Yugabyte-db: Issues with timeouts for Queries Run by Hasura against catalog tables
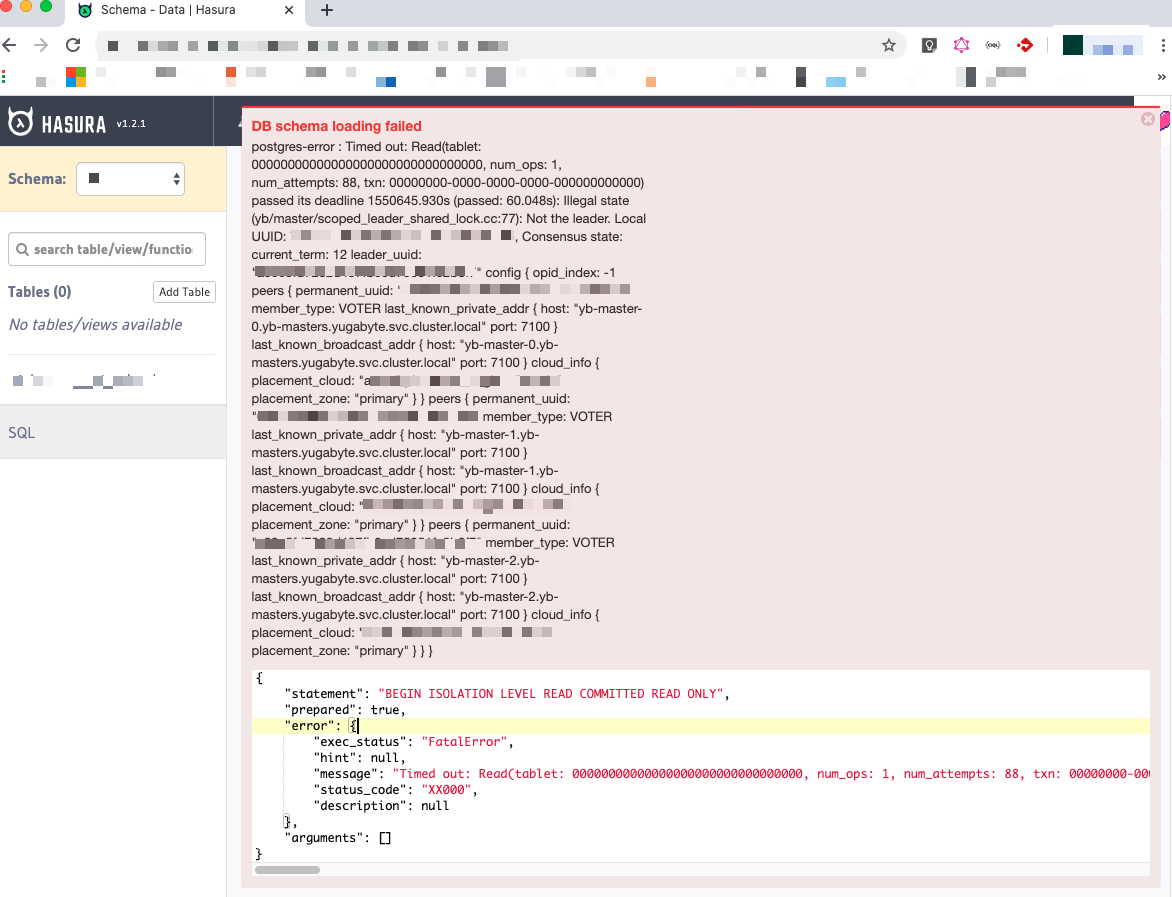
I’m using hasura with Yugabyte, it works ok with small schemas, however when there are a few tables, the queries that hasura sends to the database seem to run awefully slow. Example, regular postgres returns the following query that hasura issues in under a second, while yugabyte took over 3 minutes (when issued from dbeaver). Is this something that can be looked at, as it causing hasura to throw errors that it cannot read the schema, making hasura un-usable from an administration perspective
COALESCE(Json_agg(Row_to_json(info)), ‘[]’ :: json) AS tables
FROM (
SELECT
pgn.nspname as table_schema,
pgc.relname as table_name,
case
when pgc.relkind = ‘r’ then ‘TABLE’
when pgc.relkind = ‘v’ then ‘VIEW’
when pgc.relkind = ‘m’ then ‘MATERIALIZED VIEW’
end as table_type,
obj_description(pgc.oid) AS comment,
COALESCE(json_agg(DISTINCT row_to_json(isc) :: jsonb || jsonb_build_object(‘comment’, col_description(pga.attrelid, pga.attnum))) filter (WHERE isc.column_name IS NOT NULL), ‘[]’ :: json) AS columns,
COALESCE(json_agg(DISTINCT row_to_json(ist) :: jsonb || jsonb_build_object(‘comment’, obj_description(pgt.oid))) filter (WHERE ist.trigger_name IS NOT NULL), ‘[]’ :: json) AS triggers,
