Arctos: How to handle large cross-institution data download requests
Example request:
On Thu, Aug 1, 2019 at 10:32 AM Dusty dustymc@gmail.com wrote:
Any objections to sending these data for all Rodentia?
---------- Forwarded message ---------
From: Alyssa Vanerelli avanerel@unca.edu
Date: Thu, Aug 1, 2019 at 8:53 AM
Subject: Large data file transfer
To: dustymc@gmail.com
Cc: Brock Wooldridge twooldridge@g.harvard.edu
Dear Dusty,
I am an undergraduate student working on a research project in Dr. Hopi Hoekstra’s lab at Harvard University. The project I am working on involves investigating arboreal adaptations in rodents by using museum records to examine how key morphological traits associate with habitat type. Your database has been extremely helpful in providing records for our analyses, but so far we’ve restricted ourselves to just a few key clades within rodents. Ideally, we would like to take an unbiased look at all rodents, but we recognize that a dataset of this size is not possible to download via the normal browser interface at the moment. Depending on the file size, could we arrange a data transfer? If so, the columns we would need are GUID, SCIENTIFIC_NAME, CITATIONS, COORDINATEUNCERTAINTYMEASURES, COUNTRY, STATE_PROV, HABITAT, SPEC_LOCALITY, VERBATIM_DATE, PARTS, DEC_LAT, DEC_LONG, COLLECTING_EVENT_ID, SEX, AGE, AGE_CLASS, EAR_FROM_NOTCH, HIND_FOOT_WITH_CLAW, TAIL_LENGTH, TOTAL_LENGTH, WEIGHT, and IDENTIFICATION_REMARKS. Thank you for your time and consideration and I look forward to hearing from you.
Best,
Alyssa Vanerelli
 Jegelewicz
Jegelewicz
All 16 comments
Collections involved:
On Thu, Aug 1, 2019 at 11:10 AM Dusty dustymc@gmail.com wrote:
I think https://datadryad.org/ can provide DOI, but from here that looks like something that would need to happen between the researcher and the collection. I'm happy to facilitate, but I don't think this can realistically be Arctos' job.
I could set up an Archive, but locking that so it can have a DOI is a curatorial commitment which I am again not in a position to make. And this is 627158 records - there would likely be performance problems.
Ideally citations would be individual and machine-readable - DOIs or http://arctos.database.museum/guid/UAM:Arc:UA71-026-1381f or similar - but none of that's very realistic for most of a million records.
I could include contact information - maybe collection's data quality contact's email? - and instruct them to consult with the collection before publication.
At best, the attribute information is smooshed up into a text string in GBIF, and I don't think many of these collections are there at all. I'd not want to be directed there if I was trying to get these data! https://github.com/ArctosDB/arctos/issues/2141 might make that more tolerable (or melt GBIF...)
Data loans are again something that's up to the collection. Loans are behind VPDs, so cross-collection loans aren't really practical (except eg, MVZ where there's an existing cross-collection pathway).
There are no hard limits, but attributes are expensive to query - it took about 9 minutes to build the table, and a couple more to transfer it to my computer.
Here's who's involved.
UAM@ARCTOS> select substr(guid,1,instr(guid,':',1,2)-1),count(*) from temp_rodent group by substr(guid,1,instr(guid,':',1,2)-1) order by substr(guid,1,instr(guid,':',1,2)-1);
SUBSTR(GUID,1,INSTR(GUID,':',1,2)-1)
------------------------------------------------------------------------------------------------------------------------
COUNT(*)
----------
ALMNH:ES 48
ASNHC:Mamm 47
CHAS:Bird 2
CHAS:Mamm 3596
CHAS:Teach 108
COA:Mamm 88
DGR:Bird 4
DGR:Mamm 394
DMNS:Mamm 10453
MLZ:Mamm 1880
MSB:Host 10489
MSB:Mamm 247059
MSB:Para 1
MVZ:Hild 57
MVZ:Mamm 181188
MVZObs:Mamm 94
NMU:Mamm 1751
OWU:ES 3
OWU:Mamm 71
UAM:Arc 68
UAM:ES 2494
UAM:Mamm 49673
UAMObs:Mamm 42
UCM:Mamm 12991
UCM:Obs 1
UCSC:Mamm 177
UMNH:Mamm 34984
UMZM:Mamm 7549
UNR:Mamm 1623
UTEP:Arc 73
UTEP:ES 7398
UTEP:Mamm 5722
UTEP:Teach 27
UWBM:Mamm 37050
UWYMV:Mamm 4769
WNMU:Mamm 5184
Jegelewicz
on 2 Aug 2019
They are requesting data which they could have downloaded from the interface by making an account. There are basic statistics for that...
