Azure-functions-durable-extension: Durable Entity serialized size growing with each call
DF 2.2.0
.NET CORE 2.1
Consumption Plan - UK South
I was experimenting with using a Durable Entity as a cache. If the cache misses, it makes a HTTP GET to a service, caches the response data in the entity state and returns the result to the caller. If the cache is hot it just returns the entity state. The Entity is nice here as I can constrain concurrent calls to the Service to 1 by virtue of Durable concurrency model.
[JsonObject(MemberSerialization.OptIn)]
public class FooProxyEntity : IFooProxyEntity
{
private readonly IFooService _fooService;
[JsonProperty("data")]
public JObject Data{ get; set; }
[JsonProperty("expiresOn")]
public DateTime DataExpiresOn { get; set; }
public FooProxyEntity(IFooService fooService )
{
this._fooService= fooService;
}
public async Task<JObject> GetAsync()
{
if (DataExpiresOn < DateTime.UtcNow)
{
Data = await _fooService.GetAsync();
DataExpiresOn = DateTime.UtcNow.AddSeconds(120);
}
return data;
}
[FunctionName(nameof(FooProxyEntity))]
public static Task Run([EntityTrigger] IDurableEntityContext ctx)
=> ctx.DispatchAsync<FooProxyEntity>();
}
I'm calling the Entity from an Orchestration, like so 👍
var proxy = context.CreateEntityProxy<IFooProxyEntity>(id);
var result = await proxy.GetAsync();
I made approx 2,500 orchestration instances, each of which performs the call to the entity. Everything worked as expected, but I did notice some Exceptions in App Insights which were coming from the method DurableTask.AzureStorage.MessageManager.Decompress let me know if you want the full stack trace, but here is a snippet
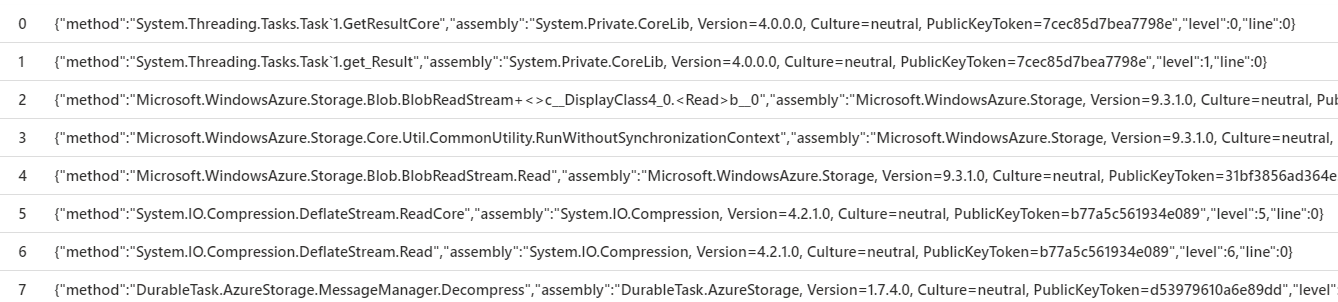
I decided to take a peak at the Entity state by looking in the TaskHubInstances table, and I discovered that the input had a reference to blob location.
After downloading the blob (330kb uncompressed, 135kb compressed) and inspecting the contents, I could see thousands of this object under "ReceivedFromInstance"
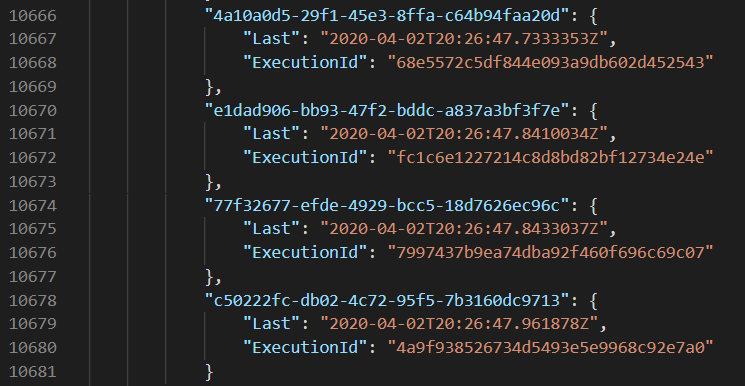
I can reasonably gather that a Call to the entity from the Orchestration results in this extra bit of state, which grows and grows over time with more Calls.
In my high-throughput use-case I'm assuming that this is not going to give the best results out of DF, if its having to serialize this much state on every call. Not to mention the extra over-head and latency of moving that blob across the wire many times.
Is there a better pattern you can recommend that might help prevent this growing state?
As an alternative, I did think about using ReadEntityStateAsync instead of performing a Call, but this won't work because ReadEntityStateAsync isn't going to be deterministic when called in an orchestration. I _could_ perform the ReadEntityStateAsync inside an activity to get the determinism, but then I'm just introducing extra hops and latency into my DF App which I can't afford to take.
 olitomlinson
olitomlinson
All 13 comments
@sebastianburckhardt does this look right to you? I'm worried about the ever-growing state for this entity. Could it be that we have one of these entries per orchestration that invokes the entity?
 cgillum
on 3 Apr 2020
cgillum
on 3 Apr 2020
Yes, this is (unfortunately) expected. Each entity has a message sorter that keeps an entry (a timestamp of the last message received) for each orchestration that it is receiving messages from. Those entries are kept for 30 minutes by default, or as configured in the options:
/// <summary>
/// Gets or sets the time window within which entity messages get deduplicated and reordered.
