Contao: Geschützte Seiten aus sitemap.xml ausschließen
Affected version(s)
Contao 4.9
Description
Damit Seiten vom Contao-Crawler indexiert werden, muss der Robot-Tag auf "follow" stehen.
Bei dieser Einstellung wird die Seite allerdings auch in der sitemap.xml eingetragen.
Ich möchte allerdings nicht, dass geschützte Seiten in der sitemap.xml aufgeführt werden.
Wäre es denkbar, dass eine explizite Option _Von xml-Sitemap ausschließen_ integriert wird?
How to reproduce
- Seite mit Robots-Tag "noindex,follow" versehen.
- Seite erscheint auf öffentlicher sitemap.xml
siehe auch:
https://github.com/contao/contao/issues/1395
 contaoacademy
contaoacademy
All 30 comments
Ich finde auch, dass die sitemap.xml Einstellung nicht an den robots noindex,nofollow meta tag gebunden sein sollte. Auch einfach nur aus UX Sicht ist dies ein nicht sichtbarer Zusammenhang.
 fritzmg
on 26 Feb 2020
fritzmg
on 26 Feb 2020
Bedeutet _geschützt_ dass auf die Seite nur von Mitgliedern zugegriffen werden kann?
 aschempp
on 26 Feb 2020
aschempp
on 26 Feb 2020
revisit https://github.com/contao/contao/issues/501
Bin immernoch der Meinung, dass in die sitemap.xml nur Seiten mit index gehören und finde die Kopplung von robots-metatag und sitemap.xml allemal besser als das was wir vorher hatten (Kopplung von Sitemap-Modul und sitemap.xml)
 asaage
on 26 Feb 2020
asaage
on 26 Feb 2020
Der Aufruf von geschützten Seiten führt zu einem Fehler 401.
Demzufolge sollten diese nicht in der Sitemap erscheinen.
Dieses Ausschlusskriterium sollte unabhängig davon gelten, wie die Einstellung Robots-Tag konfiguriert ist.
 Mynyx
on 27 Feb 2020
Mynyx
on 27 Feb 2020
@Mynyx nein, man kann ja einstellen, dass geschütze Seiten durchsuchbar sein sollen.
fritzmg
on 27 Feb 2020
@fritzmg Würdest du mir zustimmen, wenn die Sitemap für den Contao Crawler nicht relevant wäre?
Mynyx
on 27 Feb 2020
In so fern ja, der Crawler muss von Contao die initialen Seiten anders als über die öffentliche sitemap.xml bekommen. Anders wird das wohl nicht vereinbar werden?
fritzmg
on 27 Feb 2020
Genau.
Grundsätzlich denke ich auch, dass der Crawler initial alle Seiten erhalten sollte, und es keine Vorabfilterung geben sollte. Die Entscheidung sollte dann ausschließlich bei den einzelnen Subscribern des Crawlers liegen.
/cc @Toflar
Mynyx
on 27 Feb 2020
Das sehe ich anders. So funktioniert ein Crawler einfach nicht. Ein Crawler fängt irgendwo an und geht von da aus weiter. Die Sitemap ist genau dafür da, dass er Dinge finden kann, die nicht auf den Root-Seiten verlinkt sind.
 Toflar
on 27 Feb 2020
Toflar
on 27 Feb 2020
Ja, aber die sitemap.xml sollte doch keine Seiten anzeigen, die gar nicht öffentlich verfügbar sind, oder bist du da anderer Meinung?
fritzmg
on 27 Feb 2020
Vielleicht brauchen wir unterschiedliche robots.txt Sitemap Einträge, das mag sein. Wir könnten ggf. eine zusätzliche Sitemap generieren (mit einem _protected Suffix oder so) und den nur ausgeben wenn eingeloggt. Aber ich beharre darauf, dass sich der Crawler absolut korrekt verhält. Es ist wichtig, dass die technischen Zuständigkeiten korrekt eingehalten werden.
