Darknet: Training YOLOv3 with own dataset
Hi everyone,
Has anyone had success with training YOLOv3 for their own datasets? If so, could you help sort out some questions for me:
For me, I have a 5 class object detection problem. In the .cfg file, I have changed the number of classes and the number of filters to 3*(num_classes+5) = 30 in 3 different places. I can initiate the training but the loss blows up to start with and I am seeing a bunch of nans in the output massage (see snippet)

Here are my questions:
- Did you need to change the anchor box sizes and/or the number of anchors?
- Did you need to create the labels differently than for YOLO v2?
Thanks!
 sonalambwani
sonalambwani
All 218 comments
No you don't need to change your training set.
You need to calculate your anchors as previously on yolo2 but multiply by 32 (and round).
Then split the anchors among the layers. If you have 9 anchors you can split them 3 ways, but decide based on size. Each anchor should have 5+number of objects filters.
I got ok results with the default anchors but you could recompute. Remember your anchor calc should be the same scale as the input size for the network.
 ndg123
on 29 Mar 2018
ndg123
on 29 Mar 2018
@sonalambwani Just wait about 1000 iterations, and nan will disappear: https://github.com/AlexeyAB/darknet/issues/504#issuecomment-377290060
- You can re-calculate anchors, but it is not necessary. You can calculate anchors for Yolo v3 using this fork: https://github.com/AlexeyAB/darknet
and this command if in your cfg-filewidth=416andheight=416:
darknet.exe detector calc_anchors data/voc.data -num_of_clusters 9 -width 416 -heigh 416
This anchors you can use in your cfg-file (without multiplication by 32)
- You can use the same labels as for Yolo v2
 AlexeyAB
on 29 Mar 2018
AlexeyAB
on 29 Mar 2018
@AlexeyAB ,hello,but after waiting about 1000 iterations, and nan still appear:
 ss199302
on 30 Mar 2018
ss199302
on 30 Mar 2018
Hi,
I am trying to do Training YOLO on VOC.
below command i ma using , ./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
But nans keep on increasing. Is it normal or some issue.
Loaded: 0.000063 seconds
Region 82 Avg IOU: nan, Class: nan, Obj: nan, No Obj: nan, .5R: 0.000000, .75R: 0.000000, count: 1
Region 94 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: nan, .5R: -nan, .75R: -nan, count: 0
Region 106 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: nan, .5R: -nan, .75R: -nan, count: 0
3296: -nan, nan avg, 0.001000 rate, 0.416401 seconds, 3296 images
 satya2550
on 30 Mar 2018
satya2550
on 30 Mar 2018
I have a same issue. The error is shown in second yolo layer. Did you solve this problem?
 springkim
on 30 Mar 2018
springkim
on 30 Mar 2018
same tooooo
 ShiningCoding
on 30 Mar 2018
ShiningCoding
on 30 Mar 2018
@ss199302
If there are only some nan then training goes well, but if there are all nan then training goes wrong.
AlexeyAB
on 30 Mar 2018
@AlexeyAB
As you suggested, I am now training with my new dataset with the default COCO anchor boxes. I am training from "Scratch", i.e., no initialization with the pretrained convolutional weights as you have done in https://github.com/AlexeyAB/darknet/issues/504#issuecomment-377290060
For me, I see nans even after 2500 iterations. The loss (after starting off really high) has dropped within a reasonable range, but there is more of a fluctuation between the loss for each mini-batch.

Have you, or anyone else here, noticed similar behavior?
sonalambwani
on 30 Mar 2018
For me, I see nans even after 2500 iterations.
All lines have
nanvalues or only some lines?How many classes and images in your dataset? And what tool did you use for labeling?
What batch and subdivision do you use?
Do you use
random=1?Do you train using multi-GPU?
AlexeyAB
on 30 Mar 2018
It's just a few lines with nans.

Used an in-house tool for labeling.
batch=16, subdivisions = 16
Not sure about random=1. Where do I check/set that??
It's a single GPU.
sonalambwani
on 30 Mar 2018
@AlexeyAB
"How many classes and images in your dataset? And what tool did you use for labeling?"
5 classes, ~17k images in the training set.
sonalambwani
on 30 Mar 2018
@sonalambwani Looks like normal output of training.
AlexeyAB
on 30 Mar 2018
You have batch and subdivision 16. That means one image per iteration and depending on the density of objects in your images, it's possible that no object will be found in a given layer which will lead to nan. Also depends if the ground truths are similar to the anchors. If they are all very small for all very large then you may not detect them in the very large or very small layers.
So I agree with alexeyAB that this looks normal. Can you reduce the subdivisions so more images per mini batch.
ndg123
on 30 Mar 2018
I have a same issue

batch=64, subdivisions = 8
I have followed this instruction
I really didn't understand if I should change anchors in yolo-obj.cfg when i have own dataset.
 UgolUgol
on 30 Mar 2018
UgolUgol
on 30 Mar 2018
@ndg123
Thank you for your suggestions. I am now testing with batch = 64 and subdiv=16. Right off the bat, I see fewer nans. There are a few, but it's looking better.
sonalambwani
on 30 Mar 2018
per my training on customer dataset, If not all of them are nans, it is fine. since 3 different scales, that means in some scale, no object is detected. you may try different input image size, or divide into 2, or 4 different scales instead of 3? then the number of nans should change.
 lynnw123
on 30 Mar 2018
lynnw123
on 30 Mar 2018
@AlexeyAB thanks your reply,but i can't test anything
ss199302
on 2 Apr 2018
@AlexeyAB darknet.exe detector calc_anchors data/voc.data -num_of_clusters 9 -width 416 -heigh 416,this command how to write in ubuntu darknet?
ss199302
on 2 Apr 2018
@ss199302 ./darknet detector calc_anchors data/voc.data -num_of_clusters 9 -width 416 -heigh 416
 TheMikeyR
on 4 Apr 2018
TheMikeyR
on 4 Apr 2018
I am trying to run calc_anchors in linux using what @TheMikeyR says and it returns to command line immediately and gives no output. Is it supposed to print the anchors to std out? I'm new to C. Where can I find the code this command runs?
Also, I'm training on my own data, and the bounding boxes in my training data are all the exact same size, and they are all squares. Do I still need to specifiy more than one anchor?
 brieh
on 5 Apr 2018
brieh
on 5 Apr 2018
Is it possible to detect the Signature (or any handwritten area) in printed receipts using YOLO ? which would be the best cfg file for the same, and any suggestions before I start ?
 AbhishekAshokDubey
on 5 Apr 2018
AbhishekAshokDubey
on 5 Apr 2018
@brieh try Alexey repo https://github.com/AlexeyAB/darknet
Here is the code https://github.com/AlexeyAB/darknet/blob/master/src/detector.c#L839
TheMikeyR
on 5 Apr 2018
@TheMikeyR Thanks. I was using the pjreddie fork.
brieh
on 5 Apr 2018
@AlexeyAB hello! I use this command ./darknet detector calc_anchors data/voc.data -num_of_clusters 9 -width 416 -heigh 416 to get anchors,but it don't return anything.
ss199302
on 12 Apr 2018
@ss199302 same for me. Have u found the solution?
 ntudy
on 12 Apr 2018
ntudy
on 12 Apr 2018
@ss199302 @spenceryue97 did you create the labels (*.txt) files first?
sonalambwani
on 12 Apr 2018
@ss199302 @spenceryue97 and you're definitely using AlexeyAB's fork?
I never ended up getting it working. I didn't want to switch to AlexeyAB's fork because we've modified our fork of pjreddie's fork. I tried copy/pasting the code that does the clustering from AlexeyAB's detector.c to the one I have and remaking, but still gave no output.
brieh
on 12 Apr 2018
@sonalambwani Yes
ntudy
on 13 Apr 2018
@brieh I'm using pjreddie's repo
ntudy
on 13 Apr 2018
@spenceryue97 @brieh you can just get AlexeyAB's fork, run the calc_anchors and then take the numbers to your cfg in pjreddie's repo.
TheMikeyR
on 13 Apr 2018
@AlexeyAB Can you tell me when i use recall ,why my IOU appear nan,and recall and precision is 0.5% ,thanks!
ss199302
on 15 Apr 2018
@UgolUgol Have you compare the result between default anchors and the anchors calculated with the command from https://github.com/AlexeyAB/darknet?
 anguoyang
on 24 Apr 2018
anguoyang
on 24 Apr 2018
@AlexeyAB I am training my own objects, and am weirdly getting valudes for all Region 106 results and -nan for everything else:
```Region 106 Avg IOU: 0.103513, Class: 0.206469, Obj: 0.001993, No Obj: 0.000744, .5R: 0.000000, .75R: 0.000000, count: 4
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.001404, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000535, .5R: -nan, .75R: -nan, count: 0
Region 106 Avg IOU: 0.183575, Class: 0.167765, Obj: 0.002698, No Obj: 0.000716, .5R: 0.000000, .75R: 0.000000, count: 1
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.001364, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000517, .5R: -nan, .75R: -nan, count: 0
Region 106 Avg IOU: 0.112761, Class: 0.219895, Obj: 0.001320, No Obj: 0.000692, .5R: 0.000000, .75R: 0.000000, count: 4
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.001196, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000538, .5R: -nan, .75R: -nan, count: 0
Region 106 Avg IOU: 0.518243, Class: 0.616705, Obj: 0.000801, No Obj: 0.000739, .5R: 1.000000, .75R: 0.000000, count: 1
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.001336, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000534, .5R: -nan, .75R: -nan, count: 0
Region 106 Avg IOU: 0.067241, Class: 0.113757, Obj: 0.002734, No Obj: 0.000756, .5R: 0.000000, .75R: 0.000000, count: 7
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.001470, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000540, .5R: -nan, .75R: -nan, count: 0
Region 106 Avg IOU: 0.064037, Class: 0.159617, Obj: 0.005763, No Obj: 0.000764, .5R: 0.000000, .75R: 0.000000, count: 5
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.001454, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000550, .5R: -nan, .75R: -nan, count: 0
Region 106 Avg IOU: 0.092829, Class: 0.161946, Obj: 0.004937, No Obj: 0.000723, .5R: 0.000000, .75R: 0.000000, count: 8
813: 6.122332, 6.256896 avg, 0.000437 rate, 8.432507 seconds, 26016 images
```
It's the consistency that's worrying me. I've got 16 classes with around 4500 images. The one particularly odd thing about my setup is that I've set the height and width for every identified object to 0.01 (e.g. 2 0.808552 0.933797 0.01 0.01), as I only care about the position, not the bounds of the object. Hopefully that's not messing things up?
 jfries289
on 3 May 2018
jfries289
on 3 May 2018
@jfries289
every identified object to 0.01 so you will get nan for Region 82 and 94 always, but it isn't a problem. Training goes well.
But for slightly better accuracy, even if you need only position, it's better to set the real width and height of the objects, so Yolo will know which of 3 [yolo] layers (with higher receptive filed, or with higher resolution without subdiscretization) should be used to detect this object.
AlexeyAB
on 3 May 2018
@AlexeyAB Thanks for the reply. It's clear I need to improve my understanding of the regions, etc.
However, I'm still not sure my training is going successfully:
2612: 3.408263, 1.774134 avg, 0.001000 rate, 12.983424 seconds, 83584 images
My avg seems to be oscillating between 1.2 and 1.7. At this stage, I would have expected my avg to be lower. Is this the system temporarily stuck in a local minimum, or has something possibly gone wrong?
jfries289
on 3 May 2018
@jfries289
My avg seems to be oscillating between 1.2 and 1.7. At this stage, I would have expected my avg to be lower. Is this the system temporarily stuck in a local minimum, or has something possibly gone wrong?
I think this is because Yolo can't select the optimal [yolo]-layer (1 of 3), so the last [yolo]-layer predicts objects with the big error and it increases loss, also the difference between size that predicted by Yolo during training and size that you set is very large. Also may be something wrong else. I think you will able to detect objects, but with low accuracy.
I recommend you to set real sizes for object using Yolo_mark, then recalculate anchors and then start training from the begining.
In the Yolo v3, the labels with correct sizes of objects help to choose the optimal [yolo]-layer, i.e. help to train with higher accuracy.
AlexeyAB
on 3 May 2018
@AlexeyAB
In the Yolo v3, the labels with correct sizes of objects help to choose the optimal [yolo]-layer, i.e. help to train with higher accuracy.
If full-sized labels are not an option, would it be better for me to use Yolo v2? Or would I have the same issue there?
jfries289
on 3 May 2018
@jfries289
What is the range of the real sizes of objects in your dataset?
AlexeyAB
on 3 May 2018
@AlexeyAB
I would guess anywhere from 0.1 to 0.8.
jfries289
on 3 May 2018
@jfries289
In the Yolo v3, the labels with correct sizes of objects help to choose the optimal [yolo]-layer, i.e. help to train with higher accuracy.
