Containers-roadmap: [Rebalancing] Smarter allocation of ECS resources
@euank
Doesn't seem like ECS rebalances tasks to allocate resources more effectively. For example, if I have task A and task B running on different cluster hosts, and try to deploy task C, I'll get a resource error, and task C will fail to deploy. However, if ECS rebalanced tasks A and B to run on the same box, there would be enough resources to deploy task C.
This comes up pretty often for us- with the current placement of tasks, we run of resources and cannot deploy/achieve 100% utilization of our cluster hosts, because things are balanced inefficiently. Max, we're probably getting 75% utilization, and 25% is going to waste.
 abby-fuller
abby-fuller
All 97 comments
Thanks for the report Abby. Yes, this is correct our scheduler does not currently re-balance tasks across an existing cluster. This is something that is on our roadmap.
 simplycloud
on 15 Oct 2015
simplycloud
on 15 Oct 2015
+1
This is a great example of the issue at its worst:

Due to extremely poor balancing of the tasks by the scheduler I'm blocked from deploying a new revision of the hyperspace task. The only instance that has spare capacity for a new hyperspace task is already running a hyperspace task so the ECS agent just gives up.
The ideal thing to do would be for the ECS agent to automatically rebalance tasks from the first instance onto the second instance which has tons of extra resources, so that a new hyperspace could be placed onto the first instance.
Right now the only way to get ECS to operate smoothly is to allocate tons of extra server capacity so that there is always a huge margin of extra capacity for deploying new task definitions. I'd expect to need maybe say 10%-15% extra spare capacity, but it seems that things only work properly if there is nearly 50% spare capacity available.
 nathanpeck
on 15 Oct 2015
nathanpeck
on 15 Oct 2015
During a restart of services too, the same occurs.

This needs me to run a spare instance, just for proper re-scheduling during restarts.
Bigger Problem
This issue occurs on a large scale, which is very problematic. If I have 10 tasks with 1 vCPU and 1 task with 2vCPU and 10 t2.mediums (2 vCPU), the 10 smaller tasks get launched on each of the instance and 2vCPU gets not resource left (rare occurrence though), but hitting this 2 to 3 times a month

Please prioritize this issue.
Thanks.
 skarungan
on 13 Jun 2016
skarungan
on 13 Jun 2016
338 is requesting the same feature
Edit: Not the same feature, misunderstood sorry!
 djenriquez
on 12 Jul 2016
djenriquez
on 12 Jul 2016
@skarungan @djenriquez ECS has added a new feature that kind of fixed this for us. You can specify a "minimum percentage" that will allow the agent to shut down old task definitions before starting new task definitions. So let's say you are running 6 of the old task definition and you want to deploy 6 of the new task definition but there isn't enough resources to add even 1 more copy of the new task defintion. If you have min percentage at 50% then ECS agent will kill 3 of the old tasks and start 3 of the new tasks, then once those 3 new tasks are started it kills off the remaining 3 old tasks and starts 3 more new tasks.
nathanpeck
on 13 Jul 2016
Ah @nathanpeck, I completely misunderstood the feature request here. Though what you describe is very helpful, I was actually looking for a "rebalance" feature, where as new instances come up in the cluster, ECS will reevaluate its distribution of tasks to run tasks on them.
djenriquez
on 13 Jul 2016
@simplycloud where are we at with this FR? ta.
 ghost
on 10 Oct 2016
ghost
on 10 Oct 2016
+1 for something smarter from ECS on this.
We're currently using Convox to manage our ECS clusters, and our racks are currently running on t2 instances - we've noticed that tasks seem to cluster on a couple of instances, while others are pretty much empty. With the t2's in particular, this means that some instances are chewing through their CPU credits while others are gaining.
Smarter balancing of tasks would help make this more feasible until we actually outgrow the t2 class.
 mwarkentin
on 28 Oct 2016
mwarkentin
on 28 Oct 2016
@simplycloud can you please respond? This is biting people (myself included). It's been over a year since you mentioned this was on the road map. Where was it on the 15 Oct 2015 and where is it now?
 jfstephe
on 18 Nov 2016
jfstephe
on 18 Nov 2016
@mwarkentin I would not use convox with any of the t2 classes, there is a build agent that builds the images that will eat all your CPU credits on deployments.
 matthewford
on 21 Nov 2016
matthewford
on 21 Nov 2016
@mwarkentin ignore me I thought I was commenting on a convox issue.
matthewford
on 21 Nov 2016
Hi all, just hoping for an update on the rebalance feature.
Ideally, this feature should handle something similar to Nomad's System jobs, where it is just an event that ECS is listening to and can perform actions against.
In this specific case, the actions it would perform would be a redeployment of the task definition such that it ensures the proper task placement strategy is effect.
djenriquez
on 13 Jan 2017
+1
 thomask
on 1 Apr 2017
thomask
on 1 Apr 2017
+1 rebalancing wih the include of credit balance would be good.
I would already be happy if an EC2 container instance would be drained when
it has low credit balance.
Even a weight feature in the elastic-application-load-balancer that includes the credit balance of the target would help a lot.
Cant find any easy method to reduce the load of a throttled ec2 instance that hosts a normal wep-app task (wordpress).
 Zetanova
on 5 Apr 2017
Zetanova
on 5 Apr 2017
@samuelkarp @aaithal or others:
Any plans to add this feature or something similar?
 kevindiamond
on 12 Jun 2017
kevindiamond
on 12 Jun 2017
with autoscaling, i have the same problem...