row_to_json(isv) AS view_info
FROM pg_class as pgc
INNER JOIN pg_namespace as pgn
ON pgc.relnamespace = pgn.oid
/* columns */
/* This is a simplified version of how information_schema.columns was
** implemented in postgres 9.5, but modified to support materialized
** views.
*/
LEFT OUTER JOIN pg_attribute AS pga
ON pga.attrelid = pgc.oid
LEFT OUTER JOIN (
SELECT
current_database() AS table_catalog,
nc.nspname AS table_schema,
c.relname AS table_name,
a.attname AS column_name,
a.attnum AS ordinal_position,
pg_get_expr(ad.adbin, ad.adrelid) AS column_default,
CASE WHEN a.attnotnull OR (t.typtype = ‘d’ AND t.typnotnull) THEN ‘NO’ ELSE ‘YES’ END AS is_nullable,
CASE WHEN t.typtype = ‘d’ THEN
CASE WHEN bt.typelem <> 0 AND bt.typlen = -1 THEN ‘ARRAY’
WHEN nbt.nspname = ‘pg_catalog’ THEN format_type(t.typbasetype, null)
ELSE ‘USER-DEFINED’ END
ELSE
CASE WHEN t.typelem <> 0 AND t.typlen = -1 THEN ‘ARRAY’
WHEN nt.nspname = ‘pg_catalog’ THEN format_type(a.atttypid, null)
ELSE ‘USER-DEFINED’ END
END AS data_type,
CASE WHEN nco.nspname IS NOT NULL THEN current_database() END AS collation_catalog,
nco.nspname AS collation_schema,
co.collname AS collation_name,
CASE WHEN t.typtype = ‘d’ THEN current_database() ELSE null END AS domain_catalog,
CASE WHEN t.typtype = ‘d’ THEN nt.nspname ELSE null END AS domain_schema,
CASE WHEN t.typtype = ‘d’ THEN t.typname ELSE null END AS domain_name,
current_database() AS udt_catalog,
coalesce(nbt.nspname, nt.nspname) AS udt_schema,
coalesce(bt.typname, t.typname) AS udt_name,
a.attnum AS dtd_identifier,
CASE WHEN c.relkind = ‘r’ OR
(c.relkind IN (‘v’, ‘f’) AND
pg_column_is_updatable(c.oid, a.attnum, false))
THEN ‘YES’ ELSE ‘NO’ END AS is_updatable
FROM (pg_attribute a LEFT JOIN pg_attrdef ad ON attrelid = adrelid AND attnum = adnum)
JOIN (pg_class c JOIN pg_namespace nc ON (c.relnamespace = nc.oid)) ON a.attrelid = c.oid
JOIN (pg_type t JOIN pg_namespace nt ON (t.typnamespace = nt.oid)) ON a.atttypid = t.oid
LEFT JOIN (pg_type bt JOIN pg_namespace nbt ON (bt.typnamespace = nbt.oid))
ON (t.typtype = ‘d’ AND t.typbasetype = bt.oid)
LEFT JOIN (pg_collation co JOIN pg_namespace nco ON (co.collnamespace = nco.oid))
ON a.attcollation = co.oid AND (nco.nspname, co.collname) <> (‘pg_catalog’, ‘default’)
WHERE (NOT pg_is_other_temp_schema(nc.oid))
AND a.attnum > 0 AND NOT a.attisdropped AND c.relkind in (‘r’, ‘v’, ‘m’)
AND (pg_has_role(c.relowner, ‘USAGE’)
OR has_column_privilege(c.oid, a.attnum,
‘SELECT, INSERT, UPDATE, REFERENCES’))