Toflar
on 27 Feb 2020
Der Crawler für sich verhält sich korrekt, ja. Aber wir wollen ja, dass der Crawler weiterhin im Stande ist genau das zu tun, was das reguläre Indexing von Contao auch konnte. Könnte man den Crawler nicht auch anderweitig das Ergebnis aus getSearchablePages zukommen lassen?
fritzmg
on 27 Feb 2020
Ich will es technisch sinnvoll haben, ganz einfach :) Für mich ist es dann richtig, wenn Contao keine Rolle mehr spielt. Ich sollte irgend einen Crawler verwenden können, der nichts von Contao weiss. Keine Hooks, nichts - nur Standards. Je weniger Dinge Contao-spezifisch sind, desto besser. Alles andere ist für mich der falsche Ansatz. Also müssen wir Lösungen suchen, die meinen Wunsch und euren abdecken.
Toflar
on 27 Feb 2020
In contao/core-bundle/src/Crawl/Escargot/Factory.php werden die URLs zusammengestellt, mit denen der Crawler startet. Das könnte eine Möglichkeit darstellen, auch die URLs aus getSearchablePages hinzuzufügen.
Mynyx
on 27 Feb 2020
Ich sollte irgend einen Crawler verwenden können, der nichts von Contao weiss.
Wozu braucht man dann die internen Einzelheiten aus #1236?
asaage
on 28 Feb 2020
Der Crawler funktioniert wie jeder andere Crawler und er soll es auch. Er soll nichts von Contao Internas wissen und genau so ist es jetzt auch.
Die "Einzelheiten" sind JSON-LD Daten (ein weiterer Standard), die dem Crawler völlig egal sind. Sie sind komplett irrelevant für den Crawler. Sie sind nur relevant für den Indexer und das sind zwei völlig unabhängige Prozesse.
Es gibt den Prozess des Crawlens und n Prozesse die Resultate zu verarbeiten. Ich nenne sie "Subscriber". Ein Subscriber ist das Aktualisieren des Suchindexes. Ein anderer ist das Prüfen von defekten Links. Und irgendwann wird's weitere Funktionen geben, die mit den Resultaten was tun wollen (bspw. WAI-ARIA Checks wären denkbar).
Und ich will nicht, dass man dem Crawler ein Resultat von getSearchablePages() mitgeben muss, damit ein einziger Subscriber korrekt funktionieren kann.
Das ist eine Verletzung des Single Responsibility Principles. Eine Vermengung von Zuständigkeiten. Und das will ich vermeiden, weil es sorgt irgendwann für Probleme.
Wir haben aus historischen Gründen jede Menge solcher SRP Violations. Ich geb euch ein Beispiel: Die Benutzerberechtigungen im Backend werden in irgendwelchen onload_callbacks auf Basis von Query-Parametern geprüft (act=edit ist bearbeiten, act=create ist anlegen etc.). Wir haben also eine Vermengung von zwei Aufgaben/Zuständigkeiten: Berechtigungen prüfen und bestimmen, welche Berechtigungen geprüft werden müssen.
Wenn ich also jetzt an einer API arbeiten möchte, die völlig andere Query-Parameter hat. Wie soll ich die Prüfung auf Berechtigungen wiederverwenden? Richtig, gar nicht. Es geht nicht.
Wir müssen also zuerst wieder das SRP einhalten und die Zuständigkeiten in zwei Komponenten aufsplitten, bevor wir was Neues einführen können.
Klar, die Prüfung schnell, schnell in einem onload_callback einzubauen war pragmatisch und einfach und hat den Zweck erfüllt. Schnell, schnell getSearchablePages() dem Crawler hinzuzufügen wäre das auch. Aber sie ist langfristig problematisch. Und ich will nicht, dass wir Fehler wiederholen. Das können wir besser.