If full-sized labels are not an option, would it be better for me to use Yolo v2? Or would I have the same issue there?
- If real sizes of objects are big - then probably will be better to use Yolo v2.
- If real sizes of objects can be big and small - then you should re-label your objects and train with Yolo v3.
But I have never tested training using such dataset as your with the constant values of width and height.
AlexeyAB
on 3 May 2018
I have a dataset of 21k face images. I already checked the labelled data using yolo_mark. I am using yolov3 with batch 64 and subdivisions 16
I am getting nan every where shall I wait for 1000 iterations?
here is the output:
73: -nan, -nan avg loss, 0.000000 rate, 649.007621 seconds, 4672 images
Loaded: 0.000000 seconds
Region 82 Avg IOU: -nan, Class: nan, Obj: -nan, No Obj: -nan, .5R: 0.000000, .75R: 0.000000, count: 4
Region 94 Avg IOU: -nan, Class: nan, Obj: nan, No Obj: nan, .5R: 0.000000, .75R: 0.000000, count: 1
Region 106 Avg IOU: -nan, Class: nan, Obj: -nan, No Obj: -nan, .5R: 0.000000, .75R: 0.000000, count: 1
Region 82 Avg IOU: -nan, Class: nan, Obj: -nan, No Obj: -nan, .5R: 0.000000, .75R: 0.000000, count: 2
Region 94 Avg IOU: -nan, Class: nan, Obj: nan, No Obj: nan, .5R: 0.000000, .75R: 0.000000, count: 4
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: -nan, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 82 Avg IOU: -nan, Class: nan, Obj: -nan, No Obj: -nan, .5R: 0.000000, .75R: 0.000000, count: 3
Region 94 Avg IOU: -nan, Class: nan, Obj: nan, No Obj: nan, .5R: 0.000000, .75R: 0.000000, count: 1
Region 106 Avg IOU: -nan, Class: nan, Obj: -nan, No Obj: -nan, .5R: 0.000000, .75R: 0.000000, count: 4
Region 82 Avg IOU: -nan, Class: nan, Obj: -nan, No Obj: -nan, .5R: 0.000000, .75R: 0.000000, count: 4
Region 94 Avg IOU: -nan, Class: nan, Obj: nan, No Obj: nan, .5R: 0.000000, .75R: 0.000000, count: 2
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: -nan, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 82 Avg IOU: -nan, Class: nan, Obj: -nan, No Obj: -nan, .5R: 0.000000, .75R: 0.000000, count: 3
Region 94 Avg IOU: -nan, Class: nan, Obj: nan, No Obj: nan, .5R: 0.000000, .75R:0.000000, count: 3
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: -nan, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 82 Avg IOU: -nan, Class: nan, Obj: -nan, No Obj: -nan, .5R: 0.000000, .75R: 0.000000, count: 3
Region 94 Avg IOU: -nan, Class: nan, Obj: nan, No Obj: nan, .5R: 0.000000, .75R: 0.000000, count: 3
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: -nan, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 82 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: -nan, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 94 Avg IOU: -nan, Class: nan, Obj: nan, No Obj: nan, .5R: 0.000000, .75R: 0.000000, count: 6
Region 106 Avg IOU: -nan, Class: nan, Obj: -nan, No Obj: -nan, .5R: 0.000000, .75R: 0.000000, count: 2
Region 82 Avg IOU: -nan, Class: nan, Obj: -nan, No Obj: -nan, .5R: 0.000000, .75R: 0.000000, count: 5
Region 94 Avg IOU: -nan, Class: nan, Obj: nan, No Obj: nan, .5R: 0.000000, .75R: 0.000000, count: 1
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: -nan, .5R: -nan(ind), .75R: -nan(ind), count: 0
 pallpb
on 14 Jun 2018
pallpb
on 14 Jun 2018
@AlexeyAB As you mentioned earlier in Only if nan occurs for avg loss for several dozen consecutive iterations, then training went wrong. Otherwise, the training goes well., can you please give some solutions on how to correct the training process if we are getting all nans? My training loss goes on increasing and after some steps, all values become -nan.
 patilameya825
on 20 Jun 2018
patilameya825
on 20 Jun 2018
I encounter this phenomenon on my 3 classes dataset, but after training, it goes well.
I think it is from the scale mismatch of different output layer.
 guantinglin
on 11 Jul 2018
guantinglin
on 11 Jul 2018
When no object found in the given layer it gives nan. IOU is basically Area of intersection / Area of Union.
I think that looks normal.
 pushkalkatara
on 12 Jul 2018
pushkalkatara
on 12 Jul 2018
@AlexeyAB how many images do you think I should get if I want to add a new class to the COCO dataset?
 MizbaMohammed
on 16 Jul 2018
MizbaMohammed
on 16 Jul 2018
Hello @MizbaMohammed ,
Are you already aware of the default recommendation? I guess this is not very specific for COCO, but in general:
https://github.com/AlexeyAB/darknet#how-to-improve-object-detection
desirable that your training dataset include images with objects at diffrent: scales, rotations, lightings, from different sides, on different backgrounds - you should preferably have 2000 different images for each class or more, and you should train 2000*classes iterations or more
 gustavovaliati
on 16 Jul 2018
gustavovaliati
on 16 Jul 2018
I got confused when set up the anchor boxes: how should I arrange the sequence of the clustered anchor boxes? You know, they're not distributed well as we wish...... I might get [1, 1, 2, 2, 5, 6, 30, 32, 42] instead of [1,2,3,4,5,6,7,8,9], and I hesitated to just put them evenly at 3 scales in yolov3. And experiments of myself have just proved that the arrangement of anchor boxes just matters.
And the output Region 82 and Region 94, and Region 106 is another confusion: what do they mean?
Region 82 Avg IOU: 0.790874, Class: 0.993619, Obj: 0.970194, No Obj: 0.002241, .5R: 1.000000, .75R: 0.666667, count: 3
Region 94 Avg IOU: 0.665403, Class: 0.775035, Obj: 0.567849, No Obj: 0.000524, .5R: 0.800000, .75R: 0.200000, count: 5
Region 106 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000002, .5R: -nan, .75R: -nan, count: 0
How can it know how many objects the batch has at each layer? And if it decides each object has a layer
to belong to, then would the distribution of anchor boxes be a big problem?
Could anyone help with this? Thanks a lot.
 RubyLiao
on 25 Jul 2018
RubyLiao
on 25 Jul 2018
I have successfully trained 1-object detection YOLO-2 model, but still doesn't understand- what role anchors in cfg file plays? I has changed them, but didn't see any effect.
1) What is the meaning of anchors?
2) @AlexeyAB: Alexey, what do you mean _"real sizes of objects"_?
3) If anybody has some program choosing one best weight from the trained set of weights, based on test annotated images?
4) What is the advantage of YOLO-3 over YOLO-2 ?
 andyrey
on 25 Jul 2018
andyrey
on 25 Jul 2018
Hi@AlexeyAB , yolo v3-spp sounds good, is there any tutorial on how to train it? thank you
anguoyang
on 2 Aug 2018
When I am trying to calculate the anchors k-means++ can't be used without OpenCV, because there is used cvKMeans2 implementation , this error is coming. How to resolve this??
 R1234A
on 2 Aug 2018
R1234A
on 2 Aug 2018
Hi @AlexeyAB I have some questions. One is how to set the iteration times in the cfg file. Is it the "steps"?
I want to set the weights file autosave rate fix at every 100 iterations as the weights-file is saved only once every 10 000 iterations if(iterations > 1000). Is the parameter the "burn in"?
 wentianl20
on 7 Aug 2018
wentianl20
on 7 Aug 2018
@wentianl20 You should change in file detector.c in function train_detector(...):
the block with save_weights(net, buff) should be under condition if(i%100==0).
andyrey
on 7 Aug 2018
@wentianl20 steps is for learning rate policy, not for model caching frequency
 tkcrown
on 6 Sep 2018
tkcrown
on 6 Sep 2018
@AlexeyAB Sir when i install the alexyab/darknet then after make in the directory build/darknet/x64 darknet.exe not occurs.please guide me or send the procedure.thanks
 arsal181
on 14 Oct 2018
arsal181
on 14 Oct 2018
@arsal181
on Windows if you compile by using MSVS -
build/darknet/x64/darknet.exewill occuron Linux if you compile by using make -
darknetwill occur in the current directory (near with Makefile)
AlexeyAB
on 14 Oct 2018
can i use this darknet in build/darknet/x64 directory?
On Sun, Oct 14, 2018, 4:14 PM Alexey notifications@github.com wrote:
@arsal181 https://github.com/arsal181
-
on Windows if you compile by using MSVS - build/darknet/x64
/darknet.exe will occur
-on Linux if you compile by using make - darknet will occur in the
current directory (near with Makefile)—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/pjreddie/darknet/issues/597#issuecomment-429617819,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AqFw_bV9pqzP-wJijyHOZ9pRSS8PbGCgks5ukxyEgaJpZM4TA4ER
.
arsal181
on 14 Oct 2018
@arsal181
Just compy ./darknet to the ./build/darknet/x64/darknet
AlexeyAB
on 14 Oct 2018
sir when i run this error permission denied shows.
On Sun, Oct 14, 2018, 4:45 PM Alexey notifications@github.com wrote:
@arsal181 https://github.com/arsal181
Just compy ./darknet to the ./build/darknet/x64/darknet—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/pjreddie/darknet/issues/597#issuecomment-429619685,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AqFw_TQTFP8ntZhDdj5lbD6RSZfKrZFrks5ukyPwgaJpZM4TA4ER
.
arsal181
on 14 Oct 2018
I ran this command ./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
Are these many iterations normal? I saw the posts about nan.
Loaded: 0.000025 seconds
Region 82 Avg IOU: nan, Class: nan, Obj: nan, No Obj: nan, .5R: 0.000000, .75R: 0.000000, count: 2
Region 94 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: nan, .5R: -nan, .75R: -nan, count: 0
Region 106 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: nan, .5R: -nan, .75R: -nan, count: 0
14799: -nan, -nan avg, 0.001000 rate, 0.086326 seconds, 14799 images
Loaded: 0.000039 seconds
Region 82 Avg IOU: nan, Class: nan, Obj: nan, No Obj: nan, .5R: 0.000000, .75R: 0.000000, count: 1
Region 94 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: nan, .5R: -nan, .75R: -nan, count: 0
Region 106 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: nan, .5R: -nan, .75R: -nan, count: 0
14800: -nan, -nan avg, 0.001000 rate, 0.085953 seconds, 14800 images
Saving weights to darknet/backup/yolov3-voc.backup
 niphadkarneha
on 2 Nov 2018
niphadkarneha
on 2 Nov 2018
I ran this command ./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
Are these many iterations normal? I saw the posts about nan.
Loaded: 0.000025 seconds
Region 82 Avg IOU: nan, Class: nan, Obj: nan, No Obj: nan, .5R: 0.000000, .75R: 0.000000, count: 2
Region 94 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: nan, .5R: -nan, .75R: -nan, count: 0
Region 106 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: nan, .5R: -nan, .75R: -nan, count: 0
14799: -nan, -nan avg, 0.001000 rate, 0.086326 seconds, 14799 images
Loaded: 0.000039 seconds
Region 82 Avg IOU: nan, Class: nan, Obj: nan, No Obj: nan, .5R: 0.000000, .75R: 0.000000, count: 1
Region 94 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: nan, .5R: -nan, .75R: -nan, count: 0
Region 106 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: nan, .5R: -nan, .75R: -nan, count: 0
14800: -nan, -nan avg, 0.001000 rate, 0.085953 seconds, 14800 images
Saving weights to darknet/backup/yolov3-voc.backup
That looks like bad data to me. nans pop up, but they shouldn't be your only result.
jfries289
on 2 Nov 2018
@AlexeyAB Sir I have trained custom data of 1 class with 200 images for 2500 iterations.For this, I have used yolov3.cfg file.In that I have changed
width and height=416
subdivisions=8
batch=64
classes=1
filters=18
When I tried to test with an image with the weights generated, I have seen blank screen on prediction window and showing could not load image as below.
What could be the reason?
