Che: Separate issue severity and priority into two separate labelling schemes
Overall Problem
Currently in the Che repo, we set a "severity" label but in reality it blends severity and priority. This causes a few issues:
It makes issue triaging harder and less clear. The role of the triager should be to assess the severity of incoming issues, so that people working on the actual issues can see the severity and plan accordingly. Having the triager (who likely won't be working on the issue) set a priority is wrong, and often leads to the team lead/contributer/developer needing to adjust the priority.
Issues with low severity end up with high priority. For example at the time of this writing, there are 65 open issues marked as
kind/enhancementbut are also markedP1. From a priority standpoint that's fine -- maybe these enhancements are important. But from a severity POV these are not severe issues. Mixing the terminology makes this confusing.It makes planning harder. Under the current scheme, granularity is lost for those planning which issues they want to work on because the triager sets a priority. As someone who routinely has to plan issues for a sprint, it would be nice to separate these concepts so I can look at issues by severity and then determine the priority.
Severity
Describes how severe an issue is completely ignoring any priority context. Something that prevents Che from starting is by definition a blocker. An issue causing serious usability problems/regressions is by definition a major issue. Issue that have workarounds or aren't as severe are minor. Enhancements and feature requests have severity enhancement.
Now, severity can vary depending on the submitter of the bug. For example, a bug in a niche area of Che my be minor for me, but to a community member who relies on that area it could be a major or even a blocker issue.
Severity is owned by the submitter/triager.
Priority
Describes a user's or team's priority on that issue. Issues that must be fixed in the current sprint are deemed critical. Issues that should be fixed in the current sprint are deemed P1. Issues that can wait _n_ sprints but should be fixed eventually are deemed P2. Issues that we do not plan to work on can be marked as help wanted
This is assessed by individual contributors, or team leads. In the severity example above, maybe the user intends to fix the blocker issue. They can set critical for themselves, as they intend to fix it this sprint. But maybe I as a team lead working for Red Hat wouldn't set that priority as it's not a priority for my team.
Alternatively, maybe the user really wants an issue fixed, but cannot do it themselves. They can increase the priority on the issue, and maybe I as a team lead will consider taking the issue into my sprint, if the case to work on it is strong enough.
Priority is owned by the submitter, or the person/team working on the issue.
Proposal
I propose we document the following in the wiki, and I am willing to do it.
Severity Labels
| Label | Description |
| ------------- | ------------- |
| blocker | Blocks development or use of Che entirely. |
| major | A serious loss of function, usability, or a regression caused by recent work. |
| minor | An issue that does not seriously interfere with day-to-day usage of Che, and/or an easy workaround is present |
| enhancement | Request for a new feature. Cases where functionality was expected, but is missing, can also be classified as a higher severity. |
Priority Labels
| Label | Description |
| ------------- | ------------- |
| critical | Must fix in this sprint. Should be used sparingly. |
| P1 | Very important that this issue is fixed in this sprint. Ideally all P1 issues in a sprint plan should be fixed. |
| P2 | Of normal importance. |
| help wanted | A valid bug/request, but there are no plans to work on it. |
Issue Triage
During issue triage, the triager sets severity. During prioritization/sprint planning, the team lead sets priority. Any user from the community can also set priority and either work on the bug themselves, or make the case to someone else about why their issue should be worked on.
 ericwill
ericwill
All 34 comments
I personally do not have any particular issues with the current approach we are having for the triage. However, I assume that having Severity (critical -> non-critical) / Priority (low -> urgent) matrix could make sense in some cases, so +0 from my side.
Just a tip I'm trying to follow is doing the prioritization gradually in advance during the sprint (with automated backlog it becomes really easy and by the prioritization call with devex, the team would have the sprint backlog almost set)
 ibuziuk
on 2 Nov 2020
ibuziuk
on 2 Nov 2020
As for me, I don't see any problems with the triage/prioritization process we have now.
I like the current approach because it's pretty simple and it's easy to understand for the community. IMO it just works. Also, it helps a lot that we have the triage reports regularly posted in the Che Community chat. It allows people who are responsible for a particular Che area to review the triaged issue and (re-)prioritize them if necessary.
