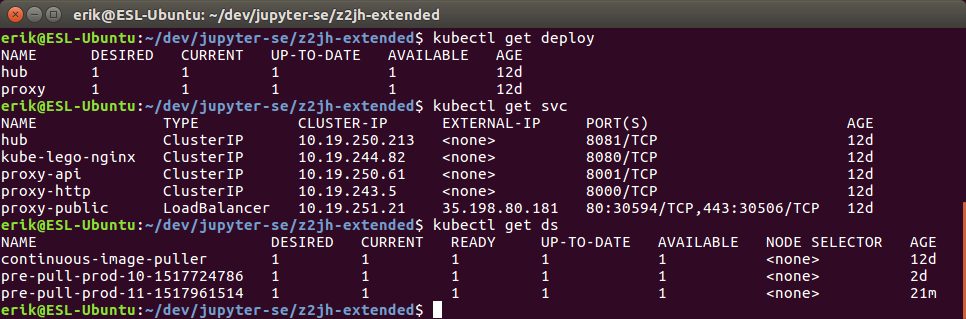
Zero-to-jupyterhub-k8s: Multiple pre-puller daemonsets
Running helm upgrades that creates new helm revisions will leave you with multiple prepuller daemonsets and prepuller pods. I manually removed all but the latest daemonset.
( Helm and Tiller is updated to 2.8, and I used v0.6 code. I've also enabled the pre-puller hook and continuous mode. )
 consideRatio
consideRatio
All 19 comments
Yes. do you see pre-puller daemons sticking on after every helm upgrade?
On Sat, Feb 3, 2018 at 10:37 PM, Erik Sundell notifications@github.com
wrote:
I made some releases with Helm, and noticed multiple prepuller daemonsets.
I manually removed all but the latest released daemonset. This is unwanted
behaviour right?( Helm and Tiller is updated to 2.8, and I used v0.6 code. )
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
https://github.com/jupyterhub/zero-to-jupyterhub-k8s/issues/476, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AAB23sCuGYTrKLAO5cq7qZjw5yBgyJiaks5tRVA7gaJpZM4R4dyB
.
--
Yuvi Panda T
http://yuvi.in/blog
 yuvipanda
on 5 Feb 2018
yuvipanda
on 5 Feb 2018
I found one for every revision i made. Is it possible to do a helm upgrade
without getting additional revisions?
Im in my bed about to sleep, I can investigate further details tomorrow!
/ erik
On Mon, Feb 5, 2018, 04:10 Yuvi Panda notifications@github.com wrote:
Yes. do you see pre-puller daemons sticking on after every helm upgrade?
On Sat, Feb 3, 2018 at 10:37 PM, Erik Sundell notifications@github.com
wrote:I made some releases with Helm, and noticed multiple prepuller
daemonsets.
I manually removed all but the latest released daemonset. This is
unwanted
behaviour right?( Helm and Tiller is updated to 2.8, and I used v0.6 code. )
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
https://github.com/jupyterhub/zero-to-jupyterhub-k8s/issues/476, or
mute
the thread
<
https://github.com/notifications/unsubscribe-auth/AAB23sCuGYTrKLAO5cq7qZjw5yBgyJiaks5tRVA7gaJpZM4R4dyB.
--
Yuvi Panda T
http://yuvi.in/blog—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
https://github.com/jupyterhub/zero-to-jupyterhub-k8s/issues/476#issuecomment-362970331,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ADqMurpKRUOj5VGe00nIyDE37s08bOMpks5tRnEfgaJpZM4R4dyB
.
consideRatio
on 5 Feb 2018
I have thought a lot about this issue and learned a lot. I'll need to get back to this, for now I'll simply post my thoughts.
Dear Rubber duck, I write you in hope of clarity...

Observation
Oh... The DS needs to be named the same for Helm to replace the old DS instead of create a new one next to the old DS.
Question --- answered
Is there a reason to have dynamic names that will remain and get siblings when a helm upgrade is run?
Well... They are supposed to be removed by the helm hook on completion, so only if it fails this is an issue i guess... Hmm... Without dynamic names, they might collide and fail if it failed before and some kubernetes objects remained...
Observation
Oh... Dynamics names on kubernetes objects are delcared for...