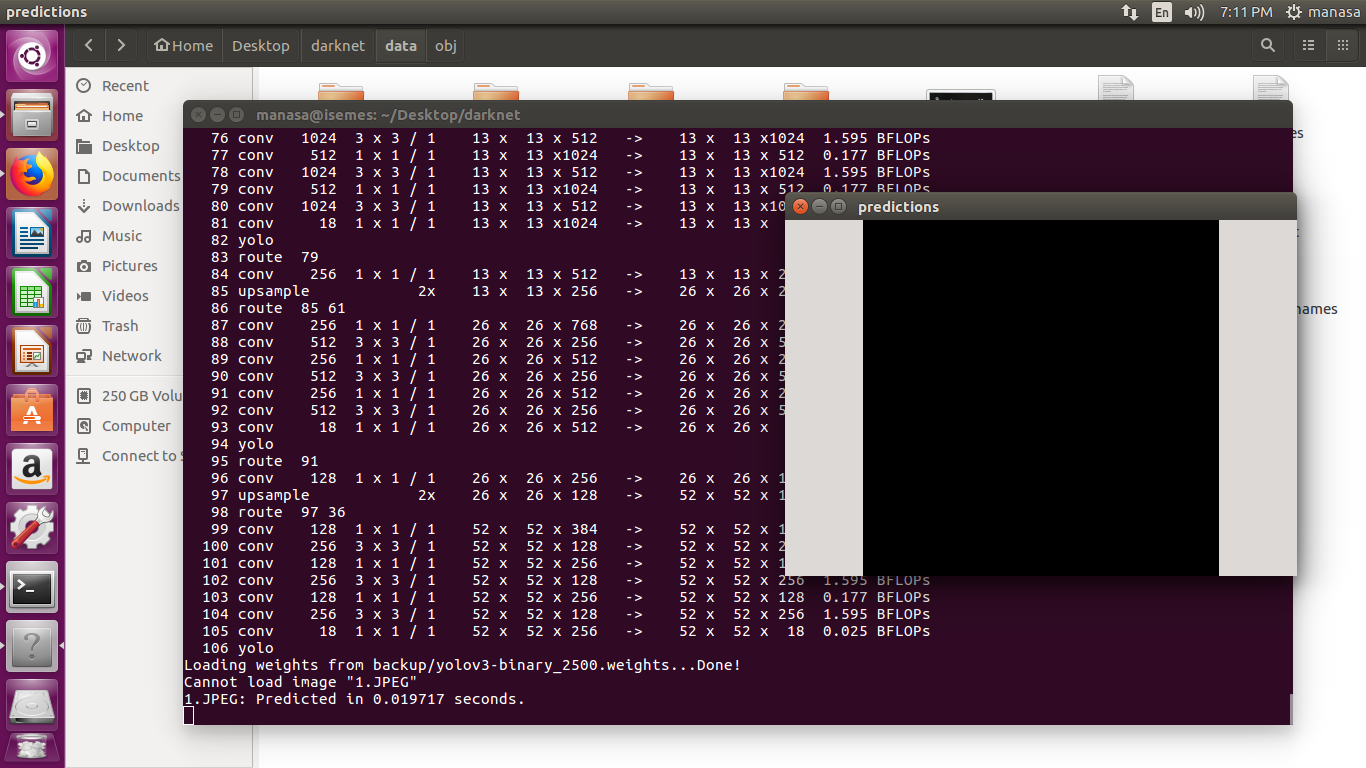
 ManasaNadimpalli
on 11 Nov 2018
ManasaNadimpalli
on 11 Nov 2018
The error message says It can't open 1.JPEG. Is this file a proper jpg? What happens if you test it with the dog and bicycle picture from the sample data?
 PeterQuinn925
on 12 Nov 2018
PeterQuinn925
on 12 Nov 2018
your image path is not correct ot check the extension of image like jpg or
png
On Mon, Nov 12, 2018 at 9:56 AM PeterQuinn925 notifications@github.com
wrote:
The error message says It can't open 1.JPEG. Is this file a proper jpg?
What happens if you test it with the dog and bicycle picture from the
sample data?—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/pjreddie/darknet/issues/597#issuecomment-437756350,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AqFw_UMMxv2KwwyiH46xqgBV6xNSMjvyks5uuP-DgaJpZM4TA4ER
.
arsal181
on 12 Nov 2018
I have placed my images (.JPEG ) and .txt files in obj folder (i.e darknet->data->obj).
And all the images are in .JPEG format only.I have my yolov3.cfg ,obj.data and obj.names in cfg (i.e darknet->cfg) folder as well as in darknet.
ManasaNadimpalli
on 12 Nov 2018
The error message says It can't open 1.JPEG. Is this file a proper jpg? What happens if you test it with the dog and bicycle picture from the sample data?
For the dog and bicycle picture,I am able to get the image but without labels.
ManasaNadimpalli
on 12 Nov 2018
Thank you..The error was in the image path.But I am now seeing only the labels but not the bounding boxes in the test image.
ManasaNadimpalli
on 12 Nov 2018
Do you known where will cause the "nan" in the source code? I can not find out where will cause "nan" in "yolo_layer.c".
 linqiaozhou
on 20 Dec 2018
linqiaozhou
on 20 Dec 2018
In the function _float *parse_fields(char *line, int n)_ in utils.c there are lines like if(p == c) field[count] = nan("");
andyrey
on 20 Dec 2018
Hi!!
I have some questions:
- I have my images (in jpg format) in the directory darknet/data/images and the labels (.txt) in teh directory darknet/data/labels
- When I try to train with my own dataset I get the following in the first iterations:
Region 94 Avg IOU: 0.327257, Class: 0.436315, Obj: 0.025532, No Obj: 0.005994, .5R: 0.000000, .75R: 0.000000, count: 4
Region 106 Avg IOU: 0.218748, Class: 0.485177, Obj: 0.011414, No Obj: 0.003186, .5R: 0.125000, .75R: 0.000000, count: 8
264: 45.015869, 26.430340 avg, 0.000005 rate, 0.082373 seconds, 264 images
Loaded: 0.000038 seconds
But after a while I get the following:
Region 94 Avg IOU: nan, Class: 0.000000, Obj: 0.000000, No Obj: 0.000000, .5R: 0.000000, .75R: 0.000000, count: 1
Region 106 Avg IOU: nan, Class: 0.000000, Obj: 0.000000, No Obj: 0.000000, .5R: 0.000000, .75R: 0.000000, count: 6
1139: -nan, nan avg, 0.001000 rate, 0.094441 seconds, 1139 images
Loaded: 0.000038 seconds
I try to put the label files in the same directory(darknet/data/images) that the images, but I have the same problem.
What could be the problem?
Regards!
 jessiffmm
on 3 Feb 2019
jessiffmm
on 3 Feb 2019
@jessiffmm
Did you calculate the anchor boxes and put them into 3 places of .cfg file?
andyrey
on 4 Feb 2019
Hi @andyrey
I haven't calculated the anchor boxes. How Can I calculate the anchor boxes?
Regards!
jessiffmm
on 4 Feb 2019
@jessiffmm
if you have build darknet, launch cmd like this:
darknet3.exe detector calc_anchors data/obj.data -num_of_clusters 9 -width 416 -height 416 -showpause
and then you'll get "anchors.txt" file with 9 pairs of digits, replace (3 places in yolo- 3) in .cfg file.
andyrey
on 4 Feb 2019
Ok @andyrey
Thanks!!
I imagine that width and height depend of the images size.
jessiffmm
on 4 Feb 2019
@jessiffmm
All images are brought to same size (416x416) or something 32-fold.
All anchors dependent on individual dataset.
andyrey
on 4 Feb 2019
Hi!
I tried to get pre-trained weights 'yolov3-tiny.conv.15' using command: 'darknet.exe partial cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15', but every time I get this error:
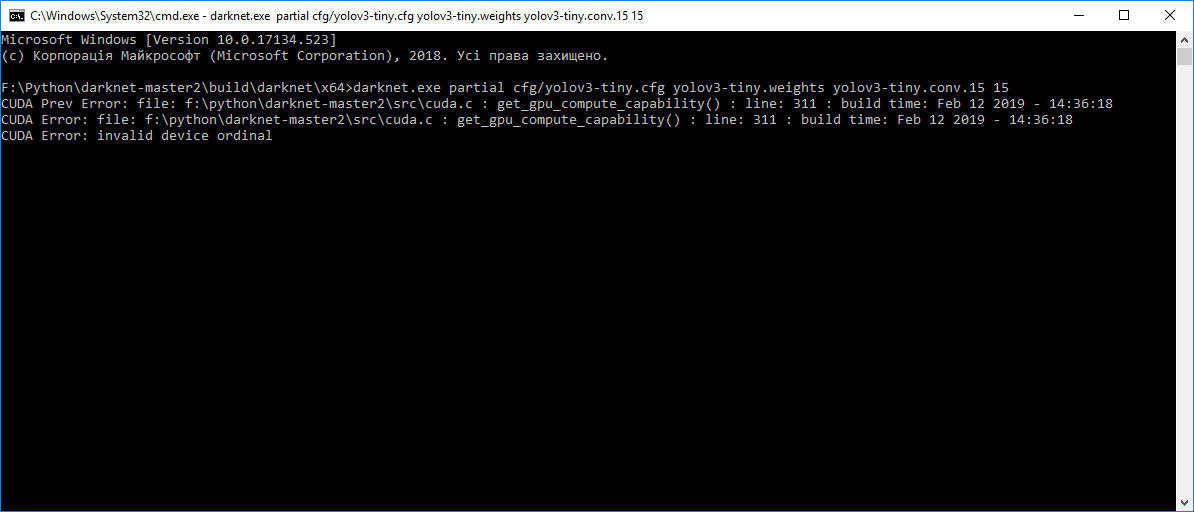
Can you help me, please.
 petrohusak
on 13 Feb 2019
petrohusak
on 13 Feb 2019
@Kertrop Try to update your code from GitHub.
AlexeyAB
on 13 Feb 2019
@Kertrop Try to update your code from GitHub.
Thank you very much, it helped.
petrohusak
on 13 Feb 2019
Sorry if it's inappropriate to ask here. I've been trying to train yolo3-tiny with my own dataset of 1 class and ~1000 positive samples. After 50 hours of training it tells:
Resizing
512
Loaded: 0.044990 seconds
Region 16 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000001, .5R: -nan, .75R: -nan, count: 0
Region 23 Avg IOU: 0.737925, Class: 0.998520, Obj: 0.991458, No Obj: 0.000621, .5R: 1.000000, .75R: 0.000000, count: 1
54261: 0.292673, 0.218497 avg, 0.001000 rate, 4.347198 seconds, 54261 images
Loaded: 0.000091 seconds
I'm running it on i5 cpu in docker on windows host :) Is it possible to tell that training will complete on that system in any near future (this week). Or I should stop that misery and run on a "normal" system?
 dubtar
on 20 Feb 2019
dubtar
on 20 Feb 2019
@dubtar
54261: 0.292673, 0.218497 avg, 0.001000 rate, 4.347198 seconds, 54261 images
Do you train with using yolov3-tiny.weights pretrained weights-file, or how did you train 54K iterations on CPU? )
There is enough low loss. So you can try to stop training, check wether it can detect anything, and if can't, then you should run it on a normal system with nVidia GPU )
AlexeyAB
on 20 Feb 2019
@AlexeyAB Thanks, man! I was following article on Medium.com, so used darknet53.conv.74.
dubtar
on 20 Feb 2019
@AlexeyAB
hi,i have some question.
What reason is this?
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 82 Avg IOU: 0.870595, Class: 0.994771, Obj: 0.700115, No Obj: 0.006700, .5R: 1.000000, .75R: 1.000000, count: 5
Region 94 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 82 Avg IOU: 0.678149, Class: 0.996602, Obj: 0.088626, No Obj: 0.002252, .5R: 1.000000, .75R: 0.500000, count: 2
Region 94 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 82 Avg IOU: 0.884214, Class: 0.999505, Obj: 0.904762, No Obj: 0.009010, .5R: 1.000000, .75R: 1.000000, count: 7
Region 94 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 82 Avg IOU: 0.784557, Class: 0.996936, Obj: 0.690478, No Obj: 0.002225, .5R: 1.000000, .75R: 0.500000, count: 2
Region 94 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 82 Avg IOU: 0.818402, Class: 0.993600, Obj: 0.891443, No Obj: 0.003130, .5R: 1.000000, .75R: 0.750000, count: 4
Region 94 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
 yxwLearn
on 25 Feb 2019
yxwLearn
on 25 Feb 2019
@AlexeyAB
Hello, I'm trying to crawl baidu food pictures in the atlas of the training, but found that iou is not high, class objective parameters, bouncing obj parameters is very big, loss has been maintained at 0.3-0.5, this is what causes? Is the picture background is too complicated or I caused by the number of each type is not the same as picture?
yxwLearn
on 25 Feb 2019
@yxwLearn Hi,
hi,i have some question.
What reason is this?Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
This is normal.
