Cockroach: kv: tracking progress of improving txn heartbeats
Using this issue to track my progress as I work on #45013.
8/4-8/5
- Experimenting with running various workload configurations on a cluster and seeing how this affects the rate of heartbeats sent
- Sleeping for ~1s during workload txns to force txn to heartbeat, then observing how the rate of heartbeating is affected (we expect the rate to increase now that more txns are heartbeating). Later, once we implement a solution, we can again force txns to sleep for 1s and compare the increase in heartbeats that ensues - hopefully, our solution results in a less dramatic increase in heartbeats sent.
Experiment details
- Added
time.Sleep()for 1s and 2s to https://github.com/cockroachdb/cockroach/blob/3b193feb06feac8d4e908a409b1abfad11d57699/pkg/workload/tpcc/new_order.go#L224 - Ran the following for no sleep, sleeping for 1s, and sleeping for 2s.
roachprod create local -n 4
roachprod put local:4 bin/workload ./workload
roachprod put local:1-3 ./cockroach ./cockroach
roachprod start local:1-3 && roachprod run local:4 './workload run tpcc --warehouses=10 --ramp=0m --duration 5m --tolerate-errors {pgurl:1} --drop --init'
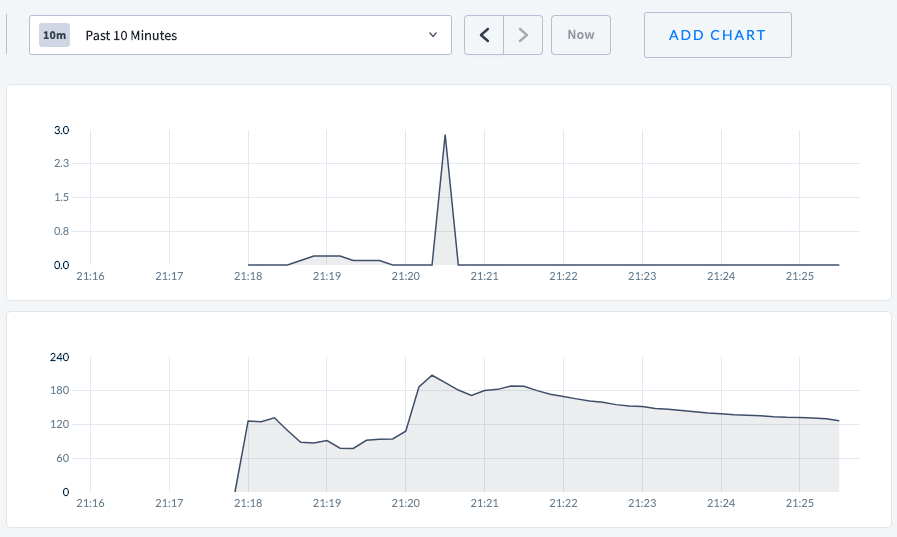
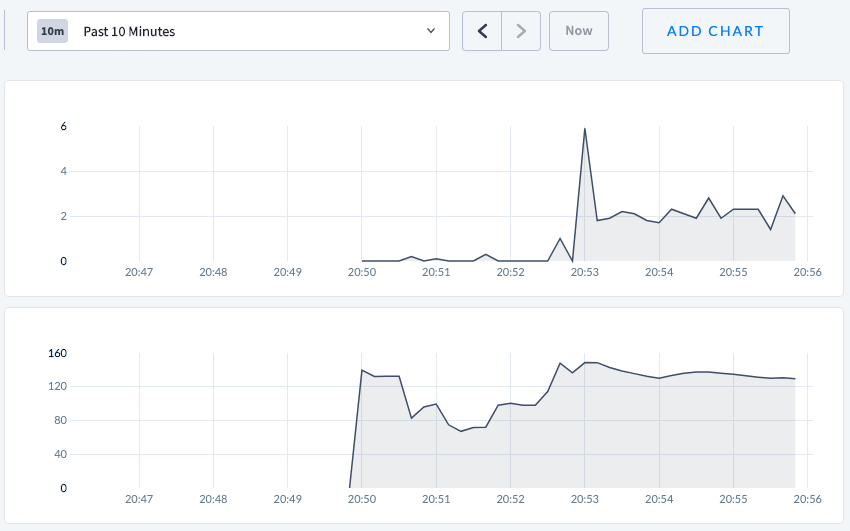
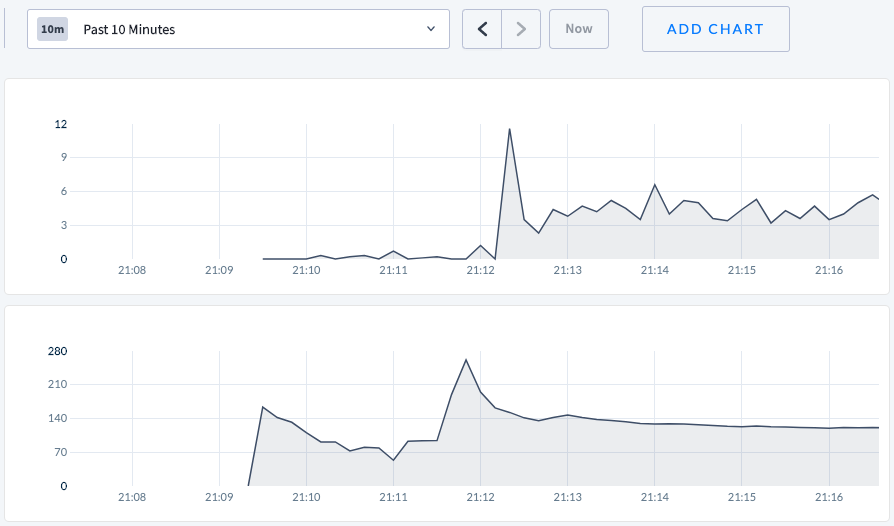
Graphs
Top: rate of heartbeatTxnRequests sent
Bottom: queries per second
- No sleep
- Sleep for 1s
- Sleep for 2s
 madelineliao
madelineliao
All 19 comments
# To build the things we want, sometimes I use them repeatedly to build out
# binaries to swap into the same running cluster.
make build
make bin/workload
# create the cluster and start it.
roachprod create local -n 4
roachprod put local:4 bin/workload ./workload # src dest
roachprod put local:1-3 ./cockroach ./cockroach # src dest
roachprod start local:1-3
# initializes the schema, and also runs the workload against it.
roachprod run local:4 './workload run tpcc --warehouses=10 --ramp=0m --duration 5m --tolerate-errors {pgurl:1} --drop --init'
