Common-voice: Add Recording validation criteria to FAQ, and link to that from listen portal
It's not entirely clear to me how strict I should be when validating recordings. For example, sometimes someone speaks a word slightly differently than in the sentence: someone misreads it and says 'cars' instead of 'car'. Should I then mark it as invalid? Or how about 'brightest' instead of 'brightness'? Where should I draw the line?
Maybe the resulting AI would be able to correct it if the user makes small errors if we allow small errors in the dataset? But I'm not sure if the dataset will be big enough for that, and maybe those errors should be solved in an entirely different way.
 Omniscimus
Omniscimus
All 47 comments
Yeah, good point. If the spoken sentence is even off by 1 word, it's invalid. We need to make that clear in the description.
 mikehenrty
on 17 Jul 2017
mikehenrty
on 17 Jul 2017
Relatedly, it would be nice to see the purported accent of the speaker -- if I hear an English accent from a "California speaker", I can know not to check "Yes".
A couple more buttons in addition to "Yes" and "Nope" might be helpful: (1) "Skip" [give me a new sample to judge without recording an answer to the current one]; (2) and maybe "Accent Not Consistent With Profile".
 DavidButterfield
on 18 Jul 2017
DavidButterfield
on 18 Jul 2017
Totally agree this seems important to get guidance on.
My instinct would be that if the person made a clear mistake (missing word ending, eg "car" from "cars" or entirely missing word) then it should not be considered valid. This will require some element of judgement, especially across accent differences (eg BrEn fillet includes the final t, AmEn has it silent) but this should at least allow any ML solutions to learn correctly.
Is there any indication on what form the validation results will take? It might be interesting and of some value to still include but flag the controversial/not fully agreed sentences (ie where there isn't a very large majority of agreement, like say 40% think it's valid vs 60% think not)
 nmstoker
on 18 Jul 2017
nmstoker
on 18 Jul 2017
It's interesting to know that utterances not consistent with the text should be flagged as invalid. I guess it makes sense, given the goal of using this as a TTS training set: if the text says "car" and the utterance says "cars", then it's a good idea to reject.
One thing I do not know how to judge are non-native pronunciations. Sometimes a non-native speaker tries to pronounce the right word but the pronunciation is off. Should such utterances be rejected? On the one hand, it's unfair to judge a TTS system on idiosyncratic pronunciations; on the other hand, though, when the proposed text is really the best way to interpret the utterance, maybe an ideal TTS system should be able to decode it, so the sentence should be kept? In any case, it's often hard to judge whether the pronunciation is really incorrect or if it is just an unfamiliar accent.
In any case, I think that these kinds of questions should be settled in the FAQ (and linked from the place where recordings are presented for validation).
 a3nm
on 18 Jul 2017
a3nm
on 18 Jul 2017
Great discussion. @kdavis-mozilla, any thoughts you'd like to add here?
mikehenrty
on 18 Jul 2017
One thing I do not know how to judge are non-native pronunciations.
Probably non-native speakers should always specify their native language(s)
and/or native linguistic region, and this information should be provided to
judges. Then the neural network can be trained to recognize and/or
generate accent variations for a language.
This is probably more important for the problem of differences between
multiple "native" pronunciations of the same language. For example English
as she is spoke by natives of England, California, the USA Southern states,
Ireland, Australia, and South Africa are all easily distinguishable from
each other by an experienced ear. So probably even "native" speakers
providing samples should specify their native linguistic region.
For speech recognition, it seems like it would be nice (and entirely
possible) for the computer to determine "English with an Irish accent" or
"Hibernian English". Surely a CIA language analyst would do no less. More
ambitiously it might even be able to suggest "English with a Japanese
accent" or "English with an Indian accent", which it seems would also be
within the capability of a CIA analyst or other neural network.
Of course you have to draw the line somewhere -- as a native Californian
who lived in Dublin for five years, I learned that the Irish can often tell
by accent which _county_ a fellow Irishman is from!
For speech generation it might not be so important to produce "English with
a Chinese accent"; but it might still be useful to have the capability to
generate English at least in either a California (Hollywood) accent or a
London accent.
The trouble here will be that most of the random people on the web who are
providing the training labels do not have experienced ears beyond
distinguishing "their own accent" vs. "not their own accent". I'm sure
people in New Zealand can tell the difference between their own accent and
that of Australians, but my own neural network has not been trained to do
that.
For humans judging audio samples produced by other speakers, it might be
nice to be able to specify "only give me samples spoken by people
purportedly from my own linguistic region" (i.e. the ones I am most
qualified to judge), or from some collection of regions the particular
judge is familiar with.
DavidButterfield
on 18 Jul 2017
Some suggestions for design and/or lables in #284.
 jdittrich
on 18 Jul 2017
jdittrich
on 18 Jul 2017
@mikehenrty @a3nm Utterances not consistent with the text should be rejected, e.g. The text asks for "car" they say "cars".