 debu99
on 6 Jul 2017
debu99
on 6 Jul 2017
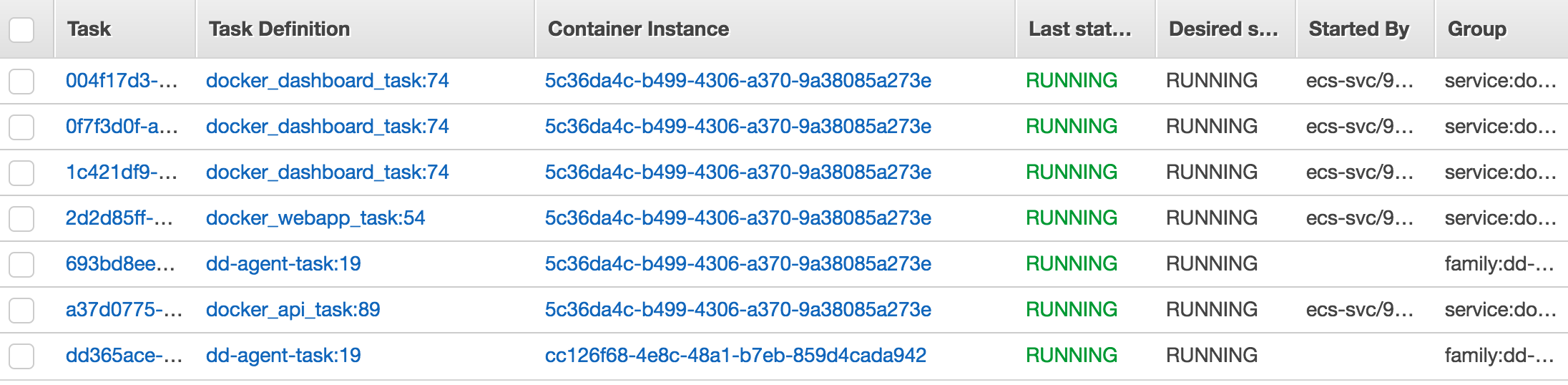
@debu99 Sorry its not clear to me, what is the issue in your screenshots?
nathanpeck
on 6 Jul 2017
@nathanpeck I think that 6/7 tasks are running on the same instance (and the one that's not looks like a daemon that runs on all instances).
mwarkentin
on 6 Jul 2017
+1 on rebalancing when the cluster grows
 devshorts
on 7 Aug 2017
devshorts
on 7 Aug 2017
My two cents...
I'd imagine that it'd be unwanted behavior to include by default, so it should be something that the user should opt-in to on a per-service basis -- if you're running a web app behind a load balancer or anything ephemeral, it's relatively safe to "move" these.
(By "move", I mean start a new instance on the new container instance, without the count of tasks in the RUNNING/PENDING state exceeding the maximum percent; and once it's running, kill the old task)
However, the rebalancing should not take the limited CPU credit of throttled instance types (tX) into account. To effectively do that, you'd need to generate a large volume of CloudWatch statistics gathering requests and/or estimate the rate of depletion which will push up your overall bill. By how much? I'm not sure, but it will start to chip away at the cost advantage you're intended to have by using the tX instance types.
You're better off using non-throttled instances for ECS clusters, or you'll need to roll your own logic/framework for managing CPU credit balances. (One can argue this is the standard "buy-versus-build" argument)
As far as I'm aware, throttled instance types are meant for burstable workloads that can be terminated and restarted without incurring pain or major service degradation. Your containers may be considered a burstable workload, but the ECS agent and Docker daemon are not -- if you starve these two of CPU, your entire ECS instance may become unusable/invisible to the ECS scheduler.
Lastly, this would not necessarily something that would live within the ECS agent, but instead need to be a centrally coordinated service within the larger EC2 Container Service.
Otherwise, the sole complexity cost of having ECS agents be aware of other ECS agents (agent-to-agent discovery, heartbeats to make sure the other ECS agent hasn't died, communication and coordination patterns to request-accept-send tasks, limiting broadcast traffic to not propagate beyond a single cluster, and many other distributed computing concerns) would make this feature DOA before you even get to solving the problem of how to properly rebalance.
 oogali
on 10 Aug 2017
oogali
on 10 Aug 2017
I would already be happy if an EC2 container instance would be drained when
it has a low credit balance and activated on a specific higher limit.
The autoscale feature could manage the rest to add more EC2 instances.
The main problem is just that if an tX instance is out of credits,
it is in ecs online and healthy node/container
but in real it is a "unhealthy" node that cant surf all services
Zetanova
on 10 Aug 2017
+1 for rebalancing
 darrylb-github
on 15 Aug 2017
darrylb-github
on 15 Aug 2017
Wouldn't using 'binpack' task placement strategy help with rebalancing in the scenarios described above. It's described in more detail here:
http://docs.aws.amazon.com/AmazonECS/latest/developerguide/task-placement-strategies.html
binpack makes sure that the instance is utilized to the maximum before placing the task on a fresh node. I understand that there will be edge cases where task placement will still not be as desired, but I think this will solve the majority of problems for you.
 amitsaxena
on 22 Aug 2017
amitsaxena
on 22 Aug 2017
@amitsaxena I'm not sure that solves the problem at all. Binpack isn't HA since it will try and pack as many items on the box as possible.
From the docs:
This minimizes the number of instances in use
The issue in this ticket is that you want to have even _spread_. So as you add more nodes to the cluster you want to maximize HA by moving tasks off of nodes that are more heavily loaded onto newer nodes that are less heavy loaded. This way each node is utilized, vs having some nodes that are running at near peak and other nodes that may have zero or very few services. This is the situation we run into now, we have nodes that are running at around 75% capacity and we'd like to make sure they have breathing room to bursts. If we add a new node to the cluster we now have a node that is doing _nothing_ vs having nodes that are at our peak run less hot and have more headroom.
devshorts
on 22 Aug 2017
Anyone working on this? It's currently the second highest rated FR. I'm hesitant to even use ECS due to this.
 thomasbiddle
on 30 Nov 2017
thomasbiddle
on 30 Nov 2017
I wonder if the new EKS service makes this less of an issue, or at least provides an option (or explanation) for the lack of progress on this issue? Some guidance from AWS would be great!
