Containers-roadmap: Targets not deregistered after task is stopped, serious routing issue with dynamic port mapping
The agent sometimes fails to remove a target from a target group after the ECS task has stopped.
We seem to be witnessing aws/amazon-ecs-agent#500 again with agent versions 1.17.3 and 1.18.0.
We have an ECS cluster of 50 services on 10 instances. Each service has one or more tasks, and each task definition has only one container. Each container has an application port as well as couple metrics exporter service ports. We use dynamic host port mapping.
Service A started logging elevated error rates when it was calling service B, and reading the logs we noticed that it was somehow getting a reply instead from a metrics agent from Service C. Digging deeper, we found that several target groups for the services had lingering unhealthy targets. One of the healthy targets in service B's target group was the Service C's metrics agent. The agent in question is the Prometheus node_exporter, which unfortunately responds HTTP 200 OK no matter which path is requested from it, and thus we believe it managed to survive in the wrong target group.
We cleaned the lingering targets manually, and configured an alarm to go off if there are any unhealthy targets. Right now, we have saved some unhealthy targets in a testing environment, and continue to dig further into this. I will also contact AWS support from the Web Console.
 Vilsepi
Vilsepi
All 26 comments
Facing same issue after updating to version 1.18.
 adityacs
on 19 Jun 2018
adityacs
on 19 Jun 2018
The same issue started for us recently as well. We are using Fargate.
 nmlynch94
on 26 Jun 2018
nmlynch94
on 26 Jun 2018
Thank you for reporting this issue. To enable our dev team to better investigate this, could you please send the following information to me at: yhlee (at) amazon.com
- Account ID
- Task definition ID
- Container instance ID and region
- Agent log (when task is stopping)
Thank you.
 yhlee-aws
on 29 Jun 2018
yhlee-aws
on 29 Jun 2018
I can attest to the same; I actually found that this was an existing bug that should now be fixed, according to the Amazon Elastic Container Service - Developer Guide. Unfortunately, I cannot provide detailed information like logs, etc., other than that this is occurring with 100% reproducibility for us with a DAEMON scheduling strategy, connected to a target group for load balancing as of version 1.18.0 of the ECS agent. All that's necessary to reproduce is Stopping/Starting an instance; this will increment the desired count by 1 on the ECS cluster's services details page. Also worth noting is that terminating will deregister the container instance and adjust the container instance number as expected.
Some additional information of our use-case: we have auto-scaling groups that over the weekends will try to cut cost by stopping non-critical instances to be started back again on Monday. These auto-scaling groups are also given the following Suspended Processes: AZRebalance, AddToLoadBalancer, AlarmNotification, HealthCheck, Launch, ReplaceUnhealthy, ScheduledActions, Terminate. Hopefully this can give some additional insight into the root cause.
 panicstevenson
on 8 Jul 2018
panicstevenson
on 8 Jul 2018
We're also facing this issue, but with the default REPLICA scheduling strategy: sometimes our awsvpc-enabled tasks are not deregistered correctly from the target group (with target type ip). ECS correctly scales the service to the desired count but we accumulate stale targets which fail health checks (because the target IP no longer exists) over time. We're not yet using Fargate, so I think the issue is independent of that.
 IngmarStein
on 18 Jul 2018
IngmarStein
on 18 Jul 2018
@panicstevenson @IngmarStein I have let our service team know about this issue, but it would help a lot if you could provide the information required by @yunhee-l above.
Thanks,
Peng
 richardpen
on 25 Jul 2018
richardpen
on 25 Jul 2018
We ran into this issue this week running on FARGATE 1.2.0. It turned out to be pretty bad for us, because we had two different ECS Services sharing the same subnets, and they happened to have the same health check URL, so we ended up with targets from one ECS service registered and healthy in another services Target Group.
Our work-around was to make sure each service has a unique health check URL, but I'd love to know if there have been any updates from the ECS team regarding this issue?