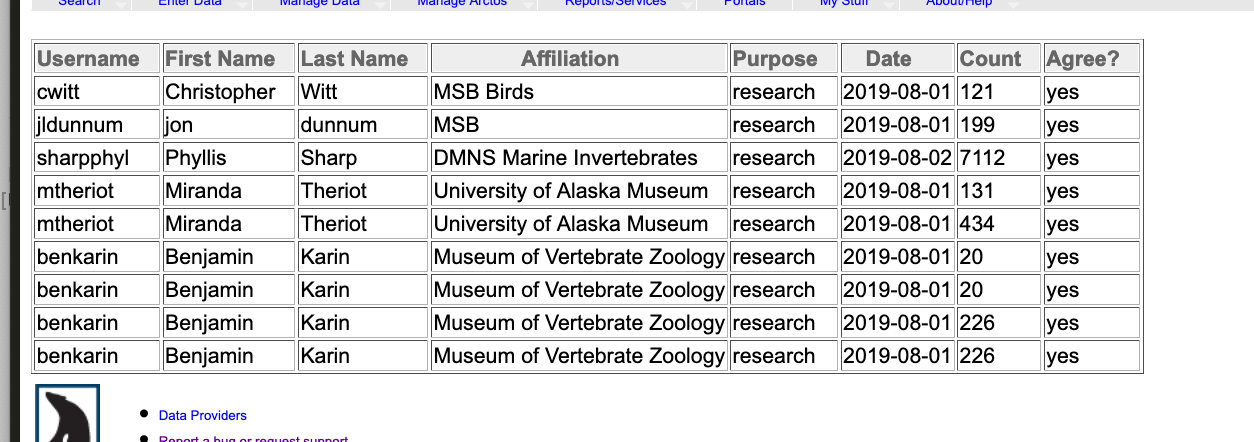
... but they don't approach the level of detail the email conversation suggests we'd like to have.
Crazy perhaps not entirely actionable idea: auto-make data loans (the structure - this would probably need a new dedicated loan type) for all downloads.
 dustymc
on 2 Aug 2019
dustymc
on 2 Aug 2019
Can anyone download this many records from the interface without a timeout?
Especially with attributes? Or is there some other type of account I am
unaware of?
I am in favor of auto-making data loans in these situations - with email to
cm to approve.
On Fri, Aug 2, 2019 at 9:52 AM dustymc notifications@github.com wrote:
They are requesting data which they could have downloaded from the
interface by making an account. There are basic statistics for that...[image: Screen Shot 2019-08-02 at 8 50 25 AM]
https://user-images.githubusercontent.com/5720791/62382539-9e2fb700-b502-11e9-9051-00dc1c66c6a4.png... but they don't approach the level of detail the email conversation
suggests we'd like to have.Crazy perhaps not entirely actionable idea: auto-make data loans (the
structure - this would probably need a new dedicated loan type) for all
downloads.—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
https://github.com/ArctosDB/arctos/issues/2205?email_source=notifications&email_token=ADQ7JBFU2LY7TZZOKWVK2CTQCRJ5BA5CNFSM4II66WYKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD3OENCQ#issuecomment-517752458,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ADQ7JBBUFYBX523INAGVR4TQCRJ5BANCNFSM4II66WYA
.
 campmlc
on 2 Aug 2019
campmlc
on 2 Aug 2019
Can anyone download this many records from the interface without a timeout?
"It depends" but it's not entirely unrealistic.
with attributes
That's currently unrealistic as a single download. Anyone can certainly patch this together - eg, use the summary to find some terms (geography maybe) and use that to split it in to smaller queries.
some other type of account
Nope, but ya'll could have SQL access to create temp tables and I was able to download via CSV any table.
auto-making data loans in these situations - with email to cm to approve.
