Dataverse: Allow upgrades across versions
I want to release as often as possible in order to get valuable features and bug fixes out to the community. There's some tension though, as more releases can create a burden for sysadmins in the community, as we recommend that upgraders step through each Dataverse release on their way to the most recent version. My thought is to allow easier upgrading to the most recent version, but any other thoughts or proposals are welcome, especially from the sysadmins in the community.
Tagging @scolapasta for a possible tech hours discussion.
 djbrooke
djbrooke
All 26 comments
@djbrooke I like the idea of releasing more often to get fixes and features out to the community! I think there's a couple ways of approaching the situation and the desired solution may actually be a combination of what I'm thinking.
As you mentioned, if there's more frequent releases (ideally) sysadmins should be able to skip ahead versions. The more I think about it, the more I feel this is a requirement rather than a _nice to have_. The reason being is so sysadmins aren't overburdened with upgrading to _every_ intermediate patch or minor to get to the latest patch or minor they're actually interested in/may need.
Basically, if the requirement is to upgrade to every intermediate version and they're a bit behind with releases, it (potentially) disincentivizes sysadmins to prioritize upgrades in their workload further causing more pain down the line when it needs to be done, making the faster release schedule somewhat moot, etc.
With that being said I don't know the level of effort required to implement this for the project... There's also the consideration of having the ability to revert to the previously deployed version if needed.
Also, food for thought, what if the project leveraged pre-releases to allow for those bug fixes/features to get out quickly? Basically you could have pre-release 4.9.2-0.x.x (following semver) and just bump that and keep your current release schedule?
Thoughts?
 andrewSC
on 20 Aug 2018
andrewSC
on 20 Aug 2018
I'll second Andrew's plug for Semantic Versioning but I personally don't find stepping through each release prohibitive as I love my archivists and our archive.
I think I can safely speak for Odum in saying that we wait for Harvard to upgrade, and for Thu-Mai and Mandy to have used any new version heavily there, before we consider upgrading. We love "known-good" releases (such as 4.7.1 and 4.8.6, or if you've ever administered a NetApp, 7.0.4, wistfully referred to by their field engineers).
So I think I too am lobbying for fewer production releases with heavier pre-release testing.
 donsizemore
on 20 Aug 2018
donsizemore
on 20 Aug 2018
I think it makes sense to support skipping incremental versions during upgrade (potentially only minor versions). If possible, one other factor that could encourage more frequent upgrading would be to support a "mayday" fall-back to a previous "known-good" version (without requiring a database/index restore). There are a number of articles discussing blue/green deployments that might be at least partly applicable here.
 pameyer
on 20 Aug 2018
pameyer
on 20 Aug 2018
We met at tech hours today and decided as a first step (and the scope of this issue) that we will extract the db scripts that get created when you deploy, then write a new script that takes in two parameters, startVersion and endVersion, and it will generate a script that will do all the db changes required, including:
- creating the tables that would have been created by deployment of each version
- update scripts from each release
We may optionally include the following in the script, if straightforward:
- clean up this script to not run redundant scripts from the different versions
- confirm that you are on the version you state with startVersion
- run the script
This seems a good first step, as most of the challenges of upgrading across version stem from db related changes. After we have this, we can open other issues for other needed solutions.
 scolapasta
on 2 Oct 2018
scolapasta
on 2 Oct 2018
Here are the raw notes from our tech hours discussion on this issue. Gustavo's summary has come out of this discussion:
- What breaks if we skip versions?
- SQL updates
- JPA updates between versions
- Glassfish ddl (dml?) scripts
- e.g. /usr/local/glassfish4/glassfish/domains/domain1/generated/ejb/dataverse-4.9.2/dataverse-4.9.2_VDCNet-ejbPU_createDDL.jdbc
- it keeps the actual sql commands that create the tables when glassfish deploys an ejb application
- Can we use create or extend tables to avoid running multiple upgrade scripts
- Can we create a script that runs through upgrading actions, providing version numbers
- If so we should provide better errors about the scripts when running multiples
- We need to confirm that the version they think they are starting on is correct
- This is what we will try first
- What instructions are we writing?