_Non-native pronunciations should be accepted if they read the text as written._
For example, an emigrant from France who's lived in the USA for 20-30 years might still have a French accent. If they read a sentence correctly, saying the words written, with their French accent, then the reading should _not_ be rejected.
Any country will have some population of non-native speakers. A speech-to-text engine targeted at that country, for example the USA, should be able to understand this population of non-native speakers. The only way to do this is to have a mix of native and non-native speakers in the training set of the speech-to-text engine, which is exactly what we want to do by accepting non-native speakers.
So generally we want to cast a big net and include all accents. Furthermore, non-native speakers are welcome, in fact encouraged to contribute. The more the merrier!
 kdavis-mozilla
on 18 Jul 2017
kdavis-mozilla
on 18 Jul 2017
>
Any country will have some population of non-native speakers. A
speech-to-text engine targeted at that country, for example the USA, should
be able to understand this population of non-native speakers. The only way
to do this is to have a mix of native and non-native speakers in the
training set of the speech-to-text engine, which is exactly what we want to
do by accepting non-native speakers.I agree with that, but I still think there are advantages to labeling (and
validating) accent data; and it doesn't preclude doing the above.
The database would be more useful if it could also be applied to
text-to-speech experimentation. For that it seems like it would be more
effective to maintain separation between linguistic regions, to enable
learning of separate models for generating speech in California and
London. Otherwise how will the model know whether this should be called
"CONtroversy" or "conTROVersy"? (It's hard for me to imagine how those two
pronunciations would be blended into any decent compromise.)
For speech-to-text it would still remain possible to train a single model
with the combined data from all the various linguistic regions (ignoring
the region labels). But beyond that, having the utterances labeled (and
validated) according to accent enables testing of additional speech-to-text
hypotheses.
For example, one might hypothesize that speech by speakers of some
particular accent is more effectively recognized by a speech-to-text neural
network trained only (or largely) by speakers with that same accent, as
compared to a more-generally trained network.
So in the case of a neural network tasked with transcribing a speech by an
Irish politician, with the accent data an experiment could compare the
accuracy of transcriptions completed by a network trained by speakers of
Hibernian English only, versus a network trained by English speakers
generally.
Depending on the outcome of such experiments, it could prove useful to keep
a collection of "more-specialized but more-accurate" speech-to-text
neural networks to be used when human (or machine) preprocessing has
already narrowed the linguistic region(s) of the speaker(s) to be
transcribed in some particular instance. More generally-trained networks
could be used in less-constrained situations, perhaps with less accuracy.
I note that the website "speaker profile" already asks for information
related to linguistic region; but it combines all American accents into one
category. The Southern accent covers a broad geographic territory and
contains differences (as compared to California) in pronunciation
significant enough to sometimes result in confusion in human listeners. A
New York accent is also quite different, though I think not as different as
the Southern accent. I imagine that prior research must already have
produced lists of linguistic regions that could perhaps be consulted for
ideas to refine the selection offered here.
(It might be interesting to capture age, too -- half the time I can hardly
understand what my youngest kid is mumbling at high speed.)
DavidButterfield
on 19 Jul 2017
@kdavis-mozilla : OK, so regarding validation criteria, if I understand correctly, the criterion that should be used when validating is as follows: if the proposed text is the best way to transcribe the utterance, then accept, else reject. This means that we should reject if there are errors on the text (e.g., "car"/"cars"), but we should accept if the accent is weird but unambiguous.
It would be nice to explain this to validators, maybe by asking a carefully-worded question (e.g., "is this the best transcription of the speech?") and having a link to details in the FAQ.
a3nm
on 19 Jul 2017
@DavidButterfield I agree with most, if not everything you've said.
My main worries for your approach are
- The amount of data collected for any one linguistic region may so small as to not be of use. (We can counteract this by bucketing data in to the enveloping linguistic region.)
- Legally we can not collect personally identifiable information about the recordings, only demographic info. However, if the number of users per linguistic region is small enough, this demographic info may become personally identifiable information which we can't collect.
- The cognitive load placed on users will increase greatly when they are presented with the linguistic regions which are more numerous than the current accents.
I'd be interested in your take on this as a potential user of the data, and thanks for the thoughtful comments!
kdavis-mozilla
on 19 Jul 2017
@a3nm I think your description of the validation criteria is correct, and I think you're right we need to communicate this better to the users.
kdavis-mozilla
on 19 Jul 2017
>
>
- The amount of data collected for any one linguistic region may so
small as to not be of use. (We can counteract this by bucketing data in to
the enveloping linguistic region.)Yes. Also, over time the number of samples for a region might grow so
that after a while the need for bucketing could decrease. I don't know how
many samples are needed to train a neural network for speech-to-text (maybe
it is smaller if the variation in accent is smaller, so a region might not
need as many samples as more general training -- another hypothesis to
test). I would expect it to be easy enough to get 100 samples from
Ireland, but probably not very easy to get 10,000. Follow-on studies
focused on a particular region might even launch a campaign to increase the
number of samples from that region. The overall database could continue to
grow over time, allowing for improved training.