@simplycloud @samuelkarp @aaithal @anyone with some information! Please respond ( - friendly, not demanding).
jfstephe
on 30 Nov 2017
Watching the reinvent keynote and @abby-fuller just came on.. then opened this issue because of a notification.. hah!
mwarkentin
on 30 Nov 2017
+1 for rebalancing
 briziomusic
on 16 Feb 2018
briziomusic
on 16 Feb 2018
@devshorts I sort of get your point about having an even spread, but having binpack placement strategy along with Multi AZ is possible as well. Something similar to:
"placementStrategy": [
{
"field": "attribute:ecs.availability-zone",
"type": "spread”
},
{
"field": "memory",
"type": "binpack"
}
]
So I don't think HA is a problem with binpack strategy, and it can be effectively used to have maximum utilization of instances before spawning new ones. We use it effectively in production!
PS: Sorry for the late reply. I somehow missed your original comment :)
amitsaxena
on 16 Feb 2018
+1 on rebalancing when the cluster grows.
 pparth
on 27 Feb 2018
pparth
on 27 Feb 2018
If there was a way to drain&stop task, we could implement this in Lambda but there is no way to do that without hacking every health check.
 soukicz
on 27 Feb 2018
soukicz
on 27 Feb 2018
For me the biggest issue has been when the VM is removed from a cluster (say for a 2 VM cluster) and then re-added (e.g. simulating an AZ outage), i no longer get real HA if i spread just across 2 AZs, because all the tasks are now on one instance in one AZ.
 azaytsev-csr
on 28 Feb 2018
azaytsev-csr
on 28 Feb 2018
+1
 lodotek
on 16 Mar 2018
lodotek
on 16 Mar 2018
Any updates on this?
 relu
on 3 May 2018
relu
on 3 May 2018
 PaulLiang1
on 25 Jun 2018
PaulLiang1
on 25 Jun 2018
@PaulLiang1 Good find, and a neat trick with Lambda.
For our friends at AWS:
I agree with the overall sentiment of this thread that at least a basic version of rebalancing ought to be built-in. Such functionality goes hand-in-hand with other AWS services like auto scaling groups where I have container instances coming and going entirely on their own through policies.
Writing Lambdas on an event stream should be for when we need a special scaling behavior for unique application or situation.
Auto rebalancing when registered instances change is something everybody can use, and shouldn't be a bespoke addition to the configuration.
 mrapczynski
on 19 Jul 2018
mrapczynski
on 19 Jul 2018
this might help
https://github.com/aws-samples/ecs-refarch-task-rebalancing#rebalance
@mrapczynski @PaulLiang1 The above lambda can be made way simpler by just forcing a new deployment of the ECS service without creating a new task definition.
But I agree, It would be cool if AWS did it automagically! Hoping they do it just like they introduced DAEMON ECS services :)
 Puneeth-n
on 19 Jul 2018
Puneeth-n
on 19 Jul 2018
Any updates on this feature?
 carlislk
on 25 Jul 2018
carlislk
on 25 Jul 2018
+1
 ricardosllm
on 27 Jul 2018
ricardosllm
on 27 Jul 2018
+1
 psyhomb
on 7 Aug 2018
psyhomb
on 7 Aug 2018
+1
 momcilovic
on 7 Aug 2018
momcilovic
on 7 Aug 2018
+1
 RealCoderiver
on 8 Aug 2018
RealCoderiver
on 8 Aug 2018
Thanks for the report Abby. Yes, this is correct our scheduler does not currently re-balance tasks across an existing cluster. This is something that is on our roadmap.
@simplycloud this is something that was on the ECS roadmap 3 years ago, what's the status 3 years later?
I would also add that it would be absolutely more fair admitting that we all should start using EKS and that this or similar features are never going to be implemented nor available in ECS.
psyhomb
on 9 Aug 2018
@psyhomb are you saying EKS is able to re-balance pods across the cluster?
 ffjia
on 9 Aug 2018
ffjia
on 9 Aug 2018
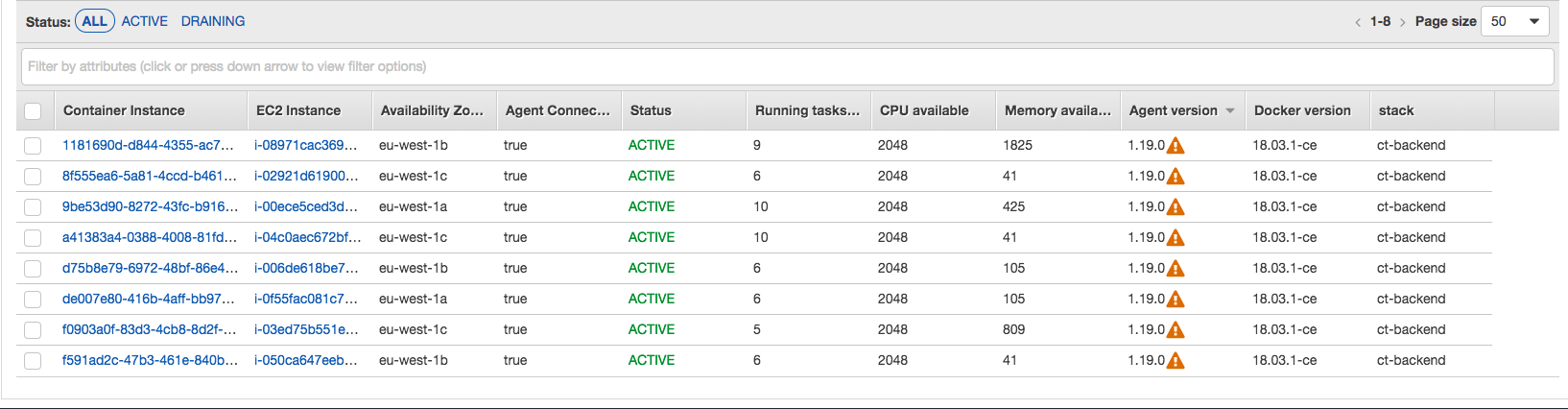
AZ spread && binpack (In that order) seems to do the trick for me. There are no wastage of resources (unless you provisioned a bit of headroom for scaling)
Puneeth-n
on 9 Aug 2018
+1
This would be super helpful. We are having issues with ECS scheduling tasks on pegged instances while ignoring newly created instances.