Pick one! I can (in theory, somehow, probably, with some work...) just make the loans, or I can send/save/something a template suitable for creating data loans.
dustymc
on 2 Aug 2019
Hi Alyssa,
The data you requested are attached. Let me know if you need something different.
Please let us know which of these data are used in any publications (in the most general sense of the word), projects, web pages, etc. Many collections will wish to create loans and projects, which is both critical to documenting collection usage and provides a way to explore these specimens in the context of other publications and projects. I am happy to coordinate that, and we can provide you with citable identifiers suitable for publication. (We can work out the details once we know more.)
Thanks - D
The zip should now be accessible at https://app.box.com/s/i8nk69mvdk2ezkqaw74gkxkhqws8qd2w
Jegelewicz
on 2 Aug 2019
auto-making data loans in these situations - with email to cm to approve.Pick one! I can (in theory, somehow, probably, with some work...) just make the loans, or I can send/save/something a template suitable for creating data loans.
I love this idea and I think option no 2
send/save/something a template suitable for creating data loans
makes most sense, as some collections may not want to do this. I'd love it if I got a notification: "data has been downloaded from your collection, would you like to create a data loan? Y/N" with a table of the data downloaded and the username of the downloader. Selecting yes would create the loan and send me to the edit loan form, where I could edit as necessary, then save. I also like the idea of a specific type of loan to delineate these from specific requests. So maybe data loan auto or something like that?
Jegelewicz
on 2 Aug 2019
downloaded
Should we require more information/confirmation/something from users who download? There's (probably) SOME value in "completelyMeaninglessUsername downloaded some data for these 500 specimens," but there's a lot more if we can somehow link that to future publications, loan requests, etc. ORCID is the obvious solution, but that may be a fairly high bar for exploratory downloads, high school teachers, etc., and it would scare off some potential users. I don't have any great ideas, and I do like easy accessibility at this stage, but perhaps something to consider.
dustymc
on 2 Aug 2019
Yes. We should require a name and purpose, min 500 char?? project
description, PI name and Institution and maybe funding agencies required or
optional?
On Fri, Aug 2, 2019, 10:55 AM dustymc notifications@github.com wrote:
downloaded
Should we require more information/confirmation/something from users who
download? There's (probably) SOME value in "completelyMeaninglessUsername
downloaded some data for these 500 specimens," but there's a lot more if we
can somehow link that to future publications, loan requests, etc. ORCID is
the obvious solution, but that may be a fairly high bar for exploratory
downloads, high school teachers, etc., and it would scare off some
potential users. I don't have any great ideas, and I do like easy
accessibility at this stage, but perhaps something to consider.—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/ArctosDB/arctos/issues/2205?email_source=notifications&email_token=ADQ7JBGQ2XMYDH2F7OCGMT3QCRRHFA5CNFSM4II66WYKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD3OJMFA#issuecomment-517772820,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ADQ7JBARFSCFT4CMZKKFUZLQCRRHFANCNFSM4II66WYA
.
campmlc
on 10 Aug 2019
It would be valuable to be able to track the Funding Sources (and Grant
numbers) for both loans and data requests. That's an important metric that
most of us are not tracking.
On Fri, Aug 9, 2019 at 5:47 PM Mariel Campbell notifications@github.com
wrote:
Yes. We should require a name and purpose, min 500 char?? project
description, PI name and Institution and maybe funding agencies required or
optional?On Fri, Aug 2, 2019, 10:55 AM dustymc notifications@github.com wrote:
downloaded
Should we require more information/confirmation/something from users who
download? There's (probably) SOME value in "completelyMeaninglessUsername
downloaded some data for these 500 specimens," but there's a lot more if
we
can somehow link that to future publications, loan requests, etc. ORCID
is
the obvious solution, but that may be a fairly high bar for exploratory
downloads, high school teachers, etc., and it would scare off some
potential users. I don't have any great ideas, and I do like easy
accessibility at this stage, but perhaps something to consider.—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<
https://github.com/ArctosDB/arctos/issues/2205?email_source=notifications&email_token=ADQ7JBGQ2XMYDH2F7OCGMT3QCRRHFA5CNFSM4II66WYKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD3OJMFA#issuecomment-517772820
,
or mute the thread
<
https://github.com/notifications/unsubscribe-auth/ADQ7JBARFSCFT4CMZKKFUZLQCRRHFANCNFSM4II66WYA.