Look only at avg loss: https://github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-objects
Note: If during training you see nan values for avg (loss) field - then training goes wrong, but if nan is in some other lines - then training goes well.
and look at mAP if you train with flag -map https://github.com/AlexeyAB/darknet#when-should-i-stop-training
Hello, I'm trying to crawl baidu food pictures in the atlas of the training, but found that iou is not high, class objective parameters, bouncing obj parameters is very big, loss has been maintained at 0.3-0.5, this is what causes?
- Can you rename you cfg file to txt file and attach it?
- How many classes and images do you have?
- Show point cloud that you can get by using command
./darknet detector calc_anchors data/obj.data -num_of_clusters 9 -width 608 -height 608 -show
using this repo: https://github.com/AlexeyAB/darknet
Is the picture background is too complicated or I caused by the number of each type is not the same as picture?
What do you mean?
AlexeyAB
on 25 Feb 2019
@AlexeyAB
sorry,something went wrong when I upload my cfg file,so I paste it.
and i have 11 classes and 5853 images,but number of pictures of each classes is different, some more or less.
I run this training on Windows .
I mean my picture quality is not very good, this is the cause of loss at 0.3 to 0.5?
`[net]
Testing
batch=1
subdivisions=1
Training
batch=64
subdivisions=32
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 500200
policy=steps
steps=400000,450000
scales=.1,.1
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
Downsample
[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
Downsample
[convolutional]
batch_normalize=1
filters=128
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
Downsample
[convolutional]
batch_normalize=1
filters=256
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
Downsample
[convolutional]
batch_normalize=1
filters=512
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
Downsample
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
#
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=48
activation=linear
[yolo]
mask = 6,7,8
anchors = 2.67,3.02, 3.26,4.61, 4.44,5.91, 4.76,8.50, 5.27,3.82, 6.97,7.43, 8.24,10.17, 8.97,5.41, 10.51,8.19, 11.25,11.33
classes=11
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 61
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=48
activation=linear
[yolo]
mask = 3,4,5
anchors = 2.67,3.02, 3.26,4.61, 4.44,5.91, 4.76,8.50, 5.27,3.82, 6.97,7.43, 8.24,10.17, 8.97,5.41, 10.51,8.19, 11.25,11.33
classes=11
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 36
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=48
activation=linear
[yolo]
mask = 0,1,2
anchors = 2.67,3.02, 3.26,4.61, 4.44,5.91, 4.76,8.50, 5.27,3.82, 6.97,7.43, 8.24,10.17, 8.97,5.41, 10.51,8.19, 11.25,11.33
classes=11
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
`
yxwLearn
on 26 Feb 2019
@AlexeyAB
oh,I trained for 14300 iteration,that the console parameter is very considerable,but when testing a classes, the effect is not very well。sorry about that I can't upload picture,so I paste it。
Region 82 Avg IOU: 0.872828, Class: 0.998161, Obj: 0.791894, No Obj: 0.002921, .5R: 1.000000, .75R: 1.000000, count: 2
Region 94 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 82 Avg IOU: 0.793445, Class: 0.999805, Obj: 0.914844, No Obj: 0.002492, .5R: 1.000000, .75R: 0.500000, count: 2
Region 94 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 82 Avg IOU: 0.878821, Class: 0.999332, Obj: 0.741771, No Obj: 0.009482, .5R: 1.000000, .75R: 1.000000, count: 9
Region 94 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 82 Avg IOU: 0.864686, Class: 0.998293, Obj: 0.986454, No Obj: 0.002985, .5R: 1.000000, .75R: 1.000000, count: 2
Region 94 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 82 Avg IOU: 0.712289, Class: 0.998681, Obj: 0.890383, No Obj: 0.003450, .5R: 1.000000, .75R: 0.000000, count: 2
Region 94 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 82 Avg IOU: 0.960917, Class: 0.999933, Obj: 0.758110, No Obj: 0.004128, .5R: 1.000000, .75R: 1.000000, count: 2
Region 94 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
14548: 0.230654, 0.198709 avg loss, 0.001000 rate, 7.220494 seconds, 931072 images
Loaded: 0.000000 seconds
Region 82 Avg IOU: 0.904501, Class: 0.999886, Obj: 0.683604, No Obj: 0.003879, .5R: 1.000000, .75R: 1.000000, count: 2
Region 94 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 82 Avg IOU: 0.836755, Class: 0.999735, Obj: 0.885447, No Obj: 0.002573, .5R: 1.000000, .75R: 1.000000, count: 2
Region 94 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 82 Avg IOU: 0.915653, Class: 0.998804, Obj: 0.946341, No Obj: 0.003264, .5R: 1.000000, .75R: 1.000000, count: 2
Region 94 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 82 Avg IOU: 0.883266, Class: 0.999722, Obj: 0.985086, No Obj: 0.006194, .5R: 1.000000, .75R: 0.750000, count: 4
Region 94 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000001, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 82 Avg IOU: 0.951540, Class: 0.998787, Obj: 0.858221, No Obj: 0.003164, .5R: 1.000000, .75R: 1.000000, count: 2
Region 94 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
Region 106 Avg IOU: -nan(ind), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.000000, .5R: -nan(ind), .75R: -nan(ind), count: 0
yxwLearn
on 26 Feb 2019
@yxwLearn
Your objects are very small. So train with width=832 height=832 in cfg-file.
AlexeyAB
on 26 Feb 2019
@AlexeyAB
Thank you!I will try it,and I calculate anchors by gen_anchors.py,This is necessary?
yxwLearn
on 26 Feb 2019
@yxwLearn No. Use default anchors.
AlexeyAB
on 26 Feb 2019
@AlexeyAB
thank you very much!
yxwLearn
on 26 Feb 2019
@AlexeyAB
what‘s wrong?
1>nvcc fatal : Unsupported gpu architecture 'compute_75'
1>nvcc fatal : Unsupported gpu architecture 'compute_75
yxwLearn
on 26 Feb 2019
@yxwLearn
- Either install CUDA 10.0
- or change 75 to 60
open darknet.sln -> (right click on project) -> properties -> CUDA C/C++ -> Device and change here;compute_75,sm_75to;compute_60,sm_60
AlexeyAB
on 26 Feb 2019
@AlexeyAB
sorry,I'm too careless。
yxwLearn
on 26 Feb 2019
@AlexeyAB
My computer video card is 1070.
but when i change the cfg-file width=832 height=832 and i also set subvisions=64,it always out of memory,I should set the random = 0?
yxwLearn
on 27 Feb 2019
@jfries289
sorry?
when it always out of memory,Should not increase the value of subvisions?
yxwLearn
on 27 Feb 2019
@AlexeyAB
I train with cfg-file width=832 height=832 and sunvisions=64,random=1,but the training very slow.
My computer video card is 1070.
yxwLearn
on 27 Feb 2019
Greater subdivisions, the slower training. Less subdivisions= faster training, but may be memory exceeding. Try to find trade-off.
andyrey
on 27 Feb 2019
@yxwLearn
Use width=416 height=416 random=1 batch=64 subdivisions=64
or
width=832 height=832 random=0 batch=64 subdivisions=64
AlexeyAB
on 27 Feb 2019
Can you help me, please
'darknet.exe' n’est pas reconnu en tant que commande interne
ou externe, un programme exécutable ou un fichier de commandes.
 sarratouil
on 28 Feb 2019
sarratouil
on 28 Feb 2019
Hi @sarratouil
Are you using ubuntu or windows?
If you are using ubuntu you have to execute with ./darknet
jessiffmm
on 28 Feb 2019
@AlexeyAB
Should I modify the parameter of the file makefile?
yxwLearn
on 1 Mar 2019
@AlexeyAB
hi,excuse me
The mAP% in the process of training is very high, but the obj has a low value?
why?
yxwLearn
on 1 Mar 2019
@AlexeyAB
And the classes is 1,the subvisions is 32,random=1, the value of the loss is 0.4-0.5, the iteration is 1300 steps
yxwLearn
on 1 Mar 2019
@AlexeyAB
Hi, I had been training 1 class with yolov3-tiny with initially 50-60 images, it is a small object. Even after 20,000 iterations it is still only giving me a average loss of 0.5-0.7 and it stopped decreasing. Is there a way to drop the detection rate? I need about 0.06 average loss. I am training with Mac with no gpu because that's the best device I could find.
Would height and width matter? What do you suggest?
My sample label text data:
0 0.246094 0.644444 0.088021 0.020370 and 0 0.819792 0.748611 0.241667 0.063889
My image dimension is 1920x1080 with resolution 72dpiDoes anchor needs to be changed?
- Is the learning rate of 0.001 okay?
Thank you so much for the help.
My tiny-yolov3
[net]
Testing
batch=1
subdivisions=1
Training
batch=64
subdivisions=2
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 500200
policy=steps
steps=400000,450000
scales=.1,.1
[convolutional]
batch_normalize=1
filters=16
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=1
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
#
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=1
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 8
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=1
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
 elainewu1
on 3 Mar 2019
elainewu1
on 3 Mar 2019
@elainewu1
Try to train with width=832 height=832 batch=64 subdivisions=8 and with default anchors
Even after 20,000 iterations it is still only giving me a average loss of 0.5-0.7 and it stopped decreasing. Is there a way to drop the detection rate? I need about 0.06 average loss. I am training with Mac with no gpu because that's the best device I could find.
It can be a normal avg loss, what mAP can you get?: https://github.com/AlexeyAB/darknet#when-should-i-stop-training
When you see that average loss 0.xxxxxx avg no longer decreases at many iterations then you should stop training. The final avgerage loss can be from 0.05 (for a small model and easy dataset) to 3.0 (for a big model and a difficult dataset).
AlexeyAB
on 3 Mar 2019
@jessiffmm i use a windows thank you it works but i have another problem
sarratouil
on 3 Mar 2019
@AlexeyAB
Hello AlexeyAB, I tried the suggestion of changing the height and width and the detection time is improved only by a second after 20,000 iterations, still needs 9 seconds to detect. What else could I do? The training set is about 60 images for 1 class and 60% of the images used for test and 40% for train.
elainewu1
on 6 Mar 2019
While training (with gpu & CUDA) i am getting following error ..
can anyone please help me ?
CUDA status Error: file: ....srccuda.c : cuda_set_device() : line: 22 : build time: Mar 10 2019 - 15:38:38
CUDA Error: unknown error
Windows 10
Cuda 10.0
CUDN 7.4
 dhilip1
on 10 Mar 2019
dhilip1
on 10 Mar 2019
@AlexeyAB you have any idea which weight of yolo that modified GoogLeNet architecture
an fast version of YOLO,
based on a neural network with fewer convolutional layers (9
instead of 24) and fewer filters in those layers.
sarratouil
on 15 Mar 2019
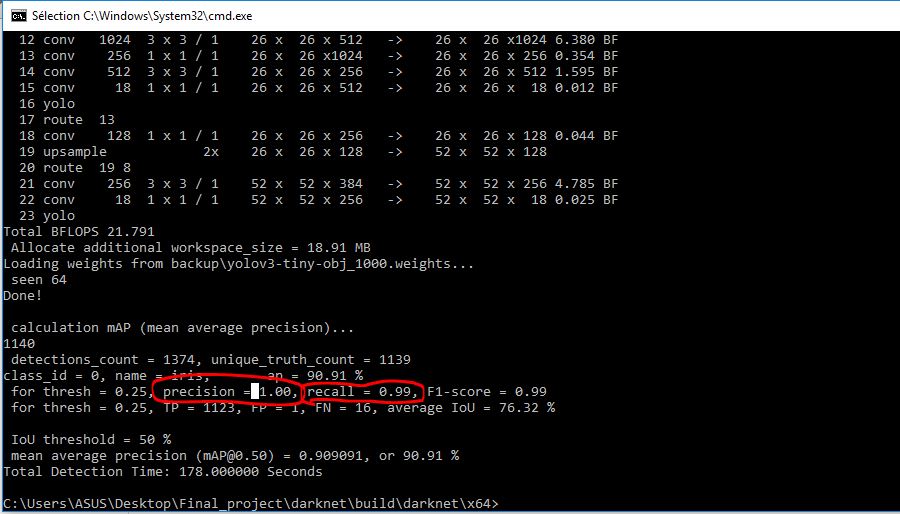
@AlexeyAB I train yolov3 to my own object such as 'iris' with 2638 images: 1500 for training and the other for the test
But I have a problem in the result
sarratouil
on 16 Mar 2019
@sarratouil There is no problem.
AlexeyAB
on 16 Mar 2019
@AlexeyAB precision=1 it's correct?
sarratouil
on 16 Mar 2019
my file config
[net]
Testing
batch=64
subdivisions=64
Training
batch=64
subdivisions=64
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 1000
policy=steps
steps=400000,450000
scales=.1,.1
[convolutional]
batch_normalize=1
filters=16
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=1
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
#
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=1
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 8
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=1
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
sarratouil
on 16 Mar 2019
@sarratouil how did u run darknet on windows ?