I'd like to keep it simple and useful as it is now.
 azatsarynnyy
on 2 Nov 2020
azatsarynnyy
on 2 Nov 2020
Couple suggestions:
based on the discussion ongoing about https://github.com/eclipse/che/issues/18245, it seems we really need this new model so we can differentiate between "issue blocks the next release" (severities) and "issue is important to get done soon" (priorities)
also to make it easier to grok and be more intuitive, I'd suggest this set of labels instead of the ones above:
Severity Labels
| Label | Description |
| ------------- | ------------- |
| blocker | Blocks development, forthcoming release, or use of Che entirely. _Use sparingly._ |
| critical | A serious loss of function, usability, or a regression caused by recent work. |
| major | A major issue that does not seriously interfere with use of Che; default severity for new issues. |
| minor | A minor issue that does not seriously interfere with use of Che, and/or an easy workaround is present|
Note: any of the above can be a task, bug, or _enhancement_. We're only talking about severity, not type of work, which is orthogonal.
Priority Labels
| Label | Description |
| ------------- | ------------- |
| P0 | Must fix in this sprint: the Priority equivalent of a blocker, as other previously planned sprint work should be stopped to focus on this super-urgent task. _Use sparingly._ |
| P1 | Very important that this issue is fixed in this sprint. Ideally all P1 issues in a sprint plan should be fixed before tackling anything of lower priority, but a sprint should not be all P1 work. |
| P2 | Of normal importance; default priority for new issues. |
| P3 | A valid bug/request, but there are no plans to work on it. |
 nickboldt
on 2 Nov 2020
nickboldt
on 2 Nov 2020
don't you think all committers will set P1 to their own bugs/enhancements ?
 benoitf
on 2 Nov 2020
benoitf
on 2 Nov 2020
Sure, if they want to differentiate "I will do the work now" vs. "I will do the work later this sprint when I have free time", then that's fine with me.
Point is this model gives you a three-tier system for prioritization:
- now, later, never
with a bonus level for:
- "omg drop everything, this HAS to happen now"
nickboldt
on 2 Nov 2020
also I see no difference between P0 and severity/blocker
why then set two different things ?
AFAIK, priorities are discussed during some calls, that could be open to anyone.
And if the automated sheet is only sorted by severities, then I still don't get who is going to read/update the priorities ?
benoitf
on 2 Nov 2020
Sure, if they want to differentiate "I will do the work now" vs. "I will do the work later this sprint when I have free time", then that's fine with me.
Point is this model gives you a three-tier system for prioritization:now, later, never
with a bonus level for "omg drop everything, this HAS to happen now"
@nickboldt but there are milestones and sprint/current-sprint / sprint/next-sprint labels
I want to fix it now: I set current milestone, I want to fix it for the next one : next milestone, etc
benoitf
on 2 Nov 2020
I'd love if the sheet could be sorted by prio: that way there's a point to having prio labels.
Today I can't sort the automated sheet (unlike the version from a couple months ago where I could use the comment field to set a prio for myself/my team, then sort on that column). As a lead, that was WAAAAAY more useful than the current method of "you have no way to sort your sprint issues make your time".

Adding the ability to sort the sheet's sprint buckets and backlog by prio would be super useful. It would make the sheet 1 step closer to a tool like BZ or JIRA, which seems to be the whole reason for building it: a kanban board for both GH issues and JIRA in the same UI.
nickboldt
on 2 Nov 2020
Having milestones in addition to sprint/current-sprint + sprint/next-sprint ... seems like you've accepted that people won't use milestones and have created a pair of pseudo-milestones instead. Why do we need both?
Wouldn't it be better to just use the milestones? Then I can set something for 7.21 (current milestone), 7.22 (next milestone) and 7.23 (future milestone).
In JIRA I can assign issues to 2.4, 2.5, 2.6, or 2.7 ... not just "this sprint" and "next sprint". Surely we want the ability to plan more than 6 weeks ahead?
nickboldt
on 2 Nov 2020
Milestones are for Github users. To know if an issue is fixed or will be fixed in the next milestone I just at to look at milestones.
All the remaining is useless for a contributor.
So the point here is for Team Lead or for a github user ?
I would not speak about JIRA here as JIRA is another tool and most github projects are using github issues.
