Zettlr: [BUG] Opening file performance worsened on 1.7 (versus 1.6)
Description
On v1.7, it takes considerable longer _for me_ to open a file in Zettlr. On v1.6 it would take around 1 second, but seldom more than 2. On v1.7 it takes 2-3 seconds, with occasionally 4 seconds or more.
As a result the application feels a lot more sluggish and is slower to work with.
Reproducing
- Launch Zettlr
- After the program shows up, wait an additional 5 seconds to give everything time to settle.
- Click on a file to open it. That file now opens slowly.
I also made a recording with the Zettlr log alongside. That way the timestamps can be used to time how long the different operations actually take. That recording is here.
Expected behaviour
I would expect files to open in 1 second or at most 2 seconds occasionally, but not take several seconds regularly. This makes Zettlr considerably slower than other Electron-based apps (like Visual Studio Code, which opens files < 1 second on my computer).
Platform
- OS and version: Windows 7 64-bit
- Zettlr Version: 1.7.0
- Screen Resolution: 1920x1080.
- I have whitelisted both Zettlr as well as my Zettelkasten directory in my virusscanner (Microsoft Security Essentials).
Additional information
It surprises me that during those slows open, the process explorer I use shows that Zettlr writes >500kb to disk. The average file in my Zettelkasten is just 1-2kb big. It seems odd to me that Zettlr has to handle 250x as many data as the text file is big.
 Jos512
Jos512
All 5 comments
Since Zettlr makes the Developer Tools available, we can look at the performance of the app while it runs. So I took a deep dive to look at the inside of Zettlr.
I have a disclaimer up front:
- I did not select an example to analyse, so performance can be better or worse than what I'll show. The timings in this example are however comparable with what I experience in Zettlr.
- I'm not a JavaScript developer nor an expert in Developer Tools. If there's a mistake that I made in my analysis, it's because of the beginner mind and not to push some agenda or to make this issue seem more important.
I made a four step analysis with the Performance tab of the Developer Tools. The recording is of me switching from one file to another. Here's what the first screen shows:
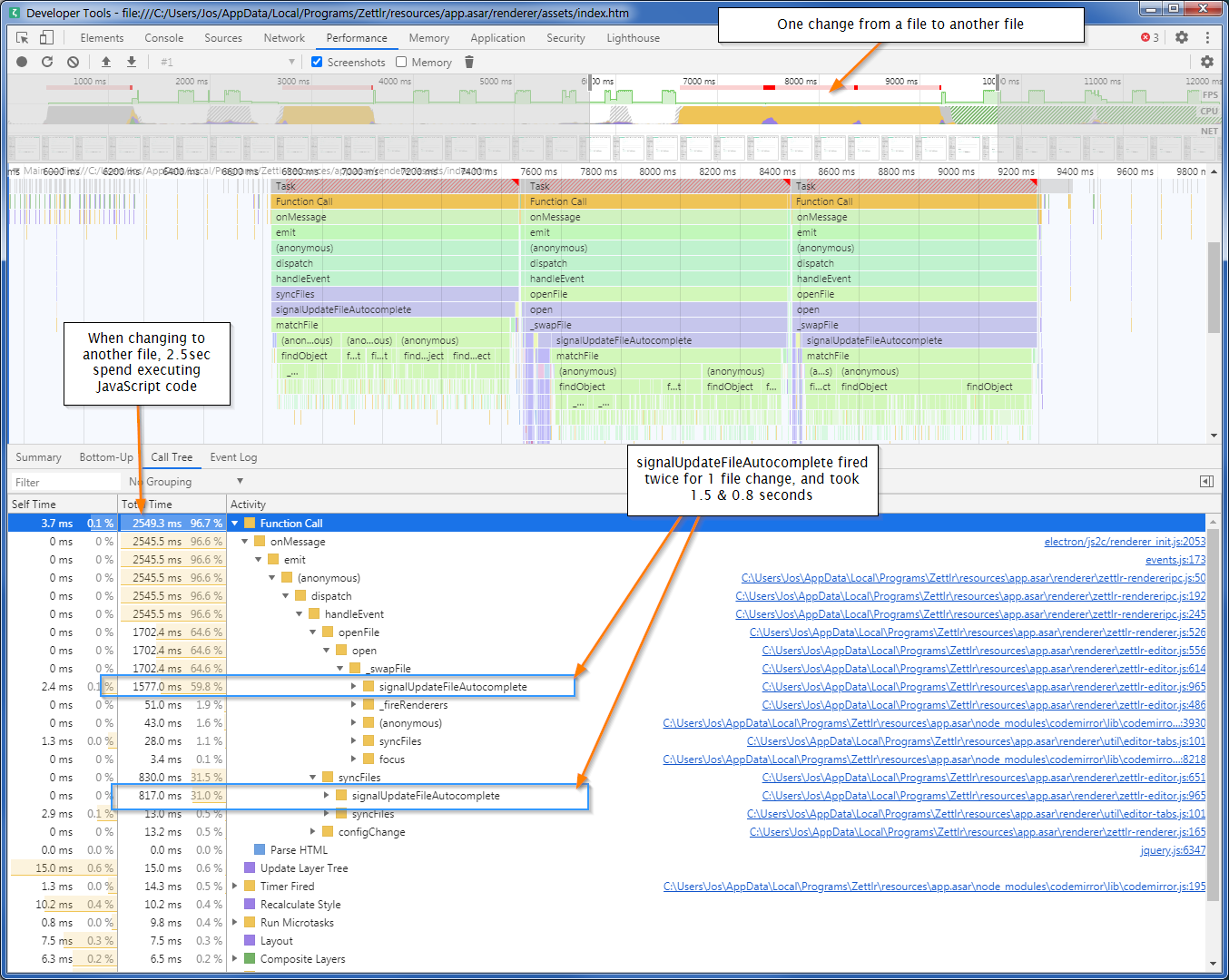
For this file change, Zettlr spend 2.5 seconds executing JavaScript code.