- Tell people to back-up
- Check the state between every upgrade? With an automated script?
- Maybe some way of telling people what was changed between those versions (a table?)
 matthew-a-dunlap
on 3 Oct 2018
matthew-a-dunlap
on 3 Oct 2018
FWIW: Given that the normal instructions have you delete the generated dir, I'm not sure that the actual deployment of the intermediate wars does anything. For TDL, I've been successful in basically applying the non-war instructions for each version sequentially and then deploying the final war.I did that for 4.8.4-4.8.6 and then for 4.8.6-4.9.3 (just on the dev/test machine so far.) Doing things sequentially is critical - later scripts sometimes update things created in prior patches. And there are cases where doing all the steps is not necessary but harmless. For example, the 4.8.5-6 upgrade script modifies a table that was only created if you deployed 4.8.5, so the sql gives warnings, but the 4.8.6 creates the table correctly to start (presumably because the scripts in /generated get updated). Similarly, it appears that the instruction to sync the preprocess.R file between TwoRavens and Dataverse is no longer needed/valid in 4.9.3, so syncing them before deploying the 4.9.3 war works (because 4.9.3 writes its new version), but the sync itself isn't needed. There are also things like the 4.9 note to generate DOIs for existing published files that, if one is going straight to 4.9.3 should not be done at all. (So far, this seems like an outlier, but for the general case, we should watch for things where sequential upgrades would NOT work.)
Overall, I haven't seen anything where deploying the intermediate wars is necessary (and if you have, please let me know!). If anyone wants specific notes for 4.8.6-4.9.3, I'd be happy to share...
 qqmyers
on 4 Oct 2018
qqmyers
on 4 Oct 2018
@qqmyers good examples. Thanks for your input. You seem to grok the situation quite well. The SQL update scripts we've been writing for years never have "add table" statements in them. We figure the war file will add the tables (with warnings, unfortunately, which is what #4920 is about). So one of the main deliverables of this issue is capturing the "createDDL" file mentioned above as part of our release process. This will probably benefit #4040 because within OpenShift the process of starting Glassfish just for the purpose of deploying the war file to create tables is time consuming. With the createDDL file available in the future, we can hopefully speed this up because the postgres container could just use the createDDL directly without involving Glassfish /cc @danmcp @thaorell . This is the way @craig-willis did it as the first person to Dockerize Dataverse. See https://github.com/nds-org/ndslabs-dataverse/blob/4.7/dockerfiles/README.md#generating-ddl says the following.
Generating DDL
The Dataverse Dockerfile depends on a pre-generated DDL script. Below are the steps to generate DDL.
Modify WEB-INF/classes/META-INF/persistence.xml, changing the ddl-generation to generate:
<property name="eclipselink.ddl-generation" value="create-tables"/> <property name="eclipselink.ddl-generation.output-mode" value="both"/> <property name="eclipselink.application-location" value="/tmp/"/> <property name="eclipselink.create-ddl-jdbc-file-name" value="createDDL.sql"/>
Oh and while I'm thinking of it, as I just mentioned at https://groups.google.com/d/msg/dataverse-community/Tyfz7d5xQ24/EN9OfGPlAQAJ we we currently say, "When upgrading within Dataverse 4.x, you will need to follow the upgrade instructions for each intermediate version" at http://guides.dataverse.org/en/4.9.3/installation/upgrading.html so we should update this text as part of the pull request for this issue.
 pdurbin
on 4 Oct 2018
pdurbin
on 4 Oct 2018
Hey guys, do I get the right impression that you are suffering from migration hell?