>
- Legally we can not collect personally identifiable information about
the recordings, only demographic info. However, if the number of users per
linguistic region is small enough, this demographic info may become
personally identifiable information which we can't collect.Is it that you "cannot collect" personally identifiable information, or
that you "cannot convey" such information to others? My prior exposure
to that issue left me thinking the latter -- a medical study knows who the
patients are, but they (are supposed to) de-identify them before making the
collected data available to others.
This issue is addressed by the same method as the first issue above --
bucket the data into large enough groups. My impression is that the groups
don't really have to be very large, and that past demonstrations of
de-identification were done using data that was unique to fewer than ten
individuals. It shouldn't be too hard to get at least that many from each
major linguistic region.
Further, I suspect previous re-identification demonstrations were in arenas
such as medical where far more detailed patient-specific information was
available that could be cross-correlated with external databases. The
information collected here seems much less likely to have such
individually-distinct external correlates. No one is going to be
identified simply by saying his native linguistic region is Ireland.
>
- The cognitive load placed on users will increase greatly when they
are presented with the linguistic regions which are more numerous than the
current accents.Yes, I did notice that; it's a tradeoff. But a speaker need only do it
once, so this part of the cognitive load is still "constant time" rather
than "linear with the number of samples given". As long as it's not so
complicated as to scare people off -- but I think that can be done.
The speaker can't be expected to be conversant with linguistic principles,
so their self-categorization (in their "profile") has to be based on
something generally-recognizable. But people generally recognize their own
accent and closely-related ones, so even if the menu of choices for
linguistic region is large, if it is organized (like a thesaurus rather
than a dictionary) so that users can find their general region, I think
they will generally be able to then recognize and select the most-specific
nearby entry that applies to them. (Probably want them to specify their
"native" region where they learned to talk, rather than the region where
they happen to be living now.)
For example entries for: United States -- Southern, United States -- East,
United States -- Generic, Canada, all near each other on the list; etc. A
Brit might not know the difference between those, but a Brit doesn't have
to know that section of the list, he only needs to select between "UK --
England" and "UK - Scotland", etc.
Of course people from Boston will complain that they don't sound anything
like New Yorkers, so you have to draw the line somewhere. I'd try to draw
the line in the same place where I think it would cross over into a
significant difference to the neural network training, but I suppose that
isn't well-enough understood to produce a bright line. My lack of
knowledge here would probably lead me to look for a reference to existing
linguistic categories already researched by prior studies, and try to
bucket those into sensible groups likely to be recognized by users.
DavidButterfield
on 19 Jul 2017
Another problem with validating only accents you're familiar with could be that users might be able to start validating their own recordings if the data set for their accent is small.
Anyway it seems to me that the core problem is that validators currently don't verify the accents in the recordings. This is bad because of 1. people who accidentally choose a wrong accent and 2. trolls who deliberately choose a wrong accent. But:
I think we can greatly reduce this by requiring contributors to pick their accent(s) before their first recording. We should also prompt them to review them if the list of accents updates (such as in #270).
Correct me if I'm wrong but I don't think there are really many people who enjoy deliberately picking a wrong accent. :smile: We could review the data after collecting and run another accents validation thing if this occurred a lot.
Added bonus is that in this set up, we can actually add quite specific accents to the list without big problems, as long as data sets which are too small are bucketed into their parent category.
Omniscimus
on 20 Jul 2017
Another problem with validating only accents you're familiar with could
be that users might be able to start validating their own recordings if the
data set for their accent is small.
Ugh. I wonder if there's some way to make that less likely. Does it
remember your profile from one day to the next, or does the user have to
re-specify the profile each session?
If profiles persist, in one approach each profile could be assigned a
random pool number in the range 0 to 9 (for example): sample submissions
would be marked with the profile's pool number, while samples for
validation could be offered from the set of samples marked with other
pool numbers. So a submitter should not see his own submissions.
We could review the data after collecting and run another accents
validation thing if this occurred a lot.
Assuming the error rate is low enough, I think this could be done mostly by
machine -- train a neural network to recognize the accent in English speech
samples. (And it seems like that should be a much easier answer to get
highly accurate than an actual translation of the speech into text.)
Maybe train the network using half the samples from each region, then let
it classify the other half of the samples. Whenever it gets a different
answer than the (human-provided) label on the sample, add the sample to a
list for human investigation. Then repeat that process swapping the two
halves. Then retrain it with all the samples and their human-corrected
labels.
