Almanac.httparchive.org: Markup 2020
Part I Chapter 3: Markup
Content team
| Authors | Reviewers | Analysts | Draft | Queries | Results |
| ------- | --------- | -------- | ----- | ------- | ------- |
| @j9t @catalinred @iandevlin | @zcorpan @matuzo @bkardell | @Tiggerito | Doc | *.sql | Sheet |
Content team lead: @j9t
Welcome chapter contributors! You'll be using this issue throughout the chapter lifecycle to coordinate on the content planning, analysis, and writing stages.
The content team is made up of the following contributors:
New contributors: If you're interested in joining the content team for this chapter, just leave a comment below and the content team lead will loop you in.
_Note: To ensure that you get notifications when tagged, you must be "watching" this repository._
Milestones
0. Form the content team
- [x] Jul 6th: Project owners have selected an author to be the content team lead
- [x] Jul 13th: The content team has at least one author, reviewer, and analyst (minimally viable team formed)
1. Plan content
- [x] Jul 20th: The content team has completed the chapter outline in the draft doc
- [x] Jul 27th: Analysts have triaged the feasibility of all proposed metrics
2. Gather data
- [x] Jul 27th: Analysts have added all necessary custom metrics and drafted a PR to track query progress
- Aug 1 - 31: August crawl
- [x] Sep 7th: Analysts have queried all metrics and saved the output to the results sheet
3. Validate results
- [x] Sep 14th: The content team has reviewed the results sheet
4. Draft content
- [x] Nov 12th: Authors have completed the first draft in the doc
- [x] Nov 26th: The content team has prototyped all data visualizations
5. Publication
- [x] Nov 26th: The content team has reviewed the final draft, converted to markdown, and filed a PR to add it to the 2020 content directory
- Dec 9th: Target launch date
 obto
obto
All 188 comments
I'm afraid I'm not fluent enough in English to create the content. I can help reviewing, though.
 borisschapira
on 27 Jun 2020
borisschapira
on 27 Jun 2020
I’m happy to contribute to this. With my current workload the least I can commit to is reviewing—I look forward to coordinating with whoever would be driving this section.
 j9t
on 28 Jun 2020
j9t
on 28 Jun 2020
I can review this chapter.
 ibnesayeed
on 29 Jun 2020
ibnesayeed
on 29 Jun 2020
I'd love to help in any way.
 catalinred
on 30 Jun 2020
catalinred
on 30 Jun 2020
I can contribute with ideas for things to query, and review.
 zcorpan
on 1 Jul 2020
zcorpan
on 1 Jul 2020
I would be happy to contribute and/or review.
 iandevlin
on 2 Jul 2020
iandevlin
on 2 Jul 2020
@j9t thank you for agreeing to be the lead author for the Markup chapter! As the lead, you'll be responsible for driving the content planning and writing phases in collaboration with your content team, which will consist of yourself as lead, any coauthors you choose as needed, peer reviewers, and data analysts.
The immediate next steps for this chapter are:
- Establish the rest of your content team. Several other people were interested or nominated (see below), so that's a great place to start. The larger the scope of the chapter, the more people you'll want to have on board.
- Start sketching out ideas in your draft doc.
- Catch up on last year's chapter and the project methodology to get a sense for what's possible.
There's a ton of info in the top comment, so check that out and feel free to ping myself or @rviscomi with any questions!
obto
on 2 Jul 2020
@matuzo we'd still love to have you contribute as a peer reviewer or coauthor as needed. Let us know if you're still interested!
@iandevlin @catalinred @ibnesayeed @zcorpan @iandevlin I've put you down as reviewers for now, and will leave it to @j9t to reassign at his discretion
obto
on 2 Jul 2020
Thanks @obto—I’m excited to work on this together with all of you who have also expressed interest! 🙏
👉 @iandevlin, @catalinred, @ibnesayeed, @zcorpan, @iandevlin, @matuzo, can you confirm that and how you’d like to be involved? Who would also like to write and co-author, who would like to cover analysis? I like the idea of forming a really strong team together. (Feel free to respond here but also directly through email, as per my profile.)
(If everyone of you is aboard, and if we can split the responsibilities well I think we already have a good setup. I’d wait until all of you confirmed to decide with you whether that’s the case or whether we need more support.)
👉 Do you have preferences for how to coordinate? Not everything will be useful to discuss in this thread; I’m not sure there is or that we need a Slack channel; maybe an email list does; what do you think and prefer?
—For my status, I’m going to take a few days to review what we have (notably docs and 2019 chapter), and will follow up here. (I’m off from July 5–9, then, when I’m going to be slow or unavailable to respond to messages.)
j9t
on 3 Jul 2020
Hi @j9t! I would also like to co-author, if possible. As for communication, happy to use whatever, although I do find Slack verfy useful (I use it all the time these days)
iandevlin
on 3 Jul 2020
Hi @j9t,
I made a study on markup in the past and I'd like to help with research and writing if that's possible as well.
Slack is part of my workflow already but I'm open to any alternative.
catalinred
on 3 Jul 2020
Hope you don't mind me jumping in here.
I'm one of the core contributors for the almanac, working on development and translations, but I also wrote one of the chapters last year, and also copy edited a lot of the chapters last year.
First up I want to say that use whatever works for the team, so take all that I'm going to say with that in mind. However I would strongly encourage GitHub and GoogleDocs over Slack and Email for a lot of the comms. Because while we want to make collaboration as easy as possible for you, we also should bear in mind that people might join and drop out of this, and future years.
For example last year the Markup Chapter had these links:
- #5 - the equivalent to this issue where we picked the team and decided what metrics to look at
- #84 - where we worked on the metrics
- The SQL we finally came up with for the metrics
- The results
- #133 - where we tracked the writing of the chapters
- The chapter in a Google Docs as it was worked on and comments were added
(Most of these are tracked in @rviscomi 's excellent PM sheet from last year).
As you can see there is a wealth of information that is available to you, 2020 authors, analysts and reviewers to help you for this year's chapters to potentially answer questions like why certain metrics weren't looked at last year (were they not considered? Or not possible? Or they were looked at but no interesting data so never made it into the chapter?). You can look at all the metrics from last year, and the results, and – perhaps more importantly – the discussions around them and then decide which ones to look at again this year, which to drop, and what new ones to add - using the above links to help inform you of those decisions.
That wouldn't be possible and a lot of valuable reasoning might be lost if these discussions happened over less linkable, searchable and plus+1-able mediums like Slack and/or Email.
It also means random people (like me here!) can stick our big noses in to try to help. Or you can @ people outside of the immediate chapter team (like @rviscomi @obto or myself) or pull in other people outside of the Web Almanac if you've a question for them.
On the other hand, there is a lot to be said for the interactivity for chat so totally understand if you want to go that direction. Just ask you to bear above in mind if you do.
A few other resources to be aware of:
- We have a
#web-almanacchannel on slack. I encourage you to join, and I presume it's possible to open another channel dedicated to this chapter on that if needs be? - You can also have a discussion room on GitHub in the team space. Though we tried that for some of the translator teams last year and it wasn't used much to be honest. Not sure I see the benefit over direct discussion in the issues to be honest. But thought I'd throw it out there as an option.
Anyway, will let you all decide as a team but thought I'd throw my 2 cents in based on last year's experience - hope it helps!
 bazzadp
on 3 Jul 2020
bazzadp
on 3 Jul 2020
@j9t
can you confirm that and how you’d like to be involved?
I sign up as reviewer.
I can't commit to the analyst role or author role, but I can help discuss ideas for things to include.
zcorpan
on 3 Jul 2020
Thanks @bazzadp—this is excellent feedback! Thanks for jumping in :) This is good context and good information to review.
For communication, I signed up for httparchive Slack, and maybe we can indeed just open a channel there to coordinate.
@iandevlin, @catalinred, @zcorpan, great to hear—I’ll update the intro accordingly. @catalinred, would “research” reflect the analyst role?
j9t
on 3 Jul 2020
@catalinred, would “research” reflect the analyst role?
Actually, I was thinking about writing or reviewing. Can't help with the analyst role.
Let me know where you want me.
catalinred
on 3 Jul 2020
@j9t please count me in as a reviewer. I would have offered to be a co-author, but my plate is too full this year.
ibnesayeed
on 3 Jul 2020
Excellent! Thanks for confirming and clarifying, Catalin, Sawood. As we heard from everyone but him I reached out to Manuel directly to check on his interests.
As mentioned before, I’ll be off for a few days now but will use that time to review last year’s chapter as well as the docs. Maybe this is a good time for us all to do that? I have a look particularly at the introductory references as well as Barry’s comment.
Everyone, also @obto, @bazzadp, do you have ideas on the analyst role, and who could help with that? I can imagine that’s a bit of a special role in that maybe analysts for other topics could potentially help with, too, if they have bandwidth and are interested in the subject and helping us out?
j9t
on 4 Jul 2020
I’ve seen @rviscomi reaching out to the HTTP Archive community and others to try to get some more analysts. We had same issue last year and had to share them across chapters. If you know anyone with SQL skills willing to help out then give them a nudge 🙂
What you all can do to help in the meantime is to do the review as you suggested and come up with what metrics you would like to see. Then once we have an analyst they can write the actual SQL to query the HTTP Archive. The good thing is we have all of last years queries already so, assuming a lot of those are going to be reused, it hopefully won’t be as much work as last year.
Last year’s author of this chapter @bkardell also created a glitch app to allow you to explore the data without requiring SQL skills so that would be worth checking out too to research and validate ideas.
What is more important is if you want anything new which is not in the current dataset then need that asked for before the August crawl we will be using. Of course having an analyst dedicated to this chapter who knows the current dataset would help you in figuring out if you need anything added, but pipe up here and @rviscomi , @obto , myself and anyone else that fancies can hopefully help answer any questions in the meantime.
Hope that helps!
bazzadp
on 4 Jul 2020
@rviscomi some milestone entries in this and other chapters do not have chackboxes, is this intentional?
ibnesayeed
on 10 Jul 2020
@ibnesayeed yes those are informational dates to explain why the other milestones are when they are. For example, there's nothing the content team needs to do to make sure the August crawl happens, but it explains why metrics must be prepared by July 27, and why querying metrics can't begin until September.
 rviscomi
on 10 Jul 2020
rviscomi
on 10 Jul 2020
Hey everyone—after a quick vacation and reviewing the major docs, an update. I’ll keep it brief:
👉 I’ve added a first outline and metrics in the Markup draft doc. Can everyone please check they have access, and review, add, and comment, notably on what you think is missing metrics-wise?
👉 Does anyone of you feel we aren’t enough people (except for analysts, which we don’t have any yet)? Do you have particular people in mind we should contact? Feel free to just reach out to them or coordinate with me if that makes it easier.
I’ve pinged @matuzo again to check on his availability, but will take him off the list (intro section ↑) if we don’t hear anything affirmative. (If Manuel still finds the time that would be awesome, so I think we can still add him to the team later.)
