Confluent-kafka-dotnet: Offset loosing
Description
Hello,
I have faced with periodical offsets resetting on broker configuration change. Attempts to understand what was going on did not lead me to anything.
Offsets are loosing for one group and keeping for others. I can stable reproduce this behaviour for a single consumer group.
How to reproduce
I have one producer, one consumer, 3 brokers. Producer is constantly writes messages with performance=300 msgs / sec.
Consumer is reading messages from topic and commiting offsets of read messages automatically. I monitor consumer latency and lag.
Consumer configuration:
config["group.id"] = "KafkaTests";
config["statistics.interval.ms"] = 10000;
config["fetch.message.max.bytes"] = 128000;
config["queued.max.messages.kbytes"] = 1024;
config["queued.min.messages"] = 200;
config["fetch.wait.max.ms"] = 1000;
config["session.timeout.ms"] = 30000;
config["offset.store.method"] = "broker";
config["default.topic.config"] = new Dictionary<string, object>() { { "auto.offset.reset", "smallest" } };
config["enable.auto.commit"] = "true;
When I shut a single kafka broker down, consumer latency (and lag) is growing up and consumer starts to consume already processed messages second time.
When I turn broker back, lag is usually decreases but not to original value. It might look like this
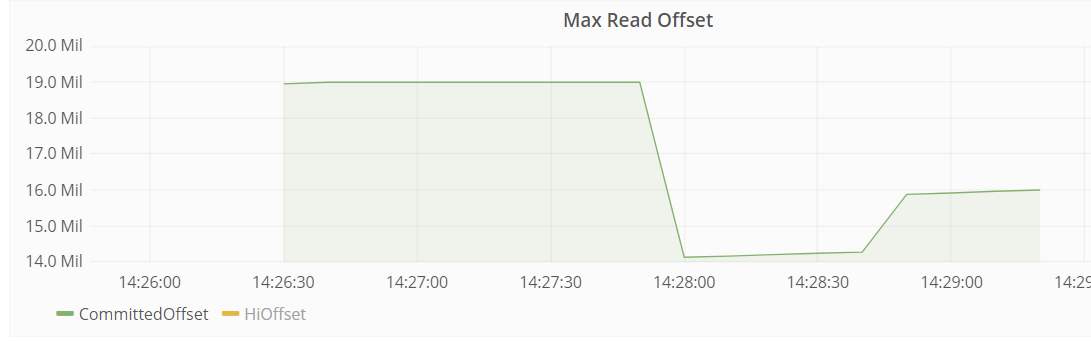
I don't understand what's going on, it looks like broker misconfiguration, but can't find any relevant information in internet.
You can see log of fetched offsets below:
7|2018-01-29 14:26:22.943|rdkafka#consumer-1|OFFSETFETCH| [thrd:main]: HttpLogMessage [0] offset INVALID
7|2018-01-29 14:26:22.944|rdkafka#consumer-1|OFFSETFETCH| [thrd:main]: kafka1:9092/1: OffsetFetchResponse: HttpLogMessage [0] offset 2449840
7|2018-01-29 14:27:44.861|rdkafka#consumer-1|OFFSETFETCH| [thrd:main]: HttpLogMessage [0] offset INVALID
7|2018-01-29 14:27:44.861|rdkafka#consumer-1|OFFSETFETCH| [thrd:main]: kafka2:9092/3: OffsetFetchResponse: HttpLogMessage [0] offset 2346535
7|2018-01-29 14:28:44.347|rdkafka#consumer-1|OFFSETFETCH| [thrd:main]: HttpLogMessage [0] offset INVALID
7|2018-01-29 14:28:44.347|rdkafka#consumer-1|OFFSETFETCH| [thrd:main]: kafka1:9092/1: OffsetFetchResponse: HttpLogMessage [0] offset 2373064
Please let me know if I should provide more info / logs
Checklist
Please provide the following information:
- [x] Confluent.Kafka nuget version: 0.11.2
- [x] Apache Kafka version: 0.10.2
- [x] Client configuration:
- [x] Operating system: windows
- [x] Provide logs (with "debug" : "..." as necessary in configuration)
- [ ] Provide broker log excerpts
- [ ] Critical issue
 divan-9
divan-9
All 18 comments
"debug": "cgrp,topic,fetch" should provide more information why and where it starts consuming
 edenhill
on 29 Jan 2018
edenhill
on 29 Jan 2018
I have debug=all logfile (14mb) and I can grep some info from it. Is it enough?
divan-9
on 29 Jan 2018
@divan-9, hi! Did you find out the offset loosing reason?
 mishanpopov
on 24 Jul 2018
mishanpopov
on 24 Jul 2018
@mishanpopov nope
divan-9
on 24 Jul 2018
have you tried with a later version of librdkafka?
can you provide a minimal C# program that I can run to try and reproduce?
feel free to provide some additional log messages in this thread. cgrp,topic,fetch should be enough, but maybe set debug to all to be sure.
