Yolov5: Validation results are pretty good, but not working at inference time
Question
Please refer to the attachment for the issue.
Summary of the question:
- Even if the model works pretty good in validation data, why it is failing for both classification and localization of the objects in real time data (images downloaded from google)?
PS. I added inference time augmentation which increases the accuracy for classification but localization is still an issue.
Thanks in advance!
 anirbanmalick
anirbanmalick
All 7 comments
Hello @anirbanmalick, thank you for your interest in our work! Please visit our Custom Training Tutorial to get started, and see our Jupyter Notebook ![]() , Docker Image, and Google Cloud Quickstart Guide for example environments.
, Docker Image, and Google Cloud Quickstart Guide for example environments.
If this is a bug report, please provide screenshots and minimum viable code to reproduce your issue, otherwise we can not help you.
If this is a custom model or data training question, please note Ultralytics does not provide free personal support. As a leader in vision ML and AI, we do offer professional consulting, from simple expert advice up to delivery of fully customized, end-to-end production solutions for our clients, such as:
- Cloud-based AI systems operating on hundreds of HD video streams in realtime.
- Edge AI integrated into custom iOS and Android apps for realtime 30 FPS video inference.
- Custom data training, hyperparameter evolution, and model exportation to any destination.
For more information please visit https://www.ultralytics.com.
![github-actions[bot] picture](https://avatars2.githubusercontent.com/in/15368?v=4&s=40) github-actions[bot]
on 13 Oct 2020
github-actions[bot]
on 13 Oct 2020
@anirbanmalick I this your attachment may not be operating correctly. You can simply paste all of your information directly in the issue.
In any case, high validation mAP may not correlate well with real world results when your dataset fails to represent the deployed environment sufficiently. This is a common issue in deployments. The responsibility is on you to bring sufficient quantity and variety to the training data. If you want to see what works, look at the COCO dataset etc for guidance on this.
 glenn-jocher
on 13 Oct 2020
glenn-jocher
on 13 Oct 2020
Thanks for replying!
My bad if the document is not working properly. I am putting the snapshots from the same document for your reference.
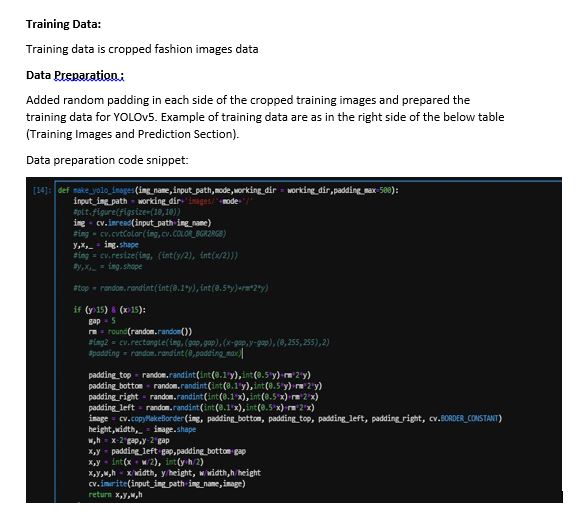
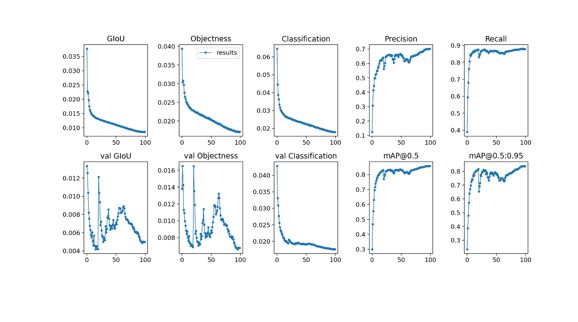




Note: The dataset is huge in terms of variability. However, since they are cropped initially, I hope it loses some variability in the beginning itself. Hope I am able to clarify my doubt.
What could be the possible way out in order to improve the localization?
Also want to know if the method of data preparation not sufficient/correct? What could be done to induce more variability in the training data without adding other labelled images (i.e, using the cropped images only as training data)?
anirbanmalick
on 13 Oct 2020
The images you train and validate on need to be as similar as the images you will be doing inference on. If you plan to do inference on images like those "real life" google images, then start annotation some of them and add them to your training data instead of having objects with black background.
If you can't make change to your training data, then you'll need to make the validation data as similar to those you plan to predict on and then the model will do what it can but that will not be near what its really able to do.
 Ownmarc
on 13 Oct 2020
Ownmarc
on 13 Oct 2020
It makes lot of sense Ownmarc. Thanks!
What do you suggest to be the population size per class if I am trying to add new samples like the 'real images' in the training data. From my experience, 800-1000 samples per class should work for fashion product images. Do you also agree with it?
anirbanmalick
on 13 Oct 2020
depends on the sparsity of the data, start with 300 per class, train a model, see if its good enough, if its not, use the previous model to annotate more data and correct it. You'll go faster like that (active learning) and you'll gain great insight on what the model is failing on). You'll want to get more data similar the the one its failing on. Its good practice to balance your classes if you can, but not necessary.
Ownmarc
on 13 Oct 2020
Yes, basically what @Ownmarc said is correct. You can't train for a soccer game by playing tennis.
glenn-jocher
on 13 Oct 2020
Related issues
 hktxt
·
3Comments
hktxt
·
3Comments
 ShreshthSaxena
·
4Comments
ShreshthSaxena
·
4Comments
 nanometer34688
·
3Comments
nanometer34688
·
3Comments
 FSNStefan
·
4Comments
FSNStefan
·
4Comments
 milind-soni
·
3Comments
milind-soni
·
3Comments