👉 @catalinred, @iandevlin, do you have bandwidth to help me with chapter coordination? As this would be useful to discuss directly, I’ve also sent you an email, Catalin (I can’t spot yours, Ian). (If anyone else likes to help with this please let me know—I’ve simply thought to start with asking the co-authors :)
Regarding communication, it _seems_ we can work like this right now but maybe it would still benefit us if we had a Markup channel in Slack. I’m on the fence but might as well open one—just so that you aren’t surprised if that happens :)
Is there anything else that comes to _your_ mind right now?
j9t
on 12 Jul 2020
@j9t Hello! My email is [email protected]. And yes, I should have the bandwidth to help.
iandevlin
on 13 Jul 2020
Hi,
I read again @bkardell 's last year awesome piece and I think there is a lot of precious info to keep from (and compare to) last year's chapter, e.g.:
- Top elements comparison: 2005/2019 and now 2020
- Elements per page: frequency, average numbers
- Top deprecated elements
Besides that, here are some of my thoughts, random things that I'd like to see in this new Markup chapter:
- A
doctypebreakdown, would love to see how the latest HTML doctype hopefully crushes the other obsolete doctypes. <link rel="icon">stats - this will help us know how people are using the favicon nowadays
SVG or PNG? If missing then we may assume they use thefavicon.icoin the root maybe.
<link rel="icon" href="/favicon.svg" type="image/svg+xml"><link rel="icon" href="/favicon.png" type="image/png">
- When it comes to links, knowing that a missing
rel="noopener"when usingtarget="_blank"is considered a security vulnerability, we may show some stats on when and how these are used in the wild. noscriptusage stats - is this number affected by popularscripts as GTM, as it recommends you to paste anoscriptelement containing aniframeimmediately after the opening tag?rel=amphtml- might be interesting to know how many pages are linking to an AMP version using<link rel="amphtml">- the old and wrong way to stop links navigating by using
href=”javascript:void(0)- would love to find nothing here, though. - How many pages are correctly adding a
langattribute for thehtmlelement and are they using the<link hreflang="">to specify the language of the document too? - I'm deeply interested to see how many
buttons are being used without a specifiedtype. Also, what are the stats regarding the other native<button>,<input type=imageor<input type=button? - How about the popular
data-*custom attributes? Curious to see the numbers and based on their naming we find we might draw some interesting conclusions about their purpose. <meta name="generator" content="WordPress">- people don't remove this from the<head>so we might find out how many of the pages we analyze are actual WordPress pages.- There is some confusion when it comes to HTML replaced and void elements, and seeing some actual stats might help understand them better. On the void elements, maybe some stats whether people are closing them or not, e.g.
<img src="">or<img src=""/>. - Besides the already popular custom elements stats, I'd like to see how many people are using
<h7>or<h8>in their HTML. Last time I checked within ~8mil pages, I found more than 20K<h7>elements. - Video and audio
autoplayis considered a bad practice so it would be interesting to see the elements and values for theautoplayattribute in the wild:autoplay,autoplay=trueandautoplay=false - Ways of including SVG in HTML, inline SVG, as an
<img>, as an<object>, as an<embed>, as an<iframe>. Count the top five or top ten SVG elements (when speaking of inline SVG). - Knowing that a perfectly valid HTML page doesn't need a
bodyat all, curious if we can we find any HTML without abody? It would be interesting to see the results here. - HTML document size, the average, lowest, and highest size we can find in the HTTPArchive set.
- Last but not least, would we be able to HTML validate the whole data set? I'm guessing this would be cumbersome but would love to see numbers, I bet a lot of the pages are not valid, e.g. https://validator.w3.org/nu/?doc=https://twitter.com
Let me know your thoughts!
catalinred
on 13 Jul 2020
Hey @j9t, looks like things are moving along pretty smoothly. Is there anything you need from me to keep things moving forward, and have the chapter outline and metrics settled on by the end of the week?
obto
on 13 Jul 2020
Everyone, please share your thoughts on the first outline as well as metrics to look at in our Markup doc—thank you!
@iandevlin, excellent! I’ve followed up per email.
@catalinred, I love it! I’ve synced your ideas with the doc’s “Metrics” section, adding what was not there yet under “Patterns” (we can rename). Please edit/comment where you see fit!
@obto, thanks for checking in! We do have a skeleton available with the draft doc—do you have any feedback on that? It doesn’t seem we have an analyst coming out of our group—do you have thoughts on that, to look into closer coordination?
j9t
on 13 Jul 2020
I've requested edit access. Writing here for now.
On doctypes, I think an interesting metric is an accurate number of how many pages are in quirks mode (and how it has changed over time). There is a custom metric for this already, see https://github.com/HTTPArchive/httparchive.org/issues/186#issuecomment-655611526
zcorpan
on 14 Jul 2020
@j9t The document looks great. I especially like the categorization of the metrics you've put together.
As for finding an analyst, it's looking like we'll have to share them between chapters like we did last year. We are actively looking though and @rviscomi has reached out in a few places.
I'm happy to be a stand-in if we cant find some more analysts soon however :)
obto
on 14 Jul 2020
@matuzo we'd still love to have you contribute as a peer reviewer or coauthor as needed. Let us know if you're still interested!
Hey,
sorry, I was on vacation and I didn't check my mails. I'd love to contribute as a reviewer. :)
Thanks!
 matuzo
on 14 Jul 2020
matuzo
on 14 Jul 2020
@catalinred—I had contacted you through email; could you check or otherwise let me know how to best coordinate directly? Thanks :)
j9t
on 17 Jul 2020
I have left a few comments and suggestions for inclusion in the draft.
ibnesayeed
on 17 Jul 2020
@catalinred—I had contacted you through email; could you check or otherwise let me know how to best coordinate directly? Thanks :)
That’s a bit odd because I did reply to you :)
catalinred
on 18 Jul 2020
That’s a bit odd because I did reply to you :)
Strange. Checked again, received literally nothing. Could you forward your response to [email protected]?
j9t
on 18 Jul 2020
Last year’s author of this chapter @bkardell also created a glitch app to allow you to explore the data without requiring SQL skills so that would be worth checking out too to research and validate ideas.
Yeah I should add we can get new data dumps and integrate them for that tool rather quickly, it's still currently manual - but a lot more can be done if anyone is interested in developing this tool further either now or over time... For example, one thing I added since was an endpoint that will let you analyze the differences between two dataset dumps http://rainy-periwinkle.glitch.me/delta/desktop/aug_2019/march_2020
 bkardell
on 18 Jul 2020
bkardell
on 18 Jul 2020
Quick status:
➕ The main document is up and has already received some feedback. Thanks everyone who has taken a look—everyone who hasn’t yet, please check it out, too, and share your thoughts!
➖ For the moment I still consider us a bit weak on the analysis side. This may nothing to be worried about yet given that there seems to be help by the project (and we’re watched over 🙏), however if anyone could have a closer look at this, including Brian’s and others’ feedback, and maybe drive this, that could be a great help.
Catalin, Ian, and I are going to meet up tomorrow (Monday) to sync up and discuss the doc in person. We’re going to follow up again here.
j9t
on 19 Jul 2020
Quick status update:
We have a private Slack channel #markup-2020 now. @zcorpan, @matuzo, I couldn’t find you in Slack yet but please hit me up so to add you—the same applies to everyone who would work with us. (It’s a private channel as public feedback can already be covered here.)
The metrics section seemed in need of refinement. I set up a spreadsheet to be clearer about the questions we try to answer and the data to retrieve for that. I’ve begun to reflect our doc’s metrics there; @catalinred, since the “patterns” section includes most of your suggestions, can you help and transfer those over (to complete the “Question to answer” column)?
Once we have moved the metrics I hope we can have better conversation around the data needed as well as what we deem the most important items to cover (as Catalin’s own analyses show, element popularity alone is already a huge topic 😊).
j9t
on 20 Jul 2020
@HTTPArchive/analysts this chapter is in need of your help!
rviscomi
on 20 Jul 2020
I'm doing analytics for SEO and noticed there is quite an overlap in the metrics needed. I could help by including what you need in the metrics we gather. e.g. we already get all link and meta tags which would cover some of your requirements. We also gather data on links, hXs and images.
 Tiggerito
on 22 Jul 2020
Tiggerito
on 22 Jul 2020
Thanks @Tiggerito! Can I put you down as this chapter's designated analyst, or are you only able to help with custom metrics? The custom metrics are the highest priority so even that would be greatly appreciated.
rviscomi
on 22 Jul 2020
Put me down. With my metrics and SQL pull requests (getting big), should I add in what's needed with this chapter?
Tiggerito
on 22 Jul 2020
Great thank you! Yes, feel free to bundle SEO and Markup custom metrics into a single PR if needed.
rviscomi
on 22 Jul 2020
Great thank you! Yes, feel free to bundle SEO and Markup custom metrics into a single PR if needed.
Great, I'll rename the pull requests to reflect that.
Tiggerito
on 22 Jul 2020
Great to have you here, @Tiggerito!
Going through the metrics sheet I think we transferred almost all data, which I crossed out in the doc. @ibnesayeed, @catalinred, can you check on and move the few items that don’t seem to have been transferred over yet (javascript links, link targets, boilerplate)?
I see us somewhere between reviewing and normalizing that sheet and “just” starting with analysis—is that a view you’d share, especially @rviscomi given your experience?
Unless I’m missing something important I’d propose proceeding from two ends:
- @catalinred, @iandevlin, can you help me clean up the metrics sheet, like adding information on data needed, regrouping, tweaking comments? I’d focus on that over the next two days (I can’t invest much time at once right now).
- @Tiggerito, can you share your view on the metrics in terms of how suitable they are to work with? That can inform our normalization work and maybe put our minds a bit at ease that we’ll get a look at the data we need.
Call me out on and excuse anything I’m missing please, and then thanks everyone who has invested in reviewing and documenting over the last few days!
j9t
on 22 Jul 2020
Hi @j9t and all,
I'll read through stuff to get myself up to speed and see if anything was missed.
I've already pulled over the old SQL scripts. That helped me get a grasp what was done last year, and an idea on what can be done.
First glance on the metrics sheet and I think we may have a few that are not viable. Mainly on the checking validity and style of the html. Most of our data comes from the DOM of a rendered crawl, which means we are looking at parsed and cleaned up html. Syntax errors handled, formatting like type of quote removed, if a tag was specified as self closing or an empty open/close etc.
The rest look like they can be gathered from the DOM, WebPageTest data, or other data gathered during the crawl.
We can peek at the raw html, however that query is very expensive (I think $80 a go). And it's very hard to process it as we only have basic string manipulation like regex to work with. It's recommended that we avoid these sorts of queries. I don't think we would be able to do syntax type tests on it anyhow.
The critical bit at the moment is to make sure we get the almanac.js file updated so it captures all the data needed. We have a week to get that code implemented tested and approved. I'll focus on the sheet and add notes about viability and if almanac.js is involved, what state that is in.
We also have access to Lighthouse data. I'm not sure what it reports on related to markup at this time.
And a Technologies table that may come in use. e.g. to identify WordPress for us.
Tiggerito
on 22 Jul 2020
I've gone through the spreadsheet and added a few new columns and comments/questions.
