It would be great to also have a default template for RDS storage backend in addition to DynomoDB and S3.
 rothgar
rothgar
All 12 comments
Is there a plan for how to handle deleting/retaining data?
Example: I define an S3 bucket as an addon (either manually or via the storage command). I don't want to preserve the data in the bucket, so I set the DeletionPolicy in CF to Retain. The bucket is not deleted, but I also can't delete the deployment and redeploy, b/c CF will fail b/c of the already existing bucket.
At this point, I think I may define some static resources externally in Terraform to work around this.
I assume the same would apply for RDS (though maybe the snapshot retention policy could help? ...I don't have experience with it personally).
(I mention it here as input for the storage command design considerations.)
But on the subject of having the default template, I'd use it regardless of the above. 👍
 jonchase
on 24 Jul 2020
jonchase
on 24 Jul 2020
Hi @jonchase we're considering how to do this safely in #1172. Your use case seems fairly common and we need to find a better story for resource names, since customers may want to retain data but start with a "fresh" bucket on a new version or iteration of the service.
We're considering making the bucket or table name into a fully optional parameter, which would allow us to rely on CF to generate random resource names and avoid naming collisions.
We set the deletion policy to 'retain' by default because we don't want folks to accidentally lose data by tearing down an S3 bucket with "svc delete" before backing things up. Does that make sense?
 bvtujo
on 27 Jul 2020
bvtujo
on 27 Jul 2020
Could really use this too. If it helps any, I wrote documented Go types (converted from TS using Quicktype) for the CloudFormation AWS::RDS::DBInstance type to make this easier:
Go types + marshallers:
https://gist.github.com/GavinRay97/c8faa0b75567725d8f09cd110e2ed6e6#file-main-go
Original TS types (it kind of butchered the JSDoc comments on struct translation):
https://gist.github.com/GavinRay97/c8faa0b75567725d8f09cd110e2ed6e6#file-main-ts
 GavinRay97
on 12 Sep 2020
GavinRay97
on 12 Sep 2020
Hi everyone!
Until we provide a way of generating the CloudFormation template from storage init, you can use the following template in your "addons/" directory and it should create an aurora cluster for you!
https://gist.github.com/efekarakus/e68c176b41ef4ab8d18fbbe3fa78fcc4
 efekarakus
on 18 Sep 2020
efekarakus
on 18 Sep 2020
Another template but this time for Aurora Serverless with Postgres that can be copy pasted to your addons: https://gist.github.com/efekarakus/1ab9a34f6d4c80f6b035be4b8198d00e using the private subnets from your environment
note-to-self: If you'd like to do credentials rotation, take a look at using the Lambda from: https://gist.github.com/efekarakus/2d69190e54b8d9a3719f2bd81181b73f
efekarakus
on 4 Oct 2020
Thanks for sharing those gists, @efekarakus.
What's the correct way to use an RDS add on when I have multiple backend services accessing the same database instance?
 afgallo
on 3 Mar 2021
afgallo
on 3 Mar 2021
Hi @afgallo !
If possible, the recommended approach would be to have a single backend service be the API in front of the RDS database. Other services can communicate with the database through the API using service discovery for example. The benefits are that your services become loosely coupled, you can easily make data changes without impacting other services, and a reduction in blast radius in case one service starts misbehaving.
However, if we deem that our application is small and it's easier to share the database, then one way of doing that is through SSM parameters (see https://github.com/aws/copilot-cli/issues/1368#issuecomment-692316027)
For example, I'd modify the addon template above, like this to add a SSM parameter for the database endpoint:
EndpointAddressParam:
Type: AWS::SSM::Parameter
Properties:
Name: !Sub ${App}-${Env}-${Name}-DBEndpoint # Give a path to the parameter
Type: String
Value: !GetAtt AuroraDBCluster.Endpoint.Address # Retrieve the RDS endpoint address
Then in the manifests of my other services, I can refer the password as well as the endpoint through the secrets field:
name: 'other-service'
secrets:
DB_ENDPOINT: '<app>-<env>-<service>-DBEndpoint'
DB_PASSWORD: 'arn:aws:secretsmanager:<region>:<aws_account_id>:secret:<secretID created in the addon template>'
Hope this helps!
efekarakus
on 3 Mar 2021
EDIT:
_Reading the documentation again, it seems that I cannot yet launch Backend services in a private subnet but would still like some clarification on the below, thank you!_
Thanks for your reply, @efekarakus. I am really digging copilot. This may be the answer for me to start using AWS ECS on Fargate which previously would mean a lot of infrastructure maintenance burden.