# could use these to swap in a new crdb binary.
make build; roachprod put local:1-3 ./cockroach ./cockroach # src dest
roachprod stop local:1-3; roachprod start local:1-3
# could use these to swap in a new workload binary
# (also, we don't actually need to drop the schema and reinitialize it)
make bin/workload; roachprod put local:4 bin/workload ./workload # src dest
roachprod run local:4 './workload run tpcc --warehouses=10 --ramp=0m --duration 5m --tolerate-errors {pgurl:1}'
# open the admin UI
roachprod adminurl --open local:1
Here's the brain-dump of things I use to run tpcc experiments. Given that we're initially trying to willfully induce more heartbeats, I think it should suffice.
 irfansharif
on 5 Aug 2020
irfansharif
on 5 Aug 2020
Sweet! Just saw the edit (btw, might be easier to just add subsequent comments down below as we keep iterating, it'll notify subscribers). Given that now we know that the targeted sleep is enough to go from no heartbeats to some, it gives us a concrete number to track and bring down as we try coalescing heartbeats. Looking through how "distsender.rpc.heartbeattxn.sent" is populated, looks like it actually counts the raw HeartbeatTxnRequests sent, not just the "batches" sent. https://github.com/cockroachdb/cockroach/blob/d013d122c6a0ec135f933afa4fa5a31fe40697c3/pkg/kv/kvclient/kvcoord/dist_sender.go#L799-L802
Given that today the batch containing these HeartbeatTxnRequests are in single request batches, they're one and the same. https://github.com/cockroachdb/cockroach/blob/d013d122c6a0ec135f933afa4fa5a31fe40697c3/pkg/kv/kvclient/kvcoord/txn_interceptor_heartbeater.go#L303-L310
But as we're trying to pack more HeartbeatTxnRequests into a single batch, the number we're interested in is actually "the number of batches containing HeartbeatTxnRequests". A gross hack like below should give you what you'd be looking for.