- the rbac objects: cluster-role, role, clusterrolebinding, rolebinding, serviceaccount in rbac.yaml
- a job and deamonset in job.yaml
Observation
Oh... the successful upgrades will delete these dynamically named objects...
Question - answered
__Having both the helm-hook-puller and continuous-puller active__
Is this meant to be supported? I figured I wanted to make sure things are pulled before my hub is updated with a new image if i made an upgrade, but at the same time use the continuous to allow for new nodes to be added and get them updated with images.
Question - answered
Do we really need to have a hook-image-puller DS alongside the continuous-image-puller DS?
Perhaps we can update the code in main.go to not always create a new DS, but only do so if there is no continuous puller.
Well... No...
- With prePuller hook enabled, a job is created as a pre-install/upgrade helm-hook, it will run code within the pre-puller image that blocks until all images are in place.
- Some RBAC roles are required by this job. It might create a deamonset that helps pull images to the nodes. It will certainly see if all nodes have got their images and therefore require some permissions setup with the RBAC roles.
- Hmmm, will a continuous image puller daemonset be created alongside this helm hook job? No... This is a pre-install/upgrade hook, the hub image is not upgraded for example... Shit....
Question - answered
- The RBAC objects created for the hook-puller is supposed to be deleted after a successful hook right? If the hook-image-puller requires them, doesn't the continuous-image-puller also require them? They are not setup for the continuous image puller though... I think have answered my own question now, the permissions given are only meant to be used to create/delete a daemonset.
Question - answered
What is that /block command in the pre puller image? Oh it was the name of the output of the compiled .go code files...
Action point
A comment could be useful in the Dockerfile that a compilation is run and it will output a executable (/block).
Question
Is there a way to force helm to initialize a daemonset first, and then the other objects, and if that initialization fails, roll back the upgrade? If so, that would allow us to have one single puller image, and not need all RBAC stuff...
Me...


Why not run the image puller daemon set as a pre-install hook as well?
 |
consideRatio
on 7 Feb 2018
|
consideRatio
on 7 Feb 2018
Is there a reason to have dynamic names that will remain and get siblings when a helm upgrade is run?
Well... They are supposed to be removed by the helm hook on completion, so only if it fails this is an issue i guess... Hmm... Without dynamic names, they might collide and fail if it failed before and some kubernetes objects remained...
That's exactly the problem: https://github.com/jupyterhub/zero-to-jupyterhub-k8s/issues/425
Unfortunately it leaves a lot of resources behind on failure, in my case I get this when pulling a large image that causes helm to timeout.
Perhaps another alternative is to avoid using hooks, have the pre-puller as a normal pod, and add an initContainer to Jupyterhub which checks for a successful pull status before starting?
 manics
on 7 Feb 2018
manics
on 7 Feb 2018
So the underlying bug here seems to be that this particular line: https://github.com/jupyterhub/zero-to-jupyterhub-k8s/blob/master/images/pre-puller/main.go#L117 is not actually working as intended all the time, and so the deletion is not successful some of the time. Need to investigate why.
yuvipanda
on 7 Feb 2018
@consideRatio thank you for your well put together rubber duck! I enjoyed it :)
- The hook and the continuous pre-puller can co-exist. The hook creates a daemonset that has the same specs (but different name!) as the continouos pre-puller to pull images, then it deletes the daemonset (when it is not buggy!) and moves on.
- Helm hooks only have a definition of 'done' for certain objects - Jobs, Pods, but not for DaemonSets. If they did indeed we can completely remove the block go setup!
- The problem with making this an initContainer on JupyterHub (or delaying JupyterHUb startup based on image use) is that JupyterHub will be unavailable for that entire period of time, while currently it is fine...
yuvipanda
on 7 Feb 2018
Thank you for reading @manics and @yuvipanda :D
__The cleanup issue__
The main concern for me is stability, I'm interesting in reducing the problems by simplifying the hook-image-puller / continuous-image-puller logic.
__The hook-puller-job__
- needs rbac permissions to read info from k8s and create/delete a daemonset. Let us name these statically.
__Ideas__
- Use static/fixed names instead of dynamic/variable names for all objects in rbac.yaml as well as the daemonsets
- Keep using a dynamic/variable name for the pre-install-hook job, they will end one way or another.