@AlexeyAB should i use different anchors for my own dataset , or i keep the default anchors ?
 cyrineee
on 16 Mar 2019
cyrineee
on 16 Mar 2019
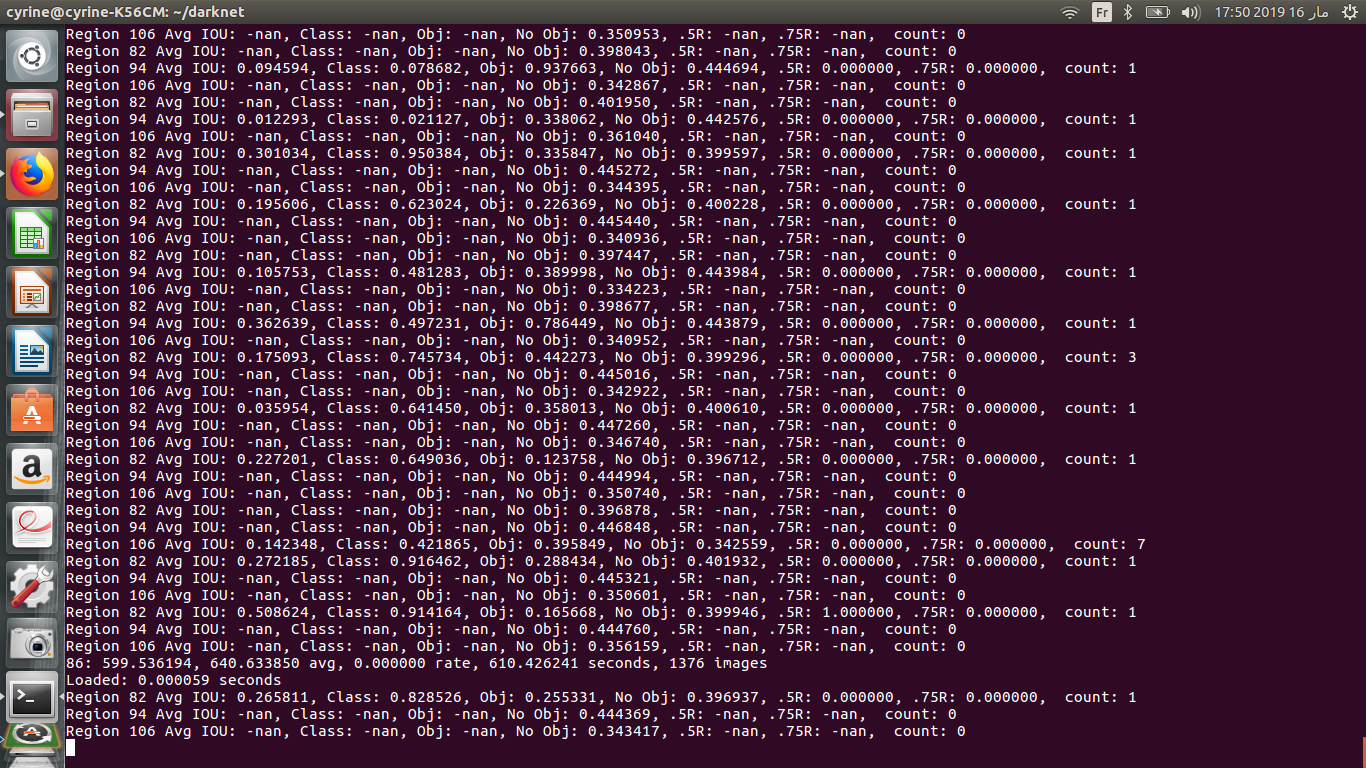
it my training going well ? i have too much NaN
cyrineee
on 16 Mar 2019
@cyrineee you can run it with execute darknet.sln of draknet folder on visual studio
this link help you : https://github.com/AlexeyAB/darknet
sarratouil
on 18 Mar 2019
@AlexeyAB Sir, I trained and detected the Thai license plates along with digits using yolov3. I can see the detected output in the terminal when I give test image as shown in the image.
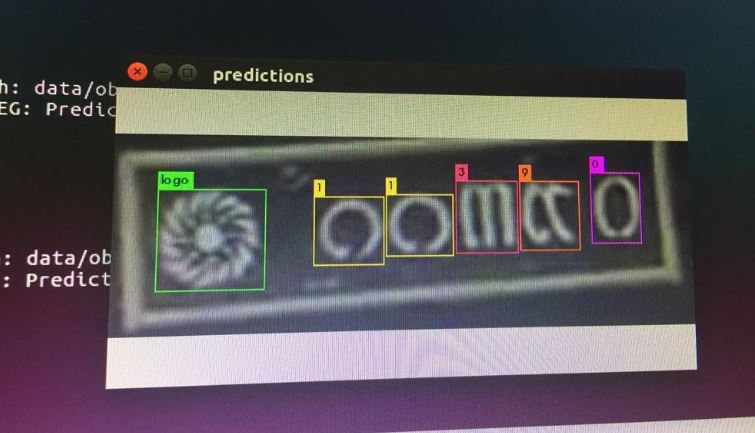
Now, I want to print the detected characters on the terminal as
license plate: 11390
So to get this, I need help regarding where can I change the code and what to add to extract the detected digits and print them.
Thanks in advance
Manasa.
ManasaNadimpalli
on 23 Mar 2019
Dear friends, let us ask here questions specific to the topic- YOLO-3. Please, do not ask here questions referred to common items of programming on C/C++, like console output or how to use printer, just take one of many books on programming or use extensive Internet resources .
andyrey
on 23 Mar 2019
@ManasaNadimpalli Hi,
If you use this repository https://github.com/AlexeyAB/darknet and if you use Detection on Image (not on Video) then as you see the detection are already sorted from Left to Right: https://github.com/AlexeyAB/darknet/blob/9815012a01c13f70806381e0c5d556599117c76b/src/image.c#L333
So in the console output detections already sorted from left to right.
If you want to use Darknet as SO/DLL library by using your own C/C++/Python application, then you should sort detection by yourself in your code.
AlexeyAB
on 23 Mar 2019
@ManasaNadimpalli Hi,
If you use this repository https://github.com/AlexeyAB/darknet and if you use Detection on Image (not on Video) then as you see the detection are already sorted from Left to Right: https://github.com/AlexeyAB/darknet/blob/9815012a01c13f70806381e0c5d556599117c76b/src/image.c#L333
So in the console output detections already sorted from left to right.
If you want to use Darknet as SO/DLL library by using your own C/C++/Python application, then you should sort detection by yourself in your code.
Thank you Sir.I am able to do it on image. Now I need to do it on video. Is there sort function for video to get the detection from left to right? If not,is it possible to add it to detect in video?
Regards
Manasa.
ManasaNadimpalli
on 26 Mar 2019
::Resolved this Error ::
Solution :: Need to install the nvidia drivers !!!
When i try to train the custom images in windows getting following error? Can any one please help ?
./darknet detector train data/obj.data yolo-obj.cfg darknet19_448.conv.23 CUDA status Error: file: ....srccuda.c : cuda_set_device() : line: 22 : build time: Mar 10 2019 - 21:51:45 CUDA Error: unknown error
dhilip1
on 31 Mar 2019
@AlexeyAB and others who knows...
I got 2 strongly overlapped objects of different classes (one object's bounding box (BB) is inside another object's BB), it should not be in my case. Changing nms doesn't change result. I understand this as:
nms influence only on objects of same class, but not on the objects of different classes. Am I right or wrong?
andyrey
on 31 Mar 2019
@andyrey
Changing nms doesn't change result. I understand this as:
nms influence only on objects of same class, but not on the objects of different classes.
Yes.
AlexeyAB
on 31 Mar 2019
Hello @AlexeyAB , Can I print the detected output on one side of the video frame while I am running on video?
Thanks in advance
ManasaNadimpalli
on 7 Apr 2019
@ndg123
Hi!, I have a question what of we have different input size for the network ?
what value should we take for height and width and anchors box ?!
 wahid18benz
on 9 Apr 2019
wahid18benz
on 9 Apr 2019
@sonalambwani Just wait about 1000 iterations, and
nanwill disappear: AlexeyAB#504 (comment)1. You can re-calculate anchors, but it is not necessary. You can calculate anchors for Yolo v3 using this fork: https://github.com/AlexeyAB/darknet and this command if in your cfg-file `width=416` and `height=416`: `darknet.exe detector calc_anchors data/voc.data -num_of_clusters 9 -width 416 -heigh 416`This anchors you can use in your cfg-file (without multiplication by 32)
1. You can use the same labels as for Yolo v2
voc.data is not in data/
 BogoK
on 15 Apr 2019
BogoK
on 15 Apr 2019
@AlexeyAB
you have any idea how i convert the model .h5 to .weight model darknet
sarratouil
on 15 Apr 2019
@AlexeyAB I train yolov3 to my own object such as 'iris' with 2638 images: 1500 for training and the other for the test
But I have a problem in the result
hi,
Im sorry im very new to yolo. Can i know how calculate mAP performance and get this kind of output using the trained weight file.
thank you
 sumitra20
on 19 Jun 2019
sumitra20
on 19 Jun 2019
@sumitra20
Use this repository to calculate mAP: https://github.com/AlexeyAB/darknet
How to calculate mAP on Darknet: https://github.com/AlexeyAB/darknet#when-should-i-stop-training
Read about mAP: https://medium.com/@jonathan_hui/map-mean-average-precision-for-object-detection-45c121a31173
AlexeyAB
on 19 Jun 2019
@AlexeyAB As I am new to YOLO I do not know how the training works here. Can the YOLO training be stopped in the middle and continue from the same step where it got stopped, just like SSD and Faster R-CNN using Tensorflow-api?
 dinesh1218
on 19 Jun 2019
dinesh1218
on 19 Jun 2019
@dinesh1218 -yes, you can stop and re-launch training process later, and YOLO takes the last saved weight for resuming training. I have done it many times.
andyrey
on 19 Jun 2019
@andyrey Thank you so much. will check it.
dinesh1218
on 19 Jun 2019
@sumitra20
Use this repository to calculate mAP: https://github.com/AlexeyAB/darknet
How to calculate mAP on Darknet: https://github.com/AlexeyAB/darknet#when-should-i-stop-training
Read about mAP: https://medium.com/@jonathan_hui/map-mean-average-precision-for-object-detection-45c121a31173
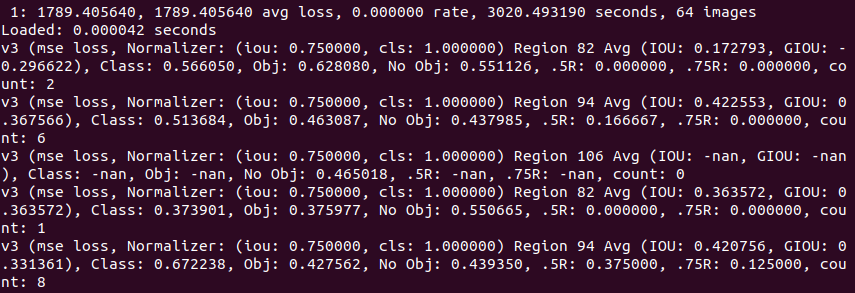
@AlexeyAB Thank you so much for the link, its very helpful. I have just started training the yolov3 model using my own data-set and my average loss from the beginning of the training until now (43rd training iteration) is 0.0000. Could that indicate any error?
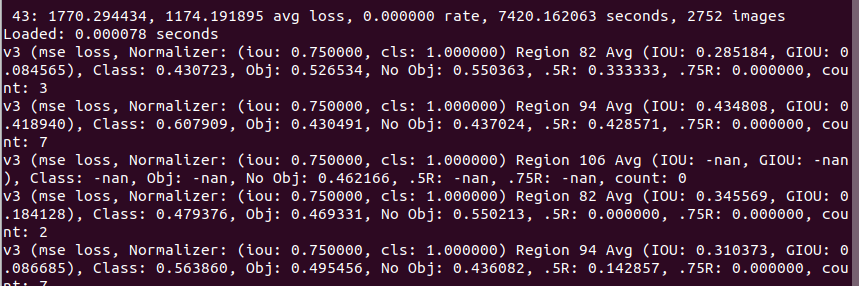
sumitra20
on 20 Jun 2019
@andyrey Can you please guide me to restart YOLO training from saved weights. When I tried to use the below command it starts from beginning.