diff --git a/pkg/kv/kvclient/kvcoord/dist_sender.go b/pkg/kv/kvclient/kvcoord/dist_sender.go
index 04f0fad6f0..ebdd79d416 100644
--- a/pkg/kv/kvclient/kvcoord/dist_sender.go
+++ b/pkg/kv/kvclient/kvcoord/dist_sender.go
@@ -796,7 +796,8 @@ func (ds *DistSender) Send(
// batch and its composite request methods.
func (ds *DistSender) incrementBatchCounters(ba *roachpb.BatchRequest) {
ds.metrics.BatchCount.Inc(1)
- for _, ru := range ba.Requests {
+ // Hack, looking at only the first request in the batch (trying not to count individual requests, but "batches of a certain request type").
+ for _, ru := range ba.Requests[:1] {
m := ru.GetInner().Method()
ds.metrics.MethodCounts[m].Inc(1)
}
(If you were wondering about the "low" heartbeat rate that’s because we’re trying a low warehouse count, which implies a low worker thread count/activity. In real clusters with real workloads, this would be much higher.)
irfansharif
on 6 Aug 2020
I'm a bit suspicious of this approach but I may be missing what we're trying to quantify. TPC-C has a rate of issuing transactions. If you keep up with that rate, then the contention can increase. That contention is like can itself lead to degraded performance.
I think trying to base the experimentation on the observation that when latencies get above a certain point in TPC-C then a regime change can occur due to the increased load due to heartbeats seems challenging. Doing that while actually changing the behavior of the underlying queries seems even more challenging.
My guess is that a better experiment might be to play with adjusting the point in the lifetime of a transaction that the first heartbeat is kicked off and seeing what that does to the throughput of various workloads, TPC-C included.
To make this more concrete, I think we want to find a warehouse count for a test cluster whereby TPC-C passes but barely. This can be done with one run of tpccbench against a cluster. Do this with a binary that has a cluster setting added that controls how long into the life of the transaction the first txn heartbeat is sent. Then try adjusting this higher and lower. See if adjusting it to be higher allows a passing score at a larger warehouse count. Similarly observe what happens when setting it to a lower value like 500ms on down to something like 10ms.
 ajwerner
on 6 Aug 2020
ajwerner
on 6 Aug 2020
What we were initially trying above are quite a few steps away from what you're describing, which I agree we'll need to get to to evaluate the efficacy of txn heartbeat batching with respect to #45013. What we were attempting above was to get just used to playing around with roachprod/workload/etc., and use it as a first step to even observe txn heartbeats happening. And once we start batching them together, we'd use the same tiny "experiment" to make sure we _are_ actually batching them together without having broken anything (think super duper early smoke tests).
irfansharif
on 7 Aug 2020
Got it. I was under the impression was the goal would be to understand the win.
ajwerner
on 7 Aug 2020
8/10-8/12
Added RequestBatcher and RangeDescriptorCache fields to TxnCoordSenderFactory, and instantiating the RequestBatcher whenever a new factory is created here:
https://github.com/cockroachdb/cockroach/blob/89208ec8b5350fd34036b559a258403e820deda6/pkg/kv/kvclient/kvcoord/txn_coord_sender_factory.go#L61
Since RequestBatcher batches by range ID, we initially thought that we wouldn't be able to do this batching at the client level, but @nvanbenschoten and @andreimatei pointed out that we could use the range descriptor cache to access the range ID, and that this has been done before at the client level.
