Amphtml: Amp Caching: Numerous stale versions of the same article appearing in search
What's the issue?
There are essentially three different issues at play here with caching that may all be interconnected in some way. These are all big problems for us in recent times as we have upped our live-blog style articles during the Corona pandemic. On the advice of @morsssss, I decided to write a new issue here.
1. Article content refreshes inconsistently, often stale
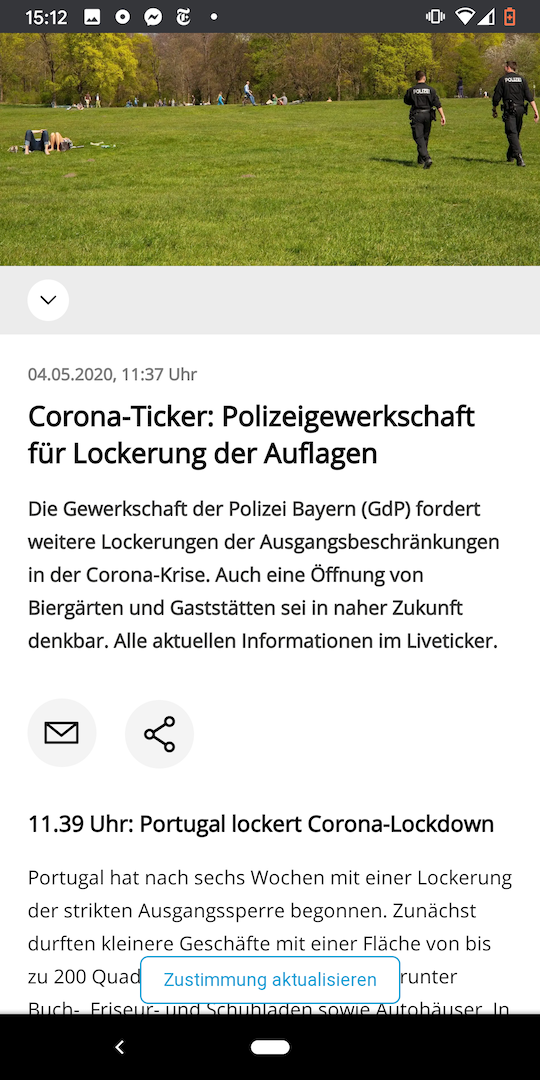
Despite a max-age set to 1000, I have seen in search results articles up to around 24 hours old. At the moment of writing I checked the main article I have been concerned with (and the one that will be referenced in examples throughout this issue) and it was ˜16 hours stale. I checked it again a few minutes later and the content is now ˜26 hours stale. A few minutes later again and it is actually now the fresh article. I took a screenshot of one of these on my phone. Note the time on my phone and the time of the article update (a day ago at 2:30pm)
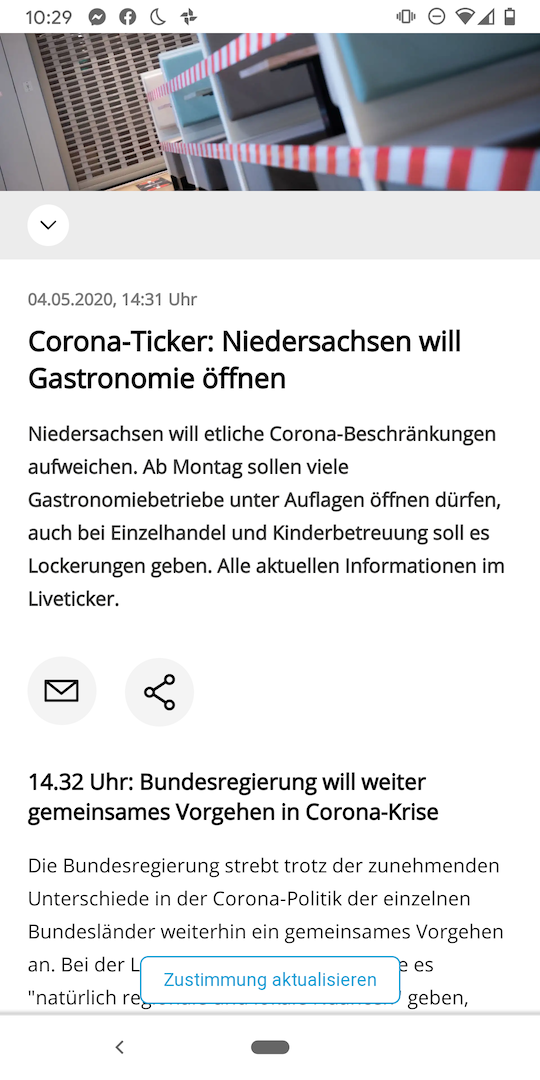
Meaning that yes, sometimes accessing the same article can be like going back in time. Sometimes though it can be really up to date.