) AS isc
ON isc.table_schema = pgn.nspname
AND isc.table_name = pgc.relname
AND isc.column_name = pga.attname
/* triggers */
LEFT OUTER JOIN pg_trigger AS pgt
ON pgt.tgrelid = pgc.oid
LEFT OUTER JOIN information_schema.triggers AS ist
ON ist.event_object_schema = pgn.nspname
AND ist.event_object_table = pgc.relname
AND ist.trigger_name = pgt.tgname
/* This is a simplified version of how information_schema.views was
** implemented in postgres 9.5, but modified to support materialized
** views.
*/
LEFT OUTER JOIN (
SELECT
current_database() AS table_catalog,
nc.nspname AS table_schema,
c.relname AS table_name,
CASE WHEN pg_has_role(c.relowner, ‘USAGE’) THEN pg_get_viewdef(c.oid) ELSE null END AS view_definition,
CASE WHEN ‘check_option=cascaded’ = ANY (c.reloptions) THEN ‘CASCADED’
WHEN ‘check_option=local’ = ANY (c.reloptions) THEN ‘LOCAL’
ELSE ‘NONE’
END AS check_option,
CASE WHEN pg_relation_is_updatable(c.oid, false) & 20 = 20 THEN ‘YES’ ELSE ‘NO’ END AS is_updatable,
CASE WHEN pg_relation_is_updatable(c.oid, false) & 8 = 8 THEN ‘YES’ ELSE ‘NO’ END AS is_insertable_into,
CASE WHEN EXISTS (SELECT 1 FROM pg_trigger WHERE tgrelid = c.oid AND tgtype & 81 = 81) THEN ‘YES’ ELSE ‘NO’ END AS is_trigger_updatable,
CASE WHEN EXISTS (SELECT 1 FROM pg_trigger WHERE tgrelid = c.oid AND tgtype & 73 = 73) THEN ‘YES’ ELSE ‘NO’ END AS is_trigger_deletable,
CASE WHEN EXISTS (SELECT 1 FROM pg_trigger WHERE tgrelid = c.oid AND tgtype & 69 = 69) THEN ‘YES’ ELSE ‘NO’ END AS is_trigger_insertable_into
FROM pg_namespace nc, pg_class c
WHERE c.relnamespace = nc.oid
AND c.relkind in (‘v’, ‘m’)
AND (NOT pg_is_other_temp_schema(nc.oid))
AND (pg_has_role(c.relowner, ‘USAGE’)
OR has_table_privilege(c.oid, ‘SELECT, INSERT, UPDATE, DELETE, TRUNCATE, REFERENCES, TRIGGER’)
OR has_any_column_privilege(c.oid, ‘SELECT, INSERT, UPDATE, REFERENCES’))
) AS isv
ON isv.table_schema = pgn.nspname
AND isv.table_name = pgc.relname
WHERE
pgc.relkind IN (‘r’, ‘v’, ‘m’)
and (pgn.nspname=‘public’)
GROUP BY pgc.oid, pgn.nspname, pgc.relname, table_type, isv.*
) AS info;
 IS-Josh
IS-Josh
All 3 comments
Hi, just letting you know i've found an optimisation for this query which enables it to run against large schemas and in a reasonable time for smaller schemas. I've passed on the suggestion to Hasura https://github.com/hasura/graphql-engine/issues/4925
IS-Josh
on 29 May 2020
@IS-Josh --
wow... thx for finding an alternate suggestion for the query that's optimal and recommending that to Hasura team as well! Really appreciate it.
 kmuthukk
on 29 May 2020
kmuthukk
on 29 May 2020
While waiting for the fix to be applied to hasura, i've found a workaround (with kubernetes) If anyone is needing a fast fix
- copy the latest version of the console-assets directory in the hasura pod to local
/srv/console-assets.
run: kubectl cp {namespace}/{podname}:srv/console-assets {localpath}
gunzip {localpath}/versioned/main.js.gz
edit main.js (apply the changes as noted in hasura/graphql-engine#4925 - by searching and adding in the two lines of code) and save
gzip {localpath}/versioned/main.js
Upload the contents of console-assets on local machine to a shared location (azure file share)
- Edit deployment yaml for hasura to add a volume(as per adding a volume to a kubernetes deployment) and mount path -mounting the volume to /home
volumeMounts:
- name: hasura-console-assets
mountPath: "/home" - Edit Hasura deployment yaml and use local console-assets by specifying the new location of the modified assets
- name: HASURA_GRAPHQL_CONSOLE_ASSETS_DIR
value: "/home" - It's a good idea to also hard code the Hasura version to avoid issues when newer versions are available and you've bounced a pod.
IS-Josh
on 3 Jun 2020
Related issues
 hudclark
·
4Comments
hudclark
·
4Comments
 ndeodhar
·
5Comments
ndeodhar
·
5Comments
 bmatican
·
3Comments
bmatican
·
3Comments
 frafra
·
3Comments
frafra
·
3Comments
 rhzs
·
5Comments
rhzs
·
5Comments
Most helpful comment
Hi, just letting you know i've found an optimisation for this query which enables it to run against large schemas and in a reasonable time for smaller schemas. I've passed on the suggestion to Hasura https://github.com/hasura/graphql-engine/issues/4925