❔Question
Hello, my two training results on the custom datasets are different, but the random seed and other parameters have not been modified. What is going on?
Additional context
- First training

- Second training

I can be sure that my other settings and training commands have not changed.
command:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node 4 train.py --batch-size 64 --data data/tiny_set.yaml --cfg yolov5s.yaml --weights '' --cache --device 0,1,2,3
first training train_batch0.jpg

second training train_batch0.jpg

 Pluto1314
Pluto1314
All 13 comments
@Pluto1314 there's not much use in examining partially completed trainings.
In any case, it's common knowledge that multithreaded ops, and CUDA ops are typically non-deterministic in nature.
https://pytorch.org/docs/stable/notes/randomness.html
There are some PyTorch functions that use CUDA functions that can be a source of nondeterminism. One class of such CUDA functions are atomic operations, in particular atomicAdd, which can lead to the order of additions being nondetermnistic. Because floating-point addition is not perfectly associative for floating-point operands, atomicAdd with floating-point operands can introduce different floating-point rounding errors on each evaluation, which introduces a source of nondeterministic variance (aka noise) in the result.
PyTorch functions that use atomicAdd in the forward kernels include torch.Tensor.index_add_(), torch.Tensor.scatter_add_(), torch.bincount().
A number of operations have backwards kernels that use atomicAdd, including torch.nn.functional.embedding_bag(), torch.nn.functional.ctc_loss(), torch.nn.functional.interpolate(), and many forms of pooling, padding, and sampling.
There is currently no simple way of avoiding nondeterminism in these functions.
Additionally, the backward path for repeat_interleave() operates nondeterministically on the CUDA backend because repeat_interleave() is implemented using index_select(), the backward path for which is implemented using index_add_(), which is known to operate nondeterministically (in the forward direction) on the CUDA backend (see above).
 glenn-jocher
on 27 Oct 2020
glenn-jocher
on 27 Oct 2020
Also from https://pytorch.org/docs/stable/notes/randomness.html:
REPRODUCIBILITY
Completely reproducible results are not guaranteed across PyTorch releases, individual commits or different platforms. Furthermore, results need not be reproducible between CPU and GPU executions, even when using identical seeds.
glenn-jocher
on 27 Oct 2020
Thank you very much for your response, so does this uncertainty have a big impact on the results?
Pluto1314
on 27 Oct 2020
@Pluto1314 variations due to inherent reproducibility issues would have the same impact on the final result as seed changes I suppose. In COCO training with different seeds would yield similar mAPs (but completely different model weights).
glenn-jocher
on 27 Oct 2020
The only method I'm aware of that might guarantee you identical results might be to train on CPU with --workers 0, but this is impractical naturally, so you simply need to adapt your workflow to accommodate minor variations in final model results.
glenn-jocher
on 27 Oct 2020
I get it, thank you very much for your answers.
Pluto1314
on 27 Oct 2020
I will close this issue, thanks again.
Pluto1314
on 27 Oct 2020
Hi, sorry to disturb you again. My two testing results got a big difference.
First training weight
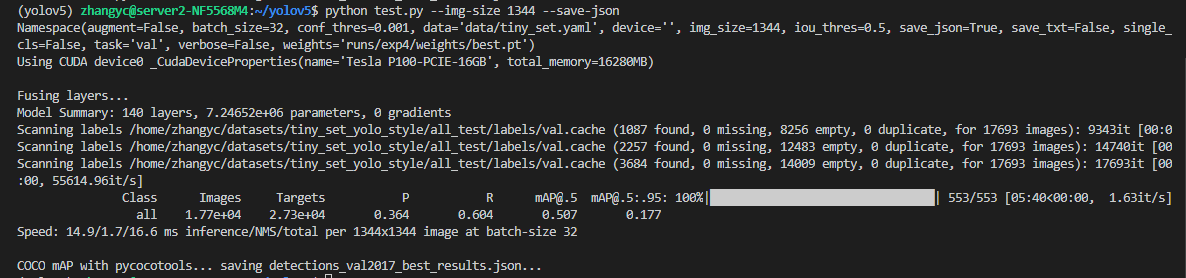
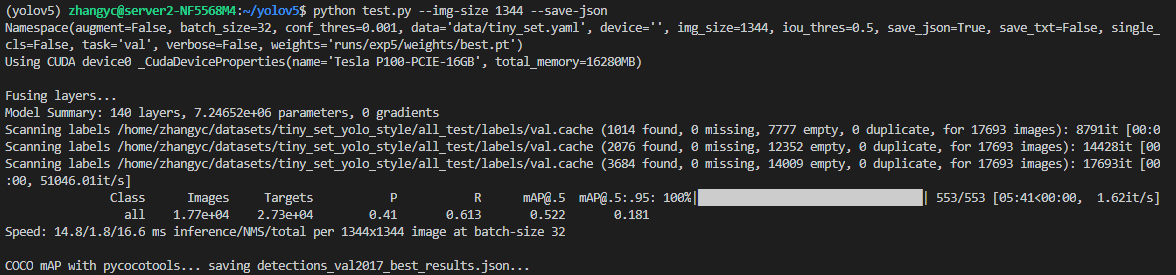
Second training weight
Pluto1314
on 28 Oct 2020
@glenn-jocher Will it not make such a big difference if I use a single GPU?
Pluto1314
on 28 Oct 2020
@Pluto1314 I have nothing to add to what I already posted before.
glenn-jocher
on 28 Oct 2020
@Pluto1314 Hey, just experiment with it. Even you have awesome P100 GPUs, haha. :)
 dongjuns
on 31 Oct 2020
dongjuns
on 31 Oct 2020
@dongjuns I really don't know how to solve it, even if I add these:
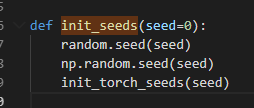
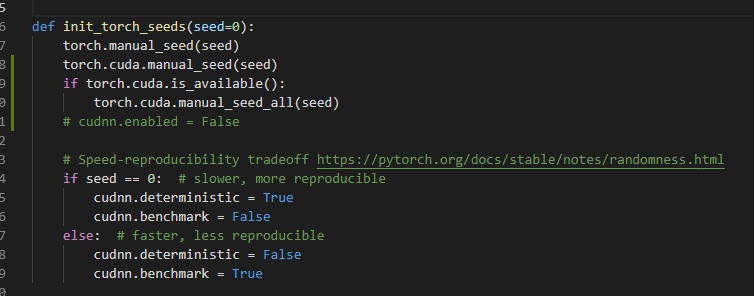
Pluto1314
on 31 Oct 2020
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
![github-actions[bot] picture](https://avatars2.githubusercontent.com/in/15368?v=4&s=40) github-actions[bot]
on 1 Dec 2020
github-actions[bot]
on 1 Dec 2020
Related issues
 e-shawakri
·
34Comments
e-shawakri
·
34Comments
 ZeKunZhang1998
·
40Comments
ZeKunZhang1998
·
40Comments
 ChristopherSTAN
·
33Comments
ChristopherSTAN
·
33Comments
 SamiurRahman1
·
23Comments
SamiurRahman1
·
23Comments
 NanoCode012
·
56Comments
NanoCode012
·
56Comments
Most helpful comment
The only method I'm aware of that might guarantee you identical results might be to train on CPU with --workers 0, but this is impractical naturally, so you simply need to adapt your workflow to accommodate minor variations in final model results.