My question was about a scenario I wanted to explore with copilot - I want to have a microservices oriented architecture where there's an API gateway (Load Balanced Web Service) with a myriad of services (Backend Service). The API gateway is responsible for handling requests after they get passed on by ALB. This is where I would handle common HTTP stuff like authentication and authorisation, caching, payload parsing, etc. The API gateway does not communicate directly to the database as it sits on the public subnet as per the image below. The only way to talk to the data tier is through other services that sit on the private subnet.
Essentially, this is the high-level approach:
ALB -> API Gateway -> Services -> Database Cluster
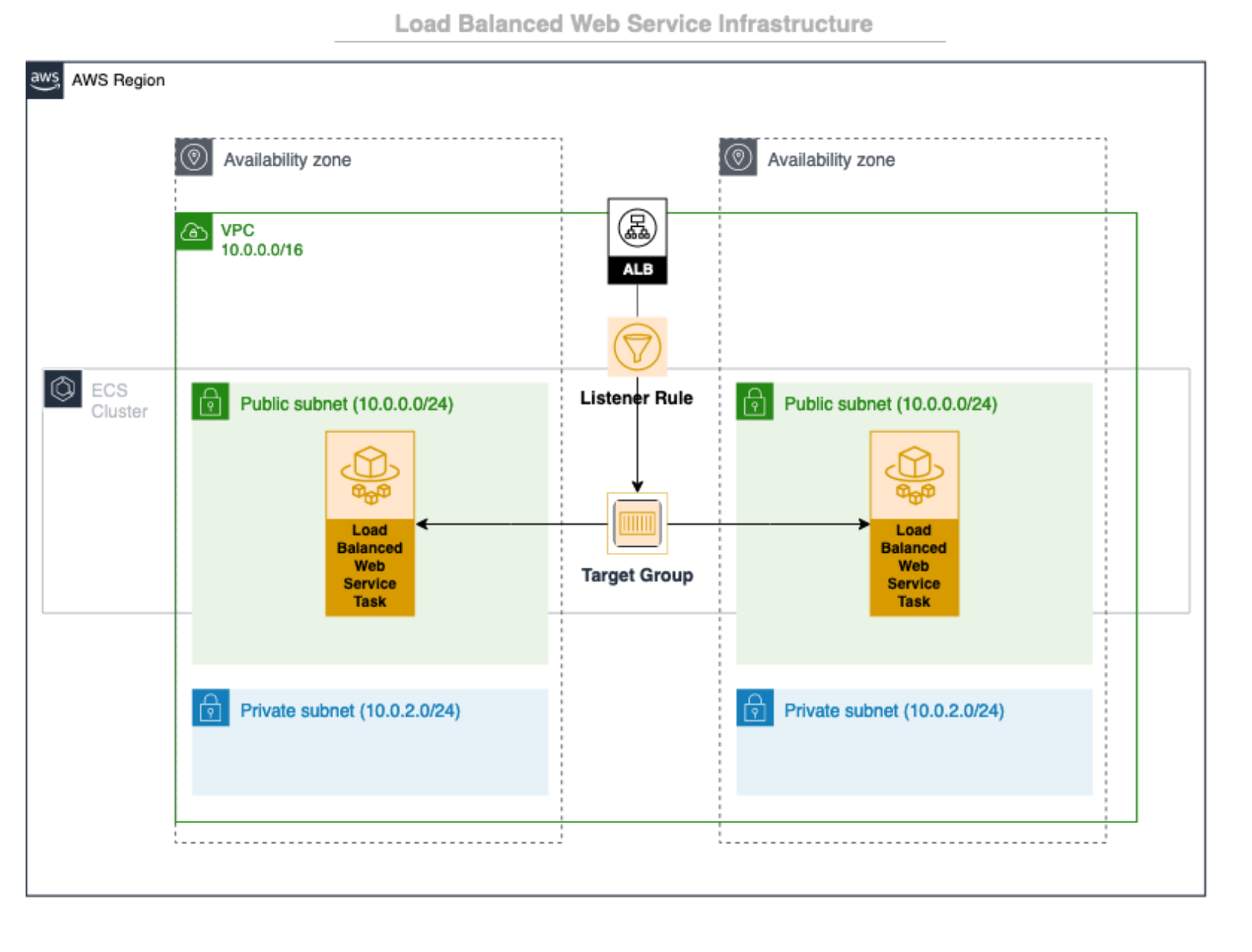
I guess most backend services, for now, will share the same database, but the idea is that the can independently do their "CRUD" tasks on a given "Model". For instance, my user service knows how to manage data for the "User" Model. It doesn't know about the "Sales" service, though.