2. There are duplicate versions of the stale articles appearing in Google search
This is another odd thing that has been happening. I presumed it was because the editors can change the slug in the CMS, and our server was resolving those articles when reached with a old slug without redirecting. Of course AMP wouldn't know that they are supposed to be the same article. Since this was reported we set up the server to 301 redirect amp articles with outdated or incorrect slugs to the current one, but the behavior seems to have persisted.
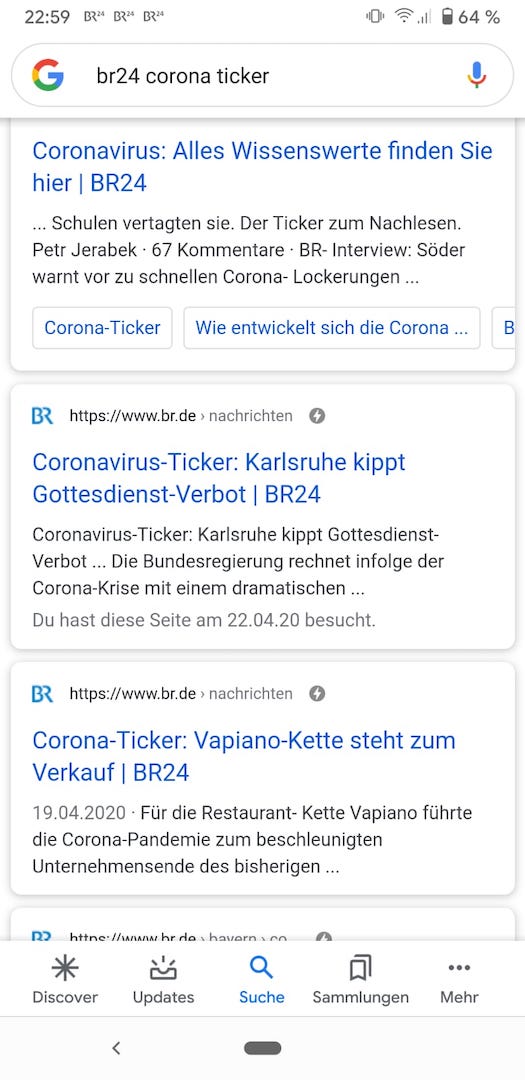
Worth noting that the normal versions of the page are not set to redirect so maybe that needs to be changed, but the canonical link is dynamically updated in the article data sent to the amp pages when the slug changes. And the documentation just says
Any time you move the location of AMP files on your server, set up redirects from old locations to new locations. The Google AMP Cache follows redirects when resolving AMP URLs.
If a URL redirects to another valid AMP URL, the Google AMP Cache returns and caches the content of the resolved redirect.
3. The update-cache url generated is met with an ingestion error despite attempting to follow the documentation and using amp-toolbox.
Edit: I was given by our team the wrong rsa public key. This has been resolved, but had no discernible difference in the outcome.
How do we reproduce the issue?
The simplest way to reproduce this issue is to sporadically search for coronaticker br24 on a device that can view amp articles (looking for either Corona-Ticker: or Coronavirus-ticker: the other variants are different articles for the regions of Bavaria) , or to go to directly to this link https://www.br.de/nachrichten/amp/deutschland-welt/live-ticker-corona-karlsruhe-kippt-gottesdienst-verbot,Rt6bDgj where the amp article is served.
I will also post here a specific example of doing this with screenshots.