The resulting neural network might then be used as a pre-processor to
select which accent-specific neural network to use to process a stream of
speech.
DavidButterfield
on 20 Jul 2017
I meant, we could for the time being just NOT provide validators with the accent, so contributors just validates if the sentence was read out correctly. Validating accents appearently adds significant complexity, and it's unclear (unlikely?) if it's really necessary. If, in retrospect, it was, we could still validate accents separately.
Omniscimus
on 20 Jul 2017
Apologies but it was hard for me to follow this long conversation. I had a similar thought I want to share.
Instead of just "yes", "no", why not expand to other options like "no sound" or "too quiet"?
The latter two are very prominent in my experience.
 orschiro
on 21 Jul 2017
orschiro
on 21 Jul 2017
Instead of just "yes", "no", why not expand to other options like "no sound" or "too quiet"?
Indeed, I'd also advocate for this. Maybe make it more general and call it "bad quality". Possibly, let the user select what is actually bad, when the button is bad. The user should be able to select:
- no sound
- too quiet
- background noise
- different noise/silence at beginning or end (i.e. "needs to be cut off")
 rugk
on 22 Jul 2017
rugk
on 22 Jul 2017
no sound
The system should automatically detect when there's no sound IMO. Otherwise it could just be marked as Nope, no further specification needed as to why the recording is invalid.
too quiet
A resulting system should understand what you're saying regardless of how loudly you speak, so if the recording is OK apart from how loud it is, I think it should just be marked as 'Yes'.
background noise
Again a resulting system should still recognize speech even if there is background noise or a bad mic quality. So I'd say, mark as 'Yes'.
different noise/silence at beginning or end
I agree that this is very frequent in the recordings, almost in all of them there is some kind of click at the beginning or end. However, marking all of those as something other than 'Yes' would make all those unusable, because we also dont know if the sentence is otherwise valid (e.g. a recording with a click which accurately represents the sentence, vs one with a click which does not represent the sentence, marked as 'Click audible' would not be used).
Another problem with using many buttons is that different people use different criteria when selecting those buttons. I think a better solution would be to just keep Yes/No but greatly increase the amount of explanation about when a recording should be marked as valid / invalid.
Omniscimus
on 22 Jul 2017
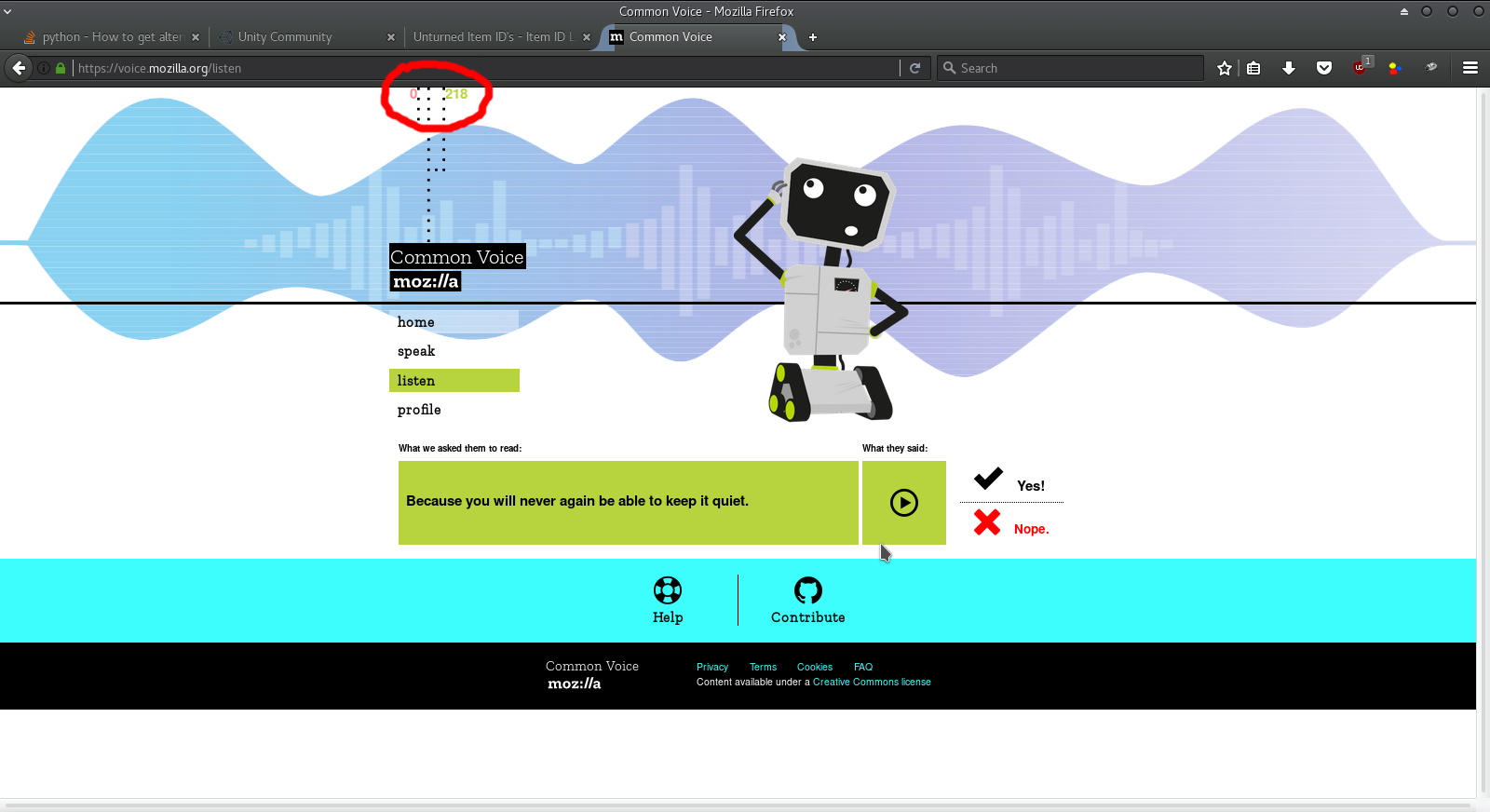
hey another issue is that the counting of total voted sentences is weird. i means whether i press yes or nope it always increasing as the positive count even i have pressed some of those sentences as nope. let me show you in the following picture. i mean it's functioning normally?? i seriously doubt it though.
 tanmayameher
on 23 Jul 2017
tanmayameher
on 23 Jul 2017
