Darknet: need instruction on writing a self-defined network using darknet
Hi,there.I'm trying to implement a MOT network using darknet but got some error without any clue ,could anybody tell me what's going wrong?
network structure
The network structure of Simple Online and Realtime Tracking with a Deep Association Metric is below
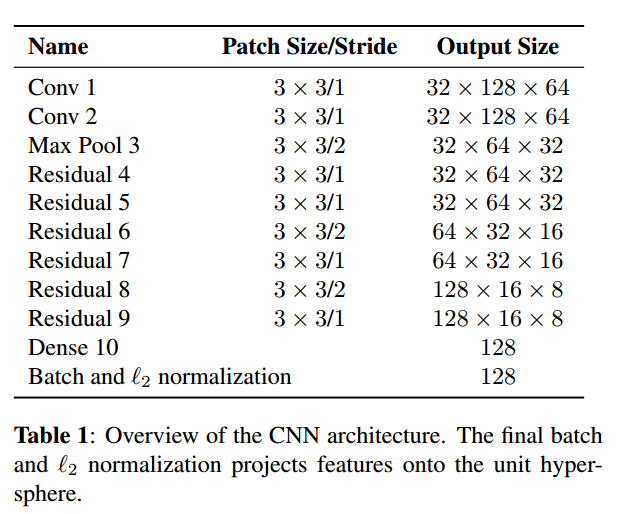
my cfg file
[net]
batch=64
subdivisions=64
height=256
width=128
channels=3
hue=.1
saturation=.75
exposure=.75
policy=poly
power=4
max_batches = 100000
momentum=0.9
decay=0.0005
learning_rate=0.001
burn_in=10000
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=elu
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=elu
[maxpool]
size=3
stride=2
# Residual Block stride=1,filters=32
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=elu
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=elu
[shortcut]
activation=elu
from=-3
# Residual Block stride=1,filters=32
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=elu
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=elu
[shortcut]
activation=elu
from=-3
# Residual Block increase dim,stride=2,filters=64
[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=elu
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=elu
[shortcut]
activation=elu
from=-3
# Residual Block increase dim,stride=1 ,filters=64
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=elu
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=elu
[shortcut]
activation=elu
from=-3
# Residual Block increase dim,stride=2 ,filters=128
[convolutional]
batch_normalize=1
filters=128
size=3
stride=2
pad=1
activation=elu
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=elu
[shortcut]
activation=elu
from=-3
# Residual Block increase dim,stride=1 ,filters=128
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=elu
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=elu
[shortcut]
activation=elu
from=-3
[dropout]
probability=.4
# full connected layer
[connected]
output=128
activation=elu
# L2Norm layer
[l2norm]
[connected]
output=1501
activation=elu
# softmax layer
[softmax]
groups=1
Data
The MARS dataset consist of 1501 class with about one milion of image.
I've prepared my data file according to cifar10 example as below
trainval.txt
/home/ss/data/MOTData/train_in_one/0105C6T0044F121_0105.jpg
/home/ss/data/MOTData/train_in_one/0717C3T0008F005_0717.jpg
/home/ss/data/MOTData/train_in_one/0811C3T0021F075_0811.jpg
/home/ss/data/MOTData/train_in_one/0603C3T0001F031_0603.jpg
...
mot.names
0003
0005
0007
0009
0011
0013
0015
0017
0019
0021
...