584 is somewhat similar to this.
 mhowlett
on 11 Aug 2018
mhowlett
on 11 Aug 2018
I am also getting the same/similar problem with client version 0.11.4 and 0.11.5
 i5riza
on 24 Aug 2018
i5riza
on 24 Aug 2018
hi @i5riza - thanks for commenting... if you can provide a minimal complete example + logs demonstrating the problem that would help a lot - we can then spot any issues with the code / configuration, or count that out as being the problem. we do have some system tests internally that should cover this scenario. it might be worth trying 1.0-experimental-10 which has quite a number of fixes (though I can't think of anything relevant to this issue).
mhowlett
on 24 Aug 2018
@mhowlett , I cannot reproduce this issue. It happens randomly in random period of time. But, that might be somehow related to state of kafka cluster when some nodes go down and up.
i5riza
on 27 Aug 2018
@i5riza, This is definitely possible although you should see a log message documenting the failed commit. Try grepping for "COMMITFAIL"
 rnpridgeon
on 28 Aug 2018
rnpridgeon
on 28 Aug 2018
@mhowlett , i added debug:all option in dev and will give you feedback right after I will monitor offset loosing or "3/3 are down".
Tonight we experienced down of one broker in prod. In about 10-15 mins after last entry was written to state-change.log, consumer lost offset and started to process records already processed in the past. I am not sure how kafka handles replication factor internally, but maybe this is related somehow? Cluster is of 3 nodes. Do not have "debug:all" for prod.
i5riza
on 30 Aug 2018
@mhowlett , there was no entry in logs with COMMITFAIL after partition offset was reset to 0, but there was something related:
[2018-09-02 22:00:24.9954266 [7] [Confluent.Kafka.Consumer] [Information] 7|"topic-consumer-name#consumer-1"|"WAKEUP"|"[thrd:main]: broker.hostname.com:9092/0: Wake-up"
Let me know if you need full log.
Looking forward.
i5riza
on 4 Sep 2018
@i5riza - just quickly wanted to suggest that if you're on windows, this could be #603 (in which case use 0.11.4 until we get 1.0-beta out). haven't looked in depth yet.
mhowlett
on 5 Sep 2018
@mhowlett, probably you mean issue "borkers 3 of 3 are down". Other ticked is reported for this issue. I am talking about lost offset, what is also actual for older version (0.11.4, for example).
Since current ticket is reported on 29th of Jan, you may have the same issue even in upcoming 1.0 beta. I guess it might be worth to dig a bit deeper into this problem.
i5riza
on 5 Sep 2018
Hi again, @mhowlett
Some more info. I am using beta2. Still loosing offsets. Some points
- Consumer.Committed(...) returns -1001 for every partition until i recommit something again
- config: enable.auto.offset.store=false
- config: enable.auto.commit=true
- config: auto.offset.reset=earliest
I am storing offsets (client.CommitOffsets(...)) based on some rules, but i do not care about commit routine, i.e. this is why auto-commit is fine for me.
I noticed that if I restart the client while it is processing messages (catching up), i never getting lost offsets. But if I restart it some time later (after weekend, for example), then offsets will be lost and consumption will start from offset 0.
I also tried with auto-store enabled, but no luck here - sometimes offsets get lost. Note: kafka cluster in test/local environment is mostly in idle or low usage state.
i5riza
on 5 Nov 2018
Check the broker offsets.retention.minutes, it could be that your committed offsets are deleted due to retention policy.
edenhill
on 5 Nov 2018
Seems that this was an improvement we really needed! Thank you!
i5riza
on 26 Nov 2018
Problem is not reproducing after upgrading broker to 0.11.1 . I guess initial problem relates to https://issues.apache.org/jira/browse/KAFKA-5600 but not quite sure
divan-9
on 26 Dec 2019
Check the broker
offsets.retention.minutes, it could be that your committed offsets are deleted due to retention policy.
@edenhill Bro, you just saved my life. I have spent 2 days on it without any clues. It turns out that I set retention time to 1 min. Thanks again for the @edenhill and also to question contributor @divan-9.
 TonyWang666
on 29 Apr 2021
TonyWang666
on 29 Apr 2021
Related issues
 alfhv
·
3Comments
alfhv
·
3Comments
 snober
·
3Comments
snober
·
3Comments
 MihaiComan87
·
3Comments
MihaiComan87
·
3Comments
 farodin91
·
3Comments
farodin91
·
3Comments
 kvandake
·
3Comments
kvandake
·
3Comments
Most helpful comment
@edenhill Bro, you just saved my life. I have spent 2 days on it without any clues. It turns out that I set retention time to 1 min. Thanks again for the @edenhill and also to question contributor @divan-9.