If I understood you correctly, I can achieve this by adding an add-on with the template for the database cluster in just one of those Backend services and leverage its connection string viam SSM parameters in other services. This will mean every time I deploy the services that has the add-on, CF will try to update my database cluster deployment if it needs to. Other services won't re-deploy the cluster.
Is that correct? Do you see any issues with such an approach?
Thanks in advance!
afgallo
on 3 Mar 2021
If I understood you correctly, I can achieve this by adding an add-on with the template for the database cluster in just one of those Backend services and leverage its connection string viam SSM parameters in other services. This will mean every time I deploy the services that has the add-on, CF will try to update my database cluster deployment if it needs to. Other services won't re-deploy the cluster.
Yup you understood it exactly right!
Is that correct? Do you see any issues with such an approach?
I can't think of really any issues besides the ones mentioned above: one backend service affecting the other ones since they all share the same database. If adding the SSM parameter seems to be a viable route, we had other users do it and it seemed to work for them :) it's just slightly more work for you since Copilot doesn't provide environment-level resources at the moment.
it seems that I cannot yet launch Backend services in a private subnet
As of v1.3.0, we added a network field to the manifests to place tasks in private subnets:
network:
vpc:
placement: 'private'
However, this field is really only useful if you imported a VPC with NAT gateways when running copilot env init. Otherwise, your tasks won't be able to reach out to the internet. So for example, you won't be able to pull an ECR image if the tasks are placed in private subnets. We're working towards enabling NAT gateways when users specify placement: private!
efekarakus
on 4 Mar 2021
Awesome, thanks for clarifying all that.
I can't think of really any issues besides the ones mentioned above: one backend service affecting the other ones since they all share the same database. If adding the SSM parameter seems to be a viable route, we had other users do it and it seemed to work for them :) it's just slightly more work for you since Copilot doesn't provide environment-level resources at the moment.
Another approach I could consider is below:
ALB -> API Gateway -> User Service -> Database Facade -> Database Cluster
That way, I can have a user service that is concerned with dealing with all things "user" talking to an API that provides access to the database (i.e. Database facade).
Even though the documentation states that:
VPC and Networking
Each environment gets its own multi-AZ VPC. Your VPC is the network boundary of your environment, allowing the traffic you expect in and out, and blocking the rest. The VPCs Copilot creates are spread across two availability zones to help balance availability and cost - with each AZ getting a public and private subnet.
Your services are launched in the public subnets but can be reached only through your load balancer.
The addition of private services with NAT gateways will be very welcomed!
afgallo
on 4 Mar 2021
Another template but this time for Aurora Serverless with Postgres that can be copy pasted to your addons: https://gist.github.com/efekarakus/1ab9a34f6d4c80f6b035be4b8198d00e using the private subnets from your environment
note-to-self: If you'd like to do credentials rotation, take a look at using the Lambda from: https://gist.github.com/efekarakus/2d69190e54b8d9a3719f2bd81181b73f
Hi @efekarakus, thank you for sharing these templates!
Do you have a template for adding Postgres RDS as well? (not aurora-postgres)
Thank you!
 renatogbp
on 3 Apr 2021
renatogbp
on 3 Apr 2021
Hi folks! Happy to share that the Aurora Serverless integration is now released and available under storage init https://github.com/aws/copilot-cli/releases/tag/v1.5.0! 🚀🥳
efekarakus
on 14 Apr 2021
Related issues
 jaybauson
·
3Comments
jaybauson
·
3Comments
 shrasool
·
4Comments
shrasool
·
4Comments
 BenediktMiller
·
3Comments
BenediktMiller
·
3Comments
 fullstackdev-online
·
3Comments
efekarakus
·
3Comments
fullstackdev-online
·
3Comments
efekarakus
·
3Comments
Most helpful comment
Hi everyone!
Until we provide a way of generating the CloudFormation template from
storage init, you can use the following template in your "addons/" directory and it should create an aurora cluster for you!https://gist.github.com/efekarakus/e68c176b41ef4ab8d18fbbe3fa78fcc4