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
https://github.com/ArctosDB/arctos/issues/2205?email_source=notifications&email_token=ABOHKESWUXS2NLJJP3LRW5LQDXXW3A5CNFSM4II66WYKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD376RGQ#issuecomment-520087706,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ABOHKEX22ZAW5PC2FXNWBGDQDXXW3ANCNFSM4II66WYA
.
 tucojoe
on 10 Aug 2019
tucojoe
on 10 Aug 2019
Downloads include things like K12 student projects; 500 characters and a funding agency seems like it would kill something we've been pushing as part of our mission for a long time.
Some of the CC licenses may legally prohibit further restrictions; demanding funding information before accessing licensed data seems like a great way to find out how sue-able we really are.
Individual collections own and control the data and are positioned to address much of this via licensing. MSB:Mamm uses Arctos Data Ownership and Use (https://arctosdb.org/data/), in which I don't see anything that would inspire me to ask for a data loan (and some dangerous citation instructions).
It's probably worth keeping in mind that we're "competing" with things like GBIF, who generally require free-use licenses. If this becomes too much of an obstacle users are likely to just forget whatever cool thing they wanted from Arctos, download from GBIF, and cite nothing. (Does anyone consider that when determining what to share via DWC?)
There's a place for funding information in Projects, which I think is structurally correct. https://www.crossref.org/services/funder-registry/ has come to exist; adding a "provide fundref and orcid data in any publications" clause to loans would make it easy to tie deeper into funding data.
I don't think it would be burdensome for Arctos to request more data from users who download. I think I can do more with data as it's being downloaded. Beyond that, this looks more and more like a 'licensing' (including eg, loan agreements) issue to me.
Here are the 14 (of 2823) projects with funding information.
http://arctos.database.museum/project/10002576
http://arctos.database.museum/project/10002320
http://arctos.database.museum/project/10003135
http://arctos.database.museum/project/10003174
http://arctos.database.museum/project/10003069
http://arctos.database.museum/project/10002450
http://arctos.database.museum/project/10003070
http://arctos.database.museum/project/10002647
http://arctos.database.museum/project/10001967
http://arctos.database.museum/project/10003147
http://arctos.database.museum/project/10003155
http://arctos.database.museum/project/10003002
http://arctos.database.museum/project/10002872
http://arctos.database.museum/project/10002523
Here's licensing data:
GUID_PREFIX DISPLAY
-------------------- ------------------------------------------------------------------------------------------
ALMNH:ES CC BY
APSU:Bird
APSU:Fish
APSU:Herp
APSU:Mamm
ASNHC:Herb CC BY
ASNHC:Mamm CC BY