Maybe we could use inputs from other github projects as well
If I look at VS Code:
5000 issues and no severity/priority
https://github.com/microsoft/vscode/issues
If I look at kubernetes
https://github.com/kubernetes/kubernetes/labels?q=priority+
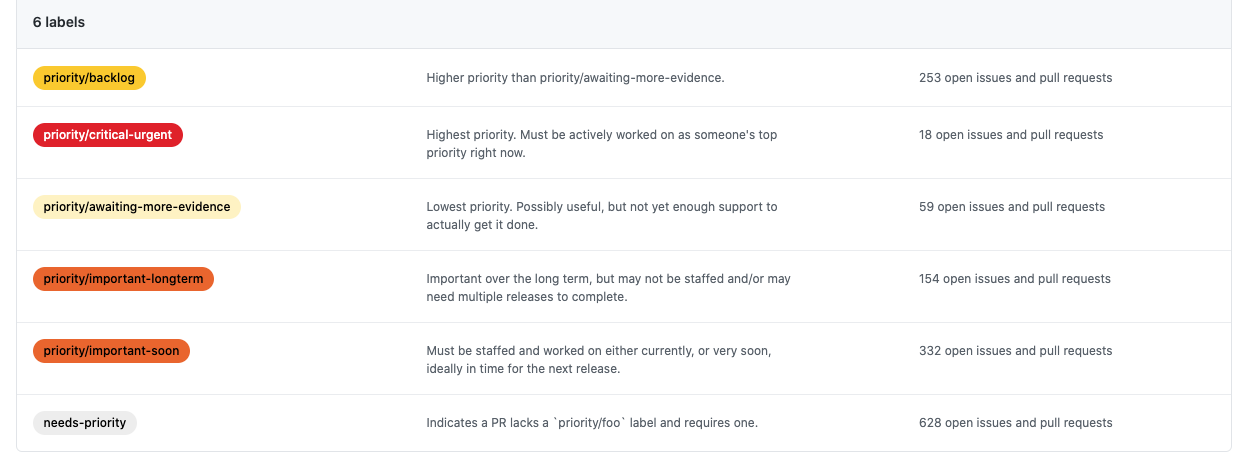
There is still 600+ issues with need-priority
benoitf
on 2 Nov 2020
As for me, I don't see any problems with the triage/prioritization process we have now.
I like the current approach because it's pretty simple and it's easy to understand for the community. IMO it just works. Also, it helps a lot that we have the triage reports regularly posted in the Che Community chat. It allows people who are responsible for a particular Che area to review the triaged issue and (re-)prioritize them if necessary.
I'd like to keep it simple and useful as it is now.
This proposal would change nothing, except that the triager sets a differently named label. Everything else stays the same.
ericwill
on 2 Nov 2020
also I see no difference between P0 and severity/blocker
why then set two different things ?AFAIK, priorities are discussed during some calls, that could be open to anyone.
And if the automated sheet is only sorted by severities, then I still don't get who is going to read/update the priorities ?
Sure, there are corner cases where a small percentage of users could face a blocker issue, but that doesn't mean I or my team will fix it. So it would be labelled severity/blocker but with low priority.
ericwill
on 2 Nov 2020
Milestones are for Github users. To know if an issue is fixed or will be fixed in the next milestone I just at to look at milestones.
Great! So why do we need sprint labels?
https://github.com/eclipse/che/issues?q=is%3Aissue+is%3Aclosed+no%3Amilestone (>8000 closed issues, no milestone)
https://github.com/eclipse/che/issues?q=is%3Aissue+is%3Aclosed+label%3Asprint%2Fnext-sprint+ (100 issues closed in "next sprint" which is about as meaningful as a JIRA closed with fixversion = 2.x or Future)
https://github.com/eclipse/che/issues?q=is%3Aissue+is%3Aclosed+label%3Asprint%2Fcurrent-sprint+ (469 issues closed this sprint)
https://github.com/eclipse/che/issues?q=is%3Aissue+is%3Aclosed+label%3Asprint%2Fcurrent-sprint+no%3Amilestone (358 issues closed this sprint but with no milestone)
So... can we agree that we need:
- severity
- priority
- milestone / fixversion
As to the value of JIRA being low because "most github projects are using github issues"... the argument "I'm using a flawed solution because that's many people do" is hardly compelling. We used to use telegraph machines to send messages, but then we evolved better tools like telephones, the internet, etc. :D
nickboldt
on 2 Nov 2020
I'm just asking what would solve priority for Che users
I think they're only interested to know if in which milestone it will be done.
To me priority for Che users means nothing as you can have external contributors working on issues so setting milestone will inform it
If you talk about dowstream products then for CRW you've company priorities in JIRA. But other dowstream projects may have their own priorities this is why it is not there.
benoitf
on 2 Nov 2020
I'm just asking what would solve priority for Che users
I think they're only interested to know if in which milestone it will be done.To me priority for Che users means nothing as you can have external contributors working on issues so setting milestone will inform it
Severity is for bug reporters (users).
Priority is for people doing the work (community contributors/Red Hat employees/anyone).
We already have priority combined with severity. My proposal is that we simply split the two so its easier to see which bugs are severe, without being forced to sort via priority.
ericwill
on 2 Nov 2020
I personally like the idea to split severity/priority.