Tiggerito
on 23 Jul 2020
I've gone through the spreadsheet and added a few new columns and comments/questions.
Thanks, @Tiggerito, I'll add my thoughts/answers to the spreadsheet as well.
catalinred
on 23 Jul 2020
Thanks @Tiggerito, @catalinred!
What's the most pressing we need right now?
(I’m a bit behind in terms of reviewing and working on the metrics again but it’s #1 on my list.)
j9t
on 23 Jul 2020
I see us somewhere between reviewing and normalizing that sheet and “just” starting with analysis—is that a view you’d share, especially @rviscomi given your experience?
Yes, if I understand the question correctly, you can use the results of the metrics triaging to revisit the chapter outline and adjust as needed. The biggest rush is accounting for any custom metrics that need to be added before the August 1 crawl. You could continue revising the outline throughout August before the analysis is done. It's a good idea to lock in the scope of the chapter for the sake of not introducing any newly required metrics, but if you and @Tiggerito agree to a bit of scope creep and it doesn't require going back and adding custom metrics, that's ok too. Hope that answers your question!
rviscomi
on 23 Jul 2020
What's the most pressing we need right now?
In my opinion, we should first decide on the approximate chapter categorization.
After deciding on the matter above, we need to carefully study all the suggested metrics in the sheet and decide which one are really important, as we might need extra help from the @HTTPArchive/analysts team because @Tiggerito said he might not have enough time to invest in all the metrics we're looking for.
catalinred
on 23 Jul 2020
I've got what I think is an almost complete version of the script to get the data. I think there are still a few open items, but most things have been implemented.
Here is a zipped up example of the data:
If you provide me with test URLs and what you expect, I can run the tests.
Tiggerito
on 24 Jul 2020
In my opinion, we should first decide on the approximate chapter categorization.
I added categories and made some other updates to the metrics spreadsheet that I hope are useful here, and help us get a more detailed view at what we try to do. (This is not to distract from @Tiggerito’s and @catalinred’s work, who have both added more substantial value over the last few days.)
I also adjusted the doc outline a little bit, aligning it with the metrics and thereby simplifying the structure (general, elements, attributes). I’m not sure we need subsections at this point, but that these depend on what we can measure and then decide to interpret.
(Completely open to discuss and revisit all of this—please share your views.)
@Tiggerito, @catalinred, it seems we won’t get data for _everything_ we would like to look at, but can already cover a good number of metrics. Can you help assess whether we should spend more time on refining, or go for it?
j9t
on 24 Jul 2020
@j9t is quirks mode (& change over time) covered? I don't see it in the metrics spreadsheet or doc outline. See https://github.com/HTTPArchive/almanac.httparchive.org/issues/899#issuecomment-657837767
zcorpan
on 25 Jul 2020
We only have until the end of the month to submit the metrics code, and there is no fixing it after that date. I say we hold on features now and focus on checking that the data provided will be usable and accurate.
Tiggerito
on 25 Jul 2020
The metric for quirks mode is implemented in httparchive already and has been for a few years. @rviscomi can you help?
zcorpan
on 25 Jul 2020
@j9t is quirks mode (& change over time) covered?
We would look for doctypes (see rows 2 and 3)—did you want to make this more explicit?
j9t
on 25 Jul 2020
Should we also look for the stats of well known URL shortner service URLs, both as hyper links and as page requisites?
ibnesayeed
on 25 Jul 2020
Should we also look for the stats of well known URL shortner service URLs
Added (row 21), at least for anchor elements—which allowed to mark off the last item in the doc (which we seemed not to have covered from what we had collected there).
I updated, reordered, marked some dups (in terms of us already getting that data), and felt free to loop in @Tiggerito when that seemed relevant.
I grow to like this, though for me it was the icing on the cake if we can get budget (if I get this right) to check on all attributes (currently rows 25, 26, 28, 29). I’ve expressed this there—please let me know, @Tiggerito, how we could build a case for this if it’s possible to get respective data.
Other views?
j9t
on 25 Jul 2020
@j9t is quirks mode (& change over time) covered?
We would look for doctypes (see rows 2 and 3)—did you want to make this more explicit?
There is an existing script that returns true if document.compatMode === 'BackCompat'?
Tiggerito
on 26 Jul 2020
I'm doing another review of the metrics and what we can get. Outstanding:
w3c and any other raw validation or check on tagging method is not really possible. It looks like we do not have access to any w3c validation data and we only have regex commands available to do this.
class and id values. I'd really like to know how this data would be used. This will bloat out the data collected increasing the query cost for all chapters. Because of this I may not get approval anyhow. Could something smaller like the number of class names used be enough?
What values are used for href attributes for anchors?
I'm capturing protocols but don't understand the comments about srcset and data mime types. What exactly do I need to get?
Identifying an app? - I still don't understand what to do here.
I'd love to have some example URLs and their expected results so I can test some of this stuff beyond my fake test page.
Tiggerito
on 26 Jul 2020
@j9t @Tiggerito looking for doctypes is very much related, but a less direct and less accurate metric for the question "how many pages use quirks mode?" than document.compatMode. I'd also like to get a historical trend for this one, which should be possible since the custom metric has existed for a few years.
Thanks!
zcorpan
on 26 Jul 2020
Could something smaller like the number of class names used be enough?
Might not see the forest for the trees, can you elaborate? How I read this it would refer to taking the same data (all values for @class).
I'm capturing protocols but don't understand the comments about srcset and data mime types. What exactly do I need to get?
I moved this out of the href row (separate topic) and tagged you FYI.
I'd love to have some example URLs and their expected results so I can test some of this stuff beyond my fake test page.
How and who can best help?
j9t
on 26 Jul 2020
Could something smaller like the number of class names used be enough?
Might not see the forest for the trees, can you elaborate? How I read this it would refer to taking the same data (all values for
@class).
I'm not sure where the value is in knowing every class name and id every website uses. I was testing today and would estimate that collecting class names and ids would massively increase the data stored. The team involved in data gathering are already concerned in the bloat of data gathered. This adds a massive amount to that bloat.
Please provide a need for this data.
I'm capturing protocols but don't understand the comments about srcset and data mime types. What exactly do I need to get?
I moved this out of the
hrefrow (separate topic) and tagged you FYI.
That's still vague and wanting a massive data set. src and srcset will always be different. We can't record every value every page uses. And I don't see any value in doing that.
We can track counts of use. e.g. how many images include srcset.
I'm not sure how to determine mime types. If that is clarified I could track counts of different mime types used. I presume that would also indicate that a src was data: based.
I'd love to have some example URLs and their expected results so I can test some of this stuff beyond my fake test page.
How and who can best help?
We have one chance at getting the code right for this data gathering. I'm currently testing it against a fake page I've created to test things, and so far one person has given me a url to do a real world test. My confidence is low that all the metrics will track as expected.
As a reminder. A single database query on a table that stores the raw html costs about $80 (we have $300 in total). The idea is that we intelligently collect the data we need into a different table to reduce that size and cost. We don't want that optimised table to bloat out and be just as expensive. The biggest bloat comes from listing details instead of reporting on counts.
Tiggerito
on 26 Jul 2020
Thanks for adding more detail, @Tiggerito. Let’s move away from the expensive queries, then, and scrap looking at class, id, href, src, and srcset _values_, and instead look at their overall counts. I believe we already marked the detailed queries “N” or ”?” in the spreadsheet, so I didn’t take action there.
How well do tests need to be prepared? Everyone, does someone have the bandwidth to help with that?
j9t
on 26 Jul 2020
It's good to exercise the custom metrics on a few major websites and have a thorough code review to make sure they can gracefully handle any edge cases.
rviscomi
on 26 Jul 2020
Thanks for adding more detail, @Tiggerito. Let’s move away from the expensive queries, then, and scrap looking at
class,id,href,src, andsrcset_values_, and instead look at their overall counts. I believe we already marked the detailed queries “N” or ”?” in the spreadsheet, so I didn’t take action there.
Counts it will be. I still don't understand the requirements for src and srcset. On what elements?
Tiggerito
on 27 Jul 2020
It's good to exercise the custom metrics on a few major websites and have a thorough code review to make sure they can gracefully handle any edge cases.
Yep, so send me example URLs that cover some of the features you want me to capture, and what results you expect.
Tiggerito
on 27 Jul 2020
I still don't understand the requirements for src and srcset. On what elements?
On img and source elements—I added respective info in the spreadsheet.
j9t
on 27 Jul 2020
I still don't understand the requirements for src and srcset. On what elements?
On
imgandsourceelements—I added respective info in the spreadsheet.
I've expanded the image data to also include source data and counts of src and srcset attributes. I also counted picture elements and a few other attributes (media, type).
picture: {
total: 0
},
source: {
total: 0,
src_total: 0,
srcset_total: 0,
media_total: 0,
type_total: 0
},
img: {
total: 0,
src_total: 0,
srcset_total: 0,
Yep, so send me example URLs that cover some of the features you want me to capture, and what results you expect.
I assume this question is for @j9t? I haven't been tracking the custom metrics needed for this chapter, so I don't know what URLs would be good test cases.
As far as results, see https://github.com/HTTPArchive/legacy.httparchive.org/pull/170#issue-453176318 for a good example of running the custom metric draft through WebPageTest and linking to the results from the PR. This helps reviewers see what the output should be and proves that it's working as intended.
rviscomi
on 27 Jul 2020
Yep, so send me example URLs
I assume this question is for @j9t?
I can only pass this on at the moment—is there someone in the team who could help with this?
@Tiggerito, maybe you have an example for how detailed this should be? I understand we need something like “URL https://example.com/, find 24 tags (not elements 😉), elements foo, bar, baz, 7 attributes, namely …? etc., to use that to compare what you’re retrieving?
j9t
on 27 Jul 2020
I've already added some test URLs to the Markup Metrics sheet for some of the rows.
catalinred
on 27 Jul 2020
Sorry, I'm looking for real world websites that use the features you want to get data on. I'll test those in the sheet. I can't test code snippets.
Tiggerito
on 28 Jul 2020
There's some good examples there @catalinred I'll get to testing them.
Tiggerito
on 28 Jul 2020
First test. When counting svg elements it does not spot svgs that are inside other svgs. Is that fine?
Tiggerito
on 28 Jul 2020
First test. When counting svg elements it does not spot svgs that are inside other svgs. Is that fine?
Nested SVGs is actually a valid thing, please see this article by @SaraSoueidan for some good examples:
https://www.sarasoueidan.com/blog/mimic-relative-positioning-in-svg/
So, what do you think about counting how many inner SVGs too>? Would that be feasible?
catalinred
on 28 Jul 2020
First test. When counting svg elements it does not spot svgs that are inside other svgs. Is that fine?
Nested SVGs is actually a valid thing, please see this article by @SaraSoueidan for some good examples:
https://www.sarasoueidan.com/blog/mimic-relative-positioning-in-svg/So, what do you think about counting how many inner SVGs too>? Would that be feasible?
the css selector does not see them. I'm sure it's possible, I just don;t know how.
ahrefs was a good test for target...