- The continuous-image-puller (aka persistent-image-puller) should be installed as a pre-install hook to allow it to be utilized with new image definitions by the pre-install-hook job. I presume you can use weights do define an pre-install hook ordering, this should update first of all.
- The hook-image-puller (aka temporary-image-puller) should only be created+deleted if a persistent-image-puller isn't available.
__Expected outcome__
- Lowered complexity -> Less potential cleanups required
consideRatio
on 7 Feb 2018
@yuvipanda thank you for explaining things to me, I have learned so much working with this project!
consideRatio
on 7 Feb 2018
Can you explain what you mean by static / dynamic name in hooks? IIRC the objects being leftover aren't those, but just the daemonset that is created in https://github.com/jupyterhub/zero-to-jupyterhub-k8s/blob/master/images/pre-puller/main.go#L99
yuvipanda
on 7 Feb 2018
The continuous-image-puller (aka persistent-image-puller) should be installed as a pre-install hook to allow it to be utilized with new image definitions by the pre-install-hook job. I presume you can use weights do define an pre-install hook ordering, this should update first of all.
Daemonsets don't really work as helm hooks unfortunately, if they did you can do this and get rid of our pre-puller.
The hook-image-puller (aka temporary-image-puller) should only be created+deleted if a persistent-image-puller isn't available.
This also doesn't work, since the primary goal of the hook pre-puller is to allow JupyterHub to not be restarted / use new image until it is present on all nodes. If we don't have it, then there's still a period of time when new user pulls are going to take a long time, thus affecting overall perceived performance.
I think my next step is to use the official Kubernetes client library (http://github.com/kubernetes/client-go) for it, to remove some of our own code.
yuvipanda
on 7 Feb 2018
@yuvipanda about the static/dynamic names, I didn't know what to call the difference between the naming below so i just called them like that and hoped for the best :D
- Static example: "pre-puller"
- Dynamic example: "pre-puller-{{ .Release.Revision }}"
@yuvipanda about helm hooks
Oh crap I imagined one could use them to get an ordering in the install/upgrade process. If one could get the puller-daemonset updated (or created temporary), followed by a job being completed, followed by a hub update, that would be great I have imagined.
I will read up about helm hooks and ordered installations of kubernetes objects tonight. I got hopeful when i saw the helm hook annotation about "weight", I did not consider a difference between jobs and daemonsets.
consideRatio
on 7 Feb 2018
Relevant documentation about Helm Hooks:
- https://docs.helm.sh/developing_charts/#hooks-and-the-release-lifecycle
What does it mean to wait until a hook is ready? This depends on the resource declared in the hook. __If the resources is a Job kind, Tiller will wait until the job successfully runs to completion. And if the job fails, the release will fail. This is a blocking operation, so the Helm client will pause while the Job is run.__
__For all other kinds, as soon as Kubernetes marks the resource as loaded (added or updated), the resource is considered “Ready”.__ When many resources are declared in a hook, the resources are executed serially. If they have hook weights (see below), they are executed in weighted order. Otherwise, ordering is not guaranteed. (In Helm 2.3.0 and after, they are sorted alphabetically. That behavior, though, is not considered binding and could change in the future.) It is considered good practice to add a hook weight, and set it to 0 if weight is not important.
I'm taking one step at the time now. One part I'm getting a bit confident about, is that we can utilize one single daemonset object for both the persistent continuous-image-puller and the temporary hook-image-puller generated by the blocking job, and that we can avoid creating/deleting it from the blocking job itself.
This is how
- Define a daemonset with a fixed name like "pre-puller" in a template within a conditional that sais that puller-hook is enabled OR continuous-puller is enabled. Make this DS have a pre-install helm hook with a very low weight (forces it to be added/updated before any other pre-install/upgrade Jobs that will be blocking later.)
- Make the DS remove itself if not the continuous-image-puller is set to be true by adding an helm-specific annotation to it.
- Slim the blocking Go-code in the blocking pre-install Job to not include creation/deletion of a daemonset. Also slim the RBAC permissions.
I'll experiment with this as I'm eager to learn about this no matter what!
Hmmm... but rubber duck, why do I do this for the sake of the project?
- Perhaps there will be less potential object to cleanup if something goes wrong.
- ... less permissions available to end up in the wrong hands.
- ... code might be easier to overview
- ?
Also... what more do I hope to improve?