 aric49
on 13 Aug 2018
aric49
on 13 Aug 2018
Same issue here, where certain instances are bogged down with tasks while others are empty. Could you provide a status update on this feature?
 francoisvdv
on 11 Sep 2018
francoisvdv
on 11 Sep 2018
+1
 dsouzajude
on 14 Sep 2018
dsouzajude
on 14 Sep 2018
+1
 leonfs
on 8 Oct 2018
leonfs
on 8 Oct 2018
+1 a much needed feature.
 deepsit19
on 9 Oct 2018
deepsit19
on 9 Oct 2018
For some of the use-cases mentioned above, in particular rebalancing tasks across container instances in a cluster, and also rebalancing tasks when the cluster (i.e. the autoscaling group) scales up, this has very much helped me a lot and is a much simpler solution.
https://github.com/maginetv/ecs-task-balancer
Would love your feedback on this.
dsouzajude
on 16 Oct 2018
With EKS and all, is this still a serious feature? Rebalancing is basically a requirement when resizing/downsizing a cluster.
 withernet
on 19 Oct 2018
withernet
on 19 Oct 2018
Thanks everyone for the feedback on this issue. I wanted to let you know that we on the ECS team are aware of this issue, and that it is under active consideration. +1's and additional details on use cases are always appreciated and will help inform our work moving forward.
 coultn
on 31 Oct 2018
coultn
on 31 Oct 2018
@coultn is there anything new on this issue?
Reminder: reported on Oct 15, 2015
psyhomb
on 21 Nov 2018
@psyhomb We are looking at potential solutions. I cannot share more details at this time, but please be assured that we are actively working on it.
coultn
on 21 Nov 2018
+1 for the sake of re:Invent!
 plektra
on 27 Nov 2018
plektra
on 27 Nov 2018
+1 on rebalancing
 matthewjohnson2821
on 27 Nov 2018
matthewjohnson2821
on 27 Nov 2018
I am trying to setup what is mentioned in this blog post: https://aws.amazon.com/blogs/compute/how-to-automate-container-instance-draining-in-amazon-ecs/
I am facing issue with the re-balancing of the containers. I have an ECS cluster with 2 instances and service with 2 containers. The task placement strategy I am using AZ spread. When we deploy or update the service , the containers are placed across AZs but when we are updating the cluster image and change instances, the containers are placed on 1 instance within the same AZ.
 ajain04
on 30 Nov 2018
ajain04
on 30 Nov 2018
@coultn
We are looking at potential solutions. I cannot share more details at this time, but please be assured that we are actively working on it.
If you're actively working on it, like you said, I would like to know why this issue (feature) is still on the Proposed list then?
https://github.com/aws/containers-roadmap/labels/Proposed
it's not even on the roadmap yet if I see it correctly
psyhomb
on 13 Dec 2018
@psyhomb we are looking closely at this problem, and trying to determine a solution that makes the most sense. As you can see even from this comment thread, there are many different aspects to the problem and potential solutions. I'm interested to hear what is most important to you - what specific problem are you trying to solve, and what would you need to see in a solution?
coultn
on 13 Dec 2018
Our re-balancing use case is around managing CPU spikes. We are hosting many different public web sites on a cluster, and bin-packing them to keep the instance utilization high. But we want to allow cpu usage to spike beyond the reservation values. Its easy to make the asg add more instances, but without a re-balance it doesn't get you anywhere.
 jeichorn
on 14 Dec 2018
jeichorn
on 14 Dec 2018
@coultn given that more or less Amazon is taking almost everything from the OSS please revisit some of the OSS projects, like for example ClusterLabs' pacemaker, and maybe you will find potential solution for the above explained issue, instead of asking generic questions!
psyhomb
on 14 Dec 2018
@coultn since you're asking, the problem we are running into is two fold:
- If we increase the size of the cluster, then nodes for hours can be sitting with no tasks.
- If we decrease the size of the cluster, then the scheduler seems to favor specific nodes for dumping tasks on.
So, with regards to solutions:
- To address the first problem; I'd imagine a better solution would be to check which nodes in the cluster at an interval are "unbalanced"; and then move tasks to those nodes to balance the cluster.
- To address the second problem; instead of "dumping" tasks on a few target nodes when a cluster shrinks, then some kind of check should be done before task placement to make sure one node isnt just getting overloaded with new tasks.
Another option is to simply allow for manual movement of tasks throughout the cluster...
withernet
on 14 Dec 2018
If you have multiple ECS services that are autoscaling through the day you might want to re-pack the containers and and scale-in the hosts to remove some excess capacity.
But it should to be smart about which container host it should terminate for a scale-in.. you'd want to keep zones balanced and terminate the host with the least amount of resources reserved.. otherwise it's going to have to relocate many containers.
Currently the ASG isn't smart about which host it terminates on scale-in and usually kills the oldest host, which will often be the one with the most running containers.
 jamiegs
on 19 Dec 2018
jamiegs
on 19 Dec 2018
moving this over to the container roadmap, since it's ultimately a set of feature requests, and not an ecs-agent bug.
abby-fuller
on 10 Jan 2019
+1.