ASUMZ:Bird CC BY
ASUMZ:Bivalve CC BY
ASUMZ:Ento CC BY
ASUMZ:Fish CC BY
ASUMZ:Herp CC BY
ASUMZ:Invert CC BY
ASUMZ:Mamm CC BY
BYU:Herp Arctos Data Ownership and Use
CHAS:Bird CC0
CHAS:EH CC0
CHAS:ES CC0
CHAS:Egg CC0
CHAS:Ento CC0
CHAS:Fish CC0
CHAS:Herb CC0
CHAS:Herp CC0
CHAS:Inv CC0
CHAS:Mamm CC0
CHAS:Teach CC0
COA:Bird
COA:Egg
COA:Ento
COA:Herp
COA:Mamm
COA:Rept
DGR:Bird
DGR:Ento
DGR:Mamm
DMNS:Bird CC BY-NC
DMNS:Egg CC BY-NC
DMNS:Herp CC BY-NC
DMNS:Inv CC0
DMNS:Mamm CC BY-NC
DMNS:Para CC BY-NC
HWML:Para
KNWR:Ento CC0
KNWR:Herb CC0
KNWR:Inv CC0
KNWRObs:Fish CC0
KNWRObs:Herb CC0
KNWRObs:Mamm CC0
KWP:Ento CC BY
MLZ:Bird Arctos Data Ownership and Use
MLZ:Egg Arctos Data Ownership and Use
MLZ:Herb
MLZ:Mamm Arctos Data Ownership and Use
MSB:Bird
MSB:Fish
MSB:Herp Arctos Data Ownership and Use
MSB:Host Arctos Data Ownership and Use
MSB:Mamm Arctos Data Ownership and Use
MSB:Para Arctos Data Ownership and Use
MSBObs:Mamm
MVZ:Bird CC0
MVZ:Egg CC0
MVZ:Herp CC0
MVZ:Hild CC0
MVZ:Mamm CC0
MVZObs:Bird CC0
MVZObs:Fish
MVZObs:Herp CC0
MVZObs:Mamm CC0
NBSB:Bird
NMMNH:Bird CC BY
NMMNH:Ento CC BY
NMMNH:Fish CC BY
NMMNH:Geol CC BY
NMMNH:Herb CC BY
NMMNH:Herp CC BY
NMMNH:Inv CC BY
NMMNH:Mamm CC BY
NMMNH:Paleo CC BY
NMU:Bird CC0
NMU:Ento
NMU:Fish
NMU:Herb
NMU:Herp
NMU:Mamm CC0
NMU:Para CC0
OWU:Amph CC BY
OWU:Bird CC BY
OWU:EH CC BY
OWU:ES CC BY
OWU:Ento CC BY
OWU:Fish CC BY
OWU:Geol CC BY
OWU:Herb CC BY
OWU:Inv CC BY
OWU:Mamm CC BY
OWU:Para CC BY
OWU:Rept CC BY
PSU:Mamm
STAR:Alg CC BY
STAR:Herb CC BY
UAM:Alg CC BY-NC
UAM:Arc
UAM:Art Arctos Data Ownership and Use
UAM:Bird CC BY-NC
UAM:EH CC BY-NC-ND
UAM:ES Arctos Data Ownership and Use
UAM:Ento CC BY
UAM:Env
UAM:Fish Arctos Data Ownership and Use
UAM:Herb CC BY-NC
UAM:Herp Arctos Data Ownership and Use
UAM:Inv Arctos Data Ownership and Use
UAM:Mamm CC BY-NC-SA
UAMObs:Bird CC BY-NC
UAMObs:EH
UAMObs:Ento CC BY
UAMObs:Fish
UAMObs:Mamm Arctos Data Ownership and Use
UAMb:Herb CC BY
UC-SCFS:Bird CC0
UC-SCFS:Mamm CC0
UCM:Bird CC BY
UCM:Egg CC BY
UCM:Fish CC BY
UCM:Herp CC BY
UCM:Mamm CC BY
UCM:Obs CC BY
UCSC:Bird CC0
UCSC:Fish Arctos Data Ownership and Use
UCSC:Herp Arctos Data Ownership and Use
UCSC:Mamm Arctos Data Ownership and Use
UMNH:Bird CC0
UMNH:Ento
UMNH:Herp CC0
UMNH:Mala
UMNH:Mamm CC0
UMNH:Teach CC BY
UMNHObs:Mamm CC BY
UMZM:Bird CC0
UMZM:Mamm CC0
UNM:ES
UNR:Bird
UNR:Egg
UNR:Fish
UNR:Herp
UNR:Mamm
USNPC:Para
UTEP:Arc CC BY
UTEP:Bird CC BY
UTEP:ES CC BY
UTEP:Ento CC BY
UTEP:Fish CC0
UTEP:Herb CC BY
UTEP:Herp CC BY
UTEP:HerpOS CC BY
UTEP:Inv CC BY
UTEP:Mamm CC BY
UTEP:Teach CC BY
UTEP:Zoo CC BY
UTEPObs:Ento
UTEPObs:Herp CC BY
UWBM:Herp Arctos Data Ownership and Use
UWBM:Mamm Arctos Data Ownership and Use
UWYMV:Bird Arctos Data Ownership and Use
UWYMV:Egg Arctos Data Ownership and Use
UWYMV:Fish Arctos Data Ownership and Use
UWYMV:Herp Arctos Data Ownership and Use
UWYMV:Mamm Arctos Data Ownership and Use
WNMU:Bird
WNMU:Fish
WNMU:Mamm
Obviously we need a licensing webinar.