@tanmayameher the red number is the number of recordings you've submitted; the green number is how many you've validated. Maybe this could be made clearer on a stats page (#262)
Omniscimus
on 23 Jul 2017
uh now i am a bad reader too :P lol ok. i got it. thanks for clearing the doubt though. 👍
tanmayameher
on 23 Jul 2017
@Omniscimus cool, thanks for sharing this info! I now saw it for the first time and never paid attention before. :-)
orschiro
on 23 Jul 2017
Some people (i would say only guys, because i haven't heard any girl/woman doing such things yet) trying to really screw things up by saying everything right but putting some extra words or pronouncing a similar word etc. which otherwise changes the entire meaning of the sentence (esp. a sexual reference with double meaning ). So, whoever validating; please be watchful of those words and trolls too (esp. of a middle aged guy with a very loud and coarse voice, he uses the above mentioned thing all the time, because he is so desperate for those things :stuck_out_tongue_winking_eye:). It's sad that some guys have so much butter in their food and of course in their you know what :stuck_out_tongue_winking_eye: ; they don't have any work and try to even screw a valuable open-source project. :rage:
tanmayameher
on 24 Jul 2017
I agreee @tanmayameher that trolls are disappointing. But that's why we have nice people like you, to make sure their work doesn't get through. Thank you for your help!
mikehenrty
on 24 Jul 2017
One thing is still not clear for me: I had a case where someone correctly read the sentence, but he pronounced the word "shepherd" as if it were written "sheferd". Is this a Yes or a Nope?
 jf99
on 24 Jul 2017
jf99
on 24 Jul 2017
>
One thing is still not clear for me: I had a case where someone correctly
read the sentence, but he pronounced the word "shepherd" as if it were
written "sheferd". Is this a Yes or a Nope?I wonder if that is a common non-native error (due to it being usual that
"ph" is pronounced "f").
(Words containing the letter "h" are more likely to cause trouble like
this, because "h" usually modifies the pronunciation of the letter that
precedes it, e.g. ch, sh, ph, gh, th, wh; but not if the "h" starts a new
syllable, as in "shepherd", "uphill", "loophole", "haphazard".)
If it is not a common error, I think it would clearly be "Nope".
But if it is a common error, then:
For text-to-speech it wants to be "Nope" because one would not likely
ever want to train a neural network to generate such speech.
But for speech-to-text it might want to be "Yes" because we want a
neural network to recognize common speech variations, perhaps even if they
are incorrect. Ultimately if a human could easily understand the speaker's
intent, it would be nice if the neural network could match the human
performance.
This is a reason to consider a third validation response aside from "Yes"
or "Nope".
Perhaps a category for speech that is "recognizable but would not be
correctly said that way by a native speaker no matter what his accent".
DavidButterfield
on 24 Jul 2017
Perhaps a category for speech that is "recognizable but would not be correctly said that way by a native speaker no matter what his accent".