Any chance you might consider using tooling like Flyway or Liquibase to make life easier?
 poikilotherm
on 5 Oct 2018
poikilotherm
on 5 Oct 2018
@poikilotherm yes, we are suffering from migration hell. 😄
I brought up Flyway at tech hours on Tuesday (and I was looking briefly again at the Liquibase website) but the idea was dismissed and I can't remember exactly why.
Do you have experience with either of these tools or others? In the room there were people who have experience with Django's "migrations" feature ( https://docs.djangoproject.com/en/2.1/topics/migrations/ ) which apparently "just works". It would be nice to have something similar for Java and JPA (Java Persistence API).
pdurbin
on 5 Oct 2018
I have been working with Django migrations and used MongoDB related Java migration stuff a bit.
Currently cannot call myself an expert in this field, but I am aware that using this kind of tooling is state of the art and bullet-proof industry grade stuff.
I can just encourage every dev to read up these notes by Scott Allen: https://odetocode.com/blogs/scott/archive/2008/01/30/three-rules-for-database-work.aspx
Flyway and Liquibase seem to be the prominent big players in this field. Good 4 minute readup: https://reflectoring.io/database-refactoring-flyway-vs-liquibase
IMHO Flyway seems to be a better fit for Dataverse, as the abstraction is not needed and the solution is more lightweight.
poikilotherm
on 5 Oct 2018
"I brought up Flyway at tech hours on Tuesday (and I was looking briefly again at the Liquibase website) but the idea was dismissed and I can't remember exactly why."
@pdurbin because I thought I remembered that the open source version of Flyway meant you were locked into whatever the most recently released postgres version was.
pameyer
on 5 Oct 2018
@pameyer what do you mean by locked in? You are locked into Postgres 9.6 anyway right now, aren't you?
If this dependency was changed to Postgres 10 or 11, this would mean an upgrade outside of Dataverse anyway (maybe using Flyway CLI) either via dump/restore or pg_upgrade...?
About Flyway + Postgres compatibility: https://flywaydb.org/documentation/database/postgresql
There seems to be support for versions I would call "old aged" and even methusalems are supported if you buy a license...
poikilotherm
on 5 Oct 2018
Interesting. Here's a screenshot from https://flywaydb.org/documentation/database/postgresql (thanks for the link):
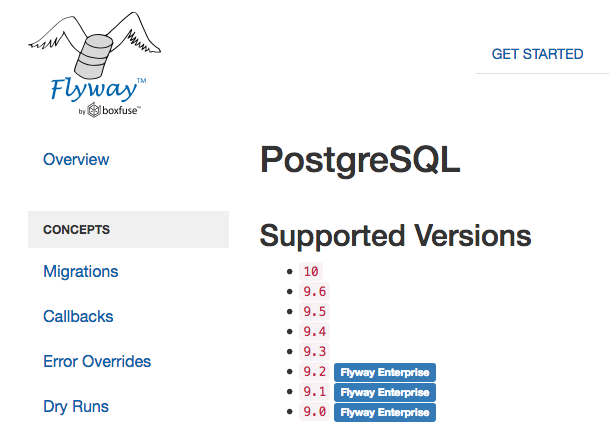
When you click "download/pricing" at https://flywaydb.org/download they call this feature of Enterprise Edition "Older database versions compatibility".
pdurbin
on 5 Oct 2018
Not specifying how this is done, but in favor of easier upgrading to the most recent version without having to step through each individual release.
 shlake
on 5 Oct 2018
shlake
on 5 Oct 2018
I just approved pull request #5317 but I did leave some suggestions in a review that could be implemented now or later. I encourage @andrewSC @donsizemore @pameyer @qqmyers @shlake and anyone else who's interested to take a look.
pdurbin
on 15 Nov 2018
-capture errors thrown by scripts to aid in troubleshooting
-currently appears to run to completion preternaturally fast but not sure it works (ends in error when error logging enabled)
 kcondon
on 16 Nov 2018
kcondon
on 16 Nov 2018
@kcondon Please try again!