I still run out of enough CPU or Memory to place a task, even though the whole cluster is still having 2 or 3 instances worth CPU and Memory free. Currently, I have to scale down to rebalance tasks manually and then scale up to allow recycling of big tasks.
 vimmis
on 3 Apr 2019
vimmis
on 3 Apr 2019
If there isn't a rebalancing tool for ECS right now you could consider other AWS containers options:
Fargate, then node management/packing isn't your problem (for a price admittedly) 😄
EKS where you have a lot more scheduling tools, e.g. you can deploy the descheduler to repack/reschedule workloads to avoid under/over utlitised nodes, and the cluster-autoscaler which will manage the ASG size in a workload-aware manner, picking the best nodes to remove for scale-in, and reschedule work-loads off low utilization nodes to enable scale-in, or pre-scale-up to ensure reserve capacity for fast service scale-up. You can combine those tools with Pod Disruption Budgets to ensure replicas don't get rescheduled too frequently or too quickly. And both soft and hard CPU/RAM resource requirements at both the replica and application (namespace) level, enabling strict reservation or sharing CPU/RAM between burstable workloads. You generally just have a lot more workload management tools and options with EKS.
For ECS, perhaps you need a service like the Kubernetes descheduler to facilitate repacking?
 whereisaaron
on 3 Apr 2019
whereisaaron
on 3 Apr 2019
For ECS, perhaps you need a service like the Kubernetes descheduler to facilitate repacking?
@whereisaaron, yes at least for my use case.
vimmis
on 3 Apr 2019
Any updates on this front?
 benyanke
on 5 Apr 2019
benyanke
on 5 Apr 2019
+1 for rebalancing. We currently us AZ spread for placement, but we have automated autoscaling with with rolling our own ami to keep our hosts as up to date as possible. When we drain nodes from the cluster, tasks have to be moved to other nodes, and when autoscaling brings up new nodes, those nodes will sit idle until either another node is removed or all the services have been redployed over time.
 mdc-drivin
on 9 May 2019
mdc-drivin
on 9 May 2019
WTF (Why The Face) AWS! It's coming up to 4 years. 4 ducking years since this issue was first raised. The situation today is even worse than 4 years ago.
Not everyone desperately waiting on this issue is actively commenting and begging in the comments. A lot of people are probably like me, waiting patiently on the sidelines hoping AWS would eventually come to their senses and fix this issue.
We used to be able to work around this issue ourselves by starting up a new set of container hosts. (Which you guys confusingly named "container instances"). By gradually draining and deregistering the old set of 3x container hosts, our 400x or so docker containers would gradually get distributed evenly over the new set of 3x container hosts. But somehow, instead of fixing this issue, you guys have recently managed to break this workaround.
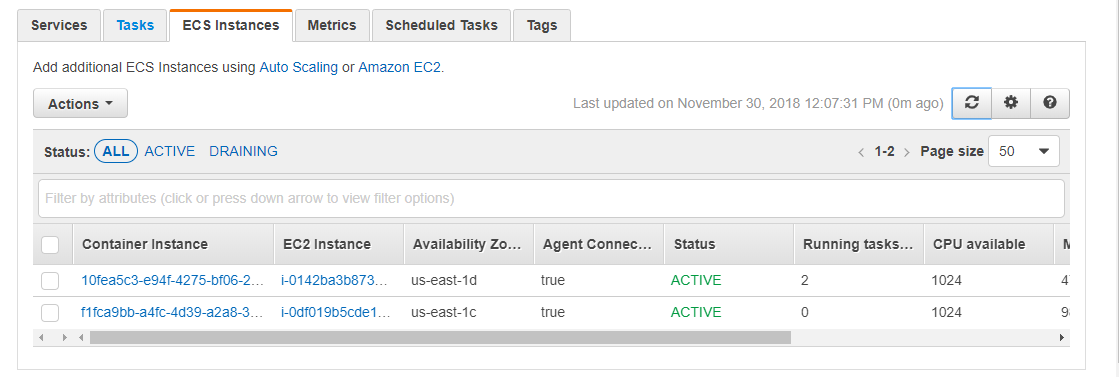
Just look at this screenshot:

Look at it! This is the type of sheet I have to deal with now. Through deregistering a container host that was previously struggling to run 190x or so containers, out of the 3x new container hosts, one got allocated 40x or so tasks, one got allocated 60x or so tasks, the last one got allocated 0. Ducking zero!
The only reason I'm changing out the container hosts for new ones is because the 3x old container hosts had unequal distribution and errors were occurring. One was struggling with memory and started to page at 190x or so containers. While one was relatively idle with only 110x or so containers. With all the traffic load balanced over containers in all 3x containers hosts, the net effect is errors.
Add the ducking rebalancing / redistribution feature. You're making us all look like idiots in front of our employers. We fought for AWS to be adopted over every other cloud offering. AWS used to be the innovators. What happened?
Microsoft Azure is fighting hard for our business from the top down. I used to have a lot of technological reasons to fight for AWS against Azure. With issues such as this unfixed for 4 ducking years, I'm going to look like a clown if I continue arguing to stay with AWS.