This allows us to batch heartbeat txn requests in the txnLockGatekeeper, which is the final interceptor the request goes through before it's sent off:
https://github.com/cockroachdb/cockroach/blob/89208ec8b5350fd34036b559a258403e820deda6/pkg/kv/kvclient/kvcoord/txn_coord_sender.go#L131-L147
The changes we tried are here. When looking at heartbeat metrics in the same way we did earlier, we saw the same # of heartbeat requests come through, and when returning an empty response, we saw the # of heartbeats drop to 0 (which is what we expected). We're planning on creating an interface to combine RequestBatcher and RangeDescriptorCache into a HeartbeatBatcher and then possibly creating another interceptor in the interceptorStack that would take care of batching the heartbeats.
madelineliao
on 13 Aug 2020
The approach in #52705 is starting to take shape! There are just a few things that stood out to me:
- Instead of passing a
RangeDescriptorCacheandRequestBatcherinto eachTxnCoordSender, we should consider creating a wrapper abstraction around the two. You could imagine some kind oftxnHeartbeatBatcherobject that wraps aRequestBatcherand aRangeDescriptorCacheand (optionally) provides type safety forHeartbeatTxnrequests. - Instead of providing this
txnHeartbeatBatcherto thetxnLockGatekeeper, hand it to thetxnHeartbeateritself! Then the heartbeater won't even need atxnLockGatekeeperand we won't need to intercept requests.
 nvanbenschoten
on 13 Aug 2020
nvanbenschoten
on 13 Aug 2020
8/13-14
Updates:
Added TxnHeartbeatBatcher struct:
https://github.com/cockroachdb/cockroach/blob/8887b1a754672d10097baeacb9390a132d1a758c/pkg/kv/kvclient/kvcoord/txn_coord_sender_factory.go#L28-L31
and also moved the heartbeatBatcher to the txnHeartbeater like Nathan suggested. Had to look through the code a bit to convince myself that heartbeat txn requests can be sent directly from the heartbeater without going through the interceptor stack - basically, heartbeat requests already bypass the interceptor stack and are sent directly to the txnLockGatekeeper anyways (it wouldn't really make sense to send a heartbeat request through all the interceptors, especially back to the heartbeater layer itself since that would be circular). See:
https://github.com/cockroachdb/cockroach/blob/7ad048f9935dd565dede9153ebf441e4346e004f/pkg/kv/kvclient/kvcoord/txn_interceptor_heartbeater.go#L312-L315
Within the txnLockGatekeeper, no extra processing is done on heartbeatTxnRequest's; they're simply sent on. Thus, for our heartbeat batching, it seems that we can safely bypass the txnLockGatekeeper and send heartbeats directly to the batcher:
https://github.com/cockroachdb/cockroach/blob/7ad048f9935dd565dede9153ebf441e4346e004f/pkg/kv/kvclient/kvcoord/txn_lock_gatekeeper.go#L68-L86
Questions
While the above works with the simple case of adding heartbeat requests to the batcher with a max batch size of 1, larger batch sizes pose an issue since heartbeat requests need to be associated with a specific txn so that the heartbeater knows when to shut down the heartbeat loop. Since we're batching heartbeats now, it seems that we need to include a Txn field in the HeartbeatTxnRequest so that we can still do this (which @ajwerner described in #45013).
I would think that when batches of size _n_ are sent, then the returned response br will be a list/ResponseUnion also of length _n_. In order to check the heartbeater's corresponding txn to see if the heartbeatLoop should be shut down, we'd then have to do an O(_n_) scan through br to find the response with the matching txn.
https://github.com/cockroachdb/cockroach/blob/8887b1a754672d10097baeacb9390a132d1a758c/pkg/kv/kvclient/kvcoord/txn_interceptor_heartbeater.go#L329-L332
Is my understanding correct? And if so, is there a better way to handle the batched responses than for each heartbeater to scan through all of them? (Or does the scan actually not slow things down that much?)
madelineliao
on 17 Aug 2020
This is looking better! Thanks for the progress update.
I would think that when batches of size n are sent, then the returned response br will be a list/ResponseUnion also of length n. In order to check the heartbeater's corresponding txn to see if the heartbeatLoop should be shut down, we'd then have to do an O(n) scan through br to find the response with the matching txn.
RequestBatcher.Send should return the correct Response and an Error directly, so you shouldn't need to touch h.heartbeatBatcher.batcher.BatchResp. Was that not working?
On that point, we should probably avoid reaching inside of the heartbeatBatcher object. That breaks the abstraction we're trying to provide. Instead, the object could provide a func (*txnHeartbeatBatcher) Send(ctx context.Context, hb *roachpb.HeartbeatRequest) method that internally looks up the range ID and manipulates the batcher object.
