System information
Type | Version/Name
--- | ---
Distribution Name | Redhat
Distribution Version | 7.2
Linux Kernel | 3.10.0-327.el7.x86_64
Architecture |
ZFS Version | 0.6.4.2
SPL Version | 0.6.4.2
Describe the problem you're observing
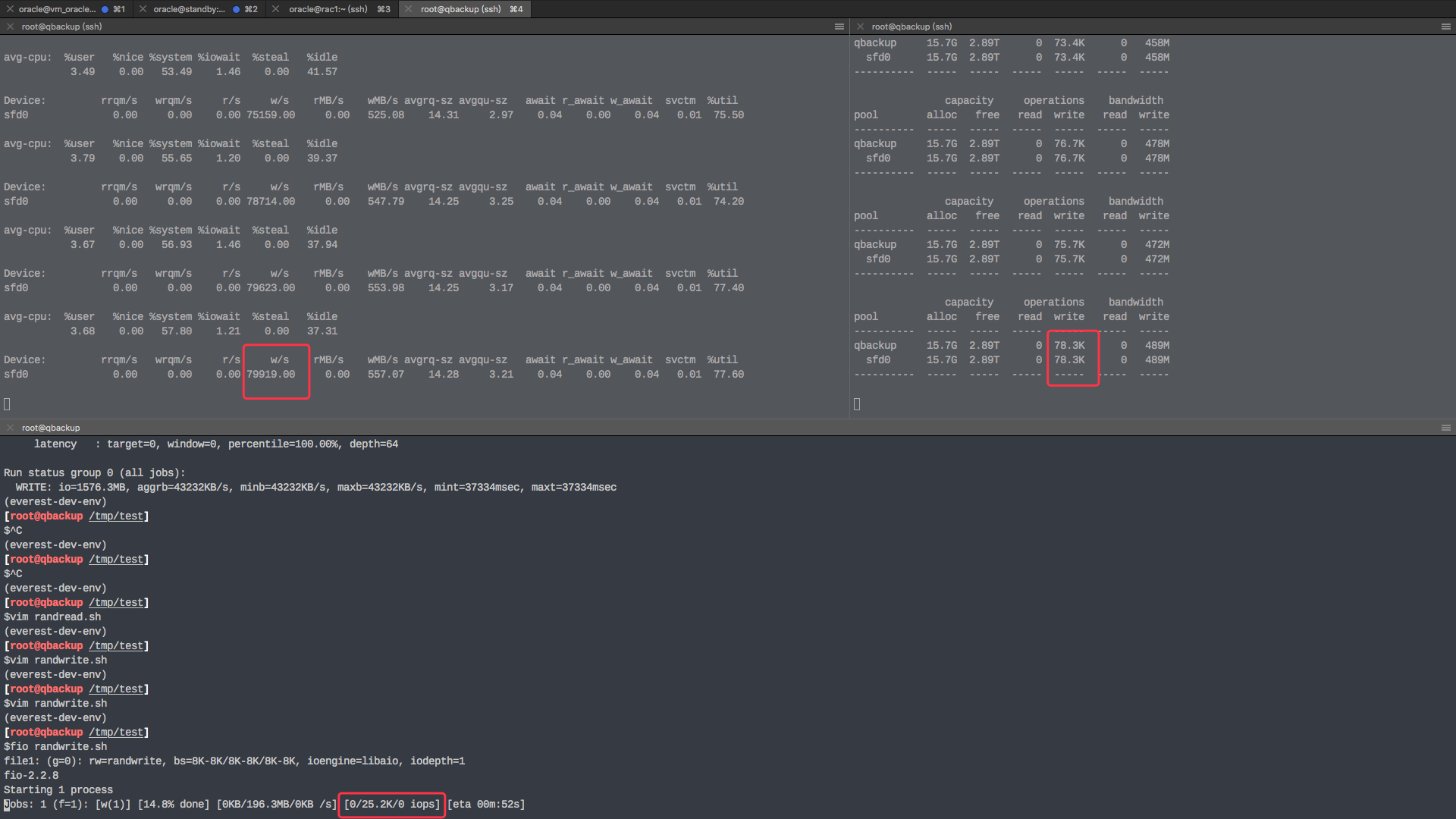
Write amplification 2~3x when fio test
These screenshots show details:

$zfs get copies qbackup
NAME PROPERTY VALUE SOURCE
qbackup copies 1 default
Describe how to reproduce the problem
Zfs config
$cat /sys/module/zfs/parameters/zfs_vdev_aggregation_limit
8192
$cat /sys/module/zfs/parameters/zfs_dirty_data_max
214748364
zpool create test sdd # 60G Intel ssd
zfs create -V 10G test/test1
OR
zpool create qbackup sfd0 # 3.2TB Flashcard
zfs create -V 100G qbackup/test1
Fio config
[global]
numjobs=1
rw=randwrite
bs=8k
runtime=60
ioengine=libaio
direct=1
iodepth=1
name=jicki
group_reporting
[file1]
filename=/dev/qbackup/test1
Include any warning/errors/backtraces from the system logs
 woquflux
woquflux
All 10 comments
I believe this is working as designed. For a brand new dataset, there is no pre-existing metadata. By default, there will be 2 copies of metadata and 1 copy of the data. So this benchmark is creating and writing new metadata (2x) + 1 data for every random block written.