- Eeehh... One thing at the time...
consideRatio
on 7 Feb 2018
I don't have anything meaningful to add to this discussion but I just wanted to say that your description of the problem was amazing @consideRatio
 choldgraf
on 7 Feb 2018
choldgraf
on 7 Feb 2018
I've come across some issues, I'm investigating and trying to solve them, but some sleep is needed...
Helm version issue
The Helm annotation allowing deletion of jobs through annotations like "helm.sh/hook-delete-policy": hook-succeeded that was introduced in Helm v2.7.0. Without it non-fixed names for the roles is troublesome as I end up getting "it already exist" issues...
Timeout issue
If the pre-puller blocking job takes too long, the helm upgrade fails like below. I think a connection is timed out and closed for some reason - https://github.com/kubernetes/helm/issues/3015
Update Complete. ⎈Happy Helming!⎈
Saving 1 charts
Deleting outdated charts
Error: UPGRADE FAILED: transport is closing
Verifying images pulled issue (Issue #477 I think)
__Understanding 1 - Got it wrong__
Each image had multiple names available, and I got confused ...
The
node.gofile within the blocking pre-puller job relies on finding a match between a string like<image>:<tag>but sometimes is comparing against<image>@sha256:<hash>. Perhaps when you have pushed a new tag without changing the image.I found out that one can get the
<image>@sha256:<hash>version from<image>:<tag>via# only works if you have the image available afaik... docker inspect --format='{{ index .RepoDigests 0 }}' <image>:<tag>
__Understanding 2__
The API request by node.go only return 50 images. I was waiting to find two images, but found only one, the other was somewhere behind those first 50 images. It seems like it returns the newest images first though. But... if you wait for the k8s-network-tools image one can get in trouble since it might not be found in those first 50 after several releases.
I read about a limit query parameter, but the API doesn't seem to respect it. So the option remaining is to chain request until the continue field in the metadata isn't set anymore.
In page search for GET /api/v1/nodes and you will find info about query params such as limit and continue. https://kubernetes.io/docs/api-reference/v1.9/#node-v1-core
Information about the metadata containing a continue field
Oh... Nevermind... The limit probably works, but the main request to /api/v1/nodes never was limited, but the nest images was limited......... Sad kitten is sad....
Me...

consideRatio
on 8 Feb 2018
I figure the way forward might be to...
- Start using a library for accessing the k8s API and pay a price of an image size as well as maintenance for the blocking Job
- Go wild and believe that the library won't break your heart.
- Ensure that the blocking Job using the library is always able to schedule on the master node or at least have affinity for the master node, or simply any node that has that image pulled already somehow.
Time to sleep...

consideRatio
on 8 Feb 2018
My current goal
Understand and setup a stable functional continuous-image-puller.
--- STATUS: Working afaikSetup a stable and functional hook-image-puller that will block the helm upgrade until images are available for minimal downtime and a small consistent waiting time for users spinning up new servers.
--- STATUS: > 50 images on a node limitation bug, along with some cleanup issues.
Question - answered
Why does some k8s object update to a new version, and some others not but instead say that the object already exist? Well, because some objects that are helm hooks, and are not meant to do that I think. I imagine it could result in a recursive problem as the hooks are meant to come before an update operation, so what would happen if you'd make the hook involve an update operation itself? Hmm...
Related discussion
https://github.com/kubernetes/helm/issues/3128
About "helm.sh/hook-delete-policy" and the double value of "hook-succeeded,hook-failed".
https://github.com/kubernetes/helm/issues/2243
About having "Stages", instead of a single pre-install "stage" where the hook things are run. Similar to having multiple helm charts that would update in sequence I figure...
Preliminary conclusions
If one has a continuous puller, it should be upgraded, and hence shouldn't be an helm hook, and therefore can't predate the other objects that are to be upgraded. This means that we need the two daemonsets that @yuvipanda have suggested, one hook-puller and one continuous puller.
Question --- answer guessed
Can the hook-puller daemonset be deleted by a "helm.sh/hook-delete-policy" of "hook-succeeded,hook-failed"? It is currently only set to "hook-succeeded", but it is possible to have both succeed and failed, but I'm not very confident on the meaning of hook-failed, is the failure referring to a failure of the sequence of hooks executed in the order of the weights, or on an individual object basis, but then... how would a hooked role "fail"? So I think it is related to the sequence but I have not confirmed...