- Search
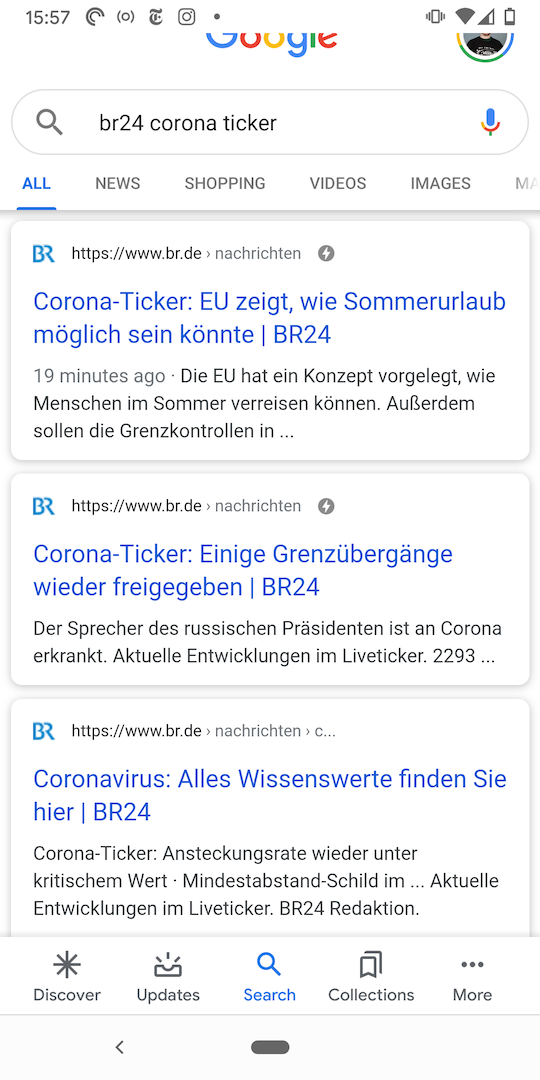
coronaticker br24and click on the matching amp article in the results Note the time of the last update. There is an update on average every 30 minutes.
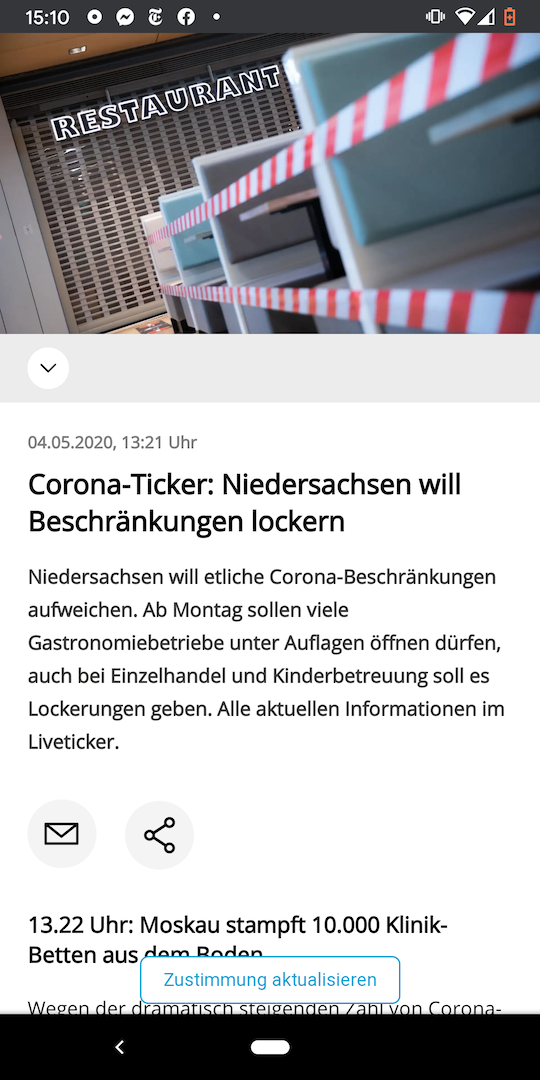
Visit that same article and note the time of the last update there.