Wake up.
 asdf01
on 23 May 2019
asdf01
on 23 May 2019
What a waste of time:
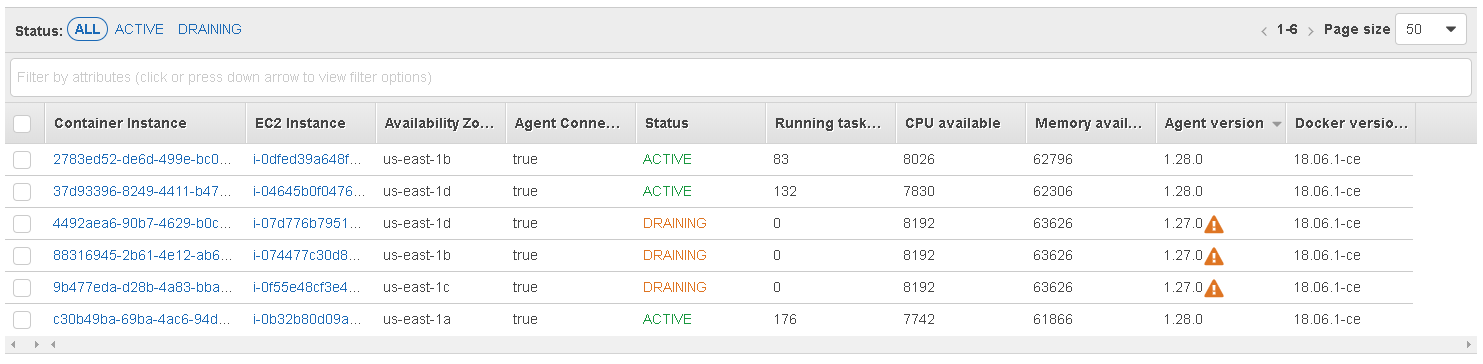
One container host got allocated 176 containers, while another got allocated with less than half at 83. Task Placement Strategy: AZ spread my buttER.
asdf01
on 23 May 2019
This is a massive deal and im really surprised to see that ECS has no intelligent balancing with container placement on instances.
+1 for this it would increase the value of ECS hugely.
 Zebirdman
on 29 May 2019
Zebirdman
on 29 May 2019
Update for anyone who lands here, i used the lambda function shown here https://github.com/aws-samples/ecs-refarch-task-rebalancing and was able to get some pretty reasonable rebalancing across our instances.
You can also modify the code so that instead of it creating new task definitions it uses the force-update-true setting to simply re pull the existing versions. For now ive found that this is enough for our needs but hopefully in future this will be a built in feature without needing external monitors and lambda functions to trigger.
Zebirdman
on 6 Jun 2019
@Zebirdman according to https://github.com/aws-samples/ecs-refarch-task-rebalancing/issues/2 it works only with up to 10 services, making it a non-solution really : /
@coultn
Issues/limitations I have encountered so far:
- Agents disconnecting due to OOM. This could happen. Problem is that the cluster has almost no way to tackle this and recover. As long as the agent is permanently disconnected, the scheduler doesn't kill it or try to help it recover in any way. This renders all tasks already running there invisible to the scheduler. There might be still running, there might be pending tasks, but there is no way for the scheduler to know.
- Scaling out with a scaling policy in the auto scaling group. Sure, it will spawn a new node, but that new node won't receive any existing tasks that already run in some other instance, thus rendering it kind of pointless.
- Assuming a node running hot at close to 100% CPU usage, it could be really helpful to have a mechanism to detect which task has an abnormally high CPUUtilization, in order to stop it and place it in another node that could accommodate its recent high utilization.
Any plan currently to address the above issues?
 dimisjim
on 6 Jun 2019
dimisjim
on 6 Jun 2019
I'm in the middle of an ECS rollout myself and just ran into this. Are there any plans to implement appropriate scaling policies for ASG based ECS deployments?
 cmeisinger
on 13 Jun 2019
cmeisinger
on 13 Jun 2019
@coultn
Issues/limitations I have encountered so far:
1. Agents disconnecting due to OOM. This could happen. Problem is that the cluster has almost no way to tackle this and recover. As long as the agent is permanently disconnected, the scheduler doesn't kill it or try to help it recover in any way. This renders all tasks already running there invisible to the scheduler. There might be still running, there might be pending tasks, but there is no way for the scheduler to know. 2. Scaling out with a scaling policy in the auto scaling group. Sure, it will spawn a new node, but that new node won't receive any existing tasks that already run in some other instance, thus rendering it kind of pointless. 3. Assuming a node running hot at close to 100% CPU usage, it could be really helpful to have a mechanism to detect which task has an abnormally high CPUUtilization, in order to stop it and place it in another node that could accommodate its recent high utilization.Any plan currently to address the above issues?
Thanks for your detailed feedback! These really are three different issues. The first one has to do with agent health generally, but not specifically rebalancing. We are always working to make the agent more reliable and robust.
Regarding the second issue: this has to do with the fact that cluster autoscaling today is usually reactive, meaning it only scales in response to containers that are already running. We are planning on some improvements to cluster autoscaling (https://github.com/aws/containers-roadmap/issues/76) that will mitigate this, by scaling the cluster based on the containers you want to run, not just the containers that are already running. This means that you will be more likely to place new tasks on newly-added instances. Additionally, as the status of this issue indicates, we are researching how to rebalance services to that have spread placement strategies defined so that the service can be spread evenly in the manner intended even if it is not currently evenly spread.
The third issue is what I would call "cluster heat management." This would be a new capability for ECS that goes beyond just placement strategies. The problem is fairly complicated, because there may well be multiple tasks and multiple instances with high utilization, and those utilizations may be changing rapidly. Optimal solutions to this type of problem are computationally infeasible (they boil down to problems know as "binpacking" or "knapsack" problems, which are known to be computationally infeasible to solve optimally). Thus, solutions to such problems usually rely on approximations and heuristics.
coultn
on 13 Jun 2019
@dimisjim i wasn't aware of that but the lambda function is using the generic describe services API call. It would be trivial to change this to individual service calls based on a list you pass to it which should easily get around this. Of course im not aware of how many services people might be running, based on what i do it doesn't seem like a serious inconvienience to do this.