If we look at the total time that Zettlr spend in particular methods, one stand out: the two calls that Zettlr made to signalUpdateFileAutocomplete(). That took 1577ms the first call, and then another 817ms the second call.
So let's see what the performance for signalUpdateFileAutocomplete() is:
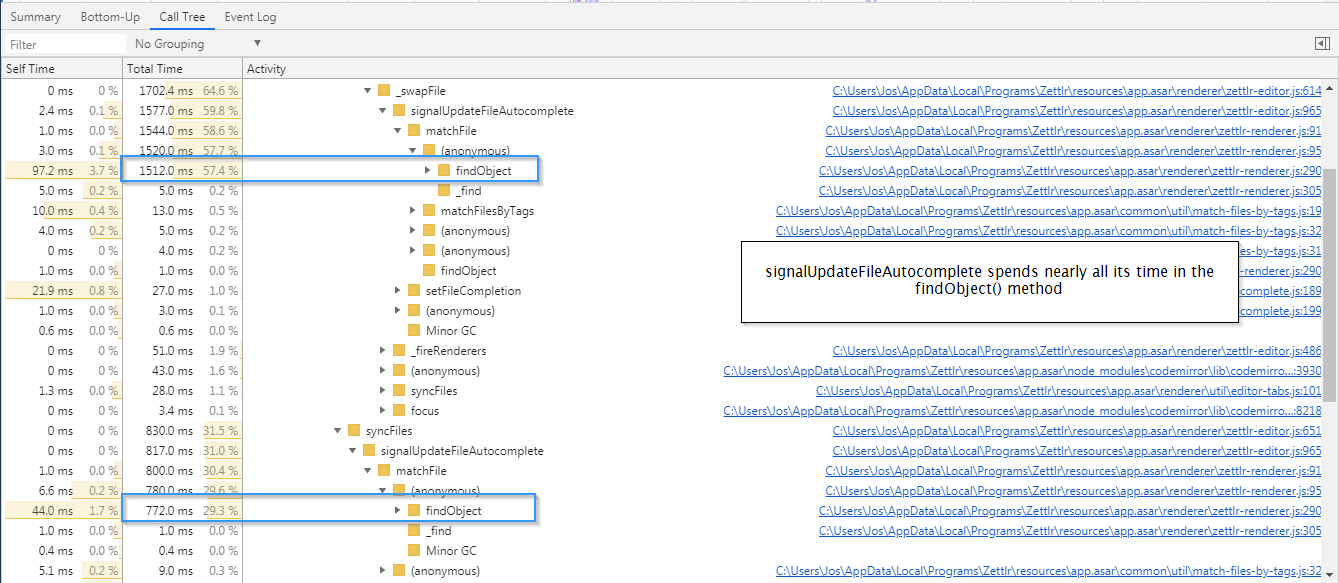
Nearly all the time that Zettlr executes that method, it in fact is busy with the findObject() method. That's odd, why would it take so long to find a file?