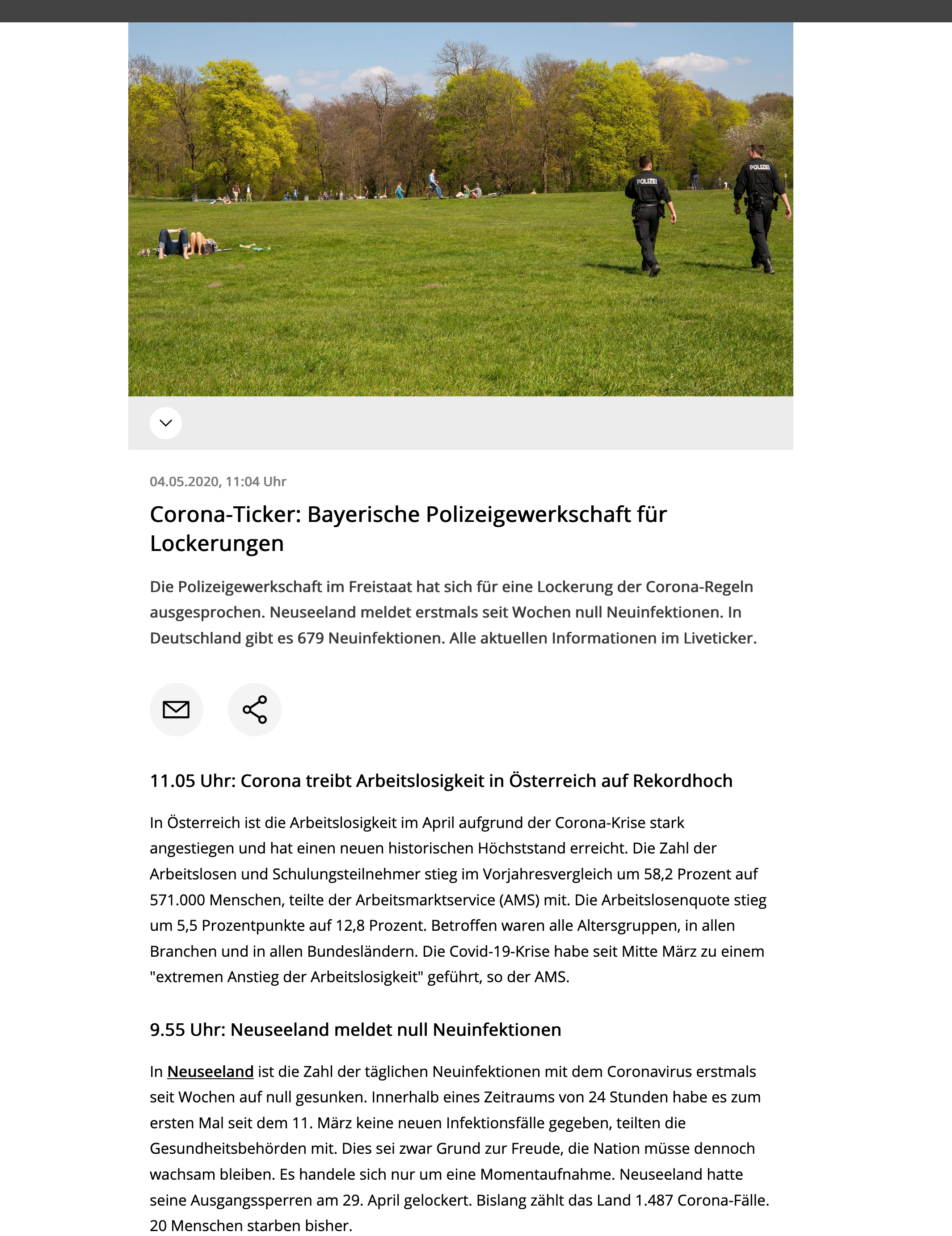
Repeat step 1-2. You could possibly see the same update as in step 3 like I did with this screenshot from yesterday, or something entirely different.
What browsers are affected?
All browsers, that I know of.
Which AMP version is affected?
We have had problems with caching for awhile but an earnest effort to fix them has only been going on in the last couple of months.
So I will just put the current version: 2004240001480
Final Notes
I just wanted to include the response headers sent by the amp pages in case that is helpful.
HTTP/1.1 200 OK
Server: openresty/1.15.8.1
Content-Type: text/html; charset=utf-8
x-powered-by: https://www.brnext.de/
Access-Control-Allow-Origin: https://www-br-de.cdn.ampproject.org
Access-Control-Allow-Credentials: true
ETag: W/"18ba2-OSrq055XbGAfzWi8WLMhZY5alds"
Strict-Transport-Security: max-age=15724800; includeSubDomains
Content-Encoding: gzip
Content-Length: 31122
Cache-Control: max-age=1000
Date: Mon, 04 May 2020 13:07:27 GMT
Connection: keep-alive
Vary: Accept-Encoding
_While the site is powered by Next, we are not using Next's amp integration and instead are just server side rendering the articles with the same express server._
Sometimes I read issues on here that can come off quite aggressive. I am by no means assuming that I have done everything 100% correctly here and AMP is therefore broken. I would just appreciate any ideas as to what can be causing this behavior, and potentially some re-organizing of the caching documentation. Thanks for your time!
 tannerbaum
tannerbaum
All 15 comments
@tannerbaum , wow! Thanks for taking the time to create this fantastically detailed report. I'm hoping it will help us cut through the ambiguity often found in cache situations.