Preliminary conclusion
I suppose it would be good to annotate all the roles with "hook-succeeded,hook-failed" rather than hook-succeeded only, that would clean up some stuff better overall.
Speculation
The puller daemonset is setup with rolling update as an updateStrategy. This isn't required, or is it? I don't think so. A hook won't have an update, and the continuous puller can have downtime without any issues. On my todo list is verifying my understanding of updateStrategies and rollingUpdate, but i figure it relates to putting something in place before removing another one. It does not seem relevant to do for the image-puller.
Idea
Within the blocking hook job, one could perhaps wait for a ready status in another way than using the list nodes api and reading about the images, but instead see if all the hook-image-puller daemonset's spawned pods are running as compared to initing. If that is possible, my issue with having more than 50 images available and that the list nodes api only displays X nodes, and each node information contains only details about a maximum of 50 images... The following messages are from the logs of my debugging session... I realized that no matter how many images I added, I remained at a maximum of 50 available in the information from the k8s __nodes__ api request
2018/02/16 01:54:29 [48 AVAILABLE] gcr.io/kubernetes-helm/tiller@sha256:a3baf14e3ec497ecc44cf81642d4df2b57c16cd097789234b81e9b630931ef61
2018/02/16 01:54:29 [48 AVAILABLE] gcr.io/kubernetes-helm/tiller:v2.6.2
2018/02/16 01:54:29 [49 AVAILABLE] asia.gcr.io/google-containers/rescheduler@sha256:66a900b01c70d695e112d8fa7779255640aab77ccc31f2bb661e6c674fe0d162
2018/02/16 01:54:29 [49 AVAILABLE] eu.gcr.io/google-containers/rescheduler@sha256:66a900b01c70d695e112d8fa7779255640aab77ccc31f2bb661e6c674fe0d162
2018/02/16 01:54:29 [49 AVAILABLE] gcr.io/google-containers/rescheduler@sha256:66a900b01c70d695e112d8fa7779255640aab77ccc31f2bb661e6c674fe0d162
2018/02/16 01:54:29 [49 AVAILABLE] asia.gcr.io/google-containers/rescheduler:v0.3.1
2018/02/16 01:54:29 [49 AVAILABLE] eu.gcr.io/google-containers/rescheduler:v0.3.1
2018/02/16 01:54:29 [50 AVAILABLE] asia.gcr.io/google_containers/heapster-amd64@sha256:8e04183590f937c274fb95c1397ea0c6b919645c765862e2cc9cb80f097a8fb4
2018/02/16 01:54:29 [50 AVAILABLE] eu.gcr.io/google_containers/heapster-amd64@sha256:8e04183590f937c274fb95c1397ea0c6b919645c765862e2cc9cb80f097a8fb4
2018/02/16 01:54:29 [50 AVAILABLE] gcr.io/google_containers/heapster-amd64@sha256:8e04183590f937c274fb95c1397ea0c6b919645c765862e2cc9cb80f097a8fb4
2018/02/16 01:54:29 [50 AVAILABLE] asia.gcr.io/google_containers/heapster-amd64:v1.4.3
2018/02/16 01:54:29 [50 AVAILABLE] eu.gcr.io/google_containers/heapster-amd64:v1.4.3
2018/02/16 01:54:29 [NEEDED] eu.gcr.io/jupyter-se/singleuser:imgpullfix-16
2018/02/16 01:54:29 [NEEDED] jupyterhub/k8s-network-tools:v0.6
2018/02/16 01:54:29 0 of 2 images pulled in node gke-jupyter-se-default-pool-2f51798a-xvx3
Hi @consideRatio. Are you ready to close this issue? If not, what would be the next action needed 👍
 willingc
on 27 Feb 2018
willingc
on 27 Feb 2018
@willingc I read it through again, I think we got it all in #502, closing!
consideRatio
on 27 Feb 2018
Thanks @consideRatio :cookie:
willingc
on 27 Feb 2018
Related issues
 betatim
·
4Comments
betatim
·
4Comments
 jgerardsimcock
·
4Comments
jgerardsimcock
·
4Comments
 bleggett
·
3Comments
consideRatio
·
3Comments
consideRatio
·
3Comments
bleggett
·
3Comments
consideRatio
·
3Comments
consideRatio
·
3Comments