🤦♂️
Tiggerito
on 28 Jul 2020
It looks like otherwise all URLs returned what I think is the right data 🥳
Tiggerito
on 28 Jul 2020
ahrefs was a good test for target...
Lol. I dug a bit further and it looks like this is expected behavior when the value for target is not a known keyword such as _blank. The link will still open up in a new tab, here's a quick demo https://codepen.io/catalinred/pen/oNbRwOP
I think this is a good find and might help if we can get all the values for the target attribute here, and then see how many of them are _blank - which is a known keyword by UAs. As a fun fact here, we can also point out in the article the occurrences for the reversed "blank_" values.
catalinred
on 28 Jul 2020
Hi, the code is being reviewed and they spotted that my deprecated element list was not complete. I tried to scrape the values but it missed a lot.
https://html.spec.whatwg.org/multipage/obsolete.html#non-conforming-features
Would it be possible for someone to compile a list of all the elements you want to track as deprecated.
Thanks.
Tiggerito
on 28 Jul 2020
The spec should list everything. Note though that they are not deprecated, but obsolete.
zcorpan
on 28 Jul 2020
https://html.spec.whatwg.org/multipage/obsolete.html#non-conforming-features
@Tiggerito Besides the proper specs, this list might help as well:
https://discuss.httparchive.org/t/use-of-deprecated-html-features-on-the-web/1416/2
they are not deprecated, but obsolete.
@zcorpan My bad here I guess, I'm one who marked these as deprecated.
I'm so used to call these deprecated elements... not an excuse, but maybe because this is how they're usually called almost everywhere? But I do understand there is a subtle difference here and I renamed this to "obsolete" in the metrics sheet.
catalinred
on 28 Jul 2020
https://html.spec.whatwg.org/multipage/obsolete.html#non-conforming-features
@Tiggerito Besides the proper specs, this list might help as well:
https://discuss.httparchive.org/t/use-of-deprecated-html-features-on-the-web/1416/2they are not deprecated, but obsolete.
@zcorpan My bad here I guess, I'm one who marked these as deprecated.
I'm so used to call these deprecated elements... not an excuse, but maybe because this is how they're usually called almost everywhere? But I do understand there is a subtle difference here and I renamed this to "obsolete" in the metrics sheet.
From reviewing both sources I have:
applet,acronym,bgsound,dir,frame,frameset,noframes,isindex,keygen,listing,menuitem,nextid,noembed,plaintext,rb,rtc,strike,xmp,basefont,big,blink,center,font,marquee,multicol,nobr,spacer,tt
And it's been renamed to obsolete.
Tiggerito
on 29 Jul 2020
I found someone using an obsolete element. Guess who?
Google.com
Tiggerito
on 29 Jul 2020
😬 It really stands out. By now it must be a remnant from past days.
j9t
on 29 Jul 2020
Code has been merged. We made it 🥳
Tiggerito
on 30 Jul 2020
@j9t @Tiggerito for the two milestones overdue on July 27 could you check the boxes if:
- the outline has been reviewed and all feasible metrics have been identified
- any necessary custom metrics have been created and you've created a draft PR to track which feasible metrics have had their queries implemented (we've updated the milestone description to clarify this)
Keeping the milestone checklist up to date helps us to see at a glance how all of the chapters are progressing. Thanks for helping us to stay on schedule!
obto
on 30 Jul 2020
@obto, everything should be in place but it’s best for @Tiggerito to confirm. (We’ll update the boilerplate again.)
The rough outline is documented; we will add more detail and tweak once we have more insight into the data.
j9t
on 30 Jul 2020
@obto, everything should be in place but it’s best for @Tiggerito to confirm. (We’ll update the boilerplate again.)
The rough outline is documented; we will add more detail and tweak once we have more insight into the data.
The 27th milestone is complete. I've created a draft PR for the queries and will be updating it as I review what queries we need.
Tiggerito
on 31 Jul 2020
FYI, I split out markup into it's own pull request for the SQL queries.
https://github.com/HTTPArchive/almanac.httparchive.org/pull/1137
Tiggerito
on 1 Aug 2020
As we’re now entering the crawl phase:
Big thanks @Tiggerito for getting everything ready for analysis and likewise big thanks @catalinred for all the work adding detail around our metrics. Likewise thanks to @ibnesayeed and @iandevlin for their work in between, and actually everyone here for their feedback and help so far.
I’ve been coordinating a bit in the background, and what is likely going to happen next is that as soon as we get data back, @Tiggerito, @catalinred, and @iandevlin would hop on a VC to talk about the data and roughly plan our work on the chapter.
Until then there doesn’t seem much to do, but after that I could see (and prefer) us move swiftly, to also involve everyone who’s interested in contributing, notably our reviewers. I look forward to hitting that stage!
I hope this sums up well enough where we stand and where we’re headed, and works for everyone!
j9t
on 1 Aug 2020
Until then there doesn’t seem much to do
Well, I guess authors can continue working on the draft while leaving details (with TODO notes) that can only be filled when the numbers are in.
ibnesayeed
on 1 Aug 2020
Good news. I've had a chance to see some initial data from what I think was some test crawls, and it looks like everything is working 🥳
My next step will be to start mapping the asked for metrics into BigQuery SQL requests.
Tiggerito
on 3 Aug 2020
I'm now documenting more precise metrics we need so that I can create the queries. You can see what I've done so far:
https://github.com/HTTPArchive/almanac.httparchive.org/pull/1137
The sheet references the metrics on this list.
This is where you will need to double check that I will be gathering the exact data you will need.
Tiggerito
on 8 Aug 2020
How often do elements appear per document?
Could we clarify this one. As it could be complex. What numbers are wanted?
Tiggerito
on 8 Aug 2020
How do people use the viewport meta element to control layout on mobile devices?
I'd need exact rules on what to pull out and identify.
So far I have, is "user-scalable=no" in it.
Tiggerito
on 8 Aug 2020
Heading elements, logical sequence?
Does the heading logical sequence make any sense now that people
are used to add e.g. a h1 for eachsection?
I have a sequence of headings with their levels. But no idea how I can process this into a "makes sense" metric? e.g.
[1,2,2,6,3,4,8]
Tiggerito
on 8 Aug 2020
If you don't mind me interjecting:
How often do elements appear per document?
Could we clarify this one. As it could be complex. What numbers are wanted?
Is this the same as went into figure 1 of 2019's Markup Chapter. If so should be easy to reuse the queries.
How do people use the
viewportmeta element to control layout on mobile devices?I'd need exact rules on what to pull out and identify.
So far I have, is "user-scalable=no" in it.
There's more to it than just that and you could look at the mobile-web results sheet from last year. However, rather than try to figure out everything in the analysis stage, I would suggest to just list every variation of the content attribute and the frequency it's used. That way authors, analysts and reviewers can drill down on the data in spreadsheet (e.g. filter to see how many contain user-scalable=no). Analysing the results in this way is some of the best way of finding interesting stats in the results, and my big preference is to give the raw data in spreadsheet format, rather than assuming too much and giving summaries from SQL which limits further investigation without running more SQL. I did this a lot for the HTTP/2 chapter last year, where I just listed header values and number of sites for each instance, and then analysed that in spreadsheets before writing the chapter.
Heading elements, logical sequence?
Does the heading logical sequence make any sense now that people
are used to add e.g. a h1 for eachsection?I have a sequence of headings with their levels. But no idea how I can process this into a "makes sense" metric? e.g.
[1,2,2,6,3,4,8]
I would suggest for going down it should be in order (e.g. 2->6 is wrong) but going up is allowed. That would not be perfect as things like this are wrong:
- h1
- h2
- h3
- h4
- h3
But it is a simple rule to implement and will give obvious errors.
And are people really used to adding h1 for sections? It's allowed but I personally doubt it's used much. Would be interesting to see how many sites have more than one <h1>. General advice still seems to be:
Don’t use loads of
<h1>s. Make<h1>the main heading of your page, then use<h2>,<h3>,<h4>, etc. in a proper hierarchy without skipping levels.
bazzadp
on 8 Aug 2020
What values are used for src and srcset on img and source elements?
I said yes to this, but have no idea what to gather?
Tiggerito
on 8 Aug 2020
What values are used for
srcandsrcsetonimgandsourceelements?I said yes to this, but have no idea what to gather?
OK that's clearly one were all the values would be less than useful, so need some more info on what the requester is looking for. File extension for src might be interesting one for example but probably belongs more in Media chapter than here.
This is what we use for hero images on the Almanac:
<!-- Show large image for large screens and high density screens and use webp when supported -->
<picture>
<source media="(min-width: 327px)" type="image/webp" srcset="/static/images/2019/markup/hero_lg.webp" />
<source media="(min-width: 327px)" type="image/jpeg" srcset="/static/images/2019/markup/hero_lg.jpg" />
<source type="image/webp" srcset="/static/images/2019/markup/hero_lg.webp 2x" />
<source type="image/jpeg" srcset="/static/images/2019/markup/hero_lg.jpg 2x" />
<source type="image/webp" srcset="/static/images/2019/markup/hero_sm.webp" />
<source type="image/jpeg" srcset="/static/images/2019/markup/hero_sm.jpg" />
<img src="/static/images/2019/markup/hero_lg.jpg" class="content-banner" alt="" width="866" height="433" loading="eager" />
</picture>
Given that values of media and type attributes would be more interesting than the src and srcset attributes so maybe that's what they meant? If that's the case then those attributes are ones were it would make more sense to list them all and frequency to let the authors pull out relevant stats.
What could also be more interesting is the second attribute from the srcset attribute, and ignore the first. and this would also apply to <img> elements as much as <source>:
<img srcset="elva-fairy-480w.jpg 480w,
elva-fairy-800w.jpg 800w"
sizes="(max-width: 600px) 480px,
800px"
src="elva-fairy-800w.jpg"
alt="Elva dressed as a fairy">
<img srcset="elva-fairy-320w.jpg,
elva-fairy-480w.jpg 1.5x,
elva-fairy-640w.jpg 2x"
src="elva-fairy-640w.jpg"
alt="Elva dressed as a fairy">
If you don't mind me interjecting:
How often do elements appear per document?
Could we clarify this one. As it could be complex. What numbers are wanted?Is this the same as went into figure 1 of 2019's Markup Chapter. If so should be easy to reuse the queries.
No worries @bazzadp , glad for the help. I think figure 1 relates the the request for "What are the most popular elements?" which I mapped to a last year query.
This seems more about getting info on say, how many times do people add a span to a page. With a repeat for all element types.
I'll test out the suggestion from @rviscomi on Slack, which was to pick the top elements and do a percentile on them.
Tiggerito
on 8 Aug 2020
Figure 1 has two columns (if you ignore the 2005 stat they are compared against):
- The number sites with an element - here for example
<title>ranks highly as most sites have 1 instance of that - The frequency of elements (in total? per page?) - here
<title>is no where to be seen (as only used once on a page) and<div>rules the roost as expected.
bazzadp
on 8 Aug 2020
How do people use the
viewportmeta element to control layout on mobile devices?
I'd need exact rules on what to pull out and identify.