Let's take a closer look:
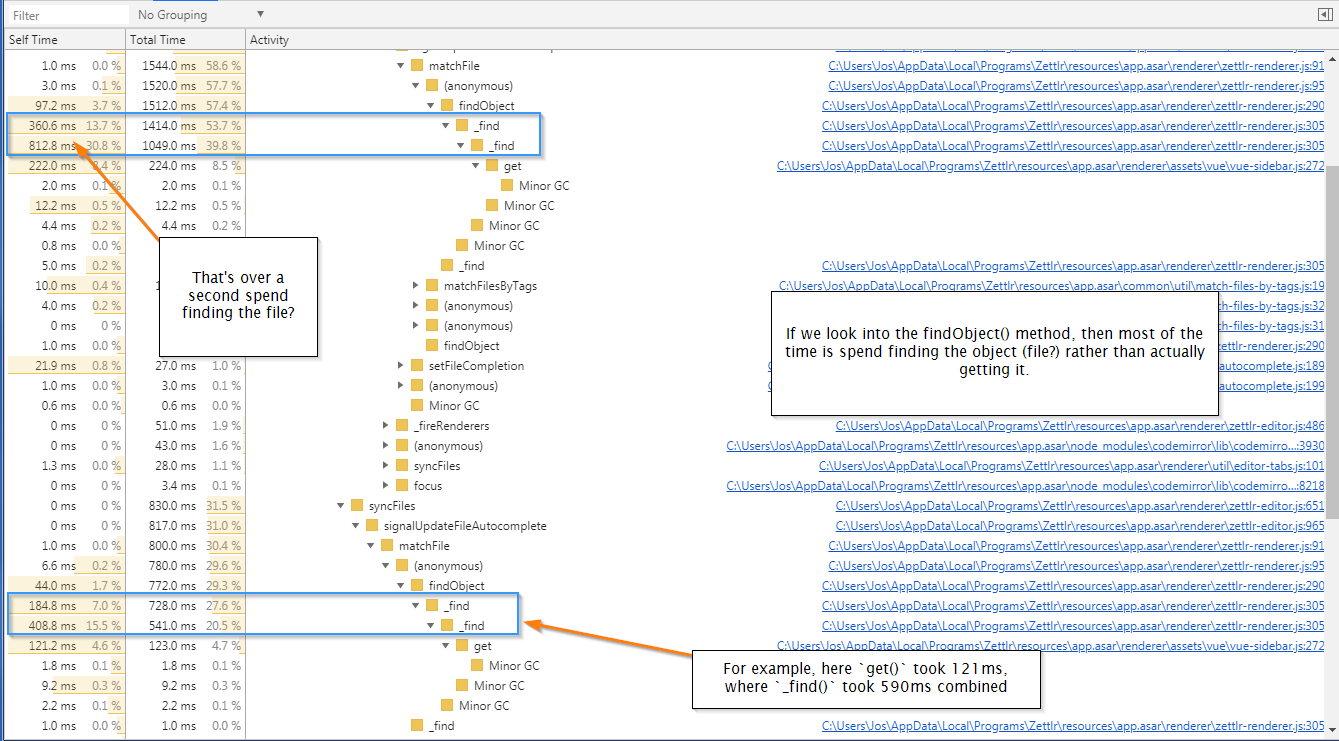
Most of the time that findObject() takes is actually spend by the _find() method that findObject() calls. And if I understand this performance graph correctly, it seems that findObject() calls _find() three times. The first two are very time-consuming; the last is a couple milliseconds.
So what does _find() do? In the renderer.js file we find:

If my performance analysis is correct (and that's a significant _if_), this small little method is what costed me almost 1.8 seconds when switching to another file. :thinking:
This is where _find() is located in the Zettlr source code:
The method's code is:
~~~js
/**
- Helper function to find dummy file/dir objects based on a hash
- @param {Integer} hash The hash identifying whatever is to be searched for.
- @param {Object} [obj=this._paths] A sub-object or the whole tree to be searched.
- @return {Mixed} Either null, or ZettlrFile/ZettlrDir if found.
*/
_find (hash, obj = this._paths) {
if (parseInt(obj.hash) === parseInt(hash)) {
return obj
} else if (obj.hasOwnProperty('children')) {
for (let c of obj.children) {
let ret = this._find(hash, c)
if (ret != null) return ret
}
}
return null
}
~~~
Like I said, I don't know much about JavaScript. But I suspect that parsing is time consuming.
This code also brings up a couple questions for me, if you don't mind me interrogating in the quest for performance. :slightly_smiling_face:
(1) The comment at the top of the file says that the hash parameter is an integer. If so, why does the method call parseInt() on that parameter?
(2) Can the method's performance be improved by first seeing if the 'children' property is there, and then performing the parsing? For example:
~js
if (obj.hasOwnProperty('children')) {
for (let c of obj.children) {
let ret = this._find(hash, c)
if (ret != null) return ret
}
} else if (parseInt(obj.hash) === parseInt(hash)) {
return obj
}
~
(3) Does Zettlr need the method at all? Zettlr can also at start up read the locations of all files and store that in a string dictionary. Looking up the value from a dictionary is a O(1) operation, no matter how big the dictionary becomes. Plus that storing the file names (like "2020-07-03 124522.md") are small strings that take little memory space.