If you need any more details I'm happy to provide what I can.
 ryanschneider
on 19 Oct 2018
ryanschneider
on 19 Oct 2018
I ended up putting together a lambda function to go through and deregister all of the unhealthy targets, not sure if it will help anyone here as a temporary workaround but I'll share for those watching.
from boto3 import client as aws
from pprint import pprint as pp
from re import search
# This crawls through target groups looking for unhealthy targets and deregisters them when it finds one.
# This exists because there is a bug in the target group health checks where if a container exits
# after failing a health check it is not deregistered in the same manner as it it had failed
# a ALB health check.
#
# Should be executed from a cloudwatch event scheduled for every 5 minutes.
def lambda_handler(event, context):
for tg in aws('elbv2').describe_target_groups()['TargetGroups']:
if is_match(tg['TargetGroupArn']):
targets = has_unhealthy(tg['TargetGroupArn'])
if len(targets) > 0:
pp(aws('elbv2').deregister_targets(TargetGroupArn=tg['TargetGroupArn'], Targets=targets))
return
# expects ARN for target group, returns boolean if matches a list of service names.
def is_match(arn):
# hard-coding this, it should be passed as variables but this is just a hack anyways ...
services = ["put-your-service-names-here", "as-an-array"]
for s in services:
if search('targetgroup/\w+-' + s, arn):
return True
return False
# expects ARN for target group, returns list of target Id
def has_unhealthy(arn):
targets = []
for target in aws('elbv2').describe_target_health(TargetGroupArn=arn)['TargetHealthDescriptions']:
if target['TargetHealth']['State'] == 'unhealthy':
targets.append({'Id': target['Target']['Id']})
return targets
Note that the service names to search are hard-coded in the script, bad practice I know but it was just a temporary hack while we moved off of fargate anyways.
 tagct
on 22 Oct 2018
tagct
on 22 Oct 2018
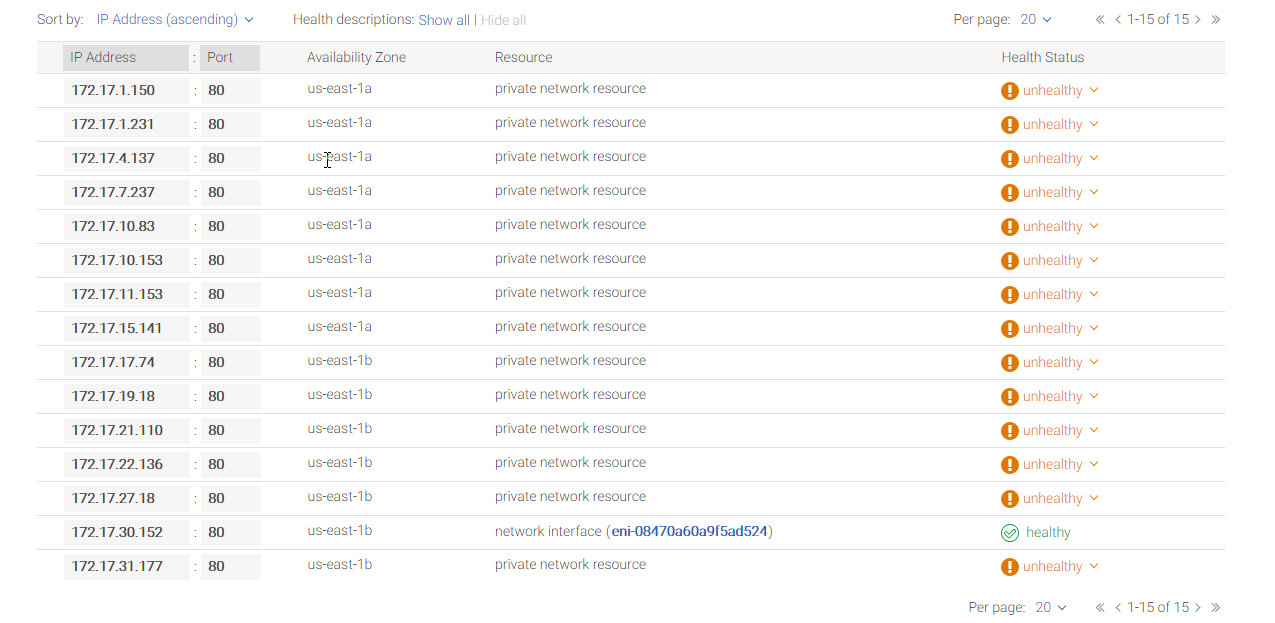
We're experiencing the same issue. Seem to be getting an accumulation of targets that aren't being deregistered.