Isn't that very hard to judge given all the different accents, dialects and ways of pronouncing words?
orschiro
on 25 Jul 2017
i am not able to validate anything since yesterday. It's saying "Sorry! we are processing our audio files, try again shortly". Are you guys doing training as per schedule? or it is a problem in my browser or something???
tanmayameher
on 26 Jul 2017
@tanmayameher related: https://github.com/mozilla/voice-web/issues/359#issuecomment-317967768
orschiro
on 26 Jul 2017
Sorry all, the site has been having some stability issues the last couple of days. Things should be getting noticeably better.
mikehenrty
on 27 Jul 2017
Hi, Any news on the user prompt for validation, "did they accurately speak the sentence below?"?
In my opinion, this ambiguity (some users will interpret "accurately" as "correct pronunciation", others will take it to mean "mentioned all words" etc.) _really_ hurts your validation loop - and, ultimately, data quality.
 bricksdont
on 11 Jan 2018
bricksdont
on 11 Jan 2018
@bricksdont As a replacement, how about:
Press play, listen & tell us: did they speak the sentence below exactly as it is written?
This should be less ambiguous. Then maybe list some additional guidance below.
 flyingpimonster
on 12 Jan 2018
flyingpimonster
on 12 Jan 2018
@flyingpimonster Would be a an option, yes, but then "exactly as it is written" maybe has the same downsides as "accurately". I was thinking of sth along the lines of
Press play, listen & tell us: did they accurately speak the sentence (ignore different accents)?
Would be a minimal change that does not increase cognitive load too much.
Depends on the intended use, of course. But for general-purpose STT systems in general-purpose languages like English, non-standard accents are vital for robust models and telling apart accents is clearly a secondary goal, if at all.
bricksdont
on 12 Jan 2018
Or "did they accurately read the sentence as written (accounting for
speaker accent)"? After all, you don't want people thinking they ignore the
accuracy check if there's a regional accents. Saying "speaker accent"
avoids muddying the water around whether all accents are regional.
On Fri, 12 Jan 2018, 10:21 Mathias Müller, notifications@github.com wrote:
@flyingpimonster https://github.com/flyingpimonster Would be a an
option, yes, but then "exactly as it is written" maybe has the same
downsides as "accurately". I was thinking of sth along the lines ofPress play, listen & tell us: did they accurately speak the sentence (ignore different accents)?
Would be a minimal change that does not increase cognitive load too much.
Depends on the intended use, of course. But for general-purpose STT
systems in general-purpose languages like English, non-standard accents are
vital for robust models and telling apart accents is clearly a secondary
goal, if at all.—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/mozilla/voice-web/issues/273#issuecomment-357200096,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ADhflHIwh22zO6m7j75p8XoxIWTzwx9Jks5tJzIpgaJpZM4OaTrr
.
nmstoker
on 12 Jan 2018
What about something along the lines of "Is this the best possible transcript for what was said? (ignoring style)"
One thing I'm still not quite sure about are contractions. I guess whether a speaker used a contraction or not can be ignored?
 mitaa
on 13 Mar 2018
mitaa
on 13 Mar 2018
@mitaa said:
What about something along the lines of "Is this the best possible transcript for what was said? (ignoring style)"
I like it.
I came here to suggest something like:
Would you write down this text if you heard the recording?
As a non-native english speaker, I can try to speak more proper English, but that's not really how I speak. We also do some bad pronunciations of different words, but everyone understands, so I've read all of it in as I'd say it (even if I know I could be more pedantic with pronunciations, like saying [idiai] for idea instead of [aidi] which is exactly like ID - sadly it makes things context dependent, but language already is like that).
 odinho
on 23 Jun 2018
odinho
on 23 Jun 2018
What if the sentence is sung or whistled whispered instead of spoken properly? I reviewed some sentences by someone who submitted chantlike recordings (nobody would say it like this in real life). I don’t think this is a good idea: if we wanted to make a song text recognition software, we wouldn’t do this in Common Voice, do we?
Another question particular for German:
Can we say, e.g. „Willst du ins Kino geh’n?“ (one syllable)
when the sentences reads „Willst du ins Kino gehen?“ (two syllables)?
This is common behavior in spoken language so it would be cool, if the STT converts this to the standard way in written language or would this cause dirtying the data?
 Ordoviz
on 23 Jun 2018
Ordoviz
on 23 Jun 2018
@Ordoviz I think you wanted to write "whispered" instead of "whistled". Imo, as long as a human can clearly understand the words, a STT engine should be able to understand them as well. And I'm not so much an expert of machine learning, but I guess singing and whispering is good, because it increases the diversity of the dataset. There are also people disguising their voice (e.g. a man trying to talk like a woman) and the like. I think this is great.
About geh'n -> gehen:
Absolutely, one should not be forced to speak clinical for the STT engine. And I have a question related to that: Some people say "nix" instead of "nichts". One could argue the same way here. However, there is a sentence "Satz mit X, das war wohl nix." It's a common German phrase and I'd argue "nix" is the only correct spelling in this special case. Now we have two choices:
- flag all recordings as wrong in which the speaker says "nix" instead of "nichts" (the RNN has to learn the difference between both words)
- change this one sentence to "Satz mit X, das war wohl nichts."