./darknet detector train data/obj.data yolo-obj.cfg darknet53.conv.74
I have the following weights saved inside my backup folder - yolo-obj_1000.weights and yolo-obj_last.weights. Should I need to use these weights to restart my training, if so how can I do it?
dinesh1218
on 20 Jun 2019
Yes, instead _darknet53.conv.74_ you should set your last weight.
andyrey
on 20 Jun 2019
@sumitra20
Use this repository to calculate mAP: https://github.com/AlexeyAB/darknet
How to calculate mAP on Darknet: https://github.com/AlexeyAB/darknet#when-should-i-stop-training
Read about mAP: https://medium.com/@jonathan_hui/map-mean-average-precision-for-object-detection-45c121a31173
@AlexeyAB
When I use the repository you shared to calculate mAP, I find "TP + FP" is not equal to "detections_count". It confuse me a lot, and I wonder if that is wrong.
Looking forward to you reply, thanks!
 CThuw
on 21 Sep 2019
CThuw
on 21 Sep 2019
I have the same issue, should I wait or something is going wrong?

 hanouel
on 3 Oct 2019
hanouel
on 3 Oct 2019
@AlexeyAB @pjreddie @CThuw is there any way by which i can access the loss and average loss value during training so that the training gets automatically stops if the loss value comes under certain range?
 hghimanshu
on 11 Oct 2019
hghimanshu
on 11 Oct 2019
@hghimanshu Hi, I don't have a programmatical answer but here is an idea :
Darknet saves weights as it goes so you have .weight files available even though the learning isn't done.
You can check your log file in real time with tail -f log and when you are satisfied with your loss and loss average you can simply use the latest weight file obtained.
 ArnoBen
on 12 Nov 2019
ArnoBen
on 12 Nov 2019
@AlexeyAB or anyone else Could you please suggest me more about training?
Supposed that, I have 3 classes of objects [cat, dog, fish] and each class contains 450 of labelled images for training.
After finished the training with using pretrained weights-file (such as yolov3-tiny.conv.15) and, later that, I want to expand the objects to 6 classes [cat, dog, fish, bird, horse, bear] what should I do?
A. Using the previous trained weights-file (from 3 classes) and training with the image dataset of only additional 3 classes [bird, horse, bear]. The file obj.names are contained 6 classes as [cat, dog, fish, bird, horse, bear].
B. Using the previous trained weights-file (from 3 classes) and training with the image dataset contains all of 6 classes [cat, dog, fish, bird, horse, bear]. The images dataset is mixed between [cat, dog, fish] images from the previous training and the new images for [bird, horse, bear]. The file obj.names are contained 6 classes as [cat, dog, fish, bird, horse, bear].
C. Discard the previous train weights-file and start training from the beginning by using the yolov3-tiny.conv.15 weights-file.
I also have no idea about how to edit the cfg file for those methods. Could you please suggest me?
 BankPC
on 8 Dec 2019
BankPC
on 8 Dec 2019
2BankPC. My experience:You cannot reuse weights, trained on 3 classes, for expanding to 6 classes.
You will get failure in training process if you try to use it.
Your "C" is most adequate variant. You only can reuse your previous dataset, but even here you have to renew your 3-class annotations to 6-classes.
andyrey
on 8 Dec 2019
Hello when i use this command i
./darknet detector train data/obj.data yolo-obj.cfg darknet53.conv.74
i get Couldn't open file: data/obj.data
Please help
 Lumi1717
on 21 Mar 2020
Lumi1717
on 21 Mar 2020
go to cfg directory and copy the coco.data and rename the file with
obj.data and paste the data directory
On Sat, Mar 21, 2020 at 10:36 PM Lumi1717 notifications@github.com wrote:
Hello when i use this command i
./darknet detector train data/obj.data yolo-obj.cfg darknet53.conv.74
i get Couldn't open file: data/obj.data
Please help—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/pjreddie/darknet/issues/597#issuecomment-602076975,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AKQXB7P6QPJ2SXHXWR5SLKLRIT3H7ANCNFSM4EYDQEIQ
.
arsal181
on 21 Mar 2020
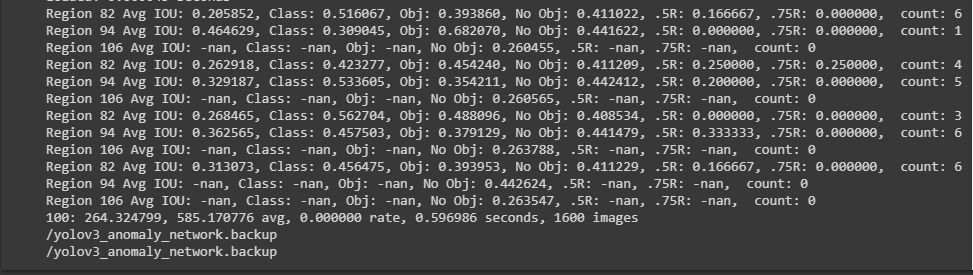
I'm trying to train yolov3 model using darknet53 on my own custom dataset. Can anyone help me with issue I have.
My training gets stopped at 100th iteration even when the max batches in yolov3.cfg is 12000 and also the backup file is not getting saved at the location given in input.cfg file. I'm attaching snippets of input.cfg and yolov3.cfg for your clear understanding. Thank you in advance.
yolov3.cfg
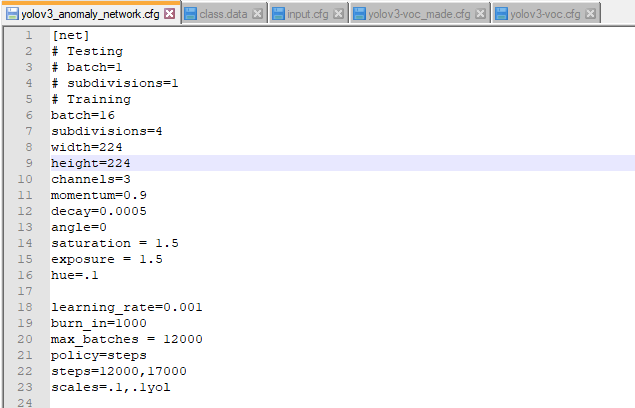
input.cfg

 sujan1997
on 28 Mar 2020
sujan1997
on 28 Mar 2020
@AlexeyAB @pjreddie
Dear sir!
I use this command for the display of graph:
./darknet detector train data/obj.data yolo-obj.cfg darknet53.conv.74 -map
but it didn't show any graph .....
Please guide me through
 Raoabdulrehman771
on 1 Apr 2020
Raoabdulrehman771
on 1 Apr 2020
you should use last saved weight rather than darknet53 weights
On Wed, Apr 1, 2020 at 11:52 AM Rao Abdul Rehman Khan <
[email protected]> wrote:
@AlexeyAB https://github.com/AlexeyAB
Dear sir!
I use this command for the display of graph:
./darknet detector train data/obj.data yolo-obj.cfg darknet53.conv.74 -map
but it didn't show any graph .....
Please guide me through—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/pjreddie/darknet/issues/597#issuecomment-607068914,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AKQXB7KLEKOE6ZP4JFHWHK3RKLQETANCNFSM4EYDQEIQ
.
arsal181
on 1 Apr 2020
@arsal181
Thank you for your reply...
i want to ask you, can i see the loss graph at runtime..
Raoabdulrehman771
on 2 Apr 2020
@Raoabdulrehman771
In my case, showing the plot of loss function, doesn't depend on flag _-map_ in command line. It is inside program and built in. Can you see console output to confirm the process of training has been launched at all? If yes, you should find out in main() code the proper place referred to plotting and rebuild the program.
andyrey
on 2 Apr 2020
@andyrey
can you specify a file name?
Raoabdulrehman771
on 3 Apr 2020
@Raoabdulrehman771
in file detector.c
check running these lines in function
_void run_detector(int argc, char **argv)_
from line 1377
_else if(0==strcmp(argv[2], "train")) train_detector(datacfg, cfg, weights, gpus, ngpus, clear, dont_show, calc_map);
else if(0==strcmp(argv[2], "valid")) validate_detector(datacfg, cfg, weights, outfile);
else if(0==strcmp(argv[2], "recall")) validate_detector_recall(datacfg, cfg, weights);
else if(0==strcmp(argv[2], "map")) validate_detector_map(datacfg, cfg, weights, thresh, iou_thresh, NULL);_
andyrey
on 3 Apr 2020
Hi,@andyrey!
My situation:
I need training to identify 7 objects. After the first training, I identified 3 objects, the second time I took the weight that had been successfully trained before to train 3 more objects. This time I still succeed. The third time, I took the weight file that was successfully trained before (the second time) to continue training, the error happens as shown in the picture?
I have studied for a long time but still can not fix.
Hope you can help me!
Can you ask me with yolov3 how many subjects can I train?
In case, I want to train more objects on the file weight before I have to do?
Currently, I am using google colab for training because I am not eligible to buy a good computer to train data.
 ThuanK42
on 15 Apr 2020
ThuanK42
on 15 Apr 2020
@ThuanK42
Hello, Thuan, I don't understand your first fraze: _"I need training to identify 7 objects"_. Did you mean training to detect all objects of 7 different classes? Different images can contain various number of objects, but we can detect and distinct only those belonging to trained classes.
If you firstly train the model for 7 classes, then, after adding to your dataset new labeled samples, you can prolong training and you can use weight from the first training, but in this case you can use the same cfg file, same number of classes (7). Of course, on test you can detect any number of objects( but some limit exists) in the picture, each object belongs to one of 7 trained classes.
andyrey
on 15 Apr 2020
First, thank you for your feedback.
I want to identify with my own data set, I want to identify computer mice, motorbikes, buses, airplanes, laptops, phones, TVs. During the first 2 training sessions, I identified : computer mouse, motorbike, bus, airplane, laptop, phone. But at the last training session when I continued to get the weight file that had been successfully trained before, there was an error below
error -nan
help you , pls
ThuanK42
on 15 Apr 2020
@ThuanK42
Firstly you should check up, why you can't detect TV-set. Try to test one of the training images from 1st dataset,where TV-set is, with the best weight from the 1st train. Does it detected?
If you get _-nan_ in further training, do you get the process of training broken? If yes, check up your newer added dataset. Usually subprogram _anchors finding_ reports some problem samples.
If not, go on training.
And, if you prolong training, I recommend you to train over all summary dataset, not only newly added.
andyrey
on 15 Apr 2020
Hello, how can i get the mAP form my weights after training , and did yollov3 use a focal loss function ?
 amalchaaari
on 15 Apr 2020
amalchaaari
on 15 Apr 2020
darknet.exe detector map data/obj.data yolo-obj.cfg
backupyolo-obj_7000.weights
I think YOLOv3 does not use focal loss because it has some problems
On Thu, Apr 16, 2020 at 2:03 AM Amal Chaari notifications@github.com
wrote:
Hello, how can i get the mAP form my weights after training , and did
yellov3 user a loss focal loss function ?—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/pjreddie/darknet/issues/597#issuecomment-614278689,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AKQXB7OCMROSWP5ACO5RUKLRMYOKDANCNFSM4EYDQEIQ
.
arsal181
on 16 Apr 2020
thank you, did you know witch loss function Yolov3 use ?
amalchaaari
on 16 Apr 2020
@andyrey thank you
ThuanK42
on 17 Apr 2020
First, thank you for your feedback.
I want to identify with my own data set, I want to identify computer mice, motorbikes, buses, airplanes, laptops, phones, TVs. During the first 2 training sessions, I identified : computer mouse, motorbike, bus, airplane, laptop, phone. But at the last training session when I continued to get the weight file that had been successfully trained before, there was an error below
error -nan
help you , pls
You should decrease your learning rate more.
I encountered the same issue when training with learning_rate = 0.001 in my ~800 sample. After I changed it to 0.00005, it converged.
Hope it could help.
 tailtq
on 14 Jun 2020
tailtq
on 14 Jun 2020
Hello,
Does anybody know how Darknet repository calculates the best.weights file?
Which criteria is used?
Thank you very much in advance!
Best regards.
 AntonioNuAc
on 29 Jun 2020
AntonioNuAc
on 29 Jun 2020
I am getting the iteration number as negative during training in the chart.png. The maximum batches are kept as 1000 in the cfg file with 64 images in each batch.
Even the weights file is getting saved as yolov3-tiny_201326000.weights where the number "201326000" stands for the iteration number.
Thank you.
Please help.
 vaibhavi-003
on 19 Aug 2020
vaibhavi-003
on 19 Aug 2020
I am getting the iteration number as negative during training in the chart.png. The maximum batches are kept as 1000 in the cfg file with 64 images in each batch.
Even the weights file is getting saved as yolov3-tiny_201326000.weights where the number "201326000" stands for the iteration number.
Thank you.
Please help.