Toflar
on 28 Feb 2020
Der Crawler funktioniert wie jeder andere Crawler und er soll es auch. Er soll nichts von Contao Internas wissen und genau so ist es jetzt auch.
Grundsätzlich verstehe ich nun was deine Intention ist. Auf der anderen Seite ist es allerdings eine Definitionsfrage, was unter einem "normalen" Crawler verstanden wird. Abstrakt könnte dies als Prozess beschrieben werden, der ein Set von URLs als Startparameter erhält, diese herunterlädt und verarbeitet bzw. zur Verarbeitung zur Verfügung stellt sowie dabei entdeckten neuen URLs unter Einhaltung bestimmte Kriterien folgt.
Dafür wie der Crawler das Set von URLs als Startparameter erhält, besteht allerdings kein einheitlicher Standard.
Eine öffentliche Sitemap ist eine Möglichkeit, die insbesondere von Crawlern für öffentliche Suchmaschinen verwendet wird - eine spezielle Form von Crawlern.
Bei anderen Crawlern, wie zum Beispiel algolia, besteht auch die Möglichkeit extraUrls zu übergeben (https://www.algolia.com/doc/tools/crawler/getting-started/quick-start/#link-extraction).
Auch verhält es sich ja so, dass der Crawler geschützte Seiten aktuell nur dadurch crawlen kann, dass Contao zuvor eine Session erstellt und das Sessioncookie als Parameter den Crawler übergibt. Der Crawler kann geschützte Seiten also nicht selbstständig crawlen sondern benötigt dafür Informationen von Contao.
Und ich will nicht, dass man dem Crawler ein Resultat von
getSearchablePages()mitgeben muss, damit ein einziger Subscriber korrekt funktionieren kann.
Gerade für andere Anwendungszwecke wie die Suche nach defekten Links oder WAI-ARIA Checks wäre es sinnvoll alle Seiten einer Website zu testen - unabhängig von deren Einstellungen für die Suche bzw. Sitemap.
PS: Vielen Dank für deine ausführlichen Erläuterungen.
Mynyx
on 28 Feb 2020
Bei anderen Crawlern, wie zum Beispiel algolia, besteht auch die Möglichkeit
extraUrlszu übergeben (https://www.algolia.com/doc/tools/crawler/getting-started/quick-start/#link-extraction).
Das geht bei uns ja auch:
contao:
crawl:
additional_uris:
- 'https://....'
Wie am 12. März auf Mumble besprochen, wollen wir als in Contao 4.9 keine geschützten Seiten mehr in die XML-Dateien schreiben. In Contao 4.10 wollen wir dann die XML-Sitemaps als Routen ausliefern (so wie neu die Dateien favicon.ico und robots.txt), die dann bei einem authentifizierten Benutzer zusätzlich die geschützten Seiten ausgeben können.