labels
Exactly the same as mot.names
mot.data
classes=1501
train=data/mot/mot_train_new.txt
valid=data/mot/mot_test_new.txt
labels=data/mot/mot_labels.names
names =data/mot/mot_labels.names
backup=backupMOT/
Run
I've ran training command as below
./darknet classifier train data/mot/mot.data cfg/mot.cfg
output error
I got error like
1
layer filters size input output
0 conv 32 3 x 3 / 1 128 x 256 x 3 -> 128 x 256 x 32 0.057 BFLOPs
1 conv 32 3 x 3 / 1 128 x 256 x 32 -> 128 x 256 x 32 0.604 BFLOPs
2 max 3 x 3 / 2 128 x 256 x 32 -> 64 x 128 x 32
3 conv 32 3 x 3 / 1 64 x 128 x 32 -> 64 x 128 x 32 0.151 BFLOPs
4 conv 32 3 x 3 / 1 64 x 128 x 32 -> 64 x 128 x 32 0.151 BFLOPs
5 res 2 64 x 128 x 32 -> 64 x 128 x 32
6 conv 32 3 x 3 / 1 64 x 128 x 32 -> 64 x 128 x 32 0.151 BFLOPs
7 conv 32 3 x 3 / 1 64 x 128 x 32 -> 64 x 128 x 32 0.151 BFLOPs
8 res 5 64 x 128 x 32 -> 64 x 128 x 32
9 conv 64 3 x 3 / 2 64 x 128 x 32 -> 32 x 64 x 64 0.075 BFLOPs
10 conv 64 3 x 3 / 1 32 x 64 x 64 -> 32 x 64 x 64 0.151 BFLOPs
11 res 8 64 x 128 x 32 -> 32 x 64 x 64
12 conv 64 3 x 3 / 1 32 x 64 x 64 -> 32 x 64 x 64 0.151 BFLOPs
13 conv 64 3 x 3 / 1 32 x 64 x 64 -> 32 x 64 x 64 0.151 BFLOPs
14 res 11 32 x 64 x 64 -> 32 x 64 x 64
15 conv 128 3 x 3 / 2 32 x 64 x 64 -> 16 x 32 x 128 0.075 BFLOPs
16 conv 128 3 x 3 / 1 16 x 32 x 128 -> 16 x 32 x 128 0.151 BFLOPs
17 res 14 32 x 64 x 64 -> 16 x 32 x 128
18 conv 128 3 x 3 / 1 16 x 32 x 128 -> 16 x 32 x 128 0.151 BFLOPs
19 conv 128 3 x 3 / 1 16 x 32 x 128 -> 16 x 32 x 128 0.151 BFLOPs
20 res 17 16 x 32 x 128 -> 16 x 32 x 128
21 dropout p = 0.40 65536 -> 65536
22 connected 65536 -> 128
23 l2norm 128
24 connected 128 -> 1501
25 softmax 1501
Learning Rate: 0.001, Momentum: 0.9, Decay: 0.0005
509914
128 256
Segmentation fault (core dumped)
It was ran on a Nvidia 1080ti machine,i think batch=64 and subdivisions=64 is far enough to train such a small network. Any idea? Thank you in advance!
 shartoo
shartoo
All 5 comments
@shartoo Hi,
What parameters do you use in the Makefile?
Do you use this repo https://github.com/pjreddie/darknet or this https://github.com/AlexeyAB/darknet ?
What versions of CUDA and cuDNN do you use?
 AlexeyAB
on 1 Mar 2019
AlexeyAB
on 1 Mar 2019
GPU=1
CUDNN=1
opencv=1
I'm using pjreddie's darknet and my cuda version is 8.0. I can run cifar10 model ,it works .
shartoo
on 1 Mar 2019
@shartoo
May be there is some bug.
Just try to localize it:
- try to use square network size 256x256
- try to find empty last line in the
mot_train_new.txt - try to cooment
l2normanddropoutlayers
AlexeyAB
on 1 Mar 2019
Thank you for your advice, all of the image are 128x256 thus i can't change this. I've tried to commented l2norm it make no sense. I'll find if there were sth wrong in mot_train.txt
shartoo
on 1 Mar 2019
I‘ve found the problem now, there are only 625 classes in training data though the number ranges from 1 to 1501 but not continuous.I have to create new label file.Thank you!
shartoo
on 2 Mar 2019
Related issues
 Cipusha
·
3Comments
Cipusha
·
3Comments
 bit-scientist
·
3Comments
bit-scientist
·
3Comments
 siddharth2395
·
3Comments
siddharth2395
·
3Comments
 louisondumont
·
3Comments
louisondumont
·
3Comments
 kebundsc
·
3Comments
kebundsc
·
3Comments
Most helpful comment
I‘ve found the problem now, there are only 625 classes in training data though the number ranges from 1 to 1501 but not continuous.I have to create new
labelfile.Thank you!