I completely agree with @ericwill that priority is mostly for TL.
But actually I set priority implicitly by taking issues in the current sprint. So, setting sprint/current-sprint will do the same job as settings priority/* labels but less to maintain.
 tolusha
on 3 Nov 2020
tolusha
on 3 Nov 2020
I find confusing to mix github severity labels with the name of JIRA priority labels

in JIRA we have
Priority/Blocker
Priority/Critical
Priority/Major
and here we would have same names but for severity ?
benoitf
on 4 Nov 2020
What exactly is confusing about it? We have a completely separate flow and triage process in GitHub (team leads do triage and bugs are reported by anyone) whereas in JIRA bugs are filed and triaged only by Red Hat employees.
ericwill
on 4 Nov 2020
@ericwill to use default JIRA labels for priority in the field github severity
benoitf
on 4 Nov 2020
I mean, it could be helpful to match priority labels with JIRA if they're introduced
priority/blocker
priority/critical
priority/major
priority/minor
and keep severity as it is (or on different levels of P0/P1/P2/P3)
benoitf
on 4 Nov 2020
if you want to use numeric values for severity, please consider SEV instead of P. P = Prio. SEV = Severity.
triaged only by Red Hat employees
To be fair, anyone can use JIRA if they sign up (same's true for GH). It's not restricted to RH people ... in fact we have lots of non-RH and non-IBM people using JIRA for JBoss Tools and Developer Studio, and a few for CRW too.
nickboldt
on 4 Nov 2020
But actually I set priority implicitly by taking issues in the current sprint. So, setting sprint/current-sprint will do the same job as settings priority/* labels but less to maintain.
It's two levels of granularity, and you don't have to use both if it's overkill.
Large grained: set a milestone (or a sprint/ target).
Fine grained: set a priority for within that milestone (or sprint) so that you can more easily see what work you have to do week 1 of the sprint vs. what you can postpone to later in the sprint.
Having 4 different ways to identify when work will be done just gives us flexibility and choice:
- milestone: concrete assignment so everyone knows when work is planned or when it was actually done
sprint label: flexible plan, as "next sprint" can be the next 3 weeks, 6 weeks, 9 weeks, etc.
priority: additional level of identification of when work needs to be done, from the team lead's perspective
- severity: description of the scope of the problem or the urgency, from the customer's perspective
And we like flexibility and choice, right?
nickboldt
on 4 Nov 2020
after reading all the thread again
- There is no need to have split labelling scheme with priority and severity labels (severity will become unmaintained once priority is added) and it could end with inconsistencies.
- There is only a requirement of priority
- Github priority field can be aligned with JIRA priority field. Then JIRA users do know what are the meaning and it's easier to see
criticalthanP2because is P2 something critical or major, etc. Automated sheet will also sort by the same priorities
To not restart from scratch, let's simply rename severity to priority and then each TL can refine its issues and update priorities from there (like moving enhancement with priority/critical or decreasing some bugs to priority/minor
Priority Label
| Label | Description |
| ------------- | ------------- |
| blocker | rename severity/blocker |
| critical | rename severity/P1 |
| major | rename severity/P2 |
| minor | new type but will do what was proposed there: https://github.com/eclipse/che/issues/17997|
| trivial | align with JIRA|
benoitf
on 5 Nov 2020
after reading all the thread again
* There is no need to have split labelling scheme with priority and severity labels (severity will become unmaintained once priority is added) and it could end with inconsistencies.
Yes that is the point, severity != priority. Severity of a bug does not change once the severity has been determined. Priority changes depending on who is working on the issue and what their priorities are.
Currently there is no way to filter bugs only on severity, I have to go through priority which includes all kinds of enhancements, non-severe bugs, etc. This is not useful.
* There is only a requirement of priority * Github priority field can be aligned with JIRA priority field. Then JIRA users do know what are the meaning and it's easier to see `critical` than `P2` because is P2 something critical or major, etc. Automated sheet will also sort by the same priorities
There is a requirement of severity, see above. Currently we have no way of filtering for that. This is a problem that other bug trackers like bugzilla have solved years ago: see sections 11 and 12 of this page.
ericwill
on 5 Nov 2020
There is a requirement of severity,
The requirement on severity does not seems to be shared by all TLs
No one is complaining that on JIRA CodeReady Workspaces, we only see priority field
benoitf
on 5 Nov 2020
There is a requirement of severity,
The requirement on severity does not seems to be shared by all TLs
No one is complaining that on JIRA CodeReady Workspaces, we only see priority field
The change does not negatively affect other TL's if they don't care about severity, we are only adding 3 labels and using them during issue triage instead of the current labels. TL's can still manage their priorities the same way.