 ryanpagel
on 21 Nov 2018
ryanpagel
on 21 Nov 2018
Any updates? We are experiencing the same issue.
 nikskiz
on 11 Jan 2019
nikskiz
on 11 Jan 2019
We are also experiencing this issue today. :(
 jemaltieri
on 7 Feb 2019
jemaltieri
on 7 Feb 2019
To enable our dev team to better investigate this, could you please send the following information to me at: sharanyd (at) amazon.com
- Account ID
- Task definition ID
- Container instance ID and region
- Agent log (when task is stopping)
Thank you.
 sharanyad
on 7 Feb 2019
sharanyad
on 7 Feb 2019
There was an issue to deregister target properly for ip type target group in some circumstances. It has been fixed.
@ryanpagel @nikskiz @jemaltieri
Are you still experiencing this issue? Feel free to send information to libruce (at) amazon.com for us to investigate. This is not an ECS agent issue, only (Region + Account ID + Cluster + ECS Service ) information required.
Thanks
 wbingli
on 20 Apr 2019
wbingli
on 20 Apr 2019
There was an issue to deregister target properly for
iptype target group in some circumstances. It has been fixed.@ryanpagel @nikskiz @jemaltieri
Are you still experiencing this issue? Feel free to send information to libruce (at) amazon.com for us to investigate. This is not an ECS agent issue, only (Region + Account ID + Cluster + ECS Service ) information required.
Thanks
I will keep an eye out for it...
nikskiz
on 22 Apr 2019
@wbingli I haven't noticed this issue for quite a while. Seems to be resolved from what I can tell.
ryanpagel
on 22 Apr 2019
This is definitely still an issue. Yesterday I removed a dozen unhealthy hosts from a single target group. Sending an email to sharanyd with details...
 MinskyBA
on 4 Jun 2019
MinskyBA
on 4 Jun 2019
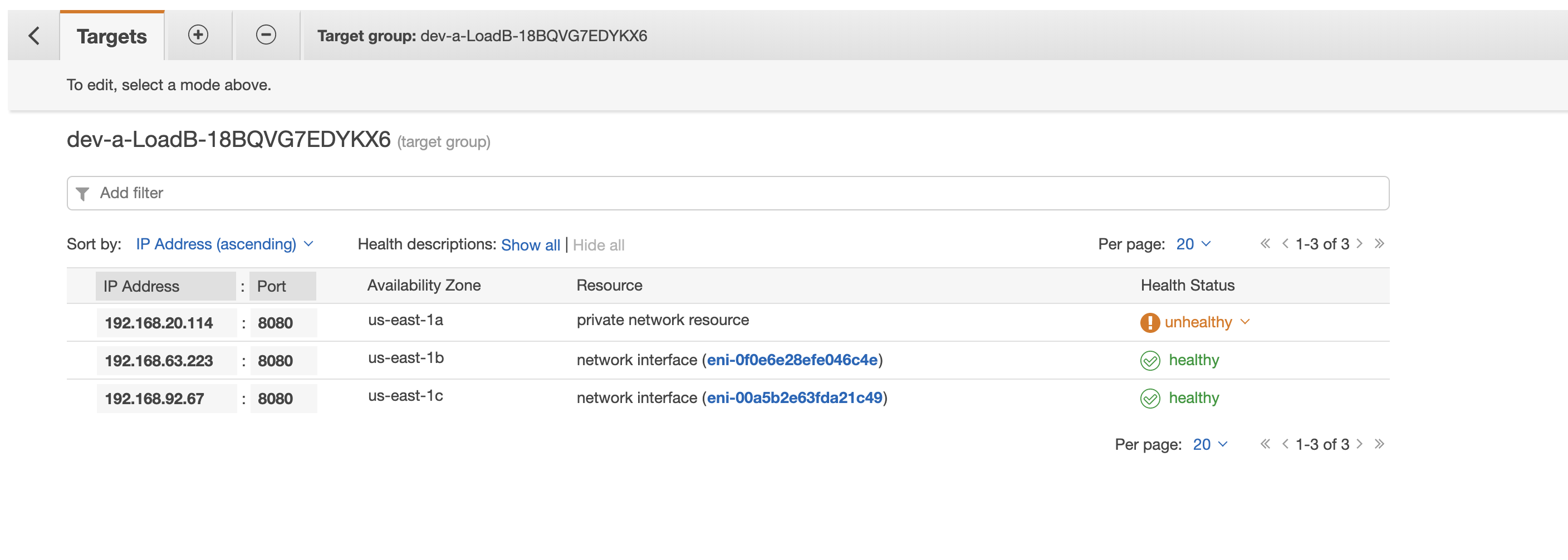
Just adding to this issue to confirm I'm still seeing this issue.