Also, now that we're not going through the txnLockGatekeeper, we will need to unlock h.mu before we send the heartbeat and re-lock it after we get a response.
nvanbenschoten
on 17 Aug 2020
While the above works with the simple case of adding heartbeat requests to the batcher with a max batch size of 1, larger batch sizes pose an issue since heartbeat requests need to be associated with a specific txn so that the heartbeater knows when to shut down the heartbeat loop. Since we're batching heartbeats now, it seems that we need to include a Txn field in the HeartbeatTxnRequest so that we can still do this (which @ajwerner described in #45013).
I think we need to include a Txn in the HeartbeatTxnRequest and use that instead of CommandArgs.Header.Txn on the evaluation side; you'll have to fallback to using Header.Txn for backwards compatibility.
However, this creates a weird situation whereby the heartbeat is sent in a txn, but not in the txn that it heartbeats; the batcher uses a NonTransactionalSender, so generally requests will be sent outside of a transaction, except that sender automagically falls back to wrapping a request in a transaction when the DistSender needs to split it. I think we'd be wise to avoid this, and I think you can avoid it by removing the isTxn flag from the heartbeat request here: https://github.com/cockroachdb/cockroach/blob/843dcc4cde552fe7c0029a47231cd386618b33cb/pkg/roachpb/api.go#L1206 . This should prevent this automatic wrapping in transactions: https://github.com/cockroachdb/cockroach/blob/b76b7da534567a9d17e0298462f34e8ea130440f/pkg/kv/kvclient/kvcoord/dist_sender.go#L1127
I'm unsure about why you've tied this need to include the txn in the request to needing to do anything new with the responses. It seems to me that the RequestBatcher makes the batching completely transparent to the caller, doesn't it? So each heartbeater should get the right response for its heartbeat I think.
 andreimatei
on 17 Aug 2020
andreimatei
on 17 Aug 2020
My teammates type faster than I do.
I'm unsure about why you've tied this need to include the txn in the request to needing to do anything new with the responses.
That was me being wrong about some things. I think this was before we realized we could bypass the interceptor stack altogether; we were trying to associate each Txn with each HeartbeatTxnRequest to be able to extract the range ID for each request so to work with RequestBatcher (we were trying to shoehorn requestbatcher that only knows about roachpb.Requests into this interceptor stack that only knows about Batch{Request,Response}s). This was in _addition_ to needing to change up our evaluation paths to look towards the request itself for the associated Txn instead of the batch header, but the first reason is unjustified in retrospect.
RequestBatcher.Send should return the correct Response and an Error directly, so you shouldn't need to touch h.heartbeatBatcher.batcher.BatchResp. Was that not working?
I think the confusion here is arising from the fact that today the txnHeartbeater today is using Batch{Request/Response}s to send out heartbeats (because it's an interceptor that is only taught the SendLocked interface).
But if we're bypassing the rest of the interceptor stack altogether, txnHeartBeater can be taught to simply work with raw roachpb.Requests instead. Are we going to need to include the Txn in HeartbeatTxnResponse as well? I think so, today it looks like we reach into the batch response header to get to it, and that would no longer be applicable.
irfansharif
on 17 Aug 2020
Are we going to need to include the Txn in HeartbeatTxnResponse as well
Yes, we will need to do that. We'll also need to include an Error in the HeartbeatTxnResponse so that we don't kill the entire batch when one heartbeat fails (for instance, here). Or just return an ABORTED transaction proto for the corresponding response in that case.