ericwill
on 5 Nov 2020
Let's collect some votes here from TLs (per org chart - https://docs.google.com/presentation/d/1Pp-0ER7HT-yXZLF6Uks1KWBPs1ynMJIisWZS6eIe_LE/edit#slide=id.g7c3068dd28_1_19 ):
- @nickboldt - in favour of splitting priority and severity
- @ericwill - in favour
- @azatsarynnyy - in favour https://github.com/eclipse/che/issues/18160#issuecomment-721100216
- @tolusha - in favour https://github.com/eclipse/che/issues/18160#issuecomment-721100216
- @ibuziuk - in favour "could make sense in some cases," but +0 https://github.com/eclipse/che/issues/18160#issuecomment-720551786
And:
- @skabashnyuk no vote
- @sleshchenko no vote
- @l0rd no vote
- @fbricon no vote
- @sunix no vote
- @akurtakov no vote
And votes from non-TLs:
- @benoitf - against
So that's 4 or 5 votes in favour, 6 with no vote, and 1 against (from a non-TL).
Sounds like a passing vote to me.
Since using the new labels is completely optional, and will benefit anyone who chooses to use them, can we just use them and see how it goes?
nickboldt
on 5 Nov 2020
it will affect complexity of the system, readability and maintainability:
- some TL will set priorities, some others won't.
- severity may not be updated as well after initial value
- there was like an implicit severity usage of priority for many people.
so why do we even need to set severity if no-one cares ?
benoitf
on 5 Nov 2020
@nickboldt let's ask : use only priority label
@nickboldt as a big fan of JIRA, there is no severity there, no ?
benoitf
on 5 Nov 2020
@nickboldt let's ask : use only priority label
@nickboldt as a big fan of JIRA, there is no severity there, no ?
In JIRA I get notified of new issues in the components I am responsible for so I am the one triaging them, not someone else.
ericwill
on 5 Nov 2020
True ... but JIRA also has:
- kanban boards where you can reorder your sprint plan by dragging and dropping items, so the need to order by severity or priority is less important
- jql queries that are waaaay more advanced than what you can do in GH for finding your issues
- meaningful milestones (aka affectsversion and fixversion) that are set for EVERY issue, or else jiralint nags the owner to do it correctly
- components that will automatically set the assignee for every new issue, so the TL can triage their inflowing backlog without the need for a round-robin approach and a "needs-triage" label
- email notification when you get a new issue in your backlog, so you immediately know your team has new work being assigned
So it's a smoother & more feature-rich tool, obviating the need to invent workarounds to make filtering and triage easier.
if no-one cares
4 people voting yes = people care. 6 people abstaining = a typical democracy, where less than half the population chooses to exercise their rights. 40% voter turnout is pretty damn good in my experience. Open Source projects are not countries like these https://en.wikipedia.org/wiki/Compulsory_voting#Current_and_past_use_by_countries where voting is compulsory.
nickboldt
on 5 Nov 2020
Since using the new labels is completely optional, and will benefit anyone who chooses to use them, can we just use them and see how it goes?
it's the point there: it should not be optional: all people should use the same system.
if there are priorities they should be used by everyone and should reflect the current priorities of the project.
The overall idea is to have one mechanism to decide priorities across all teams.
If I want to know priorities issues when I look at a github issue, I should not be aware on the team preferences
benoitf
on 5 Nov 2020
I really don't understand what's controversial here. All I am proposing:
- we add some labels for severity
- issue triagers set this label at triage time instead of the severity/priority combination we have right now
- people working on issues, TL's, and architects set priority as before
This does not impact or take anything away from any TL, it just adds some additional metadata whereby those planning the work can better filter issues.
ericwill
on 5 Nov 2020
@ericwill this proposal implies changes in the triage/prioritization flow and to the queries that we use to monitor issues. And we have been working on current triage/prioritization/queries for months. From the comments above it looks like other TLs are happy with the current situation. Looking at other project on GitHub I can't find anyone making this distinction. That may explain the push back.
 l0rd
on 6 Nov 2020
l0rd
on 6 Nov 2020
Related issues
 luckymore0520
·
3Comments
luckymore0520
·
3Comments
 AndrienkoAleksandr
·
3Comments
AndrienkoAleksandr
·
3Comments
 sudheerherle
·
3Comments
sudheerherle
·
3Comments
 apupier
·
3Comments
l0rd
·
3Comments
apupier
·
3Comments
l0rd
·
3Comments