/// </summary>
public int EntityMessageReorderWindowInMinutes { get; set; } = 30;
Clearly this is not a great design. As you have noticed, it particularly causes problems in situations where an entity receives messages from many different orchestrations or entities in a short time period.
Our long-term plan is to remove the message sorter logic entirely and instead use in-order reliable queues in the back-end. But this new back-end implementation is still under development, so it is not a quick fix.
As a quick workaround, you can lower the parameter or set it to zero (which turns off the message sorting logic completely). Note however that it means that messages sent to entities (by orchestrations or by other entities) may be delivered out of order and/or duplicated.
 sebastianburckhardt
on 3 Apr 2020
sebastianburckhardt
on 3 Apr 2020
We could also fix this by having the orchestration send a special termination message to the entity when it terminates which then removes the entry.
sebastianburckhardt
on 3 Apr 2020
@sebastianburckhardt Thanks very much!
In my use-case where I use an Entity as a cache, I can probably get away with having EntityMessageReorderWindowInMinutes set to zero, as I can sacrifice precision for throughput!
I'll give it a go and report back.
EDIT: Btw let me know if/when you need any early testing effort on the new back-end, I would happily contribute my time.
olitomlinson
on 3 Apr 2020
@sebastianburckhardt - by"in-order reliable queues" are you referring to an Azure Service Bus implementation or maybe this will be configurable (support for Redis, Azure Service Fabric, SQL Server) etc? Thanks!
 MedAnd
on 7 Apr 2020
MedAnd
on 7 Apr 2020
We plan to make it configurable, though the first version of it uses EventHubs for the queues, since it best matches our requirements (it provides in-order reliable delivery, as well as load balancing of partitions, and supports long polling). Another alternative we want to support (soon-ish) is a simple queue built on top of Azure Tables.
For the storage part, we are going to use (https://github.com/Microsoft/FASTER) layered on top of Azure PageBlobs.
sebastianburckhardt
on 7 Apr 2020
@sebastianburckhardt - maybe I should ask these via twitter 🙂 but the idea to leverage FASTER in Durable Functions reminds me of another very promising and high throughput MS Research technology with similar features... wondering if there are any plans for incorporating project AMBROSIA into Azure Functions?
cc @jongoldDB
MedAnd
on 8 Apr 2020
Yes, this has long been our plan. We have no shortage of great plans! It takes a while to execute them though 🙂. We'll get there eventually. AMBROSIA seems ideal in particular for a K8s/KEDA scenario.
sebastianburckhardt
on 8 Apr 2020
@sebastianburckhardt @cgillum
I'm revisiting this with a new use-case to see if anything has changed now that I'm using entity-to-entity signalling rather than orchestration-to-entity signalling. The pattern is still the same with many thousand of individual entities all concentrating a few signals each onto the one aggregator entity.
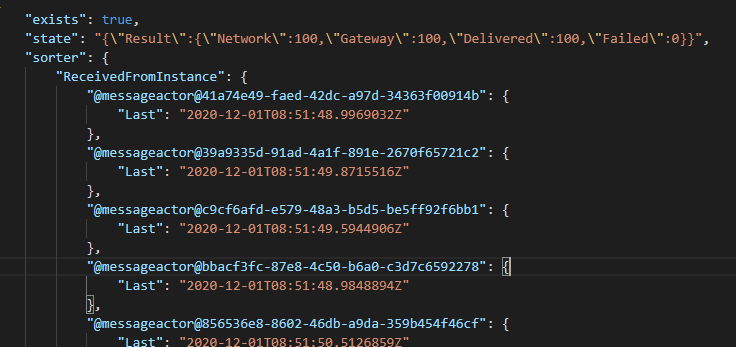
Unfortunately, I still can't use Entities as a precise aggregator/counter as the sorter history becomes too big when trying to aggregate several thousands of signals made to the Entity.
With the Netherite provider, Is it still an objective to fix this expanding history to make this high-volume/high-frequency/high-precision _aggregator_ use-case viable?
olitomlinson
on 1 Dec 2020
Yes, Netherite solves this problem. The state will no longer contain any "sorter" entries.
With Netherite, the message sorting logic is superfluous, because EventHubs already guarantees per-partition in-order delivery, and it gets turned off automatically.
sebastianburckhardt
on 3 Dec 2020
@sebastianburckhardt Awesome! I can't wait to try it out!
olitomlinson
on 3 Dec 2020
@olitomlinson The Netherite early preview is now public, if you want to try it out! It is in the microsoft/durabletask-netherite GitHub repository.
sebastianburckhardt
on 9 Dec 2020
@sebastianburckhardt Awesome - There goes my weekend! :D
olitomlinson
on 9 Dec 2020
Related issues
 pacodelacruz
·
3Comments
cgillum
·
4Comments
pacodelacruz
·
3Comments
cgillum
·
4Comments
 thomas-schreiter
·
3Comments
thomas-schreiter
·
3Comments
 val-janeiko
·
3Comments
val-janeiko
·
3Comments
 ethanroday
·
4Comments
ethanroday
·
4Comments
Most helpful comment
We plan to make it configurable, though the first version of it uses EventHubs for the queues, since it best matches our requirements (it provides in-order reliable delivery, as well as load balancing of partitions, and supports long polling). Another alternative we want to support (soon-ish) is a simple queue built on top of Azure Tables.
For the storage part, we are going to use (https://github.com/Microsoft/FASTER) layered on top of Azure PageBlobs.