nvanbenschoten
on 17 Aug 2020
I think we'd be wise to avoid this, and I think you can avoid it by removing the isTxn flag from the heartbeat request here:
Yes, we'll want to remove that flag,
nvanbenschoten
on 17 Aug 2020
Currently trying to figure out how to handle errors for individual responses (since previously, we looked at the pErr returned in the batch response:
https://github.com/cockroachdb/cockroach/blob/e37a467796257d9fe9a6a14cbc2192af2f968fd7/pkg/kv/kvclient/kvcoord/txn_interceptor_heartbeater.go#L324-L349
It seems that the only type of pErr handled is the roachpb.TransactionAbortedError, in which case we abort the txn, update the observed status, and return early. For other errors, we simply set respTxn accordingly:
https://github.com/cockroachdb/cockroach/blob/e37a467796257d9fe9a6a14cbc2192af2f968fd7/pkg/kv/kvclient/kvcoord/txn_interceptor_heartbeater.go#L346
Later on, the status of respTxn is checked again:
https://github.com/cockroachdb/cockroach/blob/e37a467796257d9fe9a6a14cbc2192af2f968fd7/pkg/kv/kvclient/kvcoord/txn_interceptor_heartbeater.go#L351-L365
A couple questions:
- Why do we check specifically for the
TransactionAbortedErrorand return early when we encounter it? Won't that be handled when we later check ifrespTxn.Status == roachpb.ABORTED? - What do
pErr's besides aTransactionAbortedErrormean? When those happen, does that mean the txn is not contained in the batch response header (i.e., we have to get the txn information from thepErrrather than frombr- hence, the reason for this line):
https://github.com/cockroachdb/cockroach/blob/e37a467796257d9fe9a6a14cbc2192af2f968fd7/pkg/kv/kvclient/kvcoord/txn_interceptor_heartbeater.go#L346
(tldr: trying to see what exactly pErr gives us in the heartbeat interceptor. Since the requestbatcher deals with raw requests, when batching heartbeat txn requests, a pErr is no longer returned. Not sure if we need to surface the pErr for the specific request somehow, or if we can just look at respTxn.Status)
madelineliao
on 24 Aug 2020
Why do we check specifically for the TransactionAbortedError and return early when we encounter it? Won't that be handled when we later check if respTxn.Status == roachpb.ABORTED?
I believe it's because we want to account for when we _don't_ have a transaction proto available to us.
https://github.com/cockroachdb/cockroach/blob/e37a467796257d9fe9a6a14cbc2192af2f968fd7/pkg/kv/kvclient/kvcoord/txn_interceptor_heartbeater.go#L327-L328
I haven't looked too closely as to when that happens. Is it when a txn record has already been GC-ed away?
What do pErr's besides a TransactionAbortedError mean? When those happen, does that mean the txn is not contained in the batch response header (hence, the reason for this line)
Did you mean that the txn _is_ contained in the batch response header? We're unwrapping them in the line you linked, I think.
Not sure if we need to surface the pErr for the specific request somehow, or if we can just look at respTxn.Status.
I don't think we do. Similar to what Nathan described in https://github.com/cockroachdb/cockroach/issues/52415#issuecomment-675133811, we should be able to get by just working off of the latest view of the Txn that the heartbeat request evaluation codepath just found out about.
So if it finds the txn to have been aborted, simply returning that (which we seem to be doing already) and working off of that in the interceptor should suffice, I believe. We'll just need to be careful for when we can't produce a txn record, here:
This I think is similar to the case today where we don't find a corresponding txn proto when working with pErrs directly. We could always include a txn with an ABORTED status in the reply.
irfansharif
on 24 Aug 2020
Did you mean that the txn is contained in the batch response header? We're unwrapping them in the line you linked, I think.
I meant that in the case that there is a pErr, we get the txn from pErr.GetTxn() rather than br.Txn, so I didn't know if that meant that br.Txn isn't valid if an error occurred.
Regarding the error handling in the interceptor - since the only thing the interceptor uses pErr for is pErr.GetTxn(), does that mean in the HeartbeatTxn command, we can always return a nil error as long as we include a txn with the appropriate status in the reply?
https://github.com/cockroachdb/cockroach/blob/86165b9435549aebb922f88bd0056b82e5d60715/pkg/kv/kvserver/batcheval/cmd_heartbeat_txn.go#L41-L43
Functionally, in master code, since the interceptor only uses the pErr to check txn status, returning nil should be ok right? Although it does feel a little weird not returning any errors.
madelineliao
on 24 Aug 2020
I do think it's fine to return nil. After all, the heartbeat request exists to inspect txn status, which could very well be found to be aborted. It doesn't seem that unusual to me then to have our response reflect as much (rather than encoding that in an error condition).