What do you think?
jf99
on 23 Jun 2018
flagging our UX designer @m-branson for this excellent conversation on how to describe validation criteria succinctly
mikehenrty
on 25 Jun 2018
Thanks @mikehenrty all of this feedback is fantastic & great to absorb. It appears we can all agree that language is very nuanced and varies greatly globally.
In the short-term, I propose we leave the current baseline, english prompt as is. Opting instead to provide quick access (via a link) to an overview of our best-case validation criteria. IMO this can show up as an i or FAQ callout next to the prompt. It could also simply be the work accurate linked itself. This link end point would be validation criteria that is explained in more detail, ideally on our FAQ page (I will leave that content to you to finalize @mikehenrty @Gregoor @kdavis-mozilla).
As you all know, it is challenging to succinctly prompt for accurate validation. By providing access to a better informaed understanding of what accurate means I believe we'll see some better success overall.
Additionally, I believe we should be open for this prompt string to be translated more appropriately for each language & encourage you all to continue refining these strings as you encounter them. It's extremely helpful! 😊
 mbransn
on 28 Jun 2018
mbransn
on 28 Jun 2018
Thank you Megan, I updated this bug title to reflect your suggestions. Thanks everyone!
mikehenrty
on 29 Jun 2018
Please fix this. I have uploaded many recordings, but it is terribly demotivating to imagine that some of them might be rejected because the person validating thinks my accent is off, or there is background noise, or I am pronouncing a word in a nonstandard fashion, all of which are things speech recognition needs to be able to deal with.
Given that the goal is to make computers understand speech the way humans do, it seems that the criterion @odinho suggested hits the nail on the head: A recording should be considered valid if a human listener would understand it to transcribe to the given text.
I have created a simple mockup showing how this could be incorporated into the page, while also addressing some other UX problems:
Status Quo
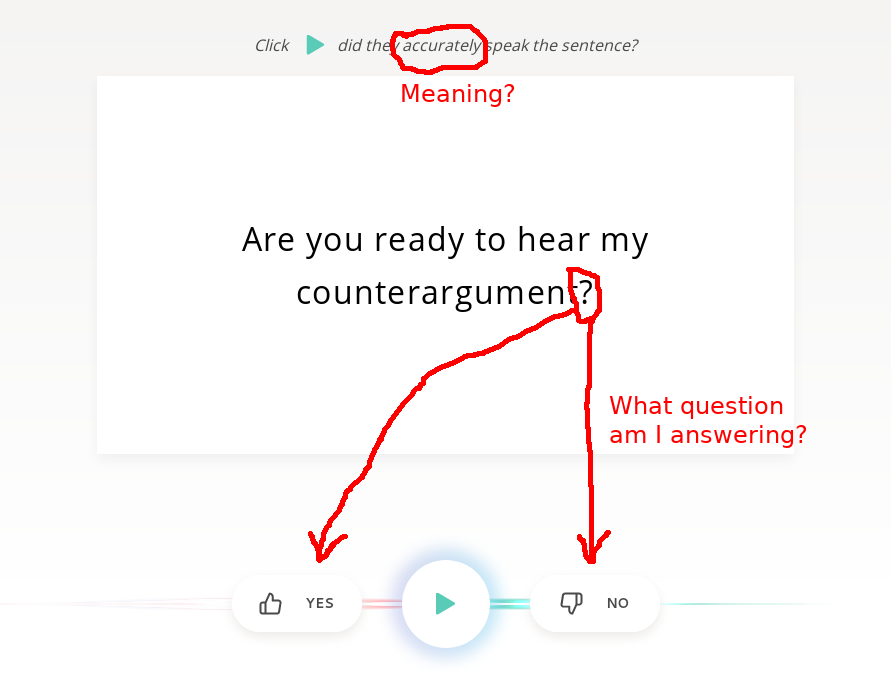
Note that not only does the page not explain what "accurately" means, but it is even unclear what question is being answered. Should I click "Yes" if I'm ready to hear the counterargument? What's worse, the prompt did they accurately speak the sentence? disappears after listening to the first recording, so afterwards the only question that can be directly related to the "Yes" and "No" buttons is the one in the text field!