Jegelewicz
on 12 Aug 2019
Dusty, this may be the case for regular downloads, but when we get a
request such as this rodent dataset, we should ask for more specific
information in order to set up the loans at each collection that chooses to
do so.
I would want:
1) Name of requestor and PIs
2) Project description, including how these data will be used
3) Funding agencies and grant numbers, if any
What else?
On Mon, Aug 12, 2019 at 10:31 AM Teresa Mayfield-Meyer <
[email protected]> wrote:
Obviously we need a licensing webinar.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/ArctosDB/arctos/issues/2205?email_source=notifications&email_token=ADQ7JBE4AAW5OWUDMTDQL2LQEGF4PA5CNFSM4II66WYKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD4DCVPQ#issuecomment-520497854,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ADQ7JBFQYHGMGB6K4V6QS6DQEGF4PANCNFSM4II66WYA
.
campmlc
on 12 Aug 2019
licensing webinar
Yes! Sorta...
- I think it should be broad enough to include "licenses" like loan agreements, and
- I'm not sure a webinar is the best format; I suspect (mostly from things like citations per loaned item stats) that some sort of open discussion would be more effective at finding what works, what doesn't, in which situations things work, etc.
@campmlc if I faced that situation I might just pull smaller datasets and stitch them back together - anyone could very easily do that, and we provide documentation (including a way around the download process) for how to do so. I'm not sure doing something special for people who don't find a way around minor technical limitations of certain approaches addresses the concern.
dustymc
on 12 Aug 2019
This is one place to start.
Jegelewicz
on 12 Aug 2019
Could we have something where people have to check a box when they download data that has the basics of a loan agreement (we agree to cite the collections who data we have downloaded in any publication and provide a copy of the published material to the collection)?
Something similar to the Download Agreement we have now when you download data, but expanded to include more loan info with maybe a link to the portals so people know where to find the contact info for curators?
For individual museums keeping track of those downloads, I'm a little worried about creating something that I have to check and review every single time someone downloads some of our data. We just don't have the man power for that.
Maybe instead a monthly report like we get from Vertnet on how our data is being downloaded? I know we can get some of that data under reports, but I can never get the Download Agreements or Query Statistics to work without timing out.
 ewommack
on 14 Aug 2019
ewommack
on 14 Aug 2019
Yes, we can easily modify the download agreement, which already contains a form of an acknowledgement. We should probably also mention that the license included with each specimen record takes precedence over the download agreement. Here's what's there now.
These data are intended for use in education and research and may not be repackaged, redistributed, or sold in any form without prior written consent from the Museum. Those wishing to include these data in analyses or reports must acknowledge the provenance of the original data and notify the appropriate curator prior to publication. These are secondary data, and their accuracy is not guaranteed. Citation of the data is no substitute for examination of specimens. The Museum and its staff are not responsible for loss or damages due to use of these data.
Yes I can send reports as email, but we should probably solidify what's being captured first. Here's a summary for scale.
UAM@ARCTOS> select sum(num_records) from cf_download where DOWNLOAD_DATE>=to_date('2019-07-14');
SUM(NUM_RECORDS)
----------------
851678
UAM@ARCTOS> select sum(sum_count) from query_stats where CREATE_DATE>=to_date('2019-07-14');
SUM(SUM_COUNT)
--------------
29510680
Related issues
 ccicero
·
8Comments
ccicero
·
8Comments
 acdoll
·
8Comments
Jegelewicz
·
6Comments
acdoll
·
8Comments
Jegelewicz
·
6Comments
 alexkrohn
·
3Comments
alexkrohn
·
3Comments
 DerekSikes
·
3Comments
DerekSikes
·
3Comments
Most helpful comment
Should we require more information/confirmation/something from users who download? There's (probably) SOME value in "completelyMeaninglessUsername downloaded some data for these 500 specimens," but there's a lot more if we can somehow link that to future publications, loan requests, etc. ORCID is the obvious solution, but that may be a fairly high bar for exploratory downloads, high school teachers, etc., and it would scare off some potential users. I don't have any great ideas, and I do like easy accessibility at this stage, but perhaps something to consider.