irfansharif
on 24 Aug 2020
Seems like things are working! We added a time.Sleep(2s) to workload, then ran the workload without batching and with batching. The resulting graphs are below - the three graphs are, from top to bottom
- Rate of heartbeat batches sent
- Cumulative total # of heartbeat batches sent
- Queries per second
Without batching:
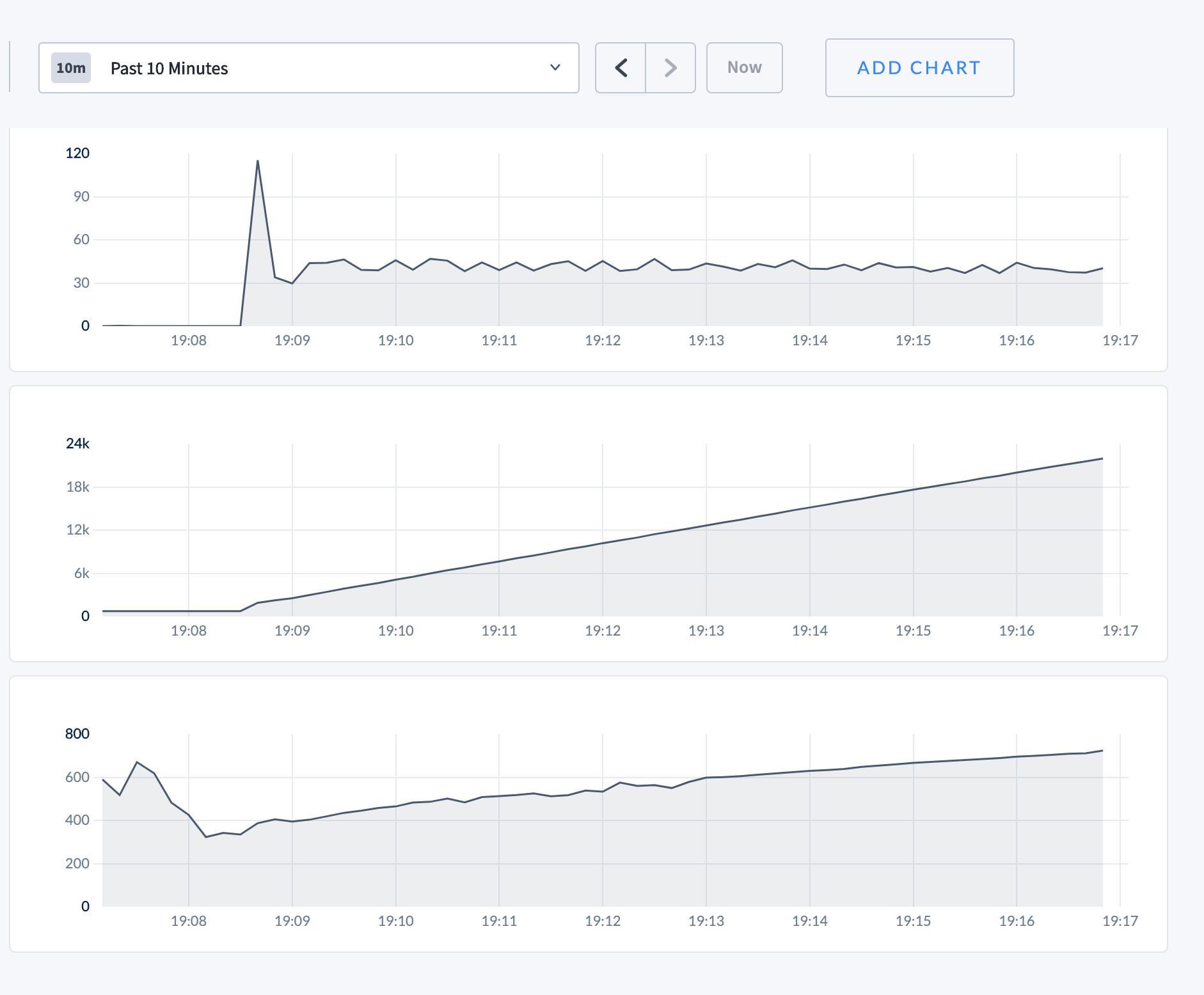
