garza that would be great as this is really more of a DataCite thing. I can say what we have done at Dryad but maybe best for DataCite folks to weigh in here and I can pickup after!
 dlowenberg
on 20 Nov 2019
dlowenberg
on 20 Nov 2019
Thanks @dlowenberg! Tagging @mfenner
djbrooke
on 21 Nov 2019
I was curious to see what possible citations would be excluded if only a certain number of relation types were included, so I used a (probably very poorly written) script to mine the Event Data database. Script and data are in the attached zip file. Thought others might be curious.
Given a list of DOIs, the script limits the number of relation types to record, but I did less limiting when using DOIs from Zenodo, since it's a self-curated repository that lets depositors choose from many relation types, so you can really see how the relation types are used inconsistently, but also see which relation types are most popular among many different types of people. I'd be curious to hear from the Zenodo folks if they've looked into how the relation types are being used.
In their UI, I find it interesting that Zenodo also breaks the list of related research objects by which relation type was used to describe the relationship, e.g. https://doi.org/10.5281/zenodo.1188975
jggautier
on 24 Nov 2019
I think we may want to raise the priority on this. When I just set TDL up with MDC and ran the weekly script to get citations, stock v4.20 pulled back the list of reports that were uploaded by counter-processor as citations: e.g. from the Dataverse citations pop-up:
Citations for this dataset are retrieved from Crossref via DataCite using Make Data Count standards. For more information about dataset metrics, please refer to the User Guide.
https://api.datacite.org/reports/4fff1804-5879-4417-a9fe-72bd99574828
https://api.datacite.org/reports/65305d0e-42a7-4fd8-a835-fbab46eeab24
https://api.datacite.org/reports/46347bc7-c6c1-4847-aec7-3da1f2772b32
https://api.datacite.org/reports/1f4e9d1a-a006-489b-a3ba-de5568190367
https://api.datacite.org/reports/2dba48dd-ff45-479e-b24b-3271e9ef71a7
I don't see this behavior on QDR where I've implemented ~ the PR for this issue to filter these out. I don't know if this is a change at DataCite, or just that testing the citation retrieval has always been done for datasets that hadn't yet had metrics collected via counter-processor, but I think this is unusable as is.
For TDL, I've removed these 'citations' - truncated the datasetexternalcitations table and turning off the weekly cron job. (I didn't see any real citations by other DOIs to keep - I'll be checking with them to see if some are expected.)
qqmyers
on 2 Oct 2020
Related issues
 pameyer
·
55Comments
pameyer
·
55Comments
 eaquigley
·
52Comments
eaquigley
·
52Comments
 bmckinney
·
75Comments
bmckinney
·
75Comments
 tdilauro
·
55Comments
tdilauro
·
55Comments
 acoppock
·
44Comments
acoppock
·
44Comments
Most helpful comment
@jggautier - probably. I wasn't sure which relationships would be considered citation versus 'structural' across the community so I thought I'd start with the obvious ones (and make sure people thought a whitelist was a good approach). If there's community agreement, I can add others as needed (or others can - the PR is editable). If not, it may be that the whitelist has to be configurable. We'll probably be discussing this at QDR later today (if @adam3smith doesn't chime in here first).
FWIW: what that PR does already is get rid of the 2000+ is-part-of/has-part relationships between files and datasets that QDR is reporting, which then gives us a reasonable number of citations to start looking at GUI/display issues, etc.)