So far I have, is "user-scalable=no" in it.There's more to it than just that and you could look at the mobile-web results sheet from last year. However, rather than try to figure out everything in the analysis stage, I would suggest to just list every variation of the
contentattribute and the frequency it's used. That way authors, analysts and reviewers can drill down on the data in spreadsheet (e.g. filter to see how many containuser-scalable=no). Analysing the results in this way is some of the best way of finding interesting stats in the results, and my big preference is to give the raw data in spreadsheet format, rather than assuming too much and giving summaries from SQL which limits further investigation without running more SQL. I did this a lot for the HTTP/2 chapter last year, where I just listed header values and number of sites for each instance, and then analysed that in spreadsheets before writing the chapter.
There always is. I don't no anything about viewports so assumed there would be millions of different values people would use.
Would a raw dump of say the top 10000 content values be good enough. The referenced sheets split the content up into name value pairs within the content, which I could probably learn to do. Or maybe this is something for another chapter to focus on, like mobile?
Tiggerito
on 8 Aug 2020
Heading elements, logical sequence?
Does the heading logical sequence make any sense now that people
are used to add e.g. a h1 for eachsection?I have a sequence of headings with their levels. But no idea how I can process this into a "makes sense" metric? e.g.
[1,2,2,6,3,4,8]I would suggest for going down it should be in order (e.g. 2->6 is wrong) but going up is allowed. That would not be perfect as things like this are wrong:
h1
h2
h3
- h4
- h3
But it is a simple rule to implement and will give obvious errors.
And are people really used to adding h1 for sections? It's allowed but I personally doubt it's used much. Would be interesting to see how many sites have more than one
<h1>. General advice still seems to be:Don’t use loads of
<h1>s. Make<h1>the main heading of your page, then use<h2>,<h3>,<h4>, etc. in a proper hierarchy without skipping levels.
I like that rule and could probably create a js function to return a good/bad result.
People do a lot of strange things. The SEO chapter also looks into that.
Maybe the markup people can confirm the rules of a valid sequence?
Tiggerito
on 8 Aug 2020
Would a raw dump of say the top 10000 content values be good enough.
I'd be surprised if there was more than a few hundred or so unique content values to be honest, and once you get to that level you'll be dealing with really small percentages. So I'd probably limit to the top 20 or 50 values and if that covers say 95% of usage then we're good.
If it does turn out there are lots of values and you do need thousands of rows to get to that 95% usage, then my approach of listing all the most commonly used values may not be the right approach for that stat. I think 10,000 would be stretching the usefulness of analysing this data in spreadsheets and better done in SQL and really shouldn't go beyond a few 100, and preferable a lot less.
bazzadp
on 8 Aug 2020
What values are used for
srcandsrcsetonimgandsourceelements?
I said yes to this, but have no idea what to gather?OK that's clearly one were all the values would be less than useful, so need some more info on what the requester is looking for. File extension for
srcmight be interesting one for example but probably belongs more in Media chapter than here.This is what we use for hero images on the Almanac:
<!-- Show large image for large screens and high density screens and use webp when supported --> <picture> <source media="(min-width: 327px)" type="image/webp" srcset="/static/images/2019/markup/hero_lg.webp" /> <source media="(min-width: 327px)" type="image/jpeg" srcset="/static/images/2019/markup/hero_lg.jpg" /> <source type="image/webp" srcset="/static/images/2019/markup/hero_lg.webp 2x" /> <source type="image/jpeg" srcset="/static/images/2019/markup/hero_lg.jpg 2x" /> <source type="image/webp" srcset="/static/images/2019/markup/hero_sm.webp" /> <source type="image/jpeg" srcset="/static/images/2019/markup/hero_sm.jpg" /> <img src="/static/images/2019/markup/hero_lg.jpg" class="content-banner" alt="" width="866" height="433" loading="eager" /> </picture>Given that values of
mediaandtypeattributes would be more interesting than thesrcandsrcsetattributes so maybe that's what they meant? If that's the case then those attributes are ones were it would make more sense to list them all and frequency to let the authors pull out relevant stats.What could also be more interesting is the second attribute from the
srcsetattribute, and ignore the first. and this would also apply to<img>elements as much as<source>:<img srcset="elva-fairy-480w.jpg 480w, elva-fairy-800w.jpg 800w" sizes="(max-width: 600px) 480px, 800px" src="elva-fairy-800w.jpg" alt="Elva dressed as a fairy"><img srcset="elva-fairy-320w.jpg, elva-fairy-480w.jpg 1.5x, elva-fairy-640w.jpg 2x" src="elva-fairy-640w.jpg" alt="Elva dressed as a fairy">
Would this be more in the media department. I think they do dig a lot deeper into this sort of stuff.
Tiggerito
on 8 Aug 2020
Would a raw dump of say the top 10000 content values be good enough.
I'd be surprised if there was more than a few hundred or so unique content values to be honest, and once you get to that level you'll be dealing with really small percentages. So I'd probably limit to the top 20 or 50 values and if that covers say 95% of usage then we're good.
If it does turn out there are lots of values and you do need thousands of rows to get to that 95% usage, then my approach of listing all the most commonly used values may not be the right approach for that stat. I think 10,000 would be stretching the usefulness of analysing this data in spreadsheets and better done in SQL and really shouldn't go beyond a few 100, and preferable a lot less.
The sheet you shared had 5,000 unique name value pairs. Which is fine, but I suspect the combinations of them, in different orders, with different spacing, different cases etc would be massive.
I could try and normalise the content, e.g. reorder alphabetically, all lower case, no spaces?
Tiggerito
on 8 Aug 2020
Figure 1 has two columns (if you ignore the 2005 stat they are compared against):
- The number sites with an element - here for example
<title>ranks highly as most sites have 1 instance of that- The frequency of elements (in total? per page?) - here
<title>is no where to be seen (as only used once on a page) and<div>rules the roost as expected.
I thought one query from last year acquired data for both those tables, but now think it is two. I'd already created two metrics for them under the one request. Maybe that other request was for the second metric and I can cross one off 😀
Tiggerito
on 8 Aug 2020
The sheet you shared had 5,000 unique name value pairs. Which is fine, but I suspect the combinations of them, in different orders, with different spacing, different cases etc would be massive.
Yeah I guess it pays to look at stats I'm quoting! ☺️
I'm guessing many are very, very rarely used. See how many rows you need to return until you get 95%. That's a completely arbitrary number btw so maybe 90% is sufficient or 99% is more desirable? I just think if you have top 20 values and it only covers less than 50% of the site for example, then any conclusions are a bit ropey.
I could try and normalise the content, e.g. reorder alphabetically, all lower case, no spaces?
Yes you could, but let's see if you need to do this first. Then again it might be useful as in theory ordering and spacing don't matter (not sure about caps?).
bazzadp
on 8 Aug 2020
Thanks @Tiggerito, @bazzadp!
Two thoughts on scanning:
Headings, outlines, orders don’t look like a super-critical thing to me. I can imagine the SEO team to look into that and I’d be fine with that. (Open to other thoughts.)
Image markup as with
srcsetwas something @catalinred suggested I believe. As it keeps coming up, do you mind clarifying if necessary, Catalin? (I’m not too concerned about that markup—I like it in the chapter but I see it more of a nice to have.)
I’m currently on the road and will review again tomorrow night (CEST).
j9t
on 8 Aug 2020
Yeah heading ordering is probably more for Accessibility chapter to worry about, and maybe SEO. In fact that gave me an idea and I just checked and Lighthouse has a check for this!
"heading-order": {
"id": "heading-order",
"title": "Heading elements appear in a sequentially-descending order",
"description": "Properly ordered headings that do not skip levels convey the semantic structure of the page, making it easier to navigate and understand when using assistive technologies. [Learn more](https://web.dev/heading-order/).",
"score": null,
"scoreDisplayMode": "notApplicable"
},
And yeah it's a tough call as to what fits where. I would say concentrate on what YOU want to explore in this chapter and if there's some overlap, then that's fine. The more likely situation is you will run out of time to explore everything, so prioritise what you want and less important stuff will naturally drop out. It's good to not constrain yourselves during brainstorming, but then at some point it comes to practicalities of writing queries, dealing with any clarifications and oddities, and then analysing the data and you'll soon realise it's better to limit yourselves a bit.
Saying that, if something is interesting to you then don't assume it will be covered by other chapters either!
bazzadp
on 8 Aug 2020
- Image markup as with
srcsetwas something @catalinred suggested I believe. As it keeps coming up, do you mind clarifying if necessary, Catalin? (I’m not too concerned about that markup—I like it in the chapter but I see it more of a nice to have.)
Actually, it wasn't me who suggested that :)
catalinred
on 9 Aug 2020
- Image markup as with
srcsetwas something @catalinred suggested I believe. As it keeps coming up, do you mind clarifying if necessary, Catalin? (I’m not too concerned about that markup—I like it in the chapter but I see it more of a nice to have.)Actually, it wasn't me who suggested that :)
I take the blame of asking for statistics of srcset attribute (and this attribute is not limited to only the img element). ;-)
ibnesayeed
on 9 Aug 2020
Using tips from @bazzadp I created a sheet that lists the most popular meta viewport values.
This is based on a sample of 10k pages, not the full data, and I'm not sure how old the sample is.
To make the values more useful I normalised them:
- removed all spaces
- changed to lower case
- removed unnecessary .0 fractions
- sorted name=value pairs alphabetically
'initial-scale=1,width=device-width' wins about 43% on mobile and desktop.
It's more likely to be missing on a desktop 17% than a mobile 11%.
I think this will be a worthwhile sheet to produce when we have this years data.
Tiggerito
on 10 Aug 2020
Here's a similar sheet for doctypes. This time I just changed them to lowercase and removed any extra spaces.
Tiggerito
on 10 Aug 2020
For srcset, I suggest coordinating with the Media team (cc @tpiros)
zcorpan
on 10 Aug 2020
Hi all,
I've implemented the queries for almost all of the data we agreed on. A few are complex and I've had a long day, so I will leave them to a point where my brain is working again.
The introductory comment for the pull request contains a fill list if the data I'm gathering with links to sample sheets of results. In most cases the data is just made up/random, but the ones related to pages_element_count_ and summary_pages_ are using a real sample set of data.
It would be a good idea to look at what I've come up with to see if it is what you want.
Tiggerito
on 15 Aug 2020
I've updated the chapter metadata at the top of this issue to link to the public spreadsheet that will be used for this chapter's query results. The sheet serves 3 purposes:
- Enable authors/reviewers to analyze the results for each metric without running the queries themselves
- Generate data visualizations to be embedded in the chapter
- Serve as a public audit trail of this chapter's data collection/analysis, linked from the chapter footer
obto
on 1 Sep 2020
I've now updated all queries to point to the latest data and ran a few to test things. Some initial results are in the sheet:
Once the queries have been reviewed I can continue to populate the sheet.
Tiggerito
on 5 Sep 2020
@Tiggerito, while we’re now getting ready to work with the data, just to confirm, you’d let us know when we can do so, or should we take a different approach, or do you need something from either of us here right now?
