Azure-sdk-for-python: container_client.download_blob("some/path").readall() sometimes results in partial downloads (with HTTP 206 being logged in the httplib)
- Package Name: azure-storage-blob
- Package Version: 12.4.0
- Operating System: Based on docker image python:3.7-slim-buster
- Python Version: CPython 3.7.9
Describe the bug
When downloading a blob, sometimes it gets downloaded only partially and still allows the rest of the code to continue while the docs clearly state the readall method blocks until all data is downloaded (see https://docs.microsoft.com/en-us/python/api/azure-storage-blob/azure.storage.blob.storagestreamdownloader?view=azure-python#readall--).
To Reproduce
Steps to reproduce the behavior:
- Create a container client to
- container_client.download_blob("some/path").readall()
This only fails very sporadically, but is still causing issues in our system as we are downloading many files during a run. We've seen errors being raised during the parsing of the blob contents and when we retry automatically (in the error handling code), it usually comes through. It's only since we integrated Sentry for error reporting that we notice that the underlying httplib is logging a status code of 206, which is likely to be the issue.
Expected behavior
That the code blocks until all data is downloaded, as the documentation states is should.
Screenshots
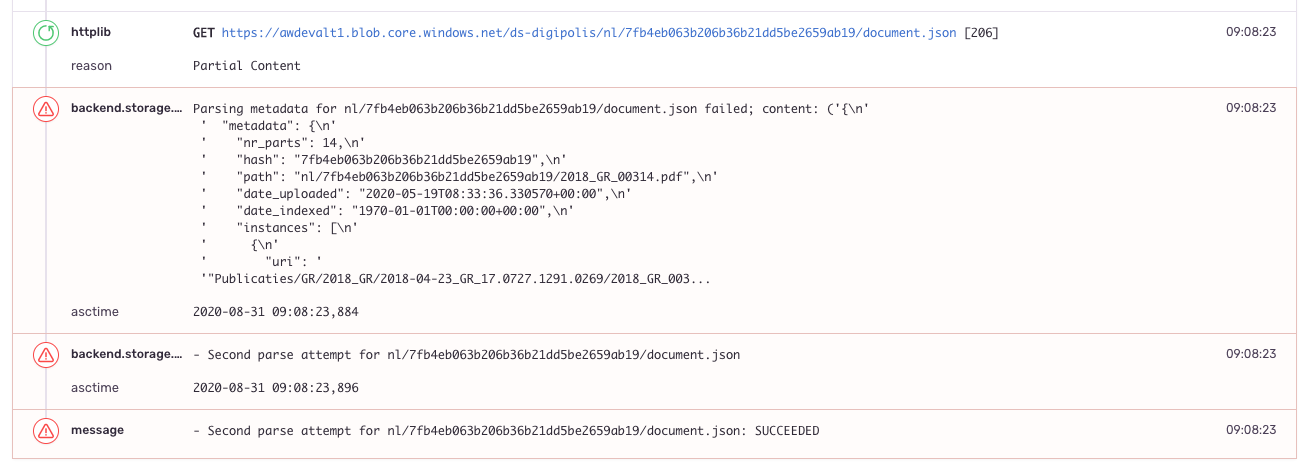
Some snapshots of the logged error in Sentry (in which you can see the breadcrumb in which httplib reports the status code of 206 being received):
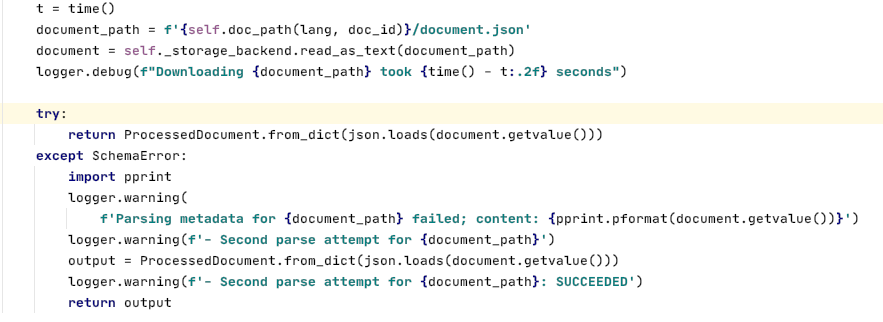
Snapshot of the code triggering the download using a helper method:
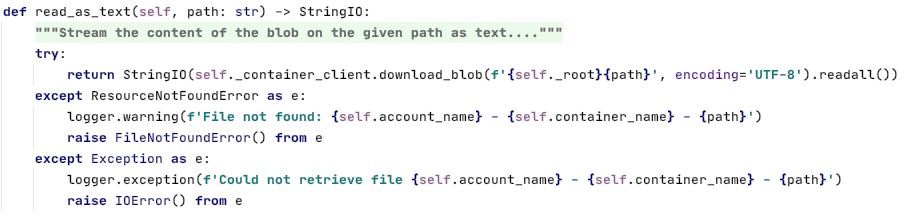
Snapshot of the helper method that uses the Azure SDK to actually download the blob into an stream:
Additional context
We are accessing our storage account from an AKS cluster in the same region using the DefaultAzureCredential combined with aad-pod-identity.