@sebastianbenz @Gregable @CrystalOnScript FYI
 morsssss
on 5 May 2020
morsssss
on 5 May 2020
Worth noting that the one thing I haven't tried yet is amp-live-list. I am not sure if that will solve the problem though; it isn't like there is a ton of content coming in every second its just that old versions of the article are getting served or the data in the amp cache itself isn't getting updated.
tannerbaum
on 6 May 2020
Hey! I've been trying to get my head around different AMP caching scenarios too, and @tannerbaum has previously commented on this issue from my team (within our own repo): https://github.com/bbc/simorgh/issues/6317. There's some detail in there regarding how we've tried to look at how stale the data is on some of our pages, if that could provide another angle. I'd be really interested in any recommendations that come out of this! A big +1 to Tanner's last point, it'd just be nice to know if there's anything we're missing, or if anything could be tweaked in the documentation. Cheers!
 tochwill
on 7 May 2020
tochwill
on 7 May 2020
Thanks to you both! We don't usually get such a detailed bug report. Since caching situations are often complex, this will really help us determine whether there's a problem somewhere or whether we just need to provide much more explicit instructions about how to use the cache. And more examples.
@tannerbaum , something got eaten at the end of the first sentence of your last comment. Do you know what that was? I do know that github will sanitize out HTML tags 😏
morsssss
on 7 May 2020
Thanks to you both! We don't usually get such a detailed bug report. Since caching situations are often complex, this will really help us determine whether there's a problem somewhere or whether we just need to provide much more explicit instructions about how to use the cache. And more examples.
@tannerbaum , something got eaten at the end of the first sentence of your last comment. Do you know what that was? I do know that github will sanitize out HTML tags 😏
Ha that is funny, hadn't seen that happen before. Edited the comment, it was amp-live-list
Edit: I should mention that I have learned today that the systems team provided me with the wrong public key to the private key we are using. Will have an update in a few days if that fixes any of these problems.
tannerbaum
on 8 May 2020
Oh! Do you mean that you've been using the wrong public key?
Certain issues you describe are not ideal in any case, but I'd very much hope that using the proper keys will make things much better. In that case, we'd simply want to recommend that a proper error message gets output when the keys don't match.
morsssss
on 8 May 2020
But, in general, if you want to guarantee very fresh content, I do think <amp-list> and other server call methods (like <amp-live-list> and <amp-script>) are the best bet. In cases, of course, where that's practical.
morsssss
on 8 May 2020
@tannerbaum , some folks who work on the Google AMP cache can look into this. They'd just like to know first whether you've fixed your public key - and whether that's made things better.
morsssss
on 11 May 2020
One thing I've observed is that your own server appears to be returning different results on multiple fetches. I suspect that there is some caching issue going on on your end. That's not to say that the AMP Cache isn't doing something odd here.
For example, amongst about 10 or so runs of the command, I saw this sub-sequence in this order:
$ curl https://www.br.de/nachrichten/amp/deutschland-welt/coronavirus-alle-entwicklungen-im-live-ticker,Rt6bDgj | md5sum
8baba7780a8b6c282041783167ca58f1
$ curl https://www.br.de/nachrichten/amp/deutschland-welt/coronavirus-alle-entwicklungen-im-live-ticker,Rt6bDgj | md5sum
e3c27da826227ac43c2aab81f8095976
$ curl https://www.br.de/nachrichten/amp/deutschland-welt/coronavirus-alle-entwicklungen-im-live-ticker,Rt6bDgj | md5sum
8baba7780a8b6c282041783167ca58f1
If each one was unique, then perhaps this article changes a lot, but the first and third sums are the same meaning the article went from version A -> B -> A on your own server. Either A->B or B->A was a regression.
Note here that none of these requests went through the AMP Cache, they were directly to your server from my local machine.
Is it possible that your server infrastructure sometimes serves an old copy to a new request, and that we cache that?