Zebirdman
on 17 Jun 2019
+1 rebalancing
 fpuntoni
on 24 Jul 2019
fpuntoni
on 24 Jul 2019
♫Welcome to the jungle, it gets worse here every day♫
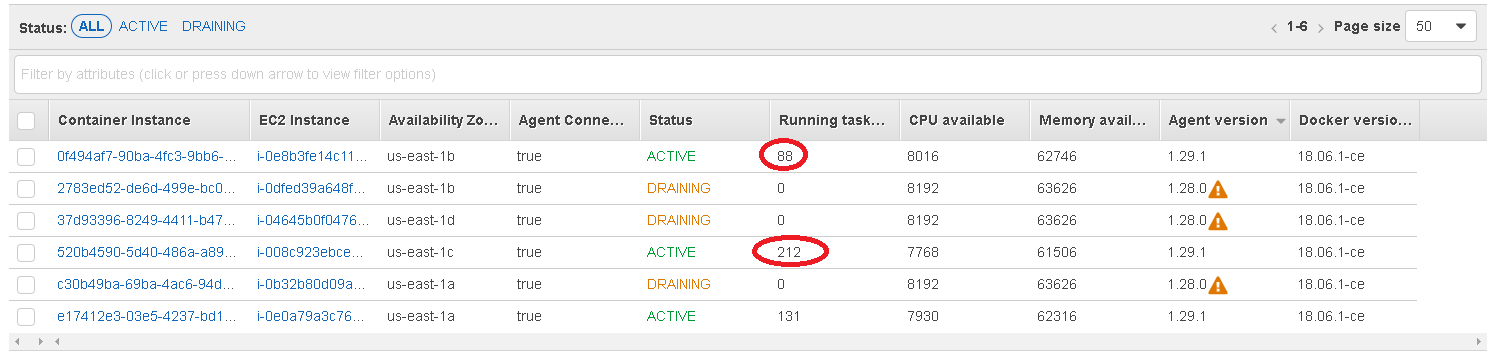
asdf01
on 2 Aug 2019
♫Welcome to the jungle, it gets worse here every day♫
Hi, can you tell us more about the specifics? Are these services or one-off tasks? What placement strategy are you using?
Thanks
coultn
on 2 Aug 2019
Is there an ETA on re-balancing? I'm currently rolling out some clusters on mainly (or even exclusively) spot instances and I'd like to be able to easily rebalance workloads.
Similarly, it would be very useful to have a way to select containers for rebalancing - for example, a stateless middle tier app container or cron worker is far more adventageous for rescheduling than a relational database, which may incur downtime. If it was possible to have containers marked somehow (docker labels?) that they are safe to kill at will, provided the service stays in health limits, that would be ideal.
benyanke
on 2 Aug 2019
so ECS is going out of support soon? Should I be stopping my investments into ECS?
benyanke
on 2 Aug 2019
ECS and EKS are both important to our customers and therefore both are important to AWS. As you can see on the container roadmap, we have been continuously shipping features and improvements for both products. As an example of the ongoing level of support, ECS and EKS also have similar runway on this roadmap. ECS has 4 coming soon, 11 we're working on it issues here. Excluding region launches, EKS has 4 coming soon, 13 we're working on it. We listen closely to our customers, and this roadmap is one of the key ways we do that, so if you have feedback (such as have been given on the rebalancing issue) we want to hear it!
coultn
on 2 Aug 2019
Thanks @coultn !
benyanke
on 2 Aug 2019
Hi @coultn Thanks for your interest in this issue.
Firstly I hope you can understand my position if I come across a little pessimistic. I've been around for a while and the only way to use AWS is to take what AWS gives you. Asking and begging AWS for stuff is just a waste of time and setting yourself up for false hope. These views were calcified over the years from painful episodes with AWS Support.
Explaining our situation yet again to AWS would just create more false hope. Most likely this exercise is just another complete waste of time, but hopefully someone would get some entertainment value out of it. Please forgive the snarky comments... it's good for my mental health.
can you tell us more about the specifics?
~350 ecs services -> ~400 -> ~500 ecs tasks through the course of the day with autoscaling.
Is that all AWS was missing? Specifics? I think all of us in this thread is feeling a little silly right now. If only one of us over the course of the last 4 years was a little more specific. We could have avoided all this grief.
Are these services or one-off tasks?
They are all tasks generated from services. Some configured with fixed numbers of tasks. Some configured with autoscaling from 2-30 tasks per service depending on load.
What placement strategy are you using?
I'm using the AZ Spread my buttER placement strategy. You didn't think the cause of everyone's grief was that simple did you? Not one person in the last 4 years thought of using the AZ spread placement strategy.
Within a particular service, the AZ spread strategy works fine. The joke's on you if that's what you based your feasibility study on. Because when you go to production with your full suite of services, ECS just keeps on allocating tasks to the same machine regardless of how busy the machine is.
Even a simple round robin task allocation method would have produced acceptable results. Instead, you get this retarded black box ECS allocation algorithm. AWS support seems to love using the terms, "not necessarily" and "not guaranteed" to describe the allocation behaviour when the more appropriate word is "retarded".
Even massaging the task placement by hand doesn't work. Manually killing a task on a very busy machine, just sees the new instance of that task started back up on the same already busy machine.
@coultn: ECS has 4 coming soon, 11 we're working on it issues here.
@coultn: EKS has 4 coming soon, 13 we're working on it.
@benyanke: Thanks @coultn !
How can you guys even understand each other?! You guys both look caucasian, is there an English v2.0 out that I don't know about? Where's the English v2.0 roadmap? Why did you guys drop backward compatibility with English v1.0?
so if you have feedback (such as have been given on the rebalancing issue) we want to hear it!
What are you guys going to do with the last 4 years of feedback? Have a laugh over a bottle of wine? You guys could have taken any one of the following interpretation of rebalancing:
- number of tasks
- reserved cpu
- reserved memory
- actual cpu
- actual memory
Instead you guys chose to go with "nothing". So I'd be interested in hearing what you guys plan to do with this round of feedback... another bottle of wine?
asdf01
on 5 Aug 2019
Wow. It is not fixed yet! I will try put my case with strong example which should cover the pain area we all are facing.