Sorted it out. The problem was because of using pretrained weights. Once I started the training from start with no weights passed, it got resolved.
vaibhavi-003
on 19 Aug 2020
Does anyone know why I get this error? Saving weights to backup/yolov3_custom_train_last.weights
Couldn't open file: backup/yolov3_custom_train_last.weights. Do I have to manually create a backup folder or why cant it open it? I tried running it with the sudo command btw
 patrikszepesi
on 20 Aug 2020
patrikszepesi
on 20 Aug 2020
Does anyone know why I get this error? Saving weights to backup/yolov3_custom_train_last.weights
Couldn't open file: backup/yolov3_custom_train_last.weights. Do I have to manually create a backup folder or why cant it open it? I tried running it with the sudo command btw
@patrikszepesi
You need to ensure you create a folder "backup", script wont do it for you.
You need to have the following data in the file "obj.data".
classes = 2
train = data/train.txt
valid = data/test.txt
names = data/obj.names
backup = backup/
All the weight files will be saved in this folder.
 deeplearner93
on 20 Aug 2020
deeplearner93
on 20 Aug 2020
I am using Mac, and despite using a Mac my backup folder is not in the root directory of darknet, but in build/darkent/x64/ just like how windows would save it. I had backup=backup in my obj.data. Do you recommend me rewriting the path in my obj.data folder to build/darkent/x64/. or should I manually create a backup folder in the root directory?
patrikszepesi
on 20 Aug 2020
Having a problem using my custom dataset. The chart pops out but it's "not responding". Also, I enabled GPU=1 but it's using CPU based from the attachment I've sent. I'm using batch=64 and subdivisions=32. Anyone can help?
 shawntyshawny
on 7 Sep 2020
shawntyshawny
on 7 Sep 2020
@shawntyshawny
Having a problem using my custom dataset. The chart pops out but it's "not responding". Also, I enabled GPU=1 but it's using CPU based from the attachment I've sent. I'm using batch=64 and subdivisions=32. Anyone can help?
Are you sure you downloaded the proper CUDA version ?
ArnoBen
on 7 Sep 2020
@shawntyshawny
Having a problem using my custom dataset. The chart pops out but it's "not responding". Also, I enabled GPU=1 but it's using CPU based from the attachment I've sent. I'm using batch=64 and subdivisions=32. Anyone can help?
Are you sure you downloaded the proper CUDA version ?
Hello sir! I already found the solution and yep it's the CUDA version. I downloaded CUDA 10.1 instead of 10.0 and everything worked. Also, the reason why the chart is not responding is because WITH_CUDA is not checked in the OpenCV CMake. ENABLE_CUDA & ENABLE_CUDNN must be checked as well in the darknet CMake. Now I can properly train my custom dataset. Thanks for the response!
shawntyshawny
on 8 Sep 2020
I am Trying
./detector train data/obj.data yolo-obj.cfg yolov4.conv.137 -map
there should be a chart here
 eltonfernando
on 15 Sep 2020
eltonfernando
on 15 Sep 2020
https://github.com/AlexeyAB/darknet
if you want to generate graph, please use this repository
On Tue, Sep 15, 2020 at 4:50 AM Elton fernandes dos santos <
[email protected]> wrote:
I am Trying
./detector train data/obj.data yolo-obj.cfg yolov4.conv.137 -mapthere should be a chart here
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/pjreddie/darknet/issues/597#issuecomment-692377466,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AN54NRGSWRONTN2KIVZI63TSF2T3TANCNFSM4EYDQEIQ
.
Raoabdulrehman771
on 16 Sep 2020
Hi everyone, please i need help. I am running yolov3 for object detection and i have this error:
PS C:darknet> darknet.exe detector train data/obj.data cfg/yolov3-custom.cfg darknet53.conv.74
darknet.exe : The term 'darknet.exe' is not recognized as the name of a cmdlet, function, script file,
or operable program. Check the spelling of the name, or if a path was included, verify that the path is
correct and try again.
At line:1 char:1
- darknet.exe detector train data/obj.data cfg/yolov3-custom.cfg darkne ...
~~~
- CategoryInfo : ObjectNotFound: (darknet.exe:String) [], CommandNotFoundException
- FullyQualifiedErrorId : CommandNotFoundException
 pakson20
on 15 Oct 2020
pakson20
on 15 Oct 2020
it looks like he's looking for a global executable and not inside the folder you're in. anyhow check if you have a darknet.exe and try to execute with click.
eltonfernando
on 15 Oct 2020
use ./darknet rather than darknet.exe
On Thu, Oct 15, 2020 at 6:18 PM Elton fernandes dos santos <
[email protected]> wrote:
it looks like he's looking for a global executable and not inside the
folder you're in. anyhow check if you have a darknet.exe and try to execute
with click.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/pjreddie/darknet/issues/597#issuecomment-709318623,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AKQXB7M2FMXH2FMTX7T46D3SK3ZDLANCNFSM4EYDQEIQ
.
arsal181
on 15 Oct 2020
@arsal181
Thanks for the reply. I did it with ./darknet but got the same error.
pakson20
on 15 Oct 2020
@eltonfernando
Thanks for the reply. But i don't have darknet.exe. My main directory is darknet.
pakson20
on 15 Oct 2020
Well, this is a problem, you need darknet.exe. Need to compile for that
eltonfernando
on 16 Oct 2020
@eltonfernando
Thanks again for your reply.
But the problem is that when I build darknet in VS, it is successful but in the x64 folder it appear darknet instead of darknet.exe.
I have attached two pictures showing what i explain.
pakson20
on 16 Oct 2020
Sorry, I don't work with the OS windows. But what you have looks like an executable. you're trying to run from the darkent folder, but yours is darkent/x64
open a cmd inside that x64 folder and try ./darknet
you should receive a return -> usage: ./darknet
eltonfernando
on 16 Oct 2020
Seems something like folder properties unchecked "show file extension"..
andyrey
on 16 Oct 2020
@andyrey
Thanks for your reply. However, what do you mean?
i have set up everything to run a yolov3 detection on windows10 with no GPU.
after running the following code in cmd
C:darknetbuilddarknetx64>darknet_no_gpu.exe detector train data/obj.data cfg/yolov3-custom darknet53.conv.74, i got the following error
GPU isn't used
Used AVX
Used FMA & AVX2
opencv version: 4.2.0
Couldn't open file: data/obj.data
Please any help will be very helpful.
Thanks in advance
pakson20
on 18 Oct 2020
@eltonfernando
I did what you mentioned above but still get below error
GPU isn't used
Used AVX
Used FMA & AVX2
opencv version: 4.2.0
Couldn't open file: data/obj.data
Thanks anyway for your reply and time.
pakson20
on 18 Oct 2020
@pakson20 this happens when the path is wrong or the file does not exist in data/obj.data
I didn't understand why you want to run without GPU
eltonfernando
on 18 Oct 2020
@eltonfernando
The reason is that i am new on yolo and I just want it to run without error.
My PC does not have a GPU for the moment.
Thank you very much for your reply.
pakson20
on 18 Oct 2020
@pakson20 : you should check up if you have provided obj.data file in subfolder "data". I don't remember exactly, it contains list of classes names.
andyrey
on 18 Oct 2020
@andyrey
@eltonfernando
Thanks a lot for your help. it finally works after i put data/obj.data , cfg/yolov3-custom and darknet53.conv.74 in the subfolder "data".
Thanks once more.
best regards
pakson20
on 19 Oct 2020
please help
PS C:darknet> ./darkent.exe detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
./darkent.exe : The term './darkent.exe' is not recognized as the name of a cmdlet, function, script file, or operable
program. Check the spelling of the name, or if a path was included, verify that the path is correct and try again.
At line:1 char:1
- ./darkent.exe detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
~~~~~
- CategoryInfo : ObjectNotFound: (./darkent.exe:String) [], CommandNotFoundException
- FullyQualifiedErrorId : CommandNotFoundException
 Malithi-gif
on 17 Nov 2020
Malithi-gif
on 17 Nov 2020

Malithi-gif
on 17 Nov 2020
write erro: ./ reaplace darkent.exe to darknet.exe
eltonfernando
on 17 Nov 2020
Yes It works, now get new error
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
CUDA status Error: file: C:darknetsrcdark_cuda.c : cuda_set_device() : line: 39 : build time: Nov 17 2020 - 18:52:29
I used cuda version 10.1
Malithi-gif
on 17 Nov 2020

Malithi-gif
on 17 Nov 2020
Dear Malithi,Do you have GPU?
Le mardi 17 novembre 2020 à 15:53:54 UTC+2, Malithi-gif notifications@github.com a écrit :
Yes It works, now get new error
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
CUDA status Error: file: C:darknetsrcdark_cuda.c : cuda_set_device() : line: 39 : build time: Nov 17 2020 - 18:52:29
I used cuda version 10.1
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub, or unsubscribe.
pakson20
on 17 Nov 2020
@pakson20, I haven't GPU
Malithi-gif
on 17 Nov 2020
In that case, try the following;1. Go to your make file and set GPU = 02. run with the command darknet_no_gpu instead of darknet
Le mardi 17 novembre 2020 à 16:36:50 UTC+2, Malithi-gif notifications@github.com a écrit :
@pakson20, I haven't GPU
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub, or unsubscribe.
pakson20
on 17 Nov 2020
@Malithi-gif
In that case, try the following;
- Go to your make file and set GPU = 0
- run with the command darknet_no_gpu instead of darknet
You should also have built the file darknet_no_gpu the same way you built darknet.
pakson20
on 17 Nov 2020
@pakson20
GPU=0
CUDNN=1
CUDNN_HALF=0
OPENCV=1
AVX=0
OPENMP=0
LIBSO=0
ZED_CAMERA=0
ZED_CAMERA_v2_8=0
I changed GPU as a 0 and I got anther error,
PS C:darknet> ./darknet_no_gpu detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
./darknet_no_gpu : The term './darknet_no_gpu' is not recognized as the name of a cmdlet, function, script file, or
operable program. Check the spelling of the name, or if a path was included, verify that the path is correct and try
again.
At line:1 char:1
- ./darknet_no_gpu detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
~~~~
- CategoryInfo : ObjectNotFound: (./darknet_no_gpu:String) [], CommandNotFoundException
- FullyQualifiedErrorId : CommandNotFoundException
Thanks for the help.
Malithi-gif
on 17 Nov 2020
Should I need to rebuild to get darknet_no_gpu?
Malithi-gif
on 17 Nov 2020
yes you should. Try it.
Le mardi 17 novembre 2020 à 16:59:18 UTC+2, Malithi-gif notifications@github.com a écrit :
Should I need to rebuild to get darknet_no_gpu?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub, or unsubscribe.
pakson20
on 17 Nov 2020
@Malithi-gif
Do not forget to get rid of ./
So you should run darknet_no_gpu.exe
pakson20
on 17 Nov 2020
@pakson20 Try to build darknet in cmake, getting another error.
PThreads_windows_DLL_DIR: C:/darknet/3rdparty/pthreads/include/../bin
CMake Warning at CMakeLists.txt:110 (find_package):
By not providing "FindOpenCV.cmake" in CMAKE_MODULE_PATH this project has
asked CMake to find a package configuration file provided by "OpenCV", but
CMake did not find one.
Could not find a package configuration file provided by "OpenCV" with any
of the following names:
OpenCVConfig.cmake
opencv-config.cmake
Add the installation prefix of "OpenCV" to CMAKE_PREFIX_PATH or set
"OpenCV_DIR" to a directory containing one of the above files. If "OpenCV"
provides a separate development package or SDK, be sure it has been
installed.
Thanks for the supporting
Malithi-gif
on 17 Nov 2020
@Malithi-gif
I am not using cmake . I have installed darknet by using the legacy way.
You may follow these youtube tutorials to install and to run darknet. They are very well explained. thanks
Setting up yoloV3
https://youtu.be/wBtiGTToVEE
Run yolov3 on custom dataset
https://youtu.be/zJDUhGL26iU
pakson20
on 17 Nov 2020
@pakson20 thank you so much
Malithi-gif
on 17 Nov 2020
Does anyone have video slicing knowledge in python?
I need to slice the video according to the object. That's means track the object and get the video clip that includes that object.