Over time, the metadata will catch up and data that shares metadata blocks should result in fewer overall writes.
 richardelling
on 28 Aug 2017
richardelling
on 28 Aug 2017
Thanks for your reply~
So this phenomenon should be disappeared If I did precondition like dd the entire disk?
woquflux
on 28 Aug 2017
I believe @richardelling is correct. It's important thing to keep in mind that you _should not_ expect a 1-to-1 relationship between write(2) system calls and I/Os to the pool. There are a variety of factors which can can result in an inflation of IOs (multiple copies of meta data, spill blocks, etc) and others which will reduce the number of IOs (aggregation of writes by the ARC or vdev disk layer, compression, deduplication, nop-wriites, etc). Preconditioning your device with dd won't have any impact on what ZFS needs to write or how it writes it.
 behlendorf
on 29 Aug 2017
behlendorf
on 29 Aug 2017
Thanks,I will try again~
woquflux
on 7 Sep 2017
I understand that numbers of IO increase. But I found another thing strange.
Throughput amplificat 2~3x too ...
zfs config:
zpool create test /dev/sdg -f # Intel 3500 SSD 240G (Intel SSDSC2BB240G4)
zfs create -V 200G test/test1 -o volblocksize=4k
echo '8912' > zfs_vdev_aggregation_limit # This option because I had to simulati production environment, huge disk total size ,few io aggregation.
fio config A:
[global]
bs=8k
ioengine=libaio
#rw=randread
rw=randwrite
time_based
runtime=3600
direct=1
group_reporting
iodepth=1
[job1]
size=200G
filename=/dev/test/test1
fio config B and recreate zvol:
[global]
bs=128k
ioengine=libaio
#rw=randread
rw=randwrite
time_based
runtime=3600
direct=1
group_reporting
iodepth=1
[job1]
size=200G
filename=/dev/test/test1

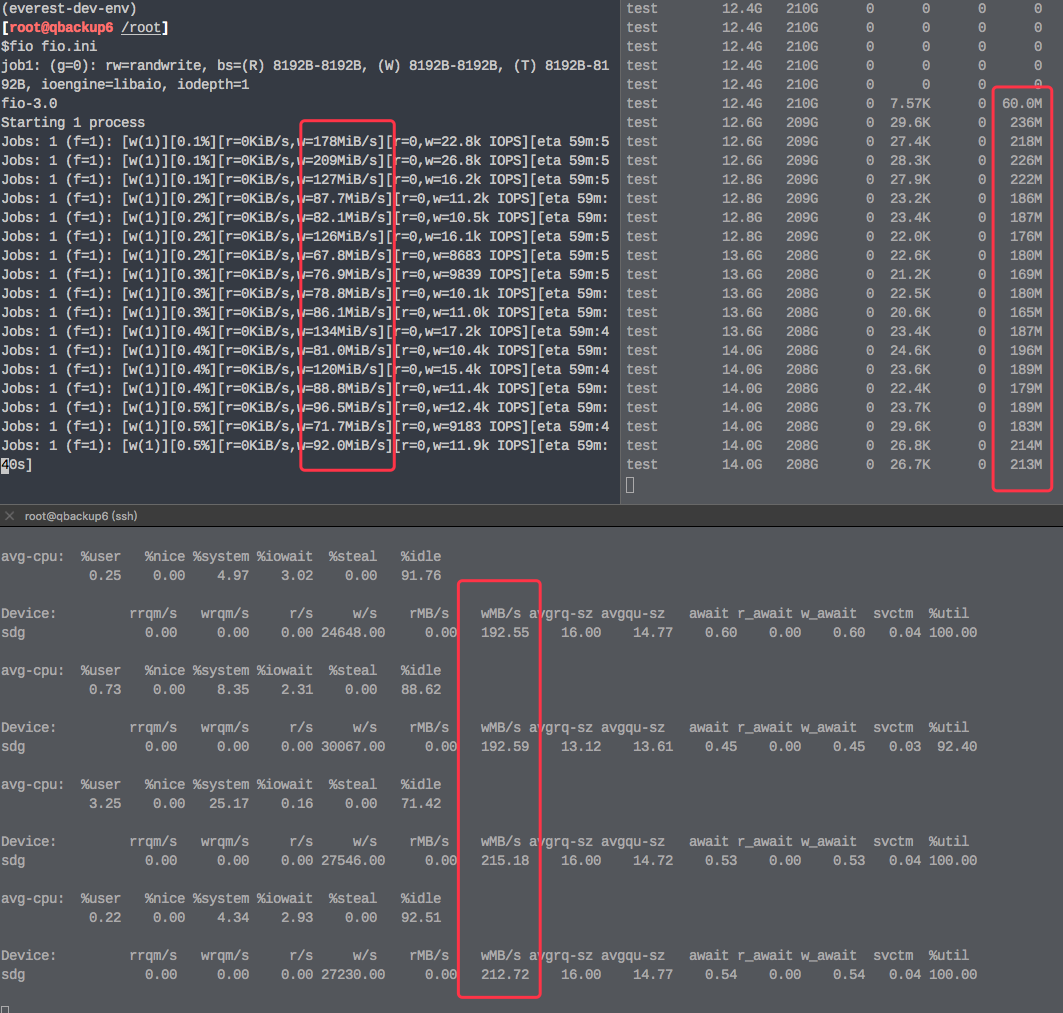
Every things seems ok when bs to 128k of fio.