I have 6 different types of services running total 10 tasks.
- 2(7000MB each), 1(2048MB each), 2(768MB each), 2(768MB each), 2(128MB each), 1(512MB each).
- CPU reservation is not set. Not needed for me.
- m5.large(8GB and 2vCPU) instance used.
- Desired cluster instances is 3. Max 20(Just in case!). Using SchedulableContainers(Google it!) mechanism to auto scale instances.
- Default Placement Strategy with Roll Over. Tried other placement strategies as well with binpack and/or custom combos but not satisfied.
Results :
6 instances occupied, Worst scenario (50% times, this is the case) : Be it Dev or Prod. This is general case most of the times. Costs more.
5 instances occupied, Average scenario (50% times, this is the case) : Be it Dev or Prod. This is general case most of the times.
4 instances occupied, Best scenario (~0% times, this is the case) : If I manually launch above services starting from biggest to smallest taking good enough small pauses in-between. Then this remains for a while, until some tasks are updated.
If someone can suggest a solution or AWS is happy to fix this problem then it is great. I don't think it is a big challenge for AWS. I don't mind if AWS ECS will spin couple of instances for some short duration to smartly re-balance tasks on 4 instances. At the end, for longer duration it should run them with 4 instances which is optimal and desired.
Thanks for hearing me out. Cheers. :)
 cpmangukiya
on 5 Dec 2019
cpmangukiya
on 5 Dec 2019
 pavneeta
on 13 Jan 2020
pavneeta
on 13 Jan 2020
We still have this issue as of 2020.
 lofrank
on 9 Feb 2020
lofrank
on 9 Feb 2020
I'm even considering one machine per cluster now...
 heijmerikx
on 10 Mar 2020
heijmerikx
on 10 Mar 2020
One solution that you can use today is the "cluster capacity providers" feature of ECS: run capacity providers with its own ASG for each availability zone that you want to run tasks in and then set even weights so that tasks get distributed evenly across all the capacity providers. This will ensure even distribution across all three availability zones at all times: https://docs.aws.amazon.com/AmazonECS/latest/developerguide/cluster-capacity-providers.html
For distribution across instances within a single ASG ensure that you are using "spread on instanceId" (https://docs.aws.amazon.com/AmazonECS/latest/developerguide/task-placement-strategies.html) Note that each service gets spread individually though, so if you are running many services with only 1 task they will all get "spread" individually across the available pool of instances and their first task will likely be spread to the same first instance. This may explain some of the results some people are seeing with all tasks on a single instance.
nathanpeck
on 10 Mar 2020
There is a new feature in ECS preview to update placement strategies and constraints. The announcement says the changes will be enforced at the next deploy. Does that mean we can use this new feature to re-balance tasks that have been placed on sub-optimal hosts?
While not exactly the solution this issue is probably looking for, it sounds like this would allow one way of redistributing tasks for those who need it.
 hlarsen
on 20 Mar 2020
hlarsen
on 20 Mar 2020
Is there going to be any action on this or do we need to switch to Kubernetes? This is a pretty major problem for a production environment. Cluster capacity providers are a really big improvement, but it's not really a full solve for this. As nathanpeck pointed out the tasks still pile up on certain instances. If the answer is "we don't have resources to work on this and it's not going to get fixed anytime soon", that's fine and I get it; but please just say that so that we know that we need to make the investment to switch everything over to Kubernetes.
 sunomie
on 29 Apr 2020
sunomie
on 29 Apr 2020
There is a new feature in ECS preview to update placement strategies and constraints. The announcement says the changes will be enforced at the next deploy. Does that mean we can use this new feature to re-balance tasks that have been placed on sub-optimal hosts?
While not exactly the solution this issue is probably looking for, it sounds like this would allow one way of redistributing tasks for those who need it.
Hi @hlarsen Yes, you can use the Update Placement strategy feature to re-balance a given service acorss ECS instances that have piled up on certain instances. You can use --Force-Deploy flag to cause an immediate deployment and enforcement of the updated palcement configuration or wait for the next service deployment.
@sunomie - I understand your frustration, unfortunately there is no one size fits all solution here. Could you please share more information about your cluster setup or discuss the problem in depth offline, you can reach me at [email protected]
- Are there multiple services deployed on it ?
- Are you using Capacity Providers with Cluster Auto Scaling ?
- Were you able to use the update placement strategy to redistribute tasks ?
- Is the goal to improve cluster utilization or heat management ?
pavneeta
on 30 Apr 2020
I cannot believe this issue has not been resolved after 5 years. Where is your customer obsession now?
I'm emailing Bezos.
 nam178
on 2 Sep 2020
nam178
on 2 Sep 2020
cluster capacity providers
yep, you could use that but you need a math degree to understand what is going to do and even then the provider examples do not work
 jamengual
on 3 Oct 2020
jamengual
on 3 Oct 2020
Happy fifth birthday, issue #105! 🥳 I've been subscribed to this thread for four of those years now!
 Makeshift
on 27 Nov 2020
Makeshift
on 27 Nov 2020
Related issues
 ORESoftware
·
3Comments
ORESoftware
·
3Comments
 MartinDevillers
·
3Comments
MartinDevillers
·
3Comments
 pauldougan
·
3Comments
pauldougan
·
3Comments
 adlemich
·
3Comments
adlemich
·
3Comments
 groodt
·
3Comments
groodt
·
3Comments
Most helpful comment
Thanks everyone for the feedback on this issue. I wanted to let you know that we on the ECS team are aware of this issue, and that it is under active consideration. +1's and additional details on use cases are always appreciated and will help inform our work moving forward.