Essentially just checking in as we’ve reached the next milestone—and not meaning to rush :)
j9t
on 9 Sep 2020
@Tiggerito, while we’re now getting ready to work with the data, just to confirm, you’d let us know when we can do so, or should we take a different approach, or do you need something from either of us here right now?
Essentially just checking in as we’ve reached the next milestone—and not meaning to rush :)
I'm waiting on the queries to be reviewed and merged before I go full speed and start populating the sheet. I did ad a few results to the sheet so you guys could get an idea on the format and maybe play with how you can convert the data into usable charts etc.
Tiggerito
on 10 Sep 2020
Our queries have been approved and merged into he project. I will now start pulling in the data 🥳
Tiggerito
on 20 Sep 2020
All the data is now in the results sheet. To make things easier I've added a column to the metrics sheet. That links to the tabs with the relevant results.
Tiggerito
on 20 Sep 2020
Pardon the delay!
All the data is now in the results sheet. To make things easier I've added a column to the metrics sheet. That links to the tabs with the relevant results.
That’s awesome, thanks @Tiggerito! I suppose that means @iandevlin, @catalinred, and I can now dive in and get back to you for any questions? I’m taking this on as my homework and will try to get back to you (or the group here) asap!
j9t
on 21 Sep 2020
I realize this is pretty late in the game but a thing just came up on twitter (https://twitter.com/sil/status/1308825654000001028) that could be an interesting nugget in the markup chapter of the almanac - basically, how many pages contain "best viewed [at|with] [chrome|webkit|firefox|edge|ie|screen-size]". The screen size or designation (or IE) would have an interesting side effect of being a hint about the probable age of the code as well :)
bkardell
on 23 Sep 2020
Thanks @bkardell that'd be interesting data! I'd suggest adding a custom metric to detect that from the HTML response body. That data would be available in November at the earliest, so not very practical for the 2020 chapter, but something we could write a blog/forum post about and/or cover in the 2021 chapter. Would you (or anyone else) be interested in writing the custom metric?
rviscomi
on 23 Sep 2020
Hey everyone—just to give a status: I’ve been in touch with Tony and Rick over the desktop and mobile numbers to, just to have this documented, work with both data if the distinction is needed, but to otherwise look at the _mobile_ data. (Desktop and mobile cover pretty much the same URLs, if I recall the chats and a scan of the methodology documentation right.)
Now, I’m planning to go through the results to begin working on the draft. As I’m spread very thin I’d not like to become a bottleneck, however—I’d love it if we can start somewhat in parallel, @iandevlin and @catalinred. Can you share your own status and thinking?
If I don’t get to make significant progress over the next week I would like to talk about a Plan B so that our timeline—which, given delay on the final data end I wouldn’t peg at Oct 12 for the draft anymore? @rviscomi?—is not put in danger. This just as a heads-up as, unfortunately, I couldn’t dedicate as much time to the chapter yet as I’d have liked to. I dislike that already, and the least I see myself doing is be transparent and help mitigate where needed.
j9t
on 27 Sep 2020
Desktop and mobile cover pretty much the same URLs, if I recall the chats and a scan of the methodology documentation right.
Most of the URLs are in both sets. If a page serves different content depending on the UA string, it's possible for the same URL to produce different markup across desktop and mobile, but this would be rare and statistically insignificant if I had to guess. The mobile set is a bit larger, so if you were to only look at one that's the right choice.
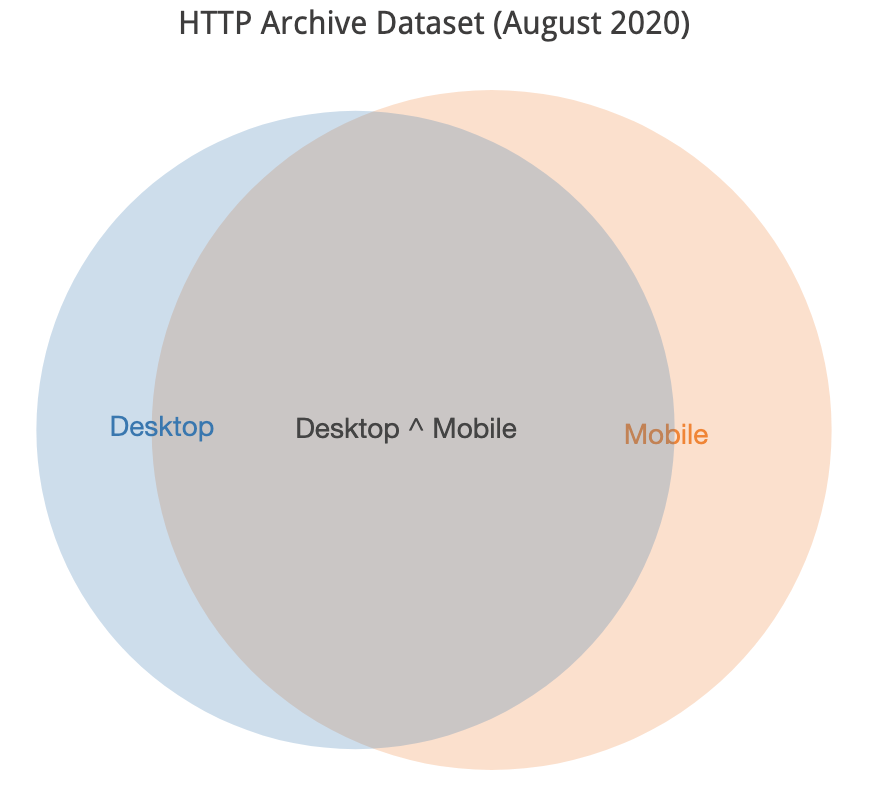
desktop | mobile | mobile_only | desktop_only | both | either
-- | -- | -- | -- | -- | --
5,593,642 | 6,347,919 | 1,953,067 | 1,198,790 | 4,394,852 | 7,546,709
given delay on the final data end I wouldn’t peg at Oct 12 for the draft anymore? @rviscomi?
These milestones help us stay on schedule for the target release date, so while it's ok for one or two to slip, I do hope that the lost time can be made up in other milestones. So I'd still like to see you aim for a draft by Oct 12, but if not we can explore options to get back on schedule or delay this chapter's release as a last resort.
rviscomi
on 27 Sep 2020
FYI, @bazzadp just posted about a Lighthouse query that may contain data of interest. The post contains screenshots of examples:
https://app.slack.com/client/T5ELN8H17/CGFLV2S06/thread/CGFLV2S06-1601119631.003300
Tiggerito
on 28 Sep 2020
I’ve been digging myself into the data, and am slowly starting to fill the draft.
I’ve pinged you, @iandevlin, @catalinred, by mail to coordinate and to contribute fire power—this is going to be some work and it would be great to break it up a little.
Quick note: I’m using “§” in the draft to refer to respective sheets in the data spreadsheet. I’m also referencing draft sections from the spreadsheet, to allow for some clue whether and where it’s being covered.
Will send more updates.
j9t
on 28 Sep 2020
There’s more progress in the draft. (Note some status and infos—marked “⚠️”—at the beginning.)
At the moment I put all energy into providing a foundation and first draft. That I also intend to push through until Oct 12 (FYI @rviscomi). Yet then I’m in need to hand over to someone for the next sweep (I’m around to edit and review during that time). @iandevlin, @catalinred, let me know if I missed feedback from you, however it would be awesome if you could let me know about your preferences and availability so that we can coordinate on this.
A general note, then—if you have a few minutes to spare to help now, please give the draft doc a quick scan and sanity check and let me know directly if there are any questions or concerns. (@bazzadp, could you perhaps signal me whether that’s on track?) That could be helpful so that in this draft stage, I don’t blindly run into some problem. Thanks!
j9t
on 30 Sep 2020
Looks like a good start @j9t ! Made a few comments but looks like it's on the right track.
Some more food for thought (some of which you've obviously thought about yourself already I can see from this draft):
- What to repeat from last year? There's a balance here as want to refer to and update last year's chapters but don't just want to say the same thing again.
- What to drop from last year? Don't be afraid to do this if something was completely covered last year, or no further insight's this year.
- What new this year to differentiate it from last year? We want to build upon last year and bring new insights each year.
- Any linkage and cross-referencing to other chapters? I'm a big fan of this to make the Web Almanac seem like one coherent report than separate chapters.
- What stats to include? And what to ignore? Some of the stats we've gathered just won't be that surprising and interesting so pick and choose what to include rather than try to squeeze it all in.
- What sort of graphics to include? Last year's Markup chapter had a lot of different chart types compared to some chapters so a lot to live up to here! 😀
- Any more funky interactive we can include? This issue was inspired by this chapter's glitch app so is there something along those lines that we could include directly in the chapter this year? Dev team will need to help with this obviously but looking for Authors to come up with the what, and we'll look at the how.
- Are there any big outliers that are amusing or exciting to read? Good thread on that in our slack with some examples (including one that went viral last year).
- How to build a story across the chapter and move from one section to the other and then sum up in the conclusion.
bazzadp
on 1 Oct 2020
Thanks @bazzadp and @zcorpan for your feedback! This is very helpful, this will be very useful to include. Just so that you’re not surprised, I’ve either moved some of the comments into the doc (Barry, I expanded the draft intro to call out to add more graphics, cross-refs, etc.) or will keep them for now so that either I or a co-author can respond and take care of them.
j9t
on 1 Oct 2020
Thanks @bkardell that'd be interesting data! I'd suggest adding a custom metric to detect that from the HTML response body. That data would be available in November at the earliest, so not very practical for the 2020 chapter, but something we could write a blog/forum post about and/or cover in the 2021 chapter. Would you (or anyone else) be interested in writing the custom metric?
I could write the metric, but would need a lot of guidance on how/what to look for. i.e. all the phrases to look for and what data to extract.
Tiggerito
on 4 Oct 2020
Small progress update: There _is_ steady progress 💁♂️ At the moment that’s still largely foundational work, transferring metrics over from almost all areas (which we’ll then augment and edit).
Feel free to have a look at the draft at any time and to leave comments on anything major. I’ll post more updates and will work with @catalinred and @iandevlin on inviting for general review as soon as we can.
j9t
on 6 Oct 2020
More progress. Most sheets are now represented in the draft.
I’ve moved some stuff from “Trivia” to “General,” which makes for a better balance.
I’ll soon shift from blindly shoveling data into the doc to editing—the last sheet for me to focus on is likely going to be pages_element_count_by_device_and_percentile.sql (already marked as WIP).
@catalinred (or @iandevlin), our line was interrupted lately, can you focus on the currently open sections (“Input types”, “Button types”, and “Links in new windows” as well as any sheets marked “🛑”—unrepresented) to retrieve anything of interest there? And—can you do so by end of _tomorrow_, to maintain a chance of a good editing sweep on Sunday, in time to possibly invite for first reviews on Monday (Oct 12)? That would be 🚀🚀🚀🚀🚀🚀🚀🚀 😁
(The editing phase should then pick up slack on comparisons to last and other years, cover trends, add graphics, revisit the tone, what not. There’s still more to do for sure.)