woquflux
on 28 Sep 2017
@woquflux thanks for the clear reproducer. That does seem odd, I'll do some investigating.
behlendorf
on 28 Sep 2017
Maybe smaller block needs more metadata to flush?
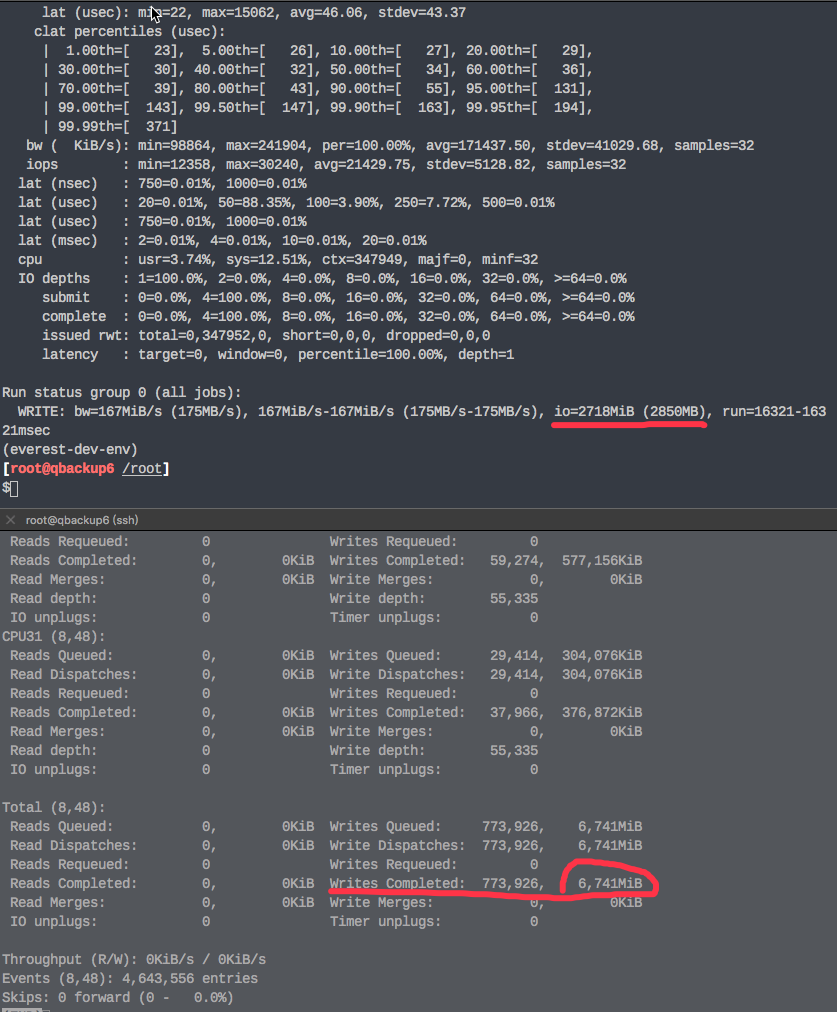
I had tested again with blktrace , found it write 3x data finally.
woquflux
on 30 Sep 2017
@behlendorf What is the new progress,please?
woquflux
on 9 Oct 2017
@woquflux nothing new to report. I haven't been able to investigate yet.
behlendorf
on 10 Oct 2017
This issue has been automatically marked as "stale" because it has not had any activity for a while. It will be closed in 90 days if no further activity occurs. Thank you for your contributions.
![stale[bot] picture](https://avatars3.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 25 Aug 2020
stale[bot]
on 25 Aug 2020
Related issues
 Hubbitus
·
4Comments
Hubbitus
·
4Comments
 FransUrbo
·
4Comments
FransUrbo
·
4Comments
 Greek64
·
3Comments
Greek64
·
3Comments
 pcd1193182
·
4Comments
pcd1193182
·
4Comments
 tronder88
·
3Comments
tronder88
·
3Comments
Most helpful comment
@behlendorf What is the new progress,please?