Proposal
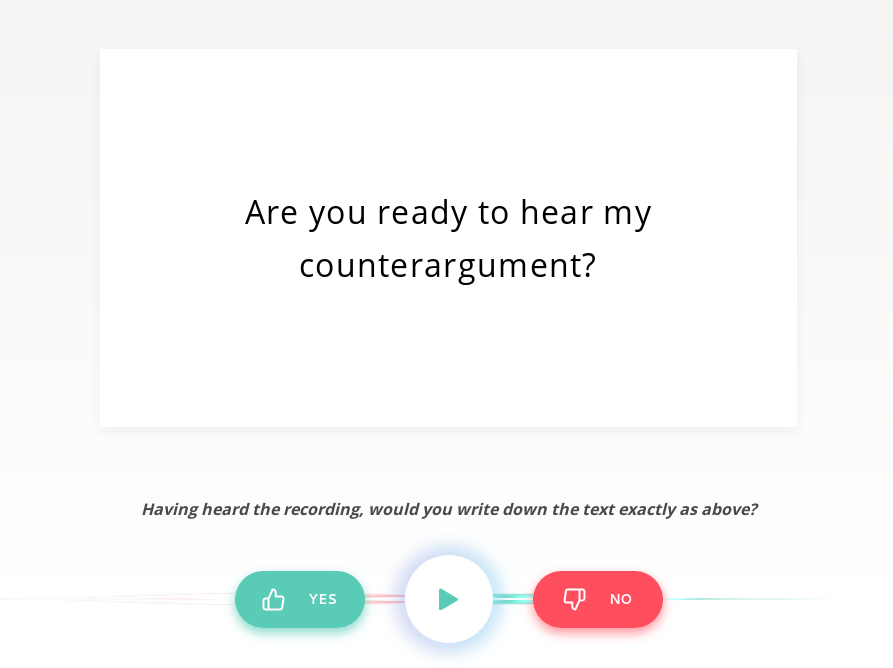
This arrangement makes it clear at all times which question I am answering. The wording of the accuracy criterion, adapted from @odinho's suggestion, is an improvement over the current one, even if it does not exhaustively lay out all the details that belong in an FAQ section. Additionally, I have modified the buttons to always appear in green/red instead of only on hover, which reduces cognitive load when looking for the right button to click.
 p-e-w
on 25 Oct 2018
p-e-w
on 25 Oct 2018
Thanks for that idea, @p-e-w. I really like it. @lissyx also just recommended that we put recording criteria on the speak page. In that case it would be sth along the lines of "Speak naturally, as if you are talking to a friend"
 Gregoor
on 3 Dec 2018
Gregoor
on 3 Dec 2018
While straying into the German validations (https://voice.mozilla.org/de/listen), I came across a guy who is pronouncing all the punctuation (e.g. "Punkt", "Komma", "Fragezeichen"). I don't know how common this is, but maybe that case needs to be covered in the accept/reject criteria?
 countingpine
on 25 Apr 2020
countingpine
on 25 Apr 2020
Hey, I know I am late to this party here, but the initial idea of this issue is something that regularly comes up when I talk to people who donated to common voice. People don't know how to validate sentences. And the initial solution, adding some basic rules to the FAQs and link to them from the validation page sounds very well to me. I also like @p-e-w s proposal, since this looks also easy to implement.
 stefangrotz
on 11 May 2020
stefangrotz
on 11 May 2020
Thanks for the consistent input here all, this (outlining criteria for speak and listen) is something we're working hard to implement. We now have a public roadmap and this feature is slated for the next 3-4 months, see "Criteria for recording and validation".
cc @bacharakis
mbransn
on 14 May 2020
Related issues
 jankeromnes
·
3Comments
jankeromnes
·
3Comments
 ivonnekn
·
5Comments
ivonnekn
·
5Comments
 kenrick95
·
3Comments
kenrick95
·
3Comments
 connorshea
·
5Comments
ivonnekn
·
4Comments
connorshea
·
5Comments
ivonnekn
·
4Comments
Most helpful comment
Please fix this. I have uploaded many recordings, but it is terribly demotivating to imagine that some of them might be rejected because the person validating thinks my accent is off, or there is background noise, or I am pronouncing a word in a nonstandard fashion, all of which are things speech recognition needs to be able to deal with.
Given that the goal is to make computers understand speech the way humans do, it seems that the criterion @odinho suggested hits the nail on the head: A recording should be considered valid if a human listener would understand it to transcribe to the given text.
I have created a simple mockup showing how this could be incorporated into the page, while also addressing some other UX problems:
Status Quo
Note that not only does the page not explain what "accurately" means, but it is even unclear what question is being answered. Should I click "Yes" if I'm ready to hear the counterargument? What's worse, the prompt did they accurately speak the sentence? disappears after listening to the first recording, so afterwards the only question that can be directly related to the "Yes" and "No" buttons is the one in the text field!
Proposal
This arrangement makes it clear at all times which question I am answering. The wording of the accuracy criterion, adapted from @odinho's suggestion, is an improvement over the current one, even if it does not exhaustively lay out all the details that belong in an FAQ section. Additionally, I have modified the buttons to always appear in green/red instead of only on hover, which reduces cognitive load when looking for the right button to click.