(I’m in serious crisis mode working on this. I intend to pull this through with you until this is out, but I may need to quite cut my time investment. If @catalinred or @iandevlin or someone else could coordinate with me to switch driver seats at times, that would be awesome. Please reach out and I’ll do my best to support you as a co-pilot. 🥂)
j9t
on 9 Oct 2020
(Added and edited a little more, now focusing on a first review—should finish and incorporate edits by tomorrow; small chance it could be Monday. Reached out to @catalinred and @iandevlin both per mail and through doc comments to coordinate on open content parts.)
j9t
on 10 Oct 2020
Reviewed the current draft and made a first round of edits; also added a bit more detail here and there; also left some notes and comments. It’s clearly not done yet but I think it’s a foundation.
I’m on the road tomorrow but will have the manuscript with me to go through once more.
@catalinred, @iandevlin, and I are in touch; we’re accruing a bit of delay when it comes to the Oct 12 deadline, yet given the Oct 26 deadline for being done, as I understand it, it seems we’re still on track for that deadline.
More updates to follow.
j9t
on 11 Oct 2020
Thanks for the update @j9t it's exciting to see your team's progress!
rviscomi
on 12 Oct 2020
@catalinred, @iandevlin, and I keep at it… at the moment (though I just missed to raise this in our last email correspondence) I think we might be able to open the draft up for in-depth review this weekend.
I haven’t looked at the graphics situation at all yet—how’s that normally handled, who could help generate/export them? @rviscomi, @bazzadp, I may have overlooked this?
j9t
on 14 Oct 2020
I haven’t looked at the graphics situation at all yet—how’s that normally handled, who could help generate/export them? @rviscomi, @bazzadp, I may have overlooked this?
There’s a fascinating, and not at all overly-long and drawn out, read on that in this Figures Guide 😀
bazzadp
on 14 Oct 2020
Status: Just edited the doc again, added missing copy, pinged open todos, reviewed and responded to comments. Pretty close to calling for review. Coordinating with @catalinred and @iandevlin on the last steps and todos (Catalin, Ian, just sent an update per email). Trying to gauge whether we can add the remainder until EOD tomorrow (Mon), to soon after that open the draft for review.
Note: The last two sections may take a few extra days, as I’ll wait for the remainder to be in to write these. They may require a separate review but should not slow us down much.
j9t
on 18 Oct 2020
🚨 The draft doc is now ready for review, @zcorpan, @ibnesayeed, @matuzo (and everyone else who is available and interested)!
ℹ️ The last two sections (status and conclusion) are not done yet—I’ll handle these until the weekend (Oct 25) to then ask for a separate review. That seemed desirable to keep moving.
Please review and leave comments in the doc, and general thoughts here.
Special thanks to @catalinred, @iandevlin, and @Tiggerito for all their work over the last few days! 🙏
j9t
on 20 Oct 2020
Hey!
I’ve added comments, but I’m a bit out of the loop. So, if my questions don’t make sense or if you've already discussed the issues raised, just ignore them and delete my comments. :)
Great work, I enjoyed reading the draft!
matuzo
on 21 Oct 2020
Timing: You may have all seen @rviscomi’s launch date update. Given the progress we’ve already made I’d like us to use this to commit to and push for the Nov 9 date (for matching the Oct 26 goal). Let’s do this 🙏 🚀
j9t
on 21 Oct 2020
I hadn't seen it, but I agree.
On Wed, 21 Oct 2020 at 21:43, Jens Oliver Meiert notifications@github.com
wrote:
Timing: You may have all seen @rviscomi https://github.com/rviscomi’s launch
date update
https://github.com/orgs/HTTPArchive/teams/almanac-contributors/discussions/8.
Given the progress we’ve already made I’d like us to use this to commit to
and push for the Nov 9 date (for matching the Oct 26 goal). Let’s do this
🙏 🚀—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/HTTPArchive/almanac.httparchive.org/issues/899#issuecomment-713831772,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AAEHKVSDZUAOZJ3J54NTED3SL42WNANCNFSM4OJ2CAOQ
.
iandevlin
on 21 Oct 2020
@j9t in case you missed it, we've adjusted the milestones to push the launch date back from November 9 to December 9. This gives all chapters exactly 7 weeks from now to wrap up the analysis, write a draft, get it reviewed, and submit it for publication. So the next milestone will be to complete the first draft by November 12.
However if you're still on schedule to be done by the original November 9 launch date we want you to know that this change doesn't mean your hard work was wasted, and that you'll get the privilege of being part of our "Early Access" launch.
Please see the link above for more info and reach out to @rviscomi or me if you have any questions or concerns about the timeline. We hope this change gives you a bit more breathing room to finish the chapter comfortably and we're excited to see it go live!
obto
on 22 Oct 2020
@obto, I appreciate you trying to make sure we all saw the update but the last note was about exactly that. To avoid any confusion here:
Given the progress we’ve already made I’d like us to use this to commit to and push for the Nov 9 date (for matching the Oct 26 goal). Let’s do this 🙏 🚀
Thanks everyone who reviewed so far! @catalinred, @iandevlin, and I have been working through the comments, and until the weekend we should have the last two sections available, too.
j9t
on 22 Oct 2020
I also added some comments - interesting stuff :)
bkardell
on 23 Oct 2020
Thanks @bkardell! It's great to see reviews by previous authors :)
Can you also add yourself to the contributors file? I've updated the metadata at the top of this issue to add you to the list of reviewers.
rviscomi
on 23 Oct 2020
(The last two days brought more updates, and pretty much all content is in now, but I’ll give another update tomorrow to share more and call for another review.)
j9t
on 25 Oct 2020
🚨 After all the updates over the last few days (incorporating review feedback, general editing, adding the last missing sections, updating graphics) I’d like to call another and possibly final review round for the doc:
- Could everyone please give the doc another read?
- @catalinred, @iandevlin, could we together keep an eye on and go over all comments to resolve them?
- Reviewers, can you give past and future comments a check and clarify on how important you deem them?
I’d also be curious about any general feedback—if you could leave a high-level comment in the doc, share feedback here, or message me directly that would be awesome!
Minor note: I’ve sorted contributors somewhat by order of appearance. We’ll look at this again at the end but please raise it with me if you think there’s been an oversight—there may sure be!
On the next steps: I understand that once we feel content with the draft (let’s aim for Wednesday?) we can freeze the draft and move it to Markdown. @rviscomi, is that correct? Pardon me if I’m just too quick running through everything right now, but is there some documentation on this? What’s linked in the intro doesn’t seem to work (yet), and I can’t find anything tangible on a quick search.
Last but not least: A big thanks in between to everyone who has contributed so far! This has been impressive. I’m super glad you’re all there, and I for my part find the draft reads better and better, and gets more useful and more useful, every time one goes through! High five everyone! 🙏
j9t
on 26 Oct 2020
Kudos to the team for doing a phenomenal job with this chapter. Keep up the momentum!
On the next steps: I understand that once we feel content with the draft (let’s aim for Wednesday?) we can freeze the draft and move it to Markdown. @rviscomi, is that correct? Pardon me if I’m just too quick running through everything right now, but is there some documentation on this? What’s linked in the intro doesn’t seem to work (yet), and I can’t find anything tangible on a quick search.
Yes, once the draft is finalized, it will be converted to markdown and submitted as a PR to the linked directory. There aren't any 2020 chapters checked in yet, so it 404s. Here's the 2019 chapter for reference: https://github.com/HTTPArchive/almanac.httparchive.org/blob/main/src/content/en/2019/markup.md
The Chapter Lifecycle doc has some info on transitioning from draft to publication. Let me know if you have any questions not answered there.
rviscomi
on 26 Oct 2020
Good progress all!
A few admin things and the like that should be in the markdown pull request, as seen other chapters make some mistakes here which required correcting so thought I’d give you the heads up on these:
- Please include the meta data at the top. See last years chapter as an example and your discussion thread id for this year is 2039.
- Please include an Introduction and a Conclusion (see you already have this covered but gonna copy and paste this list for others 🙂)
- Please start with
## Introduction- the chapter tile and hero image will automatically be added by our templates. - Please ensure paragraphs are entered on one line and not line-breaked every 80 characters (which makes it difficult to edit or make corrections without reordering them all).
- Other chapters should be linked like
./cssor../2019/markupfor 2019 chapters so they are relative links and work across translations. - Please include Figure markup - see the Figures wiki - including captions, descriptions, sheets link and sql query link.
- Please include Fallback png images (for mobile where we don’t embed the sheets iframe) and also any external images you want to include.
- Please size your images appropriately and ideally compress them using https://tinypng.com/ (we have a GitHub Action to compress images but find tinypng.com does a better job)
- Please give all fall back images meaningful file names (e.g. top-elements.png rather than fig1.png)
- Authors all get a short bio - see last years chapter for an example. This isn’t part of the Chapter markdown and don’t have the file to save that to yet (but will have soon!) so just a heads up for now. Can comment here with your bio and we’ll to git add later.
- We’ll need a featured quote and 3 stats for the home page - see last years quotes for examples. Again don’t have the file ready for that just yet. We’ll do this last once the chapter has been edited but again good to start thinking about it.
Think that’s all for now but I’m sure I’ll think up more rules to make your life more painful if I can! 😉
bazzadp
on 26 Oct 2020
79% of documents checked with the W3C HTML checker (validator) have errors
Earlier today I added a counter to https://validator.w3.org/nu/stats.html that collects data on how many documents checked by the W3C HTML checker have errors. See the Conformance: Documents with errors row.
So far it looks like about 79% of the documents it sees have errors — and so about 21% have zero errors.
 sideshowbarker
on 28 Oct 2020
sideshowbarker
on 28 Oct 2020
That’s some impressive stats @sideshowbarker, thanks for sharing this!
catalinred
on 28 Oct 2020
79% of documents checked with the W3C HTML checker (validator) have errors
…! I felt free to add a reference in our conclusion (and to perhaps point to this elsewhere)—thanks for sharing @sideshowbarker!
j9t
on 28 Oct 2020
They are interesting stats alright, but I do have some concerns about including them.
These are tests run through the W3C Validator so could be at any point in the development cycle, whereas the rest of our stats are on published websites. Presumably only the 56% of GET-based requests are actual websites, and even then they could be development sites?
Surely it is a good thing that developers are running sites through this tool (and hopefully) correcting their HTML errors? And if that takes several attempts Then you're gonna stop when you're finally validated so could have 9 fails and only 1 success - making it look like only 10% of requests pass but in this (somewhat contrived) example 100% of sites now have valid HTML. Do we really wanna call out that developers are validating their HTML and finding errors?
And that's not to say all the other websites (including ours!) that have other ways of validating our HTML so is this tool biased towards sites that don't already validate their HTML automatically (or why would you run it through this tool?) so more likely to get errors? It also could easy (but incorrectly!) be read as 79% of websites have HTML errors when read quickly in conjunction with our other stats.
Not saying you shouldn't include it, as it is an interesting stats, but saying give these things some thought.
bazzadp
on 28 Oct 2020
These are good points, @bazzadp. The way the doc talks about this right now is “side note, use with caution: of W3C-tested documents, 79% have errors.” I’d feel comfortable with that—it doesn’t go into detail but suggests to take with a grain of salt—but am open to tweak more. (We can probably take that into the doc.)
j9t
on 28 Oct 2020
ℹ️ We’re _very_ close to being able to move to next stage, converting the chapter to Markdown and polishing it there.