Note that I have renamed the script (it is now called dbupgrade.sh); the readme file and the release notes have been updated accordingly.
The script now saves the output of produced by the sql scripts, as dbupgrade.{xxx}.log.
 landreev
on 16 Nov 2018
landreev
on 16 Nov 2018
I agree about using flyway, I have used it before and it makes migration very easy, it basically has another db table which track which sql's were executed before.
Right now if you run war you just get an error that you have duplicates, and if you are using some pgsql then it would just execute it every time.
 MrK191
on 21 Nov 2018
MrK191
on 21 Nov 2018
I pulled this out of QA so we can discuss @MrK191's comment above about flyway. In IRC he sounded wiling to make a pull request: http://irclog.iq.harvard.edu/dataverse/2018-11-21#i_79702
Also, no information has get been added to the "making releases" page. See https://github.com/IQSS/dataverse/pull/5317#discussion_r233906767
pdurbin
on 21 Nov 2018
This is close to being merged and we should not increase scope. Moving back to QA.
@MrK191 - can you please create a separate issue about Flyway?
djbrooke
on 21 Nov 2018
@djbrooke makes sense but our solution won't work without a change to our release process so I added the necessary steps to our "making releases" page in 31210f181
pdurbin
on 21 Nov 2018
Perfect, thanks
djbrooke
on 21 Nov 2018
This works, tested upgrade from v4.0 to v4.9.4 with existing data. Passing back to @landreev to update doc.
kcondon
on 26 Nov 2018
I was still working on the extra documentation under "making releases", yes. (checked in now)
As for flyway - if somebody makes a PR with a solution that works, I see no problem with accepting it. But I don't see any reason to do it in the context of this issue either; this scripting solution works, and it may help some installations out there. And the cost of having to add the 2 extra files to a release is fairly minimal. If there's another solution that works, great.
landreev
on 27 Nov 2018
@landreev I made flyway work so I can make PR. The issue with scripting is that it complicates automatic deployment and it adds additional manual step for something that can be automated.
MrK191
on 27 Nov 2018
@MrK191 thanks for offering to make a pull request for flyway and for opening #5344 to track this work!
pdurbin
on 27 Nov 2018
Related issues
 jggautier
·
3Comments
matthew-a-dunlap
·
4Comments
jggautier
·
3Comments
matthew-a-dunlap
·
4Comments
 raprasad
·
5Comments
jggautier
·
4Comments
raprasad
·
5Comments
jggautier
·
4Comments
 amberleahey
·
3Comments
amberleahey
·
3Comments
Most helpful comment
FWIW: Given that the normal instructions have you delete the generated dir, I'm not sure that the actual deployment of the intermediate wars does anything. For TDL, I've been successful in basically applying the non-war instructions for each version sequentially and then deploying the final war.I did that for 4.8.4-4.8.6 and then for 4.8.6-4.9.3 (just on the dev/test machine so far.) Doing things sequentially is critical - later scripts sometimes update things created in prior patches. And there are cases where doing all the steps is not necessary but harmless. For example, the 4.8.5-6 upgrade script modifies a table that was only created if you deployed 4.8.5, so the sql gives warnings, but the 4.8.6 creates the table correctly to start (presumably because the scripts in /generated get updated). Similarly, it appears that the instruction to sync the preprocess.R file between TwoRavens and Dataverse is no longer needed/valid in 4.9.3, so syncing them before deploying the 4.9.3 war works (because 4.9.3 writes its new version), but the sync itself isn't needed. There are also things like the 4.9 note to generate DOIs for existing published files that, if one is going straight to 4.9.3 should not be done at all. (So far, this seems like an outlier, but for the general case, we should watch for things where sequential upgrades would NOT work.)
Overall, I haven't seen anything where deploying the intermediate wars is necessary (and if you have, please let me know!). If anyone wants specific notes for 4.8.6-4.9.3, I'd be happy to share...