 leofeyer
on 12 Mar 2020
leofeyer
on 12 Mar 2020
Ich wollte das Ticket eben bearbeiten, konnte aber das Problem nicht reproduzieren. 🤷♂
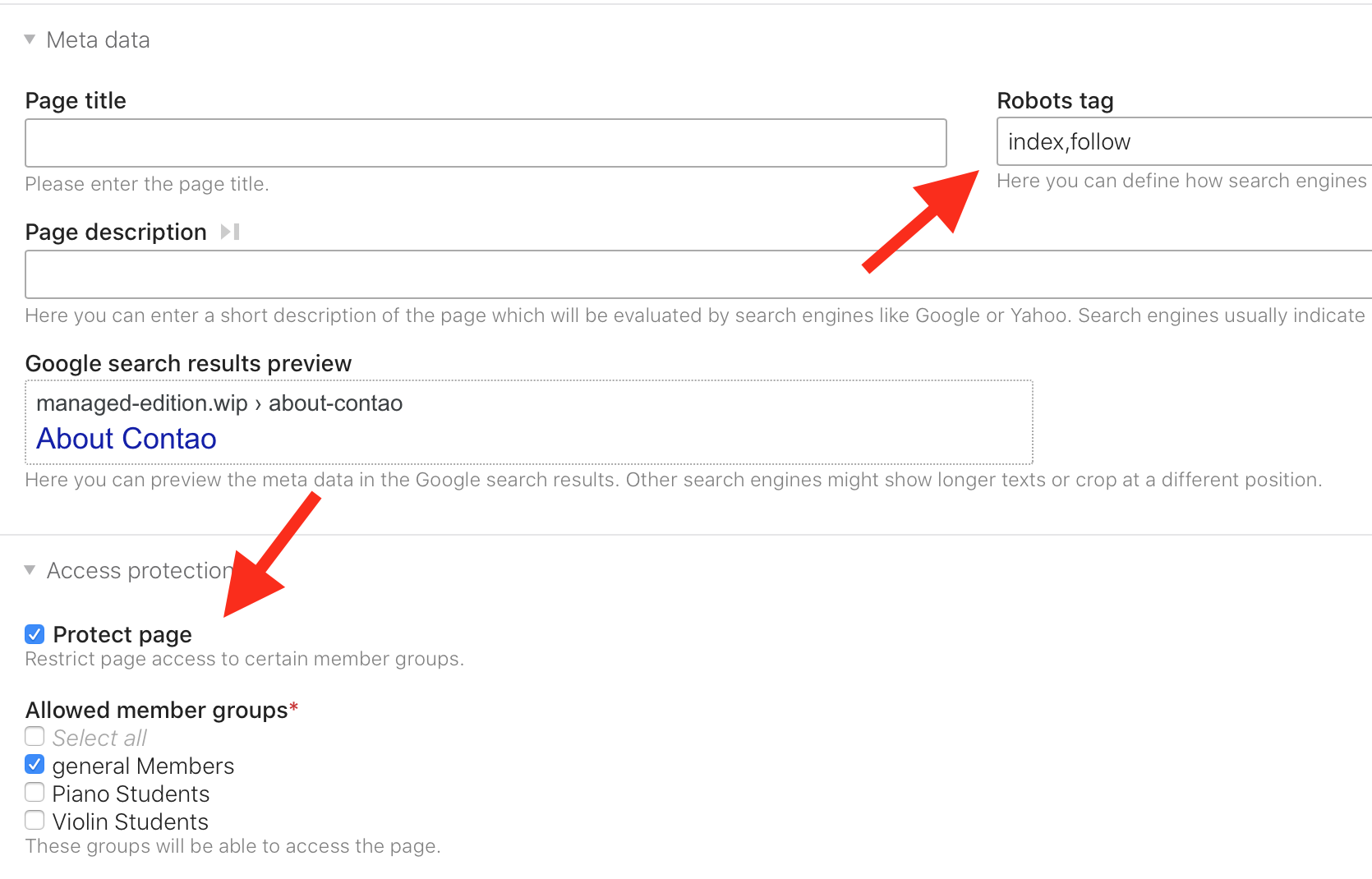
Die URL taucht in der Sitemap nicht auf:

leofeyer
on 27 Mar 2020
In der Standardkonfiguration verhält es sich wie du beschreibst.
Die URL erscheint erst in der sitemap.xml, wenn in der config.yml die Suche für geschützte Seiten aktiviert wird.
contao:
search:
index_protected: true
@leofeyer Kannst du dir das noch mal ansehen?
contaoacademy
on 11 May 2020
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
![stale[bot] picture](https://avatars3.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 10 Jun 2020
stale[bot]
on 10 Jun 2020
@leofeyer Kannst du dir das noch mal ansehen.
 fenepedia
on 10 Jun 2020
fenepedia
on 10 Jun 2020
I can confirm the issue. Protected pages do not show up in the sitemap, if
contao:
search:
index_protected: false
(the default), but they do show up if
contao:
search:
index_protected: true
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
stale[bot]
on 6 Oct 2020
@contao/developers Can you think of a way to fix this in Contao 4.9?