(4) As a more general question, can signalUpdateFileAutocomplete() perhaps be cached so that Zettlr doesn't need to call it twice? I assume that switching from one file to another doesn't involve changing the location of the file, so searching for it more than once seems wasteful. If we could do without the second call, that would save 800ms in the example above.
(5) As a more general, higher-level question: why does Zettlr need to look up the file location _after_ I click on a file? Zettlr can also store this information in a file, which it reads on start up in memory. That way the information is available in advance, and only processed once.
If I would open/close the same file 5 times during the same Zettlr session, Zettlr looks up the location of the file 5-10 times (given the signalUpdateFileAutocomplete() calls). That's a bit odd because in all that time, the file's location never changes. It's static information. In fact, even when actively working with a Zettelkasten, probably 98% of the files keep their filename and location.
Subscribing to an event that fires based on file renames or deletions might give more performance. Furthermore, if Zettlr cannot find the file whose file path it stored, it can always call _find() to go and search the file. That would be the fallback behaviour for when files are moved without Zettlr knowing, but something that would give big performance benefits for the other 98% of files.
Jos512
on 3 Jul 2020
Just took a look at the screencast and your screenshots. Here's what I noticed:
- There is a configuration updated fired every time you attempt to open a file, and I suspect this is not correct
- The twice-searching has to do with the syncFiles; we need to add a flag to fire the signal updater only if there were changes.
Then concerning your analysis:
(1) The comment at the top of the file says that the hash parameter is an integer. If so, why does the method call parseInt() on that parameter?
Because JavaScript is a bitch, and it can happen that hash accidentally gets cast to a string, in which case the triple-operator (===) would return false; it's a failsafe that's necessary as long as we stay on vanilla JavaScript.
(2) Can the method's performance be improved by first seeing if the 'children' property is there, and then performing the parsing?
I doubt that would make such a difference. However, the findObject is actually a tree search, and there is exactly no optimization as of now. We could overload the method to accept the path of a file, which would cut down search immensely by only searching the root that actually contains the file.
(3) Does Zettlr need the method at all? Zettlr can also at start up read the locations of all files and store that in a string dictionary. Looking up the value from a dictionary is a O(1) operation, no matter how big the dictionary becomes. Plus that storing the file names (like "2020-07-03 124522.md") are small strings that take little memory space.
This would trash a lot of the functionality that currently is based upon the tree-like structure of the files, which I would like to retain. However, you just gave me an idea:
We could, everytime a new file tree is being read, create a dictionary for a quick hashmap-based dictionary, in the form of
let treeDirectory = Object.create(null);
treeDirectory[treeObject.hash] = treeObject
We only would need to change the methods for replacing files and directories in the renderer in order to make that happen. I could add such a lookup table for the FSAL as well.
(4) As a more general question, can signalUpdateFileAutocomplete() perhaps be cached so that Zettlr doesn't need to call it twice?
Yes, this is simply un-optimized code. The file autocomplete needs to be updated everytime either the active file changes or something in the file tree changes.
(5) As a more general, higher-level question: why does Zettlr need to look up the file location after I click on a file?
It does not look up the file location after you click on a file. It looks up the file descriptor in the internal tree to get the necessary information. See my answer to question two.
Zettlr can also store this information in a file, which it reads on start up in memory. That way the information is available in advance, and only processed once.
You got it wrong how Zettlr works: Zettlr does cache information (in the FSAL cache) and reads only the descriptor contents each start of the app. I do not see anything of what you outlined that we do not do.
That was an actually long post, but I hope to have answered your questions.
 nathanlesage
on 9 Jul 2020
nathanlesage
on 9 Jul 2020
A different bug:
It surprises me that during those slows open, the process explorer I use shows that Zettlr writes >500kb to disk.
I think this might be the cache flushing data to disk … no nevermind, just looked it up, the cache data is only persisted on shutdown. So I actually don't know what is being persisted …
The only time Zettlr itself writes data to disk is on shutdown, normally. Could it be that it's the underlying electron process flushing data to its own cache? If so, that would be something out of my influence (but should brought to the attention of electron's devs)
nathanlesage
on 9 Jul 2020
Short update question: Does this still happen within the current betas that have so far been released? If not, we might finally close this issue.
nathanlesage
on 3 Nov 2020
Short update question: Does this still happen within the current betas that have so far been released? If not, we might finally close this issue.
For Zettlr develop branch, as of the time of writing this, files open almost instantaneously on Ubuntu 20.04
 RedDocMD
on 20 Nov 2020
RedDocMD
on 20 Nov 2020
Related issues
 danieltomasz
·
5Comments
danieltomasz
·
5Comments
 manisabri
·
4Comments
manisabri
·
4Comments
 asielen
·
5Comments
danieltomasz
·
5Comments
asielen
·
5Comments
danieltomasz
·
5Comments
 Kangie
·
4Comments
Kangie
·
4Comments