Only a handful of issues are still open at this point. @catalinred, @iandevlin, could you check on those, too, and could the reviewers please have a quick scan, too, where perhaps their input is needed again? I’ll do another sweep tomorrow morning and give an update again during the day—unless something major comes up that requires more attention we might hit a good milestone then!
Thanks everyone again for your work over the past days!
j9t
on 28 Oct 2020
ℹ️ We’re getting closer and closer—thanks all 😊 @iandevlin, @catalinred, @Tiggerito, there are just 5 comments left—could you have a look and help resolve these?
Once we are down to 0 comments I’d take that as a sign we’re good to move on to the next stage. I’m likely to dig into this and prepare a PR, but will otherwise raise a hand here or in our author thread.
j9t
on 29 Oct 2020
Morning.
I can only take a look this evening as I am out all day today.
Regards,
Ian
On Thu 29 Oct 2020, 19:47 Jens Oliver Meiert, notifications@github.com
wrote:
ℹ️ We’re getting closer and closer—thanks all 😊 @iandevlin
https://github.com/iandevlin, @catalinred
https://github.com/catalinred, @Tiggerito https://github.com/Tiggerito,
there are just 5 comments left
https://docs.google.com/document/d/1m1YvDqWgZfqmcmAEkCnXncIJwsM1QCu6Rv7aPWjG1Ms/edit#—could
you have a look and help resolve these?Once we are down to 0 comments I’d take that as a sign we’re good to move
on to the next stage. I’m likely to dig into this and prepare a PR, but
will otherwise raise a hand here or in our author thread.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/HTTPArchive/almanac.httparchive.org/issues/899#issuecomment-718950278,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AAEHKVV4PZLLZ2KZXWV4LDLSNG2D3ANCNFSM4OJ2CAOQ
.
iandevlin
on 30 Oct 2020
We’re pretty much done with the draft! I’m coordinating with Ian and Catalin and aim to start the conversion process soon, likely this weekend—more shortly!
j9t
on 30 Oct 2020
🚨 (😬) We’re comment-free with the draft!
To get there I’ve gone for another sweep and edit of the doc, including, by the way, a lot more detail (percentages) in one of the attributes sections. If you notice something there please let me know.
I’ll now look at the next steps and follow up where need be. For this purpose I may “freeze” the doc, too—I’ll make this visible in some fashion and probably point it out here, too. During that freeze please wait with comments or ping me to coordinate.
Thanks again everyone for your work and help with this, and talk very soon!
j9t
on 31 Oct 2020
(Preparation in progress with https://github.com/j9t/almanac.httparchive.org/blob/main/src/content/en/2020/markup.md.)
j9t
on 31 Oct 2020
ℹ️ I marked the draft as frozen. Conversion in progress—see https://github.com/HTTPArchive/almanac.httparchive.org/compare/main...j9t:main for a temporary diff and status indicator. Might work on this over the next few days to soon share another update.
j9t
on 1 Nov 2020
Where do I leave comments?
The paragraph on module/nomodule is still confused/wrong. 0.95% is of pages, not of module scripts. Also, nomodule is an attribute that you specify on a classic script, to be run in old browsers that don't support type=module.
If we don't have comparable metrics between type=module and nomodule, I think it's better to leave out mentioning nomodule.
zcorpan
on 2 Nov 2020
In this case, can you comment in the doc, @zcorpan ? It will be easier to follow up there.
j9t
on 2 Nov 2020
@zcorpan, for some reason I can’t tag you in the doc: Can you review and help with the module matters? That would be super-awesome. I’m there to resolve this and reflect it in the Markdown version I’m currently setting up.
j9t
on 3 Nov 2020
Done.
BTW, maybe I'm late with this suggestion for this chapter, but, I've used Docs to Markdown add-on in the past, and it worked pretty well.
zcorpan
on 3 Nov 2020
(@zcorpan, thanks for following up in the doc; I responded in there.)
I’ve prepared the initial version of the chapter to be merged: https://github.com/HTTPArchive/almanac.httparchive.org/pull/1409. Please advise, @rviscomi, @obto, @bazzadp 🙏
j9t
on 3 Nov 2020
Awesome effort by this team and thanks @j9t for driving it! We'll get the PR reviewed ASAP and it should be ready in time for a November 9 early release. 🎉
rviscomi
on 3 Nov 2020
Definitely most of the credit goes to @j9t, who has been an absolute demon. Thank you sir.
iandevlin
on 3 Nov 2020
Some more work on https://github.com/HTTPArchive/almanac.httparchive.org/pull/1409.
For the results, are we to use https://docs.google.com/spreadsheets/d/1Ta7amoUeaL4pILhWzH-SCzMX9PsZeb1x_mwrX2C4eY8/? I have a vague task on my list to review and clean up the spreadsheet (check formatting, close comments, remove internal notes)—I suppose that can be done then? @rviscomi, @Tiggerito?
j9t
on 4 Nov 2020
I'm not an expert at google sheets. I do know there is an option to copy a sheet and exclude comments in the copy?
Tiggerito
on 5 Nov 2020
This is the official sheet that will be linked from the chapter, so make it look how you want readers to see it. Comments are ok for some context and explanations of intended interpretation, but the main thing will be discoverability of metrics. Since so many metrics are packed into single tabs and the tabs are generically named I think that will be the biggest issue. (I did also flag that during analysis but it was outweighed by query costs.) To offset that, I'd encourage you to add metadata to the figures so that we can generate deep links into the sheet from each chart, like the sheets_gid attribute.
rviscomi
on 5 Nov 2020
Thanks @Tiggerito, @rviscomi. I can’t assess that meta data issue just now but preparing the sheet should generally not be an issue.
j9t
on 5 Nov 2020
(Review of https://github.com/HTTPArchive/almanac.httparchive.org/pull/1409 happily in progress ☺️ ⏳)
j9t
on 5 Nov 2020
Used the time to also go through the results sheet to prepare that. Made styling more consistent, aligned headers, resolved comments, etc.
j9t
on 5 Nov 2020
I've merged in @j9t 's Markup markdown pull request now. Congratulations on being the first 2020 team with a merged chapter!!!
I've uploaded a test deploy for those interested to see what it looks like in all it's glory.
There's still a couple of things to do:
We still need chapter bios from @catalinred and @iandevlin , so if you could submit a PR whenever you get a chance to write these:
And we'll be entering the Edit stage next where one of the Editing team will be reviewing the language for grammar, spelling and consistency across the Web Almanac. We'll tag you in the Pull Request for that so you can review the changes and make sure you're comfortable with them.
Thanks again for the tremendous effort here, and for completing this on time (you wouldn't believe the effort in chasing so many teams, so definitely appreciated when we don't have to!)
bazzadp
on 6 Nov 2020
Very, very, very excited to see this. Thanks @bazzadp and @rviscomi for all your working with me on the latest meters (and yards)!
I’m curious about the editing stage now but will likewise review the outcome again; and I encourage everyone to maybe give the chapter is another read or scan, too.
Exciting! 🥂
j9t
on 7 Nov 2020
(May still leave status updates here, even though this one is closed.)
While there’s a “final” PR open with https://github.com/HTTPArchive/almanac.httparchive.org/pull/1435 (I’ve left some initial but also high-level feedback), I’ve just gone through the spreadsheet again to make sure it’s consistently formatted and such; all good to go from my end.
j9t
on 8 Nov 2020
Congratulations everyone, this chapter has been published for early access! https://almanac.httparchive.org/en/2020/markup
rviscomi
on 10 Nov 2020
I do not remember when I was supposed to review the content as a reviewer. I was waiting for a call for review.
ibnesayeed
on 10 Nov 2020
I do not remember when I was supposed to review the content as a reviewer. I was waiting for a call for review.
The first call was about three weeks ago, followed by a few more updates asking for reviews.
j9t
on 10 Nov 2020
Thanks @j9t for the reference. I somehow missed it. If it is marked done then that's great, otherwise let me know if it needs further review.
ibnesayeed
on 10 Nov 2020
@j9t @catalinred @iandevlin and everyone else, in case you're interested, we have an analytics dashboard where you can see how many page views your chapter has received so far: https://datastudio.google.com/s/qoUxiLqPt9U. As of today, the Markup chapter has 1400+ page views and readers spend an average of 3:46 on the page. It's off to a great start!
If readers have feedback/questions/comments about the chapter, be aware that we're sending them to https://discuss.httparchive.org/t/chapter-3-markup/2039. It'd be a good idea to create an account and subscribe to the thread so you can be notified of any new comments.
And a status update on the editing process: #1435 is merged and there are a few unresolved TODOs left in the markdown. Enjoy a bit of a break if you need it, no rush, but it'd be great to resolve all of those before the full launch on December 9.
rviscomi
on 15 Nov 2020
Just an FYI, I gathered some data on the top meta tag name and properties:
https://docs.google.com/spreadsheets/d/1ram47FshAjzvbQVJbAQPgxZN7PPOPCKIK67VJZCo92c/edit#gid=704388228
https://docs.google.com/spreadsheets/d/1ram47FshAjzvbQVJbAQPgxZN7PPOPCKIK67VJZCo92c/edit#gid=1174860536
Tiggerito
on 23 Nov 2020
@Tiggerito we’re adding the direct links from the Figures (see pull request #1570 but still early days). While working on this I noticed you haven’t included the sql_files param to the Graphics and only to the Tables. Can you do a pull request to add these params to each figure_markup call? That way people will be able to see your hard work!
Also (for everyone), you probably don’t want to hear more suggestions, but another thing I noticed was that the chapter starts with lots of nice graphs but from about halfway moves to tables and only has tables from then on. Is there any data we could present as charts instead of tables, or additional tables, to break up the chapter a bit?
bazzadp
on 23 Nov 2020
@bazzadp done
Tiggerito
on 24 Nov 2020
Related issues
ibnesayeed
·
5Comments
rviscomi
·
5Comments
rviscomi
·
3Comments
rviscomi
·
5Comments
rviscomi
·
5Comments
Most helpful comment
I've merged in @j9t 's Markup markdown pull request now. Congratulations on being the first 2020 team with a merged chapter!!!
I've uploaded a test deploy for those interested to see what it looks like in all it's glory.
There's still a couple of things to do:
We still need chapter bios from @catalinred and @iandevlin , so if you could submit a PR whenever you get a chance to write these:
https://github.com/HTTPArchive/almanac.httparchive.org/blob/a8ef094c5f8ea256905868570796dcd602b5e266/src/content/en/2020/markup.md#L7-L9
And we'll be entering the Edit stage next where one of the Editing team will be reviewing the language for grammar, spelling and consistency across the Web Almanac. We'll tag you in the Pull Request for that so you can review the changes and make sure you're comfortable with them.
Thanks again for the tremendous effort here, and for completing this on time (you wouldn't believe the effort in chasing so many teams, so definitely appreciated when we don't have to!)