Zig: Suggestions for misspelled variables / scope items
We should be nice to our programmers and give suggestions for typos.
fn helloworld() void {}
test "test" {
hellowold();
}
should return:
/Users/cfkk/Source/zig2/build/distance.zig:4:3: error: use of undeclared identifier 'hellowold'; did you mean 'helloworld'?
hellowold();
^
/Users/cfkk/Source/zig2/build/distance.zig:1:1: note: 'helloworld' declared here
fn helloworld() void {}
^
 kristate
kristate
All 14 comments
I'm generally against these kinds of error notes. I think they're fun in theory but in practice useless, and sometimes downright misleading. I see this as adding bloat to the compiler code for neutral to negative benefit.
 andrewrk
on 1 Sep 2018
andrewrk
on 1 Sep 2018
@andrewrk That is unfortunate to hear.
As you are most-likely aware, this feature is in clang and many other compilers.
It is seen as a boon by many and obviously I think so too. One such example is given here:
Clang provides the best diagnostics messages I’ve seen on a C compiler.
and here:
Better compiler diagnostics. Clang usually provides much better diagnostics in case your code fails to compile, which means that you need to spend less time trying to understand what you should do to fix your code. It even goes further by suggesting you of the most likely fixes. I’ll give you two examples!
As we gear-up for the last of 0.3.0, lots of people are incoming to the language and I think there should be an effort to make error messages more friendly and understandable. Just like how you are excited about stack traces, lots of programmers are excited about error messages, too :-)
Lastly, this could be used inside of editors that support machine readable errors a la #1026
kristate
on 1 Sep 2018
I would guess that "did you mean" style messages are most helpful when you think you've spelled the symbol correctly and you don't see the error when you look at the symbol. In these cases a "did you mean" message might save you from bewilderment.
I'm not relying on experience, it's just a guess. If this is correct, such a system could be used only in case of minor spelling mistakes. Maybe that is the case already in other compilers, I don't know.
 ghost
on 1 Sep 2018
ghost
on 1 Sep 2018
@UniqueID1 yes, there are times when I am hacking at 3am and you get weirded-out by camelCase issues. This patch will help identify that situation.
kristate
on 1 Sep 2018
I mistype things rather frequently and a simple error on the undeclared identifier has always made it clear enough what the problem is.
From an accessibility perspective, however, I think is worth asking if such a feature would be useful to dyslexics.
 tgschultz
on 1 Sep 2018
tgschultz
on 1 Sep 2018
Once the self hosted compiler reaches feature parity with the C++ implementation, everyone should switch to the self hosted compiler except for the boostrapping process for building the self hosted compiler. In the future of the C++ implementation, we definitely don't need this feature, and if it were implemented it should be deleted to make the C++ implementation easier to maintain. It seems like a waste to have this feature now when it's going to be useless later.
Whether this feature is positive, negative, or neutral value in general is subjective, which makes the complexity of the implementation difficult to justify, but not impossible. At the very least I would strongly recommend holding off on this feature in the C++ implementation.
 thejoshwolfe
on 1 Sep 2018
thejoshwolfe
on 1 Sep 2018
@thejoshwolfe I was under the impression that the C++ implementation would be in parity with stage2?
I already implemented the feature in #1449 -- it adds 115 lines are removes 1 line.
kristate
on 1 Sep 2018
The stage1 C++ implementation only needs to build the stage2 self hosted implementation, and it doesn't have to do it well, just adequately. This means it's ok if the optimizations aren't all there or the error messages aren't as helpful. It's still important that all the semantics are the same, but this issue isn't about language semantics.
thejoshwolfe
on 1 Sep 2018
853 seems to outline stage1 -> stage2 -- anything that helps us debug and get stage2 written faster seems like a good idea.
kristate
on 1 Sep 2018
anything that helps us debug and get stage2 written faster seems like a good idea.
Its not clear how this addition to the stag1 compiler would make development of the self hosted compiler faster. I actually doubt there is much that can make it faster other than fixing existing issues (like currently 0.3 mainly) and thus giving Andrew more time on that issue.
I think in the short term (until 0.3) maybe docs (via the stage two compiler) are feasible (much like only stage two can do fmt) if you want to take onto something. This makes it faster to write zig because you can actually read the docs without the implementation in between like you have to when you read the code as its currently required.
Or if you can get language server going because then you do not nearly make those typos nearly as fast because you can just auto complete.
ghost
on 1 Sep 2018
I didn't think this would be such a heated debate :-)
kristate
on 1 Sep 2018
The clang errors that do this save me much time, so i'm for implementing this, especially as the work has already been done.
 shawnl
on 2 Sep 2018
shawnl
on 2 Sep 2018

I don't understand the appeal of this. The suggestion isn't even the correct type.
andrewrk
on 3 Sep 2018
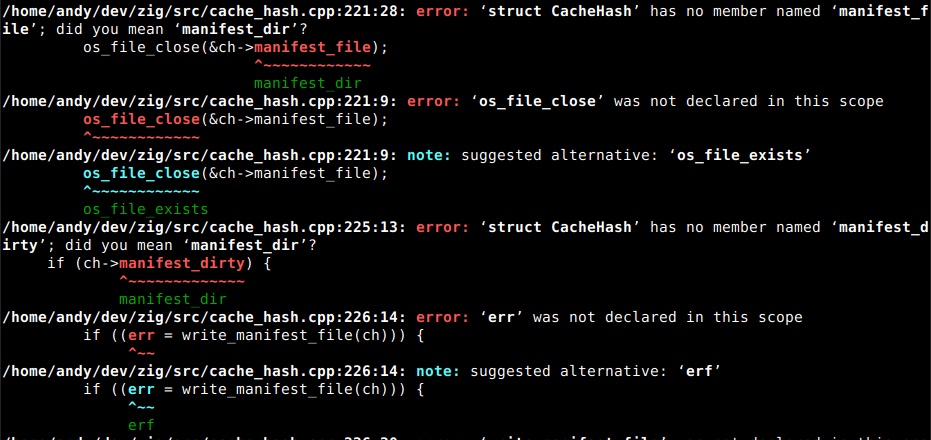
every one of these would be bugs
andrewrk
on 9 Sep 2018
Related issues
 dobkeratops
·
3Comments
andrewrk
·
3Comments
dobkeratops
·
3Comments
andrewrk
·
3Comments
 bronze1man
·
3Comments
bronze1man
·
3Comments
 komuw
·
3Comments
andrewrk
·
3Comments
komuw
·
3Comments
andrewrk
·
3Comments
Most helpful comment
I mistype things rather frequently and a simple error on the undeclared identifier has always made it clear enough what the problem is.
From an accessibility perspective, however, I think is worth asking if such a feature would be useful to dyslexics.