 Mavus
on 22 Aug 2019
Mavus
on 22 Aug 2019
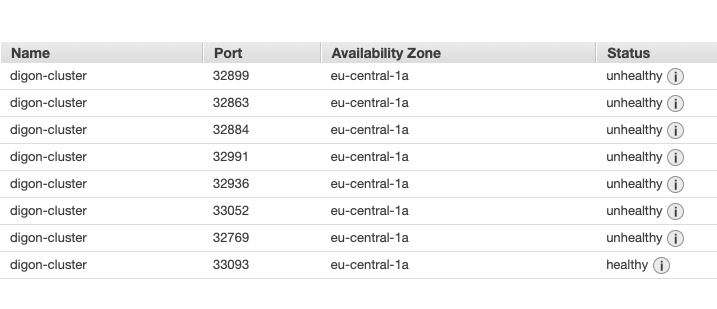
HI, we have the same problem: agent version: 1.30
 Axent96
on 27 Aug 2019
Axent96
on 27 Aug 2019
This also affects containers running in fargate. I have seen a handful of times across different services of ours, all running in fargate.
 matthewduren
on 4 Oct 2019
matthewduren
on 4 Oct 2019
Confirming that this is still an issue with containers in Fargate
 woody-klaviyo
on 11 Nov 2019
woody-klaviyo
on 11 Nov 2019
This also affects containers running in fargate. I have seen a handful of times across different services of ours, all running in fargate.
Same here, Fargate. Very disturbing behaviour. Discovered this from VPC Flow Logs.
 iniinikoski
on 24 Jan 2020
iniinikoski
on 24 Jan 2020
For the record, AWS Support recommended that we map each service to a different subnet mask. This alleviates the vast majority of bad routing that occurs with this issue. It's not an ideal solution, but it is a relatively easy one to implement for anyone who is feeling pain from this.
woody-klaviyo
on 24 Jan 2020
We have a cluster with over 1200 services. I don't think support is going to be happy with our 1200 subnets limit increase.
Further, the bad routing is only part of the problem. The elb waiters fail to go healthy, causing automated deploys to fail.
matthewduren
on 24 Jan 2020
@woody-klaviyo We got the same recommendation. However, that would mean approximately 10000 subnets all manually created, assigned in Cloud formation and maintained. Yeah, no. Maybe if you only got 1-10 services that would be somewhat feasible, but I think most people impacted by this issue here are large business companies. Which is also the reason that it's astonishing that this issue is still open.
 L3tum
on 24 Jan 2020
L3tum
on 24 Jan 2020
Yeah I totally agree, just spreading word for something that does work, but is annoying to implement. The fact that this bug is so long-running is very frustrating. On our call, they assured us that it would be solved within a month or two, but that time-frame is already out the window.
woody-klaviyo
on 24 Jan 2020
@woody-klaviyo I don't want to move too offtopic, so I'll just tag you and say this: The person responsible at my company assured me to give me an update a week later...that was 4 months ago.
L3tum
on 24 Jan 2020
Related issues
 pauldougan
·
3Comments
pauldougan
·
3Comments
 tabern
·
3Comments
tabern
·
3Comments
 clareliguori
·
3Comments
clareliguori
·
3Comments
 mineiro
·
3Comments
tabern
·
3Comments
mineiro
·
3Comments
tabern
·
3Comments
Most helpful comment
Yeah I totally agree, just spreading word for something that does work, but is annoying to implement. The fact that this bug is so long-running is very frustrating. On our call, they assured us that it would be solved within a month or two, but that time-frame is already out the window.