With batching:
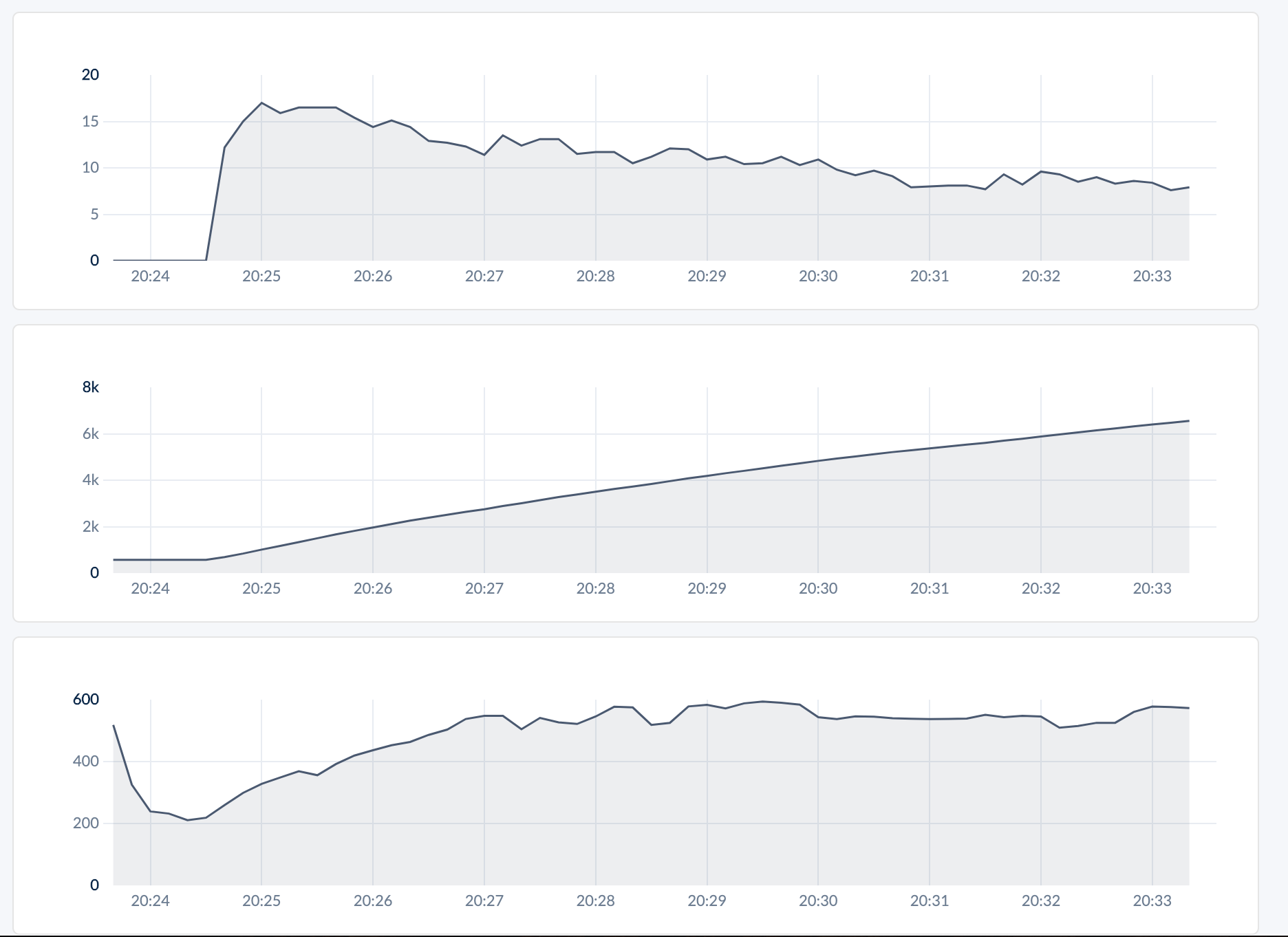
Next steps:
- Clean up
- Add tests
- Handle version migration
madelineliao
on 1 Sep 2020
45013.
irfansharif
on 14 Sep 2020
Related issues
ajwerner
·
4Comments
 richardanaya
·
3Comments
richardanaya
·
3Comments
 bdarnell
·
4Comments
bdarnell
·
4Comments
 couchand
·
3Comments
couchand
·
3Comments
 tim-o
·
3Comments
tim-o
·
3Comments