Malithi-gif
on 18 Nov 2020
hello everyone,
I am using yolov3 to train my dataset for object detection,i have created obj.name,obj.data,train.txt,test.txt file to run custom dataset on yolo v3 but i got this error
x-special/nautilus-clipboard
copy
file:///home/anil/Downloads/IMG_20201206_221020.jpg
thank you
 akrepriyanka1992
on 6 Dec 2020
akrepriyanka1992
on 6 Dec 2020
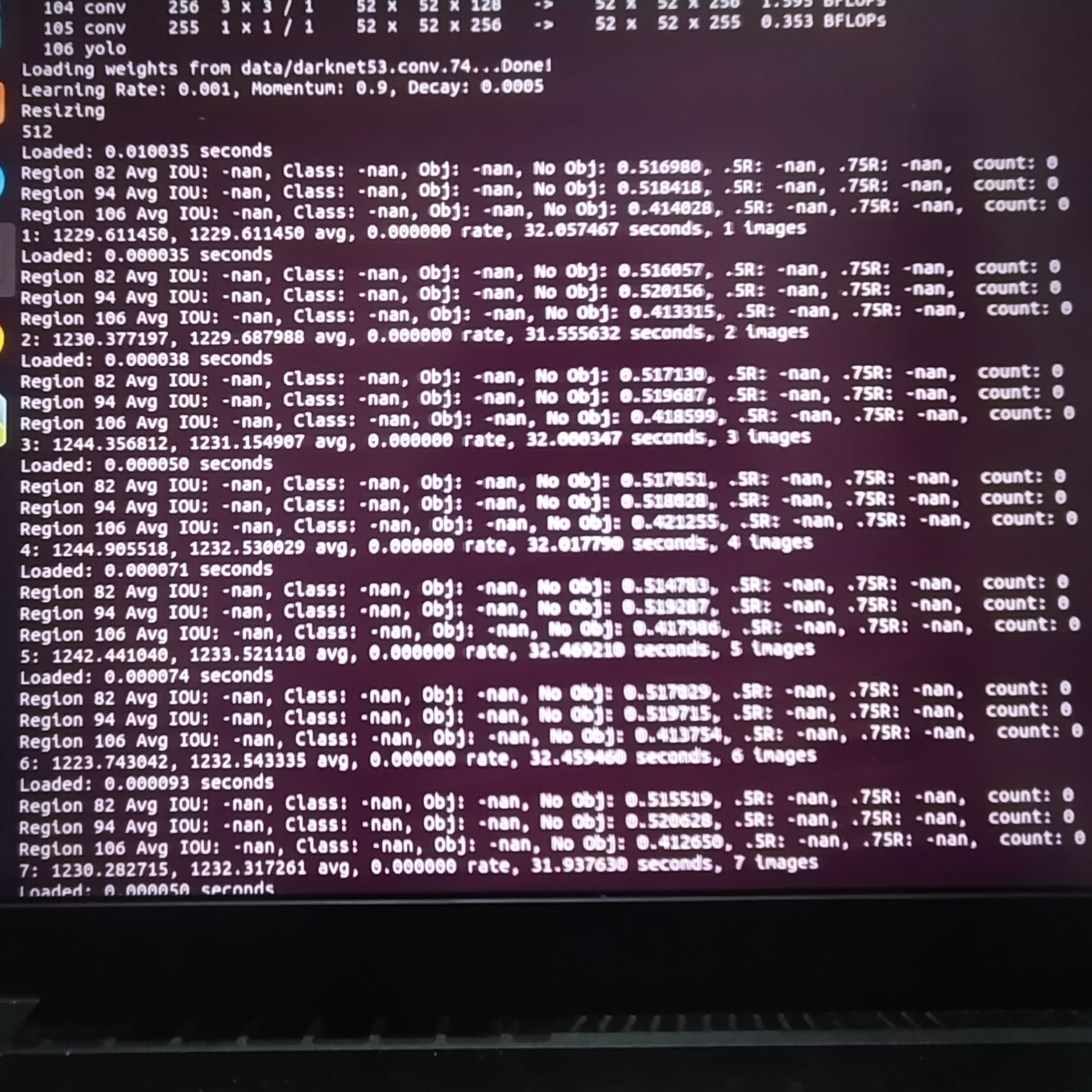
akrepriyanka1992
on 6 Dec 2020
@akrepriyanka1992
This happens sometimes, it should change over time. if you get -nan on the last line (avg, rate) then yes you have problems.
did you recalculate the anchors? this can help
eltonfernando
on 6 Dec 2020
thank you for your rply..
how to recalculate the anchors..??can you please tell me
akrepriyanka1992
on 6 Dec 2020
values defined in your file .cfg
num=6
width=416
height=416
./darknet detector calc_anchors data/obj.data -num_of_clusters 6 -width 416 -height 416
change path data/obj.data if necessary
after running the command it will calculate the anchors for you dataset, the IoU says how well the anchors managed to adapt to your dataset, if IoU is too low it means that you need to increase the number of anchors (num_of_clusters)
in copy terminal value to cfg
anchors = new value
eltonfernando
on 6 Dec 2020
I changed the width and height but same output,after execute this
(./darknet detector calc_anchors data/obj.data -num_of_clusters 6 -width
416 -height 416
)i didnt get any output..
On Sun, Dec 6, 2020 at 11:16 AM Elton fernandes dos santos <
[email protected]> wrote:
values defined in your file .cfg
num=6
width=416
height=416./darknet detector calc_anchors data/obj.data -num_of_clusters 6 -width
416 -height 416change path data/obj.data if necessary
after running the command it will calculate the anchors for you dataset,
the IoU says how well the anchors managed to adapt to your dataset, if IoU
is too low it means that you need to increase the number of anchors
(num_of_clusters)—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/pjreddie/darknet/issues/597#issuecomment-739525089,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/APE3EF2XFOTVXNEBIU6FQE3STOU5HANCNFSM4EYDQEIQ
.
akrepriyanka1992
on 7 Dec 2020
after changing num=6.it showing segmentation fault
On Sun, Dec 6, 2020 at 8:52 PM Priyanka Akre priyankakavitaakre@gmail.com
wrote:
I changed the width and height but same output,after execute this
(./darknet detector calc_anchors data/obj.data -num_of_clusters 6 -width
416 -height 416)i didnt get any output..
On Sun, Dec 6, 2020 at 11:16 AM Elton fernandes dos santos <
[email protected]> wrote:values defined in your file .cfg
num=6
width=416
height=416./darknet detector calc_anchors data/obj.data -num_of_clusters 6 -width
416 -height 416change path data/obj.data if necessary
after running the command it will calculate the anchors for you dataset,
the IoU says how well the anchors managed to adapt to your dataset, if IoU
is too low it means that you need to increase the number of anchors
(num_of_clusters)—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/pjreddie/darknet/issues/597#issuecomment-739525089,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/APE3EF2XFOTVXNEBIU6FQE3STOU5HANCNFSM4EYDQEIQ
.
akrepriyanka1992
on 7 Dec 2020
@ akrepriyanka1992
Question: What is it "_-num_of_clusters_"?
Answer: It is number of anchors (number of pairs of values), it is equal 5 for yolov2, 6 for yolov3-tiny, 9 for yolov3.
Above is for use in command line, when calculate anchors for your dataset. This will yield _num_of_clusters_ pairs, which you
should insert into your cfg file instead those "_anchors= ..._".
In .cfg the same number should be in string "_num=_"
andyrey
on 7 Dec 2020
i am using yolo v3
On Sun, Dec 6, 2020 at 9:35 PM Andrey Zakharoff notifications@github.com
wrote:
@ akrepriyanka1992
Question: What is it "-num_of_clusters"?
Answer: It is number of anchors (number of pairs of values), it is equal 5
for yolov2, 6 for yolov3-tiny, 9 for yolov3.
Above is for use in command line, when calculate anchors for your dataset.
This will yield num_of_clusters pairs, which you
should insert into your cfg file instead those "anchors= ...".
In .cfg the same number should be in string "num="—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/pjreddie/darknet/issues/597#issuecomment-739627158,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/APE3EF6LKLIGHQ3DL3HMJX3STQ5QHANCNFSM4EYDQEIQ
.
akrepriyanka1992
on 7 Dec 2020
-
All lines have nan values
-
How many classes and images in your dataset?-only one class nd 120 image
for train
-
And what tool did you use for labeling labelimg with yolo text
-
What batch and subdivision do you use? batch=64,subdivision=16
-
Do you use random=1?
-
Do you train using multi-GPU?
On Sun, Dec 6, 2020 at 10:10 PM Priyanka Akre priyankakavitaakre@gmail.com
wrote:
i am using yolo v3
On Sun, Dec 6, 2020 at 9:35 PM Andrey Zakharoff notifications@github.com
wrote:@ akrepriyanka1992
Question: What is it "-num_of_clusters"?
Answer: It is number of anchors (number of pairs of values), it is equal
5 for yolov2, 6 for yolov3-tiny, 9 for yolov3.
Above is for use in command line, when calculate anchors for your
dataset. This will yield num_of_clusters pairs, which you
should insert into your cfg file instead those "anchors= ...".
In .cfg the same number should be in string "num="—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/pjreddie/darknet/issues/597#issuecomment-739627158,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/APE3EF6LKLIGHQ3DL3HMJX3STQ5QHANCNFSM4EYDQEIQ
.
akrepriyanka1992
on 7 Dec 2020
I am facing same issue with yolo v3 for custom data,Can you please help me
to solve it
On Sun, Dec 6, 2020 at 10:46 PM Priyanka Akre priyankakavitaakre@gmail.com
wrote:
>
-
All lines have nan values
-How many classes and images in your dataset?-only one class nd 120
image for train
-And what tool did you use for labeling labelimg with yolo text-
What batch and subdivision do you use? batch=64,subdivision=16
-Do you use random=1?
-Do you train using multi-GPU?
On Sun, Dec 6, 2020 at 10:10 PM Priyanka Akre <
[email protected]> wrote:i am using yolo v3
On Sun, Dec 6, 2020 at 9:35 PM Andrey Zakharoff notifications@github.com
wrote:@ akrepriyanka1992
Question: What is it "-num_of_clusters"?
Answer: It is number of anchors (number of pairs of values), it is equal
5 for yolov2, 6 for yolov3-tiny, 9 for yolov3.
Above is for use in command line, when calculate anchors for your
dataset. This will yield num_of_clusters pairs, which you
should insert into your cfg file instead those "anchors= ...".
In .cfg the same number should be in string "num="—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/pjreddie/darknet/issues/597#issuecomment-739627158,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/APE3EF6LKLIGHQ3DL3HMJX3STQ5QHANCNFSM4EYDQEIQ
.
akrepriyanka1992
on 9 Dec 2020
this is one of my trainings, in those intervals at the beginning that loss does not fall, it is normal to receive many -nan
if you are not using pre-weight, it may take longer
you have problems if avg =-nan but if nan is in some other lines - then training goes well.
eltonfernando
on 9 Dec 2020
@eltonfernando
@andyrey
Hi everyone, Please any suggestion on how to label and trains image with similar objects ?
I am using Yolov4 to train my custom dataset. I have medical images such as varicella , angioma, etc...( see attached some medical images
). I have 4 classes for 330 images. I have set Batch = 64, Subdivision = 16, width = 608 and height = 608. I am facing the following problems.
1) During the the training , after 20000 iterations, my avg loss is still around 20.
2) When i stop the training and test, yolo is confused, i.e., it detects sometimes a varicella instead of angioma for example.
3) What is best way to draw bounding boxes on such images since the image are very similar.
pakson20
on 15 Dec 2020
@pakson20
As I understand, there is varicella at the upper picture, and angioma at the bottom? And there are another 2 classes of diseases?
What I don't understand, are these 4 classes can afflict the same person simultaneously, or each picture represents only one disease?
And BTW, how did you annotate these pictures?
andyrey
on 15 Dec 2020
@andyrey
Thanks for your reply.
In fact, you are right. Each picture represent only one disease. So I have 4 classes with each class containing one disease.
For the annotation, i am not sure to have done a good annotation and that is one of my problem. I used Labelimg to create many bounding boxes around the more pronounced red points area of any picture.
The first picture is a disease call azecma and the second one is a varicella.
I have attached the two others types of diseases, i.e., angioma and squamous, respectivelly.
pakson20
on 15 Dec 2020
@pakson20, sorry for late answer, I missed your last message. I don't think the exact positioning of the sore matters in your case. So, you need classification of the whole picture rather then detection+classification of each sore. And may be you should use the appropriate classification net, not YOLO, but something like GoogleNet or EfficientNet (sorry, I don't know exactly, may be I am wrong with names, you should search).
andyrey
on 23 Dec 2020
@andyrey
Thanks for your reply. I will do more investigation about those classification nets.
pakson20
on 23 Dec 2020
Related issues
 TheHidden1
·
3Comments
TheHidden1
·
3Comments
 sujithm
·
3Comments
sujithm
·
3Comments
 arianaa30
·
3Comments
arianaa30
·
3Comments
 gpsmit
·
3Comments
gpsmit
·
3Comments
 AaronYKing
·
3Comments
AaronYKing
·
3Comments
Most helpful comment
@sonalambwani Just wait about 1000 iterations, and
nanwill disappear: https://github.com/AlexeyAB/darknet/issues/504#issuecomment-377290060and this command if in your cfg-file
width=416andheight=416:darknet.exe detector calc_anchors data/voc.data -num_of_clusters 9 -width 416 -heigh 416This anchors you can use in your cfg-file (without multiplication by 32)