 Gregable
on 12 May 2020
Gregable
on 12 May 2020
With the correct public key we are now getting a 200 back from the clearing cache requests. Just confirmed it with this link:
https://www-br-de.cdn.ampproject.org/update-cache/c/s/www.br.de/nachrichten/amp/deutschland-welt/coronavirus-alle-entwicklungen-im-live-ticker,Rt6bDgj?amp_action=flush&_ts=1589379560&_url_signature=YOfpdofi-wbhqyWSHqBquplwj4lJTFyrGHJSgBUltJg2KDBAQB1_hmsq1zfsjrdIRJf0uoMrrj1O_5UpYQVL-CGWqLDY-X8NLmoaDNE5zci4zk-ARJ1y_0XG26DfjejsYiRoI2dVH_CnBfXOViygpkzXLgzwBtHfhtPHV2hp0hfcWba6e6WIm659B9a-FeNVBOjGehLLpBfJA8v4SRjsq2k9TdCBzGzSjnhh_Xr8lcLIkexxTdWOi4Mk6cNSHXq8QvbVQjhkDby0TSMTyjq2B5Ae1ejHZuVOVDjYlqH1PG57sn7pcP6f2VP16RXiQNPfCBH8gtU1_ibA7e1-Irl6sA
I will update the original post. That said, I haven't observed a difference yet. Just checked my phone and saw the double articles. The contents and the links end up being the exact same (first two results)
Also in an upcoming release in the next week we will actually be using amp-toolbox/cors, I needed it for amp-app-banner. Will see if that changes anything.
tannerbaum
on 13 May 2020
@Gregable, just saw your comment, thanks a ton. I am going to look into this.
tannerbaum
on 13 May 2020
Wanted to provide an update. We finally managed to get a release out and it turned out that while it is true that NextJS and our server weren't explicitly caching the pages in anyway and we had the right headers set, the AMP articles had a different Apollo Client configuration which was caching the article data itself used by the server. Mix that in with dozens of different instances of the server all with different cached versions of a frequently updating article, and you get an article that travels forward and backward in time 🙃 . Which was then cached by AMP.
First of all I want to thank @Gregable for setting me down the path to find this out. It's a really smart way of being able to test your pages outside of the amp cache. I have one last question for him and the team: is the manual purging of the cache via /update-cache even necessary then, or should I just take that code out of the project?
Thanks again everyone.
tannerbaum
on 18 Jun 2020
@tannerbaum I'm glad that this worked out in the end!
Regarding /update-cache, that mechanism exists with the goal of allowing you to push updates for specific URLs faster than the normal update frequency of the AMP Cache. For example, if you have 24h cached resource and you need to make a change suddenly.
If the stale / cache age you are now seeing for documents is good enough for your needs, there is certainly no reason you would need to implement /update-cache calls. It's not something we expect all or even most publishers to ever use.
If you do need faster refreshes than you are now seeing, there are some known issues with /update-cache which cause it to only be partially effective anyway at this time. /update-cache will improve the latency, but not necessarily work as advertised in all cases. There is nothing I can offer here as a workaround, this is just a bug that needs fixing, but it may not matter in your case.
Gregable
on 19 Jun 2020
And I'm glad that @Gregable helped you find your issue with Apollo Client! It's so hard to find and fix bugs that involve a cache, especially when multiple layers are involved.
morsssss
on 19 Jun 2020
Haha yes indeed! Thank you both again, I will close the issue now and hope that someone someday will stumble upon this and benefit from it.
tannerbaum
on 19 Jun 2020
Related issues
 radiovisual
·
3Comments
radiovisual
·
3Comments
 jpettitt
·
3Comments
jpettitt
·
3Comments
 mrjoro
·
3Comments
mrjoro
·
3Comments
 torch2424
·
3Comments
torch2424
·
3Comments
 aghassemi
·
3Comments
aghassemi
·
3Comments
Most helpful comment
One thing I've observed is that your own server appears to be returning different results on multiple fetches. I suspect that there is some caching issue going on on your end. That's not to say that the AMP Cache isn't doing something odd here.
For example, amongst about 10 or so runs of the command, I saw this sub-sequence in this order:
If each one was unique, then perhaps this article changes a lot, but the first and third sums are the same meaning the article went from version A -> B -> A on your own server. Either A->B or B->A was a regression.
Note here that none of these requests went through the AMP Cache, they were directly to your server from my local machine.
Is it possible that your server infrastructure sometimes serves an old copy to a new request, and that we cache that?