 rblock-aw
rblock-aw
All 9 comments
Thanks for the feedback! We are routing this to the appropriate team for follow-up. cc @xgithubtriage.
![msftbot[bot] picture](https://avatars2.githubusercontent.com/in/26612?v=4&s=40) msftbot[bot]
on 1 Sep 2020
msftbot[bot]
on 1 Sep 2020
Hi @rblock-aw
Thanks for reaching out!
206 is a valid response code. SDK download the blob in chunks by default, and downloading partial blob successfully will give you 206 https://docs.microsoft.com/en-us/rest/api/storageservices/get-blob#status-code.
max_single_get_size defaults to 32 * 1024 * 1024, so if your blob is > 32MB, the remaining content will be downloaded in chunks, each chunk defaults to 4MB. You can set max_single_get_size defaults or max_chunk_get_size as BlobClient/BlobServiceClient/ContainerClient parameter to adjust the single download size.
readall() returns data only after all chunks are downloaded.
Let me know if you need any other info!
 xiafu-msft
on 9 Sep 2020
xiafu-msft
on 9 Sep 2020
Hi @xiafu-msft
I get that it is a valid response code, however, it looks like readall() is returning prematurely. Basically, when retrieving the file and parsing it, it fails due to the input validation (more importantly there is no network error or so being raised, so it looks like the download came through without any issues). However, when retrying when reading from the same buffer, parsing the file contents does work as expected. Also, our files are nowhere near 32MB (our largest files are rarely bigger than 2MB even), so downloading in chunks should not happen (I should also mention we're not overriding the default behaviour for this). From our Sentry bug reports, we've seen the 206 status code, which I agree that it can be a valid response, but it seems that we still run into issues while parsing the file contents afterwards, even if readall should be blocking.
In short: we are already using readall(), chunks should not be happening since our file sizes are small and should not come into play at all due to readall() being blocking but still it looks like our parsing fails due to only having partial file contents. The code and images in the report above should provide plenty context to support my report, I am happy to provide an explanation if it is unclear how these code fragments tie together.
rblock-aw
on 11 Sep 2020
Hi @rblock-aw
I'm pretty sure readall() blocks and will return a string.
Can you try this and see what happens:
- return XXXXXX.readall() directly instead of wrapping it with a StringIO
- do json.loads(document) directly
Thanks for your patience!
xiafu-msft
on 24 Sep 2020
We'll give it a go, but it'll take some time since the error only pops up very sporadically. I'll come back to you when I have collected the necessary data points.
rblock-aw
on 24 Sep 2020
Hi, we're sending this friendly reminder because we haven't heard back from you in a while. We need more information about this issue to help address it. Please be sure to give us your input within the next 7 days. If we don't hear back from you within 14 days of this comment the issue will be automatically closed. Thank you!
msftbot[bot]
on 1 Oct 2020
We're still working on it. As said: it occurs sporadically and we need time to collect the data... I will update this as soon as we have the results in.
rblock-aw
on 2 Oct 2020
I have seen this issue again today with the latest release. No logs, unfortunately, but there is definitely a sporadically occurring issue here.
 malthe
on 25 Oct 2020
malthe
on 25 Oct 2020
Hi @rblock-aw
We will close this issue for now since we didn't get enough info to investigate.
Feel free to let me know if you have any update and we can reopen this issue!
xiafu-msft
on 19 Nov 2020
Related issues
 raviteja59
·
3Comments
raviteja59
·
3Comments
 vnimbalkar
·
4Comments
vnimbalkar
·
4Comments
 yunhaoling
·
3Comments
yunhaoling
·
3Comments
 Koppens
·
4Comments
Koppens
·
4Comments
 smereczynski
·
4Comments
smereczynski
·
4Comments