leofeyer
on 6 Oct 2020
If we do not want to backport the new sitemap feature for Contao 4.11, then I think the only option is to generate a second sitemap and pass that sitemap to the crawler.
fritzmg
on 6 Oct 2020
Btw. don't we need a separate sitemap for the crawler in any case? Even if you do not have protected pages, the search index is supposed to contain all Contao pages, except the ones excluded via tl_page.noSearch. Currently you can set noindex,nofollow, but not enable noSearch, indicating that you do not want the page to be indexed by other search engines, but still want it indexed by Contao's search index. However, since this removes the page from the sitemap, the crawler might never visit it. (Would it index it in any case, since it has noindex?)
fritzmg
on 22 Oct 2020
As discussed in Mumble on October 22nd, this will be a known limitation in Contao 4.9. The issue will be fixed in Contao 4.11 and cannot really be backported without risking to break other stuff.
leofeyer
on 22 Oct 2020
Related issues
 bennyborn
·
26Comments
bennyborn
·
26Comments
 tabcontao
·
34Comments
tabcontao
·
34Comments
 volkerrichert
·
34Comments
volkerrichert
·
34Comments
 xprojects-de
·
103Comments
xprojects-de
·
103Comments
 madmaharaja
·
25Comments
madmaharaja
·
25Comments
Most helpful comment
Der Crawler funktioniert wie jeder andere Crawler und er soll es auch. Er soll nichts von Contao Internas wissen und genau so ist es jetzt auch.
Die "Einzelheiten" sind JSON-LD Daten (ein weiterer Standard), die dem Crawler völlig egal sind. Sie sind komplett irrelevant für den Crawler. Sie sind nur relevant für den Indexer und das sind zwei völlig unabhängige Prozesse.
Es gibt den Prozess des Crawlens und
nProzesse die Resultate zu verarbeiten. Ich nenne sie "Subscriber". Ein Subscriber ist das Aktualisieren des Suchindexes. Ein anderer ist das Prüfen von defekten Links. Und irgendwann wird's weitere Funktionen geben, die mit den Resultaten was tun wollen (bspw. WAI-ARIA Checks wären denkbar).Und ich will nicht, dass man dem Crawler ein Resultat von
getSearchablePages()mitgeben muss, damit ein einziger Subscriber korrekt funktionieren kann.Das ist eine Verletzung des Single Responsibility Principles. Eine Vermengung von Zuständigkeiten. Und das will ich vermeiden, weil es sorgt irgendwann für Probleme.
Wir haben aus historischen Gründen jede Menge solcher SRP Violations. Ich geb euch ein Beispiel: Die Benutzerberechtigungen im Backend werden in irgendwelchen onload_callbacks auf Basis von Query-Parametern geprüft (
act=editist bearbeiten,act=createist anlegen etc.). Wir haben also eine Vermengung von zwei Aufgaben/Zuständigkeiten: Berechtigungen prüfen und bestimmen, welche Berechtigungen geprüft werden müssen.Wenn ich also jetzt an einer API arbeiten möchte, die völlig andere Query-Parameter hat. Wie soll ich die Prüfung auf Berechtigungen wiederverwenden? Richtig, gar nicht. Es geht nicht.
Wir müssen also zuerst wieder das SRP einhalten und die Zuständigkeiten in zwei Komponenten aufsplitten, bevor wir was Neues einführen können.
Klar, die Prüfung schnell, schnell in einem onload_callback einzubauen war pragmatisch und einfach und hat den Zweck erfüllt. Schnell, schnell
getSearchablePages()dem Crawler hinzuzufügen wäre das auch. Aber sie ist langfristig problematisch. Und ich will nicht, dass wir Fehler wiederholen. Das können wir besser.